Découvrez le schéma en étoile et son importance pour Power BI
Cet article s’adresse aux modélisateurs de données Power BI Desktop. Il décrit la conception d’un schéma en étoile et sa pertinence pour le développement de modèles de données Power BI qui sont optimisés du point de vue des performances et de la convivialité.
Cet article n’a pas pour but d’aborder par le menu la conception de schémas en étoile. Pour plus d’informations, reportez-vous directement au contenu publié, comme The Data Warehouse Toolkit : The Definitive Guide to Dimensional Modeling (3e édition, 2013) par Ralph Kimball et d’autres.
Vue d’ensemble du schéma en étoile
Le schéma en étoile est une approche de modélisation mature largement adoptée par les entrepôts de données relationnels. Les modélisateurs doivent classer leurs tables de modèle en tant que table de dimension ou table de faits.
Les tables de dimension décrivent les entités d’entreprise : les choses que vous modélisez. Les entités peuvent inclure des produits, des personnes, des lieux et des concepts, y compris le temps lui-même. La table la plus cohérente que vous trouverez dans un schéma en étoile est une table de dimension de date. Une table de dimension contient une ou plusieurs colonnes clés qui jouent le rôle d’identificateur unique et de colonnes descriptives.
Les tables de faits stockent des observations ou des événements et peuvent être des commandes client, des soldes de stock, des taux de change, des températures, etc. Une table de faits contient des colonnes clés de dimension qui se rapportent aux tables de dimension et des colonnes de mesures numériques. Les colonnes clés de dimension déterminent la dimensionnalité d’une table de faits, tandis que les valeurs clés de dimension déterminent sa granularité. Par exemple, imaginez une table de faits conçue pour stocker des cibles de ventes qui a deux colonnes clés de dimension : Date et ProductKey. Il est facile de comprendre que la table a deux dimensions. Toutefois, vous ne pouvez pas déterminer la granularité sans tenir compte des valeurs clés de dimension. Dans cet exemple, supposez que les valeurs stockées dans la colonne Date sont le premier jour de chaque mois. Dans ce cas, la granularité se situe au niveau produit/mois.
En règle générale, les tables de dimension contiennent un nombre relativement petit de lignes. En revanche, les tables de faits peuvent contenir un très grand nombre de lignes et croître au fil du temps.

Normalisation et dénormalisation
Pour comprendre certains concepts du schéma en étoile décrits dans cet article, il est important de connaître ces deux termes : normalisation et dénormalisation.
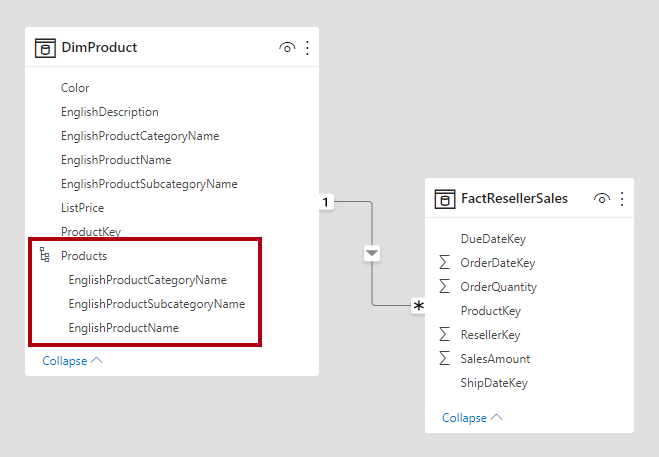
La normalisation est le terme utilisé pour décrire les données stockées de manière à réduire les données répétitives. Prenons l’exemple d’une table de produits qui a une colonne de valeur de clé unique, comme la clé de produit, et des colonnes supplémentaires qui décrivent les caractéristiques du produit, à savoir son nom, sa catégorie, sa couleur et sa taille. Une table de ventes est considérée normalisée quand elle stocke uniquement des clés, comme la clé de produit. Dans l’image suivante, remarquez que seule la colonne ProductKey enregistre le produit.
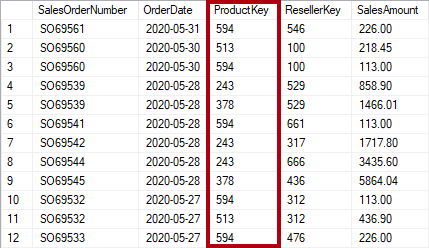
Toutefois, si la table de ventes stocke des détails sur les produits qui vont au-delà de la clé, elle est considérée comme étant dénormalisée. Dans l’image suivante, remarquez que la colonne ProductKey et d’autres colonnes relatives aux produits enregistrent le produit.

Quand vous sourcez des données à partir d’un fichier d’exportation ou d’une extraction de données, elles représentent probablement un jeu de données dénormalisé. Dans ce cas, utilisez Power Query pour transformer et mettre en forme les données sources en plusieurs tables normalisées.
Comme décrit dans cet article, vous devez vous efforcer de développer des modèles de données Power BI optimisés avec des tables qui représentent des données de fait et de dimension normalisées. Toutefois, il existe une exception où une dimension en flocon doit être dénormalisée pour produire une seule table de modèle.
Pertinence du schéma en étoile pour les modèles Power BI
La conception de schémas en étoile et de nombreux concepts associés présentés dans cet article sont très importants pour le développement de modèles Power BI qui sont optimisés du point de vue des performances et de la convivialité.
Tenez compte du fait que chaque visuel de rapport Power BI génère une requête envoyée au modèle Power BI (que le service Power BI appelle modèle sémantique–précédemment appelé jeu de données). Ces requêtes sont utilisées pour filtrer, regrouper et totaliser les données du modèle. Un modèle bien conçu fournit des tables pour le filtrage et le regroupement et des tables pour la totalisation. Cette conception répond bien aux principes des schémas en étoile :
- Les tables de dimension prennent en charge le filtrage et le regroupement.
- Les tables de faits prennent en charge la totalisation.
Aucune propriété de table n’est définie par les modeleurs pour configurer le type de table en tant que dimension ou que fait. En fait, c’est déterminé par les relations de modèle. Une relation de modèle établit un chemin de propagation de filtre entre deux tables, et c’est la propriété de cardinalité de la relation qui détermine le type de table. Une cardinalité de relation courante est un-à-plusieurs ou son opposé, plusieurs-à-un. Le côté « un » est toujours une table de type dimension, tandis que le côté « plusieurs » est toujours une table de type fait. Pour plus d’informations sur les relations, consultez Relations de modèle dans Power BI Desktop.
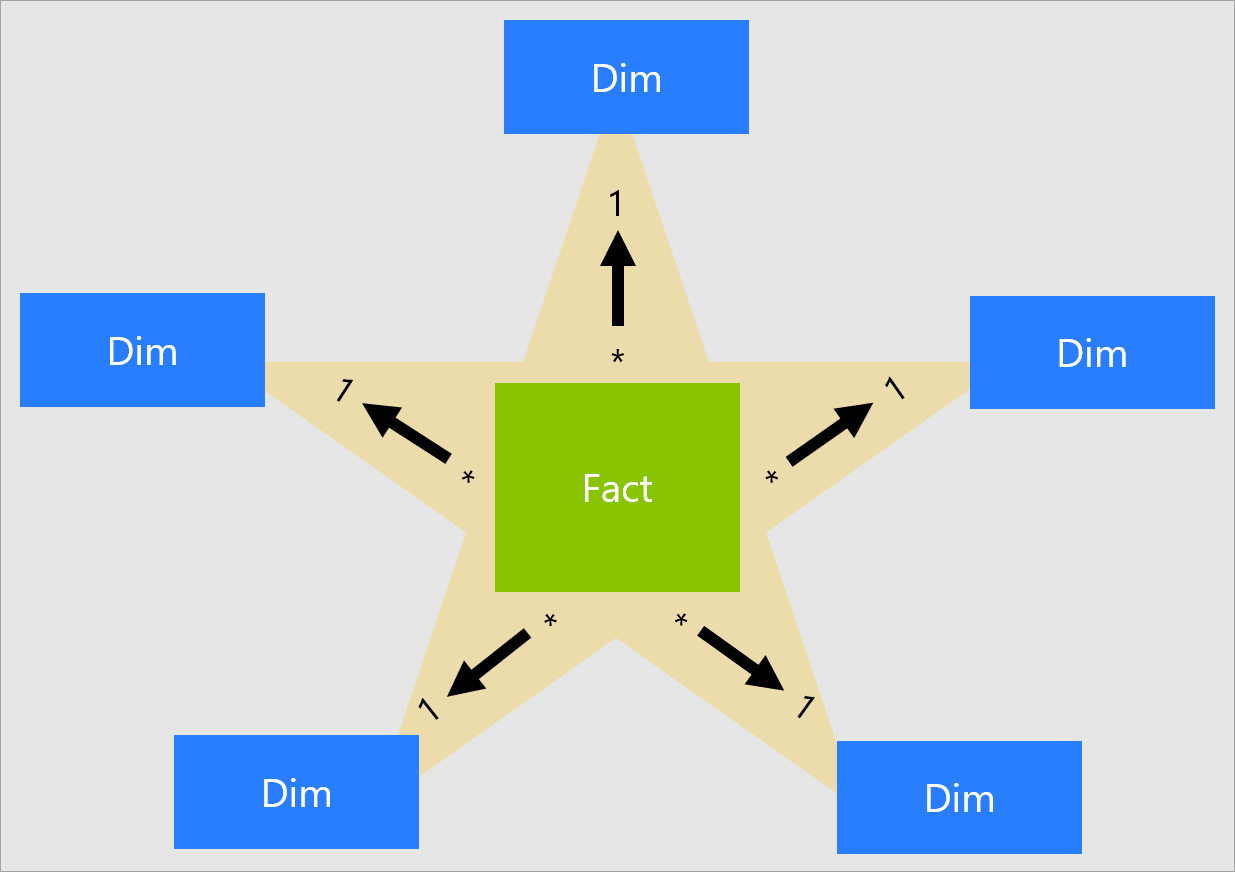
Une conception de modèle bien structurée doit inclure des tables de type dimension ou de type fait. Évitez de combiner les deux types pour une même table. Nous vous recommandons également de faire votre possible pour fournir le bon nombre de tables avec les bonnes relations en place. Il est également important que les tables de type fait chargent toujours les données avec une granularité cohérente.
Enfin, il est important de comprendre que la conception optimale du modèle relève pour partie de la science et pour partie de l’art. N’hésitez pas à vous écarter des recommandations habituelles si cela est judicieux.
De nombreux concepts supplémentaires liés à la conception de schémas en étoile peuvent être appliqués à un modèle Power BI. Ces concepts sont les suivants :
- Mesures
- Clés de substitution
- Dimensions en flocon
- Dimensions de rôle actif
- Dimension à variation lente
- Dimensions fourre-tout
- Dimensions de fait
- Tables de faits sans faits
Mesures
Dans la conception d’un schéma en étoile, une mesure est une colonne de table de faits qui stocke les valeurs à totaliser.
Dans un modèle Power BI, une mesure a une définition différente (mais similaire). Il s’agit d’une formule écrite en Dax (Data Analysis Expressions) qui réalise une totalisation. Les expressions de mesure exploitent souvent les fonctions d’agrégation DAX comme SUM, MIN, MAX ou AVERAGE pour produire un résultat de valeur scalaire au moment de la requête (les valeurs ne sont jamais stockées dans le modèle). Une expression de mesure peut aller de simples agrégations de colonnes à des formules plus sophistiquées qui remplacent la propagation de relation et/ou de contexte de filtre. Pour plus d’informations, consultez l’article Principes fondamentaux de DAX dans Power BI Desktop.
Il est important de comprendre que les modèles Power BI prennent en charge une deuxième méthode pour effectuer une totalisation. Toute colonne (généralement les colonnes numériques) peut être totalisée par un visuel de rapport ou Questions et réponses. Ces colonnes sont appelées mesures implicites. En tant que développeur de modèles, elles vous sont pratiques parce que, dans de nombreux cas, vous n’avez pas besoin de créer de mesures. Par exemple, la colonne Sales Amount de la table Reseller Sales d’Adventure Works peut être totalisée de nombreuses façons (somme, nombre, moyenne, valeur médiane, valeur minimale, valeur maximale, etc.), sans qu’il soit nécessaire de créer une mesure pour chaque type d’agrégation possible.
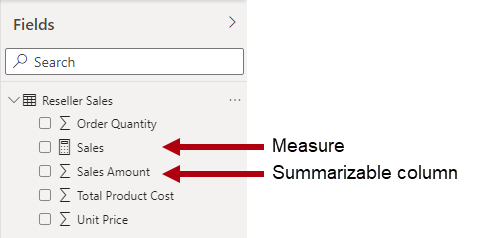
Toutefois, il existe trois raisons impérieuses de créer des mesures, même pour des totalisations simples au niveau des colonnes :
- Quand vous savez que vos auteurs de rapports sont susceptibles d’interroger le modèle en utilisant MDX (expressions multidimensionnelles), le modèle doit inclure des mesures explicites. Les mesures explicites sont définies en utilisant DAX. Cette approche de conception est très appropriée quand un jeu de données Power BI est interrogé avec MDX, car MDX ne peut pas totaliser les valeurs de colonne. MDX est notamment utilisé avec Analyser dans Excel, car PivotTables émet des requêtes MDX.
- Quand vous savez que vos auteurs de rapports sont susceptibles de créer des rapports paginés Power BI à l’aide du concepteur de requêtes MDX, le modèle doit inclure des mesures explicites. Seul le concepteur de requêtes MDX prend en charge les agrégats de serveur. Par conséquent, si les auteurs de rapports doivent faire évaluer les mesures par Power BI (et non par le moteur de rapport paginé), ils doivent utiliser le concepteur de requêtes MDX.
- Si vous devez vous assurer que vos auteurs de rapports peuvent uniquement totaliser des colonnes de manière spécifique. Par exemple, la colonne Unit Price de la table Reseller Sales (qui représente un tarif par unité) peut être totalisée, mais uniquement à l’aide de fonctions d’agrégation spécifiques. Elle ne doit jamais être cumulée, mais il est approprié de la totaliser à l’aide d’autres fonctions d’agrégation (valeur minimale, valeur minimale, moyenne, etc.). Dans ce cas, le modélisateur peut masquer la colonne Unit Price et créer des mesures pour toutes les fonctions d’agrégation appropriées.
Cette approche de conception fonctionne bien pour les rapports créés dans le service Power BI et pour Questions et réponses. Toutefois, les connexions actives Power BI Desktop permettent aux auteurs de rapports d’afficher les champs masqués dans le volet Champs, ce qui peut entraîner le contournement de cette approche de conception.
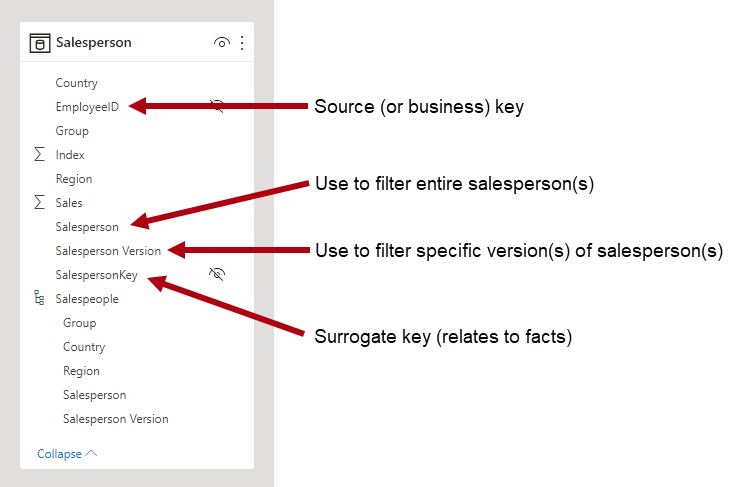
Clés de substitution
Une clé de substitution est un identificateur unique que vous ajoutez à une table pour prendre en charge la modélisation de schémas en étoile. Par définition, elle n’est ni définie ni stockée dans les données sources. En règle générale, les clés de substitution sont ajoutées aux tables de dimension des entrepôts de données relationnels afin de fournir un identificateur unique pour chaque ligne de la table de dimension.
Les relations des modèles Power BI sont basées sur une seule colonne unique dans une table, qui propage les filtres à une colonne unique dans une autre table. Quand une table de type dimension dans votre modèle n’inclut pas de colonne unique, vous devez ajouter un identificateur unique en guise de côté « un » d’une relation. Dans Power BI Desktop, vous pouvez facilement remplir cette exigence en créant une colonne d’index Power Query.

Vous devez fusionner cette requête avec la requête côté « plusieurs » afin de pouvoir y ajouter également la colonne d’index. Quand vous chargez ces requêtes dans le modèle, vous pouvez créer une relation un-à-plusieurs entre les tables du modèle.
Dimensions en flocon
Une dimension en flocon est un ensemble de tables normalisées pour une entité métier unique. Par exemple, Adventure Works classe les produits par catégorie et sous-catégorie. Les produits sont affectées à des sous-catégories, et les sous-catégories sont à leur tour affectés à des catégories. Dans l’entrepôt de données relationnel Adventure Works, la dimension des produits est normalisée et stockée dans trois tables associées : DimProductCategory, DimProductSubcategory et DimProduct.
En faisant appel à votre imagination, vous pouvez vous figurer les tables normalisées positionnées à l’extérieur de la table de faits, formant une conception en flocon.
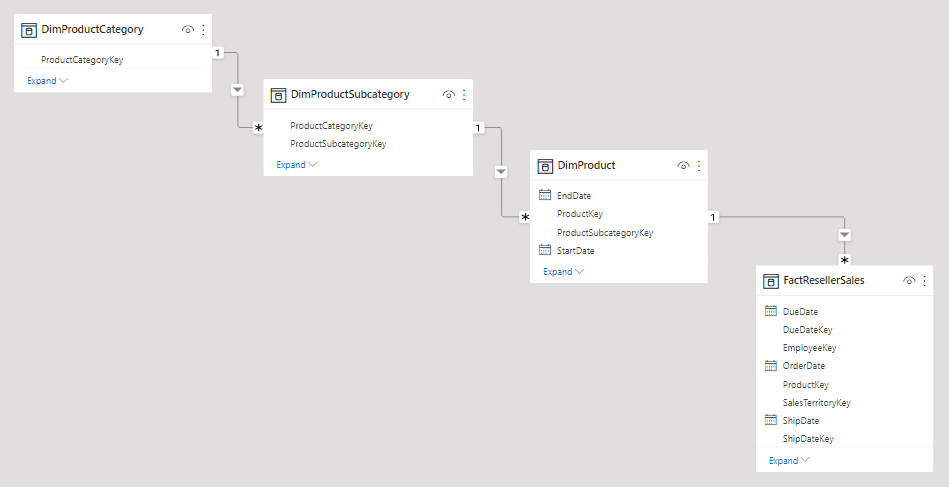
Dans Power BI Desktop, vous pouvez choisir de simuler une conception de dimension en flocon (peut-être parce que vos données sources le font) ou d’intégrer (dénormaliser) les tables sources en une table de modèle unique. En règle générale, une table de modèle unique présente plus d’avantages que plusieurs tables de modèle. La décision la plus optimale peut dépendre des volumes de données et des exigences de facilité d’utilisation du modèle.
Quand vous choisissez de simuler une conception de dimension en flocon :
- Power BI charge davantage de tables, ce qui est moins efficace du point de vue du stockage et des performances. Ces tables doivent inclure des colonnes pour prendre en charge les relations du modèle, ce qui peut agrandir la taille de ce dernier.
- Des chaînes de propagation de filtres de relation plus longues doivent être parcourues, ce qui est probablement moins efficace que l’application de filtres à une table unique.
- Le volet Champs présente davantage de tables de modèle aux auteurs de rapports, ce qui peut se traduire par une expérience moins intuitive, en particulier quand les tables de dimension en flocon contiennent seulement une ou deux colonnes.
- Il n’est pas possible de créer une hiérarchie qui englobe les tables.
Quand vous choisissez d’effectuer une intégration à une table de modèle unique, vous pouvez également définir une hiérarchie qui englobe les niveaux de granularité les plus bas et élevé de la dimension. Éventuellement, le stockage de données dénormalisées redondantes peut entraîner une augmentation de la taille de stockage du modèle, en particulier pour les tables de dimension très grandes.
Dimension à variation lente
Une dimension à variation lente (SCD) est une dimension qui gère correctement les modifications des membres de la dimension au fil du temps. Elle s’applique quand les valeurs des entités d’entreprise changent au fil du temps et de manière ad hoc. Un bon exemple de dimension à variation lente est une dimension de clients, en particulier ses colonnes de détails de contact telles que l’adresse e-mail et le numéro de téléphone. En revanche, certaines dimensions sont considérées comme évoluant rapidement quand un attribut de dimension change souvent, comme le prix du marché d’une action. L’approche de conception courante dans ces cas consiste à stocker les valeurs d’attribut à variation rapide dans une mesure de table de faits.
La théorie de la conception de schémas en étoile fait référence à deux types de SCD courants : type 1 et type 2. Une table de type dimension peut être de type 1 ou 2, ou prendre en charge les deux types simultanément pour des colonnes différentes.
SCD de type 1
Une SCD de Type 1 reflète toujours les valeurs les plus récentes ; ainsi, quand des modifications sont détectées dans les données sources, les données de la table de dimension sont remplacées. Cette approche de conception est courante pour les colonnes qui stockent des valeurs complémentaires, telles que l’adresse e-mail ou le numéro de téléphone d’un client. Quand l’adresse e-mail ou le numéro de téléphone d’un client change, la table de dimension met à jour la ligne du client avec les nouvelles valeurs. C’est comme si le client avait toujours eu ces informations de contact.
Une actualisation non incrémentielle d’une table de type dimension du modèle Power BI atteint le résultat d’une SCD de type 1. Elle actualise les données de la table afin que les valeurs les plus récentes soient chargées.
SCD de type 2
Une SCD de Type 2 prend en charge la gestion de version des membres de dimension. Si le système source ne stocke pas de versions, c’est généralement le processus de chargement de l’entrepôt de données qui détecte les modifications et gère de manière appropriée la modification dans une table de dimension. Dans ce cas, la table de dimension doit utiliser une clé de substitution pour fournir une référence unique à une version du membre de dimension. Elle comprend également des colonnes qui définissent la validité de la plage de dates de la version (par exemple, StartDate et EndDate) et éventuellement une colonne d’indicateur (par exemple, IsCurrent) pour filtrer facilement en fonction des membres de dimension actuels.
Par exemple, Adventure Works affecte des vendeurs à une région de ventes. Quand un vendeur change de région, une version du vendeur doit être créée pour que les faits historiques restent associés à l’ancienne région. Pour prendre en charge une analyse historique précise des ventes par vendeur, la table de dimension doit stocker les versions des vendeurs et leur(s) région(s) associée(s). La table doit également inclure des valeurs de date de début et de fin pour définir la durée de validité. Les versions actuelles peuvent définir une date de fin vide (ou 12/31/9999), qui indique que la version de la ligne est la version actuelle. La table doit également définir une clé de substitution, car la clé d’entreprise (en l’occurrence, l’ID d’employé) n’est pas unique.
Il est important de comprendre que quand les données sources ne stockent pas de versions, vous devez utiliser un système intermédiaire (comme un entrepôt de données) pour détecter et stocker les modifications. Le processus de chargement de table doit conserver les données existantes et détecter les modifications. Quand une modification est détectée, le processus de chargement de table doit faire expirer la version actuelle. Il enregistre ces modifications en mettant à jour la valeur EndDate et insère une nouvelle version dont la valeur StartDate commence par la valeur EndDate précédente. En outre, les faits connexes doivent utiliser une recherche basée sur le temps pour récupérer la valeur de clé de dimension correspondant à la date de fait. Un modèle Power BI utilisant Power Query ne peut pas produire ce résultat. Toutefois, il peut charger des données à partir d’une table de dimension SCD de type 2 préchargée.
Le modèle Power BI doit prendre en charge l’interrogation des données d’historique pour un membre, quelle que soit la modification, et pour une version du membre, qui représente un état particulier du membre dans le temps. Dans le contexte d’Adventure Works, cette conception vous permet d’interroger les données du vendeur, quelle que soit la région de vente affectée, ou pour une version particulière du vendeur.
Pour y parvenir, la table de type dimension du modèle Power BI doit inclure une colonne pour filtrer le vendeur et une autre colonne pour filtrer une version spécifique du vendeur. Il est important que la colonne de la version fournisse une description non ambiguë, telle que « Michael Blythe (12/15/2008-06/26/2019) » ou « Michael Blythe (Current) ». Il est également important de former les consommateurs et les auteurs de rapports aux principes de base de la dimension SCD de type 2 et de leur montrer comment obtenir des conceptions de rapport appropriées en appliquant des filtres corrects.
Une bonne pratique de conception consiste également à inclure une hiérarchie qui permet aux visuels d’accéder au niveau de version.

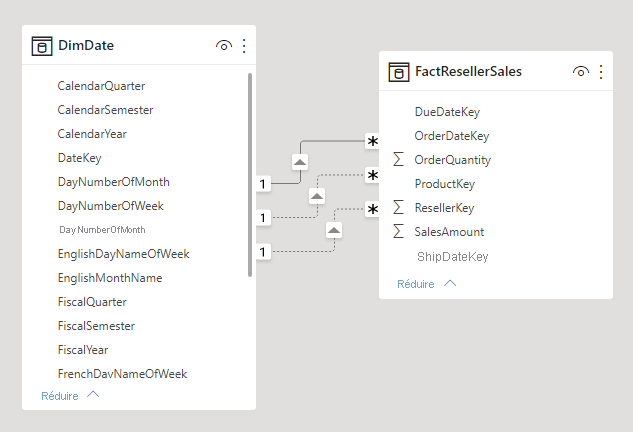
Dimensions de rôle actif
Une dimension de rôle actif est une dimension qui peut filtrer des faits liés différemment. Par exemple, dans Adventure Works, la table de dimension de date a trois relations avec les faits de ventes des revendeurs. La même table de dimension peut être utilisée pour filtrer les faits par date de commande, date d’expédition ou date de livraison.
Dans un entrepôt de données, l’approche de conception acceptée consiste à définir une table de dimension de date unique. Au moment de la requête, le « rôle » de la dimension de date est établi par la colonne de faits que vous utilisez pour joindre les tables. Par exemple, quand vous analysez les ventes par date de commande, la jointure de la table est associée à la colonne des dates de commandes client des revendeurs.
Dans un modèle Power BI, vous pouvez imiter cette conception en créant plusieurs relations entre deux tables. Dans l’exemple Adventure Works, les tables Date et Reseller Sales auraient trois relations. Même si cette conception est possible, il est important de comprendre qu’il ne peut y avoir qu’une seule relation active entre deux tables de modèle Power BI. Toutes les autres relations doivent être définies comme étant inactives. Le fait d’avoir une relation active unique signifie qu’il existe une propagation de filtre par défaut depuis les données de date vers les données des ventes des revendeurs. Dans ce cas, la relation active est définie sur le filtre le plus courant utilisé par les rapports, ce qui, dans Adventure Works, correspond à la relation de la date de commande.
La seule façon d’utiliser une relation inactive consiste à définir une expression Dax qui utilise la fonction USERELATIONSHIP. Dans notre exemple, le développeur de modèle doit créer des mesures pour permettre l’analyse des ventes des revendeurs par date d’expédition et date de livraison. Ce travail peut être fastidieux, en particulier quand la table des revendeurs définit de nombreuses mesures. En outre, elle encombre le volet Champs d’une surabondance de mesures. Il existe également d’autres limitations :
- Quand les auteurs de rapports s’appuient sur des colonnes de totalisation, au lieu de définir des mesures, ils ne peuvent pas obtenir de totalisation pour les relations inactives sans écrire de mesure au niveau du rapport. Les mesures au niveau du rapport peuvent être définies uniquement lors de la création de rapports dans Power BI Desktop.
- Avec un seul chemin de relation actif entre les données des ventes des revendeurs et les données des dates, il n’est pas possible de filtrer simultanément les ventes des revendeurs par différents types de dates. Par exemple, vous ne pouvez pas produire un visuel qui trace les ventes par date de commande par ventes livrées.
Pour surmonter ces limitations, une technique de modélisation Power BI courante consiste à créer une table de type dimension pour chaque instance de rôle actif. Les tables de dimension supplémentaires sont généralement créées sous forme de tables calculées à l’aide de DAX. À l’aide de tables calculées, le modèle peut contenir une table Date, une table Ship Date et une table Delivery Date, chacune avec une relation unique et active avec les colonnes respectives de la table Reseller Sales.

Cette approche de conception ne nécessite pas que vous définissiez plusieurs mesures pour différents rôles de date et autorise un filtrage simultané par différents rôles de date. Toutefois, cette approche de conception présente un inconvénient mineur : la table de dimension de date subit une duplication, qui se traduit par une augmentation de la taille de stockage du modèle. Comme les tables de type dimension stockent généralement moins de lignes que les tables de type fait, c’est rarement un problème.
Observez les bonnes pratiques de conception suivantes quand vous créez des tables de type dimension de modèle pour chaque rôle :
- Assurez-vous que les noms de colonne sont explicites. Bien qu’il soit possible d’avoir une colonne Year dans toutes les tables de dates (les noms de colonnes sont uniques dans la table concernée), ce n’est pas explicite à l’échelle des titres de visuels par défaut. Envisagez de renommer les colonnes dans chaque table de rôle de dimension, afin que la table Ship Date ait une colonne d’années nommée Ship Year, et ainsi de suite.
- Le cas échéant, vérifiez que les descriptions de table fournissent des commentaires aux auteurs de rapports (par le biais des info-bulles du volet Champs) sur la façon dont la propagation de filtre est configurée. Cette clarté est importante quand le modèle contient une table nommée de façon générique, comme Date, qui est utilisée pour filtrer de nombreuses tables de type fait. Dans le cas où cette table a, par exemple, une relation active avec la colonne des dates de commandes client des revendeurs, envisagez de fournir une description de table telle que « Filtre les ventes des revendeurs par date de commande ».
Pour plus d’informations, consultez Guide des relations actives et inactives.
Dimensions fourre-tout
Une dimension fourre-tout est utile quand il existe de nombreuses dimensions, en particulier composées de quelques attributs (peut-être un seul) ayant peu de valeurs. Les colonnes d’état des commandes ou les colonnes de données démographiques sur les clients (sexe, tranche d’âge, etc.) sont de bons candidats.
L’objectif de conception d’une dimension fourre-tout consiste à consolider de nombreuses « petites » dimensions en une seule dimension afin de réduire la taille de stockage du modèle et l’encombrement du volet Champs en présentant moins de tables de modèle.
Une table de dimension fourre-tout est généralement le produit cartésien de tous les membres d’attribut de dimension, avec une colonne de clé de substitution. La clé de substitution fournit une référence unique à chaque ligne de la table. Vous pouvez générer la dimension dans un entrepôt de données, ou en utilisant Power Query pour créer une requête qui effectue des jointures de requêtes externes entières, puis ajoute une clé de substitution (colonne d’index).
Vous chargez cette requête dans le modèle en tant que table de type dimension. Vous devez également fusionner cette requête avec la requête de faits, afin que la colonne d’index soit chargée dans le modèle pour prendre en charge la création d’une relation de modèle « un-à-plusieurs ».
Dimensions de fait
Une dimension de fait désigne un attribut de la table de faits requis pour le filtrage. Dans Adventure Works, le numéro de commande client des revendeurs est un bon exemple. Dans ce cas, cela n’a pas de sens pour la conception du modèle de créer une table indépendante composée uniquement de cette colonne, car il en résulterait une augmentation de la taille de stockage du modèle et un encombrement du volet Champs.
Dans le modèle Power BI, il peut être approprié d’ajouter la colonne des numéros de commande client à la table de type fait pour autoriser le filtrage ou le regroupement par numéro de commande client. Il s’agit d’une exception à la règle introduite précédemment, selon laquelle vous ne devez pas combiner des types de tables (en général, les tables de modèle doivent être de type dimension ou fait).
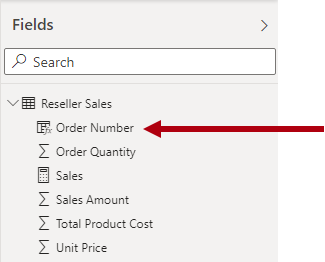
Toutefois, si la table des ventes des revendeurs Adventure Works contient des colonnes de numéro de commande et de numéro de ligne de commande qui sont requises pour le filtrage, une table de dimension de fait constitue un bon choix. Pour plus d’informations, consultez l’Aide sur les relations un-à-un (dégénérer les dimensions).
Tables de faits sans faits
Une table de faits sans faits n’inclut aucune colonne de mesure. Elle contient uniquement des clés de dimension.
Une table de faits sans faits peut stocker les observations définies par les clés de dimension. Par exemple, à une date et une heure particulières, un client particulier s’est connecté à votre site web. Vous pouvez définir une mesure pour compter les lignes de la table de faits sans faits afin d’analyser à quel moment les clients se sont connectés et leur nombre.
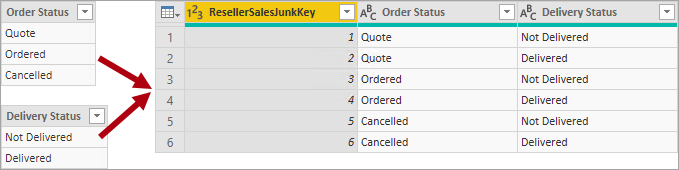
Une utilisation plus attrayante d’une table de faits sans faits consiste à stocker les relations entre les dimensions, approche de conception de modèle Power BI que nous vous recommandons pour définir les relations plusieurs-à-plusieurs. Dans une conception de relation de dimension plusieurs-à-plusieurs, la table de faits sans faits est appelée table de pontage.
Par exemple, considérez que les vendeurs peuvent être attribués à une ou plusieurs régions de vente. La table de pontage est conçue comme une table de faits sans faits composée de deux colonnes : clé de vendeur et clé de région. Les valeurs dupliquées peuvent être stockées dans les deux colonnes.
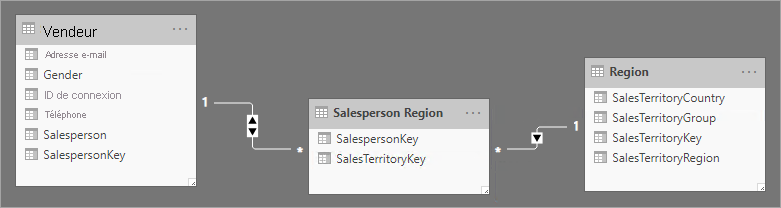
Cette approche de conception plusieurs-à-plusieurs est bien documentée et peut être obtenue sans table de pontage. Toutefois, l’approche de table de pontage est considérée comme la meilleure pratique lors de la liaison de deux dimensions. Pour plus d’informations, consultez l’aide sur les relations plusieurs-à-plusieurs (associer deux tables de type dimension).
Contenu connexe
Pour plus d’informations sur la conception du schéma en étoile ou sur la conception de modèles Power BI, consultez les articles suivants :
- Article Wikipedia sur la modélisation dimensionnelle
- Créer et gérer des relations dans Power BI Desktop
- Aide pour la relation un-à-un
- Conseils sur les relations Plusieurs-à-plusieurs
- Aide pour les relations bidirectionnelles
- Aide pour les relations actives et inactives
- Vous avez des questions ? Essayez d’interroger la communauté Power BI
- Vous avez des suggestions ? Envoyez-nous vos idées pour améliorer Power BI
Commentaires
Bientôt disponible : pendant toute l’année 2024, nous allons éliminer progressivement Problèmes GitHub comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, voir : https://aka.ms/ContentUserFeedback.
Soumettre et afficher des commentaires pour