Tutoriel : interroger un conteneur Docker SQL Server Linux dans un réseau virtuel à partir d’un notebook Azure Databricks
Ce tutoriel vous montre comment intégrer Azure Databricks à un conteneur Docker SQL Server Linux sur un réseau virtuel.
Dans ce tutoriel, vous allez apprendre à :
- Déployer un espace de travail Azure Databricks sur un réseau virtuel
- Installer une machine virtuelle Linux sur un réseau public
- Installation de Docker
- Installer Microsoft SQL Server sur Linux dans un conteneur Docker
- Interroger SQL Server à l’aide de JDBC à partir d’un notebook Databricks
Prérequis
Créez un espace de travail Databricks sur un réseau virtuel.
Installez Ubuntu pour Windows.
Téléchargez SQL Server Management Studio.
Créer une machine virtuelle Linux
Dans le portail Azure, sélectionnez l’icône Machines virtuelles. Sélectionnez ensuite + Ajouter.
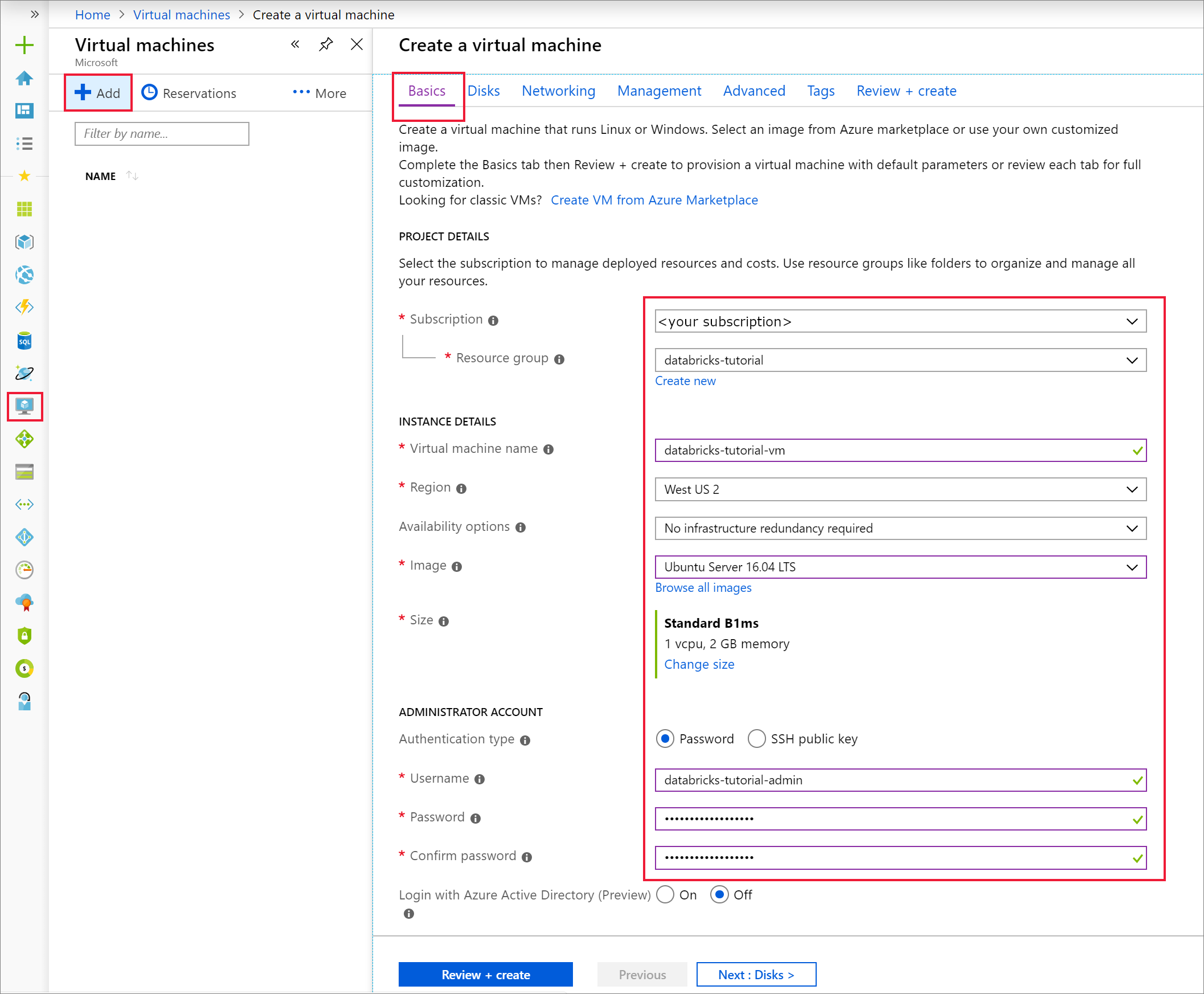
Dans l’onglet Informations de base, choisissez Ubuntu Server 18.04 LTS et remplacez la taille de machine virtuelle par B2s. Choisissez un nom d’utilisateur et un mot de passe administrateur.
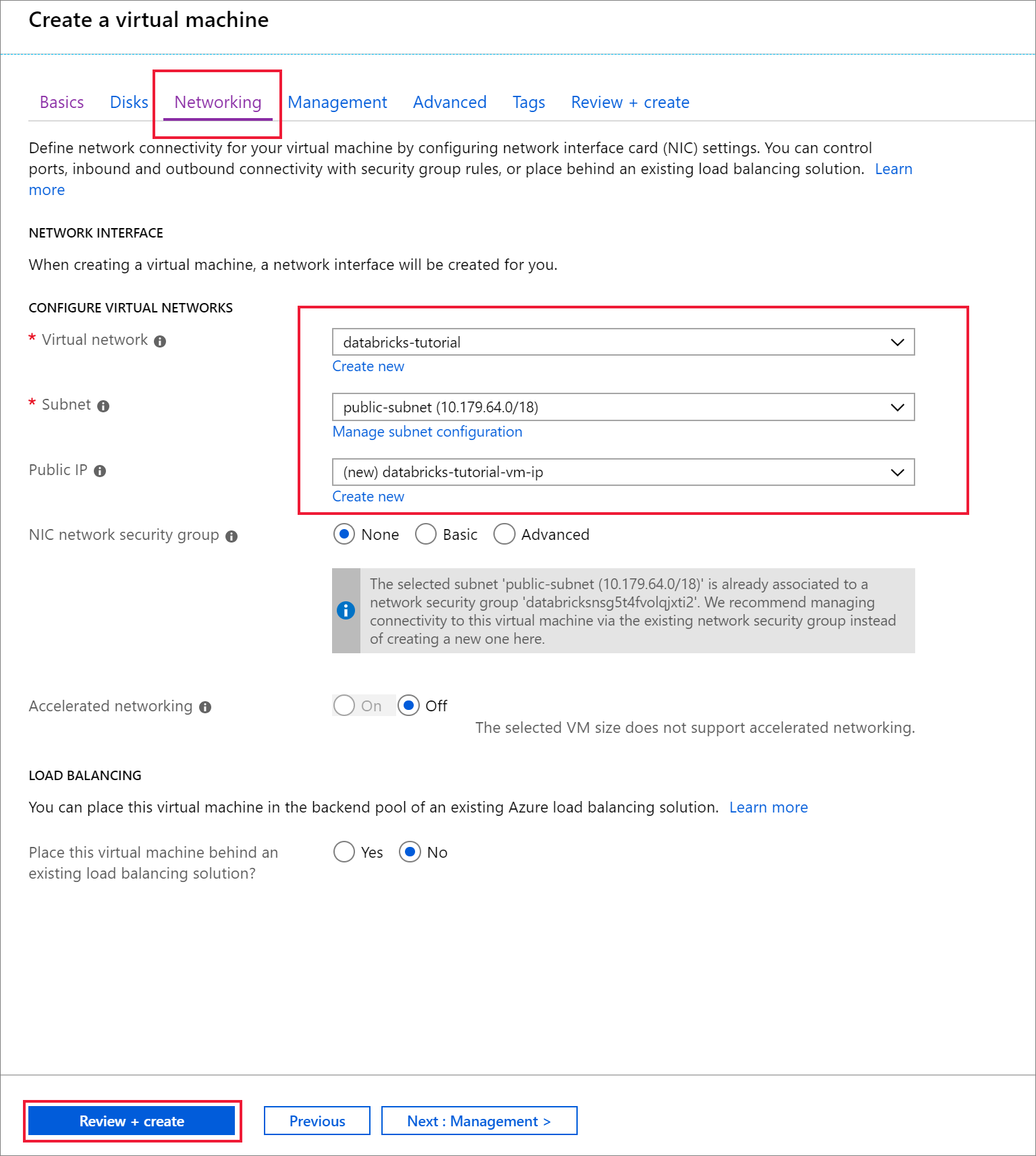
Accédez à l’onglet Réseau. Choisissez le réseau virtuel et le sous-réseau public où se trouve votre cluster Azure Databricks. Sélectionnez Vérifier + créer, puis Créer pour déployer la machine virtuelle.
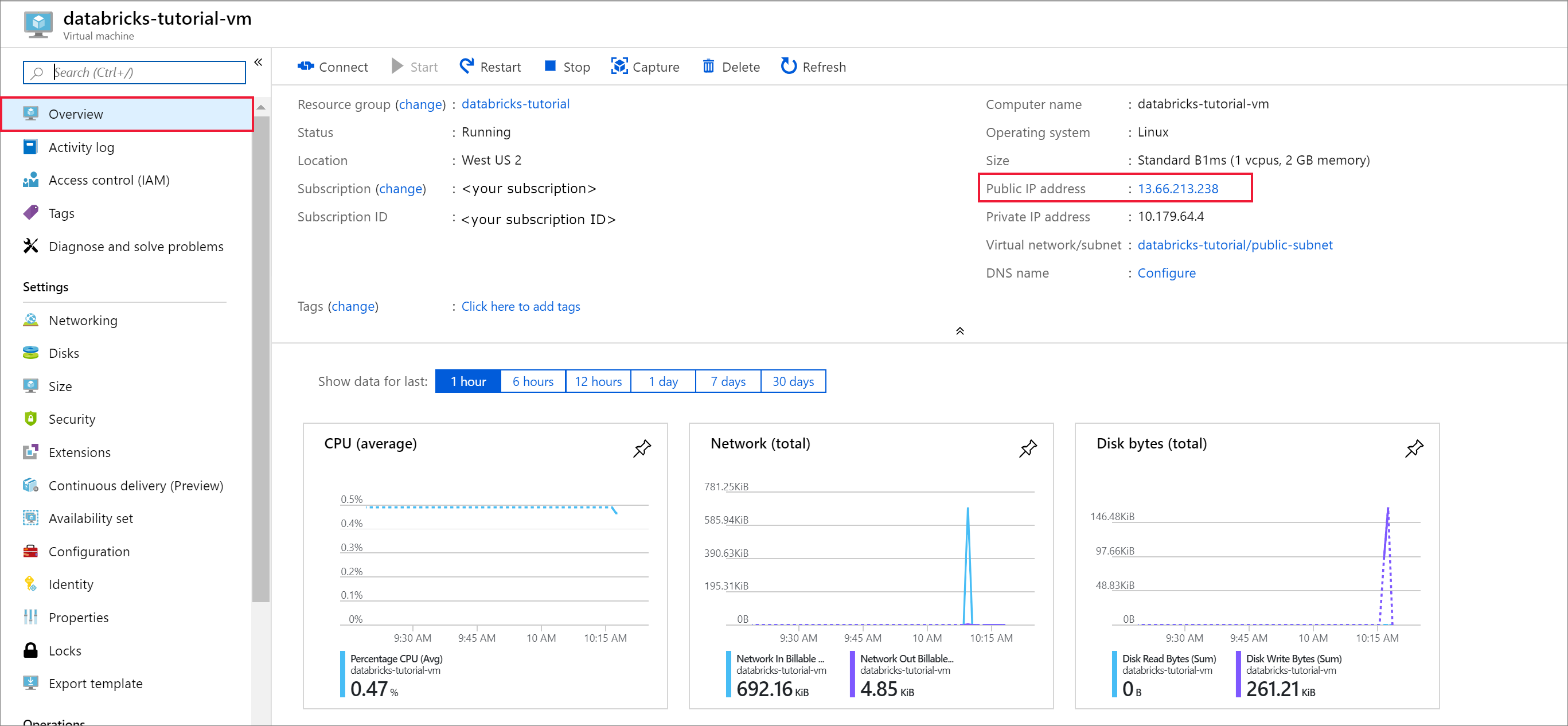
Lorsque le déploiement est terminé, accédez à la machine virtuelle. Notez l’adresse IP publique et le réseau/sous-réseau virtuel qui figurent dans la Vue d’ensemble. Sélectionnez Adresse IP publique.
Définissez Attribution sur Statique et entrez une étiquette de nom DNS. Sélectionnez Enregistrer, puis redémarrez la machine virtuelle.
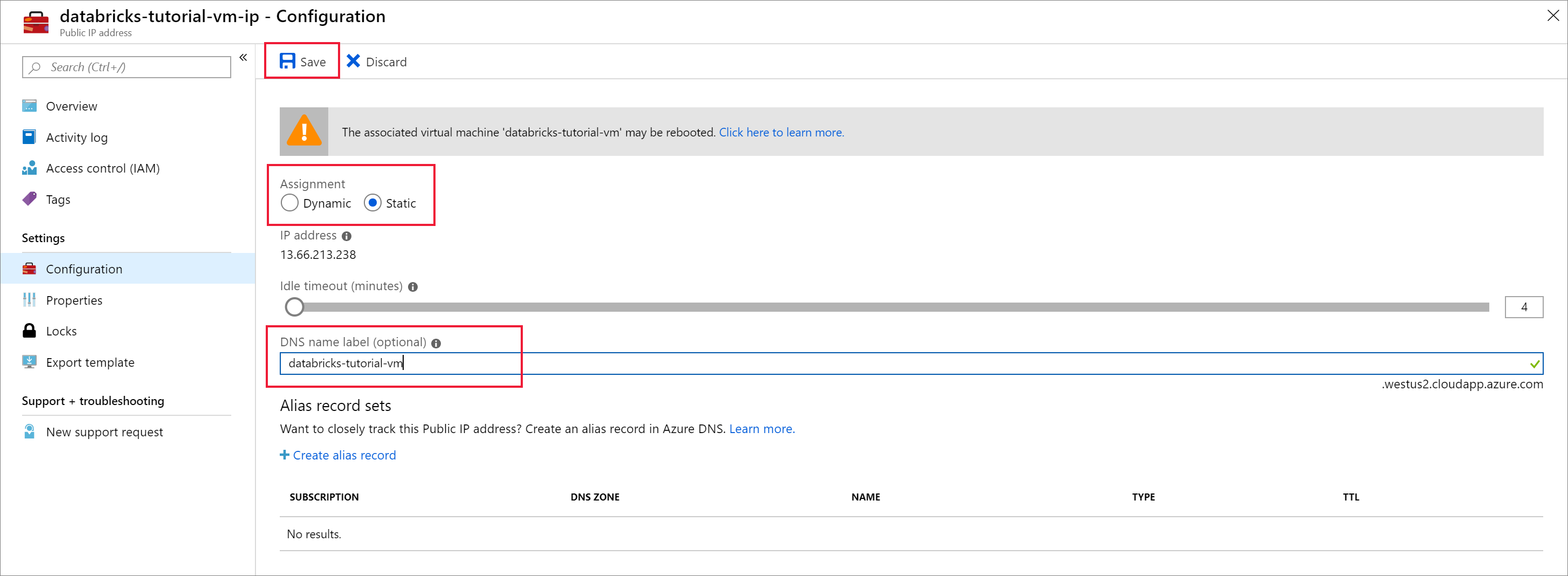
Sélectionnez l’onglet Réseau situé sous Paramètres. Notez que le groupe de sécurité réseau qui a été créé pendant le déploiement d’Azure Databricks est associé à la machine virtuelle. Sélectionnez Ajouter une règle de port d’entrée.
Ajoutez une règle afin d’ouvrir le port 22 pour le SSH. Utilisez les paramètres suivants :
Paramètre Valeur suggérée Description Source Adresses IP Spécifie que le trafic entrant provenant d’une adresse IP de source spécifique est autorisé ou refusé par cette règle. Adresses IP sources <votre adresse IP publique> Entrez votre adresse IP publique. Pour connaître votre adresse IP publique, accédez à bing.com, puis lancez une recherche sur "my IP". Source port ranges * Autorise le trafic de tous les ports. Destination Adresses IP Spécifie que le trafic sortant vers une adresse IP de source spécifique est autorisé ou refusé par cette règle. Adresses IP de destination <adresse IP publique de votre machine virtuelle> Entrez l’adresse IP publique de votre machine virtuelle. Celle-ci se trouve dans la page Vue d’ensemble de votre machine virtuelle. Plages de ports de destination 22 Ouvrez le port 22 pour le SSH. Priority 290 Attribuez une priorité à la règle. Nom ssh-databricks-tutorial-vm Nommez la règle. 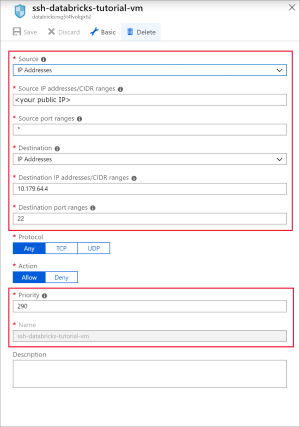
Ajoutez une règle afin d’ouvrir le port 1433 pour SQL à l’aide des paramètres suivants :
Paramètre Valeur suggérée Description Source Quelconque La source spécifie que le trafic entrant provenant d’une adresse IP source spécifique sera autorisé ou refusé par cette règle. Source port ranges * Autorise le trafic de tous les ports. Destination Adresses IP Spécifie que le trafic sortant vers une adresse IP de source spécifique est autorisé ou refusé par cette règle. Adresses IP de destination <adresse IP publique de votre machine virtuelle> Entrez l’adresse IP publique de votre machine virtuelle. Celle-ci se trouve dans la page Vue d’ensemble de votre machine virtuelle. Plages de ports de destination 1433 Ouvrez le port 22 pour SQL Server. Priority 300 Attribuez une priorité à la règle. Nom sql-databricks-tutorial-vm Nommez la règle. 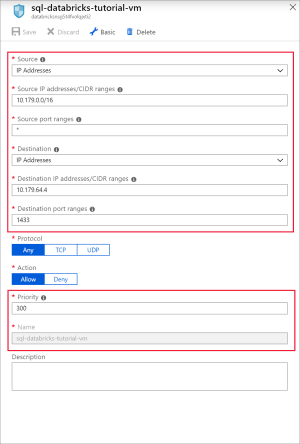
Exécuter SQL Server dans un conteneur Docker
Ouvrez Ubuntu pour Windows, ou tout autre outil qui vous permettra d’utiliser SSH dans la machine virtuelle. Dans le portail Azure, accédez à votre machine virtuelle, puis sélectionnez Se connecter pour obtenir la commande SSH dont vous avez besoin pour vous connecter.
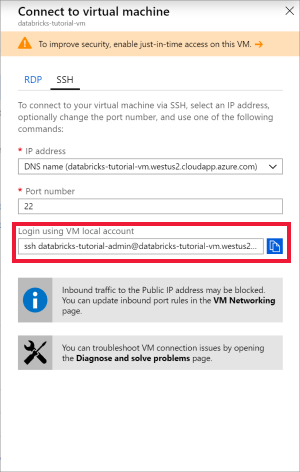
Entrez la commande dans votre terminal Ubuntu, puis entrez le mot de passe administrateur que vous avez créé lors de la configuration de la machine virtuelle.
Utilisez la commande suivante pour installer Docker sur la machine virtuelle.
sudo apt-get install docker.ioVérifiez l’installation de Docker avec la commande suivante :
sudo docker --versionInstallez l’image.
sudo docker pull mcr.microsoft.com/mssql/server:2017-latestVérifiez les images.
sudo docker imagesExécutez le conteneur à partir de l’image.
sudo docker run -e 'ACCEPT_EULA=Y' -e 'SA_PASSWORD=Password1234' -p 1433:1433 --name sql1 -d mcr.microsoft.com/mssql/server:2017-latestVérifiez que le conteneur est en cours d’exécution.
sudo docker ps -a
Créer une base de données SQL
Ouvrez SQL Server Management Studio et connectez-vous au serveur à l’aide du nom du serveur et de l’authentification SQL. Le nom d’utilisateur de connexion est SA et le mot de passe est celui qui est défini dans la commande Docker. Le mot de passe de l’exemple de commande est
Password1234.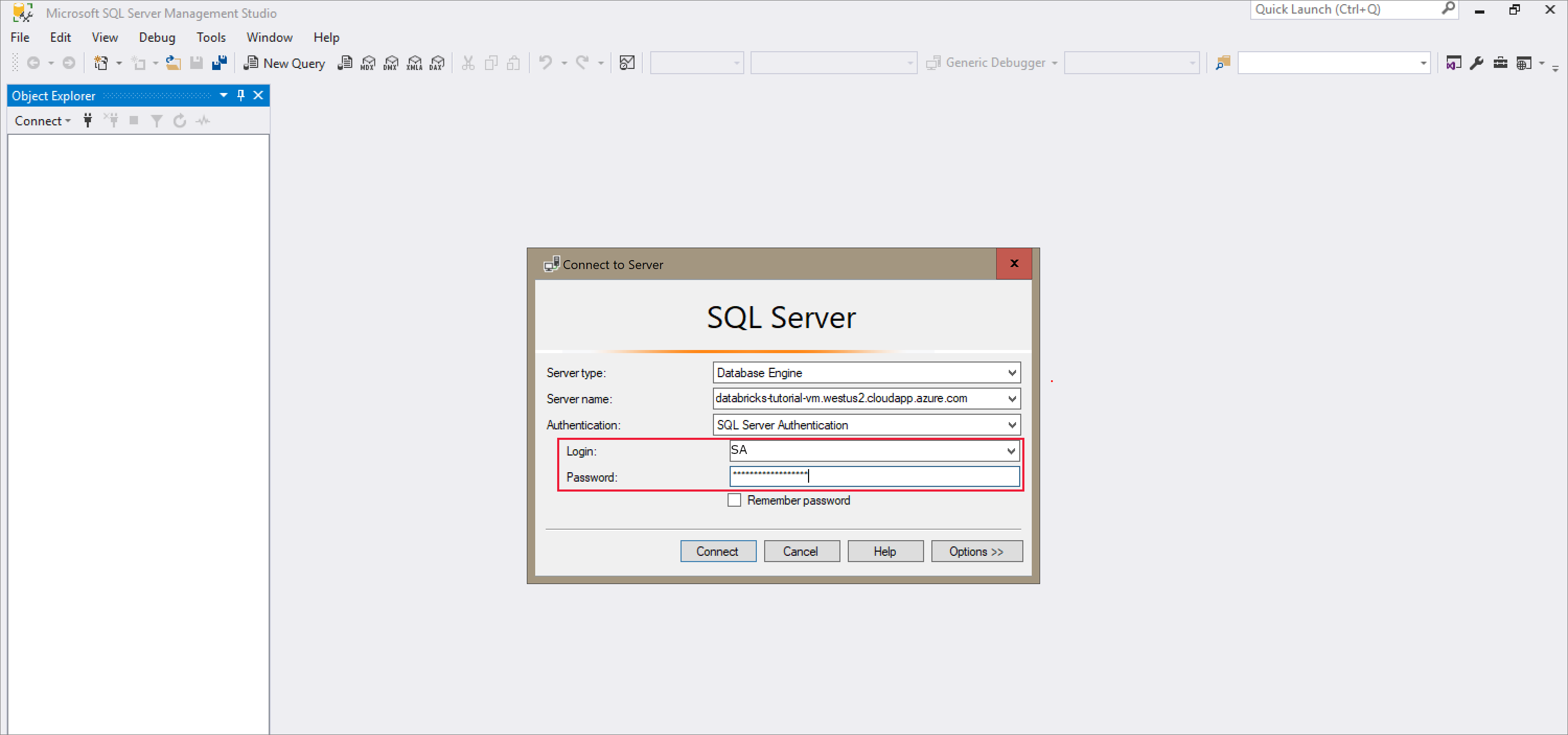
Une fois connecté, sélectionnez Nouvelle requête, puis entrez l’extrait de code suivant pour créer une base de données, une table et insérer des enregistrements dans la table.
CREATE DATABASE MYDB; GO USE MYDB; CREATE TABLE states(Name VARCHAR(20), Capitol VARCHAR(20)); INSERT INTO states VALUES ('Delaware','Dover'); INSERT INTO states VALUES ('South Carolina','Columbia'); INSERT INTO states VALUES ('Texas','Austin'); SELECT * FROM states GO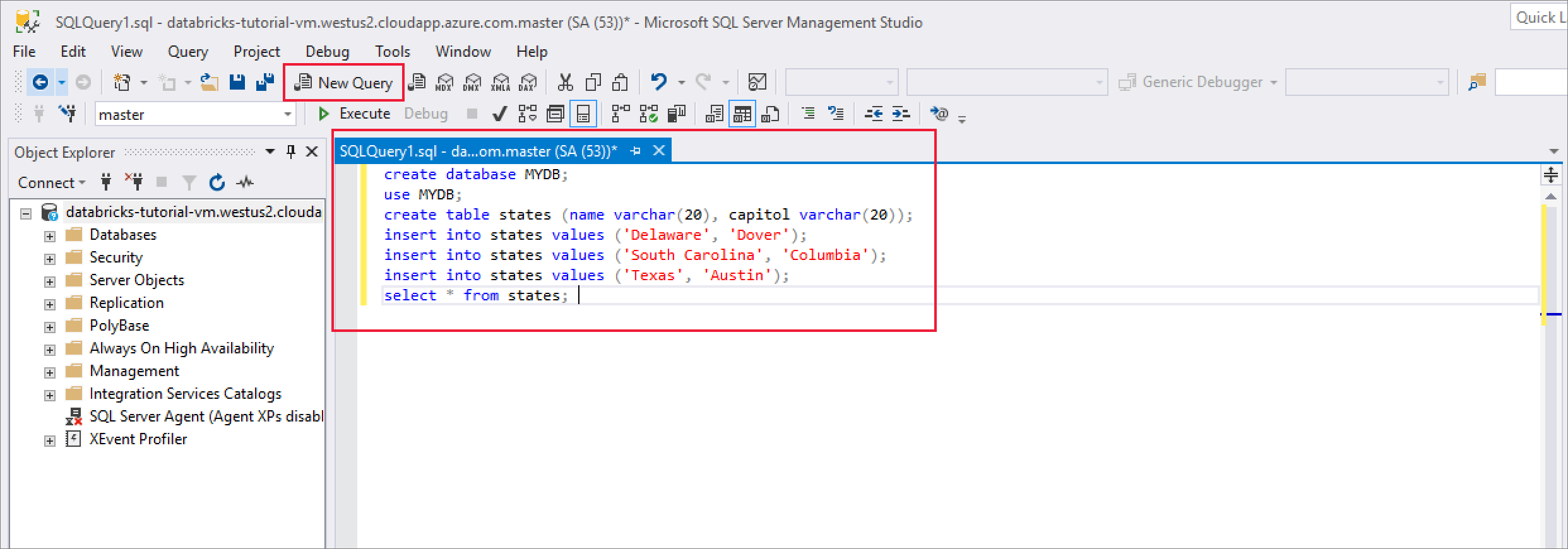
Requête SQL Server provenant d’Azure Databricks
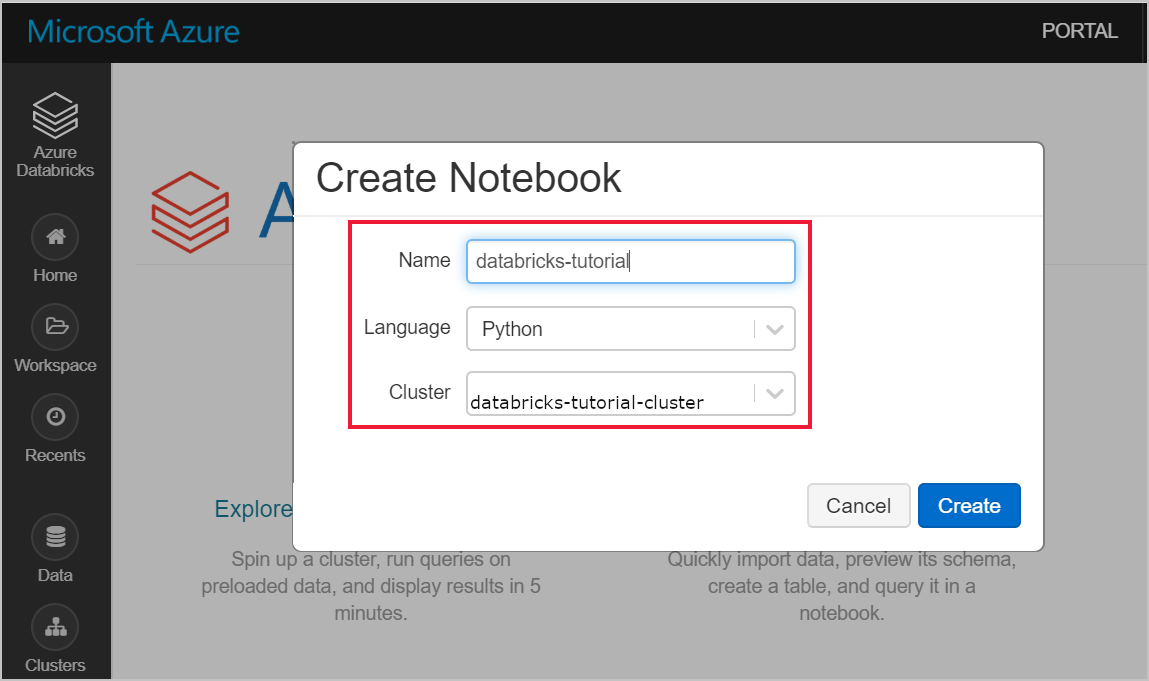
Accédez à votre espace de travail Azure Databricks et vérifiez que vous avez créé un cluster dans le cadre des prérequis. Ensuite, sélectionnez Créer un notebook. Nommez le notebook, sélectionnez Python comme langage, puis sélectionnez le cluster que vous avez créé.
Utilisez la commande suivante afin d’effectuer un test ping pour l’adresse IP interne de la machine virtuelle SQL Server. Le test ping doit réussir. Si ce n’est pas le cas, vérifiez que le conteneur est bien en cours d’exécution, puis vérifiez la configuration du groupe de sécurité réseau.
%sh ping 10.179.64.4Vous pouvez également utiliser la commande nslookup pour cette vérification.
%sh nslookup databricks-tutorial-vm.westus2.cloudapp.azure.comLorsque le test ping du serveur SQL Server a réussi, vous pouvez interroger la base de données et les tables. Exécutez le code Python suivant :
jdbcHostname = "10.179.64.4" jdbcDatabase = "MYDB" userName = 'SA' password = 'Password1234' jdbcPort = 1433 jdbcUrl = "jdbc:sqlserver://{0}:{1};database={2};user={3};password={4}".format(jdbcHostname, jdbcPort, jdbcDatabase, userName, password) df = spark.read.jdbc(url=jdbcUrl, table='states') display(df)
Nettoyer les ressources
Lorsque vous n’en avez plus besoin, supprimez le groupe de ressources, l’espace de travail Azure Databricks et toutes les ressources associées. La suppression du travail évite une facturation inutile. Si vous avez l’intention d’utiliser l’espace de travail Azure Databricks à l’avenir, vous pouvez arrêter le cluster et le redémarrer ultérieurement. Si vous ne pensez pas continuer à utiliser cet espace de travail Azure Databricks, supprimez toutes les ressources créées au cours de ce tutoriel en procédant comme suit :
Dans le menu de gauche du portail Azure, cliquez sur Groupes de ressources, puis sur le nom de ressources que vous avez créé.
Sur la page de votre groupe de ressources, sélectionnez Supprimer, saisissez le nom de la ressource à supprimer dans la zone de texte, puis sélectionnez à nouveau Supprimer.
Étapes suivantes
Passez à l’article suivant pour savoir comment extraire, transformer et charger des données à l’aide d’Azure Databricks.