Scale-out d’Azure Analysis Services
La montée en charge permet de distribuer les requêtes des clients sur plusieurs réplicas de requête dans un pool de requêtes, ce qui diminue les temps de réponse quand les charges de travail de requêtes sont importantes. Vous pouvez aussi séparer le traitement du pool de requêtes, ce qui garantit que les requêtes des clients ne sont pas affectées par les opérations de traitement. La montée en charge peut être configurée dans le portail Azure ou avec l’API REST d’Analysis Services.
La montée en charge est disponible pour les serveurs du niveau tarifaire Standard. Chaque réplica de requête est facturé au même prix que votre serveur. Tous les réplicas de la requête sont créés dans la même région que votre serveur. Le nombre de réplicas de requête que vous pouvez configurer est limité par la région de votre serveur. Pour plus d’informations, consultez Disponibilité par région. La montée en charge n’augmente pas la quantité de mémoire disponible pour votre serveur. Pour augmenter la mémoire, vous devez passer à un forfait supérieur.
Pourquoi effectuer un scale-out ?
Dans un déploiement de serveur classique, un même serveur est utilisé comme serveur de traitement et comme serveur de requêtes. Si le nombre de requêtes de clients sur des modèles présents sur votre serveur dépasse les unités de traitement des requêtes du plan de votre serveur, ou que le traitement du modèle est effectué en même temps que des charges de travail de requêtes importantes, les performances peuvent diminuer.
La montée en charge permet de créer un pool de requêtes comportant jusqu’à sept ressources de réplicas de requête supplémentaires (huit au total en comptant le serveur principal). Il est possible d’augmenter le nombre de réplicas du pool de requêtes pour répondre aux demandes de QPU aux moments critiques, et de séparer à tout moment un serveur de traitement du pool de requêtes.
Quel que soit le nombre de réplicas de requête dont vous disposez dans un pool de requêtes, le traitement des charges de travail n’est pas distribué entre les réplicas de requête. Le serveur principal sert de serveur de traitement. Les réplicas de requête ne traitent que les requêtes portant sur les bases de données model synchronisées entre le serveur principal et chacun des réplicas du pool de requêtes.
Lorsque vous effectuez une montée en charge, l’ajout incrémentiel des nouveaux réplicas de requête au pool de requêtes peut prendre jusqu’à cinq minutes. Une fois que tous les nouveaux réplicas de requête sont opérationnels, la charge des nouvelles connexions clientes est équilibrée entre les ressources du pool de requêtes. Les connexions client existantes ne sont pas modifiées à partir de la ressource à laquelle ils sont actuellement connectés. Lorsque vous effectuez une mise à l’échelle à la baisse, toutes les connexions client existantes à une ressource de pool de requêtes en cours de suppression du pool de requêtes sont arrêtées. Les clients peuvent se reconnecter à une ressource restante du pool de requêtes.
Fonctionnement
Lorsque vous effectuez la première configuration de la montée en charge, les bases de données model du serveur principal sont automatiquement synchronisées avec les nouveaux réplicas d’un nouveau pool de requêtes. La synchronisation automatique ne se produit qu’une seule fois. À cette occasion, les fichiers de données du serveur principal (chiffrées au repos dans le Stockage Blob) sont copiés à un second emplacement, également chiffré au repos dans le Stockage Blob. Les réplicas du pool de requêtes sont ensuite alimentés avec des données issues du deuxième ensemble de fichiers.
Si la synchronisation automatique ne se produit que lors de la première montée en charge du serveur, une synchronisation manuelle reste possible. pour que les données des réplicas du pool de requêtes correspondent à celles du serveur principal. En cas de traitement (actualisation) des modèles sur le serveur principal, il est nécessaire d’effectuer une synchronisation une fois les opérations de traitement terminées. Elle copie dans le deuxième ensemble de fichiers les données mises à jour des fichiers du serveur principal dans le Stockage Blob. Les réplicas du pool de requêtes sont ensuite alimentés avec les données mises à jour issues du deuxième ensemble de fichiers dans le Stockage Blob.
