Tutoriel : Migrer SQL Server vers Azure SQL Managed Instance hors connexion dans Azure Data Studio
Vous pouvez utiliser Azure Database Migration Service et l’extension de migration Azure SQL dans Azure Data Studio pour migrer des bases de données d’une instance locale SQL Server vers Azure SQL Managed Instance hors connexion et avec un temps d’arrêt minimal.
Pour connaître les méthodes de migration de base de données qui peuvent nécessiter une configuration manuelle, consultez Migration d’une instance de SQL Server Azure SQL Managed Instance.
Dans ce tutoriel, vous apprenez à migrer la base de données AdventureWorks d’une instance locale de SQL Server vers Azure SQL Managed Instance à l’aide d’Azure Data Studio et Database Migration Service. Ce tutoriel se concentre sur le mode de migration hors connexion, qui prend en compte un temps d’arrêt acceptable durant le processus de migration.
Dans ce tutoriel, vous allez apprendre à :
- Ouvrez l’Assistant Migration vers Azure SQL dans Azure Data Studio.
- Exécuter une évaluation de vos bases de données SQL Server sources
- Collecter les données de performances de votre instance SQL Server source
- Obtenez une recommandation sur la référence SKU Azure SQL Managed Instance la mieux adaptée à votre charge de travail
- Spécifier les détails de votre instance SQL Server source, de l’emplacement de sauvegarde et de l’instance cible d’Azure SQL Managed Instance
- Créer une instance Azure Database Migration Service
- Démarrer votre migration et suivre sa progression jusqu’à son achèvement
Conseil
Dans Azure Database Migration Service, vous pouvez migrer vos bases de données hors connexion ou pendant qu’elles sont en ligne. Lors d’une migration hors connexion, le temps d’arrêt de l’application commence quand la migration commence. Pour limiter le temps d’arrêt au temps nécessaire pour basculer vers le nouvel environnement après la migration, utilisez une migration en ligne. Nous vous recommandons de tester une migration hors connexion pour déterminer si le temps d’arrêt est acceptable. Si le temps d’arrêt attendu n’est pas acceptable, effectuez une migration en ligne.
Ce tutoriel décrit une migration hors connexion de SQL Server vers Azure SQL Managed Instance. Pour une migration en ligne, consultez Migrer SQL Server vers Azure SQL Managed Instance en ligne à l’aide d’Azure Data Studio.
Prérequis
Avant de commencer le tutoriel :
Installez l’extension de migration Azure SQL à partir de la place de marché Azure Data Studio.
Disposer d’un compte Azure affecté à l’un des rôles intégrés suivants :
- Contributeur pour l’instance cible Azure SQL Managed Instance et pour le compte de stockage où vous chargez vos fichiers de sauvegarde de base de données à partir d’un partage réseau SMB (Server Message Block)
- Rôle lecteur pour les groupes de ressources Azure qui contiennent l’instance cible Azure SQL Managed Instance ou votre compte de stockage Azure
- Rôle propriétaire ou contributeur pour l’abonnement Azure (obligatoire si vous créez une instance Database Migration Service)
En guise d’alternative à l’utilisation de l’un de ces rôles intégrés, vous pouvez attribuer un rôle personnalisé.
Important
Un compte Azure n’est requis que lorsque vous configurez les étapes de migration. Un compte Azure n’est pas nécessaire pour l’évaluation ou pour afficher les recommandations Azure dans l’Assistant Migration dans Azure Data Studio.
Créez une instance cible d’Azure SQL Managed Instance.
Assurez-vous que les connexions que vous utilisez pour connecter l’instance source SQL Server sont membres du rôle serveur SYSADMIN ou disposent de l’autorisation CONTROL SERVER.
Fournissez un partage réseau SMB, un partage de fichiers de compte Stockage Azure ou un conteneur d’objets blob de compte Stockage Azure contenant vos fichiers de sauvegarde complète de base de données et de sauvegarde des journaux de transactions suivants. Database Migration Service utilise l’emplacement de sauvegarde pendant la migration de la base de données.
Important
- L’extension de migration Azure SQL pour Azure Data Studio n’effectue pas de sauvegardes de base de données et n’initie aucune sauvegarde de base de données en votre nom. Au lieu de cela, le service utilise des fichiers de sauvegarde de base de données existants pour la migration.
- Si vos fichiers de sauvegarde de base de données sont fournis sur un partage réseau SMB, vous devez créer un compte Stockage Azure qui permet au service Database Migration Service de charger les fichiers de sauvegarde de base de données et de les utiliser pour la migration. Veillez à créer le compte de stockage Azure dans la même région que celle où vous créez votre instance de Database Migration Service.
- Vous pouvez écrire chaque sauvegarde dans un fichier de sauvegarde distinct ou dans plusieurs fichiers de sauvegarde. L’ajout de plusieurs sauvegardes, comme des journaux de transaction et complets à un seul support de sauvegarde n’est pas pris en charge.
- Vous pouvez fournir des sauvegardes compressées pour réduire le risque de rencontrer des problèmes de migration de sauvegardes volumineuses.
