Cette architecture de référence présente un ensemble de pratiques éprouvées pour l’exécution d’une application multiniveau dans plusieurs régions Azure, afin de bénéficier d’une haute disponibilité et d’une infrastructure de récupération d’urgence fiable.
Architecture
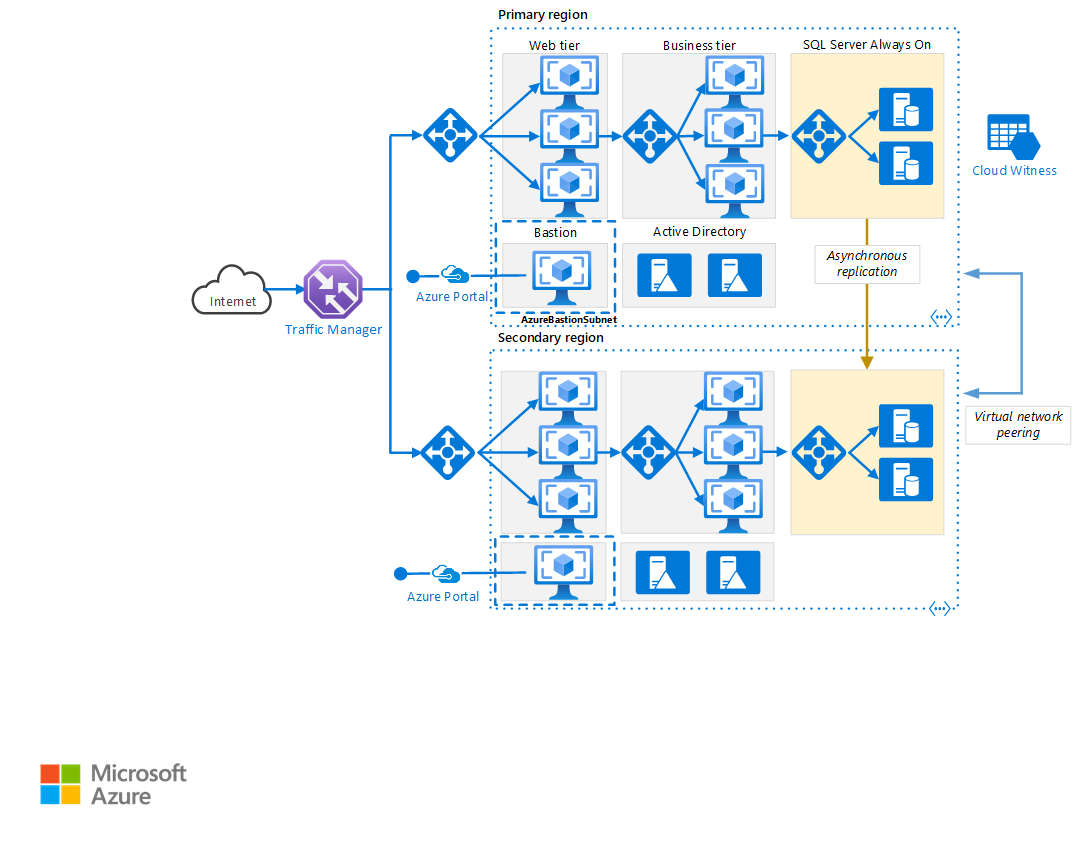
Téléchargez un fichier Visio de cette architecture.
Workflow
Régions primaires et secondaires. Pour obtenir une plus haute disponibilité, utilisez deux régions. L’une est la région primaire, tandis que l’autre sert au basculement.
Azure Traffic Manager. Traffic Manager achemine les requêtes entrantes vers l’une des régions. Pendant le fonctionnement normal, il achemine les requêtes vers la région primaire. Si cette région n’est plus disponible, Traffic Manager bascule vers la région secondaire. Pour plus d’informations, consultez la section Configuration de Traffic Manager.
Groupe de ressources. Créez des groupes de ressources distincts pour la région primaire, la région secondaire et Traffic Manager. Cette méthode vous donne la possibilité de gérer chaque région comme une seule collection de ressources. Par exemple, vous pourriez redéployer une région sans arrêter l’autre. Liez les groupes de ressources afin de pouvoir exécuter une requête pour répertorier toutes les ressources de l’application.
Réseaux virtuels. Créez un réseau virtuel distinct pour chaque région. Vérifiez que les espaces d’adressage ne se chevauchent pas.
Groupe de disponibilité SQL Server Always On. Si vous utilisez SQL Server, nous vous recommandons d’utiliser des groupes de disponibilité AlwaysOn SQL pour la haute disponibilité. Créez un groupe de disponibilité unique qui comprend les instances de SQL Server dans les deux régions.
Notes
Vous pouvez aussi utiliser Azure SQL Database, qui fournit une base de données relationnelle en tant que service cloud. Avec SQL Database, vous n’avez pas besoin de configurer de groupe de disponibilité ni de gérer le basculement.
Appairage de réseaux virtuels. Appairez les deux réseaux virtuels pour permettre la réplication des données de la région primaire vers la région secondaire. Pour en savoir plus, consultez Peering de réseaux virtuels.
Components
- Les groupes à haute disponibilité garantissent que les machines virtuelles que vous déployez sur Azure sont distribuées sur plusieurs nœuds matériels isolés dans un cluster. En cas de défaillance matérielle ou logicielle dans Azure, seule une partie de vos machines virtuelles est affectée et votre solution globale reste disponible et opérationnelle.
- Les zones de disponibilité protègent les applications et les données contre les défaillances de centre de données. Les zones de disponibilité sont des emplacements physiques individuels au sein d’une région Azure. Chaque zone est composée d’un ou de plusieurs centres de données équipés d’une alimentation, d’un système de refroidissement et d’un réseau indépendants.
- Azure Traffic Manager est un équilibreur de charge de trafic BASÉ sur DNS qui distribue le trafic de manière optimale. Il fournit des services dans les régions Azure globales, avec une haute disponibilité et une réactivité.
- Azure Load Balancer distribue le trafic entrant en fonction des règles définies et des sondes d’intégrité. Un équilibreur de charge offre une latence faible et un débit élevé, et peut gérer jusqu’à des millions de flux pour toutes les applications TCP et UDP. Un équilibreur de charge public est utilisé dans ce scénario pour distribuer le trafic client entrant à la couche web. Dans ce scénario, un équilibreur de charge interne est utilisé pour distribuer le trafic de la couche métier au cluster SQL Server back-end.
- Azure Bastion fournit une connectivité RDP et SSH sécurisée à toutes les machines virtuelles du réseau virtuel dans lequel il est approvisionné. Utilisez Azure Bastion pour protéger vos machines virtuelles contre l’exposition des ports RDP/SSH au monde extérieur, tout en fournissant un accès sécurisé à l’aide des protocoles RDP/SSH.
Recommandations
Une architecture multirégion peut offrir une meilleure disponibilité qu’un déploiement dans une seule région. Si une interruption de service régionale affecte la région primaire, vous pouvez utiliser Traffic Manager pour basculer vers la région secondaire. Cette architecture peut également se révéler utile en cas de défaillance d’un sous-système spécifique de l’application.
Plusieurs approches générales permettent de bénéficier d’une haute disponibilité dans l’ensemble des régions :
- Mode actif/passif avec serveur de secours. Le trafic est dirigé vers une région, tandis que l’autre région est en attente sur le serveur de secours. La mise en veille à chaud signifie que les VM de la région secondaire sont allouées et fonctionnent en permanence.
- Mode actif/passif avec reprise progressive. Le trafic est dirigé vers une région, tandis que l’autre région est en attente sur le centre de données de reprise progressive. La reprise progressive signifie que les machines virtuelles de la région secondaire ne sont pas allouées jusqu’à ce que le basculement soit nécessaire. La mise en œuvre de cette approche se révèle moins coûteuse, mais nécessite davantage de temps en cas de défaillance.
- Mode actif/actif. Les deux régions sont actives, et la charge de travail des requêtes est équilibrée entre les régions. Si une région devient indisponible, elle est retirée de la rotation.
Cette architecture de référence est axée sur le mode actif/passif avec serveur de secours, et utilise Traffic Manager pour le basculement. Vous pouvez déployer quelques machines virtuelles pour une sauvegarde à chaud, puis les faire évoluer en fonction des besoins.
Association régionale
Chaque région Azure est associée à une autre région de la même zone géographique. En général, vous devez choisir des régions de la même paire régionale (par exemple, USA Est 2 et USA Centre). Cette approche offre les avantages suivants :
- En cas d’interruption de service générale, la récupération d’au moins une région de chaque paire est prioritaire.
- Les mises à jour planifiées du système Azure sont déployées dans les régions associées de manière séquentielle, afin de minimiser les temps d’arrêt possibles.
- Les paires régionales appartiennent à la même zone géographique, afin de répondre aux exigences en matière de résidence des données.
Toutefois, vous devez vérifier que les deux régions prennent en charge tous les services Azure nécessaires pour votre application (voir Services par région). Pour plus d’informations sur les régions jumelées, consultez l’article Continuité des activités et récupération d’urgence (BCDR) : régions jumelées d’Azure.
Configuration de Traffic Manager
Considérez les points suivants lors de la configuration de Traffic Manager :
- Routage. Traffic Manager prend en charge plusieurs algorithmes de routage. Pour le scénario décrit dans cet article, utilisez le routage par priorité (auparavant désigné sous le terme de routage par basculement). Quand cette méthode de routage est configurée, Traffic Manager envoie toutes les requêtes à la région primaire, sauf si elle devient inaccessible. À ce moment-là, les requêtes basculent automatiquement vers la région secondaire. Consultez Configurer la méthode de routage de basculement.
- Sonde d’intégrité. Traffic Manager utilise une sonde HTTP (ou HTTPS) pour superviser la disponibilité de chaque région. La sonde vérifie la présence d’une réponse HTTP 200 pour un chemin d’URL spécifié. Une bonne pratique consiste à créer un point de terminaison qui signale l’intégrité globale de l’application et à utiliser ce point de terminaison pour la sonde d’intégrité. Dans le cas contraire, la sonde risque de signaler un point de terminaison intègre alors que des parties critiques de l’application sont défaillantes. Pour plus d’informations, consultez Modèle Supervision de point de terminaison d’intégrité.
Lorsque Traffic Manager bascule, il y a une période pendant laquelle l'application n'est pas accessible aux clients. Ce laps de temps dépend des facteurs suivants :
- La sonde d’intégrité doit détecter que la région primaire est devenue inaccessible.
- Les serveurs DNS (Domain Name Service) doivent mettre à jour les enregistrements DNS mis en cache pour l’adresse IP, qui dépend de la durée de vie (TTL) DNS. La valeur TTL par défaut est de 300 secondes (5 minutes), mais vous pouvez configurer cette valeur quand vous créez le profil Traffic Manager.
Pour plus d’informations, consultez À propos de la supervision de Traffic Manager.
En cas de basculement de Traffic Manager, nous vous recommandons de procéder à une restauration manuelle plutôt que d’implémenter une restauration automatique. Dans le cas contraire, l’application risque d’alterner continuellement entre les régions. Vérifiez que tous les sous-systèmes de l’application sont intègres avant d’effectuer la restauration automatique.
Traffic Manager revient automatiquement en arrière par défaut. Pour éviter ce problème, réduisez manuellement la priorité de la région primaire après un événement de basculement. Par exemple, supposez que la région primaire a la priorité 1, et que la base de données secondaire a la priorité 2. Après un basculement, définissez la priorité de la région primaire sur la valeur 3 afin d’empêcher la restauration automatique. Lorsque vous êtes prêt à revenir, mettez la priorité sur la valeur 1.
La commande Azure CLI suivante met à jour la priorité :
az network traffic-manager endpoint update --resource-group <resource-group> --profile-name <profile>
--name <endpoint-name> --type azureEndpoints --priority 3
Une autre approche consiste à désactiver temporairement le point de terminaison jusqu'à ce que vous soyez prêt à revenir en arrière :
az network traffic-manager endpoint update --resource-group <resource-group> --profile-name <profile>
--name <endpoint-name> --type azureEndpoints --endpoint-status Disabled
En fonction de la cause d’un basculement, vous devrez peut-être redéployer les ressources au sein d’une région. Avant d’effectuer une restauration automatique, exécutez un test de disponibilité opérationnelle. Le test doit vérifier entre autres ce qui suit :
- Les machines virtuelles sont configurées correctement. (Tous les logiciels nécessaires sont installés, IIS est en cours d’exécution, et ainsi de suite.)
- Les sous-systèmes d’application sont intègres.
- Test fonctionnel. (Par exemple, le niveau de la base de données est accessible à partir du niveau Web.)
Configurer les groupes de disponibilité SQL Server AlwaysOn
Avec les versions antérieures à Windows Server 2016, les groupes de disponibilité SQL Server AlwaysOn nécessitent un contrôleur de domaine et tous les nœuds du groupe de disponibilité doivent être dans le même domaine Active Directory (AD).
Pour configurer le groupe de disponibilité
Au minimum, placez deux contrôleurs de domaine dans chaque région.
Donnez à chaque contrôleur de domaine une adresse IP statique.
Appairez les deux réseaux virtuels pour permettre la communication entre eux.
Pour chaque réseau virtuel, ajoutez les adresses IP des contrôleurs de domaine (des deux régions) à la liste des serveurs DNS. Vous pouvez utiliser la commande CLI suivante. Pour plus d’informations, consultez Modifier les serveurs DNS.
az network vnet update --resource-group <resource-group> --name <vnet-name> --dns-servers "10.0.0.4,10.0.0.6,172.16.0.4,172.16.0.6"Créez un cluster WSFC (Clustering de basculement Windows Server) qui inclut les instances de SQL Server dans les deux régions.
Créez un groupe de disponibilité SQL Server AlwaysOn qui inclut les instances de SQL Server dans les régions primaire et secondaire. Pour connaître les étapes, consultez Extending AlwaysOn Availability Group to Remote Azure Datacenter (PowerShell) (Extension de groupe de disponibilité AlwaysOn à un centre de données Azure à distance (PowerShell).
Placez le réplica principal dans la région primaire.
Placez un ou plusieurs réplicas secondaires dans la région primaire. Configurez ces répliques pour utiliser le commit synchrone avec basculement automatique.
Placez un ou plusieurs réplicas secondaires dans la région secondaire. Configurez ces répliques pour utiliser le commit asynchrone, pour des raisons de performance. (Dans le cas contraire, toutes les transactions T-SQL doivent attendre un aller-retour sur le réseau vers la région secondaire.)
Notes
Les réplicas avec validation asynchrone ne prennent pas en charge le basculement automatique.
Considérations
Ces considérations implémentent les piliers d’Azure Well-Architected Framework qui est un ensemble de principes directeurs qui permettent d’améliorer la qualité d’une charge de travail. Pour plus d’informations, consultez Microsoft Azure Well-Architected Framework.
Disponibilité
Avec une application multiniveau complexe, vous n’aurez peut-être pas besoin de répliquer l’ensemble de l’application dans la région secondaire. Au lieu de cela, vous pourrez simplement répliquer un sous-système critique nécessaire pour prendre en charge la continuité d’activité.
Traffic Manager est un point de défaillance possible dans le système. Si le service Traffic Manager tombe en panne, les clients ne peuvent pas accéder à votre application pendant le temps d'arrêt. Consultez le contrat SLA de Traffic Manager et déterminez si Traffic Manager peut à lui seul répondre à vos exigences métiers en matière de haute disponibilité. Si tel n’est pas le cas, envisagez d’ajouter une autre solution de gestion du trafic en guise de restauration automatique. En cas de défaillance du service Azure Traffic Manager, modifiez vos enregistrements CNAME dans DNS pour qu’ils pointent vers l’autre service de gestion du trafic. (Cette opération doit être effectuée manuellement, et votre application reste inaccessible tant que ces modifications DNS n’ont pas été propagées.)
Pour le cluster SQL Server, deux scénarios de basculement doivent être pris en compte :
Tous les réplicas de base de données SQL Server dans la région primaire échouent. Par exemple, cette défaillance pourrait se produire lors d'une panne régionale. Dans ce cas, vous devez faire basculer manuellement le groupe de disponibilité, même si Traffic Manager bascule automatiquement vers le frontend. Suivez les étapes de l’article Perform a Forced Manual Failover of a SQL Server Availability Group (Effectuer un basculement manuel forcé d’un groupe de disponibilité SQL Server), qui explique comment effectuer un basculement forcé à l’aide de SQL Server Management Studio, Transact-SQL ou PowerShell dans SQL Server 2016.
Avertissement
Avec le basculement forcé, il existe un risque de perte de données. Une fois la région primaire de nouveau en ligne, prenez un instantané de la base de données et utilisez tablediff pour rechercher les différences.
Traffic Manager bascule vers la région secondaire, mais le réplica de base de données SQL Server principal est toujours disponible. Par exemple, le niveau frontend peut échouer sans affecter les machines virtuelles SQL Server. Dans ce cas, le trafic Internet est acheminé vers la région secondaire, et cette région peut toujours se connecter au réplica principal. Toutefois, il y aura une latence accrue, car les connexions SQL Server traversent différentes régions. Dans ce cas, vous devez effectuer un basculement manuel comme suit :
- Faites basculer temporairement un réplica de base de données SQL Server dans la région secondaire sur la validation synchrone. Cette étape garantit qu'il n'y aura pas de perte de données pendant le basculement.
- Basculez vers ce réplica.
- Quand vous rebasculez vers la région primaire, restaurez le paramètre de validation asynchrone.
Simplicité de gestion
Quand vous mettez à jour votre déploiement, mettez à jour une seule région à la fois, afin de réduire le risque de défaillance globale due à une configuration incorrecte ou à une erreur dans l’application.
Testez la résilience aux défaillances du système. Voici quelques scénarios courants de défaillance à tester :
- Arrêt des instances de machine virtuelle.
- Pression sur les ressources telles que le processeur et la mémoire.
- Déconnexion/délai de réseau.
- Blocage des processus.
- Expiration des certificats.
- Simulation de défaillances matérielles.
- Arrêt du service DNS sur les contrôleurs de domaine.
Mesurez les temps de récupération et vérifiez qu’ils répondent aux besoins de votre entreprise. Testez également des combinaisons de défaillances.
Optimisation des coûts
L’optimisation des coûts consiste à examiner les moyens de réduire les dépenses inutiles et d’améliorer l’efficacité opérationnelle. Pour plus d’informations, consultez Vue d’ensemble du pilier d’optimisation des coûts.
Utilisez la Calculatrice de prix Azure pour estimer les coûts. Voici quelques autres éléments à prendre en compte :
Virtual Machine Scale Sets
Les Virtual Machine Scale Sets sont disponibles sur toutes les tailles de machines virtuelles Windows. Vous n'êtes facturé que pour les VM Azure que vous déployez et pour toutes les ressources d'infrastructure sous-jacentes consommées, telles que le stockage et les réseaux. Il n'y a pas de frais supplémentaires pour le service des Virtual Machine Scale Sets.
Pour connaître les options tarifaires des machines virtuelles individuelles, consultez Tarification des machines virtuelles Windows.
Serveur SQL
Si vous choisissez Azure SQL DBaas, vous pouvez réaliser des économies car vous n'avez pas besoin de configurer un groupe de disponibilité AlwaysOn et des machines contrôleurs de domaine. Différentes options de déploiement sont disponibles, de la base de données unique à l'instance gérée, en passant par les pools élastiques. Pour en savoir plus, consultez Tarification d’Azure SQL.
Pour connaître les options de tarification des machines virtuelles SQL Server, consultez Tarification des machines virtuelles SQL.
Équilibreurs de charge
Vous n'êtes facturé que pour le nombre de règles d'équilibrage de charge et de règles de sortie configurées. Les règles NAT entrantes sont gratuites. Il n'y a pas de frais horaires pour l'équilibreur de charge Standard Load Balancer lorsqu'aucune règle n'est configurée.
Tarification de Traffic Manager
La facturation de Traffic Manager repose sur le nombre de requêtes DNS reçues, avec une remise pour les services recevant plus de 1 milliard de requêtes mensuelles. Vous êtes également facturé pour chaque point de terminaison surveillé.
Pour plus d’informations, consultez la section sur les coûts dans Microsoft Azure Well-Architected Framework.
Tarification de VNET Peering
Un déploiement à haute disponibilité qui utilise plusieurs régions Azure fera appel à VNET-Peering. Des tarifs différents s'appliquent à VNET Peering au sein d'une même région ainsi qu'à Global VNET Peering.
Pour plus d'informations, consultez Tarification de réseau virtuel.
DevOps
Utilisez un modèle Azure Resource Manager pour approvisionner les ressources Azure et leurs dépendances. Utilisez le même modèle pour déployer les ressources dans les régions primaire et secondaire. Incluez toutes les ressources du même réseau virtuel afin qu’elles soient isolées dans la même charge de travail de base. En incluant toutes les ressources, il est plus facile d'associer les ressources spécifiques de la charge de travail à une équipe DevOps, afin que celle-ci puisse gérer indépendamment tous les aspects de ces ressources. Cet isolement permet à l'équipe et services DevOps d'effectuer une intégration et une livraison continues (CI/CD).
En outre, vous pouvez utiliser différents modèles Azure Resource Manager et les intégrer à Azure DevOps Services pour approvisionner différents environnements en quelques minutes, par exemple pour répliquer des scénarios de production ou des environnements de test de charge uniquement lorsque cela s'avère nécessaire, ce qui permet de réduire les coûts.
Pensez à utiliser Azure Monitor pour analyser et optimiser les performances de votre infrastructure, et pour superviser et diagnostiquer les problèmes de réseau sans vous connecter à vos machines virtuelles. Application Insights est un composant d'Azure Monitor. Il vous fournit des journaux et des métriques enrichies pour vérifier l'état de votre environnement Azure dans sa globalité. Azure Monitor vous aidera à suivre l'état de votre infrastructure.
Vous devez non seulement superviser les éléments de calcul qui prennent en charge le code de votre application, mais également votre plateforme de données, en particulier vos bases de données, car des performances médiocres de la couche Données d'une application peuvent avoir de graves conséquences.
Afin de tester l'environnement Azure où les applications sont exécutées, celui-ci doit être soumis à un contrôle de version et être déployé via les mêmes mécanismes que le code d'application. Il pourra ensuite être testé et validé en utilisant les paradigmes de test DevOps.
Pour plus d'informations, consultez la section Excellence opérationnelle de Microsoft Azure Well-Architected Framework.
Contributeurs
Cet article est géré par Microsoft. Il a été écrit à l’origine par les contributeurs suivants.
Auteur principal :
- Donnie Trumpower | Architecte de solution cloud senior
Pour afficher les profils LinkedIn non publics, connectez-vous à LinkedIn.
Étapes suivantes
Ressources associées
L'architecture suivante utilise certaines des technologies suivantes :