Solución de problemas de redes con las métricas y los registros de Network Watcher
Si quiere diagnosticar un problema rápidamente, debe comprender la información disponible en los registros de Azure Network Watcher.
En su empresa de ingeniería, quiere reducir al máximo el tiempo que dedica el personal a diagnosticar y resolver cualquier problema de configuración de red. Quiere asegurarse de que saben qué información está disponible en cada registro.
En este módulo, se centrará en los registros de flujo, los registros de diagnóstico y el análisis de tráfico. Aprenderá cómo pueden ayudar estas herramientas a solucionar problemas de la red de Azure.
Uso y cuotas
Puede usar todos los recursos de Microsoft Azure hasta alcanzar su cuota. Cada suscripción tiene cuotas independientes y se realiza el seguimiento del uso para cada suscripción. Se necesita una sola instancia de Network Watcher por suscripción y región. Esta instancia proporciona una vista del uso y las cuotas para que compruebe si corre el riesgo de alcanzar una cuota.
Para ver la información de uso y cuotas, vaya a Todos los servicios>Redes>Network Watcher y, después, seleccione Uso y cuotas. Verá datos pormenorizados en función del uso y la ubicación del recurso. Se capturan datos para las métricas siguientes:
- Interfaces de red
- Grupos de seguridad de red (NSG)
- Redes virtuales
- Direcciones IP públicas
Este es un ejemplo en el que se muestra el uso y las cuotas en el portal:

Registros
Los registros de diagnóstico de red proporcionan datos pormenorizados. Usará estos datos para comprender mejor los problemas de rendimiento y conectividad. Hay tres herramientas de visualización de registros en Network Watcher:
- Registros de flujos de NSG
- Registros de diagnóstico
- Análisis de tráfico
Echemos un vistazo a cada una de estas herramientas.
Registros de flujos de NSG
En los registros de flujos puede ver información sobre el tráfico IP de entrada y salida en los grupos de seguridad de red. Los registros de flujos muestran los flujos de entrada y salida por cada regla en función del adaptador de red al que se aplica el flujo. Los registros de flujos de grupos de seguridad de red muestran si el tráfico se ha permitido o denegado en función de la información de cinco tuplas capturada. Esta información incluye lo siguiente:
- IP de origen
- Puerto de origen
- IP de destino
- Puerto de destino
- Protocolo
En este diagrama se muestra el flujo de trabajo que sigue el grupo de seguridad de red.
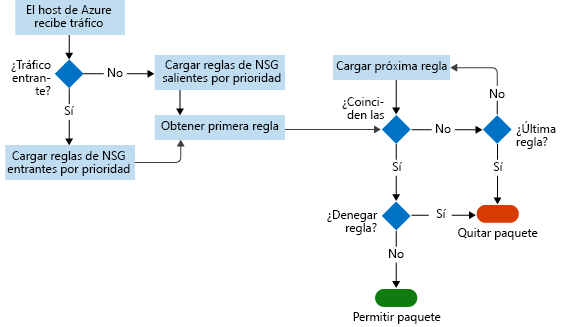
Los registros de flujos almacenan los datos en un archivo JSON. Puede ser difícil obtener información sobre estos datos mediante la búsqueda manual en los archivos de registro, sobre todo si tiene una implementación de infraestructura de gran tamaño en Azure. Para solucionar este problema, use Power BI.
En Power BI, puede visualizar los registros de flujos de grupos de seguridad de red de muchas formas. Por ejemplo:
- Llamadores principales (dirección IP)
- Flujos por dirección (de entrada y salida)
- Flujos por decisión (permitidos y denegados)
- Flujos por puerto de destino
También puede usar herramientas de código abierto para analizar los registros, como Elastic Stack, Grafana y Graylog.
Nota:
Los registros de flujos de grupos de seguridad de red no admiten cuentas de almacenamiento en la versión clásica de Azure Portal.
Registros de diagnóstico
En Network Watcher, los registros de diagnóstico son una ubicación central para habilitar y deshabilitar los registros de los recursos de red de Azure. Estos recursos pueden incluir grupos de seguridad de red, direcciones IP públicas, equilibradores de carga y puertas de enlace de aplicaciones. Después de habilitar los registros que le interesan, puede usar las herramientas para consultar y ver las entradas del registro.
Puede importar registros de diagnóstico en Power BI y otras herramientas para analizarlos.
Análisis de tráfico
Para investigar la actividad de usuarios y aplicaciones en las redes en la nube, use el análisis de tráfico.
La herramienta proporciona información detallada sobre la actividad de red entre suscripciones. Puede diagnosticar amenazas de seguridad, como puertos abiertos, máquinas virtuales que se comunican con redes peligrosas conocidas y patrones de flujo de tráfico. Análisis de tráfico analiza los registros de flujos de NSG entre las regiones y suscripciones de Azure. Puede usar los datos para optimizar el rendimiento de la red.
Para esta herramienta se necesita Log Analytics. El área de trabajo de Log Analytics debe existir en una región admitida.
Escenarios de casos de uso
A continuación, se examinarán algunos escenarios de casos de uso donde los registros y las métricas de Azure Network Watcher pueden ser útiles.
El cliente notifica un rendimiento lento
Para solucionar problemas de rendimiento lento, es necesario determinar la causa raíz del problema:
- ¿Hay demasiado tráfico que limita el servidor?
- ¿El tamaño de la máquina virtual es adecuado para el trabajo?
- ¿Los umbrales de escalabilidad se han establecido correctamente?
- ¿Hay algún ataque malintencionado?
- ¿La configuración de almacenamiento de la máquina virtual es correcta?
En primer lugar, compruebe que el tamaño de la máquina virtual es adecuado para el trabajo. Después, habilite Azure Diagnostics en la máquina virtual para obtener datos más detallados de métricas específicas, como el uso de la CPU y la memoria. Para habilitar el diagnóstico de la máquina virtual a través del portal, vaya a la Máquina virtual, elija Configuración de diagnóstico y active el diagnóstico.
Imagine que tiene una máquina virtual que se ha ejecutado de forma correcta. Pero últimamente su rendimiento ha empeorado. Para identificar si hay cuellos de botella de recursos, tendrá que revisar los datos capturados.
Empiece con un intervalo de tiempo de datos capturados antes, durante y después del problema notificado para obtener una vista precisa del rendimiento. Estos gráficos también pueden ser útiles para hacer referencias cruzadas de distintos comportamientos de recursos en el mismo período. Se comprobará lo siguiente:
- Cuellos de botella de CPU
- Cuellos de botella de memoria
- Cuellos de botella de disco
Cuellos de botella de CPU
Al analizar los problemas de rendimiento, puede examinar las tendencias para comprender si afectan al servidor. Para detectar las tendencias, use los gráficos de supervisión del portal. Es posible que vea distintos tipos de patrones en los gráficos de supervisión:
- Picos aislados. Un pico podría estar relacionado con una tarea programada o un evento esperado. Si sabe cuál es esta tarea, ¿se está ejecutando en el nivel de rendimiento necesario? Si el rendimiento es correcto, es posible que no tenga que aumentar la capacidad.
- Aumento y mantenimiento constante. Una nueva carga de trabajo podría producir esta tendencia. Habilite la supervisión en la máquina virtual para averiguar qué procesos causan la carga. El aumento de consumo podría deberse a un código ineficaz, o bien a un consumo normal de la nueva carga de trabajo. Si el consumo es normal, ¿el proceso funciona en el nivel de rendimiento necesario?
- Constante. ¿La máquina virtual siempre se ha comportado de esta forma? Si es así, debe identificar los procesos que más recursos consumen y considerar la posibilidad de agregar capacidad.
- Aumento constante. ¿Ve un aumento constante del consumo? Si es así, esta tendencia podría indicar un código ineficaz o un proceso que toma más carga de trabajo del usuario.
Si observa un uso elevado de CPU, puede:
- Aumentar el tamaño de la máquina virtual para escalarla con más núcleos.
- Investigue aún más la causa del problema. Busque la aplicación y el proceso y solucione los problemas según corresponda.
Si escala verticalmente la máquina virtual y la CPU todavía se ejecuta por encima del 95 %, ¿ofrece mejor rendimiento o mayor rendimiento de la aplicación a un nivel aceptable? Si no es así, solucione los problemas de esa aplicación concreta.
Cuellos de botella de memoria
Puede ver la cantidad de memoria que usa la máquina virtual. Los registros le ayudarán a entender la tendencia y si se corresponde con el momento en que se ven los problemas. No debe tener menos de 100 MB de memoria disponible en cualquier momento. Esté atento a las tendencias siguientes:
- Aumento y consumo constante. Es posible que un uso elevado de la memoria no sea la causa de un rendimiento incorrecto. Algunas aplicaciones, como los motores de bases de datos relacionales, hacen un uso intensivo de la memoria por diseño. Pero si hay varias aplicaciones que consumen mucha memoria, es posible que detecte un rendimiento incorrecto porque la contención de memoria provoca el recorte y la paginación en disco. Estos procesos tendrán un impacto negativo en el rendimiento.
