Configurer un groupe de basculement pour Azure SQL Database
S’applique à ![]() Azure SQL Database
Azure SQL Database
Cet article explique comment configurer un groupe de basculement pour une base de données unique ou mise en pool dans la base de données Azure SQL à l’aide du portail Azure, Azure PowerShell et Azure CLI.
Pour les scripts de bout en bout, réviser comment ajouter une base de données unique à un groupe de basculement avec Azure PowerShell ou Azure CLI.
Prérequis
Tenez compte des conditions préalables suivantes pour la création de votre groupe de basculement pour une base de données unique :
- La connexion au serveur et les paramètres de pare-feu pour le serveur secondaire doivent correspondre à ceux de votre serveur principal.
Créer un groupe de basculement
Créez votre groupe de basculement et ajoutez-y votre base de données en utilisant le portail Azure.
Dans le menu de gauche du Portail Azure, sélectionnez Azure SQL. Si Azure SQL ne figure pas dans la liste, sélectionnez Tous les services, puis tapez « Azure SQL » dans la zone de recherche. (Facultatif) Sélectionnez l’étoile en regard d’Azure SQL pour l’ajouter aux favoris et l’ajouter en tant qu’élément dans le volet de navigation de gauche.
Sélectionnez la base de données que vous souhaitez ajouter au groupe de basculement.
Sélectionnez le nom du serveur sous Nom du serveur pour ouvrir les paramètres du serveur.

Sélectionnez Groupes de basculement dans le volet Paramètres, puis sélectionnez Ajouter un groupe pour créer un groupe de basculement.

Dans la page Groupe de basculement, entrez ou sélectionnez les valeurs requises, puis sélectionnez Créer. Vous pouvez soit créer un serveur secondaire, soit sélectionner un serveur secondaire existant. Le serveur secondaire du groupe de basculement doit se trouver dans une région différente du serveur principal.
- Base de données dans le groupe : Choisissez la base de données que vous souhaitez ajouter à votre groupe de basculement. L’ajout de la base de données au groupe de basculement démarre automatiquement le processus de géoréplication.
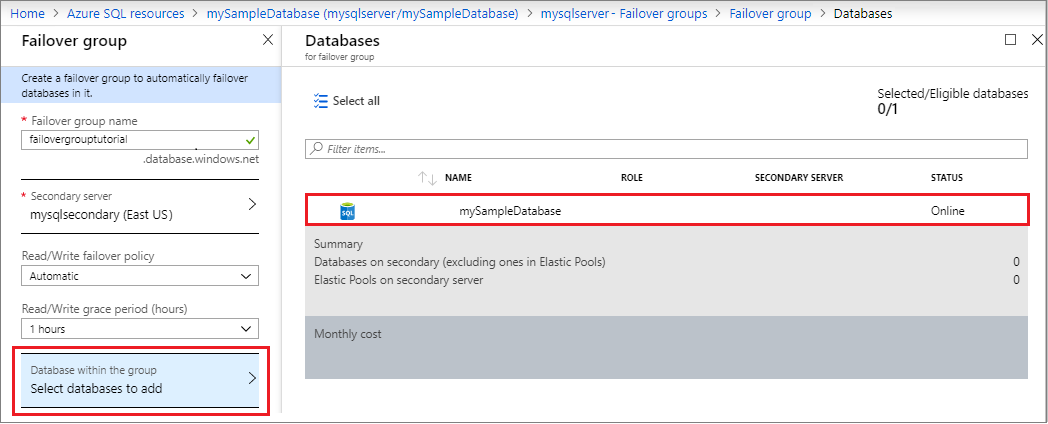
Tester le basculement planifié
Testez le basculement de votre groupe de basculement avec aucune perte de données à l’aide du portail Azure ou de PowerShell.
Testez le basculement de votre groupe de basculement à l’aide du portail Azure.
Dans le menu de gauche du Portail Azure, sélectionnez Azure SQL. Si Azure SQL ne figure pas dans la liste, sélectionnez Tous les services, puis tapez « Azure SQL » dans la zone de recherche. (Facultatif) Sélectionnez l’étoile en regard d’Azure SQL pour l’ajouter aux favoris et l’ajouter en tant qu’élément dans le volet de navigation de gauche.
Sélectionnez la base de données que vous souhaitez ajouter au groupe de basculement.
Sélectionnez Groupes de basculement dans le volet Paramètres, puis choisissez le groupe de basculement que vous venez de créer.
