Ingesta de datos mediante Azure Data Factory en Azure Cosmos DB for PostgreSQL
SE APLICA A: ![]() Azure Cosmos DB for PostgreSQL (con tecnología de la extensión de base de datos de Citus en PostgreSQL)
Azure Cosmos DB for PostgreSQL (con tecnología de la extensión de base de datos de Citus en PostgreSQL)
Azure Data Factory es un servicio de integración de datos y ETL basado en la nube. Permite crear flujos de trabajo controlados por datos para mover y transformar datos a gran escala.
Con Data Factory, puede crear y programar flujos de trabajo controlados por datos (denominados canalizaciones) que ingieren datos de distintos almacenes. Las canalizaciones pueden ejecutarse de forma local, en Azure o en otros proveedores de nube para su análisis y la generación de informes sobre ellas.
Data Factory tiene un receptor de datos para Azure Cosmos DB for PostgreSQL. El receptor de datos permite incorporar los datos (relacionales, NoSQL, archivos de lago de datos) a tablas de Azure Cosmos DB for PostgreSQL para almacenarlos, procesarlos y generar informes sobre ellos.
Importante
Data Factory no admite puntos de conexión privados para Azure Cosmos DB for PostgreSQL en este momento.
Data Factory para la ingesta en tiempo real
Estas son las razones principales para elegir Azure Data Factory para la ingesta de datos en Azure Cosmos DB for PostgreSQL:
