Traiter des fichiers texte de longueur fixe à l’aide de flux de données de mappage Data Factory
S’APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Vous pouvez transformer les données de fichiers texte de longueur fixe en utilisant des flux de données de mappage dans Microsoft Azure Data Factory. Dans le cadre de la tâche suivante, nous allons définir un jeu de données pour un fichier texte sans délimiteur, puis configurer des divisions de sous-chaînes en fonction de la position ordinale.
Créer un pipeline
Sélectionnez +Nouveau pipeline pour créer un pipeline.
Ajoutez une activité de flux de données qui sera utilisée pour le traitement des fichiers de longueur fixe :
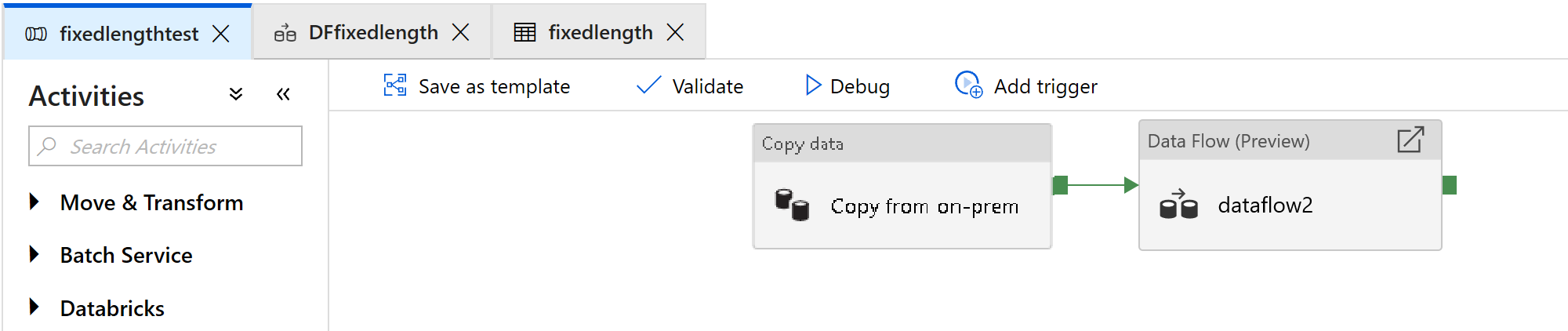
Dans l’activité de flux de données, sélectionnez Nouveau flux de données de mappage.
