Aspectos técnicos de la distribución de datos global con Azure Cosmos DB
SE APLICA A: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Gremlin
Gremlin ![]() Table
Table
Azure Cosmos DB es un servicio fundamental de Azure, por lo que se implementa en todas las regiones de Azure del mundo, incluidas las nubes públicas, soberanas, gubernamentales y del Departamento de Defensa (DoD).
En un nivel alto, los datos de contenedores de Azure Cosmos DB se particionan horizontalmente en muchos conjuntos de réplicas, que replican las escrituras, en cada región. Los conjuntos de réplicas confirman las escrituras de forma duradera con un cuórum de mayoría.
Cada región contiene todas las particiones de datos de un contenedor de Azure Cosmos DB y puede atender operaciones tanto de lectura como de escritura cuando están habilitadas las operaciones de escritura en varias regiones. Si la cuenta de Azure Cosmos DB se distribuye entre N regiones de Azure, habrá al menos Nx 4 copias de todos los datos.
En un centro de datos, implementamos y administramos Azure Cosmos DB en sellos masivos de máquinas, cada uno con almacenamiento local dedicado. En un centro de datos, Azure Cosmos DB se implementa en muchos clústeres, cada uno de los cuales puede ejecutar varias generaciones de hardware. Las máquinas de un clúster suelen repartirse entre 10 y 20 dominios de error para la alta disponibilidad dentro de una región. La siguiente imagen muestra la topología del sistema de distribución global de Azure Cosmos DB:
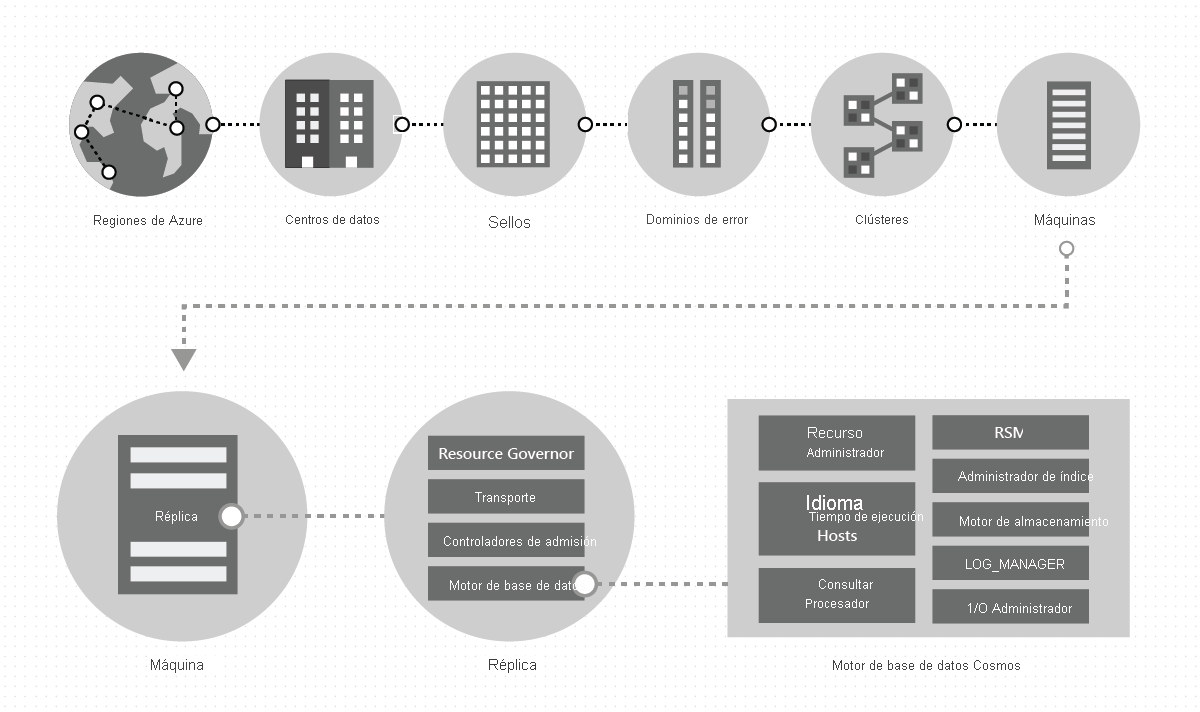
La distribución global en Azure Cosmos DB es inmediata: en cualquier momento y con solo unos cuantos clics o mediante programación con una sola llamada API, puede agregar o quitar las regiones geográficas asociadas a su base de datos de Azure Cosmos DB. Una base de datos de Azure Cosmos DB, a su vez, consta de un conjunto de contenedores de Azure Cosmos DB. En Azure Cosmos DB, los contenedores sirven de unidades lógicas de distribución y escalabilidad. Las colecciones, tablas y gráficos que se crean son (internamente) tan solo contenedores de Azure Cosmos DB. Los contenedores son totalmente independientes del esquema y proporcionan un ámbito para una consulta. Los datos de un contenedor de Azure Cosmos DB se indexan automáticamente tras su ingesta. La indexación automática permite a los usuarios consultar los datos sin las complicaciones relativas al esquema o a la administración de índices, especialmente en una configuración distribuida globalmente.