Assurez-vous que le compte de service exécutant l’instance source SQL Server dispose des autorisations en lecture et en écriture sur le partage réseau SMB qui contient les fichiers de sauvegarde de base de données.
Si vous migrez une base de données protégée par un chiffrement TDE (Transparent Data Encryption), le certificat de l’instance source de SQL Server doit être migré vers l’instance managée cible avant la restauration de la base de données. Pour plus d’informations sur la migration des bases de données avec TDE activé, consultez Tutoriel : Migrer des bases de données avec TDE (Transparent Data Encryption) activé (préversion) vers Azure SQL dans Azure Data Studio.
Conseil
Si votre base de données contient des données sensibles protégées par la fonctionnalité Always Encrypted, le processus de migration effectue automatiquement la migration de vos clés Always Encrypted vers instance managée cible.
Si vos sauvegardes de base de données se trouvent dans un partage de fichiers réseau, fournissez un ordinateur sur lequel installer l’IR auto-hébergé pour accéder et migrer les sauvegardes de base de données. L’Assistant Migration vous fournit le lien de téléchargement et les clés d’authentification pour télécharger et installer votre IR auto-hébergé.
En prévision de la migration, vérifiez que les règles de pare-feu sortantes et les noms de domaine suivants sont activés sur l’ordinateur où vous installez le runtime d’intégration autohébergé :
Noms de domaine Port sortant Description Cloud public : {datafactory}.{region}.datafactory.azure.net
ou*.frontend.clouddatahub.net
Azure Government :{datafactory}.{region}.datafactory.azure.us
Microsoft Azure géré par 21Vianet :{datafactory}.{region}.datafactory.azure.cn443 Requis par l’IR auto-hébergé pour se connecter à Database Migration Service.
Pour une fabrique de données nouvellement créée dans un cloud public, recherchez le nom de domaine complet (FQDN) de votre clé de runtime d’intégration auto-hébergée, au format{datafactory}.{region}.datafactory.azure.net.
Pour une fabrique de données existante, si vous ne voyez pas le nom de domaine complet dans votre clé d’intégration auto-hébergée, utilisez*.frontend.clouddatahub.netà la place.download.microsoft.com443 Exigé par le runtime d’intégration auto-hébergé pour télécharger les mises à jour. Si vous avez désactivé la mise à jour automatique, vous pouvez ignorer la configuration de ce domaine. *.core.windows.net443 Utilisé par l’IR auto-hébergé qui se connecte au compte de stockage Azure pour charger les sauvegardes de base de données à partir de votre partage réseau Conseil
Si vos fichiers de sauvegarde de base de données sont déjà fournis dans un compte de stockage Azure, l’IR auto-hébergé n’est pas requis pendant le processus de migration.
Lorsque vous utilisez l’IR auto-hébergé, assurez-vous que l’ordinateur sur lequel le runtime est installé peut se connecter à l’instance SQL Server et au partage de fichiers réseau source où se trouvent les fichiers de sauvegarde.
Activez le port de sortie 445 pour autoriser l’accès au partage de fichiers réseau. Pour plus d’informations, consultez Recommandations relatives à l’utilisation d’un runtime d’intégration auto-hébergé.
Si vous utilisez Database Migration Service pour la première fois, assurez-vous que le fournisseur de ressources Microsoft.DataMigration est inscrit dans votre abonnement. Vous pouvez terminer les étapes pour inscrire le fournisseur de ressources.
Ouvrez l’Assistant Migration vers Azure SQL dans Azure Data Studio.
Pour ouvrir l’Assistant Migrer vers Azure SQL :
Dans Azure Data Studio, accédez à Connexions. Sélectionnez et connectez-vous à votre instance locale SQL Server. Vous pouvez également vous connecter à SQL Server sur une machine virtuelle Azure.
Cliquez avec le bouton droit sur la connexion au serveur, puis sélectionnez Gérer.
Dans le menu du serveur, sous Général, sélectionnez Migration Azure SQL.
Dans le tableau de bord de l’extension de migration Azure SQL, sélectionnez Migrer vers Azure SQL pour ouvrir l’Assistant Migration.
