Tâches élastiques dans Azure SQL Database
S’applique à ![]() Azure SQL Database
Azure SQL Database
Dans cet article, nous évaluons les capacités et les détails des tâches élastiques pour Azure SQL Database.
- Pour un tutoriel sur la configuration des tâches élastiques, reportez-vous au tutoriel sur les tâches élastiques.
- En savoir plus sur les concepts d'automation dans les plateformes de base de données Azure.
Aperçu des tâches élastiques
Vous pouvez créer et planifier des travaux élastiques qui s’exécutent périodiquement sur une ou plusieurs bases de données Azure SQL afin d’exécuter des requêtes T-SQL (Transact-SQL) et d’effectuer des tâches de maintenance.
Vous pouvez définir la base de données ou les groupes de bases de données cibles où le travail sera exécuté, et aussi définir des planifications pour l’exécution d’un travail. Toutes les dates et heures mentionnées pour les tâches élastiques se rapportent au fuseau horaire UTC.
Un travail gère la tâche de connexion à la base de données cible. Vous pouvez également définir, gérer et conserver des scripts Transact-SQL à exécuter sur un groupe de bases de données.
Chaque tâche consigne l’état de l’exécution et retente également automatiquement les opérations en cas d’échec.
Quand utiliser des travaux élastiques ?
Vous pouvez utiliser l’automatisation des travaux élastiques dans plusieurs scénarios :
- Automatiser des tâches de gestion et les planifier pour qu’elles s’exécutent tous les jours ouvrés, en dehors des heures d’ouverture, etc.
- Déployez les modifications de schéma, la gestion des informations d'identification.
- Collection de données de performances ou collection de données de télémétrie client (client).
- Mettre à jour les données de référence (informations communes à toutes les bases de données).
- Charger des données à partir de Stockage Blob Azure
- Configurer des travaux de manière à ce qu’ils s’exécutent sur une collection de bases de données de façon récurrente, par exemple pendant les heures creuses.
- Collecter les résultats de la requête à partir d'un ensemble de bases de données dans une table centrale sur une base continue.
- Les requêtes peuvent être exécutées en permanence et configurées pour déclencher des tâches supplémentaires à exécuter.
- Collecter des données de création de rapports
- Agréger des données provenant d’une collection de bases de données dans une table de destination unique.
- Exécuter des requêtes de traitement de données avec un temps d’exécution plus long sur un grand ensemble de bases de données, par exemple, la collection de télémétrie de client. Les résultats sont rassemblés dans une table de destination unique pour une analyse ultérieure.
- Déplacement des données
- Pour des solutions développées et personnalisées, l'automatisation des opérations ou d'autres formes de gestion des tâches.
- Traitement ETL pour extraire/traiter/insérer des données entre des tables d'une base de données.
Envisagez d'utiliser des tâches élastiques lorsque vous :
- avez une tâche qui doit être exécutée régulièrement selon un planificateur, ciblant une ou plusieurs bases de données.
- avez une tâche à exécuter une seule fois, sur plusieurs bases de données.
- devez exécuter des tâches sur toute combinaison de bases de données : une ou plusieurs bases de données individuelles, toutes les bases de données sur un serveur, toutes les bases de données dans un pool élastique, avec la flexibilité supplémentaire d'inclure ou d'exclure une base de données spécifique. Les travaux peuvent s’exécuter sur plusieurs serveurs, plusieurs pools et même sur des bases de données dans différents abonnements. Les serveurs et les pools sont énumérés dynamiquement au moment de l’exécution, ce qui permet aux travaux de s’exécuter sur toutes les bases de données présentes dans le groupe cible au moment de l’exécution.
- La différence est importante par rapport à SQL Agent, qui ne peut pas énumérer dynamiquement les bases de données cibles, en particulier dans les scénarios de clients SaaS où les bases de données sont ajoutées/supprimées de manière dynamique.
Composants des travaux élastiques
| Composant | Description |
|---|---|
| Agent de tâche élastique | Ressource Azure que vous créez pour exécuter et gérer des travaux. |
| Base de données de travaux | Base de données dans Azure SQL Database qui est utilisée par l’agent de travail pour stocker les données associées aux travaux, les définitions des travaux, etc. |
| Travail | Un travail est une unité de travail composée d’une ou plusieurs étapes de travail. Celles-ci spécifient le script T-SQL à exécuter, ainsi que d’autres détails nécessaires pour exécuter le script. |
| Groupe cible | Ensemble de serveurs, de pools et de bases de données sur lesquels un travail s’exécute. |
Agent de travail élastique
Un agent de tâche élastique est la ressource Azure qui permet de créer, d'exécuter et de gérer des tâches. L'agent de tâche élastique est une ressource Azure que vous créez dans le portail (PowerShell et API REST sont également pris en charge).
La création d'un agent de tâche élastique nécessite l'existence d'une base de données dans Azure SQL Database. L'agent configure cette base de données Azure SQL existante comme base de données de tâches.
Vous pouvez démarrer, désactiver ou annuler une tâche à travers le portail Azure. Le portail Azure vous permet également d'afficher les définitions des tâches et l'historique d'exécution.
Coût de l'agent de tâche élastique
La base de données de travaux est facturée au même tarif que les autres bases de données dans Azure SQL Database. Pour connaître le coût de l'agent de tâche élastique, consultez la Calculette de prix Azure.
Base de données de travaux élastiques
La base de données des tâches est utilisée pour définir les tâches et suivre l'état et l'historique de leur exécution. Les tâches sont exécutées dans les bases de données cibles. La base de données des tâches est également utilisée pour stocker les métadonnées des agents, les journaux d'activité, les résultats et les définitions du travail. Elle contient également de nombreuses procédures stockées et d'autres objets de base de données utiles pour créer, exécuter et gérer des tâches à l'aide de T-SQL.
Azure SQL Database (S1 ou supérieure) est recommandée pour créer un agent de tâches élastiques.
La base de données des tâches doit être une base de données Azure SQL Database propre, vide, avec un objet du service S1 ou supérieur.
L'objectif de service recommandé pour la base de données des tâches est S1 ou plus. Cependant, le choix optimal dépend des besoins de performance de vos tâches : le nombre d'étapes des tâches, le nombre de cibles des tâches et la fréquence d'exécution des tâches.
Si les opérations sur la base de données de travaux sont plus lentes que prévu, supervisez les performances de la base de données et l’utilisation des ressources dans la base de données de travaux pendant les périodes de lenteur en utilisant le portail Azure ou la vue de gestion dynamique sys.dm_db_resource_stats. Si l’utilisation d’une ressource, telle que le processeur, les E/S de données ou l’écriture de journal, approche 100 % et correspond aux périodes de lenteur, envisagez de mettre la base de données à l’échelle de manière incrémentielle pour atteindre des objectifs de service plus élevés (dans le modèle DTU ou dans le modèle vCore) jusqu’à ce que les performances de la base de données de travaux soient satisfaisantes.
Important
Ne modifiez pas les objets existants et n'en créez pas de nouveaux dans la base de données des tâches, quoique vous puissiez lire les tables à des fins de compte-rendu et d'analyse.
Travaux élastiques et étapes de travail
Un travail est un élément unitaire exécuté selon une planification ou de manière ponctuelle. Un travail est constitué d’une ou plusieurs étapes de travail.
Chaque étape de travail spécifie un script T-SQL à exécuter, un ou plusieurs groupes cibles sur lesquels exécuter le script T-SQL, ainsi que les informations d’identification dont l’agent de travail a besoin pour se connecter à la base de données cible. Chaque étape de travail est associée à un délai d’expiration et à des stratégies de nouvelle tentative personnalisables, et peut éventuellement spécifier des paramètres de sortie.
Cibles de travaux élastiques
Les tâches élastiques permettent d'exécuter un ou plusieurs scripts T-SQL en parallèle sur un grand nombre de bases de données, selon une planification ou à la demande. L'objectif peut être n'importe quel niveau d'Azure SQL Database.
Vous pouvez exécuter des travaux sur la combinaison de bases de données de votre choix : une ou plusieurs bases de données individuelles, toutes les bases de données d’un serveur, toutes les bases de données dans un pool élastique, avec la possibilité d’inclure ou d’exclure des bases de données spécifiques. Les travaux peuvent s’exécuter sur plusieurs serveurs, plusieurs pools et même sur des bases de données dans différents abonnements. Les serveurs et les pools sont énumérés dynamiquement au moment de l’exécution, ce qui permet aux travaux de s’exécuter sur toutes les bases de données présentes dans le groupe cible au moment de l’exécution.
