Cette architecture de référence donne des stratégies concernant le modèle de partitionnement utilisé par les services d’ingestion d’événements. Les services d’ingestion d’événements fournissent des solutions de diffusion d’événements à grande échelle. De ce fait, ils doivent traiter les événements en parallèle et être en mesure de gérer l’ordre des événements. Ils doivent également équilibrer les charges et offrir une certaine scalabilité. Les modèles de partitionnement répondent à toutes ces exigences.
Architecture

Au centre du diagramme se trouve une zone appelée Cluster Kafka ou espace de noms Event Hubs. Elle comprend trois petits rectangles, chacun intitulé Rubrique ou hub d’événement et contenant plusieurs rectangles nommés Partition. Au-dessus de la zone principale se trouvent les rectangles appelés Producteurs. Des flèches pointent des producteurs vers la zone principale. Sous la zone principale se trouvent les rectangles intitulés Consommateur. Des flèches, étiquetées avec différentes valeurs de décalage, pointent de la zone principale vers les consommateurs. Un seul cadre bleu nommé Groupe de consommateurs englobe deux des consommateurs.
Téléchargez un fichier Visio de cette architecture.
Dataflow
Les producteurs publient des données dans le service d’ingestion, ou pipeline. Les pipelines Event Hubs se composent d’espaces de noms. Les équivalents Kafka sont des clusters.
Le pipeline distribue les événements entrants entre les partitions. Les événements restent dans l’ordre de fabrication au sein de chaque partition, mais non d’une partition à l’autre. Le nombre de partitions peut avoir un impact sur le débit, soit la quantité de données qui transitent par le système dans un laps de temps défini. Les pipelines mesurent généralement le débit en bits par seconde (bits/s) et parfois en paquets de données par seconde (paquets/s).
Les partitions se trouvent dans des flux nommés d’événements. Event Hubs appelle ces flux hubs d’événements. Dans Kafka, ce sont des rubriques.
Les consommateurs sont des processus ou des applications qui s’abonnent à des rubriques. Chacun lit un sous-ensemble spécifique du flux d’événements. Ce sous-ensemble peut comporter plusieurs partitions. Cependant, le pipeline ne peut assigner chaque partition qu’à un seul consommateur par groupe de consommateurs à la fois.
Plusieurs consommateurs peuvent former des groupes de consommateurs. Lorsqu’un groupe s’abonne à une rubrique, chaque consommateur du groupe dispose d’une vue distincte du flux d’événements. Les applications fonctionnent indépendamment les unes des autres, à leur propre rythme. Le pipeline peut également utiliser des groupes de consommateurs pour le partage de charge.
Les consommateurs traitent le flux des événements publiés auxquels ils s’abonnent. Il participent également aux points de contrôle. Ce processus permet aux abonnés d’utiliser des décalages pour marquer leur position dans une séquence d’événements de partition. Un décalage est un espace réservé qui fonctionne comme un signet pour identifier le dernier événement lu par le consommateur.
Détails du scénario
Plus précisément, ce document présente les stratégies suivantes :
- Comment attribuer des événements à des partitions
- Combien de partitions utiliser
- Comment attribuer des partitions aux abonnés lors du rééquilibrage
Il existe de nombreuses technologies d’ingestion d’événements, par exemple :
- Azure Event Hubs : plateforme de diffusion en continu Big Data complètement managée.
- Apache Kafka : plateforme de traitement de flux open source.
- Event Hubs avec Kafka : solution qui évite d’avoir à exécuter son propre cluster Kafka. Cette fonctionnalité Event Hubs fournit un point de terminaison compatible avec les API Kafka.
Outre les stratégies de partitionnement, ce document présente les différences entre le partitionnement dans Event Hubs et le partitionnement dans Kafka.
Recommandations
Gardez à l’esprit les recommandations suivantes lors du développement d’une stratégie de partitionnement.