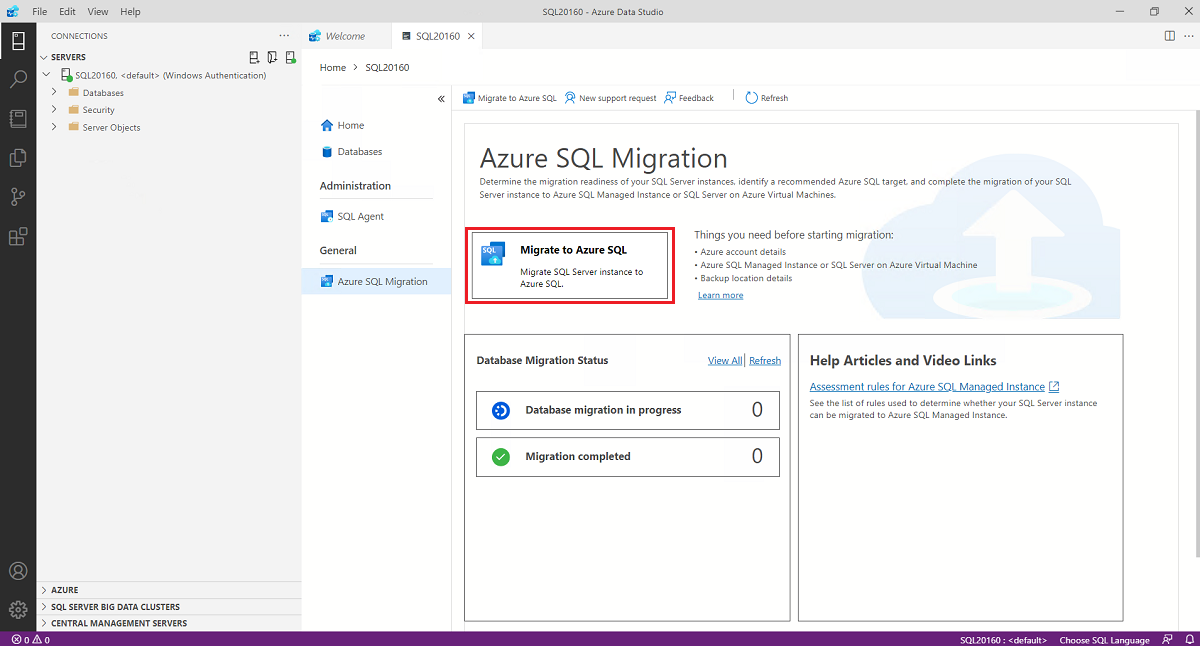
Sur la première page de l’Assistant, démarrez une nouvelle session ou reprenez une session précédemment enregistrée.
Exécuter une évaluation de base de données, collecter les données de performances et obtenir les recommandations Azure
Dans Étape 1 : Bases de données à évaluer dans l’Assistant Migrer vers Azure SQL, sélectionnez les bases de données à évaluer. Ensuite, sélectionnez Suivant.
Dans Étape 2 : Résultats et recommandations de l’évaluation, effectuez les étapes suivantes :
- Dans Choisissez votre cible Azure SQL, sélectionnez Azure SQL Managed Instance.
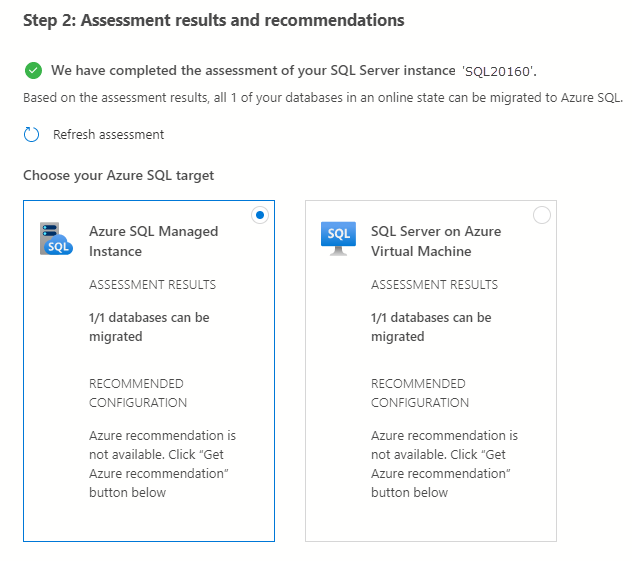
Sélectionnez Afficher/Sélectionner pour afficher les résultats de l’évaluation.
Dans les résultats de l’évaluation, sélectionnez la base de données, puis passez en revue le rapport d’évaluation pour vous assurer qu’aucun problème n’a été détecté.
Sélectionnez Obtenir la recommandation Azure pour ouvrir le volet de recommandations.
Sélectionnez Collecter les données de performance maintenant. Choisissez un dossier sur votre ordinateur local pour stocker les journaux de performances, puis sélectionnez Démarrer.
Azure Data Studio collecte les données de performances jusqu’à ce que vous arrêtiez la collecte ou fermiez Azure Data Studio.
Après 10 minutes, Azure Data Studio indique qu’une recommandation est disponible pour Azure SQL Managed Instance. Une fois la première recommandation générée, vous pouvez sélectionner Redémarrer la collecte de données pour continuer à exécuter le processus de collecte des données et affiner les recommandations SKU. Une évaluation étendue est particulièrement utile si vos modèles d’utilisation varient au fil du temps.
Dans la cible Azure SQL Managed Instance sélectionnée, sélectionnez Afficher les détails pour ouvrir le rapport de recommandation de référence SKU détaillé :
Dans Passer en revue les recommandations Azure SQL Managed Instance, passez en revue la recommandation. Pour enregistrer une copie de la recommandation, cochez la case Enregistrer le rapport de recommandations.
Sélectionnez Fermer pour fermer le sous-onglet de recommandations.
Sélectionnez Suivant pour poursuivre la migration de votre base de données dans l’Assistant.
Configurer les paramètres de migration
Dans Étape 3 : Cible Azure SQL dans l’Assistant Migrer vers Azure SQL, sélectionnez votre compte Azure, votre abonnement Azure, la région ou l’emplacement Azure, ainsi que le groupe de ressources qui contient l’instance Azure SQL Managed Instance cible. Ensuite, sélectionnez Suivant.
Dans Étape 4 : Mode de migration, sélectionnez Migration hors connexion, puis Suivant.
Notes
En mode de migration hors connexion, la base de données SQL Server source ne doit pas être utilisée pour l’activité d’écriture pendant que les sauvegardes de base de données sont restaurées sur l’instance Azure SQL Managed Instance cible. Le temps d’arrêt des applications doit être pris en compte jusqu’à la fin de la migration.
Dans Étape 5 : Configuration de la source de données, sélectionnez l’emplacement de vos sauvegardes de base de données. Vos sauvegardes de base de données peuvent se trouver sur un partage réseau local ou dans un conteneur d’objets blob de stockage Azure.
Pour les sauvegardes situées sur un partage réseau, entrez ou sélectionnez les informations suivantes :
Nom Description Informations d’identification de la source - Nom d’utilisateur Informations d’identification (authentification Windows et SQL) permettant de se connecter à l’instance source de SQL Server et de valider les fichiers de sauvegarde. Informations d’identification de la source - Mot de passe utilisateur Informations d’identification (authentification Windows et SQL) permettant de se connecter à l’instance source de SQL Server et de valider les fichiers de sauvegarde. Emplacement de partage réseau qui contient les sauvegardes Emplacement de partage réseau qui contient les fichiers de sauvegarde complète et de sauvegarde des journaux de transactions. Les fichiers non valides ou les fichiers de sauvegarde du partage réseau qui n’appartiennent pas au jeu de sauvegarde valide sont automatiquement ignorés durant le processus de migration. Compte d’utilisateur Windows avec accès en lecture à l’emplacement du partage réseau Informations d’identification Windows (nom d’utilisateur) du compte ayant accès en lecture au partage réseau pour récupérer les fichiers de sauvegarde. Mot de passe Informations d’identification Windows (Mot de passe) du compte ayant accès en lecture au partage réseau pour récupérer les fichiers de sauvegarde. Nom de la base de données cible Vous pouvez modifier le nom de la base de données cible pendant le processus de migration. Détails du compte de stockage Groupe de ressources et compte de stockage où les fichiers de sauvegarde seront chargés. Vous n’avez pas besoin de créer un conteneur. Database Migration Service crée automatiquement un conteneur d’objets blob dans le compte de stockage spécifié pendant le processus de chargement. Pour les sauvegardes stockées dans un conteneur d’objets blob du Stockage Azure, entrez ou sélectionnez les informations suivantes :
Nom Description Nom de la base de données cible Vous pouvez modifier le nom de la base de données cible pendant le processus de migration. Détails du compte de stockage Groupe de ressources, compte de stockage et conteneur où se trouvent les fichiers de sauvegarde. Dernier fichier de sauvegarde Nom de fichier de la dernière sauvegarde de la base de données que vous migrez. Important
Si la fonctionnalité de contrôle de bouclage est activée et que l’instance SQL Server source et le partage de fichiers se trouvent sur le même ordinateur, la source ne peut pas accéder au partage de fichiers à l’aide d’un FQDN. Pour résoudre ce problème, désactivez la fonctionnalité du contrôle de bouclage.
L’extension de migration Azure SQL pour Azure Data Studio n’exige plus de configurations spécifiques au niveau des paramètres réseau de votre compte Stockage Azure pour la migration de vos bases de données SQL Server vers Azure. Cependant, selon l’emplacement de sauvegarde de votre base de données et la configuration souhaitée des paramètres réseau du compte de stockage, quelques étapes sont nécessaires pour permettre à vos ressources d’accéder au compte Stockage Azure. Consultez le tableau suivant pour découvrir les différents scénarios de migration et les différentes configurations réseau :
Scénario Partage réseau SMB Conteneur de compte Stockage Azure Activé à partir de tous les réseaux Aucune étape supplémentaire Aucune étape supplémentaire Activé à partir de réseaux virtuels et d’adresses IP sélectionnés Voir 1a Voir 2a Activé à partir de réseaux virtuels et d’adresses IP sélectionnés + point de terminaison privé Voir 1b Voir 2b 1a – Configuration réseau de Stockage Blob Azure
Si votre runtime d’intégration auto-hébergé (SHIR) est installé sur une machine virtuelle Azure, consultez la section 1b – Configuration réseau de Stockage Blob Azure. Si votre runtime d'intégration auto-hébergé (SHIR) est installé sur votre réseau local, vous devez ajouter votre adresse IP cliente de la machine d’hébergement dans votre compte Stockage Azure comme suit :
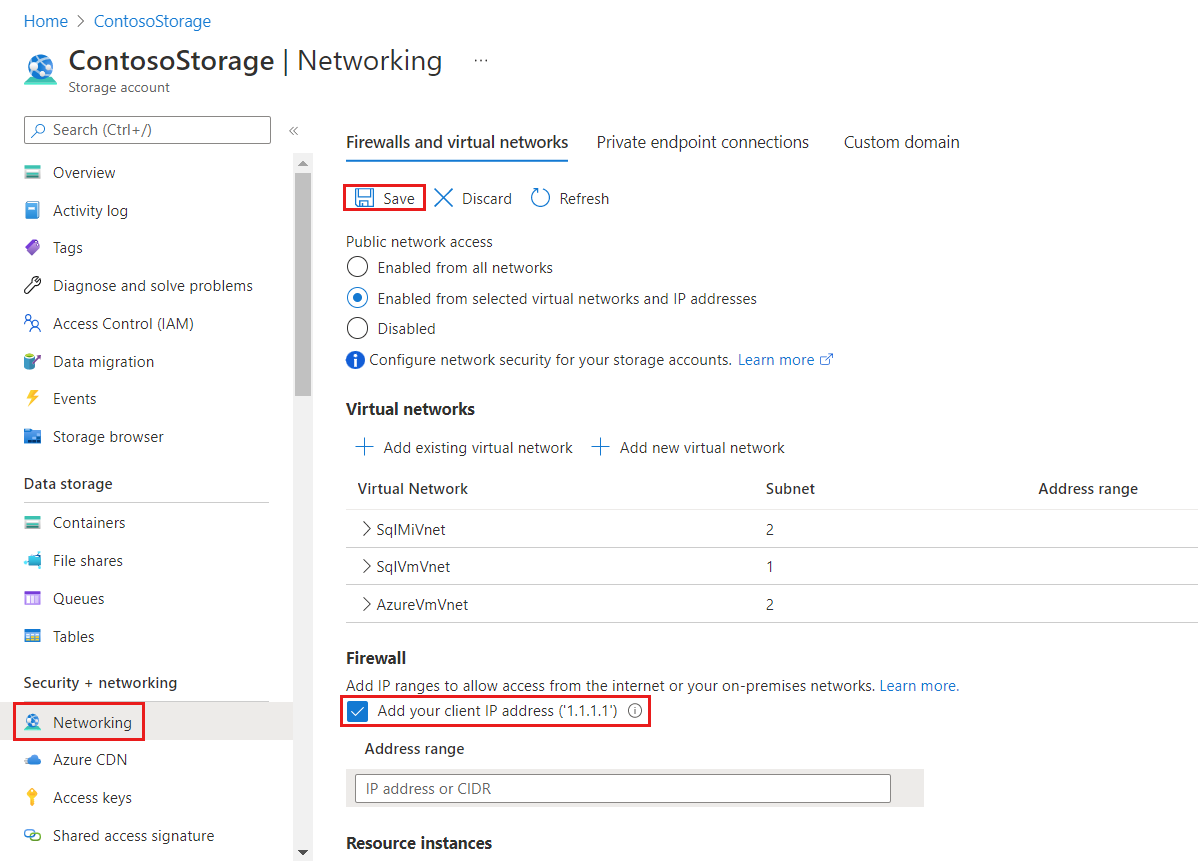
Pour appliquer cette configuration spécifique, connectez-vous au portail Azure à partir de la machine SHIR, ouvrez la configuration du compte Stockage Azure, sélectionnez Réseau, puis cochez la case Ajouter l’adresse IP de votre client. Sélectionnez Enregistrer pour rendre la modification persistante. Pour les étapes restantes, consultez la section 2a – Configuration réseau de Stockage Blob Azure (point de terminaison privé).
1b – Configuration réseau de Stockage Blob Azure
Si votre SHIR est hébergé sur une machine virtuelle Azure, vous devez ajouter le réseau virtuel de la machine virtuelle au compte Stockage Azure, car la machine virtuelle a une adresse IP non publique qui ne peut pas être ajoutée à la section Plage d’adresses IP.
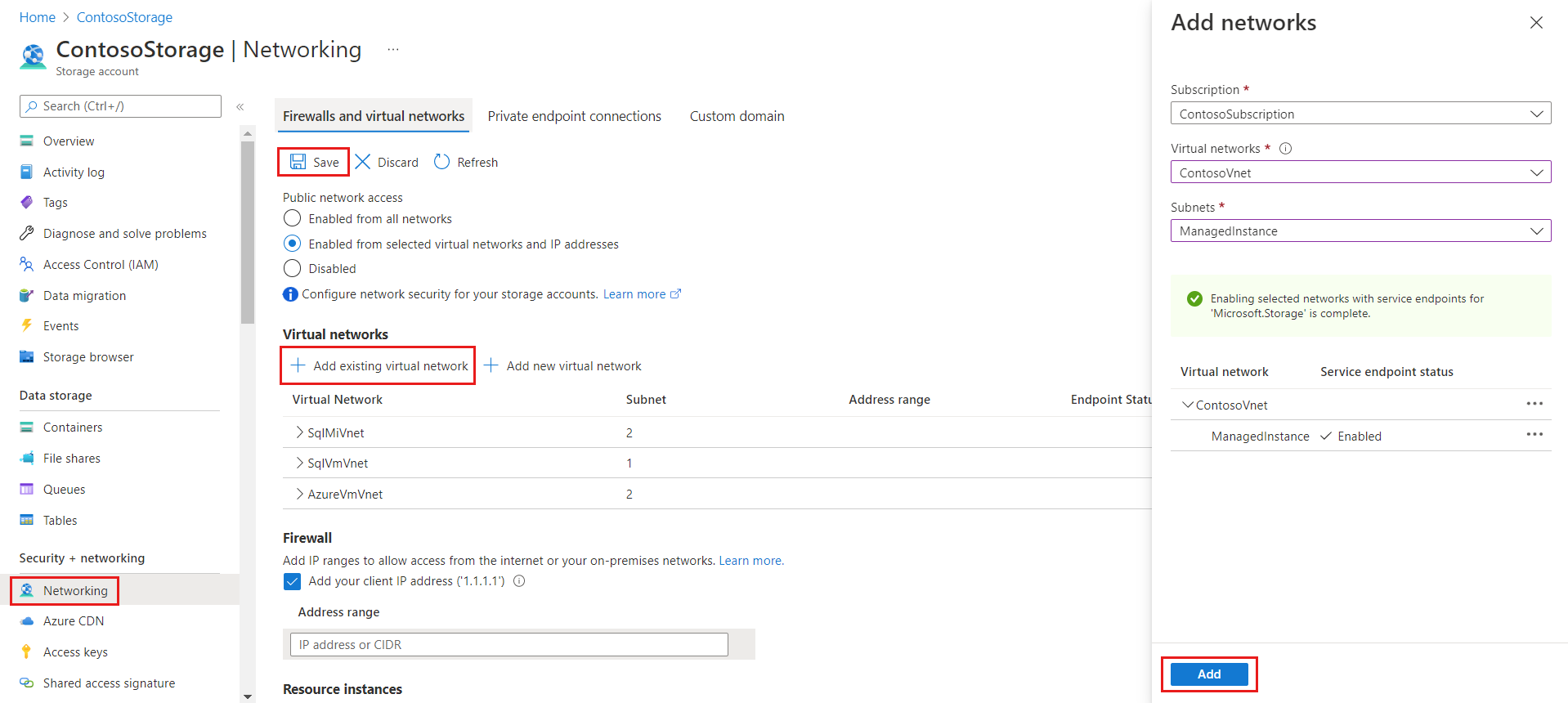
Pour appliquer cette configuration spécifique, localisez votre compte Stockage Azure. Ensuite, dans le panneau Stockage des données, sélectionnez Réseau, puis cochez la case Ajouter un réseau virtuel existant. Dans le nouveau panneau qui s’ouvre, sélectionnez l’abonnement, le réseau virtuel et le sous-réseau de la machine virtuelle Azure qui héberge le runtime d’intégration. Vous trouverez ces informations dans la page Vue d’ensemble de la machine virtuelle Azure. Il se peut que le sous-réseau indique Point de terminaison de service obligatoire. Si c’est le cas, sélectionnez Activer. Une fois que tout est prêt, enregistrez les mises à jour. Pour les étapes restantes nécessaires, reportez-vous à la section 2a – Configuration réseau de Stockage Blob Azure (point de terminaison privé).
2a – Configuration réseau de Stockage Blob Azure (point de terminaison privé)
Si vos sauvegardes sont placées directement dans un conteneur Stockage Azure, toutes les étapes précédentes sont inutiles, car aucun runtime d’intégration ne communique avec le compte Stockage Azure. Cependant, il nous reste encore à vérifier que l’instance cible de SQL Server peut communiquer avec le compte Stockage Azure pour restaurer les sauvegardes à partir du conteneur. Pour appliquer cette configuration spécifique, suivez les instructions de la section 1b – Configuration réseau de Stockage Blob Azure, en spécifiant le réseau virtuel de l’instance SQL cible au moment de compléter la fenêtre contextuelle « Ajouter un réseau virtuel existant ».
2b – Configuration réseau de Stockage Blob Azure (point de terminaison privé)
Si vous avez configuré un point de terminaison privé sur votre compte Stockage Azure, suivez les étapes décrites dans la section 2a – Configuration réseau de Stockage Blob Azure (point de terminaison privé). Cependant, vous devez sélectionner le sous-réseau du point de terminaison privé, et pas seulement le sous-réseau cible SQL Server. Vérifiez que le point de terminaison privé est hébergé dans le même réseau virtuel que l’instance cible de SQL Server. Si ce n’est pas le cas, créez un autre point de terminaison privé en suivant le processus de la section Configuration du compte Stockage Azure.
Créer une instance de Database Migration Service
Dans Étape 6 : Azure Database Migration Service dans l’Assistant Migrer vers Azure SQL, créez une instance Azure Database Migration Service ou réutilisez une instance existante que vous avez créée précédemment.
Notes
Si vous avez précédemment créé une instance Database Migration Service à l’aide du Portail Azure, vous ne pouvez pas réutiliser l’instance dans l’Assistant de migration dans Azure Data Studio. Vous pouvez réutiliser une instance uniquement si vous l’avez créée à l’aide d’Azure Data Studio.
Utiliser une instance existante de Database Migration Service
Pour utiliser une instance existante de Database Migration Service :
Dans Groupe de ressources, sélectionnez le groupe de ressources qui contient une instance existante de Database Migration Service.
Dans Azure Database Migration Service, sélectionnez une instance existante de Database Migration Service qui se trouve dans le groupe de ressources sélectionné.
Sélectionnez Suivant.
Créer une instance de Database Migration Service
Pour créer une instance de Database Migration Service :
Dans Groupe de ressources, créez un groupe de ressources pour contenir une nouvelle instance de Database Migration Service.
Sous Azure Database Migration Service, sélectionnez Créer.
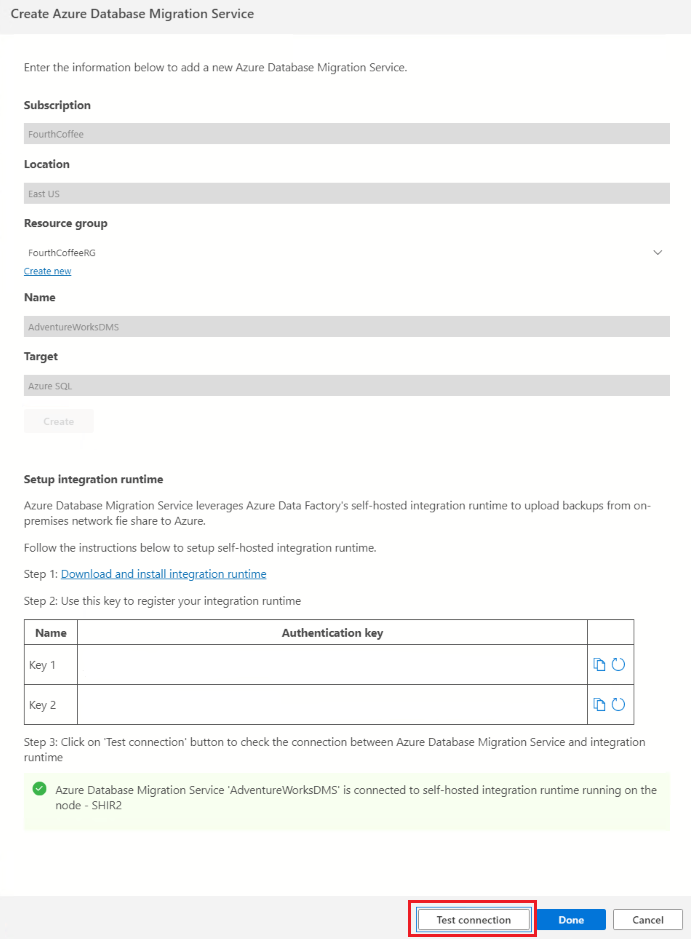
Dans Créer Azure Database Migration Service, entrez un nom pour votre instance de Database Migration Service, puis sélectionnez Créer.
Sous Configurer le runtime d’intégration, effectuez les étapes suivantes :
Sélectionnez le lien Télécharger et installer le runtime d’intégration pour ouvrir le lien de téléchargement dans un navigateur web. Téléchargez le runtime d’intégration, puis installez-le sur un ordinateur qui remplit les conditions préalables pour se connecter à l’instance SQL Server source.
Une fois l’installation effectuée, le Gestionnaire de configuration de Microsoft Integration Runtime s’ouvre automatiquement pour débuter le processus d’inscription.
Dans le tableau Clé d’authentification, copiez l’une des clés d’authentification fournies dans l’Assistant et collez-la dans Azure Data Studio. Si la clé d’authentification est valide, une icône de contrôle verte apparaît dans le Gestionnaire de configuration Integration Runtime. Une coche verte indique que vous pouvez vous Inscrire.
Après avoir enregistré le runtime d’intégration auto-hébergé, fermez Microsoft Integration Runtime Configuration Manager.
Notes
Pour plus d’informations sur l’utilisation du runtime d’intégration auto-hébergé, consultez Créer et configurer un runtime d’intégration auto-hébergé.
Dans Créer Azure Database Migration Service dans Azure Data Studio, sélectionnez Tester la connexion pour valider que l’instance de Database Migration Service nouvellement créée est connectée au runtime d’intégration auto-hébergé nouvellement enregistré.
Revenez à l’Assistant Migration dans Azure Data Studio.
Démarrer la migration de base de données
Dans Étape 7 : Résumé de l’Assistant Migrer vers Azure SQL, passez en revue la configuration que vous avez créée, puis sélectionnez Démarrer la migration pour démarrer la migration de base de données.
Surveiller la migration de base de données
Dans Azure Data Studio, dans le menu du serveur, sous Général, sélectionnez Migration Azure SQL pour accéder au tableau de bord de vos migrations Azure SQL.
Sous État de la migration de base de données, vous pouvez suivre les migrations en cours, terminées et ayant échoué (le cas échéant), ou vous pouvez afficher toutes les migrations de base de données.
