Démarrage rapide : Créer un détecteur d’objets avec le site web Custom Vision
Dans ce guide de démarrage rapide, vous allez découvrir comment utiliser le site web Custom Vision pour créer un modèle de détecteur d’objets. Une fois que vous avez créé un modèle, vous pouvez le tester avec de nouvelles images et l’intégrer à votre propre application de reconnaissance d’images.
Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer.
Prérequis
- Un ensemble d’images avec lequel entraîner votre modèle de détecteur. Vous pouvez utiliser l’ensemble d’exemples d’images disponible sur GitHub, ou choisir vos propres images à l’aide des conseils ci-dessous.
- Un navigateur web pris en charge
Créer des ressources Custom Vision
Pour utiliser le service Custom Vison, vous devez créer des ressources de formation et de prédiction Custom Vision dans Azure. Pour ce faire, dans le portail, remplissez la boîte de dialogue de la page de création Custom Vision pour créer une ressource de formation et une ressource de prédiction.
Création d'un projet
Dans votre navigateur web, accédez à la page web Custom Vision et sélectionnez Sign in (Se connecter). Connectez-vous avec le même compte que celui utilisé pour vous connecter au portail Azure.
Pour créer votre premier projet, sélectionnez New Project (Nouveau projet). La boîte de dialogue Créer un projet s’affiche.
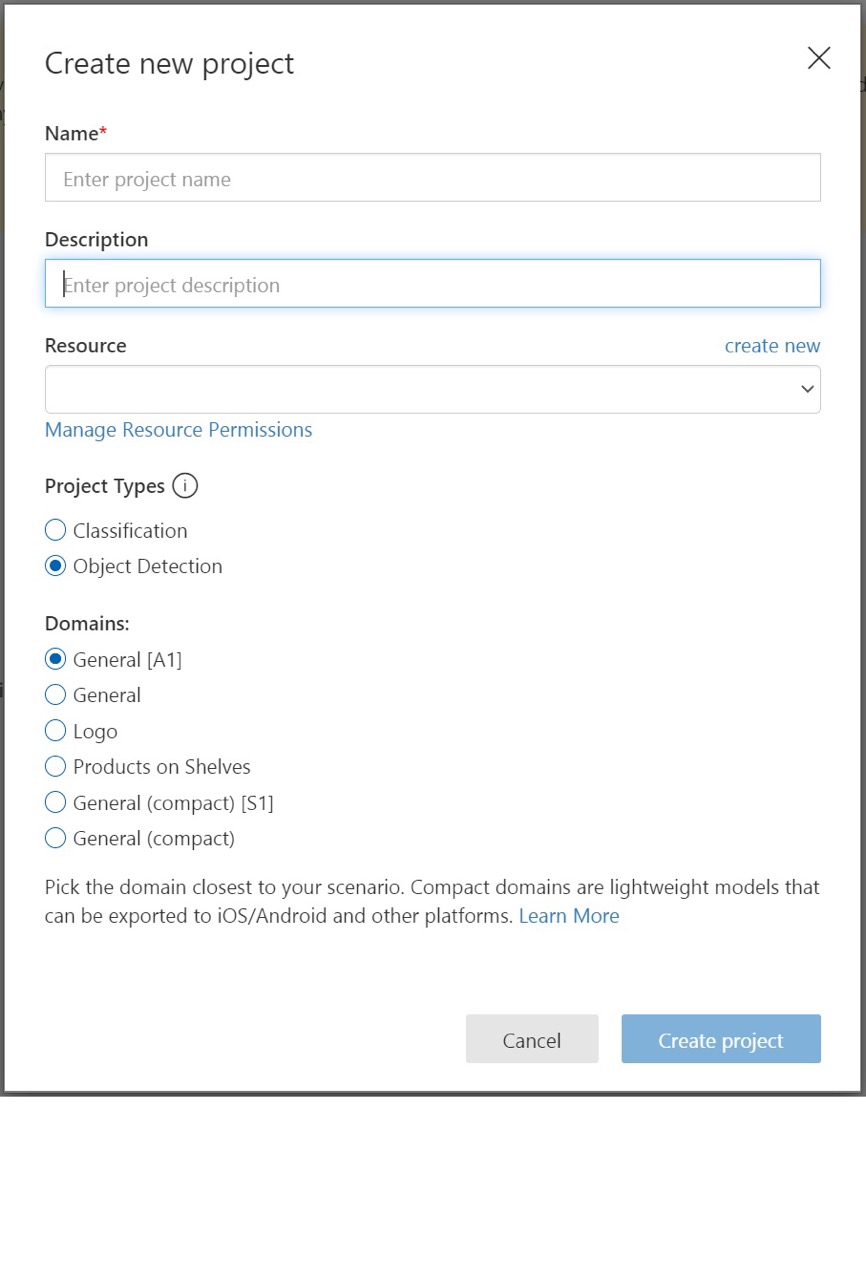
Entrez un nom et une description pour le projet. Sélectionnez ensuite votre ressource de formation Custom Vision. Si le compte avec lequel vous êtes connecté est associé à un compte Azure, la liste déroulante Ressource affiche toutes vos ressources Azure compatibles.
