Utilisation de l’intelligence artificielle pour superviser et résoudre les problèmes de performances de la base de données par Intelligent Insights (préversion)
S’applique à : ![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Intelligent Insights dans Azure SQL Database et Azure SQL Managed Instance vous permet de suivre les performances de votre base de données.
Intelligent Insights utilise l’intelligence intégrée pour surveiller en permanence l’utilisation de la base de données et détecter les événements perturbateurs entraînant des performances médiocres. Une fois un tel événement détecté, une analyse détaillée génère un journal de ressources Intelligent Insights appelé SQLInsights (sans lien avec Azure Monitor SQL Insights (préversion)) avec une évaluation intelligente des problèmes. Cette évaluation se compose d’une analyse de cause racine du problème de performances de la base de données et, dans la mesure du possible, de recommandations pour une amélioration des performances.
Qu’est-ce qu’Intelligent Insights peut faire pour vous ?
Intelligent Insights est une fonctionnalité unique de l’intelligence intégrée Azure, qui apporte les avantages suivants :
- Surveillance proactive
- Analyse des performances personnalisée
- Détection anticipée de la dégradation des performances de la base de données
- Analyse de la cause racine des problèmes détectés
- Recommandations pour l’amélioration des performances
- Capacité de scale-out sur des centaines de milliers de bases de données
- Impact positif sur les ressources de DevOps et le coût total de possession
Le fonctionnement d’Intelligent Insights
Intelligent Insights analyse les performances des bases de données en comparant leur charge de travail de l’heure passée avec la charge de travail de base des sept derniers jours. La charge de travail de la base de données est composée de requêtes déterminées comme étant les plus significatives pour les performances de la base de données, à savoir par exemple les requêtes les plus répétées et les plus grandes. Chaque base de données étant unique sur le plan de la structure, des données, de l’utilisation et de l’application, chaque ligne de base de la charge de travail générée est unique et propre à cette charge de travail. Intelligent Insights, indépendamment de la ligne de base de la charge de travail, analyse aussi des seuils opérationnels absolus et détecte des problèmes de temps d’attente excessifs, des exceptions critiques et des problèmes de paramétrages des requêtes susceptibles d’affecter les performances.
Une fois qu’un problème de détérioration des performances est détecté par plusieurs mesures observées en utilisant l’intelligence artificielle, l’analyse est effectuée. Un journal de diagnostic est généré avec une information intelligente sur ce qui se passe pour votre base de données. Intelligent Insights facilite le suivi du problème de performances de la base de données de son apparition initiale jusqu’à sa résolution. Chaque problème détecté est suivi tout au long de son cycle de vie depuis sa détection initiale et la vérification de l’amélioration des performances jusqu’à sa fin.
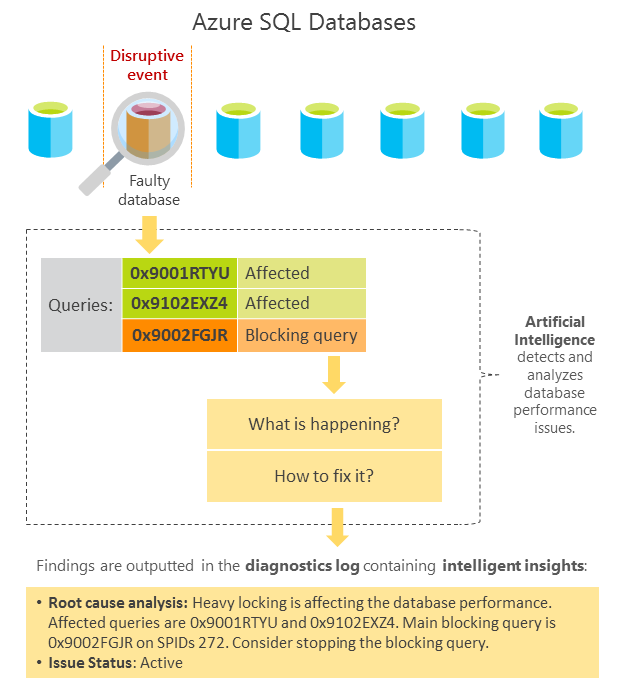
Les métriques utilisées pour mesurer et détecter les problèmes de performances de la base de données reposent sur la durée des requêtes, les demandes de délai d’expiration, les temps d’attente excessifs et les demandes erronées. Pour plus d’informations sur les métriques, consultez la section Métriques de détection.