Distribution des événements aux partitions
La stratégie d’attribution constitue l’un des aspects de la stratégie de partitionnement. Un événement qui arrive dans un service d’ingestion est dirigé vers une partition. C’est la stratégie d’attribution qui détermine laquelle.
Chaque événement stocke son contenu dans sa valeur. Outre la valeur, il contient également une clé, comme le montre le diagramme suivant :

Au centre du diagramme se trouvent plusieurs paires de cases. Une étiquette sous les zones indique que chaque paire représente un message. Chaque message contient une zone bleue intitulée Clé et une zone noire intitulée Valeur. Les messages sont disposés horizontalement. Des flèches qui pointent de la gauche vers la droite entre les messages indiquent que ces derniers forment une séquence. Au-dessus des messages se trouve l’étiquette Flux. Des crochets indiquent que la séquence forme un flux.
Téléchargez un fichier Visio de cette architecture.
La clé, qui contient des données relatives à l’événement, peut également jouer un rôle dans la stratégie d’attribution.
Il existe plusieurs approches pour attribuer des événements aux partitions :
- Par défaut, les services distribuent les événements entre les partitions en mode tourniquet (round robin).
- Les producteurs peuvent spécifier un ID de partition avec un événement. L’événement accède alors à la partition avec cet ID.
- Les producteurs peuvent fournir une valeur pour la clé d’événement. Dans ce cas, un partitionneur de type hachage détermine une valeur de hachage à partir de la clé. L’événement accède alors à la partition associée à cette valeur de hachage.
Gardez à l’esprit les recommandations suivantes lors du choix d’une stratégie d’attribution :
- Utilisez des ID de partition lorsque les consommateurs ne sont intéressés que par certains événements. Lorsque ces événements sont acheminés vers une seule partition, le consommateur peut les recevoir facilement. Il lui suffit de s’abonner à cette partition.
- Utilisez des clés lorsque les consommateurs doivent recevoir les événements dans l’ordre de fabrication. Étant donné que tous les événements associés à la même clé sont dirigés vers la même partition, les événements possédant des valeurs de clés peuvent conserver leur ordre lors du traitement. Les consommateurs les reçoivent alors dans cet ordre.
- Avec Kafka, évitez les clés si vous n’avez besoin ni de regrouper ni de classer les événements. Le producteur ne connaît pas l’état de la partition de destination dans Kafka. Si une clé achemine un événement vers une partition non fonctionnelle, des retards et des pertes d’événements risquent de se produire. Dans Event Hubs, les événements associés à des clés transitent d’abord par une passerelle avant de se diriger vers une partition. Cette approche les empêche d’accéder à des partitions non disponibles.
- La forme des données peut influencer l’approche de partitionnement. Prenez en compte la façon dont l’architecture en aval distribue les données lorsque vous choisissez les attributions.
- Si les consommateurs agrègent les données selon un certain attribut, effectuez également un partitionnement sur cet attribut.
- Lorsque la priorité est l’efficacité du stockage, effectuez le partitionnement sur un attribut qui concentre les données afin d’accélérer les opérations de stockage.
- Les pipelines d’ingestion partitionnent parfois les données pour contourner des problèmes de goulots d’étranglement des ressources. Dans ces environnements, adaptez le partitionnement en fonction du fractionnement des partitions dans la base de données.
Détermination du nombre de partitions
Suivez ces instructions pour décider du nombre de partitions à utiliser :
- Utilisez davantage de partitions pour augmenter le débit. Chaque consommateur lit à partir de la partition qui lui est attribuée. Plus il y a de partitions, plus les consommateurs peuvent recevoir d’événements d’une rubrique en même temps.
- Utilisez au moins autant de partitions que la valeur de votre débit cible en mégaoctets.