L’image suivante montre un agent de travail qui exécute des travaux sur les différents types de groupes cibles :
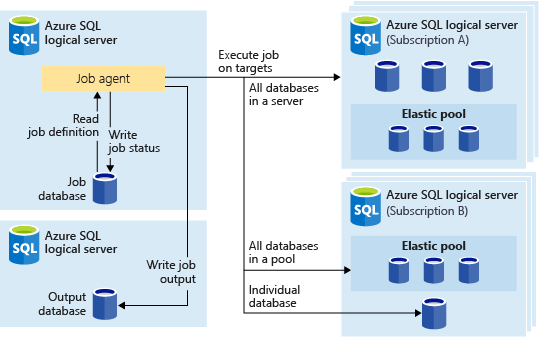
Groupe cible
Un groupe cible définit l’ensemble de bases de données sur lequel une étape de travail s’exécute. Un groupe cible peut contenir les éléments suivants, dont le nombre et la combinaison peuvent varier :
- Serveur SQL logique : si un serveur est spécifié, toutes les bases de données présentes sur le serveur au moment de l’exécution du travail font partie du groupe. Les informations d’identification de la base de données
masterdoivent être fournies pour que le groupe puisse être énuméré et mis à jour avant l’exécution du travail. Pour plus d’informations sur les serveurs logiques, consultez Qu’est-ce qu’un serveur dans Azure SQL Database et Azure Synapse Analytics ?. - Pool élastique : si un pool élastique est spécifié, toutes les bases de données qui se trouvent dans ce pool au moment de l’exécution du travail font partie du groupe. Au même titre qu’un serveur, les informations d’identification de la base de données
masterdoivent être fournies pour que le groupe puisse être mis à jour avant l’exécution du travail. - Base de données unique : spécifiez une ou plusieurs bases de données individuelles à inclure dans le groupe.
Conseil
Au moment de l’exécution du travail, l’énumération dynamique réévalue l’ensemble des bases de données dans les groupes de cibles qui incluent des serveurs ou des pools. L’énumération dynamique garantit que les travaux s’exécutent sur toutes les bases de données qui existent dans le serveur ou le pool au moment de l’exécution du travail. La réévaluation de la liste des bases de données au moment de l’exécution est particulièrement utile dans les scénarios où l’appartenance au pool ou au serveur change fréquemment.
Il est possible de désigner des pools et des bases de données uniques comme faisant partie ou non du groupe. Vous pouvez ainsi créer un groupe cible avec n’importe quelle combinaison de bases de données. Par exemple, vous pouvez ajouter un serveur à un groupe cible, mais exclure certaines bases de données d’un pool élastique (ou exclure un pool entier).
Un groupe cible peut inclure des bases de données dans plusieurs abonnements et dans plusieurs régions. Les exécutions entre régions ont une latence plus élevée que celles au sein d'une même région.
Les exemples suivants montrent comment différentes définitions de groupes cibles sont énumérées dynamiquement au moment de l’exécution du travail pour déterminer les bases de données qui seront exécutées par le travail :
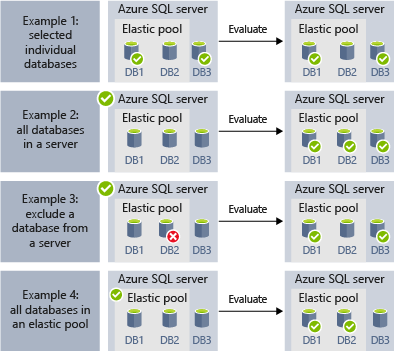
- L’exemple 1 montre un groupe cible se composant d’une liste de bases de données individuelles. Lorsqu’une étape de travail est exécutée à l’aide de ce groupe cible, l’action de l’étape de travail sera exécutée dans chacune de ces bases de données.