Lorsque vous effectuez des opérations ultérieures de montée en charge (par exemple, augmentation de deux à cinq du nombre de réplicas dans le pool de requêtes), les nouveaux réplicas sont alimentés avec des données issues du deuxième ensemble de fichiers dans le Stockage Blob. Aucune synchronisation n’est effectuée. Si vous effectuez ensuite une synchronisation après la montée en charge, les nouveaux réplicas dans le pool de requêtes seront alimentés deux fois, ce qui serait redondant. Lors des opérations ultérieures de montée en charge, il est important de garder à l’esprit plusieurs considérations :
Effectuez une synchronisation avant l’opération de montée en charge afin d’éviter une alimentation redondante des réplicas ajoutés. Les opérations simultanées de montée en charge et de synchronisation ne sont pas autorisées.
En cas d’automatisation d’opérations de traitement et de montée en charge, il est important de commencer par traiter les données sur le serveur principal, puis d’effectuer une synchronisation et enfin de passer à l’opération de montée en charge. Cette séquence réduit l’impact sur les ressources QPU et de mémoire.
Pendant les opérations de Scale-out, tous les serveurs du pool de requêtes, y compris le serveur principal, sont temporairement hors connexion.
La synchronisation reste autorisée même en l’absence de réplicas dans le pool de requêtes. Si vous passez de zéro à un ou plusieurs réplicas avec de nouvelles données issues d’une opération de traitement sur le serveur principal, effectuez tout d’abord la synchronisation sans aucun réplica dans le pool de requêtes, puis passez à la montée en charge. L’ordre synchronisation-montée en charge évite une alimentation redondante des réplicas ajoutés.
Quand vous supprimez une base de données model du serveur principal, elle n’est pas automatiquement supprimée des réplicas dans le pool de requêtes. Il est nécessaire d’effectuer une opération de synchronisation avec la commande PowerShell Sync-AzAnalysisServicesInstance, qui supprime de l’emplacement de Stockage Blob partagé du réplica le ou les fichiers de cette base de données, puis supprime la base de données model sur les réplicas du pool de requêtes. Pour déterminer si une base de données model existe sur les réplicas du pool de requêtes, mais pas sur le serveur principal, définissez le paramètre Séparer le serveur de traitement du pool de requêtes sur Oui. Utilisez ensuite SQL Server Management Studio (SSMS) pour vous connecter au serveur principal avec le qualificateur
:rwafin de voir si la base de données existe déjà. Connectez-vous aux réplicas du pool de requêtes sans le qualificateur:rwpour savoir si la même base de données s’y trouve également. Si la base de données existe sur les réplicas du pool de requêtes, mais pas sur le serveur principal, exécutez une opération de synchronisation.Lorsque vous nommez une base de données sur le serveur principal, une autre étape est nécessaire pour que la base de données soit correctement synchronisée avec tous les réplicas. Après le renommage, effectuez une synchronisation avec la commande Sync-AzAnalysisServicesInstance en spécifiant le paramètre
-Databaseavec l’ancien nom de la base de données. Cette synchronisation supprime de tous les réplicas la base de données et les fichiers portant l’ancien nom. Ensuite, effectuez une autre synchronisation en indiquant le paramètre-Databaseavec le nouveau nom de la base de données. La deuxième synchronisation copie la base de données portant le nouveau nom dans le deuxième ensemble de fichiers et alimente tous les réplicas. Il n’est pas possible d’effectuer ces synchronisations avec la commande Synchroniser le modèle du portail.