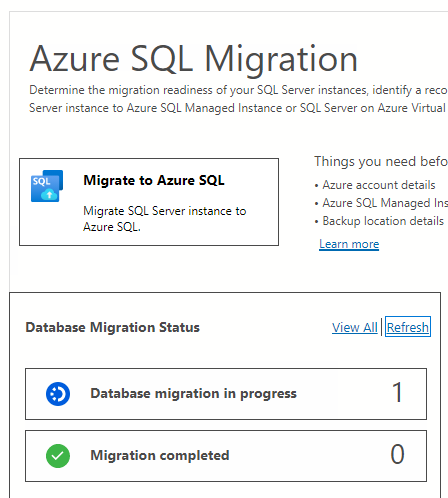
Sélectionnez Migrations de base de données en cours pour afficher les migrations actives.
Pour obtenir plus d’informations sur une migration spécifique, sélectionnez le nom de la base de données.
Le volet des détails de la migration affiche les fichiers de sauvegarde et leur état correspondant :
Statut Description Arrivé Le fichier de sauvegarde est arrivé à l’emplacement de sauvegarde de la source et a été validé. Chargement Le runtime d’intégration charge le fichier de sauvegarde sur le compte de stockage Azure. Téléchargé Le fichier de sauvegarde a été chargé sur le compte de stockage Azure. Restoring Le service restaure le fichier de sauvegarde sur Azure SQL Managed Instance. Restaurée Le fichier de sauvegarde a été correctement restauré sur Azure SQL Managed Instance. Opération annulée Le processus de migration a été annulé. Ignoré Le fichier de sauvegarde a été ignoré, car il n’appartient à aucune chaîne de sauvegarde de base de données valide.
Une fois toutes les sauvegardes de base de données restaurées sur l’instance Azure SQL Managed Instance, un basculement de migration automatique est lancé par Database Migration Service pour garantir que la base de données migrée est prête à être utilisée. L’état de la migration passe de En cours à Réussi.
Important
Après la migration, la disponibilité de SQL Managed Instance avec le niveau de service Critique pour l’entreprise peut prendre beaucoup plus de temps que la disponibilité du niveau de service Usage général, car trois réplicas secondaires doivent être amorcés pour le groupe de haute disponibilité Always On. La durée de cette opération dépend de la taille des données. Pour plus d’informations, consultez Durée des opérations de gestion.
Limites
La migration vers Azure SQL Managed Instance à l’aide de l’extension Azure SQL pour Azure Data Studio présente les limitations suivantes :
- Si vous migrez une base de données unique, les sauvegardes de base de données doivent être placées dans une structure de fichiers plats à l’intérieur d’un dossier de base de données (contenant le dossier racine conteneur), et les dossiers ne peuvent pas être imbriqués, car cela n’est pas pris en charge.
- Lors de la migration de plusieurs bases de données à l’aide du même conteneur de Stockage Blob Azure, vous devez placer les fichiers de sauvegarde de différentes bases dans des dossiers distincts dans le conteneur.
- Le remplacement des bases de données existantes à l’aide de DMS dans votre Azure SQL Managed Instance cible n’est pas pris en charge.
- DMS ne prend pas en charge la configuration de la haute disponibilité et récupération d’urgence sur votre cible pour qu’elle corresponde à la topologie source.
- Les objets serveur suivants ne sont pas pris en charge :
- travaux de l'Agent SQL Server
- Informations d'identification
- Packages SSIS
- Audit de serveur
- Vous ne pouvez pas utiliser un runtime d’intégration auto-hébergé existant créé à partir d’Azure Data Factory pour les migrations de base de données avec DMS. Au départ, le runtime d’intégration auto-hébergé doit être créé à l’aide de l’extension de migration Azure SQL dans Azure Data Studio, et il peut être réutilisé pour des migrations de base de données supplémentaires.
- Un travail LRS unique (créé par DMS) peut s’exécuter pendant un maximum de 30 jours. Lorsque cette période arrive à expiration, la tâche est automatiquement annulée et votre base de données cible est automatiquement supprimée.
- Si vous recevez l’erreur suivant :
Memory-optimized filegroup must be empty in order to be restored on General Purpose tier of SQL Database Managed Instance. Ce problème est dû à sa conception. Hekaton (également connu comme SQL Server OLTP en mémoire) n’est pas pris en charge sur un niveau d’usage général d’Instance gérée Azure SQL. Pour poursuivre la migration, une méthode consiste à effectuer une mise à niveau vers le niveau critique pour l’entreprise qui prend en charge Hekaton. Une autre méthode consiste à veiller à ce que la base de données source ne l’utilise pas quand l’Instance gérée Azure SQL est en usage général.
Étapes suivantes
- Suivez un guide de démarrage rapide pour migrer une base de données vers SQL Managed Instance à l’aide de la commande T-SQL RESTORE.
- En savoir plus sur SQL Managed Instance.
- Découvrez comment connecter des applications à SQL Managed Instance.
- Pour résoudre les problèmes, consultez Problèmes connus.