En una región determinada, los datos de un contenedor se distribuyen mediante una clave de partición que el usuario especifica y que las particiones físicas subyacentes (distribución local) administran de forma transparente.
Cada partición física también se replica en regiones geográficas (distribución global).
Cuando una aplicación que usa Azure Cosmos DB escala elásticamente el rendimiento en un contenedor de Azure Cosmos DB o consume más almacenamiento, Azure Cosmos DB controla las operaciones de administración de particiones (dividir, clonar, eliminar) de manera transparente en todas las regiones. Independientemente del escalado, la distribución o los errores, Azure Cosmos DB continúa proporcionando una sola imagen de sistema de los datos incluidos en los contenedores, que se distribuyen globalmente en cualquier cantidad de regiones.
Como se observa en la imagen siguiente, los datos de un contenedor se distribuyen a lo largo de dos dimensiones: dentro de una región y entre regiones, en todo el mundo:
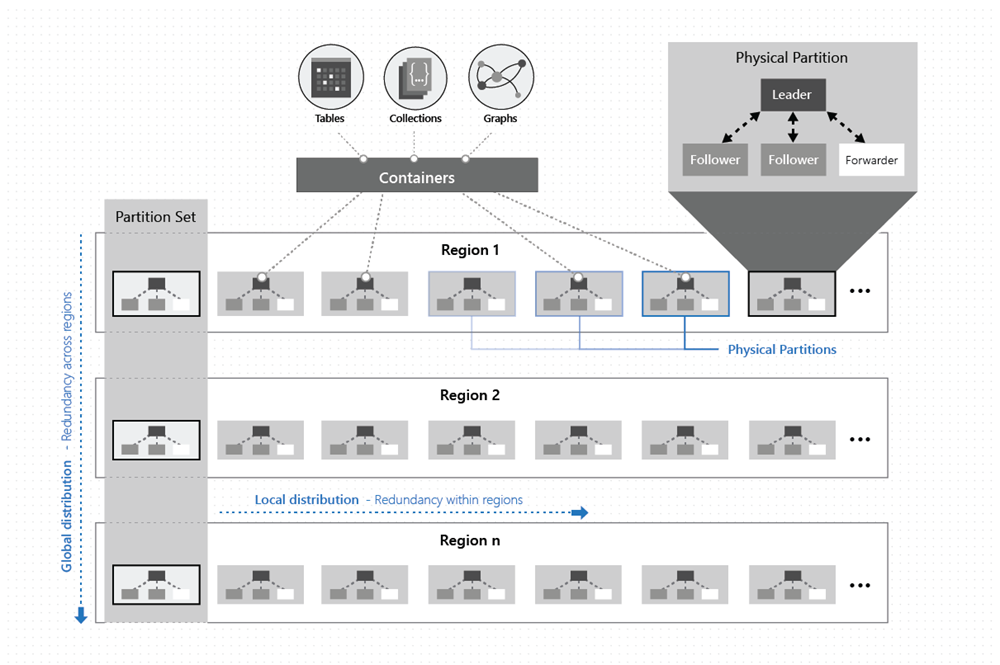
Una partición física se implementa por medio de un grupo de réplicas, llamado conjunto de replicas. Cada máquina hospeda cientos de réplicas que corresponden a diversas particiones físicas incluidas en un conjunto fijo de procesos, tal y como se muestra en la imagen anterior. Las réplicas que corresponden a las particiones físicas se colocan y su carga se equilibra de forma dinámica en las máquinas de un clúster y los centros de datos de una región.