- Pour éviter d’épuiser les consommateurs, utilisez au moins autant de partitions que de consommateurs. Supposons, par exemple, que huit partitions soient attribuées à huit consommateurs. Tous les consommateurs supplémentaires qui s’abonneront devront attendre. Vous pouvez également garder un ou deux consommateurs prêts à recevoir les événements au cas où se produirait une défaillance d’un consommateur existant.
- Utilisez plus de clés que de partitions. Dans le cas contraire, certaines partitions ne recevront pas d’événements, ce qui aura pour effet de déséquilibrer la charge des partitions.
- Dans Kafka et Event Hubs, il est possible de modifier le nombre de partitions d’un système d’exploitation au niveau Dédié. Évitez toutefois d’effectuer cette modification si vous utilisez des clés pour préserver l’ordre des événements, La raison tient aux faits suivants :
- Les consommateurs s’appuient sur certaines partitions et sur l’ordre des événements qu’elles contiennent.
- Lorsque le nombre de partitions évolue, le mappage des événements avec les partitions est susceptible de changer. Par exemple, cette formule peut produire une attribution différente :
partition assignment = hash key % number of partitions. - Ni Kafka ni Event Hubs n’essaient de redistribuer les événements arrivés sur les partitions avant la redistribution. Par conséquent, il n’est plus garanti que les événements arrivent dans l’ordre de fabrication dans une certaine partition.
En plus de ces recommandations, vous pouvez également appliquer cette formule pour déterminer approximativement le nombre de partitions :
max(t/p, t/c)
Elle utilise les valeurs suivantes :
t: débit cible.p: débit de production sur une seule partition.c: débit de consommation sur une seule partition.
Prenons par exemple la situation suivante :
- Le débit idéal est de 2 Mbits/s. Dans la formule,
test de 2 Mbits/s. - Un producteur envoie des événements à un débit de 1 000 événements par seconde, ce qui donne
pégal à 1 Mbit/s. - Un consommateur reçoit des événements à un débit de 500 événements par seconde, ce qui donne
cégal à 0,5 Mbit/s.
Avec ces valeurs, le nombre de partitions est de 4 :
max(t/p, t/c) = max(2/1, 2/0.5) = max(2, 4) = 4
Lorsque vous mesurez le débit, gardez les points suivants à l’esprit :
C’est le consommateur le plus lent qui détermine le débit de consommation. Toutefois, il est possible qu’aucune information ne soit disponible sur les applications de consommateurs en aval. Dans ce cas, estimez le débit en commençant avec une partition comme ligne de base. (N’utilisez cette configuration que dans les environnements de test, et non dans les systèmes de production). Les hubs d’événements du niveau tarifaire Standard comportant une partition produisent normalement un débit compris entre 1 et 20 Mbits/s.
Les consommateurs ne peuvent consommer les événements issus d’un pipeline d’ingestion avec un débit élevé que si les producteurs les envoient à un débit comparable. Pour déterminer la capacité requise totale du pipeline d’ingestion, mesurez le débit du producteur, et pas seulement celui du consommateur.
Attribution de partitions aux consommateurs lors du rééquilibrage
Lorsque les consommateurs s’abonnent ou se désabonnent, le pipeline rééquilibre l’attribution des partitions aux consommateurs. Par défaut, Event Hubs et Kafka appliquent une approche de type tourniquet (round robin) pour ce rééquilibrage. Cette méthode permet de répartir uniformément les partitions entre les membres.
Avec Kafka, si vous ne souhaitez pas que le pipeline rééquilibre automatiquement les attributions, vous pouvez affecter les partitions aux consommateurs de manière statique. Vous devez toutefois veiller à ce que toutes les partitions disposent d’abonnés et que les charges soient équilibrées.
En dehors de la stratégie de tourniquet (round robin) par défaut, Kafka propose deux stratégies de rééquilibrage automatique :
- Attribution de plage : appliquez cette approche pour rassembler des partitions issues de différentes rubriques. Elle permet d’identifier les rubriques qui utilisent le même nombre de partitions et suivent la même logique de partitionnement de clé. Elle joint ensuite les partitions de ces rubriques lors de l’attribution aux consommateurs.