- Fácil de usar: ofrece un entorno visual sin código para orquestar y automatizar el movimiento de datos.
- Eficaz: usa la capacidad completa del ancho de banda de red subyacente, hasta 5 GiB/s de rendimiento.
- Conectores integrados: integra todos los orígenes de datos, con más de 90 conectores integrados.
- Rentable: admite un servicio en la nube sin servidor totalmente administrado y de pago por uso que se escala a petición.
Pasos para usar Data Factory
En este artículo, creará una canalización de datos mediante la interfaz de usuario (UI) de Data Factory. La canalización de esta factoría de datos copia los datos de Azure Blob Storage a una base de datos. Para obtener una lista de los almacenes de datos que se admiten como orígenes y receptores, consulte la tabla de almacenes de datos admitidos.
En Data Factory, puede usar la actividad de copia para copiar datos entre almacenes de datos locales y en la nube en Azure Cosmos DB for PostgreSQL. Si no conoce Data Factory, esta es una guía rápida sobre cómo empezar:
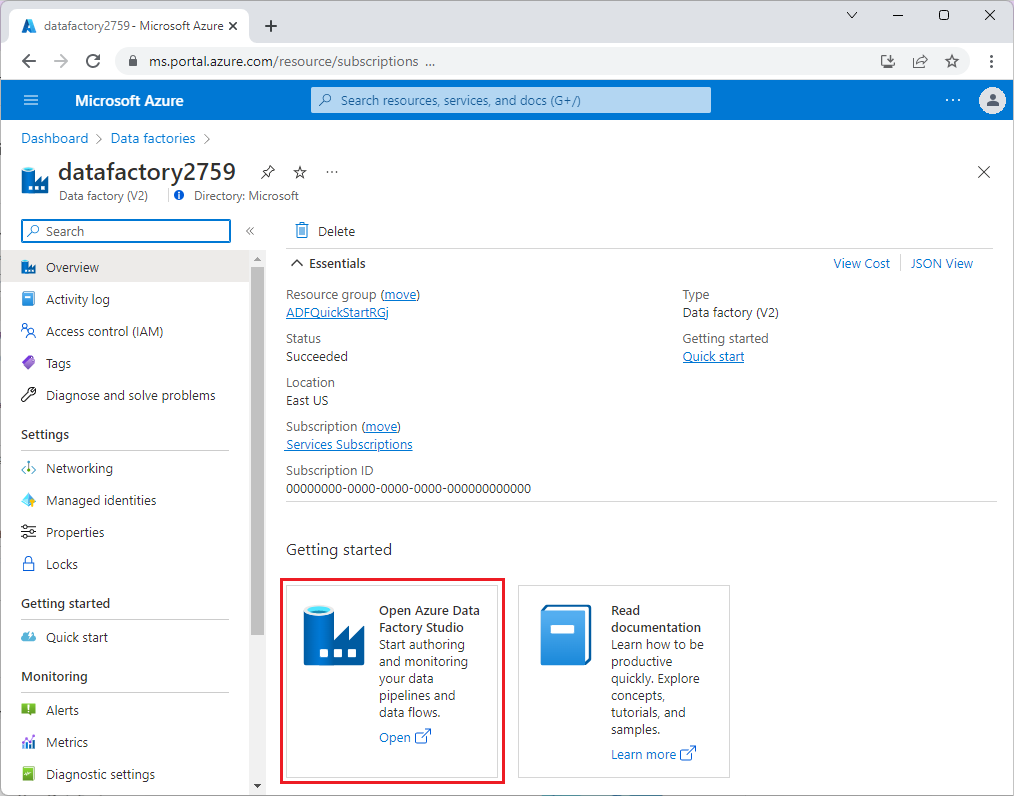
Una vez aprovisionado Data Factory, vaya a la factoría de datos e inicie Azure Data Factory Studio. Verá la página principal de Factoría de datos, tal y como se muestra en la siguiente imagen:
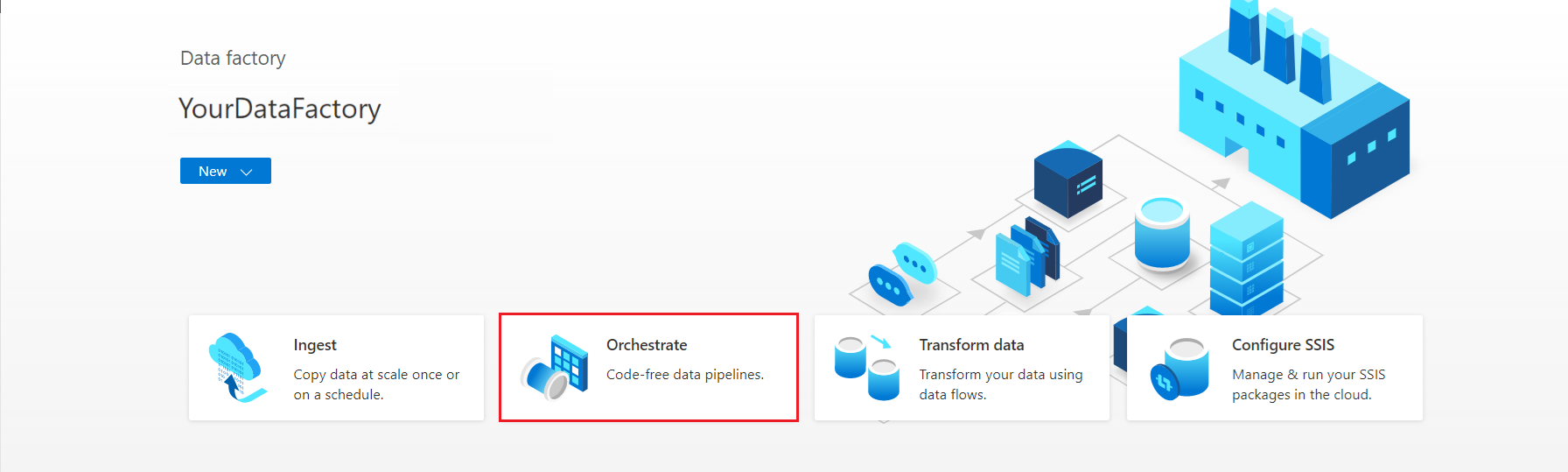
En la página principal de Azure Data Factory Studio, seleccione Orquestar.
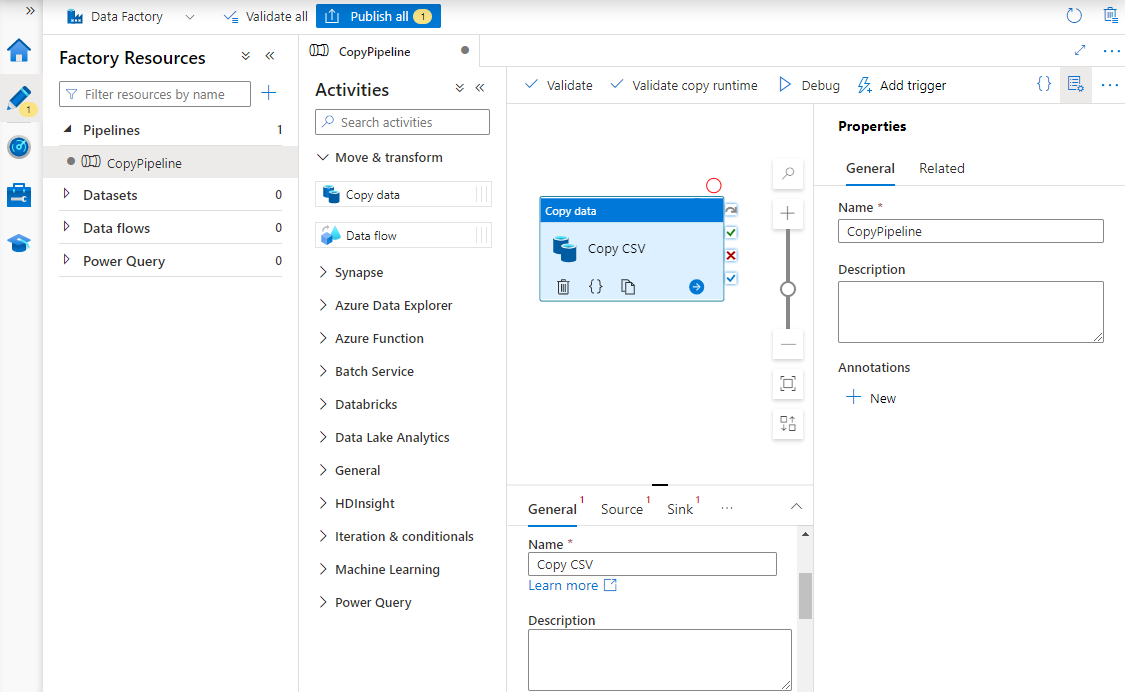
En Propiedades, escriba un nombre para la canalización.
En el cuadro de herramientas Actividades, expanda la categoría Mover y transformar y arrastre y coloque la actividad Copiar datos en la superficie del diseñador de canalizaciones. En la parte inferior del panel del diseñador, en la pestaña General, escriba un nombre para la actividad de copia.
Configure el origen.
En la página Actividades, seleccione la pestaña Origen. Seleccione Nuevo para crear un conjunto de datos de origen.
En el cuadro de diálogo New Dataset (Nuevo conjunto de datos), seleccione Azure Blob Storage y, después, seleccione Continue (Continuar).
Elija el tipo de formato de los datos y, luego, seleccione Continuar.
En la página Establecer propiedades, en Servicio vinculado, seleccione Nuevo.
En la página Nuevo servicio vinculado, escriba un nombre para el servicio vinculado y seleccione la cuenta de almacenamiento en la lista Nombre de la cuenta de almacenamiento.
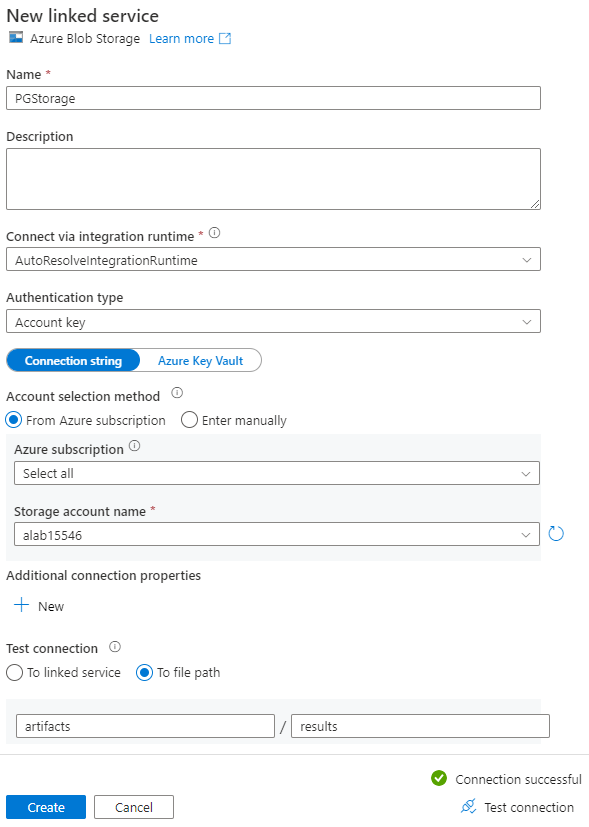
En Probar conexión, seleccione Para la ruta de acceso del archivo, escriba el contenedor y el directorio al que conectarse y, luego, seleccione Probar conexión.
Para crear la configuración, seleccione Guardar.
En la pantalla Establecer propiedades, seleccione Aceptar.
Configure el receptor.
En la página Actividades, seleccione la pestaña Receptor. Seleccione Nuevo para crear un conjunto de datos de receptor.
En el cuadro de diálogo Nuevo conjunto de datos, seleccione Azure Database for PostgreSQL y, después, Continuar.
En la página Establecer propiedades, en Servicio vinculado, seleccione Nuevo.
En la página Nuevo servicio vinculado, escriba un nombre para el servicio vinculado y seleccione Especificar manualmente en Método de selección de cuenta.
Escriba el nombre del coordinador del clúster en el campo Nombre de dominio completo. Puede copiar el nombre del coordinador de la página Información general del clúster de Azure Cosmos DB for PostgreSQL.
Deje el puerto predeterminado 5432 en el campo Puerto para la conexión directa al coordinador o reemplácelo por el puerto 6432 para conectarse al puerto PgBouncer administrado.
Escriba el nombre de la base de datos en el clúster y proporcione las credenciales para conectarse a él.
Seleccione SSL en la lista desplegable Método de cifrado.
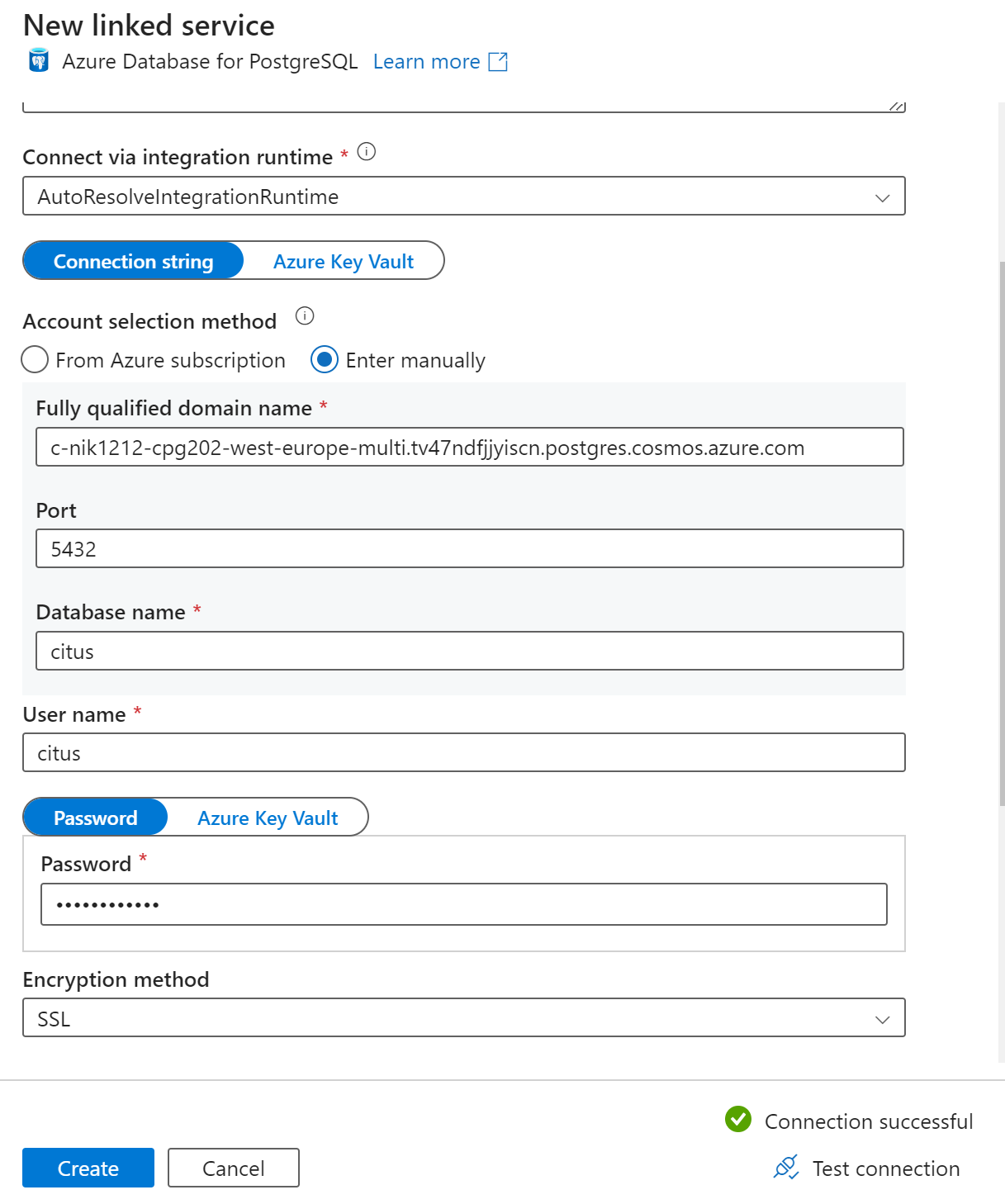
Seleccione Probar conexión en la parte inferior del panel para validar la configuración del receptor.
Para crear la configuración, seleccione Guardar.
En la pantalla Establecer propiedades, seleccione Aceptar.
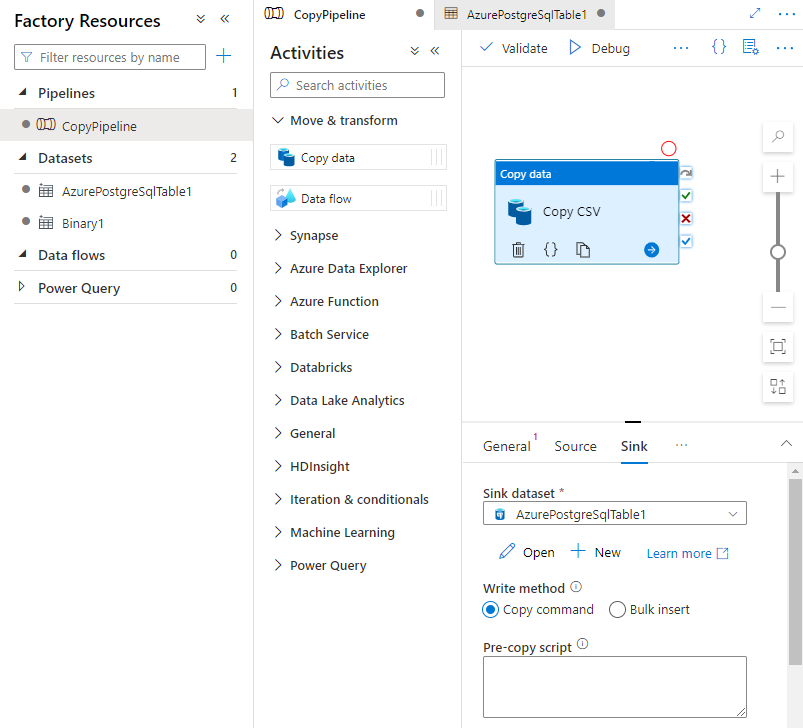
En la pestaña Receptor de la página Actividades, seleccione Abrir junto a la lista desplegable Conjunto de datos de receptor y seleccione el nombre de la tabla en el clúster de destino donde desea ingerir los datos.
En Método de escritura, seleccione Copiar comando.
En la barra de herramientas encima del lienzo, seleccione Validar para validar la configuración de la canalización. Corrija los errores, vuelva a realizar la validación y asegúrese de que la canalización se ha validado correctamente.
Seleccione Depurar en la barra de herramientas para ejecutar la canalización.
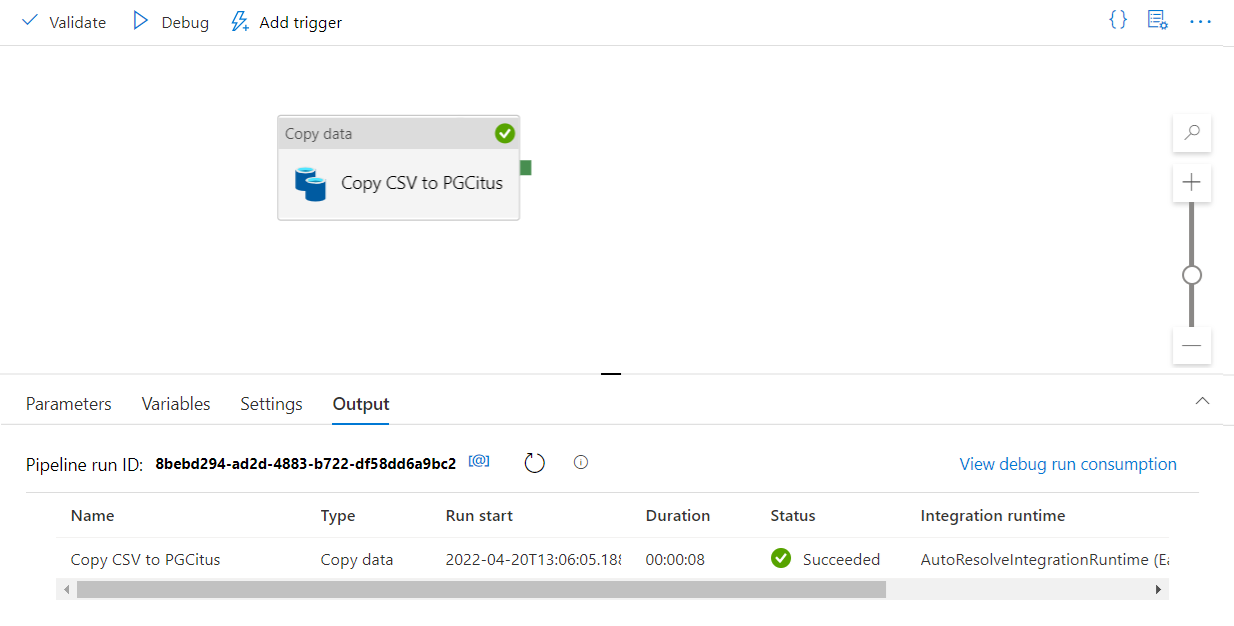
Una vez que la canalización se puede ejecutar correctamente, en la barra de herramientas superior, seleccione Publish all (Publicar todo). Esta acción publica las entidades (conjuntos de datos y canalizaciones) que creó para Data Factory.
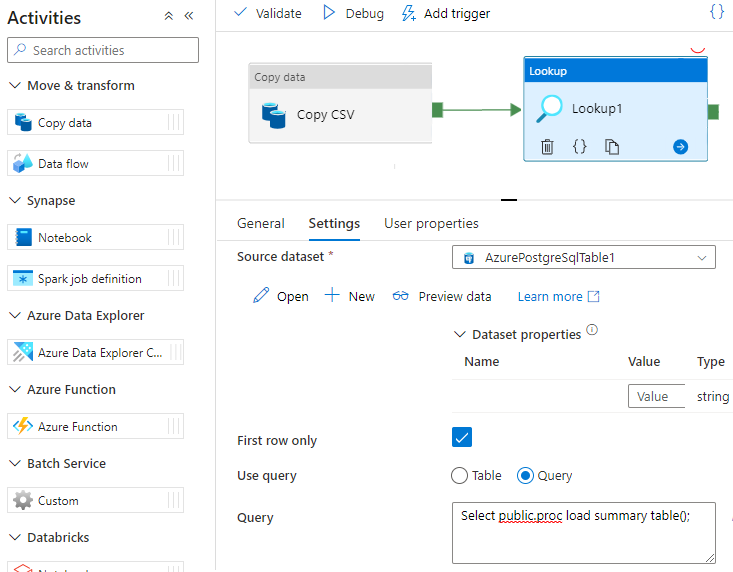
Llamada a un procedimiento almacenado en Data Factory
En algunos escenarios específicos, podría llamar a un procedimiento almacenado o a una función para insertar datos agregados de la tabla de almacenamiento provisional a la tabla de resumen. Data Factory no ofrece una actividad de procedimiento almacenado para Azure Cosmos DB for PostgreSQL, pero como solución alternativa, puede usar la actividad de búsqueda con una consulta para llamar a un procedimiento almacenado, como se muestra a continuación:
Pasos siguientes
- Obtenga información sobre cómo crear un panel en tiempo real con Azure Cosmos DB for PostgreSQL.
- Aprenda a trasladar la carga de trabajo a Azure Cosmos DB for PostgreSQL.