Una réplica pertenece de forma exclusiva a un inquilino de Azure Cosmos DB. Cada réplica hospeda una instancia del motor de base de datos de Azure Cosmos DB, que administra los recursos, así como los índices asociados. El motor de base de datos de Azure Cosmos DB funciona en un sistema tipo basado en la secuencia de registro de átomos (ARS). El motor es independiente del concepto de esquema y difumina el límite entre la estructura y los valores de instancia de los registros. Azure Cosmos DB logra la independencia total del esquema indexando todo automáticamente tras la ingesta de datos de forma eficaz, lo que permite a los usuarios consultar sus datos distribuidos globalmente sin tener que ocuparse de la administración de esquemas o de índices.
El motor de base de datos de Azure Cosmos DB consta de componentes como la implementación de varios primitivos de coordinación, tiempos de ejecución del lenguaje, el procesador de consultas y los subsistemas de almacenamiento e indexación responsables del almacenamiento transaccional y la indexación de datos, respectivamente. Para proporcionar durabilidad y alta disponibilidad, el motor de base de datos conserva sus datos y el índice en discos SSD y los replica entre las instancias de motor de base de datos de los conjuntos de réplicas, respectivamente. Los inquilinos más grandes corresponden a una mayor escala de rendimiento y almacenamiento y tienen réplicas más grandes o una mayor cantidad de las mismas o bien ambas cosas. Todos los componentes del sistema son completamente asincrónicos: no se bloquea ningún subproceso y el trabajo que realiza cada uno es de corta duración, sin incurrir en ningún cambio de subproceso innecesario. La limitación de frecuencia y la contrapresión se asocian en toda la pila desde el control de admisión a todas las rutas de acceso de E/S. El motor de base de datos de Azure Cosmos DB se ha diseñado para explotar la simultaneidad específica y ofrecer un alto rendimiento mientras opera en cantidades moderadas de recursos del sistema.
La distribución global de Azure Cosmos DB se basa en dos abstracciones clave: los conjuntos de réplicas y los conjuntos de particiones. Un conjunto de réplicas es un bloque Lego modular para la coordinación, mientras que un conjunto de particiones es una superposición dinámica de una o varias particiones físicas distribuidas geográficamente. Para entender el funcionamiento de la distribución global, es preciso comprender estas dos abstracciones clave.
Conjuntos de réplicas
Una partición física se materializa como un grupo de réplicas autoadministradas cuya carga se equilibra de forma dinámica que se reparten entre varios dominios de error, llamados conjunto de réplicas. Este conjunto implementa de forma colectiva el protocolo de máquina de estado replicado para que los datos de la partición física tengan una alta disponibilidad y sean duraderos y fuertemente coherentes. La pertenencia a N conjuntos de réplicas es dinámica: fluctúa entre NMin y NMax en función de los errores, las operaciones administrativas y el tiempo de regeneración o recuperación de las réplicas con errores. En función de los cambios de pertenencia, el protocolo de replicación también reconfigura el tamaño de los cuórums de lectura y escritura. Para distribuir uniformemente el rendimiento que se asigna a una determinada partición física, se emplean dos ideas:
En primer lugar, el costo de procesar las solicitudes de escritura en el líder es mayor que el costo de aplicar las actualizaciones en el seguidor. Consecuentemente, al líder se le presupuestan más recursos del sistema que a los seguidores.
En segundo lugar, en la medida de lo posible, el cuórum de lectura para un nivel de coherencia especificado se compone exclusivamente de las réplicas de los seguidores. Evitamos ponernos en contacto con el líder para el servicio de lecturas a menos que sea absolutamente necesario. Empleamos una serie de ideas de la investigación sobre la relación de carga y capacidad en los sistemas basados en cuórum para los cinco modelos de coherencia que admite Azure Cosmos DB.
Conjuntos de particiones
Se compone un grupo de particiones físicas, uno de cada una de las configuradas con las regiones de la base de datos de Azure Cosmos DB, para administrar el mismo conjunto de claves que se replican en todas las regiones configuradas. Esta primitiva de coordinación superior se llama un conjunto de particiones: una superposición dinámica geográficamente distribuida de particiones físicas que administran un conjunto de claves determinado. Mientras que una determinada partición física (un conjunto de réplicas) tiene el ámbito de un clúster, un conjunto de particiones puede abarcar clústeres, centros de datos y regiones geográficas, tal como se muestra en la imagen siguiente:
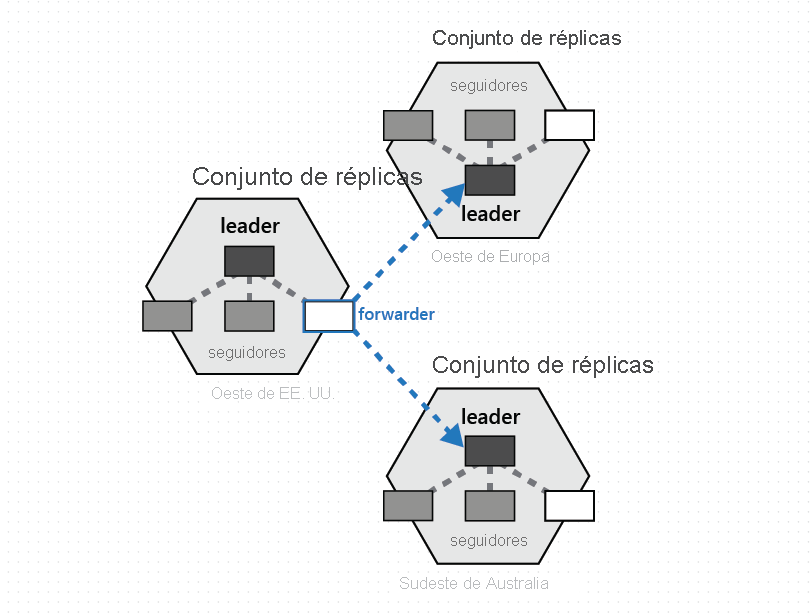
Puede ver un conjunto de particiones como un "superconjunto de réplicas" geográficamente disperso, que consta de varios conjuntos de réplicas que poseen el mismo conjunto de claves. Similar a un conjunto de réplicas, la pertenencia a un conjunto de particiones también es dinámica, varía en función de las operaciones de administración de particiones físicas implícitas necesarias para agregar o eliminar particiones nuevas hacia y desde un conjunto de particiones determinado (por ejemplo, al escalar horizontalmente el rendimiento de un contenedor, agregar o quitar una región a la base de datos de Azure Cosmos DB o cuando se producen errores). Al hacer que cada una de las particiones (de un conjunto de particiones) administre la pertenencia del conjunto de particiones dentro de su propio conjunto de réplicas, la pertenencia es totalmente descentralizada y de alta disponibilidad. Durante la reconfiguración de un conjunto de particiones, también se establece la topología de la superposición entre las particiones físicas. La topología se selecciona de forma dinámica en función del nivel de coherencia, la distancia geográfica y el ancho de banda de red disponible entre las particiones físicas de origen y las de destino.
El servicio le permite configurar sus bases de datos de Azure Cosmos DB con una sola región de escritura o varias de ellas y, según la opción, los conjuntos de particiones están configurados para aceptar las escrituras exactamente en una o en todas las regiones. El sistema emplea un protocolo de consensos anidado de dos niveles: un nivel funciona en las réplicas de un conjunto de réplicas de una partición física que acepta las escrituras, mientras que el otro funciona en el nivel de un conjunto de particiones para ofrecer garantías de ordenación completas para todas las escrituras confirmadas en el conjunto de particiones. Este consenso anidado multicapa es fundamental para la implementación de nuestros estrictos contratos de nivel de servicio de alta disponibilidad, así como para la implementación de los modelos de coherencia, que Azure Cosmos DB ofrece a sus clientes.
Resolución de conflictos
Nuestro diseño para la propagación de actualizaciones, la resolución de conflictos y el seguimiento de causalidades está inspirado en el anterior trabajo sobre algoritmos epidémicos y el sistema Bayou. Mientras que los kernels de las ideas han sobrevivido y proporcionan un cómodo marco de referencia para comunicar el diseño del sistema de Azure Cosmos DB, también han experimentado una transformación significativa al aplicarlos al sistema de Azure Cosmos DB. Esto era necesario, ya que los sistemas anteriores no estaban diseñados ni con la gobernanza de recursos ni con la escala en la que Azure Cosmos DB necesita funcionar ni tampoco para proporcionar las funcionalidades (por ejemplo, coherencia de obsolescencia limitada) y los estrictos y completos contratos de nivel de servicio que Azure Cosmos DB ofrece a sus clientes.