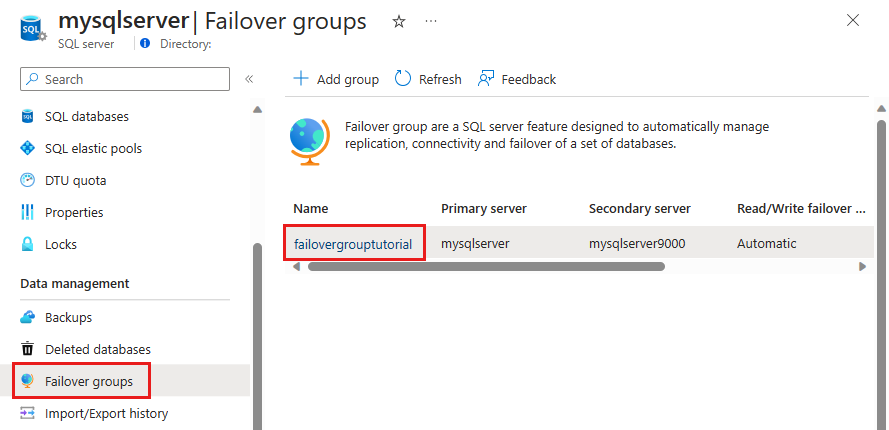
Vérifiez quel est le serveur principal et quel est le serveur secondaire.
Sélectionnez Basculement dans le volet des tâches pour faire basculer le groupe de basculement contenant votre base de données.
Sélectionnez Oui en réponse à l’avertissement qui signale que les sessions TDS seront déconnectées.
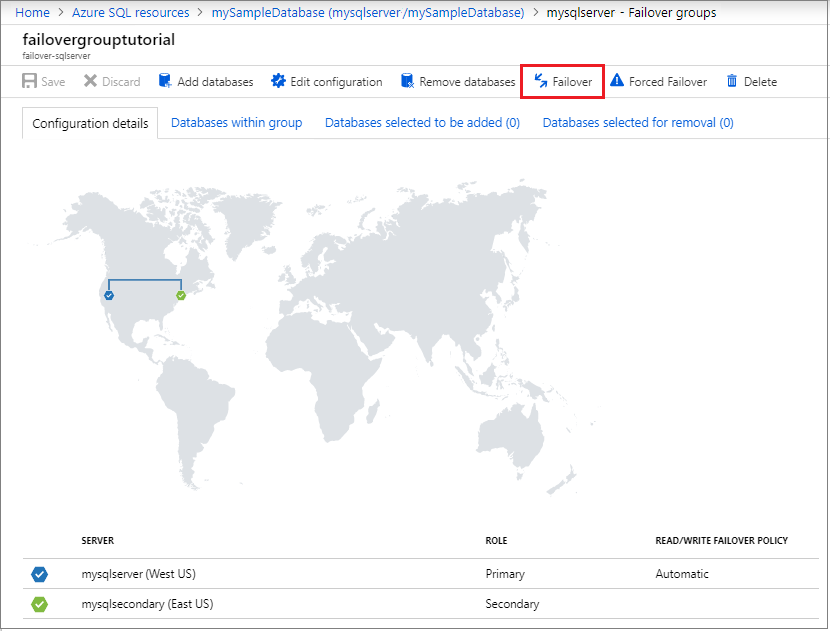
Vérifiez quel est maintenant le serveur principal et quel est le serveur secondaire. Si le basculement a réussi, les deux serveurs doivent avoir échangé leur rôle.
Resélectionnez Basculer pour rétablir les serveurs dans leur rôle d’origine.
Important
Si vous devez supprimer la base de données secondaire, retirez-la du groupe de basculement avant de la supprimer. La suppression d’une base de données secondaire avant son retrait du groupe de basculement peut entraîner un comportement imprévisible.
Pour les scripts de bout en bout, réviser comment ajouter un pool élastique à un groupe de basculement avec Azure PowerShell ou Azure CLI.
Prérequis
Tenez compte des conditions préalables suivantes pour la création de votre groupe de basculement pour une base de données mise en pool :
- La connexion au serveur et les paramètres de pare-feu pour le serveur secondaire doivent correspondre à ceux de votre serveur principal.
Créer un groupe de basculement
Créez le groupe de basculement pour votre pool élastique en utilisant le portail Azure ou PowerShell.
Créez votre groupe de basculement et ajoutez-y votre pool élastique en utilisant le portail Azure.
Dans le menu de gauche du Portail Azure, sélectionnez Azure SQL. Si Azure SQL ne figure pas dans la liste, sélectionnez Tous les services, puis tapez « Azure SQL » dans la zone de recherche. (Facultatif) Sélectionnez l’étoile en regard d’Azure SQL pour l’ajouter aux favoris et l’ajouter en tant qu’élément dans le volet de navigation de gauche.
Sélectionnez le pool élastique que vous souhaitez ajouter au groupe de basculement.
Dans le volet Vue d’ensemble, sélectionnez le nom du serveur sous Nom du serveur pour ouvrir les paramètres du serveur.
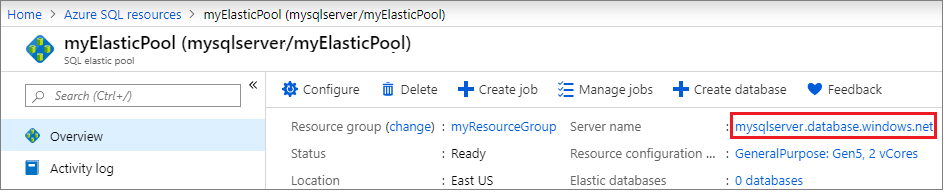
Sélectionnez Groupes de basculement dans le volet Paramètres, puis sélectionnez Ajouter un groupe pour créer un groupe de basculement.
Dans la page Groupe de basculement, entrez ou sélectionnez les valeurs requises, puis sélectionnez Créer. Vous pouvez soit créer un serveur secondaire, soit sélectionner un serveur secondaire existant.
Sélectionnez Base de données dans le groupe et sélectinnez le pool élastique que vous souhaitez ajouter au groupe de basculement. Si aucun pool élastique n’existe sur le serveur secondaire, un avertissement s’affiche pour vous inviter à y en créer un. Sélectionnez l’avertissement, puis cliquez sur OK pour créer le pool élastique sur le serveur secondaire.
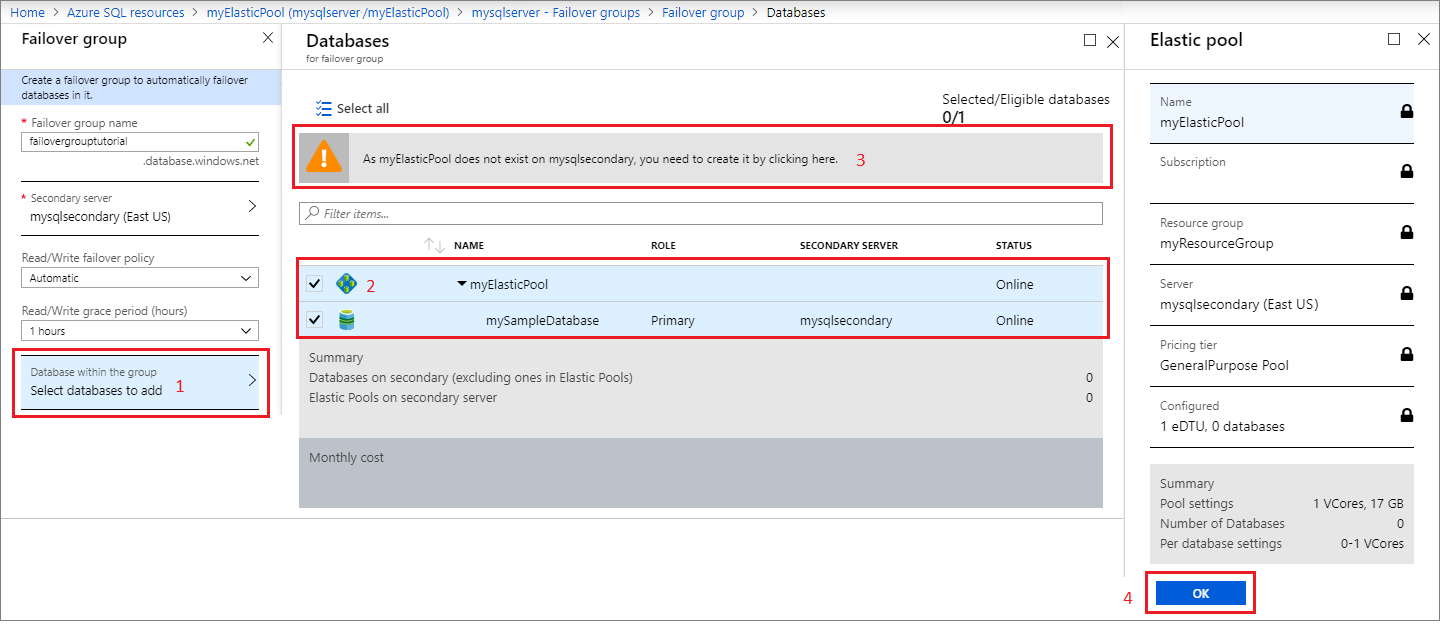
Utilisez Sélectionner pour appliquer les paramètres de votre pool élastique au groupe de basculement, puis sélectionnez Créer pour créer votre groupe de basculement. L’ajout du pool élastique au groupe de basculement démarre automatiquement le processus de géoréplication.
Tester le basculement planifié
Testez le basculement avec aucune perte de données de votre pool élastique à l’aide du portail Azure ou de PowerShell.
Faites basculer votre groupe de basculement sur le serveur secondaire, puis effectuez une restauration automatique en utilisant le portail Azure.
Dans le menu de gauche du Portail Azure, sélectionnez Azure SQL. Si Azure SQL ne figure pas dans la liste, sélectionnez Tous les services, puis tapez « Azure SQL » dans la zone de recherche. (Facultatif) Sélectionnez l’étoile en regard d’Azure SQL pour l’ajouter aux favoris et l’ajouter en tant qu’élément dans le volet de navigation de gauche.
Sélectionnez le pool élastique que vous souhaitez basculer.
Dans le volet Vue d’ensemble, sélectionnez le nom du serveur sous Nom du serveur pour ouvrir les paramètres du serveur.
Sélectionnez Groupes de basculement dans Paramètres, puis sélectionnez le groupe de basculement que vous avez créé.
Vérifiez quel est le serveur principal et quel est le serveur secondaire.
Sélectionnez Basculement dans le volet des tâches pour faire basculer votre groupe de basculement contenant votre pool élastique.
Sélectionnez Oui en réponse à l’avertissement qui signale que les sessions TDS seront déconnectées.
Vérifiez quel est le serveur principal et quel est le serveur secondaire. Si le basculement a réussi, les deux serveurs doivent avoir échangé leur rôle.
Sélectionnez Basculement à nouveau pour rétablir les paramètres d’origine du groupe de basculement.
Important
Si vous devez supprimer la base de données secondaire, retirez-la du groupe de basculement avant de la supprimer. La suppression d’une base de données secondaire avant son retrait du groupe de basculement peut entraîner un comportement imprévisible.
Utiliser Private Link
L’utilisation d’un lien privé vous permet d’associer un serveur logique à une adresse IP privée spécifique au sein du réseau virtuel et du sous-réseau.
Pour utiliser un lien privé avec votre groupe de basculement, procédez comme suit :
- Assurez-vous que vos serveurs principaux et secondaires se trouvent dans une région couplée.
- Créez le réseau virtuel et le sous-réseau dans chaque région pour héberger des points de terminaison privés pour les serveurs principaux et secondaires de sorte qu’ils aient des espaces d’adressage IP qui ne se chevauchent pas. Par exemple, la plage d’adresses de réseau virtuel principale 10.0.0.0/16 et la plage d’adresses de réseau virtuel secondaire de 10.0.0.1/16 se chevauchent. Pour plus d’informations sur les plages d’adresses de réseaux virtuels, consultez le blog Conception de réseaux virtuels Azure.
- Créez un point de terminaison privé et une zone de DNS privé Azure pour le serveur principal.
- Créez également un point de terminaison privé pour le serveur secondaire, mais cette fois, choisissez de réutiliser la même zone DNS privée que celle qui a été créée pour le serveur principal.
- Une fois le lien privé établi, vous pouvez créer le groupe de basculement en suivant les étapes décrites précédemment dans cet article.
