Guide pratique pour reconnaître des intentions vocales avec le SDK Speech pour C#
Le SDK Speech d’Azure AI services s’intègre au Language Understanding Intelligent Service (LUIS) pour fournir la reconnaissance des intentions. Une intention est quelque chose que l’utilisateur souhaite faire : réserver un vol, vérifier la météo ou effectuer un appel. L’utilisateur peut utiliser les termes qui lui semblent naturels. LUIS mappe les requêtes des utilisateurs aux intentions que vous avez définies.
Remarque
Une application LUIS définit les intentions et entités à reconnaître. Elle est distincte de l’application C# qui utilise le service Speech. Dans cet article, « appli » fait référence à l’application LUIS tandis que « application » renvoie au code C#.
Dans ce guide, vous utilisez le SDK Speech pour développer une application console C# qui dégage des intentions à partir des énoncés utilisateur obtenus par le microphone de votre appareil. Vous allez apprendre à effectuer les actions suivantes :
- Créer un projet Visual Studio faisant référence au package NuGet du kit SDK Speech
- Créer une configuration de reconnaissance vocale et obtenir un module de reconnaissance de l’intention
- Obtenir le modèle pour votre appli LUIS et ajouter les intentions dont vous avez besoin
- Spécifier la langue pour la reconnaissance vocale
- Utiliser la reconnaissance vocale à partir d’un fichier
- Utiliser la reconnaissance continue pilotée par événements, asynchrone
Prérequis
Veillez à disposer des éléments suivants avant de commencer à suivre ce guide :
- Un compte LUIS. Vous pouvez en obtenir un gratuitement via le portail LUIS.
- Visual Studio 2019 (toute édition).
LUIS et Speech
LUIS s’intègre au service Speech pour reconnaître les intentions à partir de la reconnaissance vocale. Vous n’avez besoin que de LUIS, aucun abonnement au service Speech n’est nécessaire.
LUIS utilise deux types de clés :
| Type de clé | Objectif |
|---|---|
| Création | Permet de créer et de modifier des applications LUIS programmatiquement |
| Prédiction | Utilisé pour accéder à l’application LUIS dans le runtime |
Pour ce guide, vous avez besoin du type de clé de prédiction. Ce guide utilise l’exemple d’application domotique LUIS Home Automation, que vous pouvez créer en suivant le guide de démarrage rapide Utiliser une application domotique prédéfinie. Si vous avez créé votre propre application LUIS, vous pouvez aussi l’utiliser.
Lors de la création d’une application LUIS, une clé de création est générée automatiquement par LUIS pour que vous puissiez tester l’application à l’aide de requêtes de texte. Cette clé n’active pas l’intégration du service Speech et ne fonctionne pas avec ce guide. Créez une ressource LUIS dans le tableau de bord Azure et affectez-la à l’application LUIS. Vous pouvez utiliser le niveau d’abonnement gratuit pour suivre ce guide.
Après avoir créé la ressource LUIS dans le tableau de bord Azure, connectez-vous au portail LUIS, choisissez votre application dans la page My apps (Mes applications) et basculez vers la page Manage (Gérer) de l’application. Enfin, sélectionnez Ressources Azure dans la barre latérale.

Sur la page Ressources Azure :
Sélectionnez l’icône en regard d’une clé pour la copier dans le Presse-papiers. (Vous pouvez utiliser l’une ou l’autre clé.)
Créer le projet et ajouter la charge de travail
Pour créer un projet Visual Studio pour le développement Windows, vous devez créer le projet, configurer Visual Studio pour le développement de bureau .NET, installer le SDK Speech et choisir l’architecture cible.
Pour commencer, créez le projet dans Visual Studio et assurez-vous que Visual Studio est configuré pour le développement de bureau .NET :
Ouvrez Visual Studio 2019.
Dans la fenêtre Démarrer, sélectionnez Créer un projet.
Dans la fenêtre Créer un projet, choisissez Application console (.NET Framework), puis cliquez sur Suivant.
Dans la fenêtre Configurer votre nouveau projet, entrez helloworld dans Nom du projet, choisissez ou créez le chemin du répertoire dans Emplacement, puis sélectionnez Créer.
Dans la barre de menus de Visual Studio, sélectionnez Outils>Obtenir les outils et fonctionnalités, ce qui a pour effet d’ouvrir Visual Studio Installer et d’afficher la boîte de dialogue Modification.
Vérifiez si la charge de travail Développement .NET Desktop est disponible. Si cette charge de travail n’est pas installée, cochez la case en regard de celle-ci, puis sélectionnez Modifier pour démarrer l’installation. Le téléchargement et l’installation peuvent prendre quelques minutes.
Si la case à cocher à côté de Développement .NET Desktop est déjà sélectionnée, sélectionnez Fermer pour quitter la boîte de dialogue.
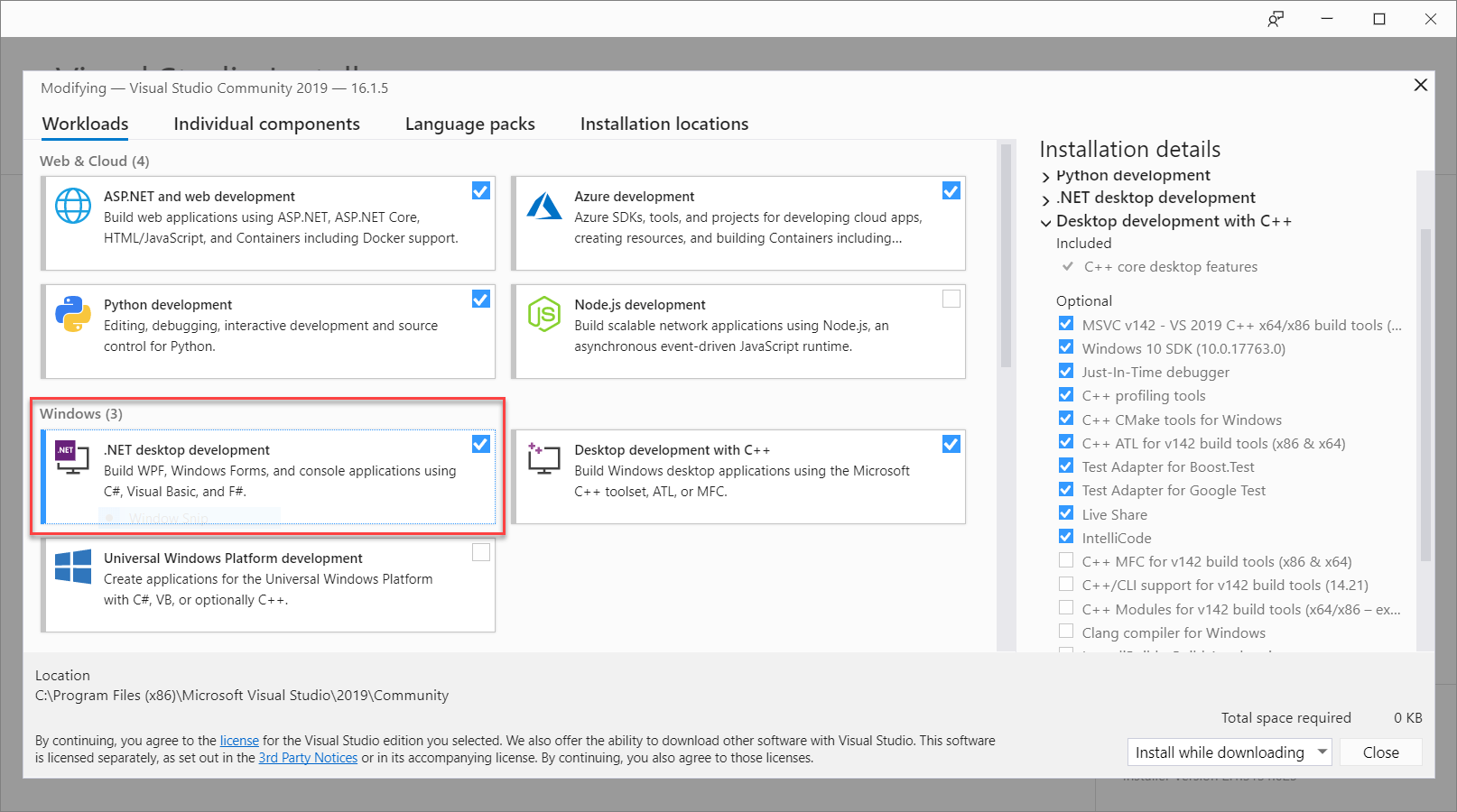
Fermez Visual Studio Installer.
Installer le Kit de développement logiciel (SDK) Speech
L’étape suivante consiste à installer le package NuGet du SDK Speech afin de pouvoir le référencer dans le code.
Dans l’Explorateur de solutions, cliquez avec le bouton droit sur le projet helloworld, puis sélectionnez Gérer les packages NuGet pour afficher le gestionnaire de package NuGet.
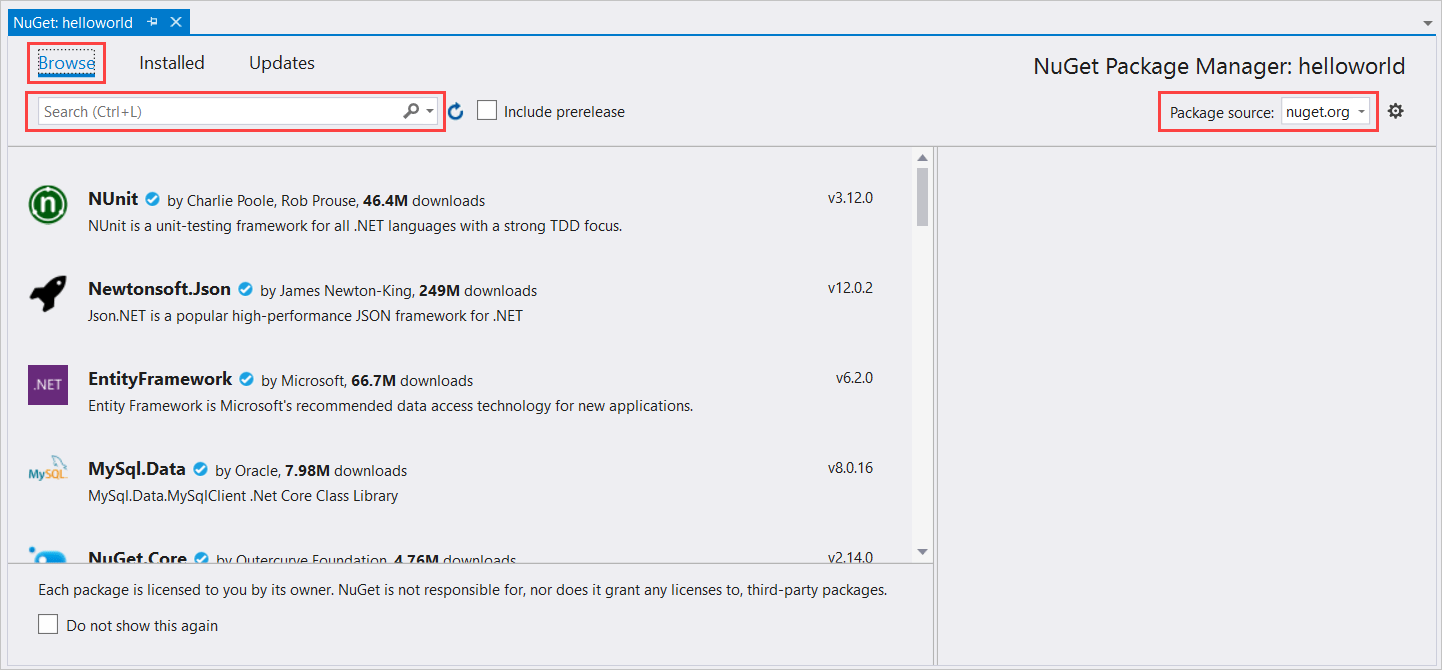
Dans l’angle supérieur droit, recherchez la zone de liste déroulante Source du package et vérifiez que nuget.org est sélectionné.
Dans l’angle supérieur gauche, sélectionnez Parcourir.
Dans la zone de recherche, tapez Microsoft.CognitiveServices.Speech et appuyez sur la touche Entrée.
Dans les résultats de la recherche, sélectionnez le package Microsoft.CognitiveServices.Speech, puis sélectionnez Installer pour installer la dernière version stable.
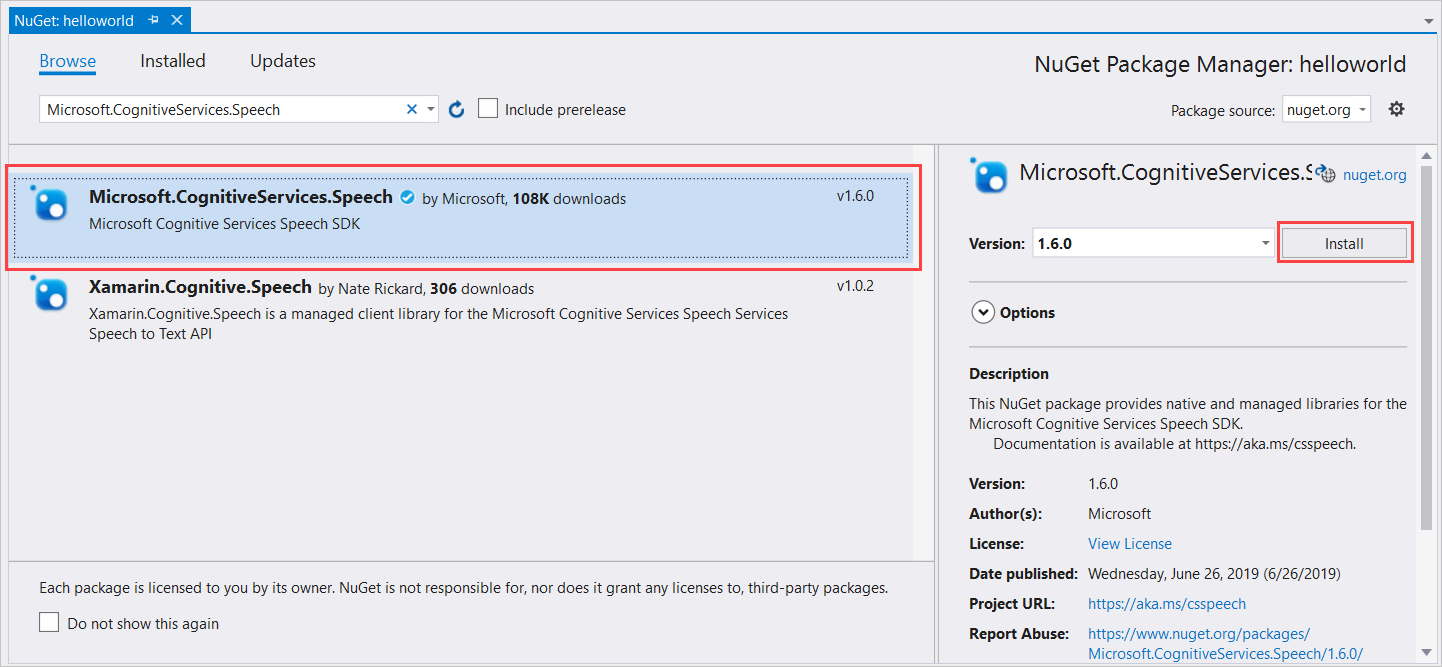
Acceptez tous les contrats et licences pour démarrer l’installation.
Une fois le package installé, un message de confirmation s’affiche dans la fenêtre Console du Gestionnaire de package.
Choisir l’architecture cible
Maintenant, pour générer et exécuter l’application console, créez une configuration de plateforme correspondant à l’architecture de votre ordinateur.
Dans la barre de menus, sélectionnez Générer>Gestionnaire de configurations. La boîte de dialogue Gestionnaire de configurations s’affiche.
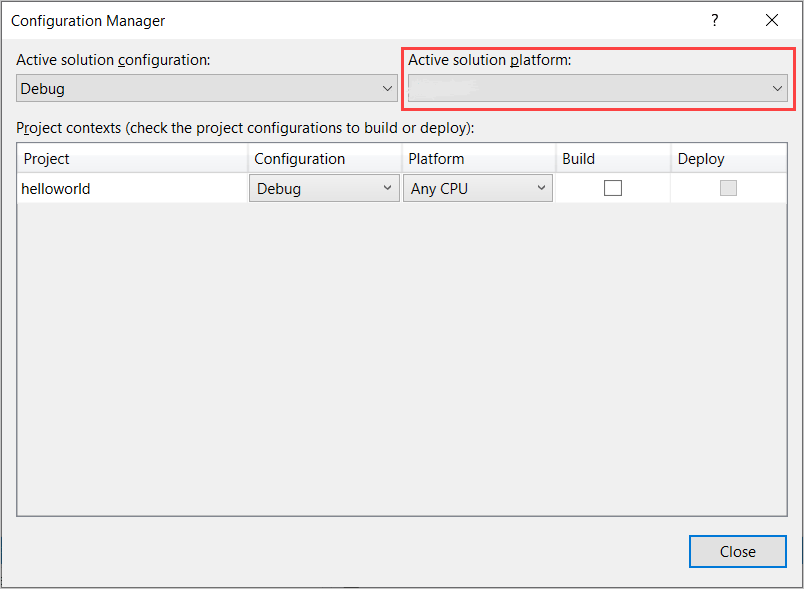
Dans la zone de liste déroulante Plateforme de la solution active, sélectionnez Nouveau. La boîte de dialogue Nouvelle plateforme de solution s’affiche.
Dans la zone de liste déroulante Tapez ou sélectionnez la nouvelle plateforme :
- Si vous exécutez Windows 64 bits, sélectionnez x64.
- Si vous exécutez Windows 32 bits, sélectionnez x86.
Sélectionnez OK, puis Fermer.
Ajouter le code
Ensuite, vous ajoutez du code au projet.
Dans l’Explorateur de solutions, ouvrez le fichier Program.cs.
Remplacez le bloc d’instructions
usingau début du fichier par les déclarations suivantes :using System; using System.Threading.Tasks; using Microsoft.CognitiveServices.Speech; using Microsoft.CognitiveServices.Speech.Audio; using Microsoft.CognitiveServices.Speech.Intent;Remplacez la méthode
Main()fournie par l’équivalent asynchrone suivant :public static async Task Main() { await RecognizeIntentAsync(); Console.WriteLine("Please press Enter to continue."); Console.ReadLine(); }Créez une méthode asynchrone vide
RecognizeIntentAsync(), comme indiqué ici :static async Task RecognizeIntentAsync() { }Dans le corps de cette nouvelle méthode, ajoutez ce code :
// Creates an instance of a speech config with specified subscription key // and service region. Note that in contrast to other services supported by // the Cognitive Services Speech SDK, the Language Understanding service // requires a specific subscription key from https://www.luis.ai/. // The Language Understanding service calls the required key 'endpoint key'. // Once you've obtained it, replace with below with your own Language Understanding subscription key // and service region (e.g., "westus"). // The default language is "en-us". var config = SpeechConfig.FromSubscription("YourLanguageUnderstandingSubscriptionKey", "YourLanguageUnderstandingServiceRegion"); // Creates an intent recognizer using microphone as audio input. using (var recognizer = new IntentRecognizer(config)) { // Creates a Language Understanding model using the app id, and adds specific intents from your model var model = LanguageUnderstandingModel.FromAppId("YourLanguageUnderstandingAppId"); recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName1", "id1"); recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName2", "id2"); recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName3", "any-IntentId-here"); // Starts recognizing. Console.WriteLine("Say something..."); // Starts intent recognition, and returns after a single utterance is recognized. The end of a // single utterance is determined by listening for silence at the end or until a maximum of 15 // seconds of audio is processed. The task returns the recognition text as result. // Note: Since RecognizeOnceAsync() returns only a single utterance, it is suitable only for single // shot recognition like command or query. // For long-running multi-utterance recognition, use StartContinuousRecognitionAsync() instead. var result = await recognizer.RecognizeOnceAsync().ConfigureAwait(false); // Checks result. if (result.Reason == ResultReason.RecognizedIntent) { Console.WriteLine($"RECOGNIZED: Text={result.Text}"); Console.WriteLine($" Intent Id: {result.IntentId}."); Console.WriteLine($" Language Understanding JSON: {result.Properties.GetProperty(PropertyId.LanguageUnderstandingServiceResponse_JsonResult)}."); } else if (result.Reason == ResultReason.RecognizedSpeech) { Console.WriteLine($"RECOGNIZED: Text={result.Text}"); Console.WriteLine($" Intent not recognized."); } else if (result.Reason == ResultReason.NoMatch) { Console.WriteLine($"NOMATCH: Speech could not be recognized."); } else if (result.Reason == ResultReason.Canceled) { var cancellation = CancellationDetails.FromResult(result); Console.WriteLine($"CANCELED: Reason={cancellation.Reason}"); if (cancellation.Reason == CancellationReason.Error) { Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}"); Console.WriteLine($"CANCELED: ErrorDetails={cancellation.ErrorDetails}"); Console.WriteLine($"CANCELED: Did you update the subscription info?"); } } }Remplacez les espaces réservés de cette méthode par votre clé de ressource LUIS, votre région et votre ID d’appli, comme suit.
Espace réservé Remplacer par YourLanguageUnderstandingSubscriptionKeyVotre clé de ressource LUIS. Là encore, vous devez obtenir cet élément à partir de votre tableau de bord Azure. Vous pouvez la trouver dans la page Ressources Azure de votre application, sous Gérer dans le portail LUIS. YourLanguageUnderstandingServiceRegionL’identificateur court pour la région de votre ressource LUIS est, par exemple, westuspour la région USA Ouest. Voir Régions.YourLanguageUnderstandingAppIdL’ID d’application LUIS. Vous pouvez le trouver dans la page Settings (Paramètres) de votre application dans le portail LUIS.
Ces modifications étant apportées, vous pouvez générer (Ctrl+Maj+B) et exécuter (F5) l’application. Lorsque vous y êtes invité, essayez de dire « Éteins les lumières » dans le micro de votre PC. L’application affiche le résultat dans la fenêtre de console.
Les sections suivantes comportent un développement du code.
Créer un module de reconnaissance de l’intention
Tout d’abord, vous devez créer une configuration de reconnaissance vocale à partir de la clé et de la région de votre prédiction LUIS. Vous pouvez utiliser les configurations de reconnaissance vocale pour créer des modules de reconnaissance pour les différentes fonctionnalités du SDK Speech. La configuration de reconnaissance vocale offre plusieurs moyens pour spécifier la ressource à utiliser. Ici, nous utilisons FromSubscription, qui accepte la région et la clé de ressource.
Notes
Utilisez la clé et la région de votre ressource LUIS et non une ressource Speech.
Ensuite, créez un module de reconnaissance de l’intention à l’aide de new IntentRecognizer(config). La configuration sachant déjà quel ressource utiliser, vous n’avez pas besoin de spécifier à nouveau la clé de ressource lors de la création du module de reconnaissance.
Importer un modèle LUIS et ajouter des intentions
À présent, importez le modèle à partir de l’appli LUIS avec LanguageUnderstandingModel.FromAppId(), et ajoutez les intentions LUIS à reconnaître par le biais de la méthode AddIntent() du module de reconnaissance. Ces deux étapes améliorent la précision de la reconnaissance vocale en indiquant les mots que l’utilisateur est susceptible d’utiliser dans ses requêtes. Il n’est pas nécessaire d’ajouter toutes les intentions de l’application si vous n’avez pas besoin de toutes les identifier dans votre application.
Pour ajouter des intentions, vous devez fournir trois arguments : le modèle LUIS (nommé model), le nom de l’intention et un ID d’intention. La différence entre l’ID et le nom s’établit comme suit.
Argument AddIntent() |
Objectif |
|---|---|
intentName |
Nom de l’intention, tel que défini dans l’appli LUIS. Cette valeur doit correspondre exactement au nom d’intention LUIS. |
intentID |
ID assigné à une intention reconnue par le kit SDK Speech. Cette valeur peut être ce que vous voulez ; il n’est pas nécessaire qu’elle corresponde au nom de l’intention, tel que défini dans l’application LUIS. Par exemple, si plusieurs intentions sont gérées par le même code, vous pouvez utiliser le même ID pour celles-ci. |
L’application LUIS Home Automation a deux intentions : une pour mettre un appareil sous tension, l’autre pour le mettre hors tension. Les lignes ci-dessous ajoutent ces intentions au module de reconnaissance de l’intention ; remplacez les trois lignes AddIntent dans la méthode RecognizeIntentAsync() par ce code.
recognizer.AddIntent(model, "HomeAutomation.TurnOff", "off");
recognizer.AddIntent(model, "HomeAutomation.TurnOn", "on");
Au lieu d’ajouter des intentions individuelles, vous pouvez aussi utiliser la méthode AddAllIntents pour ajouter toutes les intentions d’un modèle au module de reconnaissance.
Démarrer la reconnaissance
Le module de reconnaissance étant créé, et les intentions ajoutées, la reconnaissance peut commencer. Le kit SDK Speech prend en charge la reconnaissance ponctuelle et continue.
| Mode de reconnaissance | Méthodes à appeler | Résultats |
|---|---|---|
| Ponctuel | RecognizeOnceAsync() |
Retourne l’intention reconnue, si elle existe, après un énoncé. |
| Continue | StartContinuousRecognitionAsync()StopContinuousRecognitionAsync() |
Reconnaît plusieurs énoncés ; émet des événements (par exemple, IntermediateResultReceived) lorsque des résultats sont disponibles. |
L’application utilise le mode ponctuel et appelle donc RecognizeOnceAsync() pour débuter la reconnaissance. Le résultat est un objet IntentRecognitionResult contenant des informations sur l’intention reconnue. Vous extrayez la réponse JSON LUIS à l’aide de l’expression suivante :
result.Properties.GetProperty(PropertyId.LanguageUnderstandingServiceResponse_JsonResult)
L’application n’analyse pas le résultat JSON. Elle affiche uniquement le texte JSON dans la fenêtre de console.

Préciser une langue de reconnaissance
Par défaut, LUIS reconnaît les intentions en anglais (États-Unis) (en-us). En attribuant un code de paramètres régionaux à la propriété SpeechRecognitionLanguage de la configuration de reconnaissance vocale, vous pouvez reconnaître des intentions dans d’autres langues. Par exemple, ajoutez config.SpeechRecognitionLanguage = "de-de"; dans notre application avant de créer le module de reconnaissance pour reconnaître les intentions en allemand. Pour plus d’informations, consultez les langues prises en charge par LUIS.
Reconnaissance continue depuis un fichier
Le code suivant illustre deux caractéristiques supplémentaires de la reconnaissance de l’intention avec le kit SDK Speech. La première, mentionnée précédemment, est la reconnaissance continue, par laquelle le module de reconnaissance émet des événements lorsque des résultats sont disponibles. Ces événements sont traités par les gestionnaires d’événements que vous fournissez. Avec la reconnaissance continue, vous appelez la méthode StartContinuousRecognitionAsync() du module de reconnaissance pour lancer la reconnaissance à la place de RecognizeOnceAsync().
L’autre caractéristique lit l’audio contenant la reconnaissance vocale à traiter à partir d’un fichier WAV. L’implémentation implique la création d’une configuration audio utilisable lors de la création du module de reconnaissance de l’intention. Le fichier doit être de canal unique (mono) avec un taux d’échantillonnage de 16 kHz.
Pour tester ces fonctionnalités, supprimez ou mettez en commentaires le corps de la méthode RecognizeIntentAsync(), puis ajoutez le code suivant à la place.
// Creates an instance of a speech config with specified subscription key
// and service region. Note that in contrast to other services supported by
// the Cognitive Services Speech SDK, the Language Understanding service
// requires a specific subscription key from https://www.luis.ai/.
// The Language Understanding service calls the required key 'endpoint key'.
// Once you've obtained it, replace with below with your own Language Understanding subscription key
// and service region (e.g., "westus").
var config = SpeechConfig.FromSubscription("YourLanguageUnderstandingSubscriptionKey", "YourLanguageUnderstandingServiceRegion");
// Creates an intent recognizer using file as audio input.
// Replace with your own audio file name.
using (var audioInput = AudioConfig.FromWavFileInput("YourAudioFile.wav"))
{
using (var recognizer = new IntentRecognizer(config, audioInput))
{
// The TaskCompletionSource to stop recognition.
var stopRecognition = new TaskCompletionSource<int>(TaskCreationOptions.RunContinuationsAsynchronously);
// Creates a Language Understanding model using the app id, and adds specific intents from your model
var model = LanguageUnderstandingModel.FromAppId("YourLanguageUnderstandingAppId");
recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName1", "id1");
recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName2", "id2");
recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName3", "any-IntentId-here");
// Subscribes to events.
recognizer.Recognizing += (s, e) =>
{
Console.WriteLine($"RECOGNIZING: Text={e.Result.Text}");
};
recognizer.Recognized += (s, e) =>
{
if (e.Result.Reason == ResultReason.RecognizedIntent)
{
Console.WriteLine($"RECOGNIZED: Text={e.Result.Text}");
Console.WriteLine($" Intent Id: {e.Result.IntentId}.");
Console.WriteLine($" Language Understanding JSON: {e.Result.Properties.GetProperty(PropertyId.LanguageUnderstandingServiceResponse_JsonResult)}.");
}
else if (e.Result.Reason == ResultReason.RecognizedSpeech)
{
Console.WriteLine($"RECOGNIZED: Text={e.Result.Text}");
Console.WriteLine($" Intent not recognized.");
}
else if (e.Result.Reason == ResultReason.NoMatch)
{
Console.WriteLine($"NOMATCH: Speech could not be recognized.");
}
};
recognizer.Canceled += (s, e) =>
{
Console.WriteLine($"CANCELED: Reason={e.Reason}");
if (e.Reason == CancellationReason.Error)
{
Console.WriteLine($"CANCELED: ErrorCode={e.ErrorCode}");
Console.WriteLine($"CANCELED: ErrorDetails={e.ErrorDetails}");
Console.WriteLine($"CANCELED: Did you update the subscription info?");
}
stopRecognition.TrySetResult(0);
};
recognizer.SessionStarted += (s, e) =>
{
Console.WriteLine("\n Session started event.");
};
recognizer.SessionStopped += (s, e) =>
{
Console.WriteLine("\n Session stopped event.");
Console.WriteLine("\nStop recognition.");
stopRecognition.TrySetResult(0);
};
// Starts continuous recognition. Uses StopContinuousRecognitionAsync() to stop recognition.
await recognizer.StartContinuousRecognitionAsync().ConfigureAwait(false);
// Waits for completion.
// Use Task.WaitAny to keep the task rooted.
Task.WaitAny(new[] { stopRecognition.Task });
// Stops recognition.
await recognizer.StopContinuousRecognitionAsync().ConfigureAwait(false);
}
}
Révisez le code pour inclure votre clé de prédiction, votre région et votre ID d’appli LUIS, et ajouter des intentions domotiques, comme effectué précédemment. Remplacez whatstheweatherlike.wav par le nom de votre fichier audio enregistré. Ensuite, générez, copiez le fichier audio dans le répertoire de build, puis exécutez l’application.
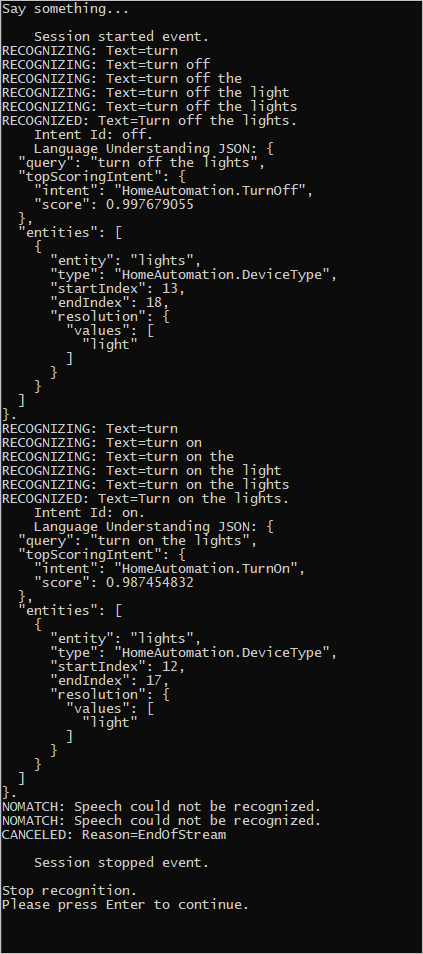
Par exemple, si vous dites « Éteins les lumières », faites une pause, puis dites « Allume les lumières » dans votre fichier audio enregistré, une sortie de console similaire à la suivante peut s’afficher :
L’équipe du kit de développement logiciel (SDK) Speech gère activement un grand nombre d’exemples dans un référentiel open source. Pour obtenir un exemple de référentiel de code source, consultez le Kit de développement logiciel (SDK) Azure AI Speech sur GitHub. Des exemples sont disponibles pour C#, C++, Java, Python, Objective-C, Swift, JavaScript, UWP, Unity et Xamarin. Retrouvez le code de cet article dans le dossier samples/csharp/sharedcontent/console.
Étapes suivantes
Démarrage rapide : Reconnaître la voix à partir d’un microphone