Recuerde que un conjunto de particiones se distribuye entre varias regiones y sigue el protocolo de replicación (escrituras en varias regiones) de Azure Cosmos DB para replicar los datos entre las particiones físicas que componen un conjunto de particiones determinado. Cada partición física (de un conjunto de particiones) acepta las escrituras y suele ofrecer lecturas a los clientes que son locales en esa región. Las escrituras aceptadas por una partición física de una región se confirman permanentemente y tienen una alta disponibilidad en la partición física antes de ser reconocidas por el cliente. Se trata de escrituras provisionales que se propagan a otras particiones físicas en el conjunto de particiones mediante un canal de antientropía. Los clientes pueden solicitar escrituras provisionales o confirmadas pasando un encabezado de la solicitud. La propagación de antientropía (incluida la frecuencia de propagación) es dinámica, según la topología del conjunto de particiones, la proximidad regional de las particiones físicas y el nivel de coherencia configurado. En un conjunto de particiones, Azure Cosmos DB sigue un esquema de confirmación principal con una partición de árbitro seleccionada dinámicamente. La selección de árbitro es dinámica y forma parte integral de la reconfiguración del conjunto de particiones según la topología de la superposición. Se garantiza que las escrituras confirmadas (incluidas las actualizaciones de varias filas o por lotes) están totalmente ordenadas.
Empleamos relojes vectoriales codificados (que contienen relojes lógicos y de id. de región que corresponden a cada nivel de consenso en el conjunto de réplicas y el conjunto de particiones, respectivamente) para que el seguimiento de causalidades y los vectores de versión detecten y resuelvan conflictos relativos a las actualizaciones. La topología y el algoritmo de selección de homólogos se han diseñado para garantizar un almacenamiento fijo y mínimo y una sobrecarga de red mínima de los vectores de versión. El algoritmo garantiza la propiedad de convergencia estricta.
En las bases de datos de Azure Cosmos DB configuradas con varias regiones de escritura, el sistema ofrece varias directivas de resolución de conflictos automáticas flexibles para que los desarrolladores elijan entre ellas, incluidas:
- La última escritura gana (LWW) que, de forma predeterminada, usa una propiedad de marca de tiempo definida por el sistema (que se basa en el protocolo de reloj de sincronización de hora). Azure Cosmos DB también permite especificar cualquier otra propiedad numérica personalizada que se vaya a usar para la resolución de conflictos.
- Directiva de resolución de conflictos definida por la aplicación (personalizada) (expresada mediante procedimientos de combinación) que se ha diseñado para la conciliación de conflictos con la semántica definida por la aplicación. Estos procedimientos se invocan tras la detección de los conflictos de escritura-escritura bajo los auspicios de una transacción de base de datos en el servidor. El sistema garantiza exactamente una vez la ejecución de un procedimiento de combinación como parte del protocolo de confirmación. Hay varios ejemplos de resolución de conflictos disponibles con los que puede practicar.
Modelos de coherencia
Independientemente de si configura la base de datos de Azure Cosmos DB con una o con varias regiones de escritura, puede elegir entre cinco modelos de coherencia bien definidos. Con varias regiones de escritura, a continuación se indican algunos aspectos notables de los niveles de coherencia:
La coherencia de obsolescencia limitada garantiza que todas las lecturas van a estar dentro de K prefijos o T segundos desde la última escritura en cualquiera de las regiones. Además, se garantiza que las lecturas con coherencia de obsolescencia limitada son monotónicas y con garantías de prefijo coherente. El protocolo de antientropía funciona con limitación de frecuencia y garantiza que los prefijos no se acumulen y que la resistencia en los escritos no tenga que aplicarse. La coherencia de sesión asegura las garantías de lectura monotónica, de escritura monotónica, de lectura de sus propias escrituras, de escritura tras lectura y de prefijo coherente en todo el mundo. Para las bases de datos configuradas con una gran coherencia, las ventajas de varias regiones de escritura (baja latencia de escritura y alta disponibilidad de escritura) no se aplican debido a la replicación sincrónica entre regiones.
La semántica de los cinco modelos de coherencia de Azure Cosmos DB se describe aquí y se describe matemáticamente con especificaciones de TLA+ de alto nivel aquí.
Pasos siguientes
A continuación, aprenda a configurar la distribución global mediante los siguientes artículos:
- Agregar o eliminar regiones de una cuenta de base de datos
- Procedimientos de creación de una directiva de resolución de conflictos personalizada
- ¿Intenta planear la capacidad de una migración a Azure Cosmos DB? Para ello, puede usar información sobre el clúster de bases de datos existente.
- Si lo único que sabe es el número de núcleos virtuales y servidores del clúster de bases de datos existente, lea sobre el cálculo de unidades de solicitud mediante núcleos o CPU virtuales.
- Si conoce las tasas de solicitudes típicas de la carga de trabajo de la base de datos actual, obtenga información sobre el cálculo de unidades de solicitud mediante la herramienta de planeamiento de capacidad de Azure Cosmos DB.