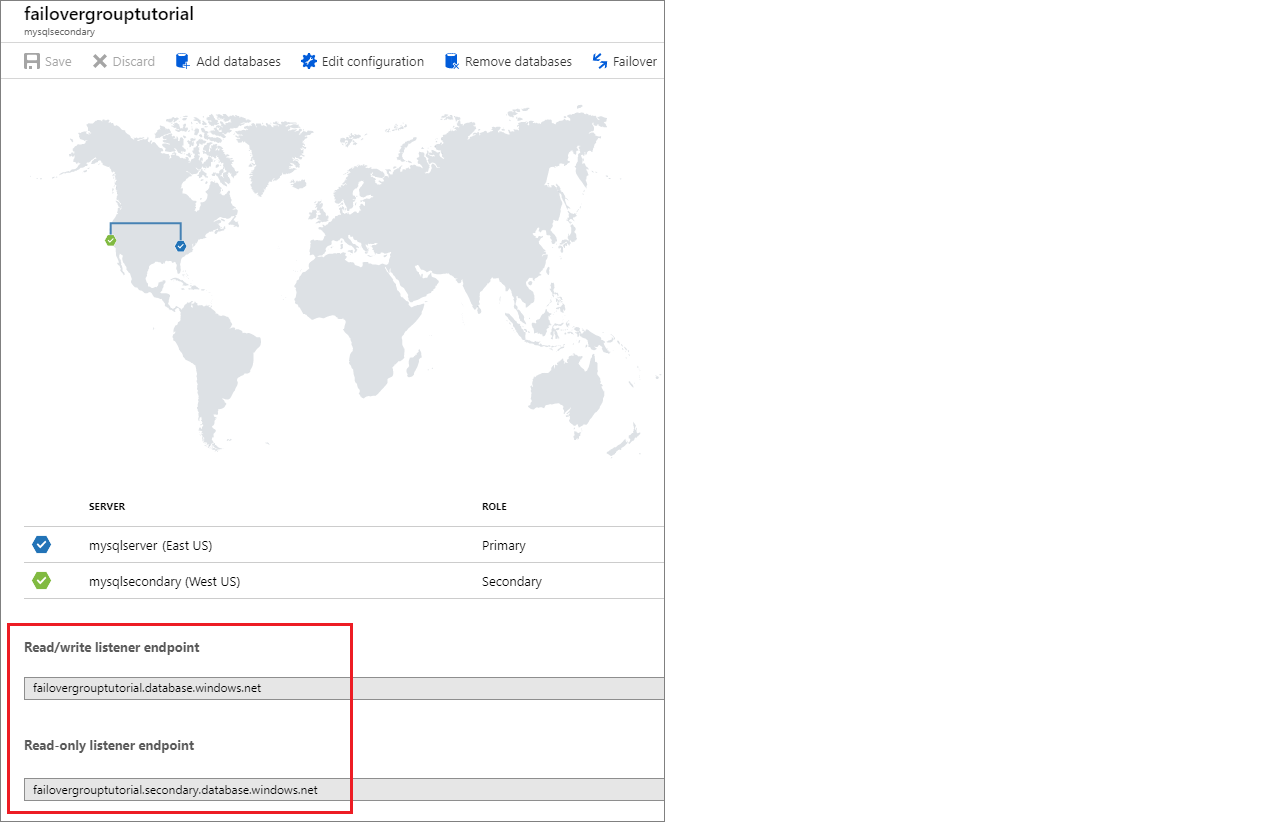
Localiser le point de terminaison de l’écouteur
Une fois votre groupe de basculement configuré, mettez à jour la chaîne de connexion de votre application sur le point de terminaison de l’écouteur. Cela permet à votre application de rester connectée à l’écouteur du groupe de basculement, plutôt qu’à la base de données primaire ou au pool élastique. De cette façon, vous n’avez pas besoin de mettre à jour manuellement la chaîne de connexion chaque fois que votre entité de base de données fait l’objet d’un basculement et le trafic est acheminé vers l’entité qui fait office d’entité principale.
Le point de terminaison de l’écouteur se présente sous la forme fog-name.database.windows.net et est visible dans le portail Azure, quand vous affichez le groupe de basculement :
Mise à l’échelle de bases de données dans un groupe de basculement
Vous pouvez effectuer une mise à l’échelle vers le haut ou vers le bas sur une base de données primaire avec une taille de calcul différente (au sein du même niveau de service) sans déconnecter les bases de données géosecondaires. Lors du scale-up, nous vous recommandons de commencer par la base de données géosecondaire, puis de terminer avec la base de données primaire. Lors du scale-down, inversez l’ordre : commencez par la base de données primaire, puis terminez par la base de données secondaire. Quand vous faites passer la base de données à un niveau de service supérieur ou inférieur, cette recommandation s’applique.
Cette séquence est recommandée dans le but spécifique d’éviter le problème de surcharge des bases de données secondaires avec une référence SKU inférieure. Celles-ci doivent alors être alimentées à nouveau lors de la mise à niveau ou du passage à une version antérieure. Vous pouvez également éviter le problème en attribuant un accès en lecture seule à la base de données primaire, ce qui peut cependant nuire à toutes les charges de travail en lecture-écriture qui y sont associées.
Remarque
Si vous avez créé une base de données géosecondaire dans le cadre de la configuration du groupe de basculement, il n’est pas recommandé d’effectuer un scale-down dessus. En effet, votre couche Données pourrait manquer de capacité pour traiter votre charge de travail normale après un géo-basculement. Il n’est pas toujours possible de mettre à l’échelle un réplica géosecondaire après un basculement non planifié lorsque l’ancien réplica géoprincipal n’est pas disponible en raison d’une panne. Il s’agit d’une limitation connue.
Empêcher la perte de données critiques
En raison de la latence élevée des réseaux étendus, la géoréplication utilise un mécanisme de réplication asynchrone. La réplication asynchrone rend la possibilité de perte de données inévitable en cas de défaillance de la base de données primaire. Pour protéger les transactions critiques d’une perte de données, le développeur d’applications peut appeler la procédure stockée sp_wait_for_database_copy_sync immédiatement après la validation de la transaction. L’appel de sp_wait_for_database_copy_sync bloque le thread appelant jusqu’à ce que la dernière transaction validée ait été transmise et renforcée dans le journal des transactions de la base de données secondaire. Toutefois, il n’attend pas que les transactions transmises soient relues (réeffectuées) sur la base de données secondaire. sp_wait_for_database_copy_sync est limité à un lien de géoréplication spécifique. Tout utilisateur disposant de droits de connexion à la base de données primaire peut appeler cette procédure.
Notes
sp_wait_for_database_copy_sync empêche la perte de données après un géobasculement pour des transactions spécifiques, mais ne garantit pas une synchronisation complète pour l’accès en lecture. Le délai causé par un appel de procédure sp_wait_for_database_copy_sync peut être significatif et dépend de la taille du journal des transactions pas encore transmis à la base de données primaire au moment de l’appel.
Modifier la région secondaire
Pour illustrer la séquence de changement, nous partons du principe que le serveur A est le serveur principal, que le serveur B est le serveur secondaire existant et que le serveur C est le nouveau serveur secondaire dans la troisième région. Pour faire la transition, suivez ces étapes :
- Sur le serveur C, créez des bases de données secondaires supplémentaires de chaque base de données du serveur A en utilisant la géoréplication active. Chaque base de données sur le serveur A aura deux bases de données secondaires, une sur le serveur B et une sur le serveur C. Cela garantit que les bases de données primaires restent protégées pendant la transition.
- Supprimez le groupe de basculement. À ce stade, les tentatives de connexion utilisant des points de terminaison de groupe de basculement commencent à échouer.
- Recréez le groupe de basculement avec le même nom entre les serveurs A et C.
- Ajoutez toutes les bases de données primaires du serveur A au nouveau groupe de basculement. À ce stade, les tentatives de signature cessent d’échouer.
- Supprimez le serveur B. Toutes les bases de données sur B sont alors supprimées automatiquement.
Modifier la région primaire
Pour illustrer la séquence de changement, nous partons du principe que le serveur A est le serveur principal, que le serveur B est le serveur secondaire existant et que le serveur C est le nouveau serveur principal dans la troisième région. Pour faire la transition, suivez ces étapes :
- Effectuez un géobasculement planifié pour faire du serveur B le serveur principal. Le serveur A devient alors le nouveau serveur secondaire. Le basculement peut occasionner un temps d’arrêt de plusieurs minutes. Sa durée effective dépend de la taille du groupe de basculement.
- Sur le serveur C, créez des bases de données secondaires supplémentaires de chaque base de données du serveur B en utilisant la géoréplication active. Chaque base de données sur le serveur B aura deux bases de données secondaires, une sur le serveur A et une sur le serveur C. Cela garantit que les bases de données primaires restent protégées pendant la transition.
- Supprimez le groupe de basculement. À ce stade, les tentatives de connexion utilisant des points de terminaison de groupe de basculement commencent à échouer.
- Recréez le groupe de basculement avec le même nom entre les serveurs B et C.
- Ajoutez toutes les bases de données primaires du serveur B au nouveau groupe de basculement. À ce stade, les tentatives de connexion cessent d’échouer.