- L’exemple 2 montre un groupe cible qui contient un serveur comme cible. Lorsqu’une étape de travail est exécutée à l’aide de ce groupe cible, le serveur est énuméré dynamiquement pour déterminer la liste des bases de données qui se trouvent actuellement dans le serveur. L’action de l’étape de travail sera exécutée dans chacun de ces bases de données.
- L’exemple 3 montre un groupe cible similaire à l’exemple 2, mais une base de données individuelle est explicitement exclue. L’action de l’étape de travail ne sera pas exécutée dans la base de données exclue.
- L’exemple 4 montre un groupe cible qui contient un pool élastique comme cible. Semblable à exemple 2, le pool est énuméré dynamiquement à l’exécution du travail pour déterminer la liste des bases de données dans le pool.
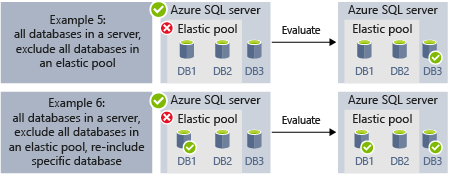
- L’exemple 5 et l’exemple 6 montrent des scénarios avancés où les serveurs, les pools élastiques et les bases de données peuvent être combinés avec des règles d’inclusion et d’exclusion.
Notes
La base de données d'une tâche peut être la cible d'une tâche. Dans ce scénario, la base de données de tâches est traitée comme toute autre base de données cible. L'utilisateur de la tâche doit être créé et disposer d'autorisations suffisantes dans la base de données des tâches. De même, les informations d'identification délimitées à la base de données de l'utilisateur de la tâche doivent également exister dans la base de données des tâches, comme pour toute autre base de données cible.
Authentification
Choisissez une méthode pour toutes les cibles d'un agent de tâche élastique. Par exemple, pour un seul agent de tâche élastique, vous ne pouvez pas configurer un serveur cible pour utiliser des informations d'identification délimitées à la base de données et une autre pour utiliser l'authentification Microsoft Entra ID.
L'agent de tâche élastique peut se connecter au ou aux serveurs/bases de données spécifiés par le groupe cible via deux options d'authentification :
- Utilisez l'authentification Microsoft Entra (anciennement Azure Active Directory) avec une identité managée affectée par l'utilisateur (UMI).
- Utilisez des informations d'identification délimitées à la base de données.
Authentification via identité managée affectée par l'utilisateur (UMI)
L'authentification Microsoft Entra (anciennement Azure Active Directory) via l'identité managée affectée par l'utilisateur (UMI) est l'option recommandée pour connecter des tâches élastiques à Azure SQL Database. Avec la prise en charge de Microsoft Entra ID, l'agent de tâche pourra se connecter aux bases de données cibles (bases de données, serveurs, pools élastiques) et aux bases de données de sortie à l'aide de l'UMI.

Si vous le souhaitez, l'authentification Microsoft Entra ID peut également être activée sur le serveur logique contenant la base de données de tâches élastiques, pour accéder à/interroger cette base de données via des connexions Microsoft Entra ID. Toutefois, l'agent de la tâche lui-même utilise l'authentification interne basée sur des certificats pour se connecter à sa base de données des tâches.
Vous pouvez créer une UMI ou utiliser une UMI existante et affecter la même UMI à plusieurs agents de tâche. Une seule UMI est prise en charge par agent de tâche. Une fois qu'une UMI est affectée à un agent de tâche, cet agent de tâche utilise uniquement cette identité pour se connecter et exécuter des tâches t-SQL sur les bases de données cibles. L'authentification SQL ne sera pas utilisée sur le serveur/les bases de données cibles de cet agent de tâche.
Le nom de l'UMI doit commencer par une lettre ou un nombre et avec une longueur comprise entre 3 et 128. Il peut contenir les caractères - et _.
Pour plus d'informations sur UMI dans Azure SQL Database, reportez-vous à Identités managées pour Azure SQL, notamment les étapes requises et les avantages de l'utilisation d'une UMI comme identité de serveur logique Azure SQL Database. Pour plus d'informations, reportez-vous à Utiliser Microsoft Entra (anciennement Azure Active Directory) pour s'authentifier sur des plateformes Azure SQL.
Important
Lorsque vous utilisez l'authentification Microsoft Entra ID, créez votre utilisateur jobuser à partir de ce Microsoft Entra ID dans chaque base de données cible. Accordez à cet utilisateur les autorisations nécessaires pour exécuter votre ou vos tâches dans chaque base de données cible.
L'identité managée affectée par le système (SMI) n'est pas prise en charge.
Authentification via des informations d'identification délimitées à la base de données
Bien que l'authentification Microsoft Entra (anciennement Azure Active Directory) soit l'option recommandée, les tâches peuvent être configurées pour utiliser des informations d'identification délimitées à la base de données pour se connecter aux bases de données spécifiées par le groupe cible lors de l'exécution. Avant octobre 2023, les informations d'identification délimitées à la base de données étaient la seule option d'authentification.
Si un groupe cible contient des serveurs ou des pools, ces informations d'identification délimitées à la base de données sont utilisées pour se connecter à la base de données master afin d'énumérer les bases de données disponibles.
- Ces informations d'identification limitées à la base de données doivent être créées dans la base de données des tâches.
- Toutes les bases de données cibles doivent disposer d'informations de connexion avec des autorisations suffisantes pour que l'exécution de la tâche réussisse (
jobuserdans le diagramme suivant). - Les informations d'identification créées dans les bases de données cibles (
LOGINetPASSWORDpourmasteruseretjobuser, das le diagramme suivant) doivent correspondre àIDENTITYetSECRETdans les informations d'identification créées dans la base de données des tâches. - Les informations d’identification peuvent être réutilisées dans différents travaux, et les mots de passe associés sont chiffrés et sécurisés pour que les utilisateurs ayant accès en lecture seule aux objets de travail ne puissent pas y accéder.
L'image suivante est conçue pour vous aider à comprendre la configuration des informations d'identification de tâche appropriées et la façon dont l'agent de tâche élastique se connecte à l'aide d'informations d'identification de base de données comme authentification pour les connexions/utilisateurs dans les serveurs/bases de données cibles.

Remarque
Lorsque vous utilisez des informations d'identification délimitées à la base de données, n'oubliez pas de créer votre utilisateur jobuser dans chaque base de données cible.
Points de terminaison privés de tâches élastiques
L'agent de tâche élastique prend en charge les points de terminaison privés de tâches élastiques. La création d'un point de terminaison privé de tâches élastiques établit une liaison privée entre la tâche élastique et le serveur cible. La fonctionnalité de points de terminaison privés des tâches élastiques diffère d'Azure Private Link.

La fonctionnalité points de terminaison privés de tâches élastiques prend en charge les connexions privées aux serveurs cible/sortie, de sorte que l'agent de tâche peut toujours les atteindre même lorsque l'option « Refuser l'accès public » est activée. L'utilisation de points de terminaison privés est également une solution possible si vous souhaitez désactiver l'option « Autoriser les services et ressources Azure à accéder à ce serveur ».
Les points de terminaison privés de tâches élastiques prennent en charge toutes les options d'authentification de l'agent de tâche élastique.
La fonctionnalité de point de terminaison privé de tâche élastique vous permet de choisir un point de terminaison privé managé par le service pour établir une connexion sécurisée entre l'agent de tâche et ses serveurs cible/sortie. Un point de terminaison privé géré par le service est une adresse IP privée au sein d’un réseau et d’un sous-réseau virtuels spécifiques. Lorsque vous choisissez d'utiliser des points de terminaison privés sur l'un des serveurs cible/sortie de votre agent de tâche, un point de terminaison privé managé par le service est créé par Microsoft. Ce point de terminaison privé est ensuite utilisé exclusivement par l'agent de tâche pour la connexion et l'exécution de tâches, ou pour écrire la sortie de la tâche sur ces bases de données cible/sortie.
Les points de terminaison privés de tâches élastiques peuvent être créés et autorisés via le Portail Azure. Les serveurs cibles connectés via la liaison privée peuvent se trouver n'importe où dans Azure, même dans différentes zones géographiques et différents abonnements. Vous devez créer un point de terminaison privé pour chaque serveur cible souhaité et pour le serveur de sortie de tâche pour activer cette communication.
Pour obtenir un tutoriel sur la configuration d'un nouveau point de terminaison privé géré par le service pour les tâches élastiques, reportez-vous à Configurer un point de terminaison privé de tâches élastiques Azure SQL.
Configuration requise pour les points de terminaison privés de tâches élastiques
- Pour utiliser un point de terminaison privé des tâches élastiques, l'agent de tâches et les serveurs/bases de données cibles doivent être hébergés dans Azure (dans la même région ou dans des régions différentes) et dans le même type de cloud (par exemple, tous deux dans le cloud public ou tous deux dans le cloud gouvernemental).
- Le fournisseur de ressources
Microsoft.Networkdoit être inscrit pour les abonnements hôtes de l'agent de tâche et des serveurs cible/de sortie. - Les points de terminaison privés de tâches élastiques sont créés par serveur cible/de sortie. Ces points de terminaison doivent être approuvés avant que l'agent de tâche élastique puisse les utiliser. Vous pouvez effectuer cette opération via le volet Mise en réseau de ce serveur logique ou de votre client préféré. L'agent de tâche élastique sera alors en mesure d'atteindre toutes les bases de données sous ce serveur à l'aide d'une connexion privée.
- La connexion depuis l'agent de tâche élastique à la base de données des tâches n'utilise pas de point de terminaison privé. L'agent de tâche lui-même utilise l'authentification interne basée sur des certificats pour se connecter à sa base de données des tâches. Attention : cela vaut si vous ajoutez la base de données des tâches en tant que membre de groupe cible. Ensuite, il se comporte comme une cible régulière que vous devrez configurer avec un point de terminaison privé si nécessaire.
Autorisations de la base de données de travaux élastiques
Durant la création de l'agent de tâche, un schéma, des tables et un rôle appelé jobs_reader sont créés dans la base de données des tâches. Le rôle, créé avec l'autorisation suivante, est conçu pour permettre aux administrateurs de contrôler plus précisément les accès aux tâches à des fins de surveillance : Les administrateurs peuvent donner aux utilisateurs la possibilité de surveiller l'exécution de la tâche en les ajoutant au rôle jobs_reader dans la base de données des tâches.
| Nom de rôle | Autorisations de schéma « jobs » | Autorisations de schéma « jobs_internal » |
|---|---|---|
| jobs_reader | SELECT | Aucun |
Attention
Vous ne devez pas mettre à jour les affichages catalogue internes dans la base de données des tâches, comme jobs.target_group_members. Les modifications manuelles de ces affichages catalogue peuvent endommager la base de données des tâches et provoquer une défaillance. Ces vues sont destinées aux requêtes en lecture seule. Vous pouvez utiliser les procédures stockées sur votre base de données des tâches pour ajouter/supprimer des groupes/membres cibles, comme jobs.sp_add_target_group_member.
Important
Tenez compte des implications en matière de sécurité avant d'accorder un niveau d'accès élevé à la base de données des tâches. Un utilisateur malveillant disposant d'autorisations appropriées peut créer ou modifier une tâche utilisant des informations d'identification stockées pour se connecter à une base de données, ce qui peut ensuite lui permettre d'identifier le mot de passe des informations d'identification ou d'exécuter des commandes malveillantes.
Surveiller des tâches élastiques
À compter d'octobre 2023, l'agent de tâche élastique est intégré aux alertes Azure pour les notifications d'état de la tâche, ce qui facilite l'utilisation de la solution pour surveiller l'état et l'historique de l'exécution de la tâche.
Le portail Azure dispose également de nouvelles fonctionnalités pour prendre en charge les tâches élastiques et la surveillance des tâches. Sur la page de présentation de l'agent Elastic job, les exécutions de tâches les plus récentes sont affichées, comme le montre la capture d'écran suivante.

Vous pouvez créer des règles d'alerte Azure Monitor avec Portail Azure, Azure CLI, PowerShell et API REST. La métrique Tâches élastiques ayant échoué est un bon point de départ pour surveiller et recevoir des alertes sur l'exécution de tâches élastiques. En outre, vous pouvez choisir d'être alerté par le biais d'une action configurable comme le SMS ou l'e-mail en installant Azure Alert. Pour plus d'informations, reportez-vous à Créer des alertes pour la base de données Azure SQL dans le portail Azure.