Remarque
Si aucune ressource n’est disponible, vérifiez que vous vous êtes connecté à customvision.ai avec le même compte que celui utilisé pour vous connecter au portail Azure. Vérifiez aussi que vous avez sélectionné le même « Répertoire » dans le site web Custom Vision que celui du portail Azure où se trouvent vos ressources Custom Vision. Dans les deux sites, vous pouvez sélectionner votre répertoire à partir du menu déroulant de compte situé en haut à droite de l’écran.
Dans le nœud
Sélectionnez Object Detection (Détection d’objet) sous Project Types (Types de projets).
Sélectionnez ensuite un des domaines disponibles. Chaque domaine optimise le détecteur pour des types spécifiques d’images, comme décrit dans le tableau suivant. Vous pouvez changer de domaine ultérieurement si vous le souhaitez.
Domain Objectif Généralités Optimisé pour un large éventail de tâches de détection d’objets. Si aucun autre domaine n’est approprié ou si vous hésitez sur le choix du domaine, sélectionnez le domaine Général. Logo Optimisé pour rechercher des logos de marque dans les images. Products on shelves (Produits en rayon) Optimisé pour la détection et la classification des produits en rayon. Compact Domains (Domaines compacts) Optimisé en fonction des contraintes de détection d’objets en temps réel sur les appareils mobiles. Les modèles générés par les domaines compacts sont exportables pour s’exécuter localement. Enfin, sélectionnez Create project (Créer le projet).
Choisir les images d’entraînement
Nous vous recommandons d’utiliser au moins 30 images par étiquette dans le jeu d’entraînement initial. Vous allez également collecter quelques images supplémentaires pour tester votre modèle une fois qu’il est entraîné.
Pour entraîner votre modèle efficacement, utilisez des images avec une variété de visuels. Sélectionnez des images dont les éléments suivants varient :
- angle de l’appareil photo
- éclairage
- background
- style de visuel
- objets individuels/groupés
- taille
- type
En outre, vérifiez que toutes vos images d’entraînement respectent les critères suivants :
- format .jpg, .png, .bmp ou .gif
- taille ne dépassant pas 6 Mo (4 Mo pour les images de prédiction)
- le côté le plus court ne doit pas comporter moins de 256 pixels ; les images d’une dimension inférieure sont automatiquement mises à l’échelle par le service Vision personnalisée
Charger et étiqueter des images
Dans cette section, vous chargez et étiquetez manuellement des images pour faciliter l’entraînement du détecteur.
Pour ajouter des images, sélectionnez Ajouter des images, puis Parcourir les fichiers locaux. Sélectionnez Open (Ouvrir) pour charger les images.

Vous verrez vos images chargées dans la section Untagged (Sans étiquette) de l’interface utilisateur. L’étape suivante consiste à étiqueter manuellement les objets que vous souhaitez que le détecteur apprenne à reconnaître. Sélectionnez la première image pour ouvrir la fenêtre de dialogue d’étiquetage.
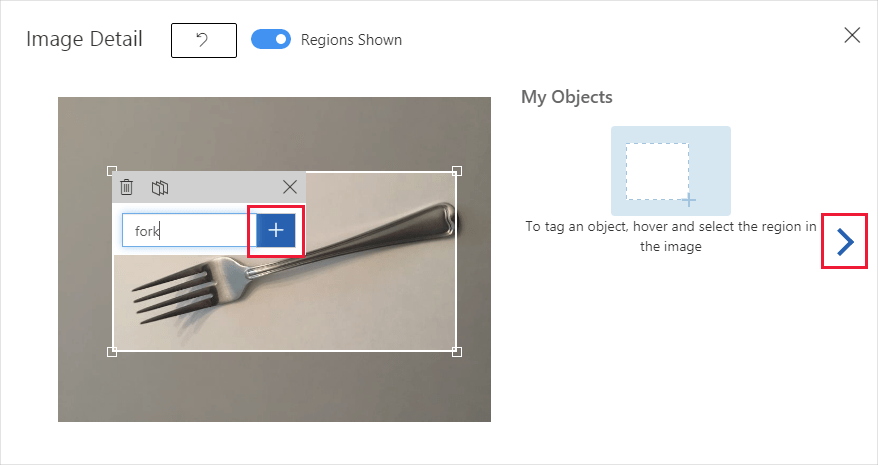
Sélectionnez et faites glisser un rectangle autour de l’objet dans votre image. Ensuite, entrez un nouveau nom d’étiquette avec le bouton + , ou sélectionnez une étiquette existante dans la liste déroulante. Il est important d’étiqueter chaque instance des objets que vous souhaitez détecter, car le détecteur utilise la zone d’arrière-plan sans étiquette comme exemple négatif dans l’entraînement. Quand vous avez terminé l’étiquetage, sélectionnez la flèche à droite pour enregistrer vos étiquettes et passer à l’image suivante.
Pour charger un autre ensemble d’images, revenez en haut de cette section et répétez les étapes.
Entraîner le détecteur
Pour entraîner le modèle de détecteur, sélectionnez le bouton Train (Entraîner). Le détecteur utilise toutes les images actuelles et leurs étiquettes pour créer un modèle qui identifie chaque objet étiqueté. Ce processus peut prendre plusieurs minutes.

Le processus d’entraînement ne doit durer que quelques minutes. Pendant ce temps, des informations sur le processus d’entraînement s’affichent dans l’onglet Performance.
Évaluer le détecteur
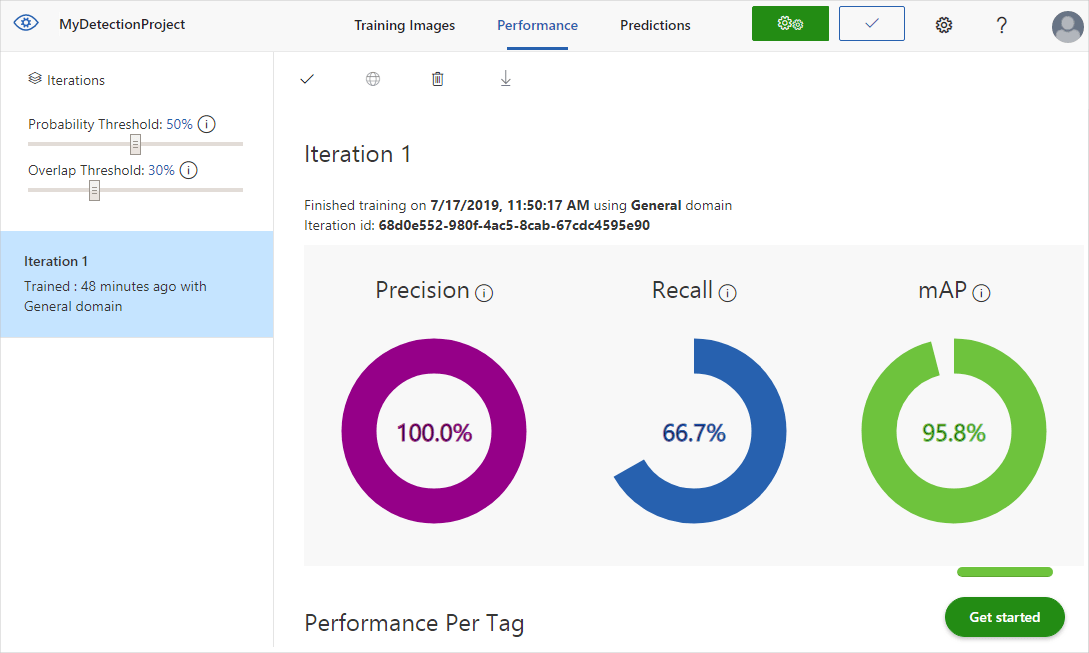
Une fois l’entraînement terminé, les performances du modèle sont calculées et affichées. Le service Custom Vision utilise les images que vous avez soumises pour l’entraînement afin de calculer la précision, le rappel et la précision moyenne. La précision et le rappel sont deux mesures différentes de l’efficacité d’un détecteur :
- La précision indique la proportion des classifications identifiées qui étaient correctes. Par exemple, si le modèle a identifié 100 images comme étant des chiens et que 99 d’entre elles étaient effectivement des chiens, la précision est de 99 %.
- Le rappel indique la proportion des classifications réelles qui ont été correctement identifiées. Par exemple, s’il y avait 100 images de pommes et que le modèle en a identifié 80 comme étant des pommes, le rappel est de 80 %.
- Moyenne des précisions moyennes est la valeur moyenne de la précision moyenne. La précision moyenne est la zone sous la courbe de précision/rappel (précision tracée par rapport au rappel pour chaque prédiction effectuée).
Seuil de probabilité
Notez le curseur Probability Threshold (Seuil de probabilité) dans le volet gauche de l’onglet Performance. Il s’agit du niveau de confiance qu’une prédiction doit avoir pour être considérée comme correcte (dans le cadre du calcul de la précision et du rappel).
Quand vous interprétez des appels de prédiction avec un seuil de probabilité élevé, ils ont tendance à retourner des résultats avec une précision élevée au détriment des rappels ; les classifications détectées sont correctes, mais beaucoup restent non détectées. Un seuil de probabilité faible a l’effet opposé : la plupart des classifications réelles sont détectées, mais il y a plus de faux positifs dans ce jeu. En ayant ceci à l’esprit, vous devez définir le seuil de probabilité en fonction des besoins spécifiques de votre projet. Ultérieurement, lors de la réception des résultats de la prédiction côté client, vous devez utiliser la même valeur de seuil de probabilité que celle utilisée ici.
Seuil de chevauchement
Le curseur Seuil de chevauchement détermine si une prédiction d’objet est assez bonne pour être considérée comme « correcte » pour l’entraînement. Il définit le chevauchement minimal autorisé entre le cadre englobant de l’objet prédit et le cadre englobant réel entré par l’utilisateur. Si les cadres englobants ne se chevauchent pas à ce degré, la prédiction n’est pas considérée comme correcte.
Gérer les itérations d’entraînement
Chaque fois que vous entraînez votre détecteur, vous créez une nouvelle itération avec ses propres métriques de performances mises à jour. Vous pouvez afficher toutes vos itérations dans le volet gauche de l’onglet Performance. Dans le volet gauche, vous pouvez aussi trouver le bouton Supprimer, qui permet de supprimer une itération si elle est obsolète. Quand vous supprimez une itération, vous supprimez également toutes les images qui lui sont spécifiquement associées.
Consultez Utiliser votre modèle avec l’API de prédiction pour apprendre à accéder à vos modèles entraînés par programmation.
Étapes suivantes
Dans ce guide de démarrage rapide, vous avez découvert comment créer et entraîner un modèle de détecteur d’objets avec le site web Custom Vision. Vous obtenez ensuite plus d’informations sur le processus itératif d’amélioration de votre modèle.