Ajouter un jeu de données d’apprentissage vocal professionnel
Dès que vous êtes prêt à créer une voix personnalisée pour la synthèse vocale dans votre application, vous devez dans un premier temps rassembler les enregistrements audio et les scripts associés pour commencer l’apprentissage du modèle vocal. Pour plus d’informations sur l’enregistrement d’échantillons vocaux, consultez le tutoriel. Le service Speech se sert de ces données pour créer une voix unique correspondant à la voix des enregistrements. Après avoir entraîné la voix, vous pouvez commencer la synthèse vocale dans vos applications.
Toutes les données que vous chargez doivent respecter les exigences associées au type de données choisi. Il est important de formater correctement vos données avant leur chargement, ce qui permet au service Speech de les traiter correctement. Pour vérifier que vos données sont correctement formatées, voir Type de données d’entraînement.
Notes
- Les utilisateurs qui disposent d’un abonnement standard (S0) peuvent charger cinq fichiers de données simultanément. Si vous atteignez la limite, patientez au moins jusqu’à la fin de l’importation de l’un de vos jeux de données. puis réessayez.
- Le nombre maximal de fichiers de données qu’il est autorisé d’importer par abonnement est de 500 fichiers zip pour les utilisateurs disposant d’un abonnement standard (S0). Pour plus d’informations, consultez les Quotas et limites du service Speech.
Charger vos données
Quand vous êtes prêt à charger vos données, accédez à l’onglet Préparer des données d’entraînement pour ajouter votre premier jeu d’entraînement et charger des données. Un jeu d’apprentissage est un ensemble d’énoncés audio et de scripts correspondants utilisés pour effectuer l'apprentissage d’un modèle vocal. Vous pouvez utiliser un jeu d’entraînement pour organiser vos données d’entraînement. Le service vérifie la disponibilité des données pour chaque jeu d’apprentissage. Vous pouvez importer des données multiples dans un jeu d’apprentissage.
Pour charger des données d’entraînement, procédez comme suit :
- Connectez-vous à Speech Studio.
- Sélectionnez Voix personnalisée> Votre nom de projet >Préparer des données d’entraînement>Charger des données.
- Dans l’Assistant Chargement de données, choisissez un type de données, puis sélectionnez Suivant.
- Sélectionnez des fichiers locaux à partir de votre ordinateur ou entrez l’URL du stockage Blob Azure pour charger des données.
- Sous Spécifier le jeu d’entraînement cible, sélectionnez un jeu d’entraînement existant ou créez-en un. Si vous avez créé un jeu d’entraînement, vérifiez qu’il est sélectionné dans la liste déroulante avant de continuer.
- Sélectionnez Suivant.
- Entrez un nom et une description pour vos données, puis sélectionnez Suivant.
- Passez en revue les détails du chargement, puis sélectionnez Envoyer.
Notes
Les ID en double ne sont pas acceptés. Les énoncés avec le même ID seront supprimés.
Les noms audio en double seront retirés de l’apprentissage. Veillez à ce que les données sélectionnées ne comportent pas les mêmes noms audio au sein du fichier .zip ou dans plusieurs fichiers .zip. Si des ID d’énoncé (dans des fichiers audio ou de script) sont dupliqués, ils sont rejetés.
Les fichiers de données sont validés automatiquement lorsque vous sélectionnez Envoyer. La validation des données passe par une série de vérifications des fichiers audio visant à contrôler leur format, leur taille et leur taux d’échantillonnage. En cas d’erreurs, corrigez-les et resoumettez-les.
Une fois que vous avez chargé les données, vous pouvez vérifier les détails dans la vue détaillée du jeu d’apprentissage. Dans la page de détails, vous pouvez vérifier plus précisément les problèmes de prononciation et le niveau de bruit de toutes vos données. Le score de prononciation au niveau de la phrase varie entre 0 et 100. Normalement, un score inférieur à 70 indique une erreur de prononciation ou un problème de correspondance du script. Les énoncés avec un score global inférieur à 70 sont rejetés. Un accent marqué peut réduire votre score de prononciation et affecter la voix numérique générée.
Résoudre les problèmes de données en ligne
Après le chargement, vous pouvez vérifier les détails des données du jeu d’apprentissage. Avant de continuer à entraîner votre modèle vocal, vous devez essayer de résoudre les problèmes de données.
Vous pouvez identifier et résoudre les problèmes de données par énoncé dans Speech Studio.
Dans la page de détails, rendez-vous à la page des Données acceptées ou celle des Données rejetées. Sélectionnez les énoncés individuels à modifier, puis sélectionnez Modifier.
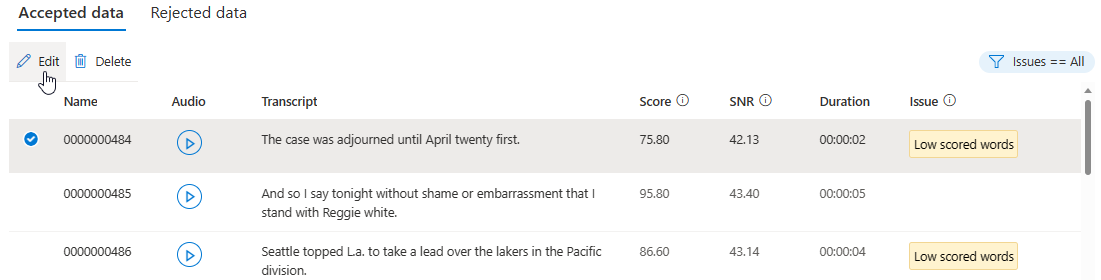
Vous pouvez choisir les problèmes de données à afficher selon vos critères.
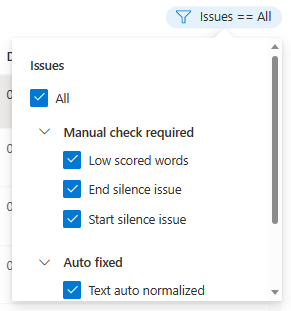
La fenêtre Modifier s’affiche.
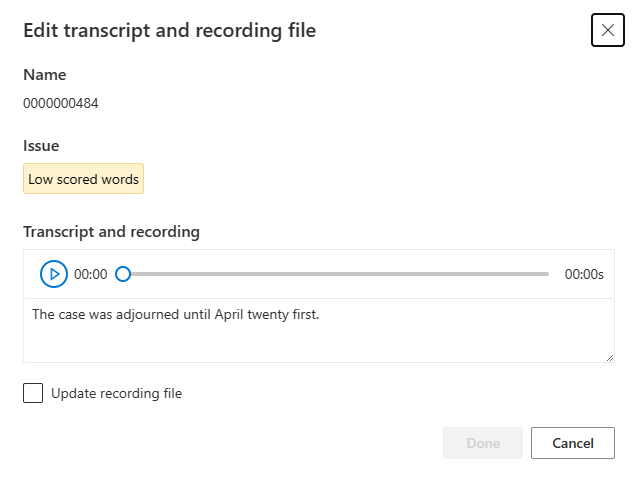
Mettez à jour la transcription ou le fichier d’enregistrement en fonction de la description du problème dans la fenêtre d’édition.
Vous pouvez modifier la transcription dans la zone de texte, puis sélectionnez Terminé
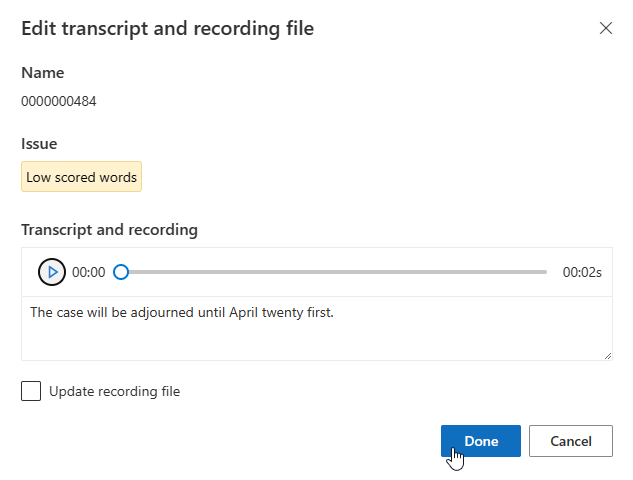
Si vous devez mettre à jour le fichier d’enregistrement, sélectionnez Mettre à jour le fichier d’enregistrement, puis chargez le fichier d’enregistrement fixe (.wav).
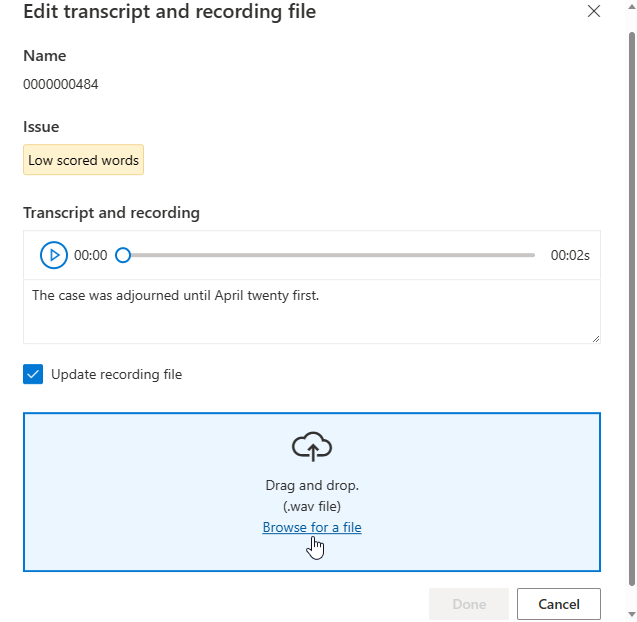
Une fois les modifications apportées à vos données, vous devez vérifier la qualité des données en cliquant sur Analyser les données avant d’utiliser ce jeu de données pour l’entraînement.
Vous ne pouvez pas sélectionner ce jeu d’apprentissage pour le modèle d’apprentissage avant la fin de l’analyse.

Vous pouvez également supprimer des énoncés présentant des problèmes en les sélectionnant et en cliquant sur Supprimer.
Problèmes de données typiques
Les problèmes sont divisés en trois types. Reportez-vous aux tableaux suivants pour vérifier les types d’erreurs respectifs.
Rejeté automatiquement
Les données avec ces erreurs ne seront pas utilisées pour l’apprentissage. Les données importées avec des erreurs seront ignorées. Vous n’avez donc pas besoin de les supprimer. Vous pouvez corriger ces erreurs de données en ligne ou charger à nouveau les données corrigées pour l’entraînement.
| Category | Nom | Description |
|---|---|---|
| Script | Séparateur non valide | Vous devez séparer l’ID d’énoncé et le contenu du script par un caractère de tabulation. |
| Script | ID de script non valide | L’ID de ligne de script doit être numérique. |
| Script | Script dupliqué | Chaque ligne du contenu du script doit être unique. La ligne est dupliquée avec {}. |
| Script | Script trop long | La taille du script doit être inférieure à 1000 caractères. |
| Script | Aucun audio correspondant | L’ID de chaque énoncé (chaque ligne du fichier de script) doit correspondre à l’ID de l’audio. |
| Script | Aucun script valide | Aucun script valide n’a été trouvé dans ce jeu de données. Corrigez les lignes de script affichées dans la liste détaillée des problèmes. |
| Audio | Aucun script correspondant | Aucun fichier audio ne correspond à l’ID de script. Le nom des fichiers .wav doit correspondre aux ID du fichier de script. |
| Audio | Format audio non valide | Le format audio des fichiers .wav n’est pas valide. Vérifiez le format de fichier .wav à l’aide d’un outil audio comme SoX. |
| Audio | Taux d’échantillonnage faible | La fréquence d’échantillonnage des fichiers .wav ne peut pas être inférieure à 16 KHz. |
| Audio | Audio trop long | La durée audio est supérieure à 30 secondes. Fractionnez le contenu audio long en plusieurs fichiers. Il est judicieux de rendre les énoncés plus courts que 15 secondes. |
| Audio | Aucun audio valide | Aucun audio valide n’est trouvé dans ce jeu de données. Vérifiez vos données audio et chargez-les à nouveau. |
| Incompatibilité | Énoncé à faible score | Le score de prononciation au niveau de la phrase est inférieur à 70. Examinez le script et le contenu audio pour vérifier qu’ils correspondent. |
Corrigé automatiquement
Les erreurs suivantes sont résolues automatiquement, mais vous devez vérifier et confirmer que les corrections ont été effectués.
| Category | Nom | Description |
|---|---|---|
| Incompatibilité | Silence résolu automatiquement | La durée du silence de début est détectée comme étant inférieure à 100 ms et a été étendue à 100 ms automatiquement. Téléchargez le jeu de données normalisé et passez-le en revue. |
| Incompatibilité | Silence résolu automatiquement | La durée du silence de fin est détectée comme étant inférieure à 100 ms et a été étendue à 100 ms automatiquement. Téléchargez le jeu de données normalisé et passez-le en revue. |
| Script | Texte normalisé automatiquement | Le texte est automatiquement normalisé pour les chiffres, les symboles et les abréviations. Examinez le script et le fichier audio pour vérifier leur correspondance. |
Vérification manuelle requise
Les erreurs non résolues énumérées dans le tableau suivant affectent la qualité de l’apprentissage, mais les données avec ces erreurs ne sont pas exclues lors de l’apprentissage. Pour un apprentissage de meilleure qualité, il est judicieux de corriger ces erreurs manuellement.
| Category | Nom | Description |
|---|---|---|
| Script | Texte non normalisé | Ce script contient des symboles. Normalisez les symboles pour qu’ils correspondent à l’audio. Par exemple, normalisez / par rapport à la barre oblique. |
| Script | Trop peu d’énoncés interrogatifs | Au moins 10 % de l’ensemble des énoncés doivent être des phrases interrogatives. Cela permet au modèle vocal d’exprimer correctement une tonalité interrogative. |
| Script | Pas assez d’énoncés exclamatifs | Au moins 10 % du total des énoncés doivent être des phrases exclamatives. Cela permet au modèle vocal d’exprimer correctement une tonalité enthousiaste. |
| Script | Aucun signe de ponctuation de fin valide | Ajoutez l’un des signes de ponctuation suivants à la fin de la ligne : point (demi-chasse « . » ou pleine chasse « 。 »), point d’exclamation (demi-chasse « ! » ou pleine chasse « ! ») ou point d’interrogation (demi-chasse « ? » ou pleine chasse « ? »). |
| Audio | Taux d’échantillonnage faible pour la voix neuronale | Un taux d’échantillonnage de 24 KHz ou supérieur est recommandé pour vos fichiers .wav en vue de créer des voix neuronales. Si la valeur est inférieure, elle est automatiquement augmentée à 24 KHz. |
| Volume | Volume global trop faible | Le volume ne doit pas être inférieur à -18 dB (10 % du volume maximal). Vérifiez que le niveau moyen du volume se situe dans la plage appropriée pendant l’enregistrement de l’exemple ou la préparation des données. |
| Volume | Dépassement du volume | Un dépassement du volume est détecté à {} s. Réglez le matériel d’enregistrement pour éviter tout dépassement du volume au-delà de la valeur maximale. |
| Volume | Problème de silence de début | Le silence des 100 premières ms n’est pas propre. Réduisez le niveau de bruit d’enregistrement et laissez un silence de début pour les 100 premières ms. |
| Volume | Problème de silence de fin | Le silence des 100 dernières ms n’est pas propre. Réduisez le niveau de bruit d’enregistrement et laissez un silence de fin pour les 100 dernières ms. |
| Incompatibilité | Mots à score faible | Examinez le script et le contenu audio pour vérifier qu’ils correspondent, et contrôlez le niveau de bruit de fond. Réduisez la durée du silence long ou fractionnez l’audio en plusieurs énoncés s’il est trop long. |
| Incompatibilité | Problème de silence de début | Un audio supplémentaire est entendu avant le premier mot. Examinez le script et le contenu audio pour vérifier qu’ils correspondent, contrôlez le niveau du bruit de fond et laissez un silence pour les 100 premières ms. |
| Incompatibilité | Problème de silence de fin | Un audio supplémentaire est entendu après le dernier mot. Examinez le script et le contenu audio pour vérifier qu’ils correspondent, contrôlez le niveau du bruit de fond et laissez un silence pour les 100 derniers ms. |
| Incompatibilité | Ratio signal-bruit faible | Le niveau du ratio signal-bruit de l’audio est inférieur à 20 dB. Un niveau de 35 dB minimum est recommandé. |
| Incompatibilité | Aucun score disponible | Échec de la reconnaissance du contenu vocal dans cet audio. Vérifiez l’audio et le contenu du script pour vous assurer que l’audio est valide et qu’il correspond au script. |
Étapes suivantes
Vous avez besoin d’un jeu de données d’apprentissage pour créer une voix professionnelle. Un jeu de données d’apprentissage inclut des fichiers audio et de script. Les fichiers audio sont des enregistrements du talent vocal lisant les fichiers de script. Les fichiers de script sont le texte des fichiers audio.
Dans cet article, vous allez créer un jeu d’apprentissage et obtenir son ID de ressource. Ensuite, à l’aide de l’ID de ressource, vous pouvez charger un ensemble de fichiers audio et de script.
Créer un script d’apprentissage
Pour créer un jeu d’apprentissage, utilisez l’opération TrainingSets_Create de l’API Custom Voice. Construisez le corps de la requête conformément aux instructions suivantes :
- Définissez la propriété requise
projectId. Consultez Créer un projet. - Définissez la propriété requise
voiceKindsurMaleouFemale. Vous ne pourrez plus changer ce type. - Définissez la propriété requise
locale. Il doit s’agir des paramètres régionaux des données du jeu d’apprentissage. Les paramètres régionaux du jeu d’apprentissage doivent être identiques aux paramètres régionaux de l’instruction de consentement. Vous ne pourrez plus changer de paramètres régionaux. Vous trouverez la liste des paramètres régionaux de synthèse vocale ici. - Si vous le souhaitez, définissez la propriété
descriptionpour la description du jeu d’apprentissage. La description du jeu d’apprentissage peut être modifiée ultérieurement.
Effectuez une requête HTTP PUT à l’aide de l’URI, comme illustré dans l’exemple TrainingSets_Create suivant.
- Remplacez
YourResourceKeypar votre clé de ressource Speech. - Remplacez
YourResourceRegionpar votre région de ressource Speech. - Remplacez
JessicaTrainingSetIdpar un ID de jeu d’apprentissage de votre choix. L’ID sensible à la casse est utilisé dans l’URI du jeu d’apprentissage et ne peut pas être modifié plus tard.
curl -v -X PUT -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"description": "300 sentences Jessica data in general style.",
"projectId": "ProjectId",
"locale": "en-US",
"voiceKind": "Female"
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/trainingsets/JessicaTrainingSetId?api-version=2023-12-01-preview"
Vous devriez recevoir un corps de réponse au format suivant :
{
"id": "JessicaTrainingSetId",
"description": "300 sentences Jessica data in general style.",
"projectId": "ProjectId",
"locale": "en-US",
"voiceKind": "Female",
"status": "Succeeded",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
Charger les données du jeu d’apprentissage
Pour charger un jeu d’apprentissage constitué de fichiers audio et de scripts, utilisez l’opération TrainingSets_UploadData de l’API Custom Voice.
Avant d’appeler cette API, stockez les fichiers d’enregistrement et de script dans Azure Blob. Dans l’exemple ci-dessous, les fichiers d’enregistrement sont https://contoso.blob.core.windows.net/voicecontainer/jessica300/*.wav et les fichiers de script sont https://contoso.blob.core.windows.net/voicecontainer/jessica300/*.txt.
Construisez le corps de la requête conformément aux instructions suivantes :
- Définissez la propriété requise
kindsurAudioAndScript. Le type détermine le type de jeu d’apprentissage. - Définissez la propriété requise
audios. Dans la propriétéaudios, définissez les propriétés suivantes :- Définissez la propriété requise
containerUrlsur l’URL du conteneur Stockage Blob Azure qui contient les fichiers audio. Utilisez des signatures d’accès partagé (SAP) pour un conteneur avec des autorisations de lecture et de liste. - Définissez la propriété requise
extensionssur les extensions des fichiers audio. - Si vous le souhaitez, définissez la propriété
prefixpour définir un préfixe pour le nom de l’objet blob.
- Définissez la propriété requise
- Définissez la propriété requise
scripts. Dans la propriétéscripts, définissez les propriétés suivantes :- Définissez la propriété requise
containerUrlsur l’URL du conteneur Stockage Blob Azure qui contient les fichiers de script. Utilisez des signatures d’accès partagé (SAP) pour un conteneur avec des autorisations de lecture et de liste. - Définissez la propriété requise
extensionssur les extensions des fichiers de script. - Si vous le souhaitez, définissez la propriété
prefixpour définir un préfixe pour le nom de l’objet blob.
- Définissez la propriété requise
Effectuez une requête HTTP POST à l’aide de l’URI, comme illustré dans l’exemple TrainingSets_UploadData suivant.
- Remplacez
YourResourceKeypar votre clé de ressource Speech. - Remplacez
YourResourceRegionpar votre région de ressource Speech. - Remplacez
JessicaTrainingSetIdsi vous avez spécifié un ID de jeu d’apprentissage différent à l’étape précédente.
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"kind": "AudioAndScript",
"audios": {
"containerUrl": "https://contoso.blob.core.windows.net/voicecontainer?mySasToken",
"prefix": "jessica300/",
"extensions": [
".wav"
]
},
"scripts": {
"containerUrl": "https://contoso.blob.core.windows.net/voicecontainer?mySasToken",
"prefix": "jessica300/",
"extensions": [
".txt"
]
}
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/trainingsets/JessicaTrainingSetId:upload?api-version=2023-12-01-preview"
L’en-tête de réponse contient la propriété Operation-Location. Utilisez cet URI pour obtenir des informations sur l’opération TrainingSets_UploadData. Voici un exemple d’en-tête de réponse :
Operation-Location: https://eastus.api.cognitive.microsoft.com/customvoice/operations/284b7e37-f42d-4054-8fa9-08523c3de345?api-version=2023-12-01-preview
Operation-Id: 284b7e37-f42d-4054-8fa9-08523c3de345