Historique des données Azure Digital Twins (avec Azure Data Explorer)
L’historique des données est une fonctionnalité d’intégration d’Azure Digital Twins. Il vous permet de connecter une instance Azure Digital Twins à un cluster Azure Data Explorer afin que les mises à jour de graphiques soient automatiquement historisées vers Azure Data Explorer. Ces mises à jour historisées incluent les mises à jour des propriétés de jumeau, les événements de cycle de vie des jumeaux et les événements de cycle de vie des relations.
Une fois que les mises à jour de graphe sont historisées vers Azure Data Explorer, vous pouvez exécuter des requêtes conjointes à l’aide du plug-in Azure Digital Twins pour Azure Data Explorer pour raisonner entre les jumeaux numériques, leurs relations et les données de série chronologique. Cela peut être utilisé pour revenir en arrière à l’heure sur l’état du graphique utilisé ou pour obtenir des insights sur le comportement des environnements modélisés. Vous pouvez également utiliser ces requêtes pour alimenter des tableaux de bord opérationnels, enrichir des applications web 2D et 3D, et générer des expériences de réalité mixte ou augmentée pour communiquer l’état actuel et historique des ressources, des processus et des personnes modélisées dans Azure Digital Twins.
Pour plus d’une présentation de l’historique des données, notamment une démonstration rapide, regardez la vidéo de démonstration d’IoT suivante :
Les messages émis par l’historique des données sont mesurés sous la dimension des tarifs des messages.
Conditions préalables : Ressources et autorisations
L’historique des données nécessite les ressources suivantes :
- Instance Azure Digital Twins, avec une identité managée affectée par le système activée.
- Espace de noms Event Hubs contenant un hub d’événements.
- Cluster Azure Data Explorer contenant une base de données. Le cluster doit avoir un accès réseau public activé.
Ces ressources sont connectées au flux suivant :
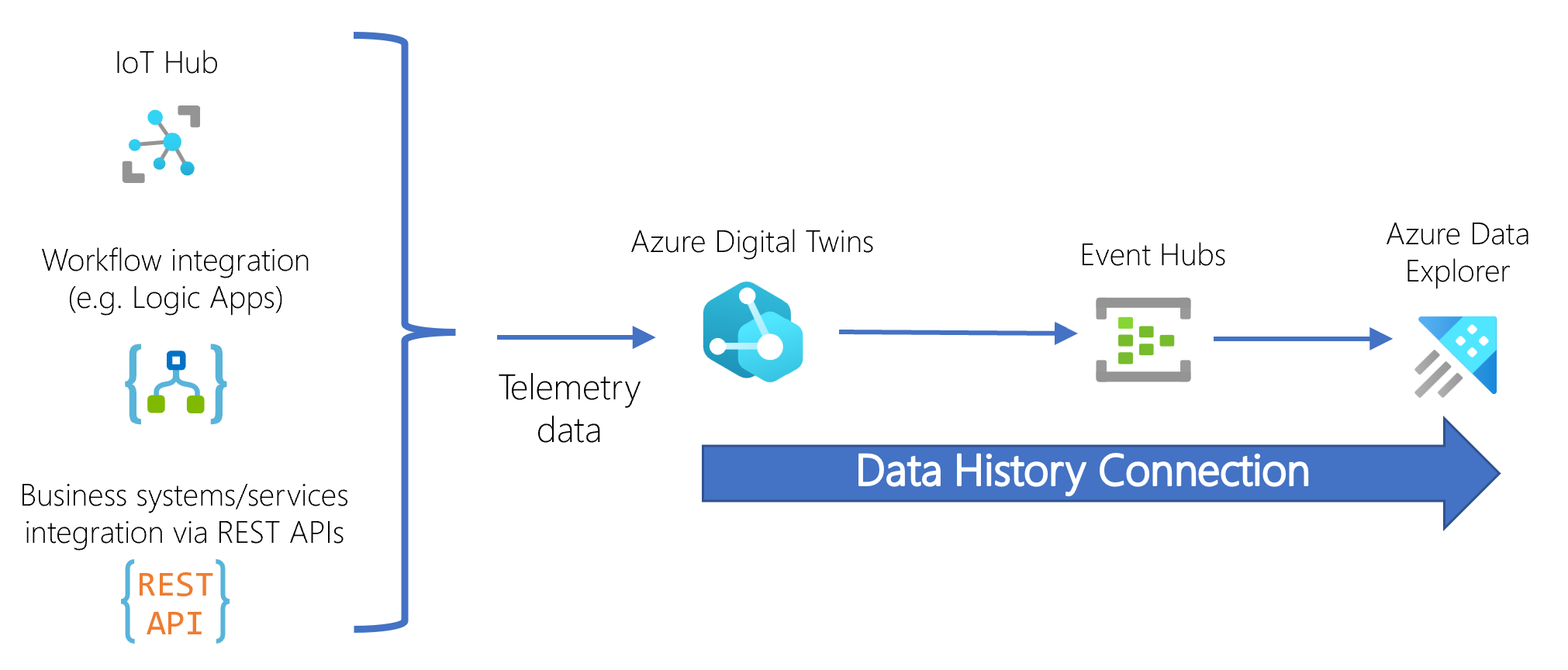
Lorsque le graphe de jumeau numérique est mis à jour, les informations transitent par le hub d’événements dans le cluster Azure Data Explorer cible, où Azure Data Explorer stocke les données sous forme d’enregistrement horodaté dans la table correspondante.
Lorsque vous utilisez l’historique des données, il est recommandé d’utiliser la version 2023-01-31 ou ultérieure des API. Avec la version 2022-05-31, seules les propriétés de jumeau (pas les événements de cycle de vie des jumeaux ou de cycle de vie des relations) peuvent être historisées. Avec les versions antérieures, l’historique des données n’est pas disponible.
Autorisations requises
Pour configurer une connexion d’historique des données, votre instance Azure Digital Twins doit disposer des autorisations suivantes permettant d’accéder aux ressources Event Hubs et Azure Data Explorer. Ces rôles permettent à Azure Digital Twins de configurer la base de données du hub d’événements et d’Azure Data Explorer à votre place (par exemple, en créant une table dans la base de données). Si nécessaire, ces autorisations peuvent être supprimées après la configuration de l’historique des données.
- Ressource Event Hubs : Propriétaire des données Azure Event Hubs
- Cluster Azure Data Explorer : Contributeur (limité à l’ensemble du cluster ou à une base de données spécifique)
- Attribution d’un principal de base de données Azure Data Explorer : Administrateur (limité à la base de données en cours d’utilisation)
Plus tard, votre instance Azure Digital Twins devra disposer de l’autorisation suivante sur la ressource Event Hubs pendant l’utilisation de l’historique des données : Expéditeur de données Azure Event Hubs (vous pouvez également choisir de conserver Propriétaire des données Azure Event Hubs dans la configuration de l’historique des données).
Ces autorisations peuvent être attribuées à l’aide d’Azure CLI ou du Portail Azure.
Si vous souhaitez restreindre l’accès réseau aux ressources impliquées dans l’historique des données (votre instance Azure Digital Twins, event hub ou cluster Azure Data Explorer), vous devez définir ces restrictions après avoir configuré la connexion d’historique des données. Pour plus d’informations sur ce processus, consultez Restreindre l’accès réseau aux ressources d’historique des données.
Créer et gérer la connexion d’historique des données
Cette section contient des informations sur la création, la mise à jour et la suppression d’une connexion d’historique des données.
Créer une connexion d’historique des données
Une fois que toutes les ressources et permissions sont configurées, vous pouvez utiliser Azure CLI, le portail Azure ou le SDK Azure Digital Twins pour créer une connexion d’historique des données entre elles. Le jeu de commandes CLI est az dt data-history.
La commande crée toujours une table pour les événements de propriété de jumeau historisés, qui peuvent utiliser le nom par défaut ou un nom personnalisé que vous fournissez. Les suppressions de propriétés de jumeau peuvent éventuellement être incluses dans ce tableau. Vous pouvez également fournir des noms de tables pour les événements de cycle de vie de relation et les événements de cycle de vie des jumeaux, et la commande crée des tables avec ces noms pour historiser ces types d’événements.
Pour obtenir des instructions pas à pas sur la configuration d’une connexion d’historique des données, consultez Créer une connexion d’historique des données.
Historique fourni par plusieurs instances Azure Digital Twins
Si vous le souhaitez, vous pouvez avoir plusieurs instances Azure Digital Twins historiser les mises à jour du même cluster Azure Data Explorer.
Chaque instance Azure Digital Twins a sa propre connexion d’historique des données qui cible le même cluster Azure Data Explorer. Dans le cluster, les instances peuvent envoyer leurs données de jumeau au choix à...
- un ensemble distinct de tables dans le cluster Azure Data Explorer.
- le même ensemble de tables dans le cluster Azure Data Explorer. Pour ce faire, spécifiez les mêmes noms de tables Azure Data Explorer lors de la création des connexions d’historique des données. Dans les schémas de la table d’historique des données, la
ServiceIdcolonne de chaque table contiendra l’URL de l’instance Azure Digital Twins source. Vous pouvez donc utiliser ce champ pour résoudre l’instance Azure Digital Twins émise chaque enregistrement dans des tables partagées.
Mettre à jour une connexion d’historique des données uniquement des propriétés
Avant février 2023, la fonctionnalité d’historique des données ne met à jour que les propriétés de jumeau historisées. Si vous disposez d’une connexion d’historique des données uniquement à partir de cette date, vous pouvez la mettre à jour pour historiser toutes les mises à jour de graphe vers Azure Data Explorer (y compris les propriétés de jumeau, les événements de cycle de vie des jumeaux et les événements de cycle de vie des relations).
Cela nécessite la création de tables dans votre cluster Azure Data Explorer pour les nouveaux types de mises à jour historisées (événements de cycle de vie des jumeaux et événements de cycle de vie des relations). Pour les événements de propriété de jumeau, vous pouvez décider si vous souhaitez que la nouvelle connexion continue à utiliser la même table à partir de votre connexion d’historique des données d’origine pour stocker les mises à jour des propriétés de jumeau à l’avenir, ou si vous souhaitez que la nouvelle connexion utilise un tout nouvel ensemble de tables. Ensuite, suivez les instructions ci-dessous pour votre préférence.
Si vous souhaitez continuer à utiliser votre table existante pour les mises à jour de propriétés de jumeau : utilisez les instructions de la section Créer une connexion d’historique des données pour créer une connexion d’historique des données avec les nouvelles fonctionnalités. Le nom de la connexion de l’historique des données peut être identique à celui d’origine ou à un autre nom. Utilisez les options de paramètre pour fournir de nouveaux noms pour les deux nouvelles tables de type d’événement et pour passer le nom de la table d’origine pour la table de mise à jour de la propriété jumeau. La nouvelle connexion remplacera l’ancienne et continuera à utiliser la table d’origine pour les futures mises à jour de propriétés de jumeau historisées.
Si vous souhaitez utiliser toutes les nouvelles tables : tout d’abord, supprimez votre connexion d’historique des données d’origine. Ensuite, utilisez les instructions de créer une connexion d’historique des données pour créer une connexion d’historique des données avec les nouvelles fonctionnalités. Le nom de la connexion de l’historique des données peut être identique à celui d’origine ou à un autre nom. Utilisez les options de paramètre pour fournir de nouveaux noms pour les trois tables de types d’événements.
Supprimer une connexion d’historique des données
Vous pouvez utiliser azure CLI, Portail Azure ou les API et kits de développement logiciel (SDK) Azure Digital Twins pour supprimer une connexion d’historique des données. La commande CLI est az dt data-history connection delete.
La suppression d’une connexion offre également la possibilité d’propre des ressources associées à la connexion d’historique des données (pour la commande CLI, le paramètre facultatif à ajouter est--clean true). Si vous utilisez cette option, la commande supprime les ressources dans Azure Data Explorer utilisées pour lier votre cluster à votre hub d’événements, y compris les connexions de données pour la base de données et les mappages d’ingestion associés à votre table. L’option « propre ressources up » ne supprime pas le hub d’événements et le cluster Azure Data Explorer utilisés pour la connexion d’historique des données.
Le propre up est une tentative optimale et nécessite que le compte exécutant la commande dispose d’une autorisation de suppression pour ces ressources.
Remarque
Si vous avez plusieurs connexions d’historique des données qui partagent le même hub d’événements ou le même cluster Azure Data Explorer, utilisez l’option « propre des ressources » tout en supprimant l’une de ces connexions peut perturber vos autres connexions d’historique des données qui s’appuient sur ces ressources.
Types de données et schémas
L’historique des données historise trois types d’événements de votre instance Azure Digital Twins dans Azure Data Explorer : événements de cycle de vie des relations, événements de cycle de vie des jumeaux et mises à jour des propriétés de jumeau (qui peuvent éventuellement inclure des suppressions de propriétés de jumeau). Chacun de ces types d’événements est stocké dans sa propre table à l’intérieur de la base de données Azure Data Explorer, ce qui signifie que l’historique des données conserve trois tables au total. Vous pouvez spécifier des noms personnalisés pour les tables lorsque vous configurez la connexion d’historique des données.
Le reste de cette section décrit en détail les trois tables Azure Data Explorer, y compris le schéma de données de chaque table.
Mises à jour des propriétés de jumeau
La table Azure Data Explorer pour les mises à jour de propriétés de jumeau a un nom par défaut d’AdtPropertyEvents. Vous pouvez conserver le nom par défaut lorsque vous créez la connexion ou spécifiez un nom de table personnalisé.
Les données de série chronologique pour les mises à jour des propriétés de jumeau sont stockées avec le schéma suivant :
| Attribut | Type | Description |
|---|---|---|
TimeStamp |
DateTime | Date et heure auxquelles le message de mise à jour de la propriété a été traité par Azure Digital Twins. Ce champ est défini par le système et n’est pas accessible en écriture aux utilisateurs. |
SourceTimeStamp |
DateTime | Propriété facultative accessible en écriture qui représente la date et l’heure auxquelles la mise à jour de la propriété a été observée. Cette propriété peut uniquement être écrite à l’aide de la version 2022-05-31 des API/SDK Azure Digital Twins et sa valeur doit respecter le format ISO 8601 de date et d’heure. Pour plus d’informations sur la mise à jour de cette propriété, consultez Mettre à jour le sourceTime d’une propriété. |
ServiceId |
String | ID d’instance de service du service Azure IoT qui journalise l’enregistrement |
Id |
String | ID du jumeau |
ModelId |
String | ID du modèle DTDL (DTMI) |
Key |
String | Nom de la propriété mise à jour |
Value |
dynamique | Valeur de la propriété mise à jour |
RelationshipId |
String | Lorsqu’une propriété définie sur une relation (par opposition aux jumeaux ou aux appareils) est mise à jour, ce champ est rempli avec l’ID de la relation. Lorsqu’une propriété de jumeau est mise à jour, ce champ est vide. |
RelationshipTarget |
String | Lorsqu’une propriété définie sur une relation (par opposition aux jumeaux ou aux appareils) est mise à jour, ce champ est rempli avec l’ID jumelle du jumeau ciblé par la relation. Lorsqu’une propriété de jumeau est mise à jour, ce champ est vide. |
Action |
Chaîne | Cette colonne existe uniquement si vous choisissez d’historiser les événements de suppression de propriété. Dans ce cas, cette colonne contient le type d’événement de propriété de jumeau (mise à jour ou suppression) |
Vous trouverez ci-dessous un exemple de table comprenant les mises à jour des propriétés d’un jumeau stockées dans Azure Data Explorer.
TimeStamp |
SourceTimeStamp |
ServiceId |
Id |
ModelId |
Key |
Value |
RelationshipTarget |
RelationshipID |
|---|---|---|---|---|---|---|---|---|
| 2022-12-15 20:23:29.8697482 | 2022-12-15 20:22:14.3854859 | dairyadtinstance.api.wcus.digitaltwins.azure.net | PasteurizationMachine_A01 | dtmi:assetGen:PasteurizationMachine;1 |
Sortie | 130 | ||
| 2022-12-15 20:23:39.3235925 | 2022-12-15 20:22:26.5837559 | dairyadtinstance.api.wcus.digitaltwins.azure.net | PasteurizationMachine_A01 | dtmi:assetGen:PasteurizationMachine;1 |
Sortie | 140 | ||
| 2022-12-15 20:23:47.078367 | 2022-12-15 20:22:34.9375957 | dairyadtinstance.api.wcus.digitaltwins.azure.net | PasteurizationMachine_A01 | dtmi:assetGen:PasteurizationMachine;1 |
Sortie | 130 | ||
| 2022-12-15 20:23:57.3794198 | 2022-12-15 20:22:50.1028562 | dairyadtinstance.api.wcus.digitaltwins.azure.net | PasteurizationMachine_A01 | dtmi:assetGen:PasteurizationMachine;1 |
Sortie | 123 |
Représentation de propriétés avec plusieurs champs
Vous pouvez avoir besoin de stocker une propriété avec plusieurs champs. Ces propriétés sont représentées avec un objet JSON dans l’attribut Value du schéma.
Par exemple, si vous représentez une propriété avec trois champs pour roll, pitch et yaw, l’historique des données stockera l’objet JSON suivant en tant que Value : {"roll": 20, "pitch": 15, "yaw": 45}.
Événements de cycle de vie des jumeaux
La table Azure Data Explorer pour les événements de cycle de vie des jumeaux a un nom personnalisé que vous spécifiez lors de la création de la connexion d’historique des données.
Les données de série chronologique pour les événements de cycle de vie des jumeaux sont stockées avec le schéma suivant :
| Attribut | Type | Description |
|---|---|---|
TwinId |
Chaîne | ID du jumeau |
Action |
Chaîne | Type d’événement de cycle de vie de jumeau (créer ou supprimer) |
TimeStamp |
Date/Heure | Date/heure du traitement de l’événement de cycle de vie des jumeaux par Azure Digital Twins. Ce champ est défini par le système et n’est pas accessible en écriture aux utilisateurs. |
ServiceId |
Chaîne | ID d’instance de service du service Azure IoT qui journalise l’enregistrement |
ModelId |
Chaîne | ID du modèle DTDL (DTMI) |
Vous trouverez ci-dessous un exemple de tableau de mises à jour de cycle de vie des jumeaux stockées dans Azure Data Explorer.
TwinId |
Action |
TimeStamp |
ServiceId |
ModelId |
|---|---|---|---|---|
| PasteurizationMachine_A01 | Créer | 2022-12-15 07:14:12.4160 | dairyadtinstance.api.wcus.digitaltwins.azure.net | dtmi:assetGen:PasteurizationMachine;1 |
| PasteurizationMachine_A02 | Créer | 2022-12-15 07:14:12.4210 | dairyadtinstance.api.wcus.digitaltwins.azure.net | dtmi:assetGen:PasteurizationMachine;1 |
| SaltMachine_C0 | Créer | 2022-12-15 07:14:12.5480 | dairyadtinstance.api.wcus.digitaltwins.azure.net | dtmi:assetGen:SaltMachine;1 |
| PasteurizationMachine_A02 | Supprimer | 2022-12-15 07:15:49.6050 | dairyadtinstance.api.wcus.digitaltwins.azure.net | dtmi:assetGen:PasteurizationMachine;1 |
Événements de cycle de vie des relations
La table Azure Data Explorer pour les événements de cycle de vie des relations a un nom personnalisé que vous spécifiez lors de la création de la connexion d’historique des données.
Les données de série chronologique pour les événements de cycle de vie des relations sont stockées avec le schéma suivant :
| Attribut | Type | Description |
|---|---|---|
RelationshipId |
Chaîne | ID de relation. Ce champ est défini par le système et n’est pas accessible en écriture aux utilisateurs. |
Name |
Chaîne | Nom de la relation. |
Action |
Type d’événement de cycle de vie de relation (créer ou supprimer) | |
TimeStamp |
Date/Heure | La date/heure de l’événement de cycle de vie de relation a été traité par Azure Digital Twins. Ce champ est défini par le système et n’est pas accessible en écriture aux utilisateurs. |
ServiceId |
ID d’instance de service du service Azure IoT qui journalise l’enregistrement | |
Source |
ID de jumeau source. Il s’agit de l’ID du jumeau où provient la relation. | |
Target |
ID de jumeau cible. Il s’agit de l’ID du jumeau où la relation arrive. |
Vous trouverez ci-dessous un exemple de tableau des mises à jour du cycle de vie des relations stockées dans Azure Data Explorer.
RelationshipId |
Name |
Action |
TimeStamp |
ServiceId |
Source |
Target |
|---|---|---|---|---|---|---|
| PasteurizationMachine_A01_feeds_Relationship0 | feeds | Créer | 2022-12-15 07:16:12.7120 | dairyadtinstance.api.wcus.digitaltwins.azure.net | PasteurizationMachine_A01 | SaltMachine_C0 |
| PasteurizationMachine_A02_feeds_Relationship0 | feeds | Créer | 2022-12-15 07:16:12.7160 | dairyadtinstance.api.wcus.digitaltwins.azure.net | PasteurizationMachine_A02 | SaltMachine_C0 |
| PasteurizationMachine_A03_feeds_Relationship0 | feeds | Créer | 2022-12-15 07:16:12.7250 | dairyadtinstance.api.wcus.digitaltwins.azure.net | PasteurizationMachine_A03 | SaltMachine_C1 |
| OsloFactory_contains_Relationship0 | contains | Supprimer | 2022-12-15 07:16:13.1780 | dairyadtinstance.api.wcus.digitaltwins.azure.net | OsloFactory | SaltMachine_C0 |
Latence de l’ingestion de bout en bout
L’historique des données Azure Digital Twins s’appuie sur le mécanisme d’ingestion existant fourni par Azure Data Explorer. Azure Digital Twins garantit que les événements de mise à jour de graphe sont mis à la disposition d’Azure Data Explorer en moins de deux secondes. Une latence supplémentaire peut être causée par l’ingestion des données par Azure Data Explorer.
Dans Azure Data Explorer, il existe deux méthodes pour ingérer des données : l’ingestion par lots et l’ingestion par streaming. Vous pouvez configurer ces méthodes d’ingestion pour des tables en fonction de vos besoins et du scénario d’ingestion de données.
L’ingestion par streaming présente la latence la plus faible. Toutefois, en raison de la surcharge de traitement, ce mode ne doit être utilisé que si moins de 4 Go de données sont ingérées par heure. L’ingestion par lots fonctionnera mieux si des taux d’ingestion de données élevés sont attendus. Par défaut, Azure Data Explorer utilise l’ingestion par lots. Le tableau suivant montre la latence de bout en bout la plus pessimiste qui peut être attendue :
| Configuration d’Azure Data Explorer | Latence de bout en bout attendue | Débit de données recommandé |
|---|---|---|
| Ingestion de streaming | <12 sec (<3 sec en général) | <4 Go/h |
| Ingestion par lots | Varie (de 12 secondes à 15 minutes, en fonction de la configuration) | >4 Go/h |
La suite de cette section contient des détails sur l’activation de chaque type d’ingestion.
Ingestion par lots (par défaut)
Sauf configuration contraire, Azure Data Explorer utilisera l’ingestion par lots. Avec les paramètres par défaut, les données ne peuvent être interrogées que dans les 5 à 10 minutes suivant la mise à jour d’un jumeau numérique. La stratégie d’ingestion peut être modifiée, de telle sorte que le traitement par lots se produise toutes les 10 secondes au minimum, ou toutes les 15 minutes au maximum. Pour modifier la stratégie d’ingestion, la commande suivante doit être exécutée dans la vue des requêtes Azure Data Explorer :
.alter table <table_name> policy ingestionbatching @'{"MaximumBatchingTimeSpan":"00:00:10", "MaximumNumberOfItems": 500, "MaximumRawDataSizeMB": 1024}'
Vérifiez que <table_name> est remplacé par le nom de la table qui a été configurée pour vous. MaximumBatchingTimeSpan doit être défini sur l’intervalle de traitement par lots préféré. L’entrée en application de la stratégie peut prendre de 5 à 10 minutes. Pour plus d’informations sur l’ingestion par lots, consultez : Commande de gestion des stratégies IngestionBatching Kusto.
Ingestion de streaming
L’activation de l’ingestion par streaming est un processus en deux étapes :
- Activez l’ingestion par streaming pour votre cluster. Vous n’aurez à effectuer cette action qu’une seule fois. (Avertissement : Cela aura un effet sur la quantité de stockage disponible pour le cache chaud et pourra ajouter des limitations supplémentaires). Pour obtenir des instructions, consultez Configurer l’ingestion en streaming dans votre cluster Azure Data Explorer.
- Ajoutez une stratégie d’ingestion par streaming pour la table souhaitée. Pour plus d’informations sur l’activation de l’ingestion par streaming pour votre cluster, consultez la documentation Azure Data Explorer : Commande de gestion des stratégies IngestionBatching Kusto.
Si vous souhaitez activer l’ingestion par streaming pour votre table d’historique des données Azure Digital Twins, vous devez exécuter la commande suivante dans le volet de requête Azure Data Explorer :
.alter table <table_name> policy streamingingestion enable
Vérifiez que <table_name> est remplacé par le nom de la table qui a été configurée pour vous. L’entrée en application de la stratégie peut prendre de 5 à 10 minutes.
Visualiser les propriétés historisées
Azure Digital Twins Explorer, outil de développement permettant de visualiser et d’interagir avec les données Azure Digital Twins, offre une fonctionnalité d’explorateur d’historique des données pour afficher les propriétés historisées au fil du temps dans un graphique ou une table. Cette fonctionnalité est également disponible dans 3D Scenes Studio, un environnement 3D immersif pour donner à Azure Digital Twins le contexte visuel des ressources 3D.

Pour plus d’informations sur l’utilisation de l’Explorateur d’historique des données, consultez Valider et explorer les propriétés historisées.
Remarque
Si vous rencontrez des problèmes lors de la sélection d’une propriété dans l’expérience de l’Explorateur d’historique des données visuels, cela peut signifier qu’il existe une erreur dans un modèle dans votre instance. Par exemple, avoir des valeurs d’énumération non uniques dans les attributs d’un modèle interrompt cette fonctionnalité de visualisation. Si cela se produit, passez en revue vos définitions de modèle et vérifiez que toutes les propriétés sont valides.
Étapes suivantes
Une fois que les données du jumeau ont été placées dans l’historique Azure Data Explorer, vous pouvez utiliser le plug-in de requête Azure Digital Twins pour Azure Data Explorer afin d’interroger les données. Pour plus d’informations sur le plug-in, consultez : Interroger des données avec le plug-in Azure Data Explorer.
Vous pouvez également approfondir l’historique des données avec des instructions de création et un exemple de scénario : Créer une connexion d’historique des données.