Mode de synchronisation
Par défaut, les réplicas de requête sont réalimentés intégralement, et non pas de façon incrémentielle. La réalimentation se produit par étapes. Ils sont détachés et attachés deux à la fois (en supposant qu’il existe au moins trois réplicas) pour garantir qu’au moins un réplica est conservé en ligne pour les requêtes à tout moment. Dans certains cas, les clients peuvent avoir besoin de se reconnecter à l’un des réplicas en ligne pendant que ce processus a lieu. En utilisant le paramètre ReplicaSyncMode, vous pouvez désormais spécifier la synchronisation du réplica de requête en parallèle. La synchronisation parallèle offre les avantages suivants :
- Réduction significative du temps de synchronisation.
- Les données des réplicas sont plus susceptibles d’être cohérentes au cours du processus de synchronisation.
- Comme les bases de données restent en ligne sur tous les réplicas pendant tout le processus de synchronisation, les clients ne doivent pas se reconnecter.
- Le cache en mémoire est mis à jour de façon incrémentielle avec uniquement les données modifiées, ce qui peut être plus rapide que la réalimentation complète du modèle.
Paramétrage de ReplicaSyncMode
Utilisez SSMS pour définir ReplicaSyncMode dans les Propriétés avancées. Les valeurs possibles sont les suivantes :
1(par défaut) : réalimentation complète de la base de données des réplicas par étapes (incrémentielle).2: synchronisation optimisée en parallèle.
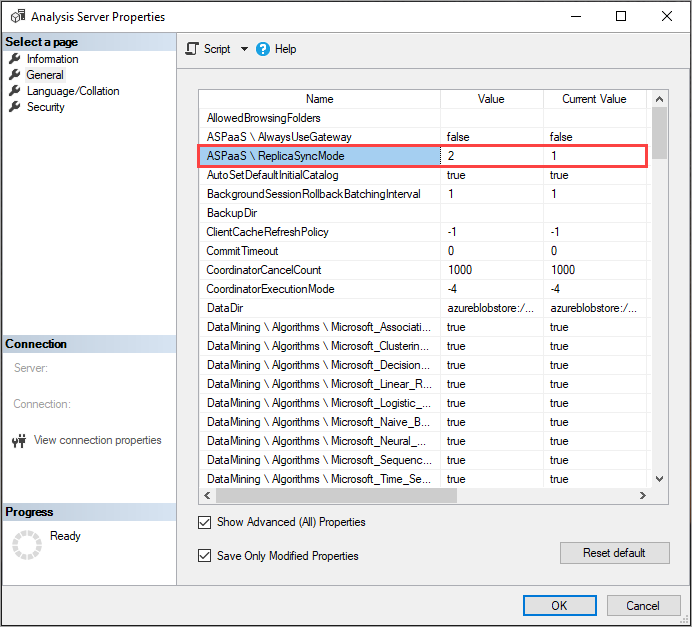
Lorsque vous définissez ReplicaSyncMode = 2, en fonction de la quantité de cache qui doit être mise à jour, la mémoire supplémentaire peut être utilisée par les réplicas de requête. Pour que la base de données reste en ligne et disponible pour les requêtes, en fonction de la quantité de données modifiée, l’opération peut nécessiter jusqu’à doubler la mémoire sur le réplica, car les segments anciens et nouveaux sont conservés simultanément en mémoire. Les nœuds de réplica ont la même allocation de mémoire que le nœud principal, et il y a généralement de la mémoire supplémentaire sur le nœud principal pour les opérations d’actualisation. Il est donc peu probable que les réplicas manquent de mémoire. En outre, le scénario commun est que la base de données est mise à jour de façon incrémentielle sur le nœud principal, et donc la nécessité de doubler la mémoire devrait être peu commune. Si l’opération de synchronisation rencontre une erreur de mémoire insuffisante, elle réessaie à l’aide de la technique par défaut (attacher/détacher deux à la fois).
Traitement distinct à partir du pool de requêtes
Pour optimiser les performances des opérations de traitement et de requête, vous pouvez choisir de séparer votre serveur de traitement du pool de requêtes. Lorsqu’ils sont séparés, de nouvelles connexions client sont attribuées aux réplicas de requête dans le pool de requêtes uniquement. Si les opérations de traitement ne prennent qu’un court laps de temps, vous pouvez choisir de séparer votre serveur de traitement du pool de requêtes uniquement pendant le temps nécessaire à la réalisation des opérations de traitement et de synchronisation, puis de le réinclure dans le pool de requêtes. La séparation du serveur de traitement du pool de requêtes et de rajout dans le pool de requêtes peuvent prendre jusqu'à cinq minutes.
Surveiller l’utilisation des unités de traitement des requêtes
Afin de déterminer si un scale-out est nécessaire pour les métriques votre serveur, supervisez votre serveur dans le portail Azure. Si vos unités de traitement des requêtes atteignent régulièrement le maximum, cela signifie que le nombre de requêtes sur vos modèles dépasse la limite d’unités de traitement des requêtes pour votre forfait. La métrique Longueur de la file d’attente des travaux du pool de requêtes augmente aussi quand le nombre de requêtes dans la file d’attente du pool de threads de requêtes dépasse les unités de traitement des requêtes disponibles.
L’indicateur de QPU moyen par ServerResourceType est également intéressant. Cette mesure compare le nombre moyen de QPU pour le serveur principal et le pool de requêtes.

Pour configurer les QPU (unités de traitement des requêtes) par ServerResourceType
- Dans un graphique en courbes Mesures, cliquez sur Ajouter une mesure.
- Dans RESSOURCE, sélectionnez votre serveur, puis, dans ESPACE DE NOMS DE LA MESURE, sélectionnez Mesures standard Analysis Services ; sélectionnez QPU dans MESURE, puis Moyenne dans AGRÉGATION.
- Cliquez sur Appliquer le fractionnement.
- Dans VALEURS, sélectionnez ServerResourceType.
Journalisation des diagnostics détaillés
Utilisez les journaux Azure Monitor pour obtenir des diagnostics plus détaillés des ressources serveur ayant fait l’objet d’un scale-out. Avec les journaux, vous pouvez utiliser des requêtes Log Analytics pour répartir les QPU et la mémoire par serveur et par réplica. Pour plus d’informations, consultez Analyser les journaux dans un espace de travail Log Analytics. Pour obtenir des exemples de requêtes, consultez Exemples de requêtes Kusto.
Configurer la montée en charge
Dans le portail Azure
Dans le portail, cliquez sur Montée en charge. Utilisez le curseur pour sélectionner le nombre de serveurs réplica de requête. Le nombre de réplicas que vous choisissez s’ajoute à votre serveur existant.
Dans Séparer le serveur de traitement du pool de requêtes, sélectionnez Oui pour exclure votre serveur de traitement des serveurs de requêtes. Les connexions client utilisant la chaîne de connexion par défaut (sans
:rw) sont redirigées vers les réplicas du pool de requêtes.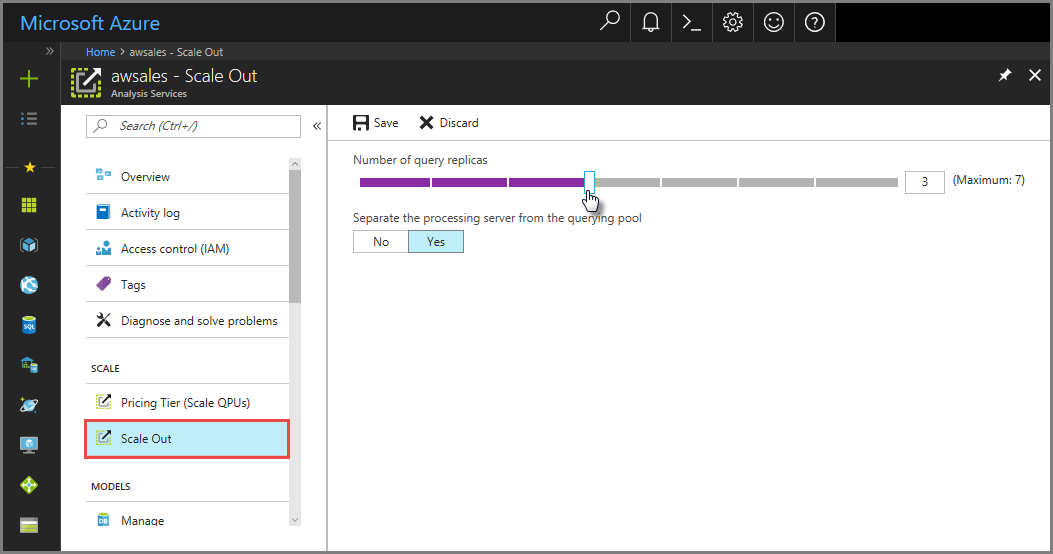
Cliquez sur Enregistrer pour provisionner vos nouveaux serveurs réplica de requête.
Lors que vous effectuez la première configuration de la montée en charge d’un serveur, les bases de données model du serveur principal sont automatiquement synchronisées avec les réplicas du pool de requêtes. La synchronisation automatique ne se produit qu’une fois, lors de la première configuration de la montée en charge pour passer à un ou plusieurs réplicas. Les modifications apportées par la suite au nombre de réplicas sur le même serveur ne déclenchent pas d’autre synchronisation automatique. Même en redéfinissant le serveur sur zéro réplica pour ensuite le repasser à un nombre supérieur de réplicas.
Synchroniser
Les opérations de synchronisation doivent être effectuées manuellement ou avec l’API REST.
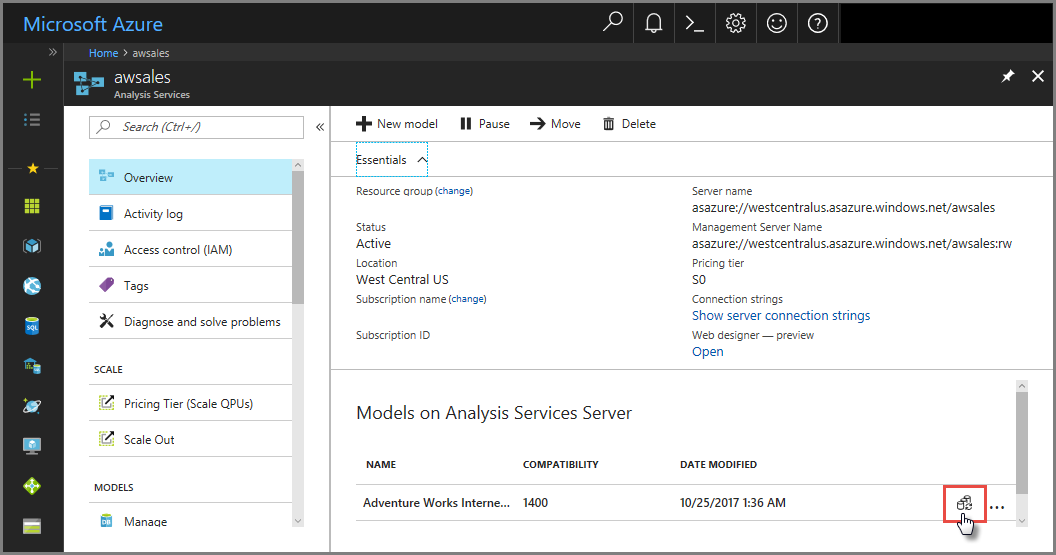
Dans le portail Azure
Dans Vue d’ensemble> modèle >Synchroniser le modèle.
API REST
Utilisez l’opération de synchronisation.
Synchroniser un modèle
POST https://<region>.asazure.windows.net/servers/<servername>:rw/models/<modelname>/sync
Obtenir l’état de la synchronisation
GET https://<region>.asazure.windows.net/servers/<servername>/models/<modelname>/sync
Codes de statut de retour :
| Code | Description |
|---|---|
| -1 | Non valide |
| 0 | En cours de réplication |
| 1 | En cours de réalimentation |
| 2 | Terminée |
| 3 | Échec |
| 4 | En cours de finalisation |
PowerShell
Notes
Nous vous recommandons d’utiliser le module Azure Az PowerShell pour interagir avec Azure. Pour commencer, consultez Installer Azure PowerShell. Pour savoir comment migrer vers le module Az PowerShell, consultez Migrer Azure PowerShell depuis AzureRM vers Az.
Avant d’utiliser PowerShell, installez ou mettez à jour le dernier module Azure PowerShell.
Pour exécuter la synchronisation, utilisez Sync-AzAnalysisServicesInstance.
Pour définir le nombre de réplicas de requête, utilisez Set-AzAnalysisServicesServer. Spécifiez le paramètre -ReadonlyReplicaCount facultatif.
Pour séparer le serveur de traitement du pool de requêtes, utilisez Set-AzAnalysisServicesServer. Spécifiez le paramètre -DefaultConnectionMode facultatif pour utiliser Readonly.
Pour plus d’informations, voir Utiliser un principal de service avec le module Az.AnalysisServices.
Connexions
Dans la page Vue d’ensemble de votre serveur, vous voyez deux noms de serveur. Si vous n’avez pas encore configuré la montée en charge pour un serveur, les deux noms de serveur fonctionnent de la même façon. Une fois le scale-out configuré pour un serveur, vous devez spécifier le nom du serveur approprié en fonction du type de connexion.
Pour les connexions de clients d’utilisateur finaux, comme Power BI Desktop, Excel et des applications personnalisées, utilisez Nom du serveur.
Pour SSMS, Visual Studio et les chaînes de connexion dans PowerShell, les applications de fonction Azure et AMO, utilisez Nom du serveur d’administration. Le nom du serveur d’administration inclut un qualificateur :rw (lecture-écriture) spécial. Toutes les opérations de traitement se produisent sur le serveur d’administration (principal).

Montée en puissance, descente en puissance vs. Montée en charge
Vous pouvez modifier le niveau tarifaire sur un serveur avec plusieurs réplicas. Le même niveau tarifaire s’applique à tous les réplicas. Une opération de mise à l’échelle entraîne d’abord la mise à niveau de tous les réplicas à la fois, puis affichera tous les réplicas sur le nouveau niveau tarifaire.
Résolution des problèmes
Problème : les utilisateurs obtiennent l’erreur impossible de trouver le serveur « <Nom du serveur> » instance en mode de connexion « ReadOnly ».
Solution : Quand vous sélectionnez l’option Séparer le serveur de traitement du pool de requêtes, les connexions clientes qui utilisent la chaîne de connexion par défaut (sans :rw) sont redirigées vers les réplicas du pool de requêtes. Si les réplicas du pool de requêtes ne sont pas encore en ligne, car la synchronisation n’est pas terminée, les connexions client redirigées peuvent échouer. Pour empêcher l’échec des connexions, vous devez avoir au moins deux serveurs dans le pool de requêtes quand vous effectuez une synchronisation. Chaque serveur est synchronisé individuellement pendant que les autres serveurs restent en ligne. Si vous choisissez de ne pas mettre le serveur de traitement dans le pool de requêtes durant le traitement, vous pouvez l’enlever du pool avant le traitement, puis le réintégrer au pool une fois le traitement terminé, mais avant la synchronisation. Utilisez les métriques Mémoire et QPU pour superviser l’état de synchronisation.
Informations connexes
Surveiller Azure Analysis ServicesGérer Azure Analysis Services