Pour un exemple, reportez-vous à Créer, configurer et gérer des tâches élastiques..
Sortie du travail
Les résultats des étapes d’un travail sur chaque base de données sont enregistrés en détail, et la sortie du script peut être capturée dans une table spécifiée. Vous pouvez aussi indiquer une base de données pour enregistrer toutes les données retournées par un travail.
Historique des travaux
Visualisez l'historique de l'exécutiondes tâches élastiques dans la base de données des tâches en interrogeant la table jobs.job_executions. Un travail de nettoyage système vide les éléments de l’historique d’exécution qui datent de plus de 45 jours. Pour supprimer manuellement l'historique datant de moins de 45 jours, exécutez la procédure stockée sp_purge_jobhistory dans la base de données des tâches.
Statut de tâche
Vous pouvez surveiller l'exécution des tâches élastiques dans la base de données des tâches en interrogeant la table jobs.job_executions.
Bonnes pratiques
Tenez compte des meilleures pratiques suivantes lorsque vous utilisez des tâches de base de données élastique :
Bonnes pratiques de sécurité
- Limitez l'utilisation des API aux personnes de confiance.
- Les informations d’identification doivent avoir les privilèges minimaux nécessaires pour effectuer l’étape de travail. Pour plus d'informations, consultez Autorisations et permissions.
- Quand vous utilisez un membre d’un groupe cible d’un serveur et/ou d’un pool, il est fortement recommandé de créer des informations d’identification distinctes avec des droits sur la base de données
masterpour afficher/lister les bases de données afin de développer les listes de bases de données du ou des serveurs/pools avant l’exécution du travail.
Performances des tâches élastiques
Les tâches élastiques utilisent des ressources de calcul minimales dans l'attente de la finalisation des tâches de longue durée.
En fonction de la taille du groupe cible de bases de données et du délai d'exécution souhaité d'une tâche (nombre de workers simultanés), l'agent nécessite différents niveaux de calcul et de performance de la part de la base de données de tâches (plus le nombre de cibles et de tâches est élevé, plus les calculs nécessaires sont importants).
Niveaux de capacité de simultanéité
À compter d'octobre 2023, l'agent de tâche élastique dispose de plusieurs niveaux de performances pour permettre l'augmentation de la capacité.
Les incréments de capacité indiquent le nombre total de bases de données cibles simultanées auxquels l'agent de tâche peut se connecter et démarrer une tâche. Pour plus de connexions cibles simultanées pour l'exécution de tâches, mettez à niveau le niveau d'un agent de tâche à partir du niveau JA100 par défaut, qui a une limite de 100 connexions cibles simultanées.
La plupart des environnements nécessitent moins de 100 tâches simultanées à tout moment. Par conséquent, JA100 est la valeur par défaut.
| Niveau agent de tâche élastique | Nombre maximal de tâches simultanées |
|---|---|
| JA100 | 100 |
| JA200 | 200 |
| JA400 | 400 |
| JA800 | 800 |
Tout dépassement du niveau de capacité de simultanéité de l'agent de tâches avec les cibles de tâches entraînera des retards dans les files d'attente pour certaines bases de données/serveurs cibles. Par exemple, si vous démarrez une tâche avec 110 cibles dans le niveau JA100, l'exécution de 10 tâches attendra la fin des autres tâches avant de commencer.
Le niveau ou l'objectif du niveau d'un agent de tâche élastique peut être modifié via le portail Azure, PowerShell ou les agents de tâche API REST. Pour voir un exemple, reportez-vous à Mettre à l'échelle l'agent de tâche.
Limiter l'impact de la tâche sur les pools élastiques
Pour éviter la surcharge des ressources durant l'exécution de tâches sur des bases de données dans un pool élastique de base de données Azure SQL, vous pouvez configurer les tâches de manière à limiter le nombre de bases de données sur lesquelles un projet peut s'exécuter simultanément.
Définissez le nombre de bases de données simultanées sur lesquelles un travail s’exécute en définissant le paramètre @max_parallelism de la procédure stockée sp_add_jobstepdans T-SQL.
Scripts idempotents
Les scripts T-SQL d'une tâche élastique doivent être idempotent. Idempotent signifie que si le script réussit et qu’il est réexécuté, le résultat sera le même. Un script peut échouer en raison de problèmes réseau passager. Dans ce cas, le travail va automatiquement refaire des tentatives d’exécution du script un nombre prédéfini de fois. Un script idempotent a le même résultat, même s’il a été exécuté deux fois (ou plus) avec succès.
Une tactique simple consiste à tester l’existence d’un objet avant de créer ce dernier. Voici un exemple hypothétique :
IF NOT EXISTS (SELECT * FROM sys.objects WHERE [name] = N'some_object')
print 'Object does not exist'
-- Create the object
ELSE
print 'Object exists'
-- If it exists, drop the object before recreating it.
De même, un script doit être capable d’exécuter avec succès par une vérification logique et s’adapter aux conditions qu’il rencontre.
Limites
Il s'agit des limitations actuelles du service de tâches élastiques. Nous travaillons activement à la suppression d’un maximum de ces limitations.
| Problème | Description |
|---|---|
| L'agent de tâches élastiques doit être recréé et démarré dans la nouvelle région après un basculement/déplacement vers une nouvelle région Azure. | Le service de tâches élastiques stocke l'ensemble de son agent de tâche et des métadonnées de tâches dans la base de données des tâches. Tout basculement ou déplacement de ressources Azure vers une nouvelle région Azure déplace également les métadonnées de la base de données des tâches, de l’agent de travail et des tâches vers la nouvelle région Azure. Toutefois, l'agent de tâches élastiques est une ressource de calcul uniquement et doit être recréé et démarré explicitement dans la nouvelle région avant que les tâches commencent à s'exécuter dans la nouvelle région. Une fois démarré, l'agent de tâches élastiques reprend l'exécution des tâches dans la nouvelle région, conformément au calendrier des tâches défini précédemment. |
| Nombre excessif de journaux d'audit de la base de données des tâches | L'agent de tâches élastiques fonctionne en interrogeant constamment la base de données de tâches pour vérifier l'arrivée de nouvelles tâches et d'autres opérations CRUD. Si l'audit est activé sur le serveur qui héberge une base de données des tâches, un grand nombre de journaux d'audit peuvent être générés par la base de données des tâches. Cela peut être atténué en filtrant ces journaux d’audit à l’aide de la commande Set-AzSqlServerAudit avec une expression de prédicat.Par exemple : Set-AzSqlServerAudit -ResourceGroupName "ResourceGroup01" -ServerName "Server01" -BlobStorageTargetState Enabled -StorageAccountResourceId "/subscriptions/7fe3301d-31d3-4668-af5e-211a890ba6e3/resourceGroups/resourcegroup01/providers/Microsoft.Storage/storageAccounts/mystorage" -PredicateExpression "database_principal_name <> '##MS_JobAccount##'"Cette commande va filtrer uniquement l'agent de tâches sur les journaux d'audit des bases de données de tâches, et non sur tous les journaux d'audit des bases de données cibles. |
| Utilisation d'une base de données Hyperscale comme base de données de tâche | L'utilisation d'une base de données Hyperscale comme base de données de tâche n'est pas prise en charge. Toutefois, les travaux élastiques peuvent cibler des bases de données Hyperscale comme n’importe quelle autre base de données dans Azure SQL Database. |
| Bases de données serverless et mise en pause automatique avec des tâches élastiques. | La base de données serverless avec mise en pause automatique n'est pas prise en charge comme base de données de tâches. Les bases de données serverless ciblées par les travaux élastiques prennent en charge la mise en pause automatique et sont reprises à la connexion des travaux. |
| Exporter une base de données de travail vers un fichier BACPAC | L’exportation d’une base de données de travail vers un fichier BACPAC n’est pas prise en charge. Si le SQL Server qui contient une base de données de tâches doit être exporté, la base de données de tâches doit d'abord être supprimée avant d'exporter le serveur. |
Contenu connexe
- Créer, configurer et gérer des travaux élastiques
- Automatiser les tâches de gestion dans Azure SQL
- Créer et gérer des tâches élastiques à l’aide de PowerShell
- Créer et gérer des tâches élastiques à l'aide de T-SQL
Étape suivante
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour