Guide pratique pour entraîner un modèle de classification de texte personnalisée
Article
L’apprentissage est le processus dans lequel le modèle apprend à partir de vos données étiquetées. Une fois l’apprentissage effectué, vous pouvez afficher les performances du modèle pour déterminer si vous devez améliorer votre modèle.
Pour effectuer l’apprentissage d’un modèle, démarrez un travail d’apprentissage. Seuls les travaux terminés avec succès créent un modèle utilisable. Les travaux d’apprentissage expirent au bout de sept jours. Après ce délai, il n’est plus possible de récupérer les détails du travail. Si votre travail d’apprentissage s’est terminé avec succès et qu’un modèle a été créé, il ne sera pas affecté par l’expiration du travail. Vous ne pouvez exécuter qu’un seul travail d’apprentissage à la fois. Vous ne pouvez pas non plus lancer d’autres travaux au sein du même projet.
L’apprentissage peut durer de quelques minutes pour quelques documents à plusieurs heures en fonction de la taille du jeu de données et de la complexité de votre schéma.
Prérequis
Avant d’effectuer l’apprentissage de votre modèle, vous avez besoin des éléments suivants :
Avant que vous démarriez le processus d’apprentissage, les documents étiquetés de votre projet sont divisés en deux jeux : un jeu d’apprentissage et un jeu de test. Chacun d’eux a une fonction différente.
Le jeu d’apprentissage est utilisé dans l’apprentissage du modèle. Il s’agit de l’ensemble à partir duquel le modèle apprend la classe/les classes attribuées à chaque document.
Le jeu de test est un jeu témoin qui n’est pas présenté au modèle pendant l’apprentissage, mais uniquement lors de l’évaluation.
Après l’apprentissage du modèle, il est utilisé pour effectuer des prédictions à partir des documents du jeu de tests. En fonction de ces prédictions, les métriques d’évaluation du modèle sont calculées.
Nous vous recommandons de vérifier que toutes vos classes sont correctement représentées dans les jeux d’apprentissage et de test.
La classification de texte personnalisée prend en charge deux méthodes pour le fractionnement des données :
Fractionnement automatique du jeu de test à partir des données d’entraînement : le système répartit les données étiquetées entre les jeux d’entraînement et de test, en fonction des pourcentages que vous avez choisis. Le système tente d’avoir une représentation de toutes les classes de votre jeu d’entraînement. Le pourcentage recommandé pour le fractionnement est de 80 % pour l’apprentissage et de 20 % pour les tests.
Notes
Si vous choisissez l’option Fractionnement automatique du jeu de test à partir des données d’apprentissage, seules les données attribuées au jeu d’apprentissage sont fractionnées selon les pourcentages fournis.
Utiliser un fractionnement manuel des données d’apprentissage et de test : cette méthode permet aux utilisateurs de définir quels documents étiquetés doivent appartenir à quel jeu. Cette étape est activée uniquement si vous avez ajouté des documents à votre jeu de test lors de l’étiquetage des données.
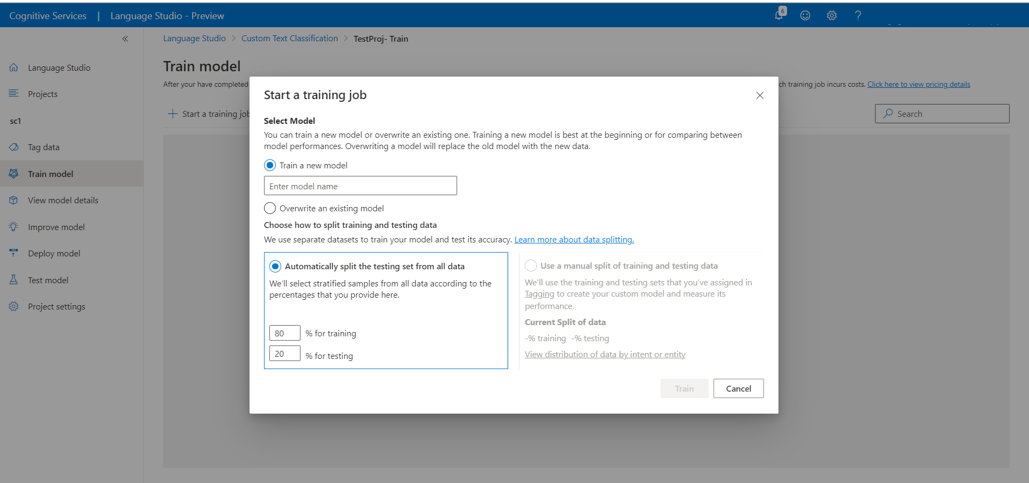
Pour commencer à effectuer l’apprentissage de votre modèle à partir de Language Studio :
Dans le menu de gauche, sélectionnez Travaux d’entraînement.
Sélectionnez Démarrer un travail de formation dans le menu supérieur.
Sélectionnez Effectuer l’apprentissage d’un nouveau modèle, puis tapez le nom du modèle dans la zone de texte. Vous pouvez également remplacer un modèle existant en sélectionnant cette option et le modèle de votre choix dans le menu déroulant. La remplacement d’un modèle entraîné est irréversible. Toutefois, cela n’affecte pas vos modèles déployés tant que vous ne déployez pas le nouveau modèle.
Sélectionnez la méthode de fractionnement des données. Vous pouvez choisir l’option Fractionnement automatique du jeu de test à partir des données d’apprentissage. Dans ce cas, le système fractionne vos données étiquetées en jeux d’apprentissage et de test, selon les pourcentages spécifiés. Vous pouvez également Utiliser un fractionnement manuel des données d’apprentissage et de test. Cette option est activée uniquement si vous avez ajouté des documents à votre jeu de tests lors de l’étiquetage des données. Pour plus d’informations sur le fractionnement des données, consultez Guide pratique pour effectuer l’apprentissage d’un modèle.
Sélectionner le bouton Train (Entraîner).
Si vous sélectionnez l’ID du travail d’apprentissage dans la liste, un volet latéral vous permet de vérifier la progression de la formation, l’état du travail et d’autres détails pour ce travail.
Notes
Seuls les emplois de formation achevés avec succès génèrent des modèles.
L’entraînement du modèle peut durer de quelques minutes à plusieurs heures selon la taille de vos données étiquetées.
Vous ne pouvez avoir qu’un seul travail d’entraînement en cours d’exécution à la fois. Vous ne pouvez pas démarrer un autre travail d’apprentissage dans le même projet tant que le travail en cours d’exécution n’est pas terminé.
Démarrer le travail d’apprentissage
Envoyez une requête POST en utilisant l’URL, les en-têtes et le corps JSON suivants pour envoyer un travail d’apprentissage. Remplacez les valeurs d’espace réservé suivantes par vos valeurs :
Nom de votre projet. Cette valeur respecte la casse.
myProject
{API-VERSION}
Version de l’API que vous appelez. La valeur référencée ici concerne la dernière version publiée. En savoir plus sur les autres versions d’API disponibles
2022-05-01
headers
Utilisez l’en-tête suivant pour authentifier votre demande.
Clé
Valeur
Ocp-Apim-Subscription-Key
Clé de votre ressource. Utilisée pour authentifier vos demandes d’API.
Corps de la demande
Utilisez le code JSON suivant dans le corps de la demande. Le modèle reçoit le {MODEL-NAME} une fois l’apprentissage effectué. Seuls les travaux d’apprentissage réussis produisent des modèles.
Pourcentage de vos données étiquetées à inclure dans le jeu d’apprentissage. La valeur recommandée est 80.
80
testingSplitPercentage
20
Pourcentage de vos données étiquetées à inclure dans le jeu de test. La valeur recommandée est 20.
20
Notes
Les trainingSplitPercentage et testingSplitPercentage sont nécessaires uniquement si Kind est défini sur percentage. La somme des deux pourcentages doit être égale à 100.
Une fois que vous avez envoyé votre requête API, vous recevez une réponse 202 indiquant que le travail a été envoyé correctement. Dans les en-têtes de réponse, extrayez la valeur location. Elle est au format suivant :
{JOB-ID} sert à identifier votre demande, car cette opération est asynchrone. Vous pouvez utiliser cette URL pour obtenir l’état de l’apprentissage.
Obtenir l’état des travaux d’apprentissage
L’apprentissage peut durer un certain temps en fonction de la taille de vos données d’apprentissage et de la complexité de votre schéma. Vous pouvez utiliser la requête suivante pour continuer à interroger l’état du travail d’apprentissage jusqu’à ce qu’il soit effectué avec succès.
Utilisez la requête GET suivante pour obtenir l’état de progression du processus d’apprentissage de votre modèle. Remplacez les valeurs d’espace réservé suivantes par vos valeurs :
Nom de votre projet. Cette valeur respecte la casse.
myProject
{JOB-ID}
ID de localisation de l’état d’entraînement de votre modèle. Il s’agit de la valeur d’en-tête location que vous avez reçue à l’étape précédente.
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx
{API-VERSION}
Version de l’API que vous appelez. La valeur référencée ici concerne la dernière version publiée. Pour plus d’informations sur les autres versions d’API disponibles, consultez Cycle de vie du modèle.
2022-05-01
headers
Utilisez l’en-tête suivant pour authentifier votre demande.
Clé
Valeur
Ocp-Apim-Subscription-Key
Clé de votre ressource. Utilisée pour authentifier vos demandes d’API.
Corps de la réponse
Une fois que vous avez envoyé la demande, vous recevez la réponse suivante.
Pour annuler un travail d’entraînement dans Language Studio, accédez à la page Travaux d’entraînement. Sélectionnez le travail d’apprentissage à annuler, puis sélectionnez Annuler dans le menu supérieur.
Créez une demande POST en utilisant l’URL, les en-têtes et le corps JSON suivants pour annuler un travail d’entraînement.
URL de la demande
Utilisez l’URL suivante quand vous créez votre demande d’API. Remplacez les valeurs d’espace réservé suivantes par vos valeurs :
Nom de votre projet. Cette valeur respecte la casse.
EmailApp
{JOB-ID}
Cette valeur est l’ID du travail d’entraînement.
XXXXX-XXXXX-XXXX-XX
{API-VERSION}
Version de l’API que vous appelez. La valeur référencée correspond à la dernière version du modèle publiée.
2022-05-01
headers
Utilisez l’en-tête suivant pour authentifier votre demande.
Clé
Valeur
Ocp-Apim-Subscription-Key
Clé de votre ressource. Utilisée pour authentifier vos demandes d’API.
Après avoir envoyé votre demande d’API, vous recevrez une réponse 202 avec un en-tête Operation-Location utilisé pour vérifier l’état du travail.
Étapes suivantes
Une fois l’apprentissage effectué, vous pouvez afficher les performances du modèle pour améliorer votre modèle le cas échéant. Dès que vous êtes satisfait de votre modèle, vous pouvez le déployer et le rendre disponible pour la classification de texte.