Ajoutez une transformation de source, de colonne dérivée, de sélection et de récepteur :
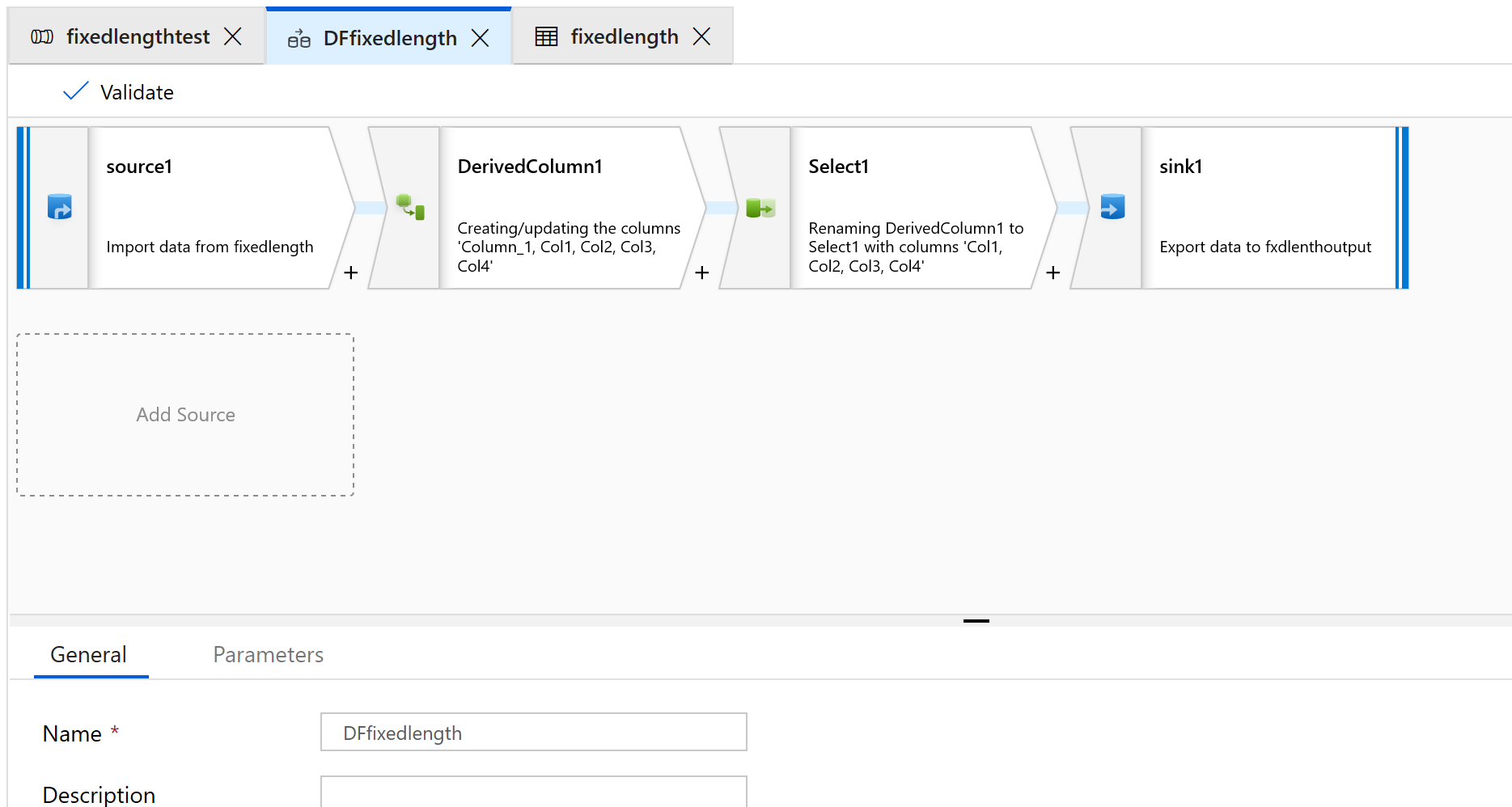
Configurez la transformation de source pour utiliser un nouveau jeu de données de type Texte délimité.
Ne définissez pas d’en-tête ou de délimiteur de colonne.
Nous allons à présent définir des points de départ et des longueurs de champ pour le contenu de ce fichier :
1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468Sous l’onglet Projection de votre transformation de source, vous devez voir une colonne de chaîne nommée Column_1.
Créez une colonne dans la colonne dérivée.
Nous allons donner des noms simples aux colonnes, tels que col1.
Dans le générateur d’expressions, tapez la chaîne suivante :
substring(Column_1,1,4)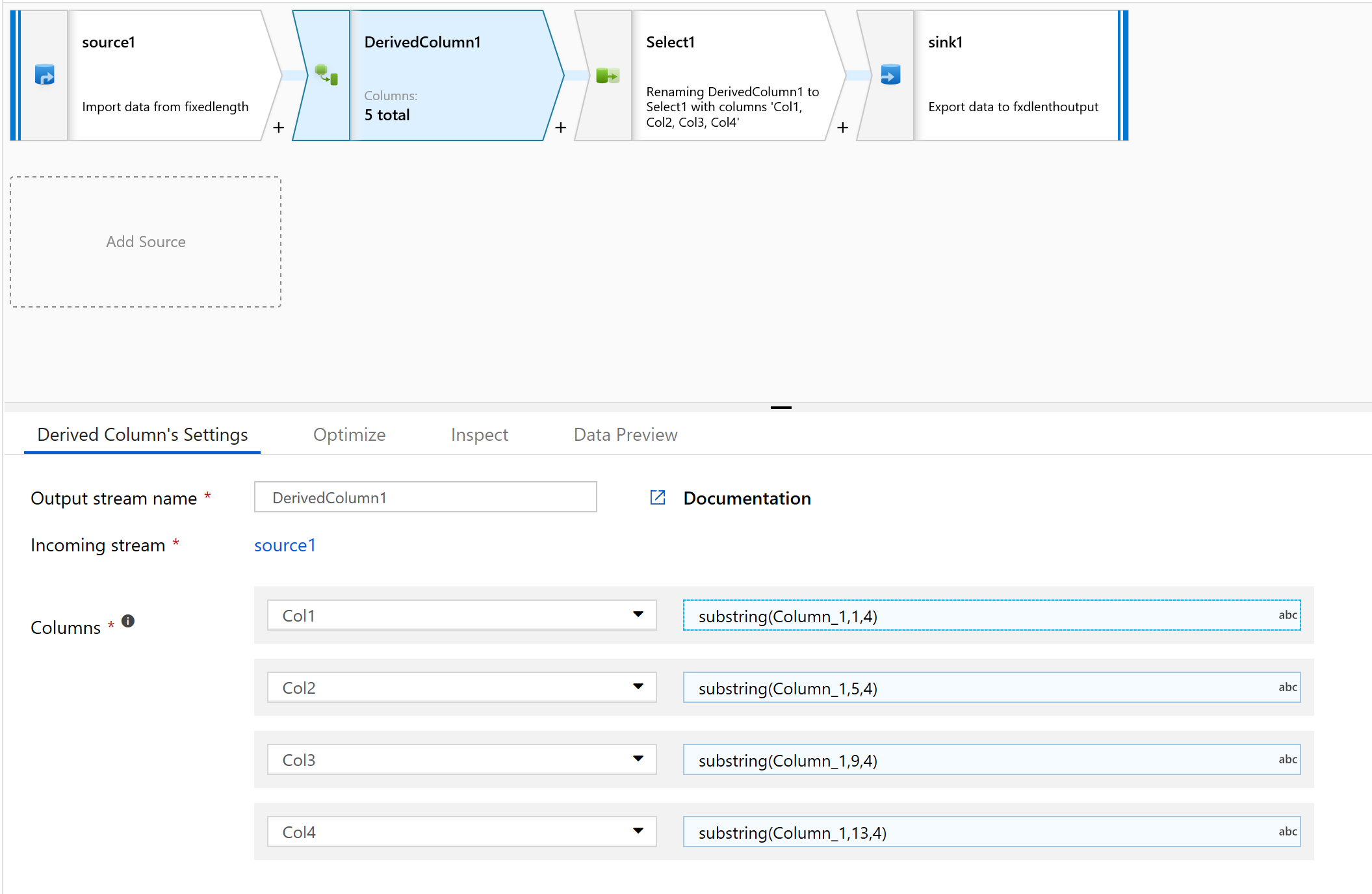
Répétez l’étape 10 pour toutes les colonnes que vous devez analyser.
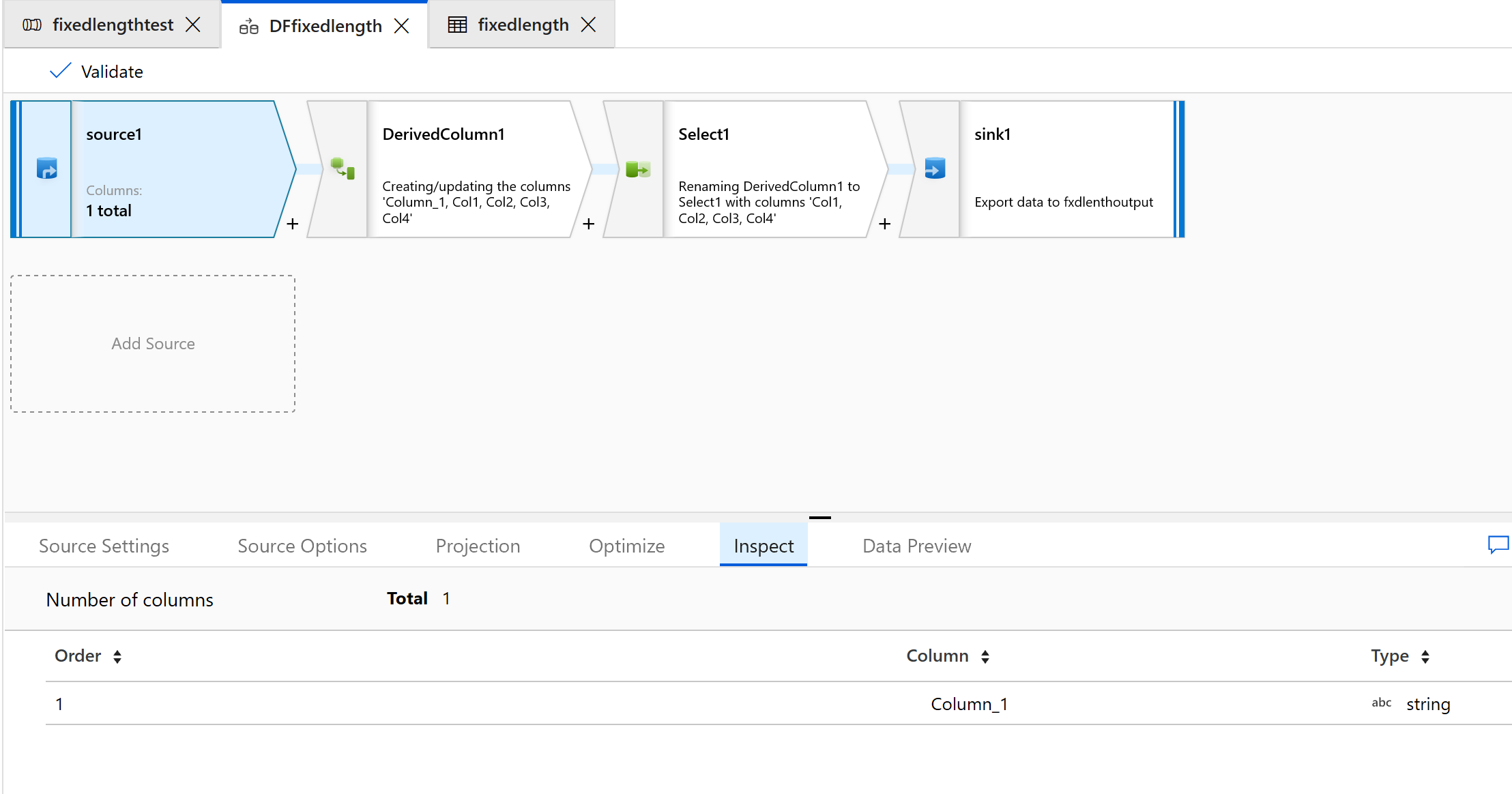
Sélectionnez l’onglet Inspecter pour afficher les nouvelles colonnes qui seront générées :
Utilisez la transformation de sélection (Select) pour supprimer les colonnes dont vous n’avez pas besoin pour la transformation :
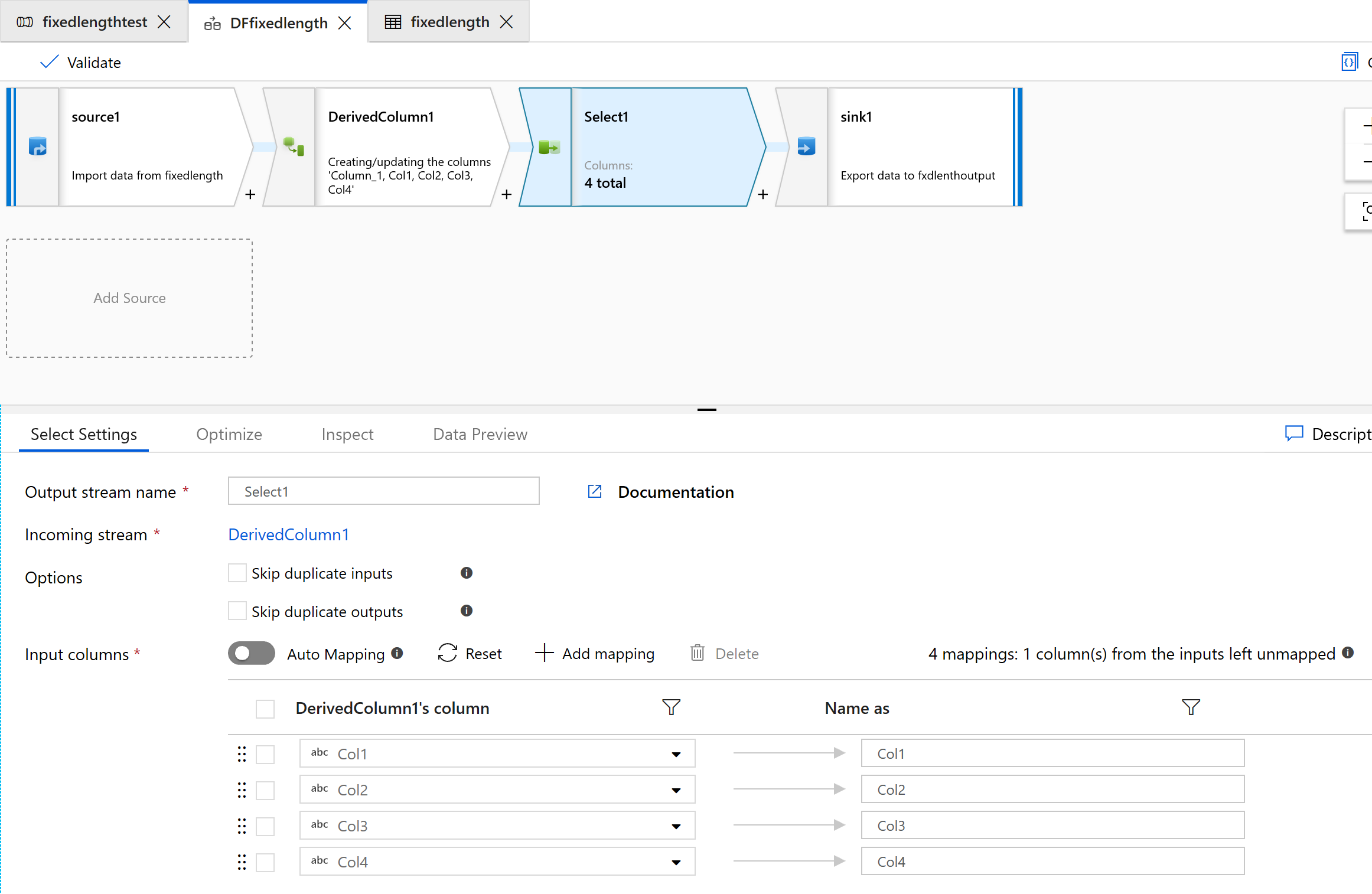
Utilisez le récepteur (Sink) pour générer les données dans un dossier :
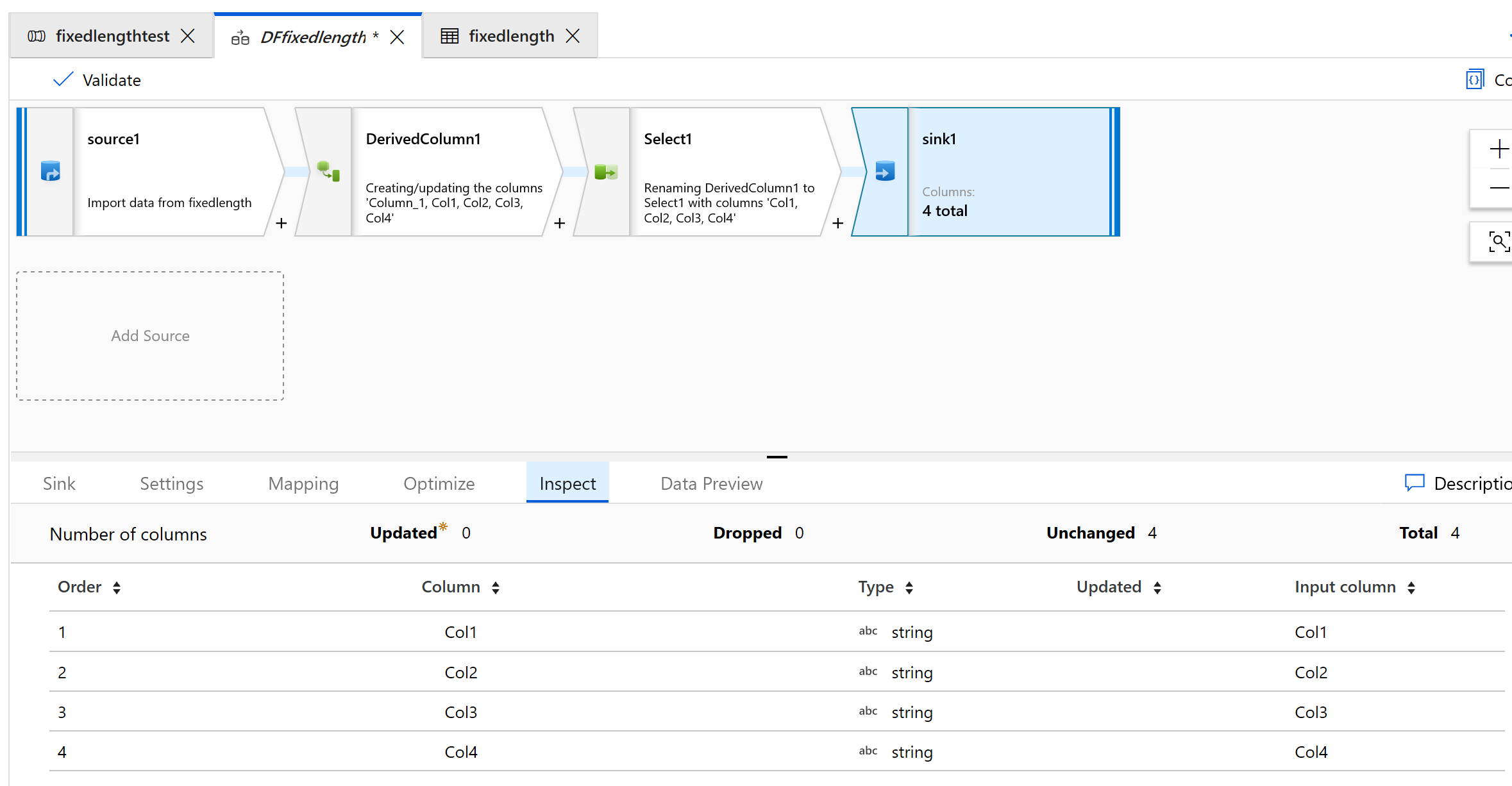
Voici à quoi ressemble la sortie :
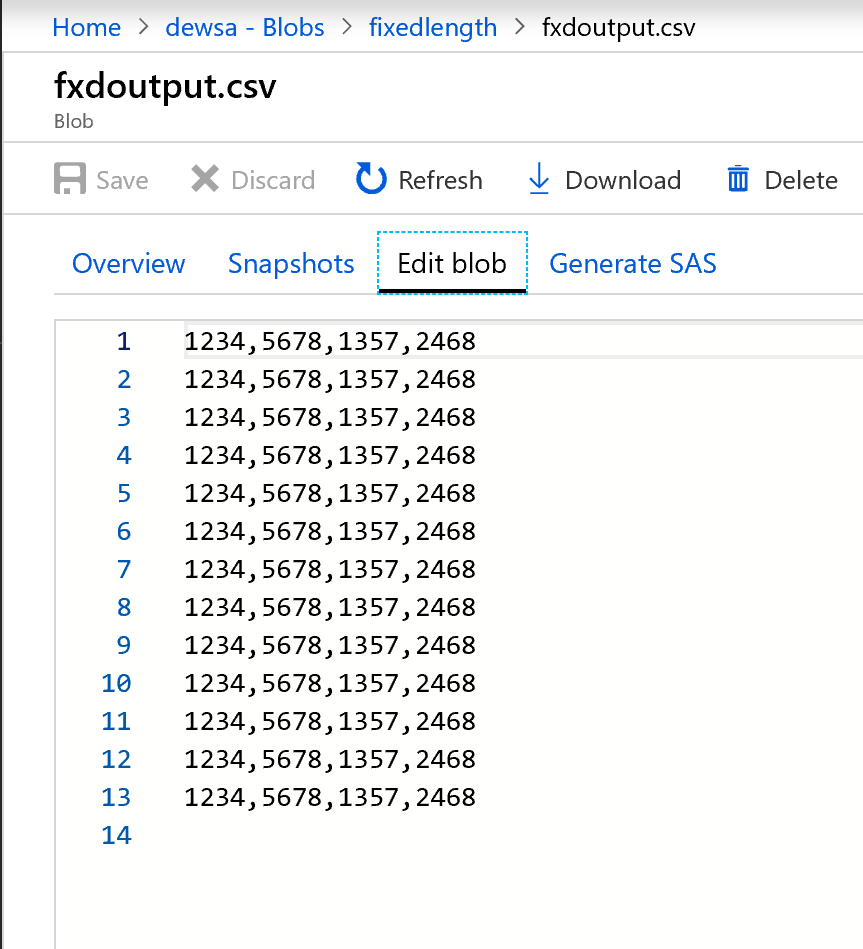
Les données de longueur fixe sont maintenant divisées en groupes de quatre caractères et attribuées à Col1, Col2, Col3, Col4, etc. Les données sont divisées en quatre colonnes, conformément à l’exemple précédent.
Contenu connexe
- Créez le reste de votre logique de flux de données à l’aide de transformations de flux de données de mappage.