- Effectuez un géobasculement planifié du groupe de basculement pour basculer entre B et C. Maintenant, le serveur C devient le principal et B le secondaire. Toutes les bases de données secondaires du serveur A sont automatiquement liées aux bases de données primaires de C. Comme à l’étape 1, le basculement peut occasionner un temps d’arrêt de plusieurs minutes.
- Supprimez le serveur A. Toutes les bases de données de A sont alors supprimées automatiquement.
Important
Une fois le groupe de basculement supprimé, les enregistrements DNS des points de terminaison de l’écouteur sont également supprimés. À ce stade, il existe une probabilité non nulle qu’une personne crée un groupe de basculement ou un alias DNS de serveur avec le même nom. Étant donné que les noms de groupe de basculement et les alias DNS doivent être globalement uniques, vous ne pourrez pas réutiliser le même nom. Pour réduire au minimum ce risque, n’utilisez pas des noms de groupe de basculement génériques.
Groupes de basculement et sécurité réseau
Pour certaines applications, les règles de sécurité demandent que l’accès réseau à la couche données soit limité à un ou plusieurs composants spécifiques, tels qu’une machine virtuelle, un service web, etc. Cette condition présente des défis pour la conception de la continuité de l’activité et l’utilisation de groupes de basculement. Tenez compte des options suivantes lors de l’implémentation d’un accès restreint.
Utiliser des groupes de basculement et des points de terminaison de service de réseau virtuel
Si vous utilisez des règles et points de terminaison de service de réseau virtuel pour restreindre l’accès à votre base de données, n’oubliez pas que chaque point de terminaison de service de réseau virtuel s’applique à une seule région Azure. Le point de terminaison ne permet pas à d’autres régions d’accepter les communications provenant du sous-réseau. Par conséquent, seules les applications client déployées dans la même région peuvent se connecter à la base de données primaire. Comme un géobasculement entraîne la redirection des sessions du client SQL Database vers un serveur dans une autre région (secondaire), ces sessions échouent si elles proviennent d’un client situé en dehors de cette région. Pour cette raison, la stratégie de basculement gérée par Microsoft ne peut pas être activée si les serveurs participants sont inclus dans les règles de réseau virtuel. Pour prendre en charge la politique de basculement manuel, effectuez les étapes suivantes :
- Fournissez des copies redondantes des composants frontend de votre application (service Web, machines virtuelles, etc.) dans la région secondaire.
- Configurez les règles de réseau virtuel individuellement pour les serveurs primaire et secondaire.
- Activez le basculement front-end à l’aide d’une configuration Traffic Manager.
- Lancez un géobasculement manuel quand la panne est détectée. Cette option est optimisée pour les applications qui nécessitent une latence cohérente entre le frontend et le niveau de données et prend en charge la récupération lorsque le frontend, le niveau de données ou les deux sont affectés par la panne.
Remarque
Si vous utilisez l’écouteur en lecture seule pour équilibrer une charge de travail en lecture seule, vérifiez que cette charge de travail est exécutée dans une machine virtuelle ou une autre ressource dans la région secondaire pour qu’elle puisse se connecter à la base de données secondaire.
Utiliser des groupes de basculement et des règles de pare-feu
Si votre plan de continuité d’activité nécessite un basculement à l’aide de groupes de basculement, vous pouvez restreindre l’accès à votre base de données SQL à l’aide de règles de pare-feu IP publiques. Cette configuration garantit qu’un basculement géographique ne bloquera pas les connexions des composants frontend et suppose que l’application peut tolérer la latence plus longue entre le frontend et le niveau de données.
Pour prendre en charge le basculement, effectuez les étapes suivantes :
- Créez une adresse IP publique.
- Créez un équilibreur de charge public et affectez-lui l’adresse IP publique.
- Créez un réseau virtuel et les machines virtuelles pour vos composants front-end.
- Créez un groupe de sécurité réseau et configurez les connexions entrantes.
- Vérifiez que les connexions sortantes sont ouvertes pour Azure SQL Database dans une région en utilisant une
Sql.<Region>étiquette de service. - Créez une règle de pare-feu SQL Database pour autoriser le trafic entrant à partir de l’adresse IP publique que vous créez à l’étape 1.
Pour plus d’informations sur la configuration de l’accès sortant et l’adresse IP à utiliser dans les règles de pare-feu, voir Connexions sortantes de l’équilibreur de charge.
Important
Pour garantir la continuité d’activité lors de pannes régionales, vous devez vérifier la redondance géographique pour les composants front-end et les bases de données.
Autorisations
Les autorisations pour un groupe de basculement sont gérées via un contrôle d’accès en fonction du rôle Azure (Azure RBAC).
L’accès en écriture à RBAC Azure est nécessaire pour créer et gérer des groupes de basculement. Le rôle Contributeur SQL Server dispose des autorisations nécessaires pour gérer des groupes de basculement.
Le tableau suivant répertorie les étendues d’autorisation spécifiques pour Azure SQL Database :
| Action | Permission | Étendue |
|---|---|---|
| Créer un groupe de basculement | Accès en écriture à RBAC Azure | Serveur primaire Serveur secondaire Toutes les bases de données dans le groupe de basculement |
| Mettre à jour un groupe de basculement | Accès en écriture à RBAC Azure | Groupe de basculement Toutes les bases de données sur le serveur primaire actuel |
| Faire basculer un groupe de basculement | Accès en écriture à RBAC Azure | Groupe de basculement sur le nouveau serveur |
Limites
Notez les limitations suivantes :
- Il n’est pas possible de créer des groupes de basculement entre deux serveurs au sein de la même région Azure.
- Les groupes de basculement prennent en charge la géoréplication de toutes les bases de données du groupe vers un seul serveur logique secondaire situé dans une autre région.
- Les groupes de basculement ne peuvent pas être renommés. Vous devrez supprimer le groupe puis le recréer sous un autre nom.
- Le renommage de base de données n’est pas pris en charge pour les bases de données situées dans un groupe de basculement. Vous devrez supprimer temporairement le groupe de basculement pour pouvoir renommer une base de données ou supprimer la base de données, à partir du groupe de basculement.
- La suppression d’un groupe de basculement pour une base de données unique ou mise en pool n’interrompt pas la réplication et n’entraîne pas la suppression de la base de données répliquée. Vous devez arrêter manuellement la géoréplication et supprimer la base de données du serveur secondaire si vous souhaitez rajouter une base de données unique ou mise en pool à un groupe de basculement après sa suppression. Si vous n’effectuez pas l’une ou l’autre de ces opérations, vous risquez d’obtenir une erreur telle que
The operation cannot be performed due to multiple errorslorsque vous tentez d’ajouter la base de données au groupe de basculement. - Le nom du groupe de basculement automatique est soumis à des restrictions d’affectation de noms.
Gérer programmatiquement des groupes de basculement
Les groupes de basculement peuvent aussi être gérés programmatiquement en utilisant Azure PowerShell, Azure CLI et l’API REST. Les tableaux ci-dessous décrivent l’ensemble des commandes disponibles. Les groupes de basculement comprennent un ensemble d’API Azure Resource Manager pour la gestion, notamment API REST de base de données Azure SQL et Azure PowerShell cmdlets. Ces API nécessitent l’utilisation de groupes de ressources et la prise en charge du contrôle d’accès en fonction du rôle (RBAC). Pour plus d’informations sur l’implémentation de rôles d’accès, consultez la page sur le contrôle d’accès en fonction du rôle Azure (RBAC Azure).
| Applet de commande | Description |
|---|---|
| New-AzSqlDatabaseFailoverGroup | Cette commande crée un groupe de basculement et l’enregistre dans les serveurs primaire et secondaire |
| Remove-AzSqlDatabaseFailoverGroup | Supprime un groupe de basculement du serveur |
| Get-AzSqlDatabaseFailoverGroup | Récupère la configuration d’un groupe de basculement |
| Set-AzSqlDatabaseFailoverGroup | Modifie la configuration d’un groupe de basculement |
| Switch-AzSqlDatabaseFailoverGroup | Déclenche le basculement d’un groupe de basculement vers le serveur secondaire |
| Add-AzSqlDatabaseToFailoverGroup | Ajoute une ou plusieurs bases de données à un groupe de basculement |
Remarque
Vous pouvez déployer votre groupe de basculement sur les abonnements à l’aide du paramètre -PartnerSubscriptionId dans Azure PowerShell en commençant par Az.SQL 3.11.0. Pour plus d’informations, consultez l’Exemple suivants.
Étapes suivantes
Pour obtenir une vue d’ensemble des options de haute disponibilité pour la base de données Azure SQL, consultez Géoréplication et Groupes de basculement.
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour