Cette architecture de référence présente un pipeline de traitement de flux de bout en bout. Le pipeline ingère les données provenant des deux sources, met en corrélation les enregistrements dans les deux flux, puis calcule une moyenne mobile dans une fenêtre de temps. Les résultats sont stockés en vue d’une analyse plus approfondie.
 Une implémentation de référence de cette architecture est disponible sur GitHub.
Une implémentation de référence de cette architecture est disponible sur GitHub.
Architecture

Téléchargez un fichier Visio de cette architecture.
Workflow
L’architecture est constituée des composants suivants :
Sources de données. Dans cette architecture, deux sources de données génèrent des flux de données en temps réel. Le premier flux de données contient des informations sur les courses, tandis que le second contient des informations sur les tarifs. L’architecture de référence comprend un générateur de données simulées qui lit le contenu d’un ensemble de fichiers statiques et envoie (push) les données vers Event Hubs. Dans une application réelle, les sources de données seraient des périphériques installés dans les taxis.
Azure Event Hubs. Event Hubs est un service d’ingestion d’événements. Cette architecture utilise deux instances d’Event Hub, à savoir une par source de données. Chaque source de données envoie un flux de données à l’Event Hub associé.
Azure Stream Analytics. Stream Analytics est un moteur de traitement des événements. Un travail Stream Analytics lit les flux de données provenant des deux instances d’Event Hub et effectue le traitement des flux de données.
Azure Cosmos DB. La sortie du travail Stream Analytics est une série d’enregistrements écrits sous forme de documents JSON dans une base de données de documents Azure Cosmos DB.
Microsoft Power BI. Power BI est une suite d’outils d’analyse métier pour analyser les données et obtenir des informations métier. Dans cette architecture, elle charge les données à partir d’Azure Cosmos DB. Les utilisateurs sont ainsi en mesure d’analyser l’ensemble complet des données historiques qui ont été collectées. Vous pouvez également transmettre en continu les résultats directement de Stream Analytics à Power BI pour disposer d’une vue en temps réel des données. Pour plus d’informations, voir Streaming en temps réel dans Power BI.
Azure Monitor. Azure Monitor collecte les mesures de performances sur les services Azure déployés dans la solution. En les visualisant dans un tableau de bord, vous pouvez obtenir des informations sur l’intégrité de la solution.
Détails du scénario
Scénario : Une compagnie de taxis collecte des données sur chaque trajet effectué en taxi. Pour ce scénario, nous partons du principe que deux périphériques distincts envoient des données. Le taxi est équipé d’un compteur qui envoie les informations suivantes sur chaque course : durée, distance et lieux de prise en charge et de dépose. Un autre périphérique accepte les paiements des clients et envoie des données sur les tarifs. La compagnie de taxis souhaite calculer le pourboire moyen par mile (1,6 km) parcouru, en temps réel, afin de déterminer les tendances.
Cas d’usage potentiels
Cette solution est optimisée pour le scénario de vente au détail.
Ingestion de données
Pour simuler une source de données, cette architecture de référence utilise les données des taxis de la ville de New York[1]. Ce jeu de données contient des données sur les courses de taxis à New York sur une période de quatre ans (2010 à 2013). Il contient deux types d'enregistrements : les données relatives aux courses et les données relatives aux tarifs. Les premières incluent la durée du trajet, la distance et les lieux de prise en charge et de dépose. Les secondes incluent le montant des tarifs des courses, des taxes et des pourboires. Les champs communs aux deux types d’enregistrement sont le numéro de médaillon (« taxi jaune »), le permis spécial et l’ID fournisseur. Ensemble ces trois champs identifient un taxi ainsi qu’un chauffeur. Les données sont stockées au format CSV.
[1] Donovan, Brian; Work, Dan (2016) : Données de trajet des taxis de New York (2010-2013). Université de l’Illinois, Urbana-Champaign. https://doi.org/10.13012/J8PN93H8
Le générateur de données est une application .NET Core qui lit les enregistrements et les envoie à Azure Event Hubs. Le générateur envoie les données des courses au format JSON et les données relatives aux tarifs au format CSV.
Le service Event Hubs utilise des partitions pour segmenter les données. Ce système de partition permet à un consommateur de lire chaque partition en parallèle. Lorsque vous envoyez des données à Event Hubs, vous pouvez spécifier explicitement la clé de partition. Sinon, les enregistrements sont affectés aux partitions de manière alternée.
Dans ce scénario particulier, les données relatives aux courses et aux tarifs doivent se retrouver avec le même ID de partition pour un taxi donné. Cela permet à Stream Analytics d’appliquer un degré de parallélisme lorsqu’il met en corrélation les deux flux de données. Un enregistrement dans la partition n des données des courses correspond à un enregistrement de la partition n des données relatives aux tarifs.

Dans le générateur de données, le modèle de données commun pour les deux types d’enregistrement comprend une propriété PartitionKey, qui est la concaténation de Medallion, HackLicense et VendorId.
public abstract class TaxiData
{
public TaxiData()
{
}
[JsonProperty]
public long Medallion { get; set; }
[JsonProperty]
public long HackLicense { get; set; }
[JsonProperty]
public string VendorId { get; set; }
[JsonProperty]
public DateTimeOffset PickupTime { get; set; }
[JsonIgnore]
public string PartitionKey
{
get => $"{Medallion}_{HackLicense}_{VendorId}";
}
Cette propriété est utilisée pour fournir une clé de partition explicite lors de l’envoi des données vers Event Hubs :
using (var client = pool.GetObject())
{
return client.Value.SendAsync(new EventData(Encoding.UTF8.GetBytes(
t.GetData(dataFormat))), t.PartitionKey);
}
Traitement des flux de données
Le travail de traitement des flux de données est défini à l’aide d’une requête SQL comprenant plusieurs étapes distinctes. Les deux premières étapes sélectionnent simplement les enregistrements dans les deux flux d’entrée.
WITH
Step1 AS (
SELECT PartitionId,
TRY_CAST(Medallion AS nvarchar(max)) AS Medallion,
TRY_CAST(HackLicense AS nvarchar(max)) AS HackLicense,
VendorId,
TRY_CAST(PickupTime AS datetime) AS PickupTime,
TripDistanceInMiles
FROM [TaxiRide] PARTITION BY PartitionId
),
Step2 AS (
SELECT PartitionId,
medallion AS Medallion,
hack_license AS HackLicense,
vendor_id AS VendorId,
TRY_CAST(pickup_datetime AS datetime) AS PickupTime,
tip_amount AS TipAmount
FROM [TaxiFare] PARTITION BY PartitionId
),
L’étape suivante joint les deux flux d’entrée pour sélectionner des enregistrements correspondants dans chaque flux.
Step3 AS (
SELECT tr.TripDistanceInMiles,
tf.TipAmount
FROM [Step1] tr
PARTITION BY PartitionId
JOIN [Step2] tf PARTITION BY PartitionId
ON tr.PartitionId = tf.PartitionId
AND tr.PickupTime = tf.PickupTime
AND DATEDIFF(minute, tr, tf) BETWEEN 0 AND 15
)
Cette requête joint des enregistrements dans un ensemble de champs qui identifient de manière unique les enregistrements correspondants (PartitionId et PickupTime).
Notes
Nous voulons que les flux TaxiRide et TaxiFare soient joints par la combinaison unique de Medallion, HackLicense, VendorId et PickupTime. Dans ce cas, le paramètre PartitionId couvre les champs Medallion, HackLicense et VendorId mais vous ne devez pas considérer que c’est toujours le cas.
Dans Stream Analytics, les jointures sont temporelles, ce qui signifie que les enregistrements sont joints au sein d’une fenêtre de temps donnée. Dans le cas contraire, le travail devrait peut-être attendre indéfiniment une correspondance. La fonction DATEDIFF spécifie la durée pouvant séparer deux enregistrements correspondants.
La dernière étape du travail calcule le pourboire moyen par mile, groupé par fenêtre récurrente de 5 minutes.
SELECT System.Timestamp AS WindowTime,
SUM(tr.TipAmount) / SUM(tr.TripDistanceInMiles) AS AverageTipPerMile
INTO [TaxiDrain]
FROM [Step3] tr
GROUP BY HoppingWindow(Duration(minute, 5), Hop(minute, 1))
Stream Analytics fournit plusieurs fonctions de fenêtrage. Une fenêtre récurrente avance dans le temps en fonction d’une période fixe, dans ce cas 1 minute par saut. Le résultat revient à calculer une moyenne mobile sur les 5 dernières minutes.
Dans l’architecture illustrée ici, seuls les résultats du travail Stream Analytics sont enregistrés dans Azure Cosmos DB. Pour un scénario de type Big Data, pensez également à utiliser Event Hubs Capture pour enregistrer les données d’événement brutes dans le stockage Blob Azure. En conservant les données brutes, vous pourrez exécuter des requêtes par lot sur vos données historiques ultérieurement afin de dériver les nouvelles informations à partir des données.
Considérations
Ces considérations implémentent les piliers d’Azure Well-Architected Framework qui est un ensemble de principes directeurs qui permettent d’améliorer la qualité d’une charge de travail. Pour plus d’informations, consultez Microsoft Azure Well-Architected Framework.
Extensibilité
Event Hubs
La capacité de débit du service Event Hubs est mesurée par les unités de débit. Vous pouvez mettre automatiquement à l’échelle un Event Hub en activant l’augmentation automatique, qui ajuste automatiquement les unités de débit en fonction du trafic, jusqu’à la limite configurée.
Stream Analytics
Pour Stream Analytics, les ressources de calcul allouées à un travail sont mesurées en unités de streaming. La mise à l’échelle des travaux Stream Analytics est améliorée si ceux-ci peuvent être parallélisés. De cette façon, Stream Analytics peut distribuer le travail entre plusieurs nœuds de calcul.
Pour l’entrée du service Event Hubs, utilisez le mot clé PARTITION BY pour partitionner le travail Stream Analytics. Les données sont divisées en sous-ensembles basés sur les partitions du service Event Hubs.
Les fonctions de fenêtrage et les jointures temporelles requièrent des unités de streaming supplémentaires. Si possible, utilisez PARTITION BY afin que chaque partition soit traitée séparément. Pour plus d’informations, voir Comprendre et ajuster les unités de streaming.
S’il n’est pas possible de paralléliser l’intégralité du travail Stream Analytics, essayez de le fractionner en plusieurs étapes, en commençant par une ou plusieurs étapes parallèles. De cette façon, les premières étapes peuvent s’exécuter en parallèle. Par exemple, dans cette architecture de référence :
- Les étapes 1 et 2 sont des instructions
SELECTsimples qui sélectionnent des enregistrements dans une seule et même partition. - L’étape 3 effectue une jointure partitionnée entre deux flux d’entrée. Cette étape tire parti du fait que les enregistrements correspondants partagent la même clé de partition et qu’ils sont donc assurés de disposer du même ID de partition dans chaque flux d’entrée.
- L’étape 4 est agrégée dans toutes les partitions. Elle ne peut pas être parallélisée.
Consultez le diagramme de travail Stream Analytics pour voir le nombre de partitions affectées à chaque étape du travail. Le diagramme de travail suivant illustre cette architecture de référence :
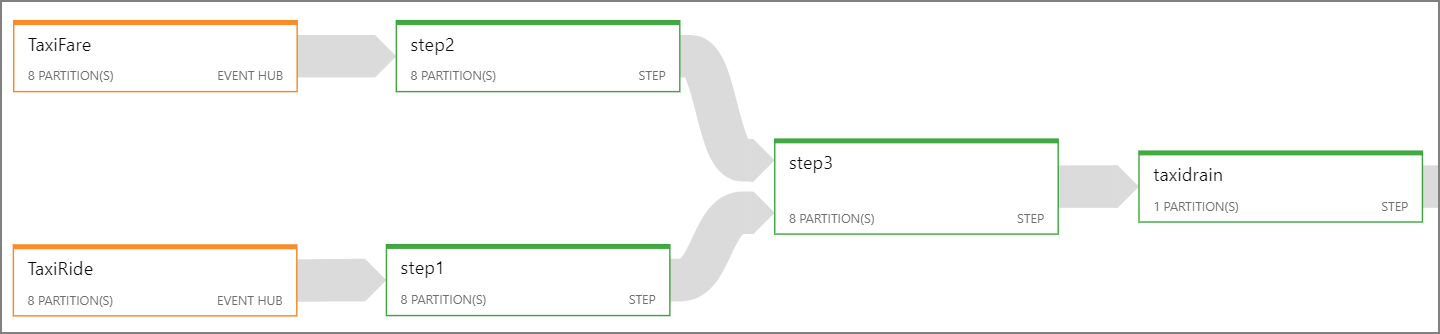
Azure Cosmos DB
La capacité de débit pour Azure Cosmos DB est mesurée en unités de requête (RU). Pour mettre à l’échelle un conteneur Azure Cosmos DB au-delà de 10 000 RU, vous devez spécifier une clé de partition lorsque vous créez le conteneur, puis inclure la clé de partition dans chaque document.
Dans cette architecture de référence, les nouveaux documents sont créés une seule fois par minute (intervalle de fenêtre récurrente). Les besoins en débit sont donc assez faibles. C’est pour cette raison qu’il est inutile d’affecter une clé de partition dans ce scénario.
Surveillance
Avec des solutions de traitement des flux de données, il est important de surveiller les performances et l’intégrité du système. Azure Monitor collecte des journaux d’activité de métriques et de diagnostics pour les services Azure utilisés dans l’architecture. Azure Monitor est intégré à la plateforme Azure et ne nécessite pas de code supplémentaire dans votre application.
Signaux d’avertissement indiquant que vous devez effectuer un scale-out de la ressource Azure appropriée :
- Le service Event Hubs limite les requêtes ou est proche du quota quotidien des messages.
- Le travail Stream Analytics utilise toujours plus de 80 % des unités de streaming allouées.
- Azure Cosmos DB commence à limiter les requêtes.
L’architecture de référence inclut un tableau de bord personnalisé, qui est déployé sur le portail Azure. Après avoir déployé l'architecture, vous pouvez afficher le tableau de bord en ouvrant le portail Azure et en sélectionnant TaxiRidesDashboard dans la liste des tableaux de bord. Pour plus d’informations sur la création et le déploiement de tableaux de bord personnalisés dans le portail Azure, voir Créer par programmation des tableaux de bord Azure.
L’illustration suivante présente le tableau de bord une fois que le travail Stream Analytics a été exécuté pendant environ une heure.
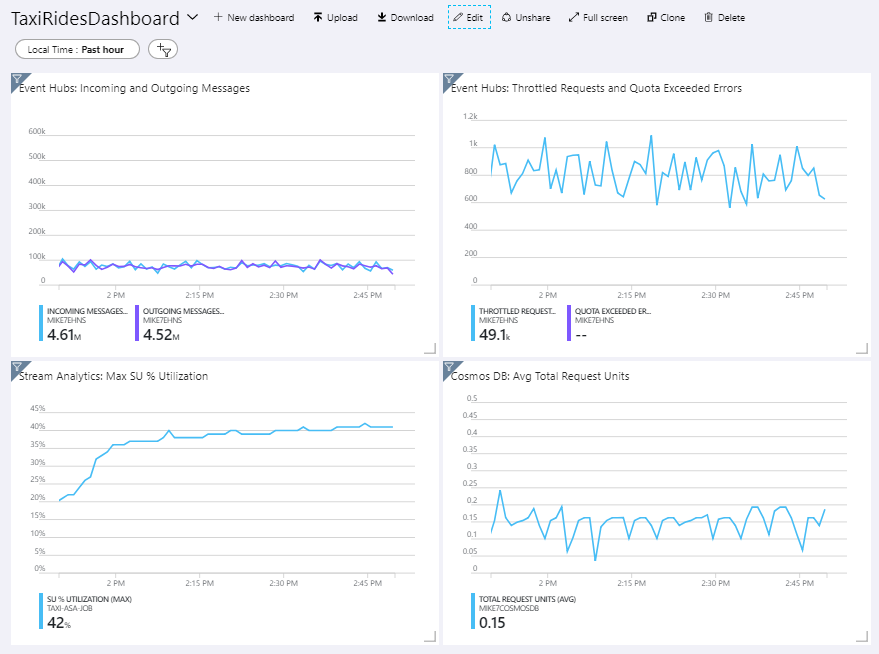
Le panneau affiché dans l’angle inférieur gauche indique que la consommation d’unités de streaming pour le travail Stream Analytics augmente pendant les 15 premières minutes, puis se stabilise. Il s’agit d’un modèle standard, car le travail atteint un état stable.
Notez que le service Event Hubs limite les requêtes (illustré dans le panneau supérieur droit). Une demande limitée occasionnelle n’est pas un problème, car le Kit de développement logiciel (SDK) client du service Event Hubs exécute une nouvelle tentative à la réception d’une erreur de limitation. Toutefois, si vous observez régulièrement des erreurs de limitation, cela signifie que l’Event Hub a besoin de davantage d’unités de débit. Le graphique suivant montre une série de tests utilisant la fonction d’augmentation automatique d’Event Hubs, qui ajuste automatiquement les unités de débit en fonction des besoins.
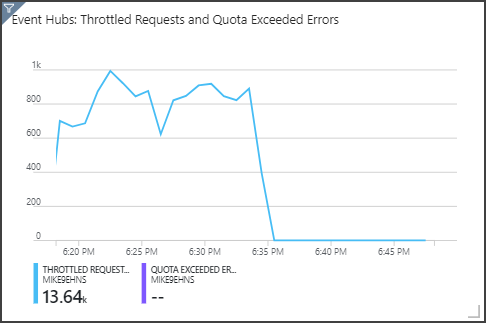
La fonction d’augmentation automatique a été activée au niveau de la marque de 06:35. Vous pouvez observer la chute p du nombre de requêtes limitées, car le service Event Hubs est automatiquement mis à l’échelle jusqu’à 3 unités de débit.
L’effet secondaire de ce processus est l’augmentation de l’utilisation des unités de streaming dans le travail Stream Analytics. Via la limitation des requêtes, le service Event Hubs réduit artificiellement le taux d’ingestion des données pour le travail Stream Analytics. Il est assez courant que la résolution d’un problème de goulot d’étranglement de performances en révèle un autre. Dans ce cas, l’allocation d’unités de streaming supplémentaires pour le travail Stream Analytics a résolu le problème.
Optimisation des coûts
L’optimisation des coûts consiste à examiner les moyens de réduire les dépenses inutiles et d’améliorer l’efficacité opérationnelle. Pour plus d’informations, consultez Vue d’ensemble du pilier d’optimisation des coûts.
Utiliser la calculatrice de prix Azure pour estimer les coûts. Les considérations suivantes s'appliquent aux services utilisés dans cette architecture de référence.
Azure Stream Analytics
Azure Stream Analytics est facturé en fonction du nombre d'unités de streaming (0,11 $/heure) requises pour traiter les données au sein du service.
Stream Analytics peut être coûteux si vous ne traitez pas les données en temps réel ou par petites quantités. Pour ces cas d'usage, envisagez d'utiliser Azure Functions ou Logic Apps afin de déplacer les données d'Azure Event Hubs vers un magasin de données.
Azure Event Hubs et Azure Cosmos DB
Pour en savoir plus sur les coûts d'Azure Event Hubs et Azure Cosmos DB, consultez l'architecture de référence Traitement de flux de données avec Azure Databricks.
DevOps
Créez des groupes de ressources distincts pour les environnements de production, de développement et de test. Des groupes de ressources distincts simplifient la gestion des déploiements, la suppression des déploiements de tests et l’attribution des droits d’accès.
Utilisez le modèle Azure Resource Manager pour déployer les ressources Azure en suivant le processus IaC (Infrastructure as Code). Grâce aux modèles, il est plus facile d'automatiser les déploiements à l'aide d'Azure DevOps Services, ou d'autres solutions de CI/CD.
Placez chaque charge de travail dans un modèle de déploiement distinct et stockez les ressources dans des systèmes de contrôle de code source. Vous pouvez déployer les modèles ensemble ou individuellement dans le cadre d'un processus CI/CD pour faciliter le processus d'automatisation.
Dans cette architecture, Azure Event Hubs, Log Analytics et Azure Cosmos DB sont identifiés comme une charge de travail unique. Ces ressources sont incluses dans un même modèle ARM.
Envisagez d'échelonner vos charges de travail. Déployez à différentes étapes et effectuez des vérifications de la validation à chaque étape avant de passer à l'étape suivante. Vous pourrez ainsi envoyer (push) les mises à jour de vos environnements de production de manière hautement contrôlée et limiter les problèmes de déploiement imprévus.
Envisagez d'utiliser Azure Monitor pour analyser les performances de votre pipeline de traitement de flux. Pour plus d'informations, consultez Supervision d'Azure Databricks.
Pour plus d’informations, consultez le pilier de l’excellence opérationnelle de Microsoft Azure Well-Architected Framework.
Déployer ce scénario
Pour déployer et exécuter l’implémentation de référence, suivez les étapes du fichier Readme de GitHub.
Ressources associées
Vous pouvez consulter les exemples de scénarios Azure suivants, qui décrivent des solutions spécifiques utilisant certaines de ces technologies :