- Attribution permanente : utilisez cette attribution pour limiter le déplacement des partitions. Comme le tourniquet (round robin), cette stratégie garantit une distribution uniforme. Cependant, elle conserve également les attributions existantes lors du rééquilibrage.
Considérations
Gardez les points suivants à l’esprit lors de l’utilisation d’un modèle de partitionnement.
Extensibilité
Un nombre élevé de partitions risque de limiter la scalabilité :
Dans Kafka, les répartiteurs stockent les données d’événement et les décalages dans des fichiers. Plus vous utiliserez de partitions, plus vous aurez de descripteurs de fichiers ouverts. Si le système d’exploitation limite le nombre de fichiers ouverts, vous devrez peut-être reconfigurer ce paramètre.
Dans Event Hubs, les utilisateurs ne sont pas confrontés aux limitations du système de fichiers. Toutefois, chaque partition gère ses propres fichiers blob Azure et les optimise en arrière-plan. Un nombre élevé de partitions rend coûteuse la gestion des données de point de contrôle. La raison en est que les opérations d’E/S peuvent prendre du temps et que les appels de l’API de stockage sont proportionnels au nombre de partitions.
Chaque producteur Kafka ou Event Hubs stocke les événements dans une mémoire tampon jusqu’à ce qu’un lot important soit disponible ou jusqu’à ce qu’un laps de temps donné soit écoulé. Ensuite, le producteur envoie les événements au pipeline d’ingestion. Il gère une mémoire tampon pour chaque partition. Plus le nombre de partitions augmente, plus les besoins en mémoire du client s’étendent. Si les consommateurs reçoivent les événements par lots, ils risquent de rencontrer le même problème. Lorsqu’ils s’abonnent à un grand nombre de partitions alors qu’ils disposent d’une mémoire tampon limitée, des problèmes peuvent survenir.
Disponibilité
Un nombre important de partitions peut également nuire à la disponibilité :
Kafka positionne généralement les partitions sur différents répartiteurs. En cas de défaillance de l’un deux, Kafka rééquilibre les partitions pour éviter de perdre des événements. Plus il y a de partitions à rééquilibrer, plus le basculement est long et plus l’indisponibilité dure. Limitez le nombre de partitions à quelques milliers pour éviter ce problème.
Plus vous utilisez de partitions, plus vous mettez de ressources physiques en service. Selon la réponse du client, d’autres défaillances risquent alors de se produire.
Avec un nombre élevé de partitions, le processus d’équilibrage de charge doit gérer davantage de variables, ce qui le met à rude épreuve. Des exceptions temporaires peuvent se produire en cas de perturbations temporaires (par exemple, des problèmes réseau ou un service Internet intermittent). Elles sont susceptibles d’apparaître pendant une mise à niveau ou un équilibrage de charge, lorsque Event Hubs déplace des partitions vers différents nœuds. Gérez le comportement temporaire en incorporant une stratégie de nouvelles tentatives pour limiter les défaillances. Utilisez EventProcessorClient dans les kits SDK .NET et Java ou EventHubConsumerClient dans les kits SDK Python et JavaScript pour simplifier ce processus.
Performances
Dans Kafka, les événements sont validés une fois que le pipeline les a répliqués sur tous les réplicas synchronisés. Cette approche permet de garantir la haute disponibilité des événements. Étant donné que les consommateurs reçoivent uniquement les événements validés, le processus de réplication ajoute à la latence. Dans les pipelines d’ingestion, ce terme fait référence au délai entre le moment où le producteur publie un événement et celui où il est lu par un consommateur. Selon des expériences menées par Confluent, la réplication de 1 000 partitions d’un répartiteur à un autre peut prendre environ 20 ms. La latence de bout en bout est alors d’au moins 20 ms. Plus le nombre de partitions augmente, plus la latence augmente. Cet inconvénient ne s’applique pas à Event Hubs.
Sécurité
Dans Event Hubs, les serveurs de publication utilisent un jeton SAP (signature d’accès partagé) pour s’identifier. Les consommateurs se connectent par le biais d’une session AMQP 1.0. Ce canal de communication bidirectionnel compatible avec les états constitue un moyen sécurisé de transférer des messages. Kafka offre également des fonctionnalités de chiffrement, d’autorisation et d’authentification, mais vous devez les implémenter vous-même.
Déployer ce scénario
Les exemples de code suivants montrent comment maintenir le débit, distribuer les messages sur une partition spécifique et conserver l’ordre des événements.
Maintien du débit
Cet exemple porte sur l’agrégation de journaux. L’objectif est de ne pas traiter les événements dans l’ordre, mais de conserver un débit donné.
Un client Kafka implémente les méthodes des producteurs et des consommateurs. Étant donné que l’ordre n’est pas important, le code n’envoie pas de messages à des partitions spécifiques. Il suit l’attribution de partitionnement par défaut :
public static void RunProducer(string broker, string connectionString, string topic)
{
// Set the configuration values of the producer.
var producerConfig = new ProducerConfig
{
BootstrapServers = broker,
SecurityProtocol = SecurityProtocol.SaslSsl,
SaslMechanism = SaslMechanism.Plain,
SaslUsername = "$ConnectionString",
SaslPassword = connectionString,
};
// Set the message key to Null since the code does not use it.
using (var p = new ProducerBuilder<Null, string>(producerConfig).Build())
{
try
{
// Send a fixed number of messages. Use the Produce method to generate
// many messages in rapid succession instead of the ProduceAsync method.
for (int i=0; i < NumOfMessages; i++)
{
string value = "message-" + i;
Console.WriteLine($"Sending message with key: not-specified," +
$"value: {value}, partition-id: not-specified");
p.Produce(topic, new Message<Null, string> { Value = value });
}
// Wait up to 10 seconds for any in-flight messages to be sent.
p.Flush(TimeSpan.FromSeconds(10));
}
catch (ProduceException<Null, string> e)
{
Console.WriteLine($"Delivery failed with error: {e.Error.Reason}");
}
}
}
public static void RunConsumer(string broker, string connectionString, string consumerGroup, string topic)
{
var consumerConfig = new ConsumerConfig
{
BootstrapServers = broker,
SecurityProtocol = SecurityProtocol.SaslSsl,
SocketTimeoutMs = 60000,
SessionTimeoutMs = 30000,
SaslMechanism = SaslMechanism.Plain,
SaslUsername = "$ConnectionString",
SaslPassword = connectionString,
GroupId = consumerGroup,
AutoOffsetReset = AutoOffsetReset.Earliest
};
using (var c = new ConsumerBuilder<string, string>(consumerConfig).Build())
{
c.Subscribe(topic);
CancellationTokenSource cts = new CancellationTokenSource();
Console.CancelKeyPress += (_, e) =>
{
e.Cancel = true;
cts.Cancel();
};
try
{
while (true)
{
try
{
var message = c.Consume(cts.Token);
Console.WriteLine($"Consumed - key: {message.Message.Key}, "+
$"value: {message.Message.Value}, " +
$"partition-id: {message.Partition}," +
$"offset: {message.Offset}");
}
catch (ConsumeException e)
{
Console.WriteLine($"Error occured: {e.Error.Reason}");
}
}
}
catch(OperationCanceledException)
{
// Close the consumer to ensure that it leaves the group cleanly
// and that final offsets are committed.
c.Close();
}
}
}
Cet exemple de code produit les résultats suivants :

Dans ce cas, la rubrique comporte quatre partitions. Plusieurs événements ont eu lieu :
- Le producteur a envoyé 10 messages, chacun dépourvu de clé de partition.
- Les messages sont arrivés dans les partitions suivant un ordre aléatoire.
- Un seul consommateur a écouté les quatre partitions et reçu les messages dans le désordre.
Si le code avait utilisé deux instances du consommateur, chacune d’elles se serait abonnée à deux des quatre partitions.
Distribution des messages à une partition donnée
Cet exemple porte sur des messages d’erreur. Supposons que certaines applications doivent traiter les messages d’erreur, mais que tous les autres messages puissent accéder à un consommateur commun. Dans ce cas, le producteur envoie les messages d’erreur à une partition donnée. Les consommateurs qui souhaitent les recevoir écoutent cette partition. Le code suivant illustre l’implémentation de ce scénario :
// Producer code.
var topicPartition = new TopicPartition(topic, partition);
...
p.Produce(topicPartition, new Message<Null, string> { Value = value });
// Consumer code.
// Subscribe to one partition.
c.Assign(new TopicPartition(topic, partition));
// Use this code to subscribe to a list of partitions.
c.Assign(new List<TopicPartition> {
new TopicPartition(topic, partition1),
new TopicPartition(topic, partition2)
});
Comme le montrent ces résultats, le producteur a envoyé tous les messages à la partition 2, et le consommateur ne lit que les messages de la partition 2 :
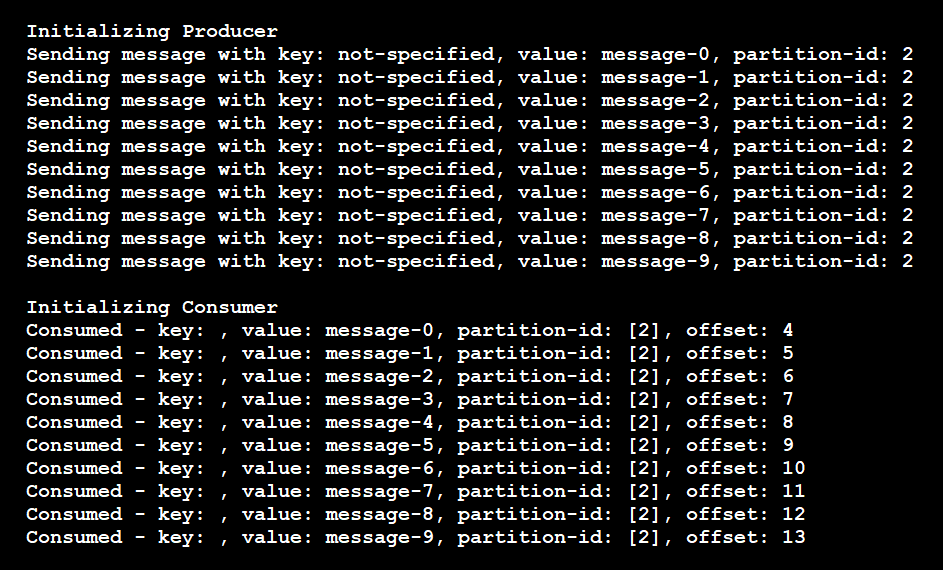
Dans ce scénario, si vous ajoutez une autre instance de consommateur pour écouter cette rubrique, le pipeline ne lui attribuera aucune partition. Le nouveau consommateur sera privé jusqu’à ce que le consommateur existant s’arrête. Le pipeline attribuera alors un autre consommateur actif pour lire les messages sur la partition. Toutefois, le pipeline n’effectuera cette attribution que si le nouveau consommateur n’est pas dédié à une autre partition.
Conservation de l’ordre des événements
Cet exemple porte sur des opérations bancaires qu’un consommateur doit traiter dans l’ordre. Dans ce scénario, vous pouvez utiliser l’ID client de chaque événement comme clé. En ce qui concerne la valeur de l’événement, prenez les informations relatives à l’opération. Le code suivant illustre une implémentation simplifiée de ce cas de figure :
Producer code
// This code assigns the key an integer value. You can also assign it any other valid key value.
using (var p = new ProducerBuilder<int, string>(producerConfig).Build())
...
p.Produce(topic, new Message<int, string> { Key = i % 2, Value = value });
Ce code produit les résultats suivants :
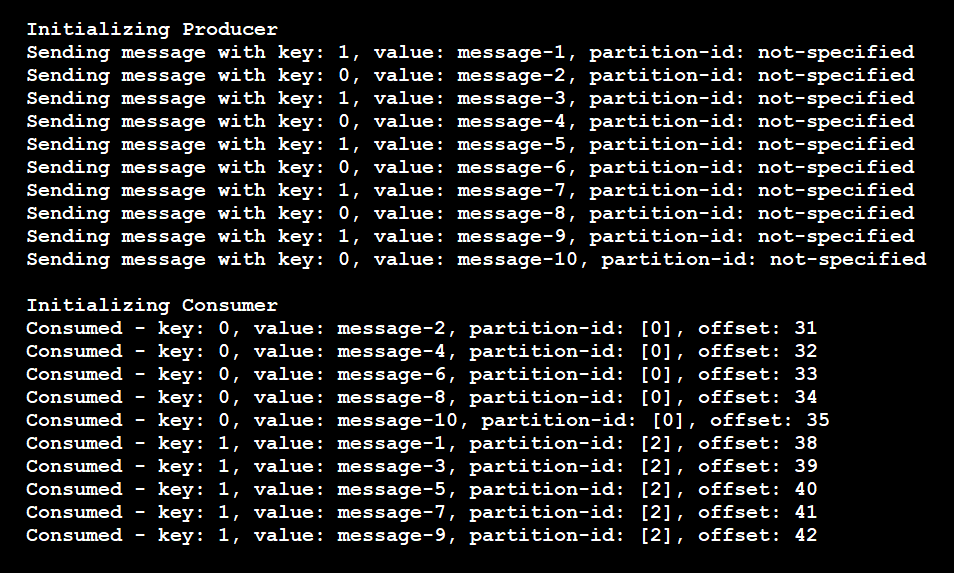
Comme le montrent ces résultats, le producteur n’a utilisé que deux clés uniques. Les messages n’ont alors été distribués qu’à deux partitions au lieu de quatre. Le pipeline permet de garantir que les messages possédant la même clé sont dirigés vers la même partition.
Contributeurs
Cet article est géré par Microsoft. Il a été écrit à l’origine par les contributeurs suivants.
Auteur principal :
- Rajasa Savant | Ingénieur de développement logiciel senior
Pour afficher les profils LinkedIn non publics, connectez-vous à LinkedIn.
Étapes suivantes
- Utiliser Azure Event Hubs à partir d’applications Apache Kafka
- Guide du développeur Apache Kafka pour Azure Event Hubs
- Démarrage rapide : Streaming de données avec Event Hubs en utilisant le protocole Kafka
- Réception d’événements en provenance et à destination d’Azure Event Hubs – .NET (Azure.Messaging.EventHubs)
- Équilibrer la charge de partition sur plusieurs instances de votre application
- Ajouter dynamiquement des partitions à un Event Hub (rubrique Apache Kafka) dans Azure Event Hubs
- Disponibilité et cohérence dans Event Hubs
- Bibliothèque de client du processeur d’événements Azure Event Hubs pour .NET
- Stratégies efficaces de partitionnement des rubriques Kafka
- Billet de blog Confluent : comment choisir le nombre de rubriques/partitions dans un cluster Kafka ?
Ressources associées
- Intégrer Event Hubs avec des fonctions serverless sur Azure
- Performances et mise à l’échelle pour Event Hubs et Azure Functions
- Style d’architecture basée sur les événements
- Traitement de flux de données avec des moteurs de données open source complètement managés
- Modèle éditeur-abonné
- Scénarios open source Apache sur Azure - Apache Kafka