Les détériorations des performances de bases de données identifiées sont enregistrées dans le journal SQLInsights Intelligence Insights avec des entrées intelligentes comprenant les propriétés suivantes :
| Propriété | Détails |
|---|---|
| les informations de base de données | Métadonnées relatives à une base de données sur laquelle une information a été détectée, telles qu’un URI de ressource. |
| Période observée | Heures de début et de fin de la période des informations détectées. |
| Métriques impactées | Métriques qui ont provoqué la génération d’un aperçu :
|
| Valeur d’impact | Valeur d’une métrique mesurée. |
| Requêtes impactées et codes d’erreur | Hachage de requête ou code d’erreur. Ces éléments peuvent être utilisés pour établir facilement une corrélation avec les requêtes affectées. Des métriques ayant trait à une augmentation de durée de requête, à un temps d’attente, à des nombres d’expiration ou à des codes d’erreur sont fournies. |
| Détections | Détection identifiée au niveau de la base de données pendant la durée d’un événement. Il existe 15 modèles de détection. Pour plus d’informations, consultez Résoudre les problèmes de performances liés à Azure SQL Database avec Intelligent Insights. |
| Analyse de la cause racine | Analyse de la cause racine du problème identifié dans un format lisible. Certaines informations peuvent contenir une recommandation d’amélioration des performances lorsque cela est possible. |
Intelligent Insights excelle dans la découverte et la résolution des problèmes affectant les performances liés aux bases de données. Pour résoudre les problèmes de performances de bases de données à l’aide d’Intelligent Insights, consultez Résoudre les problèmes de performances avec Intelligence Insights.
Options Intelligent Insights
Les options Intelligent Insights disponibles sont les suivantes :
| Option Intelligent Insights | Prise en charge d’Azure SQL Database | Prise en charge d’Azure SQL Managed Instance |
|---|---|---|
| Configurer Intelligent Insights : configurez l’analyse Intelligent Insights pour vos bases de données. | Oui | Oui |
| Diffuser en continu des insights vers Azure SQL Analytics : diffusez en continu des insights vers Azure SQL Analytics. | Oui | Oui |
| Diffuser en streaming des insights vers Azure Event Hubs : diffusez en streaming des insights vers Event Hubs pour d’autres intégrations personnalisées. | Oui | Oui |
| Diffuser en streaming des insights vers Stockage Azure : diffusez en streaming des insights vers Stockage Azure pour une analyse plus poussée et un archivage à long terme. | Oui | Oui |
Notes
Intelligent Insights est une fonctionnalité en préversion qui n’est pas disponible dans les régions suivantes : Europe Ouest, Europe Nord, USA Ouest 1 et USA Est 1.
Configurer l’exportation du journal Intelligent Insights
La sortie Intelligent Insights peut être diffusée en continu vers l’une des différentes destinations à des fins d’analyse :
- La sortie diffusée en continu sur un espace de travail Log Analytics peut être utilisée avec Azure SQL Analytics pour afficher les aperçus dans l’interface utilisateur du portail Azure. Il s’agit de la solution intégrée d’Azure, qui constitue la façon la plus courante d’afficher les insights.
- La sortie diffusée en continu sur Azure Event Hubs peut servir au développement de scénarios personnalisés de surveillance et de création d’alertes
- La sortie diffusée en continu sur le Stockage Azure peut servir au développement d’applications personnalisées pour la création de rapports personnalisés, l’archivage de données à long terme, etc.
Pour intégrer Azure SQL Analytics, Azure Event Hubs, Stockage Azure ou des produits tiers en vue d’une consommation de données, vous devez d’abord activer la journalisation Intelligent Insights (le journal « SQLInsights ») sur la page Paramètres de diagnostic d’une base de données, puis configurer les données du journal Intelligent Insights afin de les diffuser en streaming vers l’une de ces destinations.
Pour plus d’informations sur l’activation de la journalisation Intelligent Insights et la configuration des données des journaux de métriques et de ressources afin de les diffuser en continu dans un produit de consommation, consultez Journalisation des métriques et diagnostics.
Configurer Azure SQL Analytics
La solution Azure SQL Analytics fournit une interface utilisateur graphique, des fonctionnalités de création de rapports et d’alertes sur les performances des bases de données, à l’aide des données du journal de ressources Intelligent Insights.
Ajoutez Azure SQL Analytics au tableau de bord du portail Azure à partir de la Place de marché et créez un espace de travail. Pour plus d’informations, consultez Configurer Azure SQL Analytics
Pour utiliser Intelligent Insights avec Azure SQL Analytics, configurez les données du journal Intelligent Insights afin de les diffuser en continu vers l’espace de travail Azure SQL Analytics que vous avez créé à l’étape précédente. Pour plus d’informations, consultez Journalisation des métriques et diagnostics.
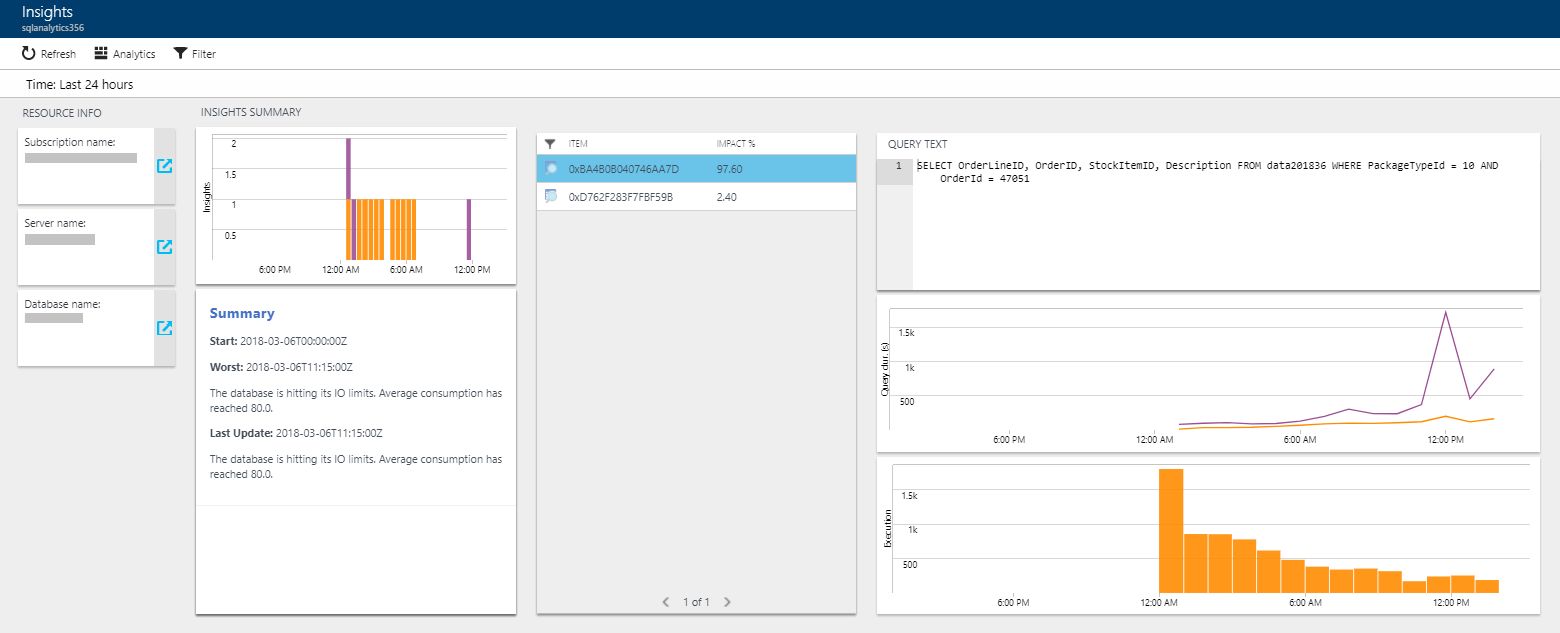
L’exemple suivant montre Intelligent Insights dans Azure SQL Analytics :
Configurer avec Event Hubs
Pour utiliser Intelligent Insights avec Event Hubs et configurer les données du journal Intelligent Insights afin de les diffuser en streaming dans Event Hubs, consultez Journalisation des métriques et diagnostics et Diffuser en streaming des journaux de diagnostics Azure vers Event Hubs.
Pour utiliser Event Hubs afin de personnaliser la supervision et les alertes, consultez Que faire des journaux de métriques et diagnostics dans Event Hubs.
Configurer avec le stockage Azure
Pour utiliser Intelligent Insights avec le Stockage, configurez les données du journal Intelligent Insights afin de les diffuser en continu sur le Stockage. Pour plus d’informations, consultez Journalisation des métriques et diagnostics et Diffuser en continu sur le Stockage Azure.
Intégrations personnalisées du journal d’Intelligent Insights
Pour utiliser Intelligent Insights avec des outils tiers ou pour le développement d’une supervision ou d’alertes personnalisées, consultez Utiliser le journal de diagnostic du niveau de performance d’Intelligent Insights.
Métriques de détection
Les métriques utilisées pour les modèles de détection qui génèrent des informations d’Intelligent Insights sont basées sur la surveillance des éléments suivants :
- Durée de la requête
- Demandes de délai d’expiration
- Délais d’attente excessifs
- Demandes erronées
Le durée de la requête et les demandes de délai d’expiration sont utilisées comme modèles principaux dans la détection des problèmes de performances de la charge de travail de la base de données. Ces métriques sont utilisées parce qu’elles mesurent directement ce qui se passe avec la charge de travail. Pour détecter tous les cas possibles de détérioration des performances de la charge de travail, des délais d’attente excessifs et des demandes erronées sont utilisés en tant que modèles supplémentaires pour indiquer des problèmes affectant les performances de la charge de travail.
Le système considère automatiquement les changements de charge de travail et les modifications du nombre de demandes de requête adressées à la base de données afin de déterminer de façon dynamique les seuils normaux et anormaux de performances de la base de données.
Toutes les métriques sont considérées dans différentes relations via un modèle de données élaboré scientifiquement, qui classe par catégories les problèmes de performances détectés. Les informations intelligentes fournies incluent les suivantes :
- Détails du problème de performances détecté.
- Analyse de la cause racine du problème détecté.
- Recommandations, dans la mesure du possible, sur la façon d’améliorer les performances de la base de données supervisée.
Durée de la requête
Un modèle de détérioration de la durée de requête analyse des requêtes individuelles et détecte l’augmentation du temps nécessaire pour compiler et exécuter une requête par rapport à la ligne de base des performances.
Si l’intelligence intégrée détecte une augmentation significative du temps de compilation ou d’exécution des requêtes qui impacte les performances de la charge de travail, ces requêtes sont marquées comme présentant un problème de détérioration des performances de durée.
Le journal de diagnostic Intelligent Insights génère le hachage de la requête dont les performances sont détériorées. Le hachage de requête indique si la détérioration des performances était liée à l’augmentation du délai de compilation ou d’exécution de la requête, laquelle a elle-même augmenté la durée de la requête.
Demandes de délai d’expiration
Le modèle de dégradation des demandes de délai d’expiration analyse les requêtes individuelles et détecte toute augmentation des délais d’expiration au niveau de l’exécution de la requête, ainsi que les demandes de délai d’expiration globales au niveau de la base de données comparées à la période de référence des performances.
Certaines des requêtes peuvent expirer avant même d’atteindre l’étape d’exécution. Sur la base des workers abandonnés par rapport aux demandes effectuées, l’intelligence intégrée mesure et analyse toutes les requêtes qui ont atteint la base de données, qu’elles soient parvenues à l’étape d’exécution ou non.