- Aumento constante del consumo. Esta tendencia podría indicar la preparación de una aplicación. Es habitual cuando se inician los motores de base de datos. Pero también podría ser una señal de fuga de memoria en una aplicación.
- Uso de páginas o archivos de intercambio. Compruebe si usa el archivo de paginación de Windows de forma intensiva, o bien el archivo de intercambio de Linux, que se encuentra en /dev/sdb.
Para resolver este uso elevado de la memoria, tenga en cuenta estas soluciones:
- Para corregir de forma inmediata el uso de los archivos de paginación, aumente el tamaño de la máquina virtual para agregar memoria y después supervise.
- Investigue aún más la causa del problema. Busque la aplicación o el proceso que causa el cuello de botella y solucione los problemas. Si conoce la aplicación, compruebe si puede limitar la asignación de memoria.
Cuellos de botella de disco
El rendimiento de la red también puede estar relacionado con el subsistema de almacenamiento de la máquina virtual. Puede investigar la cuenta de almacenamiento para la máquina virtual en el portal. Para identificar problemas con el almacenamiento, examine las métricas de rendimiento del diagnóstico de la cuenta de almacenamiento y de la máquina virtual. Busque tendencias clave cuando se produzcan problemas dentro de un intervalo de tiempo específico.
- Para comprobar el tiempo de expiración de Azure Storage, use las métricas ClientTimeOutError, ServerTimeOutError, AverageE2ELatency, AverageServerLatency y TotalRequests. Si ve valores en las métricas TimeOutError, significa que una operación de E/S ha tardado demasiado y ha agotado el tiempo de expiración. Si ve un aumento de AverageServerLatency al mismo tiempo que TimeOutErrors, se podría tratar de un problema de la plataforma. Genere un caso con el servicio de soporte técnico de Microsoft.
- Para comprobar la limitación de Azure Storage, use la métrica ThrottlingError de la cuenta de almacenamiento. Si observa limitaciones, significa que se ha alcanzado el límite de IOPS de la cuenta. Puede comprobar este problema si investiga la métrica TotalRequests.
Para corregir problemas de latencia y uso elevado del disco:
- Optimice la E/S de la máquina virtual para que la escala supere los límites de disco duro virtual (VHD).
- Aumente el rendimiento y reduzca la latencia. Si observa que tiene una aplicación que depende de la latencia y necesita un rendimiento elevado, migre los discos duros virtuales a Azure Premium Storage.
Reglas de firewall de máquina virtual que bloquean el tráfico
Para solucionar un problema de flujos de NSG, use la herramienta Comprobación del flujo de IP de Network Watcher y Registro de flujos de NSG para determinar si hay un grupo de seguridad de red o una ruta definida por el usuario que interfieren con el flujo de tráfico.
Ejecute Comprobación del flujo de IP y especifique la máquina virtual local y la máquina virtual remota. Después de seleccionar Comprobar, Azure ejecuta una prueba lógica en las reglas activas. Si el resultado es que se permite el acceso, use Registros de flujos de NSG.
En el portal, vaya a los grupos de seguridad de red. En la configuración del registro de flujo, seleccione Activado. Ahora intente conectarse de nuevo a la máquina virtual. Use Análisis de tráfico de Network Watcher para visualizar los datos. Si el resultado es que se permite el acceso, no hay ninguna regla de grupo de seguridad de red que interfiera.
Si ha llegado a este punto y todavía no ha diagnosticado el problema, es posible que haya algún error en la máquina virtual remota. Deshabilite el firewall en la máquina virtual remota y vuelva a probar la conectividad. Si se puede conectar a la máquina virtual remota con el firewall deshabilitado, compruebe la configuración del firewall remoto. Después, vuelva a habilitar el firewall.
Imposibilidad de que las subredes de front-end y back-end se comuniquen
De forma predeterminada, todas las subredes se pueden comunicar en Azure. Si dos máquinas virtuales no se pueden comunicar en dos subredes, es porque hay una configuración que bloquea la comunicación. Antes de comprobar los registros de flujos, ejecute la herramienta de comprobación del flujo de IP desde la máquina virtual de front-end a la de back-end. Esta herramienta ejecuta una prueba lógica en las reglas de la red.
Si el resultado es que un grupo de seguridad de red de la subred de back-end bloquea toda la comunicación, vuelva a configurar ese grupo de seguridad de red. Por motivos de seguridad, debe bloquear alguna comunicación con el front-end porque el front-end está expuesto a la red pública de Internet.
Al bloquear la comunicación con el back-end, se limita la cantidad de exposición en caso de que se produzca un ataque de malware o de seguridad. Pero si el grupo de seguridad de red bloquea todo, no está configurado correctamente. Habilite los protocolos y puertos específicos necesarios.