Cette architecture de référence montre comment effectuer un scoring par lot avec les modèles R à l’aide d’Azure Batch. Azure Batch fonctionne parfaitement avec des charges de travail intrinsèquement parallèles et comprend la planification des tâches et la gestion des calculs. L’inférence par lots (scoring) est largement utilisée pour segmenter les clients, prévoir les ventes, prédire les comportements des clients, prédire la maintenance ou améliorer la sécurité face à la cybercriminalité.

Téléchargez un fichier Visio de cette architecture.
Workflow
Cette architecture est constituée des composants suivants.
Azure Batch exécute des travaux de génération de prévisions en parallèle sur un cluster de machines virtuelles. Les prédictions sont effectuées à l’aide de modèles Machine Learning pré-formés implémentés dans R. Azure Batch peut automatiquement mettre à l’échelle le nombre de machines virtuelles en fonction du nombre de travaux soumis au cluster. Sur chaque nœud, un script R s’exécute dans un conteneur Docker pour évaluer les données et générer des prévisions.
Le Stockage Blob Azure stocke les données d’entrée, les modèles de Machine Learning préformés et les résultats des prévisions. Il offre un stockage économique par rapport aux performances qu’exige cette charge de travail.
Azure Container Instances fournit un calcul serverless à la demande. Dans ce cas, une instance de conteneur est déployée selon une planification pour déclencher les programmes de traitement par lots qui génèrent les prévisions. Les programmes de traitement par lots sont déclenchés à partir d’un script R à l’aide du package doAzureParallel. L’instance de conteneur s’arrête automatiquement une fois que les travaux sont terminés.
Azure Logic Apps déclenche l’intégralité du workflow en déployant les instances de conteneur selon une planification. Un connecteur Azure Container Instances dans Logic Apps permet de déployer une instance sur une plage d’événements déclencheurs.
Composants
Détails de la solution
Bien que le scénario suivant soit basé sur les prévisions de ventes du magasin de vente au détail, son architecture peut être généralisée pour tout scénario nécessitant la génération de prédictions sur une plus grande échelle à l’aide de modèles R. Une implémentation de référence pour cette architecture est disponible sur GitHub.
Cas d’usage potentiels
Une chaîne de supermarché doit prévoir les ventes de produits au cours du trimestre à venir. La prévision permet à la société de mieux gérer sa chaîne d’approvisionnement et de s’assurer qu’elle peut répondre à la demande de produits dans chacun de ses magasins. La société met à jour ses prévisions chaque semaine au fur et à mesure que de nouvelles données de ventes de la semaine précédente deviennent disponibles et que la stratégie marketing du produit du trimestre suivant est définie. Des prévisions quantiles sont générées pour estimer l’incertitude des prévisions de ventes individuelles.
Le traitement est constitué des étapes suivantes :
Une application logique Azure déclenche le processus de génération des prévisions une fois par semaine.
L’application logique démarre une instance de conteneur Azure exécutant le conteneur Docker du planificateur, qui déclenche les travaux de scoring sur le cluster Azure Batch.
Les travaux de scoring sont exécutés en parallèle sur les nœuds du cluster Azure Batch. Chaque nœud :
Extrait l’image Docker du Worker et démarre un conteneur.
Lit les données d’entrée et les modèles R pré-formés à partir du stockage d’objets BLOB Azure.
Évalue les données pour produire des prévisions.
Écrit les résultats des prévisions dans le stockage d’objets BLOB.
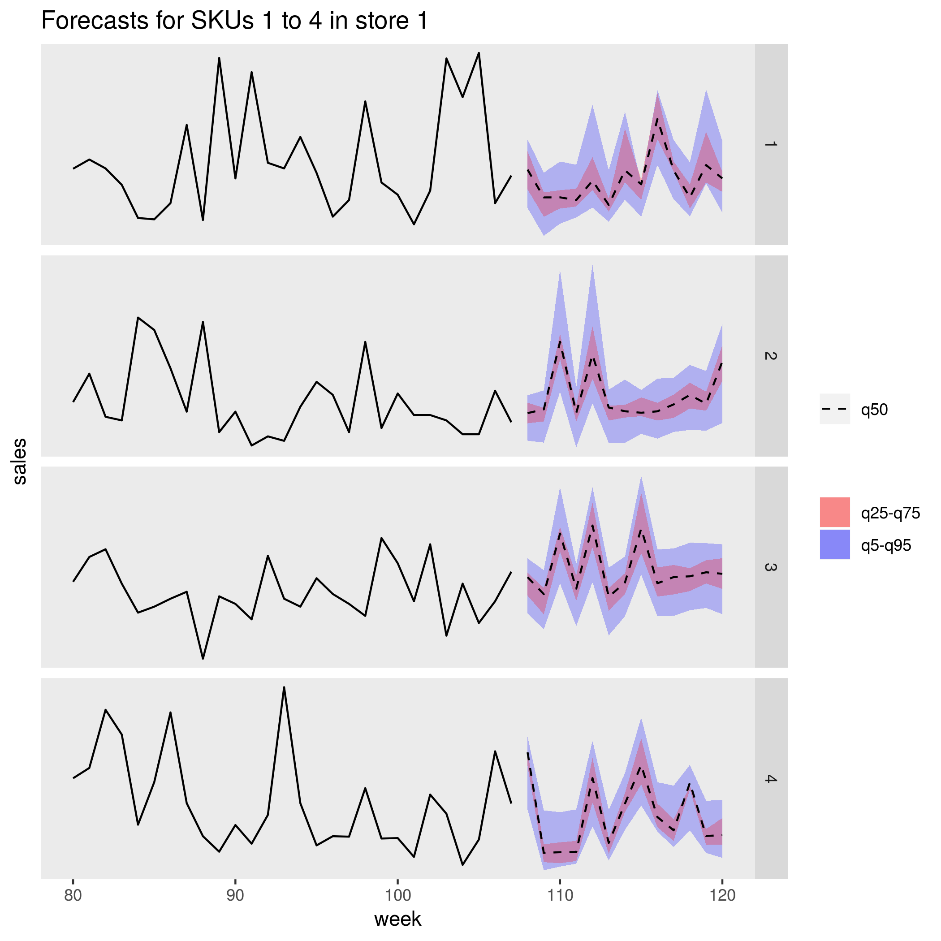
La figure suivante montre les ventes prévues pour quatre produits (références SKU) dans un magasin. La ligne noire est l’historique des ventes, la ligne en pointillés est la prévision médiane (q50), la bande rose représente le 25e et le 75e centile, tandis que la bande bleue représente le 50e et le 95e centile.
Considérations
Ces considérations implémentent les piliers d’Azure Well-Architected Framework qui est un ensemble de principes directeurs qui permettent d’améliorer la qualité d’une charge de travail. Pour plus d’informations, consultez Microsoft Azure Well-Architected Framework.
Performances
Déploiement conteneurisé
Avec cette architecture, tous les scripts R s’exécutent dans des conteneurs Docker. L’utilisation de conteneurs garantit que les scripts s’exécutent dans un environnement cohérent à chaque fois, avec la même version de R et les mêmes versions de packages. Des images Docker distinctes sont utilisées pour le planificateur et les conteneurs Worker, car chacune a un ensemble différent de dépendances de package R.
Azure Container Instances fournit un environnement serverless pour exécuter le conteneur du planificateur. Le conteneur du planificateur exécute un script R qui déclenche les travaux de scoring individuels exécutés sur un cluster Azure Batch.
Chaque nœud du cluster Azure Batch exécute le conteneur Worker, qui exécute le script de scoring.
Paralléliser la charge de travail
Lors du scoring par lot des données avec des modèles R, réfléchissez à la manière de paralléliser la charge de travail. Les données d’entrée doivent être partitionnées de façon à ce que l’opération de scoring puisse être distribuée entre les nœuds du cluster. Essayez différentes approches pour découvrir le meilleur choix pour la distribution de votre charge de travail. Prenez en compte les éléments suivants au cas par cas :
- La quantité de données pouvant être chargées et traitées dans la mémoire d’un nœud unique.
- La surcharge liée au démarrage de chaque programme de traitement par lots.
- La surcharge du chargement des modèles R.
Dans le scénario utilisé pour cet exemple, les objets de modèle sont volumineux et il ne faut que quelques secondes pour générer une prévision pour des produits individuels. Pour cette raison, vous pouvez regrouper les produits et exécuter un seul programme de traitement par lots par nœud. Une boucle au sein de chaque travail génère des prévisions pour les produits de façon séquentielle. Cette méthode est le moyen le plus efficace de paralléliser cette charge de travail particulière. Elle évite la surcharge liée au démarrage de nombreux programmes de traitement par lots plus petits et au chargement répété des modèles R.
Une autre approche consiste à déclencher un programme de traitement par lots par produit. Azure Batch forme automatiquement une file d’attente de travaux et les soumet pour qu’ils soient exécutés sur le cluster lorsque des nœuds deviennent disponibles. Utilisez la mise à l’échelle automatique pour ajuster le nombre de nœuds dans le cluster en fonction du nombre de travaux. Cette approche est utile si l’exécution de chaque opération de scoring est relativement longue, ce qui justifie la surcharge liée au démarrage des travaux et au rechargement des objets de modèle. Cette approche est également plus simple à implémenter et vous donne la possibilité d’utiliser la mise à l’échelle automatique. Il s’agit d’une considération importante si la taille de la charge de travail totale n’est pas connue à l’avance.
Superviser les travaux Azure Batch
Surveillez et terminez les travaux Batch depuis le volet Travaux du compte Batch dans le Portail Azure. Surveillez le cluster de traitement par lots, notamment l’état des nœuds individuels, dans le volet Pools.
Journaliser avec doAzureParallel
Le package doAzureParallel collecte automatiquement les journaux de tous les travaux stdout/stderr pour chaque travail soumis sur Azure Batch. Ces journaux sont disponibles dans le compte de stockage créé lors de l’installation. Pour les afficher, utilisez un outil de navigation de stockage comme Explorateur Stockage Azure ou Portail Azure.
Pour déboguer rapidement des programmes de traitement par lots, accédez aux journaux dans votre session R locale. Pour plus d’informations, consultez Configurer et soumettre des exécutions d’entraînement.
Optimisation des coûts
L’optimisation des coûts consiste à examiner les moyens de réduire les dépenses inutiles et d’améliorer l’efficacité opérationnelle. Pour plus d’informations, consultez Vue d’ensemble du pilier d’optimisation des coûts.
Les ressources de calcul utilisées dans cette architecture de référence sont les composants les plus coûteux. Pour ce scénario, un cluster de taille fixe est créé chaque fois que le travail est déclenché, puis arrêté une fois le travail terminé. Le coût est facturé uniquement pendant le démarrage, l’exécution ou l’arrêt des nœuds du cluster. Cette approche convient pour un scénario dans lequel les ressources de calcul requises pour générer les prévisions restent relativement constantes d’un travail à l’autre.
Dans les scénarios où la quantité de calcul requise pour terminer le travail n’est pas connue à l’avance, il pourrait être plus approprié d’utiliser la mise à l’échelle automatique. Avec cette approche, la taille du cluster est mise à l’échelle en fonction de la taille du travail. Azure Batch prend en charge une plage de formules de mise à l’échelle automatique que vous pouvez définir lors de la définition du cluster à l’aide de l’API doAzureParallel.
Pour certains scénarios, le délai entre les tâches pourrait être trop faible pour arrêter et démarrer le cluster. Dans ce cas, assurez-vous que le cluster s’exécute entre les travaux, le cas échéant.
Azure Batch et doAzureParallel prennent en charge l’utilisation de machines virtuelles de faible priorité. Ces machines virtuelles bénéficient d’une remise importante, mais risquent d’être affectées à d’autres charges de travail de priorité plus élevée. Par conséquent, l’utilisation de machines virtuelles de faible priorité n’est pas recommandée pour les charges de travail de production critiques. Toutefois, elles sont utiles pour les charges de travail expérimentales ou de développement.
Déployer ce scénario
Pour déployer cette architecture de référence, suivez les étapes décrites dans le référentiel GitHub.
Contributeurs
Cet article est géré par Microsoft. Il a été écrit à l’origine par les contributeurs suivants.
Auteur principal :
- Angus Taylor | Scientifique des données senior
Pour afficher les profils LinkedIn non publics, connectez-vous à LinkedIn.