Superviser les performances de Microsoft Azure SQL Database avec des vues de gestion dynamique
S’applique à ![]() Azure SQL Database
Azure SQL Database
Microsoft Azure SQL Database active un sous-ensemble de vues de gestion dynamique permettant de diagnostiquer des problèmes de performances qui peuvent être causés par des requêtes bloquées ou longues, des goulots d’étranglement des ressources, des plans de requête médiocres, et bien plus encore.
Cet article fournit des informations sur la façon de détecter des problèmes de performances courants en interrogeant des vues de gestion dynamique par le biais de T-SQL. Vous pouvez utiliser n’importe quel outil de requête, par exemple :
- L’Éditeur de requête SQL dans le portail Azure
- SQL Server Management Studio (SSMS)
- Azure Data Studio
Autorisations
Dans Azure SQL Database, en fonction de l’option de taille de calcul et de déploiement, l’interrogation d’une vue de gestion dynamique (DMV) peut nécessiter l’autorisation VIEW DATABASE STATE ou VIEW SERVER STATE. Cette dernière autorisation peut être accordée via l’appartenance au rôle serveur ##MS_ServerStateReader##.
Pour accorder l’autorisation VIEW DATABASE STATE à un utilisateur de base de données spécifique, exécutez la requête suivante à titre d’exemple :
GRANT VIEW DATABASE STATE TO database_user;
Pour accorder l’appartenance au rôle serveur ##MS_ServerStateReader## à un ID de connexion pour le serveur logique dans Azure, connectez-vous à la base de données master, puis exécutez la requête suivante à titre d’exemple :
ALTER SERVER ROLE [##MS_ServerStateReader##] ADD MEMBER [login];
Dans une instance de SQL Server et dans Azure SQL Managed Instance, des vues de gestion dynamique retournent des informations sur l’état du serveur. Dans Azure SQL Database, elles retournent des informations relatives à votre base de données logique actuelle.
Identifier les problèmes de performances d’UC
Si la consommation du processeur est supérieure à 80 % pendant de longues périodes, envisagez les étapes de résolution des problèmes suivantes, que le problème de processeur se produise maintenant ou se soit produit dans le passé.
Le problème de l’UC se produit maintenant
Si le problème se produit maintenant, il y a deux scénarios possibles :
De nombreuses requêtes individuelles consomment une quantité cumulée d’UC élevée
Utilisez la requête suivante pour identifier les principaux hachages de requête :
PRINT '-- top 10 Active CPU Consuming Queries (aggregated)--'; SELECT TOP 10 GETDATE() runtime, * FROM (SELECT query_stats.query_hash, SUM(query_stats.cpu_time) 'Total_Request_Cpu_Time_Ms', SUM(logical_reads) 'Total_Request_Logical_Reads', MIN(start_time) 'Earliest_Request_start_Time', COUNT(*) 'Number_Of_Requests', SUBSTRING(REPLACE(REPLACE(MIN(query_stats.statement_text), CHAR(10), ' '), CHAR(13), ' '), 1, 256) AS "Statement_Text" FROM (SELECT req.*, SUBSTRING(ST.text, (req.statement_start_offset / 2)+1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text)ELSE req.statement_end_offset END-req.statement_start_offset)/ 2)+1) AS statement_text FROM sys.dm_exec_requests AS req CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST ) AS query_stats GROUP BY query_hash) AS t ORDER BY Total_Request_Cpu_Time_Ms DESC;
Des requêtes longues consommant l’UC sont toujours en cours d’exécution
Utilisez la requête suivante pour identifier ces requêtes :
PRINT '--top 10 Active CPU Consuming Queries by sessions--'; SELECT TOP 10 req.session_id, req.start_time, cpu_time 'cpu_time_ms', OBJECT_NAME(ST.objectid, ST.dbid) 'ObjectName', SUBSTRING(REPLACE(REPLACE(SUBSTRING(ST.text, (req.statement_start_offset / 2)+1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text)ELSE req.statement_end_offset END-req.statement_start_offset)/ 2)+1), CHAR(10), ' '), CHAR(13), ' '), 1, 512) AS statement_text FROM sys.dm_exec_requests AS req CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST ORDER BY cpu_time DESC; GO
Le problème de l’UC s’est produit dans le passé
Si le problème s’est produit dans le passé et que vous souhaitez effectuer une analyse de la cause racine, utilisez Magasin de requêtes. Les utilisateurs ayant accès à la base de données peuvent utiliser T-SQL pour interroger les données du Magasin de requêtes. Les configurations par défaut du Magasin de requêtes utilisent un niveau de granularité d’1 heure.
Utilisez la requête suivante pour examiner l’activité des requêtes ayant une consommation d’UC élevée. Cette requête retourne les 15 premières requêtes consommant l’UC. N’oubliez pas de changer
rsi.start_time >= DATEADD(hour, -2, GETUTCDATE():-- Top 15 CPU consuming queries by query hash -- Note that a query hash can have many query ids if not parameterized or not parameterized properly WITH AggregatedCPU AS ( SELECT q.query_hash ,SUM(count_executions * avg_cpu_time / 1000.0) AS total_cpu_ms ,SUM(count_executions * avg_cpu_time / 1000.0) / SUM(count_executions) AS avg_cpu_ms ,MAX(rs.max_cpu_time / 1000.00) AS max_cpu_ms ,MAX(max_logical_io_reads) max_logical_reads ,COUNT(DISTINCT p.plan_id) AS number_of_distinct_plans ,COUNT(DISTINCT p.query_id) AS number_of_distinct_query_ids ,SUM(CASE WHEN rs.execution_type_desc = 'Aborted' THEN count_executions ELSE 0 END) AS Aborted_Execution_Count ,SUM(CASE WHEN rs.execution_type_desc = 'Regular' THEN count_executions ELSE 0 END) AS Regular_Execution_Count ,SUM(CASE WHEN rs.execution_type_desc = 'Exception' THEN count_executions ELSE 0 END) AS Exception_Execution_Count ,SUM(count_executions) AS total_executions ,MIN(qt.query_sql_text) AS sampled_query_text FROM sys.query_store_query_text AS qt INNER JOIN sys.query_store_query AS q ON qt.query_text_id = q.query_text_id INNER JOIN sys.query_store_plan AS p ON q.query_id = p.query_id INNER JOIN sys.query_store_runtime_stats AS rs ON rs.plan_id = p.plan_id INNER JOIN sys.query_store_runtime_stats_interval AS rsi ON rsi.runtime_stats_interval_id = rs.runtime_stats_interval_id WHERE rs.execution_type_desc IN ('Regular','Aborted','Exception') AND rsi.start_time >= DATEADD(HOUR, - 2, GETUTCDATE()) GROUP BY q.query_hash ) ,OrderedCPU AS ( SELECT query_hash ,total_cpu_ms ,avg_cpu_ms ,max_cpu_ms ,max_logical_reads ,number_of_distinct_plans ,number_of_distinct_query_ids ,total_executions ,Aborted_Execution_Count ,Regular_Execution_Count ,Exception_Execution_Count ,sampled_query_text ,ROW_NUMBER() OVER ( ORDER BY total_cpu_ms DESC ,query_hash ASC ) AS query_hash_row_number FROM AggregatedCPU ) SELECT OD.query_hash ,OD.total_cpu_ms ,OD.avg_cpu_ms ,OD.max_cpu_ms ,OD.max_logical_reads ,OD.number_of_distinct_plans ,OD.number_of_distinct_query_ids ,OD.total_executions ,OD.Aborted_Execution_Count ,OD.Regular_Execution_Count ,OD.Exception_Execution_Count ,OD.sampled_query_text ,OD.query_hash_row_number FROM OrderedCPU AS OD WHERE OD.query_hash_row_number <= 15 --get top 15 rows by total_cpu_ms ORDER BY total_cpu_ms DESC;Une fois que vous avez identifié les requêtes problématiques, vous devez les paramétrer pour réduire leur consommation d’UC. Si vous n’avez pas le temps de paramétrer les requêtes, vous pouvez également choisir de mettre à niveau le SLO de la base de données pour contourner le problème.
Pour plus d’informations sur la gestion des problèmes de performances du processeur dans Azure SQL Database, consultez Diagnostiquer et résoudre des problèmes liés à l’utilisation élevée du processeur dans Azure SQL Database.
Identifier les problèmes de performances d’E/S
Lors de l’identification des problèmes de performances d’entrée/sortie (E/S) de stockage, les principaux types d’attente associés aux problèmes d’E/S sont les suivants :
PAGEIOLATCH_*Pour les problèmes d’E/S de fichier de données (y compris
PAGEIOLATCH_SH,PAGEIOLATCH_EX,PAGEIOLATCH_UP). Si le nom du type d’attente contient IO, cela indique un problème d’E/S. Si le nom d’attente de verrou de la page ne comporte aucun IO, cela indique un problème différent (par exemple, contention detempdb).WRITE_LOGPour les problèmes d’E/S liés au journal des transactions.
Si le problème d’E/S se produit maintenant
Utilisez sys.dm_exec_requests ou sys.dm_os_waiting_tasks pour voir les valeurs wait_type et wait_time.
Identifier l’utilisation des données et des E/S de journal
Utilisez la requête suivante pour identifier l’utilisation des données et des E/S de journal. Si l’utilisation des données ou des E/S de journal est supérieure à 80 %, cela signifie que les utilisateurs ont utilisé les E/S disponibles pour le niveau de service Azure SQL Database.
SELECT
database_name = DB_NAME()
, UTC_time = end_time
, 'CPU Utilization In % of Limit' = rs.avg_cpu_percent
, 'Data IO In % of Limit' = rs.avg_data_io_percent
, 'Log Write Utilization In % of Limit' = rs.avg_log_write_percent
, 'Memory Usage In % of Limit' = rs.avg_memory_usage_percent
, 'In-Memory OLTP Storage in % of Limit' = rs.xtp_storage_percent
, 'Concurrent Worker Threads in % of Limit' = rs.max_worker_percent
, 'Concurrent Sessions in % of Limit' = rs.max_session_percent
FROM sys.dm_db_resource_stats AS rs --past hour only
ORDER BY rs.end_time DESC;
Pour plus d’exemples d’utilisation de sys.dm_db_resource_stats, consultez la section Superviser l’utilisation des ressources plus loin dans cet article.
Si la limite d’E/S a été atteinte, vous avez deux options :
- mise à niveau de la taille de calcul ou du niveau de service
- identifier et régler les requêtes qui consomment le plus d’E/S.
Afficher les E/S de la mémoire tampon à l’aide du Magasin des requêtes
Pour l’option 2, vous pouvez utiliser la requête suivante sur le Magasin des requêtes pour voir les E/S de la mémoire tampon et afficher les deux dernières heures d’activité suivie :
-- Top queries that waited on buffer
-- Note these are finished queries
WITH Aggregated AS (SELECT q.query_hash, SUM(total_query_wait_time_ms) total_wait_time_ms, SUM(total_query_wait_time_ms / avg_query_wait_time_ms) AS total_executions, MIN(qt.query_sql_text) AS sampled_query_text, MIN(wait_category_desc) AS wait_category_desc
FROM sys.query_store_query_text AS qt
INNER JOIN sys.query_store_query AS q ON qt.query_text_id=q.query_text_id
INNER JOIN sys.query_store_plan AS p ON q.query_id=p.query_id
INNER JOIN sys.query_store_wait_stats AS waits ON waits.plan_id=p.plan_id
INNER JOIN sys.query_store_runtime_stats_interval AS rsi ON rsi.runtime_stats_interval_id=waits.runtime_stats_interval_id
WHERE wait_category_desc='Buffer IO' AND rsi.start_time>=DATEADD(HOUR, -2, GETUTCDATE())
GROUP BY q.query_hash), Ordered AS (SELECT query_hash, total_executions, total_wait_time_ms, sampled_query_text, wait_category_desc, ROW_NUMBER() OVER (ORDER BY total_wait_time_ms DESC, query_hash ASC) AS query_hash_row_number
FROM Aggregated)
SELECT OD.query_hash, OD.total_executions, OD.total_wait_time_ms, OD.sampled_query_text, OD.wait_category_desc, OD.query_hash_row_number
FROM Ordered AS OD
WHERE OD.query_hash_row_number <= 15 -- get top 15 rows by total_wait_time_ms
ORDER BY total_wait_time_ms DESC;
GO
Afficher le nombre total d’E/S du journal pour les attentes WRITELOG
Si le type d’attente est WRITELOG, utilisez la requête suivante pour afficher le nombre total d’E/S du journal par instruction :
-- Top transaction log consumers
-- Adjust the time window by changing
-- rsi.start_time >= DATEADD(hour, -2, GETUTCDATE())
WITH AggregatedLogUsed
AS (SELECT q.query_hash,
SUM(count_executions * avg_cpu_time / 1000.0) AS total_cpu_ms,
SUM(count_executions * avg_cpu_time / 1000.0) / SUM(count_executions) AS avg_cpu_ms,
SUM(count_executions * avg_log_bytes_used) AS total_log_bytes_used,
MAX(rs.max_cpu_time / 1000.00) AS max_cpu_ms,
MAX(max_logical_io_reads) max_logical_reads,
COUNT(DISTINCT p.plan_id) AS number_of_distinct_plans,
COUNT(DISTINCT p.query_id) AS number_of_distinct_query_ids,
SUM( CASE
WHEN rs.execution_type_desc = 'Aborted' THEN
count_executions
ELSE 0
END
) AS Aborted_Execution_Count,
SUM( CASE
WHEN rs.execution_type_desc = 'Regular' THEN
count_executions
ELSE 0
END
) AS Regular_Execution_Count,
SUM( CASE
WHEN rs.execution_type_desc = 'Exception' THEN
count_executions
ELSE 0
END
) AS Exception_Execution_Count,
SUM(count_executions) AS total_executions,
MIN(qt.query_sql_text) AS sampled_query_text
FROM sys.query_store_query_text AS qt
INNER JOIN sys.query_store_query AS q ON qt.query_text_id = q.query_text_id
INNER JOIN sys.query_store_plan AS p ON q.query_id = p.query_id
INNER JOIN sys.query_store_runtime_stats AS rs ON rs.plan_id = p.plan_id
INNER JOIN sys.query_store_runtime_stats_interval AS rsi ON rsi.runtime_stats_interval_id = rs.runtime_stats_interval_id
WHERE rs.execution_type_desc IN ( 'Regular', 'Aborted', 'Exception' )
AND rsi.start_time >= DATEADD(HOUR, -2, GETUTCDATE())
GROUP BY q.query_hash),
OrderedLogUsed
AS (SELECT query_hash,
total_log_bytes_used,
number_of_distinct_plans,
number_of_distinct_query_ids,
total_executions,
Aborted_Execution_Count,
Regular_Execution_Count,
Exception_Execution_Count,
sampled_query_text,
ROW_NUMBER() OVER (ORDER BY total_log_bytes_used DESC, query_hash ASC) AS query_hash_row_number
FROM AggregatedLogUsed)
SELECT OD.total_log_bytes_used,
OD.number_of_distinct_plans,
OD.number_of_distinct_query_ids,
OD.total_executions,
OD.Aborted_Execution_Count,
OD.Regular_Execution_Count,
OD.Exception_Execution_Count,
OD.sampled_query_text,
OD.query_hash_row_number
FROM OrderedLogUsed AS OD
WHERE OD.query_hash_row_number <= 15 -- get top 15 rows by total_log_bytes_used
ORDER BY total_log_bytes_used DESC;
GO
Identifier les problèmes de performances tempdb
Lors de l’identification des problèmes de performances d’E/S, le principal type d’attente associé à des problèmes tempdb est PAGELATCH_* (pas PAGEIOLATCH_*). Toutefois, les attentes PAGELATCH_* ne signifient pas toujours qu’il y a une contention tempdb. Cette attente peut aussi s’expliquer par une contention de page de données utilisateur-objet due à des requêtes concurrentes ciblant la même page de données. Pour confirmer la contention tempdb, utilisez sys.dm_exec_requests et vérifiez que la valeur wait_resource commence par 2:x:y, où 2 est tempdb, l’ID de base de données, x est l’ID de fichier et y est l’ID de page.
Pour une contention tempdb, il est courant de réduire ou réécrire le code d’application qui repose sur tempdb. Les zones courantes d’utilisation de tempdb sont les suivantes :
- Tables temporaires
- Variables de table
- Paramètres table
- Utilisation du magasin de version (associé aux transactions longues)
- Requêtes comportant des plans de requête qui utilisent des tris, des jointures hachées et des files d’attente
Pour plus d’informations, consultez tempdb dans Azure SQL.
Principales requêtes qui utilisent des variables de table et des tables temporaires
Utilisez la requête suivante pour identifier les principales requêtes qui utilisent des variables de table et des tables temporaires :
SELECT plan_handle, execution_count, query_plan
INTO #tmpPlan
FROM sys.dm_exec_query_stats
CROSS APPLY sys.dm_exec_query_plan(plan_handle);
GO
WITH XMLNAMESPACES('http://schemas.microsoft.com/sqlserver/2004/07/showplan' AS sp)
SELECT plan_handle, stmt.stmt_details.value('@Database', 'varchar(max)') AS 'Database'
, stmt.stmt_details.value('@Schema', 'varchar(max)') AS 'Schema'
, stmt.stmt_details.value('@Table', 'varchar(max)') AS 'table'
INTO #tmp2
FROM
(SELECT CAST(query_plan AS XML) sqlplan, plan_handle FROM #tmpPlan) AS p
CROSS APPLY sqlplan.nodes('//sp:Object') AS stmt(stmt_details);
GO
SELECT t.plan_handle, [Database], [Schema], [table], execution_count
FROM
(SELECT DISTINCT plan_handle, [Database], [Schema], [table]
FROM #tmp2
WHERE [table] LIKE '%@%' OR [table] LIKE '%#%') AS t
INNER JOIN #tmpPlan AS t2 ON t.plan_handle=t2.plan_handle;
GO
DROP TABLE #tmpPlan
DROP TABLE #tmp2
Identifier les transactions longues
Utilisez la requête suivante pour identifier les transactions longues. Les transactions longues empêchent le nettoyage du magasin de versions persistantes (PVS). Pour plus d’informations, consultez l’article Résoudre les problèmes de récupération accélérée de base de données.
SELECT DB_NAME(dtr.database_id) 'database_name',
sess.session_id,
atr.name AS 'tran_name',
atr.transaction_id,
transaction_type,
transaction_begin_time,
database_transaction_begin_time,
transaction_state,
is_user_transaction,
sess.open_transaction_count,
TRIM(REPLACE(
REPLACE(
SUBSTRING(
SUBSTRING(
txt.text,
(req.statement_start_offset / 2) + 1,
((CASE req.statement_end_offset
WHEN -1 THEN
DATALENGTH(txt.text)
ELSE
req.statement_end_offset
END - req.statement_start_offset
) / 2
) + 1
),
1,
1000
),
CHAR(10),
' '
),
CHAR(13),
' '
)
) Running_stmt_text,
recenttxt.text 'MostRecentSQLText'
FROM sys.dm_tran_active_transactions AS atr
INNER JOIN sys.dm_tran_database_transactions AS dtr
ON dtr.transaction_id = atr.transaction_id
LEFT JOIN sys.dm_tran_session_transactions AS sess
ON sess.transaction_id = atr.transaction_id
LEFT JOIN sys.dm_exec_requests AS req
ON req.session_id = sess.session_id
AND req.transaction_id = sess.transaction_id
LEFT JOIN sys.dm_exec_connections AS conn
ON sess.session_id = conn.session_id
OUTER APPLY sys.dm_exec_sql_text(req.sql_handle) AS txt
OUTER APPLY sys.dm_exec_sql_text(conn.most_recent_sql_handle) AS recenttxt
WHERE atr.transaction_type != 2
AND sess.session_id != @@spid
ORDER BY start_time ASC;
Identifier les problèmes de performances d’attente d’allocation de mémoire
Si votre principal type d’attente est RESOURCE_SEMAPHORE et que vous n’avez pas de problème d’utilisation élevée de l’UC, vous avez peut-être un problème d’attente d’allocation de mémoire.
Déterminer si une attente RESOURCE_SEMAPHORE est une attente principale
Utilisez la requête suivante pour déterminer si une attente RESOURCE_SEMAPHORE est une attente principale. Un autre indicateur serait une augmentation du rang du temps d’attente de RESOURCE_SEMAPHORE dans l’historique récent. Pour plus d’informations sur la résolution des problèmes d’attente liés aux allocations de mémoire, consultez Résoudre les problèmes de performances lentes ou de mémoire insuffisante causés par les allocations de mémoire dans SQL Server.
SELECT wait_type,
SUM(wait_time) AS total_wait_time_ms
FROM sys.dm_exec_requests AS req
INNER JOIN sys.dm_exec_sessions AS sess
ON req.session_id = sess.session_id
WHERE is_user_process = 1
GROUP BY wait_type
ORDER BY SUM(wait_time) DESC;
Identifier les instructions de consommation élevée de la mémoire
Si vous rencontrez des erreurs de mémoire insuffisante dans Azure SQL Database, consultez sys.dm_os_out_of_memory_events. Pour plus d’informations, consultez Résoudre les erreurs de mémoire insuffisante avec Azure SQL Database.
Tout d’abord, modifiez le script ci-dessous pour mettre à jour les valeurs pertinentes de start_time et end_time. Ensuite, exécutez la requête suivante pour identifier les instructions de consommation élevée de la mémoire :
SELECT IDENTITY(INT, 1, 1) rowId,
CAST(query_plan AS XML) query_plan,
p.query_id
INTO #tmp
FROM sys.query_store_plan AS p
INNER JOIN sys.query_store_runtime_stats AS r
ON p.plan_id = r.plan_id
INNER JOIN sys.query_store_runtime_stats_interval AS i
ON r.runtime_stats_interval_id = i.runtime_stats_interval_id
WHERE start_time > '2018-10-11 14:00:00.0000000'
AND end_time < '2018-10-17 20:00:00.0000000';
GO
;WITH cte
AS (SELECT query_id,
query_plan,
m.c.value('@SerialDesiredMemory', 'INT') AS SerialDesiredMemory
FROM #tmp AS t
CROSS APPLY t.query_plan.nodes('//*:MemoryGrantInfo[@SerialDesiredMemory[. > 0]]') AS m(c) )
SELECT TOP 50
cte.query_id,
t.query_sql_text,
cte.query_plan,
CAST(SerialDesiredMemory / 1024. AS DECIMAL(10, 2)) SerialDesiredMemory_MB
FROM cte
INNER JOIN sys.query_store_query AS q
ON cte.query_id = q.query_id
INNER JOIN sys.query_store_query_text AS t
ON q.query_text_id = t.query_text_id
ORDER BY SerialDesiredMemory DESC;
Identifier les 10 principales allocations de mémoire actives
Utilisez la requête suivante pour identifier les 10 principales allocations de mémoire actives :
SELECT TOP 10
CONVERT(VARCHAR(30), GETDATE(), 121) AS runtime,
r.session_id,
r.blocking_session_id,
r.cpu_time,
r.total_elapsed_time,
r.reads,
r.writes,
r.logical_reads,
r.row_count,
wait_time,
wait_type,
r.command,
OBJECT_NAME(txt.objectid, txt.dbid) 'Object_Name',
TRIM(REPLACE(REPLACE(SUBSTRING(SUBSTRING(TEXT, (r.statement_start_offset / 2) + 1,
( (
CASE r.statement_end_offset
WHEN - 1
THEN DATALENGTH(TEXT)
ELSE r.statement_end_offset
END - r.statement_start_offset
) / 2
) + 1), 1, 1000), CHAR(10), ' '), CHAR(13), ' ')) AS stmt_text,
mg.dop, --Degree of parallelism
mg.request_time, --Date and time when this query requested the memory grant.
mg.grant_time, --NULL means memory has not been granted
mg.requested_memory_kb / 1024.0 requested_memory_mb, --Total requested amount of memory in megabytes
mg.granted_memory_kb / 1024.0 AS granted_memory_mb, --Total amount of memory actually granted in megabytes. NULL if not granted
mg.required_memory_kb / 1024.0 AS required_memory_mb, --Minimum memory required to run this query in megabytes.
max_used_memory_kb / 1024.0 AS max_used_memory_mb,
mg.query_cost, --Estimated query cost.
mg.timeout_sec, --Time-out in seconds before this query gives up the memory grant request.
mg.resource_semaphore_id, --Non-unique ID of the resource semaphore on which this query is waiting.
mg.wait_time_ms, --Wait time in milliseconds. NULL if the memory is already granted.
CASE mg.is_next_candidate --Is this process the next candidate for a memory grant
WHEN 1 THEN
'Yes'
WHEN 0 THEN
'No'
ELSE
'Memory has been granted'
END AS 'Next Candidate for Memory Grant',
qp.query_plan
FROM sys.dm_exec_requests AS r
INNER JOIN sys.dm_exec_query_memory_grants AS mg
ON r.session_id = mg.session_id
AND r.request_id = mg.request_id
CROSS APPLY sys.dm_exec_sql_text(mg.sql_handle) AS txt
CROSS APPLY sys.dm_exec_query_plan(r.plan_handle) AS qp
ORDER BY mg.granted_memory_kb DESC;
Suivi des connexions
La vue sys.dm_exec_connections permet de récupérer des informations sur les connexions établies avec une base de données ou un pool élastique spécifiques, ainsi que les détails de chaque connexion. En outre, la vue sys.dm_exec_sessions permet de récupérer des informations sur toutes les connexions utilisateur et tâches internes actives.
Afficher les sessions actives
La requête suivante récupère des informations sur la connexion en cours. Pour afficher toutes les sessions, supprimez la clause WHERE.
Vous voyez toutes les sessions en cours d’exécution sur la base de données uniquement si vous disposez de l’autorisation VIEW DATABASE STATE sur la base de données lors de l’exécution des vues sys.dm_exec_requests et sys.dm_exec_sessions. Sinon, vous voyez uniquement la session active.
SELECT
c.session_id, c.net_transport, c.encrypt_option,
c.auth_scheme, s.host_name, s.program_name,
s.client_interface_name, s.login_name, s.nt_domain,
s.nt_user_name, s.original_login_name, c.connect_time,
s.login_time
FROM sys.dm_exec_connections AS c
INNER JOIN sys.dm_exec_sessions AS s
ON c.session_id = s.session_id
WHERE c.session_id = @@SPID; --Remove to view all sessions, if permissions allow
Surveiller l’utilisation des ressources
Vous pouvez surveiller l’utilisation de la ressource Azure SQL Database au niveau de la requête en utilisant SQL Database Query Performance Insight dans le portail Azure ou le Magasin des requêtes.
Vous pouvez également superviser l’utilisation à l’aide de ces vues :
sys.dm_db_resource_stats
Vous pouvez utiliser la vue sys.dm_db_resource_stats dans chaque base de données. La vue sys.dm_db_resource_stats représente les données d’utilisation récente des ressources par rapport au niveau de service. Les pourcentages moyens d’UC, d’E/S des données, d’écritures du journal et de mémoire sont enregistrés toutes les 15 secondes et conservés pendant une heure.
Étant donné que cette vue fournit un aperçu plus granulaire de l’utilisation des ressources, utilisez d’abord sys.dm_db_resource_stats pour n’importe quelle analyse d’état actuel ou pour la résolution des problèmes. Par exemple, cette requête affiche l’utilisation moyenne et maximale des ressources pour la base de données actuelle sur la dernière heure :
SELECT
Database_Name = DB_NAME(),
tier_limit = COALESCE(rs.dtu_limit, cpu_limit), --DTU or vCore limit
AVG(avg_cpu_percent) AS 'Average CPU use in percent',
MAX(avg_cpu_percent) AS 'Maximum CPU use in percent',
AVG(avg_data_io_percent) AS 'Average data IO in percent',
MAX(avg_data_io_percent) AS 'Maximum data IO in percent',
AVG(avg_log_write_percent) AS 'Average log write use in percent',
MAX(avg_log_write_percent) AS 'Maximum log write use in percent',
AVG(avg_memory_usage_percent) AS 'Average memory use in percent',
MAX(avg_memory_usage_percent) AS 'Maximum memory use in percent'
FROM sys.dm_db_resource_stats AS rs --past hour only
GROUP BY rs.dtu_limit, rs.cpu_limit;
Pour les autres requêtes, consultez les exemples dans sys.dm_db_resource_stats.
sys.resource_stats
La vue sys.resource_stats de la base de données master fournit des informations supplémentaires vous permettant de superviser les performances de votre base de données par rapport à son niveau de service et à sa taille de calcul. Les données, qui sont collectées toutes les cinq minutes, sont conservées pendant environ 14 jours. Cette vue est utile pour une analyse historique de plus long terme sur l’utilisation des ressources par votre base de données.
Le graphique suivant illustre l’utilisation des ressources d’UC pour une base de données Premium avec la taille de calcul P2 pour chaque heure de la semaine. Ce graphique spécifique commence un lundi, affiche cinq journées de travail, puis un week-end où l’application connaît une activité réduite.
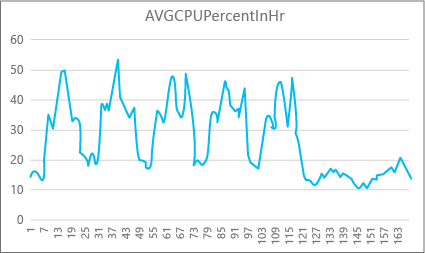
D’après les données, cette base de données présente actuellement une charge d’UC maximale légèrement supérieure à 50 % de l’utilisation de l’UC, par rapport à la taille de calcul P2 (le mardi, à la mi-journée). Si le processeur est le facteur dominant dans le profil de ressource de l’application, vous pouvez décider que P2 est la taille de calcul permettant de garantir que la charge de travail est toujours adaptée. Si vous prévoyez une croissance de l’application au fil du temps, vous avez tout intérêt à avoir une mémoire-tampon de ressources supplémentaires, afin que l’application n’atteigne jamais le plafond de performances. En augmentant la taille de calcul, vous pouvez éviter les erreurs visibles par les clients, qui sont susceptibles de se produire lorsqu’une application ne dispose pas de la puissance nécessaire pour traiter efficacement les requêtes, plus particulièrement dans les environnements sensibles à la latence. Comme exemple, considérons une base de données qui prend en charge une application remplissant les pages web en fonction des résultats des appels de la base de données.
D’autres types d’applications peuvent interpréter différemment le même graphique. Par exemple, si une application essaie de traiter les données de paie chaque jour et obtient le même graphique, ce genre de modèle de « traitement par lot » peut convenir avec une taille de calcul P1. La taille de calcul P1 comprend 100 DTU, contre 200 DTU pour la taille de calcul P2. La taille de calcul P1 fournit la moitié des performances de la taille de calcul P2. Par conséquent, 50 % d’utilisation de l’UC au niveau P2 correspond à 100 % d’utilisation de l’UC au niveau de performance P1. Si l’application n’a pas de délai d’expiration, le fait qu’une tâche volumineuse s’exécute en 2 h ou 2 h 30 peut ne pas avoir d’importance à condition qu’elle soit effectuée le jour même. Une application de cette catégorie peut probablement utiliser une taille de calcul P1. Vous pouvez tirer parti du fait qu’il y a des périodes pendant la journée où l’utilisation des ressources est moindre, ce qui signifie que toute période de pointe peut déborder sur l’un des creux plus tard dans la journée. La taille de calcul P1 peut convenir pour une application de ce type (et permettre de réaliser des économies) tant que les travaux peuvent se terminer à temps chaque jour.
Le moteur de base de données expose les informations sur les ressources utilisées pour chaque base de données active dans la vue sys.resource_stats de la base de données master dans chaque serveur. Les données de la table sont agrégées par intervalle de 5 minutes. Avec les niveaux de service De base, Standard et Premium, les données peuvent prendre plus de 5 minutes pour apparaître dans la table, ce qui signifie qu’elles conviennent mieux aux analyses historiques qu’aux analyses en quasi-temps réel. Interrogez la vue sys.resource_stats pour voir l’historique récent d’une base de données et valider que la réservation sélectionnée a fourni les performances souhaitées lorsque c’était nécessaire.
Notes
Dans Azure SQL Database, vous devez être connecté à la base de données master pour interroger sys.resource_stats dans les exemples suivants.
Cet exemple illustre l’exposition des données dans cette vue :
SELECT TOP 10 *
FROM sys.resource_stats
WHERE database_name = 'userdb1'
ORDER BY start_time DESC;
L’exemple suivant vous montre différentes manières d’utiliser la vue du catalogue sys.resource_stats pour obtenir des informations sur la façon dont votre base de données utilise les ressources :
Pour examiner l’utilisation des ressources de la semaine dernière pour la base de données utilisateur
userdb1, vous pouvez exécuter cette requête en substituant votre propre nom de base de données :SELECT * FROM sys.resource_stats WHERE database_name = 'userdb1' AND start_time > DATEADD(day, -7, GETDATE()) ORDER BY start_time DESC;Pour évaluer l’adéquation entre votre charge de travail et la taille de calcul, vous devez étudier les différents aspects des métriques de ressources : UC, lectures, écritures, nombre de Workers et nombre de sessions. Voici une requête révisée utilisant
sys.resource_statspour signaler les valeurs moyennes et maximales de ces métriques de ressources, pour chaque niveau de service pour lequel la base de données a été provisionnée :SELECT rs.database_name , rs.sku , storage_mb = MAX(rs.Storage_in_megabytes) , 'Average CPU Utilization In %' = AVG(rs.avg_cpu_percent) , 'Maximum CPU Utilization In %' = MAX(rs.avg_cpu_percent) , 'Average Data IO In %' = AVG(rs.avg_data_io_percent) , 'Maximum Data IO In %' = MAX(rs.avg_data_io_percent) , 'Average Log Write Utilization In %' = AVG(rs.avg_log_write_percent) , 'Maximum Log Write Utilization In %' = MAX(rs.avg_log_write_percent) , 'Average Requests In %' = AVG(rs.max_worker_percent) , 'Maximum Requests In %' = MAX(rs.max_worker_percent) , 'Average Sessions In %' = AVG(rs.max_session_percent) , 'Maximum Sessions In %' = MAX(rs.max_session_percent) FROM sys.resource_stats AS rs WHERE rs.database_name = 'userdb1' AND rs.start_time > DATEADD(day, -7, GETDATE()) GROUP BY rs.database_name, rs.sku;Avec les informations ci-dessus relatives aux valeurs moyennes et maximales de chaque métrique de ressources, vous pouvez évaluer l’adéquation entre votre charge de travail et la taille de calcul que vous avez choisie. En général, les valeurs moyennes de
sys.resource_statsvous offrent une bonne référence à utiliser par rapport à la taille cible. Elles doivent constituer votre principale jauge de mesure.Pour les bases de données de modèle d’achat de DTU :
Par exemple, vous pouvez utiliser le niveau de service Standard avec la taille de calcul S2. Les pourcentages d’utilisation moyens pour les lectures et écritures d’UC et d’E/S se situent en deçà de 40 %, le nombre moyen de Workers est inférieur à 50 et le nombre moyens de sessions est inférieur à 200. Votre charge de travail peut être prise en charge par la taille de calcul S1. Il est facile de voir si votre base de données s’intègre dans les limites de Workers et de sessions. Pour voir si une base de données peut s’adapter à une taille de calcul inférieure, divisez le nombre de DTU de la taille de calcul inférieure par le nombre de DTU de votre taille de calcul actuelle, puis multipliez le résultat par 100 :
S1 DTU / S2 DTU * 100 = 20 / 50 * 100 = 40Le résultat correspond à la différence de performances relative entre les deux tailles de calcul en pourcentage. Si votre utilisation des ressources ne dépasse pas ce résultat, votre charge de travail peut être traitée par la taille de calcul inférieure. Toutefois, vous devez également examiner toutes les plages de valeurs d’utilisation des ressources, et déterminer, d’après le pourcentage, combien de fois la charge de travail de votre base de données pourrait s’adapter à la taille de calcul inférieure. La requête suivante génère le pourcentage d’adéquation par dimension de ressource, selon le seuil de 40 % calculé dans cet exemple :
SELECT database_name, 100*((COUNT(database_name) - SUM(CASE WHEN avg_cpu_percent >= 40 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'CPU Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_log_write_percent >= 40 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Log Write Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_data_io_percent >= 40 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Physical Data IO Fit Percent' FROM sys.resource_stats WHERE start_time > DATEADD(day, -7, GETDATE()) AND database_name = 'sample' --remove to see all databases GROUP BY database_name;En fonction du niveau de service de votre base de données, vous pouvez décider si votre charge de travail peut s’adapter à la taille de calcul inférieure. Si l’objectif de charge de travail de votre base de données est de 99,9 % et que la requête précédente retourne des valeurs supérieures à 99,9 % pour les trois dimensions de ressources, il est probable que votre charge de travail puisse s’adapter à la taille de calcul inférieure.
En examinant le pourcentage d’adéquation, vous savez par ailleurs si vous devez passer à la taille de calcul supérieure pour atteindre votre objectif. Par exemple, l’utilisation du processeur pour un exemple de base de données au cours de la dernière semaine :
Pourcentage moyen d’UC Pourcentage maximum d’UC 24,5 100,00 Le pourcentage moyen d’UC représente environ un quart de la limite de la taille de calcul, ce qui correspondrait bien à la taille de calcul de la base de données.
Pour les bases de données de modèle d’achat de DTU et de modèle d’achat de vCore :
La valeur maximale montre que la base de données atteint la limite de la taille de calcul. Devez-vous passer à la taille de calcul supérieure ? Regardez le nombre de fois où votre charge de travail atteint 100 % et comparez ce chiffre à l’objectif de charge de travail de votre base de données.
SELECT database_name, 100*((COUNT(database_name) - SUM(CASE WHEN avg_cpu_percent >= 100 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'CPU Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_log_write_percent >= 100 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Log Write Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_data_io_percent >= 100 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Physical Data IO Fit Percent' FROM sys.resource_stats WHERE start_time > DATEADD(day, -7, GETDATE()) AND database_name = 'sample' --remove to see all databases GROUP BY database_name;Ces pourcentages correspondent au nombre d’échantillons que votre charge de travail fait rentrer sous la taille de calcul actuelle. Si cette requête retourne une valeur inférieure à 99,9 % pour l’une des trois dimensions de ressources, votre charge de travail moyenne échantillonnée a dépassé les limites. Passez à la taille de calcul supérieure ou utilisez des techniques de réglage d’application afin de réduire la charge sur la base de données.
Notes
Pour les pools élastiques, vous pouvez surveiller des bases de données individuelles dans le pool avec les techniques décrites dans cette section. Vous pouvez également superviser le pool dans son ensemble. Pour plus d’informations, consultez l’article Surveiller et gérer un pool élastique.
Nombre maximal de requêtes simultanées
Pour afficher le nombre actuel de requêtes simultanées, exécutez cette requête sur votre base de données utilisateur :
SELECT COUNT(*) AS [Concurrent_Requests]
FROM sys.dm_exec_requests AS R;
Pour analyser la charge de travail d’une base de données, modifiez cette requête pour la filtrer selon la base de données spécifique que vous analysez. Tout d’abord, mettez à jour le nom de la base de données de MyDatabase vers la base de données souhaitée, puis exécutez la requête suivante pour rechercher le nombre de demandes simultanées dans cette base de données :
SELECT COUNT(*) AS [Concurrent_Requests]
FROM sys.dm_exec_requests AS R
INNER JOIN sys.databases AS D
ON D.database_id = R.database_id
AND D.name = 'MyDatabase';
Il s’agit simplement d’un instantané à un point unique dans le temps. Pour obtenir une meilleure compréhension de votre charge de travail et des exigences liées aux demandes simultanées, il vous faut collecter plusieurs échantillons au fil du temps.
Nombre maximal d’événements de connexion simultanée
Vous pouvez analyser vos modèles d’utilisateur et d’application pour avoir une idée de la fréquence des événements de connexion. Vous pouvez également exécuter des charges réelles dans un environnement de test pour vous assurer que vous n’atteignez pas cette limite ou d’autres limites décrites dans cet article. Il n’existe aucune requête ou vue de gestion dynamique qui peut vous indiquer le nombre de connexions simultanées ou un historique dédié.
Si plusieurs clients utilisent la même chaîne de connexion, le service authentifie chaque connexion. Si 10 utilisateurs se connectent simultanément à une base de données avec les mêmes nom d’utilisateur et mot de passe, dix connexions simultanées seront établies. Cette limite s’applique uniquement à la durée de la connexion et de l’authentification. Si ces mêmes 10 utilisateurs se connectent séquentiellement à la base de données, le nombre de connexions simultanées ne sera jamais supérieur à 1.
Notes
Actuellement, cette limite ne s’applique pas aux bases de données de pools élastiques.
Nombre maximal de sessions
Pour voir le nombre de sessions simultanément actives, exécutez cette requête sur votre base de données :
SELECT COUNT(*) AS [Sessions]
FROM sys.dm_exec_connections;
Si vous analysez une charge de travail SQL Server, modifiez la requête pour vous concentrer sur une base de données spécifique. Cette requête vous aide à déterminer les éventuels besoins de votre session pour la base de données si vous envisagez de la déplacer vers Azure. Commencez par mettre à jour le nom de la base de données de MyDatabase vers la base de données souhaitée, puis exécutez la requête suivante :
SELECT COUNT(*) AS [Sessions]
FROM sys.dm_exec_connections AS C
INNER JOIN sys.dm_exec_sessions AS S
ON (S.session_id = C.session_id)
INNER JOIN sys.databases AS D
ON (D.database_id = S.database_id)
WHERE D.name = 'MyDatabase';
Là encore, ces requêtes renvoient un nombre à un point dans le temps. Si vous collectez plusieurs échantillons au fur et à mesure, vous bénéficierez d’une meilleure compréhension de l’utilisation de votre session.
Vous pouvez obtenir des statistiques d’historique sur les sessions en interrogeant la vue de catalogue sys.resource_stats et en consultant la colonne active_session_count.
Calculer les tailles de base de données et d’objets
La requête suivante renvoie la taille de votre base de données en mégaoctets :
-- Calculates the size of the database.
SELECT SUM(CAST(FILEPROPERTY(name, 'SpaceUsed') AS bigint) * 8192.) / 1024 / 1024 AS size_mb
FROM sys.database_files
WHERE type_desc = 'ROWS';
La requête suivante retourne la taille d’objets individuels (en mégaoctets) dans votre base de données :
-- Calculates the size of individual database objects.
SELECT o.name, SUM(ps.reserved_page_count) * 8.0 / 1024 AS size_mb
FROM sys.dm_db_partition_stats AS ps
INNER JOIN sys.objects AS o
ON ps.object_id = o.object_id
GROUP BY o.name
ORDER BY size_mb DESC;
Superviser les performances des requêtes
Des requêtes lentes ou longues peuvent consommer des ressources système significatives. Cette section montre comment détecter quelques problèmes courants liés aux performances de requête en utilisant la vue de gestion dynamique sys.dm_exec_query_stats. La vue contient une ligne par instruction de requête dans le plan en cache et la durée de vie des lignes est liée au plan lui-même. Lorsqu'un plan est supprimé du cache, les lignes correspondantes sont éliminées de cette vue.
Rechercher les principales requêtes par temps processeur
L’exemple suivant retourne des informations relatives aux 15 premières requêtes, classées sur la base du temps processeur moyen par exécution. Cet exemple agrège les requêtes selon leur hachage de requête et, logiquement, les requêtes équivalentes sont regroupées sur la base de leur consommation cumulée de ressources.
SELECT TOP 15 query_stats.query_hash AS "Query Hash",
SUM(query_stats.total_worker_time) / SUM(query_stats.execution_count) AS "Avg CPU Time",
MIN(query_stats.statement_text) AS "Statement Text"
FROM
(SELECT QS.*,
SUBSTRING(ST.text, (QS.statement_start_offset/2) + 1,
((CASE statement_end_offset
WHEN -1 THEN DATALENGTH(ST.text)
ELSE QS.statement_end_offset END
- QS.statement_start_offset)/2) + 1) AS statement_text
FROM sys.dm_exec_query_stats AS QS
CROSS APPLY sys.dm_exec_sql_text(QS.sql_handle) AS ST
) AS query_stats
GROUP BY query_stats.query_hash
ORDER BY 2 DESC;
Superviser les plans de requête pour le temps processeur cumulé
Un plan de requête inefficace peut également augmenter la consommation du processeur. L’exemple suivant détermine quelle requête utilise le plus de ressources de processeur cumulées dans l’historique récent.
SELECT
highest_cpu_queries.plan_handle,
highest_cpu_queries.total_worker_time,
q.dbid,
q.objectid,
q.number,
q.encrypted,
q.[text]
FROM
(SELECT TOP 15
qs.plan_handle,
qs.total_worker_time
FROM
sys.dm_exec_query_stats AS qs
ORDER BY qs.total_worker_time desc
) AS highest_cpu_queries
CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS q
ORDER BY highest_cpu_queries.total_worker_time DESC;
Superviser les requêtes bloquées
Des requêtes lentes ou longues peuvent contribuer à une consommation excessive de ressources et être la conséquence de requêtes bloquées. La cause du blocage peut être une conception médiocre d’application, de mauvais plans de requête, le manque d’index utiles, et ainsi de suite.
Vous pouvez utiliser la vue sys.dm_tran_locks pour obtenir des informations sur l’activité de verrouillage actuelle dans la base de données. Pour obtenir un exemple de code, consultez sys.dm_tran_locks. Pour plus d’informations la résolution des problèmes bloquants, consultez Comprendre et résoudre les problèmes bloquants Azure SQL.
Superviser les interblocages
Dans certains cas, plusieurs requêtes peuvent se bloquer mutuellement, ce qui entraîne un interblocage.
Vous pouvez créer un suivi d’événements étendus dans Azure SQL Database pour capturer les événements d’interblocage, puis rechercher les requêtes associées et leurs plans d’exécution dans le magasin des requêtes. Pour en savoir plus, consultez Analyser et empêcher les interblocages dans Azure SQL Database, notamment un labo pour provoquer un interblocage dans AdventureWorksLT. Découvrez-en plus sur les types de ressources susceptibles de se bloquer.
Contenu connexe
- Présentation d’Azure SQL Database et d’Azure SQL Managed Instance
- Diagnostiquer et résoudre les problèmes d’utilisation élevée du processeur dans Azure SQL Database
- Paramétrer les performances des applications et des bases de données dans Azure SQL Database
- Comprendre et résoudre les problèmes de blocage d’Azure SQL Database
- Analyser et empêcher les blocages dans Azure SQL Database
- Surveiller les charges de travail Azure SQL avec l’observateur de base de données (aperçu)
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour