Esta arquitectura de referencia muestra cómo entrenar un modelo de recomendación mediante Azure Databricks y cómo implementarlo después como una API mediante el uso de Azure Cosmos DB, Azure Machine Learning y Azure Kubernetes Service (AKS). Para consultar una implementación de referencia de esta arquitectura, vea Creación de una API de recomendaciones en tiempo real en GitHub.
Architecture
Descargue un archivo Visio de esta arquitectura.
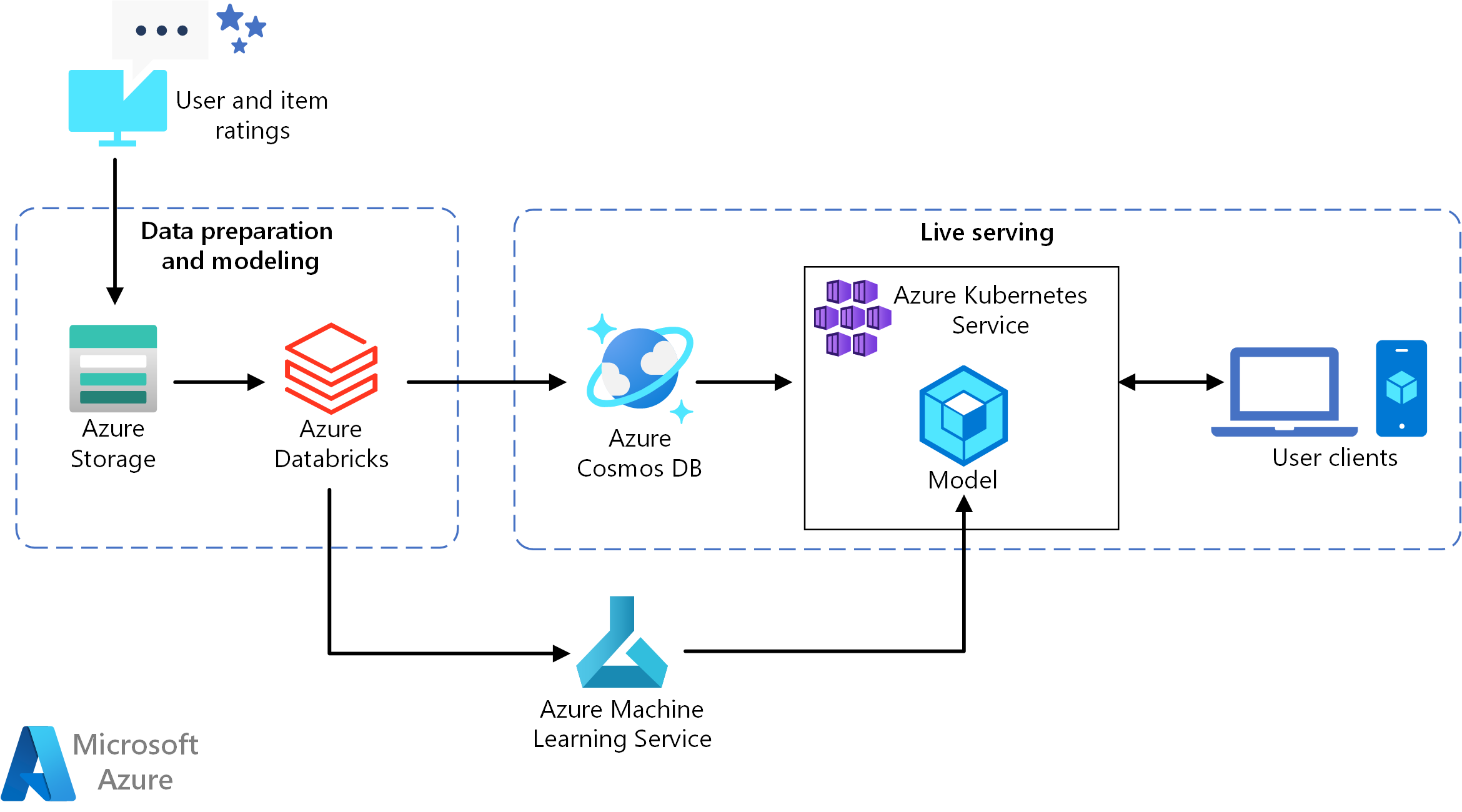
Esta arquitectura de referencia sirve para entrenar e implementar una API del servicio de recomendaciones en tiempo real que pueda proporcionar las recomendaciones de las diez mejores películas para un usuario.
Flujo de datos
- Seguimiento de los comportamientos de los usuarios. Por ejemplo, un servicio de back-end podría crear un registro cada vez que un usuario evalúa una película o hace clic en un artículo acerca de un producto o una noticia.
- Cargue los datos en Azure Databricks desde un origen de datos disponible.
- Prepare los datos y divídalos en conjuntos de entrenamiento y de pruebas para entrenar el modelo (en esta guía se describen las opciones para dividir los datos).
- Ajuste el modelo de filtrado en colaboración de Spark a los datos.
- Evalúe la calidad del modelo mediante métricas de clasificación. (En esta guía se proporcionan detalles sobre las métricas que puede usar para evaluar los recomendadores).
- Calcule previamente las diez principales recomendaciones por usuario y almacénelas como una memoria caché en Azure Cosmos DB.
- Implemente un servicio de API en AKS mediante las API de Machine Learning para incluir la API en un contenedor e implementarla.
- Cuando el servicio de back-end recibe una solicitud de un usuario, llame a la API de recomendaciones hospedada en AKS para obtener las diez principales recomendaciones y mostrárselas al usuario.
Componentes
- Azure Databricks. Databricks es un entorno de desarrollo que se usa para preparar los datos de entrada y entrenar el modelo de recomendación en un clúster de Spark. Azure Databricks también proporciona un área de trabajo interactiva para ejecutar cuadernos y colaborar en ellos en todas las tareas de procesamiento de datos o aprendizaje automático.
- Azure Kubernetes Service (AKS). AKS se usa para implementar y hacer operativa una API de servicio de un modelo de Machine Learning en un clúster de Kubernetes. AKS hospeda el modelo en contenedores, lo que proporciona una escalabilidad que cumple los requisitos de rendimiento, la administración de identidades y accesos, y la supervisión del registro y mantenimiento.
- Azure Cosmos DB. Azure Cosmos DB es un servicio de base de datos distribuida globalmente que se utiliza para almacenar las diez películas recomendadas a cada usuario. Azure Cosmos DB es ideal para este escenario, ya que proporciona baja latencia (10 ms en el percentil 99) para leer los principales elementos recomendados para un usuario dado.
- Aprendizaje automático. Este servicio se utiliza para realizar un seguimiento y administrar modelos de Machine Learning y, después, empaquetar e implementar dichos modelos en un entorno de AKS escalable.
- Microsoft Recommenders. Este repositorio de código abierto contiene código y ejemplos de la utilidad que ayudan a los usuarios empezar a compilar, evaluar y poner en marcha un sistema de recomendaciones.
Detalles del escenario
Esta arquitectura se puede generalizar para la mayoría de los escenarios del motor de recomendaciones, lo que incluye recomendaciones de productos, películas y noticias.
Posibles casos de uso
Escenario: Una organización de elementos multimedia desea proporcionar recomendaciones de películas o vídeos a sus usuarios. Al proporcionar recomendaciones personalizadas, la organización cumple varios objetivos empresariales, entre los que se incluyen una mayor proporción de clics, un aumento en la interacción en su sitio web y una mayor satisfacción del usuario.
Esta solución está optimizada para el sector minorista y los sectores de multimedia y entretenimiento.
Consideraciones
Estas consideraciones implementan los pilares del marco de buena arquitectura de Azure, que es un conjunto de principios guía que se pueden usar para mejorar la calidad de una carga de trabajo. Para más información, consulte Marco de buena arquitectura de Microsoft Azure.
En Puntuación por lotes de modelos de Spark en Azure Databricks se describe una arquitectura de referencia que usa Spark y Azure Databricks para ejecutar procesos de puntuación por lotes programados. Se recomienda este enfoque para generar nuevas recomendaciones.
Eficiencia del rendimiento
La eficiencia del rendimiento es la capacidad de la carga de trabajo para escalar con el fin de satisfacer de manera eficiente las demandas que los usuarios hayan ejercido sobre ella. Para obtener más información, vea Resumen del pilar de eficiencia del rendimiento.
El rendimiento es una consideración primordial para las recomendaciones en tiempo real, ya que las recomendaciones normalmente se encuentran en la ruta crítica de la solicitud que un usuario realiza en su sitio web.
La combinación de AKS y Azure Cosmos DB permite a esta arquitectura proporcionar un buen punto de partida para ofrecer recomendaciones para una carga de trabajo de tamaño medio con una sobrecarga mínima. En una prueba de carga con 200 usuarios simultáneos, esta arquitectura proporciona recomendaciones a una latencia mediana de aproximadamente 60 ms y funciona con un rendimiento de 180 solicitudes por segundo. La prueba de carga se ejecutó en la configuración de implementación predeterminado [un clúster de AKS 3x D3 v2 con 12 vCPU, 42 GB de memoria y 11 000 unidades de solicitud (RU) por segundo aprovisionadas para Azure Cosmos DB].
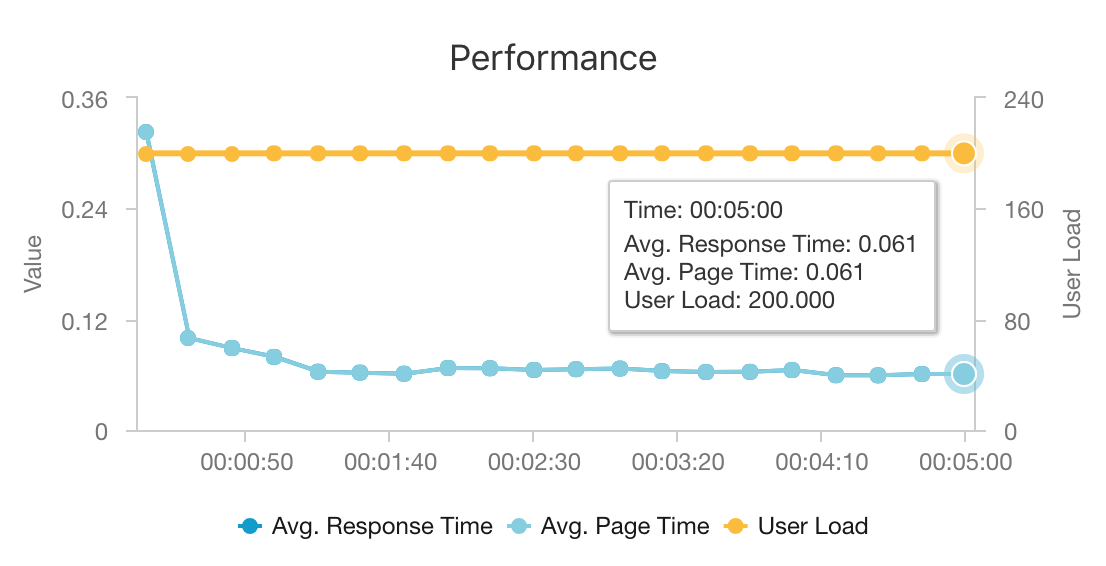
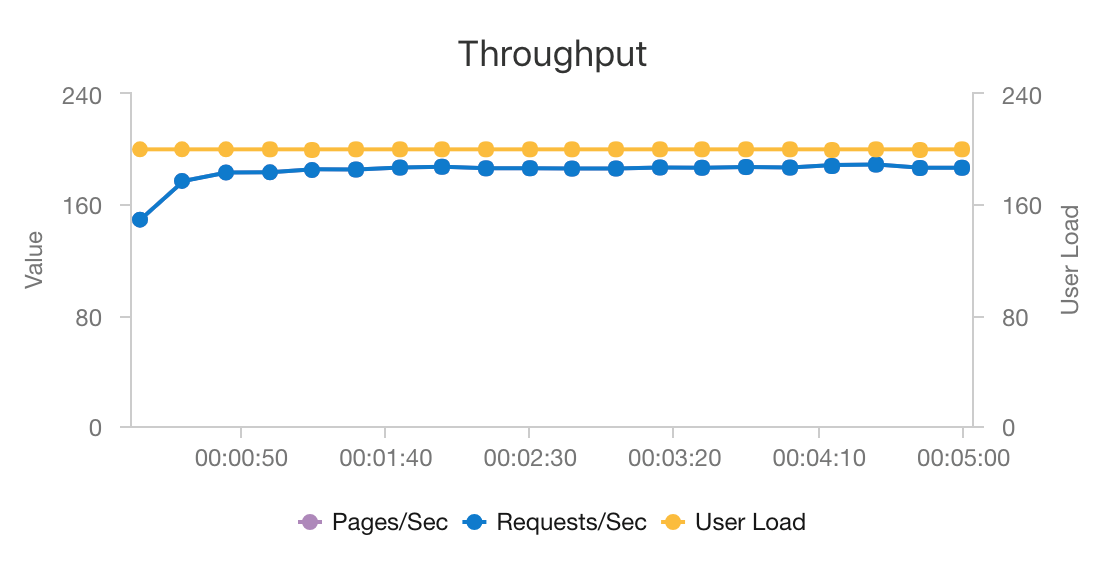
Azure Cosmos DB se recomienda por su distribución global llave en mano y su utilidad para satisfacer todos los requisitos de base de datos que tiene la aplicación. Para reducir la latencia ligeramente, considere la posibilidad de usar Azure Cache for Redis en lugar de Azure Cosmos DB para atender las búsquedas. Azure Cache for Redis puede mejorar el rendimiento de los sistemas que usan intensamente los datos de almacenes de back-end.
Escalabilidad
Si no planea usar Spark o tiene una carga de trabajo más pequeña que no necesita la distribución, considere la posibilidad de usar Data Science Virtual Machine (DSVM) en lugar de Azure Databricks. DSVM es una máquina virtual de Azure con marcos y herramientas de aprendizaje profundo para el aprendizaje automático y la ciencia de datos. Igual que sucede con Azure Databricks, cualquier modelo que se crea en una instancia de DSVM puedan usarse como un servicio en AKS mediante Machine Learning.
Durante el entrenamiento, aprovisione un clúster de Spark de mayor tamaño fijo en Azure Databricks o configure el escalado automático. Cuando el escalado automático está habilitado, Databricks supervisa la carga en el clúster y escala y reduce verticalmente según sea necesario. Aprovisione o escale horizontalmente un clúster mayor si tiene un tamaño de datos grande y desea reducir el tiempo que tarda en preparar datos o modelar tareas.
Escale el clúster de AKS para satisfacer sus necesidades de rendimiento. Procure escalar verticalmente el número de pods para utilizar plenamente el clúster y escalar la nodos del clúster para satisfacer la demanda del servicio. También puede configurar el escalado automático en un clúster de AKS. Para más información, consulte el documento Implementación de un modelo en el clúster de Azure Kubernetes Service.
Para administrar el rendimiento de Azure Cosmos DB, calcule el número de operaciones de lectura necesarias por segundo y aprovisione el número de RU por segundo (rendimiento) necesarias. Utilice los procedimientos recomendados para crear particiones y realizar el escalado horizontal.
Optimización de costos
La optimización de costos trata de buscar formas de reducir los gastos innecesarios y mejorar las eficiencias operativas. Para más información, vea Información general del pilar de optimización de costos.
Los controladores principales del costo en este escenario son:
- El tamaño de clúster de Azure Databricks necesario para el entrenamiento.
- El tamaño de clúster de AKS necesario para cumplir los requisitos de rendimiento.
- Las unidades de solicitud de Azure Cosmos DB aprovisionadas para cumplir los requisitos de rendimiento.
Administre los costos de Azure Databricks mediante la reducción de la frecuencia del entrenamiento y la desactivación del clúster de Spark cuando no esté en uso. Los costos de AKS y de Azure Cosmos DB están enlazados al rendimiento que requiere su sitio y se escalarán y reducirán verticalmente en función del volumen de tráfico del sitio.
Implementación de este escenario
Para implementar esta arquitectura, siga las instrucciones de Azure Databricks del documento de configuración. Brevemente, las instrucciones le indican que haga lo siguiente:
- Cree un área de trabajo de Azure Databricks.
- Cree un nuevo clúster con la siguiente configuración en Azure Databricks:
- Modo de clúster: Estándar
- Versión de Databricks Runtime: 4.3 (incluye Apache Spark 2.3.1 y Scala 2.11)
- Versión de Python: 3
- Tipo de controlador: Standard_DS3_v2
- Tipo de trabajo: Standard_DS3_v2 (mínimo y máximo según sea necesario)
- Terminación automática: (según sea necesario)
- Configuración de Spark: (según sea necesario)
- Variables de entorno: (según sea necesario)
- Cree un token de acceso personal en el área de trabajo de Azure Databricks. Consulte la documentación de autenticación de Azure Databricks para obtener más información.
- Clone el repositorio de Microsoft Recommenders en un entorno en el que pueda ejecutar scripts (por ejemplo, el equipo local).
- Siga las instrucciones de Instalación rápida para instalar las bibliotecas pertinentes en Azure Databricks.
- Siga las instrucciones de configuración de Instalación rápida para preparar Azure Databricks para la operacionalización.
- Importe el cuaderno de operacionalización de ALS Movie en su área de trabajo. Después de iniciar sesión en el área de trabajo de Azure Databricks, haga lo siguiente:
- Haga clic en Inicio en el lado izquierdo del área de trabajo.
- Haga clic con el botón derecho en el espacio en blanco del directorio principal. Seleccione Import (Importar).
- Seleccione URL y pegue lo siguiente en el campo de texto:
https://github.com/Microsoft/Recommenders/blob/main/examples/05_operationalize/als_movie_o16n.ipynb - Haga clic en Import.
- Abra el cuaderno en Azure Databricks y conecte el clúster configurado.
- Ejecute el cuaderno para crear los recursos de Azure necesarios para crear una API de recomendaciones que proporcione las diez recomendaciones de películas principales para un usuario determinado.
Colaboradores
Microsoft mantiene este artículo. Originalmente lo escribieron los siguientes colaboradores.
Creadores de entidad de seguridad:
- Miguel Fierro | Responsable principal de científicos de datos
- Nikhil Joglekar | Responsable de producto, algoritmos de Azure y ciencia de datos
Para ver los perfiles no públicos de LinkedIn, inicie sesión en LinkedIn.
Pasos siguientes
- Compilación de una API de recomendaciones en tiempo real
- ¿Qué es Azure Databricks?
- Azure Kubernetes Service
- Bienvenido a Azure Cosmos DB
- ¿Qué es Azure Machine Learning?