Extraire davantage de données de Power BI
L’API fetchMoreData vous permet de charger des blocs de données de différentes tailles comme moyen de permettre aux visuels Power BI de contourner la limite inconditionnelle d’une vue de données de 30 000 lignes. En plus de l’approche initiale d’agrégation de tous les blocs demandés, l’API prend désormais également en charge le chargement incrémentiel de blocs de données.
Vous pouvez configurer le nombre de lignes à extraire à l’avance, ou vous pouvez utiliser dataReductionCustomization pour autoriser l’auteur du rapport à définir dynamiquement la taille du segment.
Notes
L’API fetchMoreData est disponible dans les versions 3.4 et ultérieures.
L’API dynamique dataReductionCustomization est disponible dans les versions 5.2 et ultérieures.
Pour savoir quelle version vous utilisez, consultez le apiVersion fichier pbiviz.json .
Activer une extraction segmentée de modèles sémantiques volumineux
Définissez une taille de fenêtre pour dataReductionAlgorithm dans le fichier capabilities.json du visuel pour le dataViewMapping exigé. La valeur count détermine la taille de la fenêtre, qui limite le nombre de nouvelles lignes de données que vous pouvez ajouter à l’élément dataview à chaque mise à jour.
Par exemple, ajoutez le code suivant dans le fichier capabilities.json pour ajouter 100 lignes de données à la fois :
"dataViewMappings": [
{
"table": {
"rows": {
"for": {
"in": "values"
},
"dataReductionAlgorithm": {
"window": {
"count": 100
}
}
}
}
]
Les nouveaux segments sont ajoutés à l’élément dataview existant et fournis au visuel sous la forme d’un appel update.
Utilisation de fetchMoreData dans le visuel Power BI
Dans Power BI, vous pouvez récupérer plus de données (fetchMoreData) de l’une des deux façons suivantes :
- mode d’agrégation de segments
- mode de mises à jour incrémentielles
Mode d’agrégation de segments (par défaut)
Avec le mode d’agrégation des segments, la vue de données fournie au visuel contient les données accumulées de toutes les précédentes fetchMoreData requests. Par conséquent, la taille de la vue de données augmente à chaque mise à jour en fonction de la taille de la fenêtre. Par exemple, si le nombre total de lignes attendues est de 100 000 et que la taille de fenêtre est définie sur 10 000, la vue de données de la première mise à jour doit inclure 10 000 lignes, la vue de données de la deuxième mise à jour doit inclure 20 000 lignes, et ainsi de suite.
Sélectionnez le mode d’agrégation des segments en appelant fetchMoreData avec aggregateSegments = true.
Vous pouvez déterminer s’il existe des données en vérifiant l’existence de dataView.metadata.segment :
public update(options: VisualUpdateOptions) {
const dataView = options.dataViews[0];
console.log(dataView.metadata.segment);
// output: __proto__: Object
}
Vous pouvez également vérifier si la mise à jour est la première ou une mise à jour suivante en vérifiant options.operationKind. Dans le code suivant, VisualDataChangeOperationKind.Create fait référence au premier segment et VisualDataChangeOperationKind.Append aux segments suivants.
// CV update implementation
public update(options: VisualUpdateOptions) {
// indicates this is the first segment of new data.
if (options.operationKind == VisualDataChangeOperationKind.Create) {
}
// on second or subsequent segments:
if (options.operationKind == VisualDataChangeOperationKind.Append) {
}
// complete update implementation
}
Vous pouvez aussi appeler la méthode fetchMoreData à partir d’un gestionnaire d’événements d’interface utilisateur :
btn_click(){
{
// check if more data is expected for the current data view
if (dataView.metadata.segment) {
// request for more data if available; as a response, Power BI will call update method
let request_accepted: bool = this.host.fetchMoreData(true);
// handle rejection
if (!request_accepted) {
// for example, when the 100 MB limit has been reached
}
}
}
En réponse à l’appel de la méthode this.host.fetchMoreData, Power BI appelle la méthode update du visuel avec un nouveau segment de données.
Notes
Pour éviter les contraintes de mémoire client, Power BI limite le total de données extraites à 100 Mo. Quand cette limite est atteinte, fetchMoreData() retourne false.
Mode de mises à jour incrémentielles
Avec le mode mises à jour incrémentielles, la vue de données fournie au visuel contient uniquement l’ensemble de données incrémentielles suivant. La taille de la vue de données est égale à la taille de fenêtre définie (ou plus petite, si le dernier bit de données est inférieur à la taille de la fenêtre). Par exemple, si le nombre total de lignes attendues et de 101 000 et que la taille de fenêtre est définie sur 10 000, le visuel obtiendra 10 mises à jour avec une taille de vue de données de 10 000 et une seule mise à jour avec une vue de données d’une taille de 1 000.
Le mode mises à jour incrémentielles est sélectionné en appelant fetchMoreData avec aggregateSegments = false.
Vous pouvez déterminer s’il existe des données en vérifiant l’existence de dataView.metadata.segment :
public update(options: VisualUpdateOptions) {
const dataView = options.dataViews[0];
console.log(dataView.metadata.segment);
// output: __proto__: Object
}
Vous pouvez également vérifier si la mise à jour est la première ou une mise à jour suivante en vérifiant options.operationKind. Dans le code suivant, VisualDataChangeOperationKind.Create fait référence au premier segment et VisualDataChangeOperationKind.Segment, aux segments suivants.
// CV update implementation
public update(options: VisualUpdateOptions) {
// indicates this is the first segment of new data.
if (options.operationKind == VisualDataChangeOperationKind.Create) {
}
// on second or subsequent segments:
if (options.operationKind == VisualDataChangeOperationKind.Segment) {
}
// skip overlapping rows
const rowOffset = (dataView.table['lastMergeIndex'] === undefined) ? 0 : dataView.table['lastMergeIndex'] + 1;
// Process incoming data
for (var i = rowOffset; i < dataView.table.rows.length; i++) {
var val = <number>(dataView.table.rows[i][0]); // Pick first column
}
// complete update implementation
}
Vous pouvez aussi appeler la méthode fetchMoreData à partir d’un gestionnaire d’événements d’interface utilisateur :
btn_click(){
{
// check if more data is expected for the current data view
if (dataView.metadata.segment) {
// request for more data if available; as a response, Power BI will call update method
let request_accepted: bool = this.host.fetchMoreData(false);
// handle rejection
if (!request_accepted) {
// for example, when the 100 MB limit has been reached
}
}
}
En réponse à l’appel de la méthode this.host.fetchMoreData, Power BI appelle la méthode update du visuel avec un nouveau segment de données.
Notes
Bien que les données des différentes mises à jour des vues de données soient essentiellement exclusives, un chevauchement pourra être constaté entre des vues de données consécutives.
Pour le mappage de données de table et de catégorie, les premières N lignes de vue de données peuvent contenir des données copiées à partir de la vue de données précédente.
(dataView.table['lastMergeIndex'] === undefined) ? 0 : dataView.table['lastMergeIndex'] + 1 peut être déterminé par N
Le visuel conserve la vue de données qui lui a été transmise afin qu’il puisse accéder aux données sans communications supplémentaires avec Power BI.
Réduction des données personnalisée
Étant donné que le développeur ne peut pas toujours savoir à l’avance le type de données que le visuel permettra d’afficher, il peut autoriser l’auteur du rapport à définir dynamiquement la taille du bloc de données. À partir de la version 5.2 de l’API, vous pouvez autoriser l’auteur du rapport à définir la taille des blocs de données extraits à chaque fois.
Pour permettre à l’auteur du rapport de définir le nombre, définissez d’abord un objet de volet de propriétés appelé dataReductionCustomization dans votre fichier capabilities.json :
"objects": {
"dataReductionCustomization": {
"displayName": "Data Reduction",
"properties": {
"rowCount": {
"type": {
"numeric": true
},
"displayName": "Row Reduction",
"description": "Show Reduction for all row groups",
"suppressFormatPainterCopy": true
},
"columnCount": {
"type": {
"numeric": true
},
"displayName": "Column Reduction",
"description": "Show Reduction for all column groups",
"suppressFormatPainterCopy": true
}
}
}
},
Ensuite, après dataViewMappings, définissez les valeurs par défaut pour dataReductionCustomization.
"dataReductionCustomization": {
"matrix": {
"rowCount": {
"propertyIdentifier": {
"objectName": "dataReductionCustomization",
"propertyName": "rowCount"
},
"defaultValue": "100"
},
"columnCount": {
"propertyIdentifier": {
"objectName": "dataReductionCustomization",
"propertyName": "columnCount"
},
"defaultValue": "10"
}
}
}
Les informations de réduction des données s’affichent sous visuel dans le volet Format.
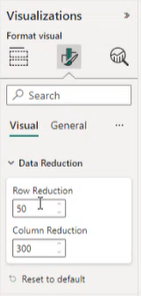
Considérations et limitations
La taille de la fenêtre est limitée à une plage comprise entre 2 et 30 000.
Le nombre total de lignes d’une vue de données est limité à 1 048 576 lignes.
En mode d’agrégation de segments, la taille de mémoire de la vue de données est limitée à 100 Mo.
Étapes suivantes
Commentaires
Bientôt disponible : pendant toute l’année 2024, nous allons éliminer progressivement Problèmes GitHub comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, voir : https://aka.ms/ContentUserFeedback.
Soumettre et afficher des commentaires pour