Une fois que le nombre de délais d’expiration pour les requêtes exécutées ou le nombre de workers de demande abandonnés franchissent le seuil géré par le système, un journal de diagnostic est rempli d’informations intelligentes.
Les informations générées contiennent le nombre de demandes de délai d’expiration et le nombre de requêtes ayant expiré. L’indication de la détérioration des performances est liée à l’augmentation du délai d’expiration à l’étape d’exécution, ou bien le niveau global de la base de données est fourni. Quand l’augmentation des délais d’expiration est considérée comme significative pour les performances de la base de données, ces requêtes sont marquées comme présentant un problème de détérioration des performances de délai d’expiration.
Délais d’attente excessifs
Le modèle des délais d’attente excessifs surveille des requêtes de base de données individuelles. Il détecte les statistiques d’attente anormalement élevées qui ont franchi les seuils absolus gérés par le système. Les métriques de délai d’attente excessif de requêtes sont observées à l’aide des Statistiques d’attente du magasin de données des requêtes (sys.query_store_wait_stats) :
- Atteinte des limites de ressources
- Atteinte des limites de ressources de pool élastique
- Nombre excessif de threads de travail ou de session
- Verrouillage de base de données excessif
- Sollicitation de la mémoire
- Autres statistiques d’attente
L’atteinte des limites des ressources ou des limites des ressources de pool élastique indiquent que la consommation des ressources disponibles sur un abonnement ou dans le pool élastique a franchi les seuils absolus. Ces statistiques indiquent une détérioration des performances de la charge de travail. Un nombre excessif de threads de travail ou de session indique une condition dans laquelle le nombre de threads de travail ou de session lancés a franchi les seuils absolus. Ces statistiques indiquent une détérioration des performances de la charge de travail.
Un verrouillage de base de données excessif indique une condition dans laquelle le nombre de verrous sur une base de données a franchi les seuils absolus. Cette statistique indique une détérioration des performances de la charge de travail. La sollicitation de la mémoire est une condition dans laquelle le nombre de threads qui demandent des allocations de mémoire a franchi un seuil absolu. Cette statistique indique une détérioration des performances de la charge de travail.
La détection d’autres statistiques d’attente indique une condition dans laquelle diverses métriques mesurées par l’intermédiaire des statistiques d’attente du magasin de données des requêtes ont franchi un seuil absolu. Ces statistiques indiquent une détérioration des performances de la charge de travail.
Quand des délais d’attente excessifs sont détectés, le journal de diagnostic Intelligent Insights produit, selon les données disponibles, des résultats variables des hachages des requêtes affectant et affectées dont les performances sont détériorées, des détails des métriques entraînant un délai d’attente d’exécution des requêtes et d’un délai d’attente mesuré.
Demandes erronées
Le modèle de dégradation des demandes erronées surveille les requêtes individuelles et détecte toute augmentation du nombre de requêtes erronées par rapport à la période de référence. Ce modèle analyse également les exceptions critiques qui ont franchi les seuils absolus gérés par l’intelligence intégrée. Le système considère automatiquement le nombre de demandes de requête adressées à la base de données, et rend compte de toutes les modifications de la charge de travail survenues durant la période analysée.
Lorsque l’augmentation mesurée des demandes erronées liée au nombre total de demandes effectuées est considéré comme significatif pour les performances de la charge de travail, les requêtes concernées sont marquées comme présentant des problèmes de détérioration des performances des demandes erronées.
Le journal Intelligent Insights génère le nombre de demandes erronées. Il indique si la détérioration des performances était liée à une augmentation des demandes erronées ou au franchissement d’un seuil d’exception critique surveillée et de la durée mesurée de la détérioration des performances.
Si l’une des exceptions critiques surveillées franchit les seuil absolus gérés par le système, une information intelligente est générée avec des détails sur l’exception critique.
Étapes suivantes
- En savoir plus sur Analyser des bases de données à l’aide de SQL Analytics.
- En savoir plus surDétecter des problèmes de performances avec Intelligent Insights.
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour