Gérer le cycle de vie du modèle au moyen du Registre des modèles d’espace de travail
Important
Cette documentation concerne le Registre des modèles d’espaces de travail. Si votre espace de travail est activé pour Unity Catalog, n’utilisez pas les procédures présentées sur cette page. En lieu et place, consultez l’article Modèles dans Unity Catalog.
Le Registre des modèles d’espace de travail sera déconseillé à l’avenir. Pour obtenir des conseils sur la mise à niveau du Registre de modèles d’espaces de travail vers Unity Catalog, consultez Migrer les flux de travail et les modèles vers Unity Catalog.
Si le catalogue par défaut de votre espace de travail est dans Unity Catalog (au lieu de hive_metastore) et que vous exécutez un cluster en utilisant Databricks Runtime 13.3 LTS ou ultérieur, les modèles sont automatiquement créés et chargés depuis le catalogue par défaut de l’espace de travail, sans qu’une configuration soit nécessaire. Pour utiliser le Registre de modèles d’espace de travail dans ce contexte, vous devez le cibler explicitement en exécutant import mlflow; mlflow.set_registry_uri("databricks") au début de votre charge de travail. Un petit nombre d’espaces de travail où le catalogue par défaut a été configuré sur un catalogue dans Unity Catalog avant janvier 2024 et pour lesquels le registre de modèles d’espace de travail a été utilisé avant janvier 2024 n’ont pas ce comportement et continuent à utiliser par défaut le registre de modèles d’espace de travail.
Cet article décrit comment utiliser Espace de travail Model Registry dans le cadre de votre flux de travail d'apprentissage automatique pour gérer le cycle de vie complet des modèles ML. Le registre de modèles d’espace de travail est une version hébergée fournie par Databricks du registre de modèles MLflow.
Le registre des modèles d'espace de travail fournit :
- Traçabilité chronologique du modèle (que le MLflow a essayé et que l’exécution a produit à un moment donné).
- Service de modèle.
- Contrôle de version de modèle.
- Transitions d’étape (par exemple, de la préproduction à la production ou à l’archivage).
- Webhooks afin que vous puissiez déclencher automatiquement des actions en fonction des événements de Registre.
- Notifications par e-mail des événements de modèle.
Vous pouvez également créer et afficher des descriptions de modèle et laisser des commentaires.
Cet article comprend des instructions pour l’interface utilisateur de Workspace Model Registry et l’API Espace de travail Model Registry.
Pour obtenir une vue d’ensemble des concepts du Registre des modèles d’espace de travail, consultez l’article Gestion de cycle de vie ML en utilisant MLflow.
Créer ou inscrire un modèle
Vous pouvez créer ou inscrire un modèle à l’aide de l’IU, ou inscrire un modèle à l’aide de l’API.
Créer ou inscrire un modèle à l’aide de l’interface utilisateur
Il existe deux manières d'enregistrer un modèle dans le registre des modèles d'espace de travail. Vous pouvez inscrire un modèle existant qui a été journalisé dans MLflow, ou vous pouvez créer et inscrire un nouveau modèle vide et lui assigner un modèle précédemment journalisé.
Inscrire un modèle journalisé existant à partir d’un notebook
Dans l’espace de travail, identifiez l’exécution MLflow contenant le modèle que vous souhaitez inscrire.
Cliquez sur l’icône Essai
 dans la barre latérale droite du notebook.
dans la barre latérale droite du notebook.
Dans la barre latérale des exécutions d’expérience, cliquez sur l'icône
 à côté de la date de l’exécution. La page Exécution de MLflow s’affiche. Cette page affiche les détails de l’exécution, notamment les paramètres, les métriques, les étiquettes et la liste d’artefacts.
à côté de la date de l’exécution. La page Exécution de MLflow s’affiche. Cette page affiche les détails de l’exécution, notamment les paramètres, les métriques, les étiquettes et la liste d’artefacts.
Dans la section Artifacts (Artefacts), cliquez sur le répertoire nommé xxx-model.
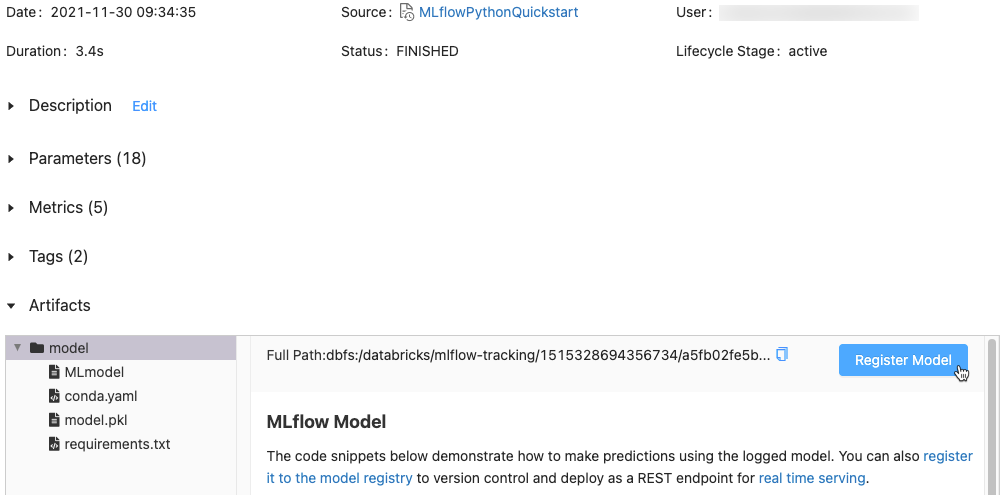
Cliquez sur le bouton Register Model (Inscrire le modèle) à l’extrême droite.
Dans la boîte de dialogue, cliquez dans la zone Modèle et effectuez l'une des opérations suivantes :
- Sélectionnez Créer un nouveau modèle dans le menu déroulant. Le champ Nom du modèle apparaît. Entrez un nom de modèle, par exemple
scikit-learn-power-forecasting. - Sélectionnez un modèle existant dans le menu déroulant.
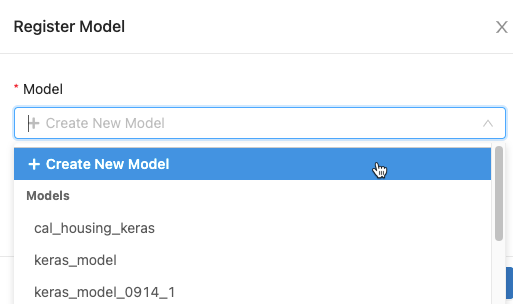
- Sélectionnez Créer un nouveau modèle dans le menu déroulant. Le champ Nom du modèle apparaît. Entrez un nom de modèle, par exemple
Cliquez sur S'inscrire.
- Si vous avez sélectionné Créer un nouveau modèle, cela enregistre un modèle nommé
scikit-learn-power-forecasting, copie le modèle dans un emplacement sécurisé géré par Espace de travail Model Registry et crée une nouvelle version du modèle. - Si vous avez sélectionné un modèle existant, cette option enregistre une nouvelle version du modèle sélectionné.
Après quelques instants, le bouton Inscrire un modèle se transforme en un lien vers la nouvelle version du modèle enregistré.
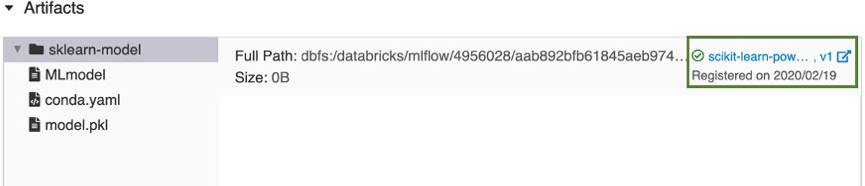
- Si vous avez sélectionné Créer un nouveau modèle, cela enregistre un modèle nommé
Cliquez sur le lien pour ouvrir la nouvelle version du modèle dans l'interface utilisateur du registre des modèles d'espace de travail. Vous pouvez également trouver le modèle dans le registre des modèles de l'espace de travail en cliquant sur l'
 Modèles dans la barre latérale.
Modèles dans la barre latérale.
Créer un modèle inscrit et lui assigner un modèle journalisé
Vous pouvez utiliser le bouton Create Model (Créer un modèle) dans la page des modèles inscrits pour créer un modèle vide et lui assigner un modèle journalisé. Suivez ces étapes :
Dans la page des modèles inscrits, cliquez sur Create Model (Créer un modèle). Attribuez un nom au modèle, puis cliquez sur Create (Créer).
Suivez les étapes 1 à 3 de la section Inscrire un modèle journalisé existant à partir d’un notebook.
Dans la boîte de dialogue Register Model (Inscrire le modèle), sélectionnez le nom du modèle que vous avez créé à l’étape 1, puis cliquez sur Register (Inscrire). Cela enregistre un modèle sous le nom que vous avez créé, copie le modèle dans un emplacement sécurisé géré par Espace de travail Model Registry et crée une version du modèle :
Version 1.Après quelques instants, le bouton Register Model (Inscrire le modèle) de l’interface utilisateur d’exécution MLflow est remplacé par un lien qui mène à la nouvelle version du modèle inscrit. Vous pouvez maintenant sélectionner le modèle dans la liste déroulante Model (Modèle) de la boîte de dialogue Register Model (Inscrire le modèle) de la page Experiment Runs (Exécutions d’expériences). Vous pouvez aussi inscrire de nouvelles versions du modèle en spécifiant son nom dans les commandes d’API comme Create ModelVersion.
Inscrire un modèle à l’aide de l’API
Il existe trois méthodes programmatiques pour enregistrer un modèle dans le registre des modèles d'espace de travail. Toutes les méthodes copient le modèle dans un emplacement sécurisé géré par Espace de travail Model Registry.
Pour journaliser un modèle et l’inscrire sous le nom spécifié au cours d’une expérience MLflow, utilisez la méthode
mlflow.<model-flavor>.log_model(...). S’il n’existe pas de modèle inscrit sous ce nom, la méthode en inscrit un nouveau, crée Version 1, puis retourne un objet MLflowModelVersion. S’il existe déjà un modèle inscrit sous ce nom, la méthode crée une nouvelle version du modèle et retourne l’objet version.with mlflow.start_run(run_name=<run-name>) as run: ... mlflow.<model-flavor>.log_model(<model-flavor>=<model>, artifact_path="<model-path>", registered_model_name="<model-name>" )Pour inscrire un modèle sous le nom spécifié après que vous avez terminé toutes vos exécutions d’expériences et décidé quel modèle vous souhaitez ajouter au registre, utilisez la méthode
mlflow.register_model(). Pour cette méthode, vous avez besoin de l’ID d’exécution pour l’argumentmlruns:URI. S’il n’existe pas de modèle inscrit sous ce nom, la méthode en inscrit un nouveau, crée Version 1, puis retourne un objet MLflowModelVersion. S’il existe déjà un modèle inscrit sous ce nom, la méthode crée une nouvelle version du modèle et retourne l’objet version.result=mlflow.register_model("runs:<model-path>", "<model-name>")Pour créer un nouveau modèle inscrit avec le nom spécifié, utilisez la méthode
create_registered_model()de l’API cliente MLflow. Si le nom du modèle existe, cette méthode lève une exceptionMLflowException.client = MlflowClient() result = client.create_registered_model("<model-name>")
Vous pouvez également inscrire un modèle avec le fournisseur Databricks Terraform et databricks_mlflow_model.
Afficher des modèles dans l’interface utilisateur
Page des modèles inscrits
La page des modèles inscrits s’affiche quand vous cliquez sur ![]() Modèles dans la barre latérale. Cette page affiche tous les modèles dans le registre.
Modèles dans la barre latérale. Cette page affiche tous les modèles dans le registre.
Vous pouvez créer un modèle à partir de cette page.
Également à partir de cette page, les administrateurs de l'espace de travail peuvent définir des autorisations pour tous les modèles dans le registre des modèles de l'espace de travail.

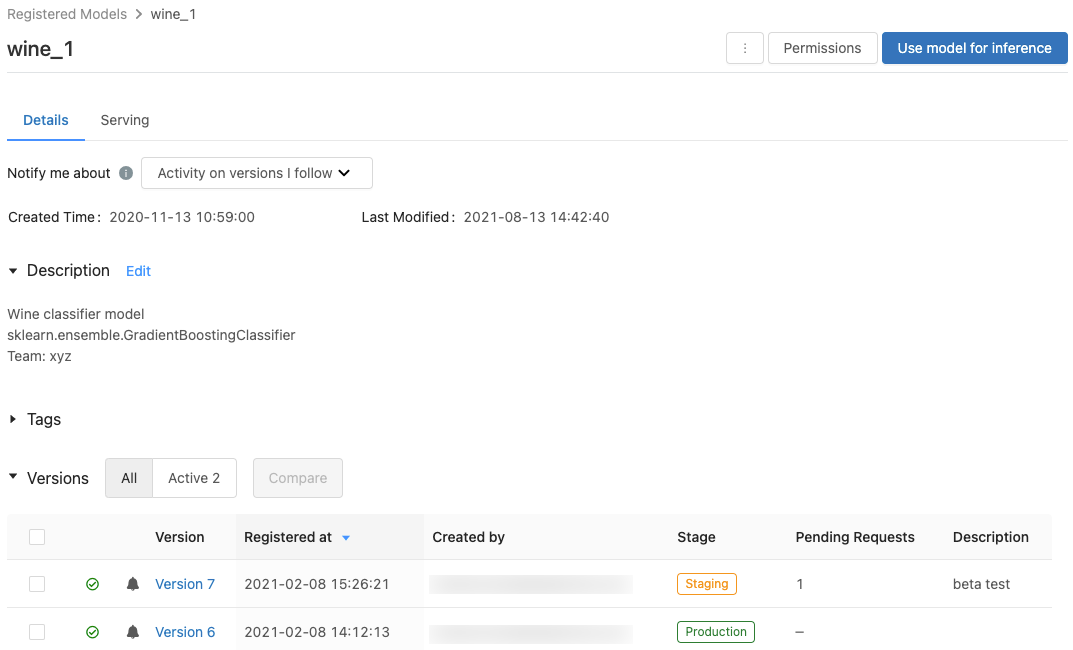
Page d’un modèle inscrit
Pour afficher la page d’un modèle inscrit, cliquez sur un nom de modèle dans la page des modèles inscrits. La page d’un modèle inscrit affiche des informations sur le modèle sélectionné et un tableau contenant des informations sur chaque version du modèle. À partir de cette page, vous pouvez également :
- Configurer le service de modèle.
- Générer automatiquement un notebook pour utiliser le modèle à des fins d’inférence.
- Configurer des notifications par e-mail.
- Comparer des versions de modèles.
- Définissez les autorisations pour le modèle.
- Supprimer un modèle.
Page de version de modèle
Pour afficher la page de version de modèle, effectuez l’une des opérations suivantes :
- Cliquez sur un nom de version dans la colonne Dernière version de la page des modèles inscrits.
- Cliquez sur un nom de version dans la colonne Version de la page d’un modèle inscrit.
Cette page affiche des informations sur une version spécifique d’un modèle inscrit et fournit également un lien vers l’exécution source (version du notebook qui a été exécuté pour créer le modèle). À partir de cette page, vous pouvez également :
- Générer automatiquement un notebook pour utiliser le modèle à des fins d’inférence.
- Supprimer un modèle.
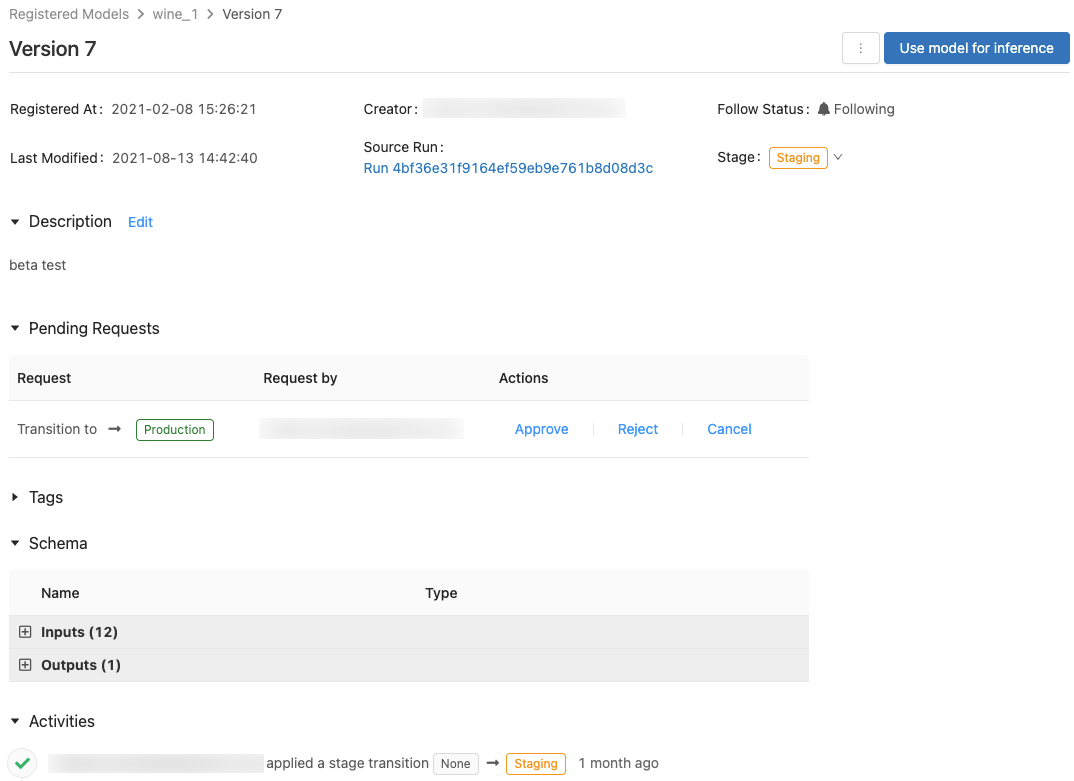
Contrôler l’accès aux modèles
Pour savoir comment contrôler l'accès aux modèles enregistrés dans le registre des modèles d'espace de travail, consultez Partager le modèle MLflow.
Effectuer la transition de la phase d’un modèle
Une version de modèle comporte l’une des étapes suivantes : Aucun, Préproduction, Production ou Archivé. La phase Staging (Préproduction) vise à tester et valider le modèle, alors que la phase Production est destinée aux versions de modèle qui ont terminé les processus de test ou de révision et qui ont été déployées dans des applications pour un scoring dynamique. Une version de modèle en phase Archived (Archivée) est considérée inactive. À ce stade, vous pouvez envisager de la supprimer. Les différentes versions d’un modèle peuvent se trouver dans des phases différentes.
Un utilisateur disposant de l’autorisation appropriée peut effectuer la transition d’une version de modèle entre les phases. Si vous avez l’autorisation de faire passer une version de modèle dans une phase déterminée, vous pouvez effectuer la transition directement. Si vous n’avez pas d’autorisation, vous pouvez formuler une demande de transition de phase. Un utilisateur autorisé à effectuer la transition des versions de modèles pourra alors approuver, rejeter ou annuler la demande.
Vous pouvez effectuer la transition d’une phase de modèle à l’aide de l’IU ou à l’aide de l’API.
Effectuer la transition d’une phase de modèle à l’aide de l’interface utilisateur
Pour effectuer la transition d’une phase de modèle, suivez ces instructions.
Pour afficher la liste des phases de modèle disponibles et les options possibles, dans la page d’une version de modèle, cliquez sur la liste déroulante en regard de Phase :, puis demandez ou sélectionnez une transition vers une autre phase.
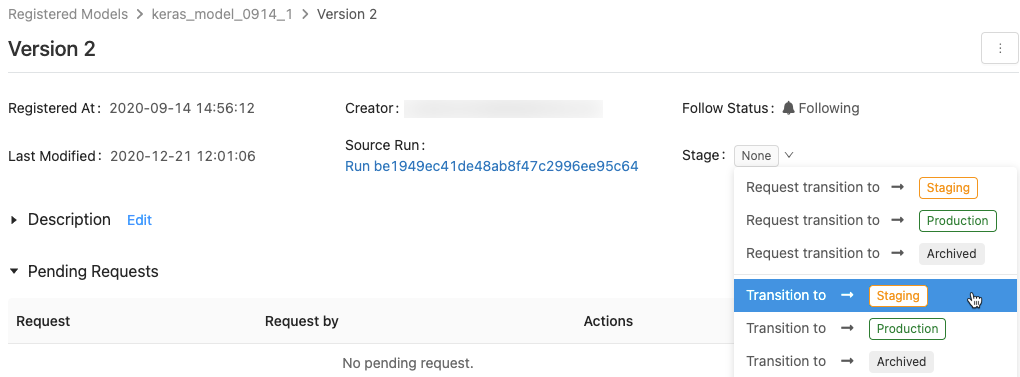
Entrez éventuellement un commentaire, puis cliquez sur OK.
Faire passer la version d’un modèle en phase Production
Après le test et la validation, vous pouvez effectuer la transition ou demander une transition vers la phase Production.
Espace de travail Model Registry autorise plusieurs versions du modèle enregistré à chaque étape. Si vous ne voulez qu’une seule version en phase Production, vous pouvez faire passer toutes les versions du modèle actuellement en phase Production vers la phase Archived (Archivage) en cochant Transition existing Production model versions to Archived (Faire passer les versions existantes d’un modèle de Production à Archivage).
Approuver, rejeter ou annuler une demande de transition de phase pour une version de modèle
Un utilisateur sans autorisation de transition de phase peut formuler une demande de transition de phase. La demande apparaît dans la section Pending Requests (Demandes en attente) dans la page d’une version de modèle :

Pour approuver, rejeter ou annuler une demande de transition de phase, cliquez sur le lien Approve (Approuver), Reject (Rejeter) ou Cancel (Annuler).
Le créateur d’une demande de transition peut aussi annuler cette demande.
Consulter les activités associées à une version de modèle
Pour afficher toutes les transitions demandées, approuvées, en attente et appliquées pour une version de modèle, accédez à la section Activities (Activités). Cet enregistrement d’activités offre une traçabilité du cycle de vie du modèle à des fins d’audit ou d’inspection.
Effectuer la transition d’une phase de modèle à l’aide de l’API
Les utilisateurs disposant des autorisations appropriées peuvent faire passer une version de modèle dans une nouvelle phase.
Pour mettre à jour la phase d’une version de modèle vers une nouvelle, utilisez la méthode transition_model_version_stage() de l’API cliente MLflow :
client = MlflowClient()
client.transition_model_version_stage(
name="<model-name>",
version=<model-version>,
stage="<stage>",
description="<description>"
)
Les valeurs acceptées pour <stage> sont : "Staging"|"staging", "Archived"|"archived", "Production"|"production" et "None"|"none".
Utiliser le modèle pour l’inférence
Important
Cette fonctionnalité est disponible en préversion publique.
Une fois qu'un modèle est enregistré dans le registre des modèles d'espace de travail, vous pouvez générer automatiquement un bloc-notes pour utiliser le modèle pour l'inférence par lots ou par flux. Vous pouvez également créer un point de terminaison pour utiliser le modèle pour le service en temps réel avec le service de modèle.
Dans le coin supérieur droit de la page du modèle inscrit ou de la page de la version du modèle, cliquez sur  . La boîte de dialogue Configurer l’inférence du modèle s’affiche, ce qui vous permet de configurer l’inférence par lots, en streaming ou en temps réel.
. La boîte de dialogue Configurer l’inférence du modèle s’affiche, ce qui vous permet de configurer l’inférence par lots, en streaming ou en temps réel.
Important
Anaconda Inc. a mis à jour ses conditions d’utilisation du service pour les canaux anaconda.org. Les nouvelles conditions d’utilisation du service peuvent vous imposer d’avoir une licence commerciale pour utiliser une distribution et des packages Anaconda. Pour plus d’informations, consultez le Forum aux questions sur l’édition commerciale d’Anaconda. Votre utilisation des canaux Anaconda est régie par leurs conditions d’utilisation du service.
Les modèles MLflow enregistrés avant la version 1.18 (Databricks Runtime 8.3 ML ou version antérieure) étaient enregistrés par défaut avec le canal conda defaults (https://repo.anaconda.com/pkgs/) en tant que dépendance. En raison de cette modification de licence, Databricks a arrêté l’utilisation du canal defaults pour les modèles enregistrés à l’aide de MLflow v1.18 et versions ultérieures. Le canal par défaut journalisé est maintenant conda-forge, qui pointe vers https://conda-forge.org/, géré par la communauté.
Si vous avez enregistré un modèle avant MLflow v1.18 sans exclure le canal defaults de l’environnement conda pour le modèle, ce modèle peut avoir une dépendance sur le canal defaults que vous n’avez peut-être pas prévue.
Pour vérifier manuellement si un modèle a cette dépendance, vous pouvez examiner la valeur channel dans le fichier conda.yaml empaqueté avec le modèle journalisé. Par exemple, les modèles conda.yaml avec une dépendance de canal defaults peuvent ressembler à ceci :
channels:
- defaults
dependencies:
- python=3.8.8
- pip
- pip:
- mlflow
- scikit-learn==0.23.2
- cloudpickle==1.6.0
name: mlflow-env
Étant donné que Databricks ne peut pas déterminer si votre utilisation du référentiel Anaconda pour interagir avec vos modèles est autorisée dans votre relation avec Anaconda, Databricks n’oblige pas ses clients à apporter des modifications. Si votre utilisation du référentiel Anaconda.com par le biais de l’utilisation de Databricks est autorisée selon les conditions d’Anaconda, vous n’avez pas besoin d’effectuer d’action.
Si vous souhaitez modifier le canal utilisé dans l'environnement d'un modèle, vous pouvez réenregistrer le modèle dans le registre des modèles Espace de travail avec un nouveau fichier conda.yaml. Pour ce faire, spécifiez le canal dans le paramètre conda_env de log_model().
Pour plus d’informations sur l’API log_model(), consultez la documentation MLflow pour la version de modèle que vous utilisez, par exemple, log_model pour scikit-learn.
Pour plus d’informations sur les fichiers conda.yaml, consultez la documentation MLflow.
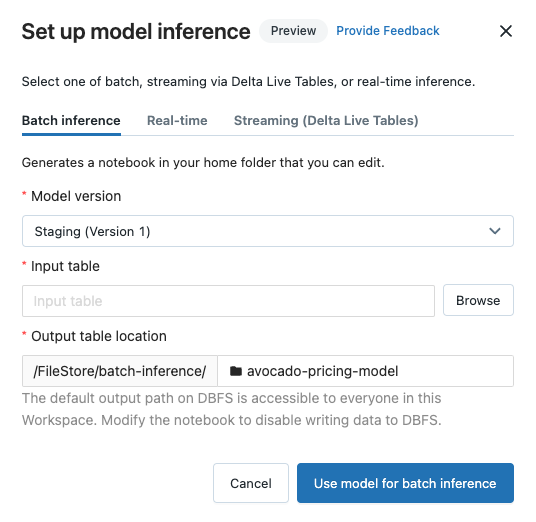
Configurer l'inférence par lots
Lorsque vous suivez ces étapes pour créer un notebook d'inférence par lots, le notebook est enregistré dans votre dossier utilisateur sous le dossier Batch-Inference, dans un dossier portant le nom du modèle. Vous pouvez modifier le notebook selon vos besoins.
Cliquez sur l'onglet Inférence par lots.
Dans le menu déroulant Version du modèle, sélectionnez la version du modèle à utiliser. Les deux premiers éléments de la liste déroulante permettent de sélectionner la version de production et la version intermédiaire du modèle (le cas échéant). Lorsque vous sélectionnez l’une de ces options, le notebook utilise automatiquement la version de production ou intermédiaire au moment de son exécution. Vous n’avez pas besoin de mettre à jour le notebook à mesure que vous continuez à développer le modèle.
Cliquez sur le bouton Parcourir en regard de Table d'entrée. La boîte de dialogue Sélectionner les données d’entrée s’affiche. Si nécessaire, vous pouvez modifier le cluster dans le menu déroulant Calcul.
Remarque
Pour les espaces de travail compatibles avec Unity Catalog, la boîte de dialogue Sélectionner les données d’entrée vous permet de sélectionner parmi trois niveaux :
<catalog-name>.<database-name>.<table-name>.Sélectionnez la base table contenant les données d'entrée du modèle, puis cliquez sur Sélectionner. Le notebook généré importe automatiquement ces données et les transmet au modèle. Vous pouvez modifier le notebook généré si les données requièrent des transformations avant leur entrée dans le modèle.
Les prédictions sont enregistrées dans un dossier du répertoire
dbfs:/FileStore/batch-inference. Par défaut, les prédictions sont enregistrées dans un dossier portant le même nom que le modèle. Chaque exécution du notebook généré crée un nouveau fichier dans ce répertoire avec le timestamp ajouté au nom. Vous pouvez également choisir de ne pas inclure le timestamp par des exécutions ultérieures du notebook (les instructions sont fournies dans le notebook généré).Vous pouvez modifier le dossier dans lequel les prédictions sont enregistrées en saisissant un nouveau nom de dossier dans le champ Emplacement de la table de sortie ou en cliquant sur l'icône du dossier pour parcourir le répertoire et sélectionner un autre dossier.
Pour enregistrer des prédictions à un emplacement dans Unity Catalog, vous devez modifier le notebook. Pour obtenir un exemple de notebook montrant comment entraîner un modèle d'apprentissage automatique qui utilise des données dans Unity Catalog et réécrire les résultats dans Unity Catalog, consultez Entraîner et enregistrer des modèles d'apprentissage automatique avec Unity Catalog.
Configurer l’inférence en streaming à l’aide de Delta Live Tables
Quand vous suivez ces étapes pour créer un notebook d’inférence en streaming, le notebook est enregistré dans votre dossier utilisateur, sous le dossier DLT-Inference dans un dossier portant le nom du modèle. Vous pouvez modifier le notebook selon vos besoins.
Cliquez sur l’onglet Streaming (Delta Live Tables).
Dans le menu déroulant Version du modèle, sélectionnez la version du modèle à utiliser. Les deux premiers éléments de la liste déroulante permettent de sélectionner la version de production et la version intermédiaire du modèle (le cas échéant). Lorsque vous sélectionnez l’une de ces options, le notebook utilise automatiquement la version de production ou intermédiaire au moment de son exécution. Vous n’avez pas besoin de mettre à jour le notebook à mesure que vous continuez à développer le modèle.
Cliquez sur le bouton Parcourir en regard de Table d'entrée. La boîte de dialogue Sélectionner les données d’entrée s’affiche. Si nécessaire, vous pouvez modifier le cluster dans le menu déroulant Calcul.
Remarque
Pour les espaces de travail compatibles avec Unity Catalog, la boîte de dialogue Sélectionner les données d’entrée vous permet de sélectionner parmi trois niveaux :
<catalog-name>.<database-name>.<table-name>.Sélectionnez la base table contenant les données d'entrée du modèle, puis cliquez sur Sélectionner. Le notebook généré crée une transformation de données qui utilise la table d’entrée en tant que source, et intègre la fonction UDF d’inférence PySpark de MLflow pour effectuer des prédictions de modèle. Vous pouvez modifier le notebook généré si les données nécessitent des transformations supplémentaires avant ou après l’application du modèle.
Indiquez le nom de la table Delta Live Tables de sortie. Le notebook crée une table dynamique avec le nom donné, et l’utilise pour stocker les prédictions de modèle. Vous pouvez modifier le notebook généré pour personnaliser le jeu de données cible selon les besoins. Par exemple, vous pouvez définir une table dynamique en streaming en tant que sortie, ajouter des informations de schéma ou des contraintes de qualité des données.
Vous pouvez ensuite créer un pipeline Delta Live Tables avec ce notebook, ou l’ajouter à un pipeline existant en tant que bibliothèque de notebooks supplémentaire.
Configurer l’inférence en temps réel
Service de Modèle expose vos modèles Machine Learning MLflow en tant que points de terminaison d’API REST évolutifs. Pour créer un point de terminaison de mise en service de modèle, consultez Créer et gérer des points de terminaison de mise en service de modèle.
Fournir des commentaires
Cette fonctionnalité est en préversion et nous aimerions recevoir vos commentaires. Pour envoyer vos commentaires, cliquez sur Provide Feedback dans la boîte de dialogue Configuration de l'inférence de modèle.
Comparer des versions de modèles
Vous pouvez comparer les versions de modèles dans le registre des modèles d'espace de travail.
- Sur la page du modèle inscrit, sélectionnez deux ou plusieurs versions du modèle en cochant la case à gauche de la version du modèle.
- Cliquez sur Comparer.
- L’écran de comparaison des versions s’affiche et présente un tableau qui compare les paramètres, le schéma et les métriques des versions de modèle sélectionnées. En bas de l’écran, vous pouvez sélectionner le type de tracé (nuage de points, contour ou coordonnées parallèles), ainsi que les paramètres ou les métriques à tracer.
Contrôler les préférences de notification
Vous pouvez configurer Espace de travail Model Registry pour vous avertir par e-mail de l'activité sur les modèles enregistrés et les versions de modèles que vous spécifiez.
Dans la page de modèle inscrit, le menu Notify me about (M’avertir à propos de) affiche trois options :

- All new activity (Toutes les nouvelles activités) : envoyer des notifications par e-mail concernant toutes les activités sur toutes les versions de ce modèle. Si vous avez créé le modèle inscrit, il s’agit de la valeur par défaut.
- Activity on versions I follow (Activité sur les versions que je suis) : envoyer des notifications par e-mail uniquement sur les versions de modèle que vous suivez. Avec cette sélection, vous recevez des notifications pour toutes les versions de modèle que vous suivez. Vous ne pouvez pas désactiver les notifications pour une version de modèle spécifique.
- Mute notifications (Désactiver les notifications) : ne pas envoyer de notifications par e-mail en cas d’activité sur ce modèle inscrit.
Les événements suivants déclenchent une notification par e-mail :
- Création d’une nouvelle version de modèle
- Demande de transition de phase
- Transition de phase
- Nouveaux commentaires
Vous êtes automatiquement abonné aux notifications de modèle lorsque vous effectuez l’une des opérations suivantes :
- Commenter cette version de modèle
- Effectuer la transition de la phase d’une version de modèle
- Effectuer une demande de transition pour la phase du modèle
Pour voir si vous suivez une version de modèle, examinez le champ Follow Status (Statut du suivi) dans la page de version de modèle, ou dans la table des versions de modèle dans la page de modèle inscrit.
Désactiver les notifications par e-mail
Vous pouvez désactiver les notifications par e-mail dans l'onglet Paramètres du registre du modèle d'espace de travail du menu Paramètres utilisateur :
- Cliquez sur votre nom d’utilisateur dans le coin supérieur droit de l’espace de travail Azure Databricks, puis sélectionnez Paramètres utilisateur dans la liste déroulante.
- Dans la barre latérale des Paramètres, sélectionnez Notifications.
- Désactivez Notifications e-mail du registre de modèles.
Un administrateur de compte peut désactiver les notifications par e-mail pour l’ensemble de l’organisation dans la page de paramètres d’administration.
Nombre maximal d’e-mails envoyés
Espace de travail Model Registry limite le nombre d’e-mails envoyés à chaque utilisateur par jour et par activité. Par exemple, si vous recevez 20 e-mails en une journée concernant les nouvelles versions de modèle créées pour un modèle enregistré, Espace de travail Model Registry envoie un e-mail indiquant que la limite quotidienne a été atteinte, et aucun e-mail supplémentaire concernant cet événement n'est envoyé avant le lendemain.
Pour augmenter la limite du nombre d’e-mails autorisés, contactez l’équipe de votre compte Azure Databricks.
Webhooks
Important
Cette fonctionnalité est disponible en préversion publique.
Les webhooks vous permettent d'écouter les événements Espace de travail Model Registry afin que vos intégrations puissent déclencher automatiquement des actions. Vous pouvez utiliser des webhooks pour automatiser et intégrer votre pipeline Machine Learning avec les outils et flux de travail CI/CD. Par exemple, vous pouvez déclencher des builds CI quand une nouvelle version de modèle est créée ou notifier les membres de l’équipe par marge chaque fois qu’une transition de modèle vers la production est demandée.
Annoter un modèle ou une version de modèle
Vous pouvez fournir des informations sur un modèle ou une version de modèle en l’annotant. Par exemple, vous pouvez souhaiter inclure une vue d’ensemble du problème ou des informations sur la méthodologie et l’algorithme employés.
Annoter un modèle ou une version de modèle à l’aide de l’interface utilisateur
L’interface utilisateur Azure Databricks permet d’annoter des modèles et des versions de modèle de plusieurs façons. Vous pouvez ajouter des informations textuelles à l'aide d'une description ou de commentaires, et également ajouter des étiquettes clé-valeur pouvant faire l'objet d'une recherche. Les descriptions et les étiquettes sont disponibles pour les modèles et les versions de modèle, tandis que les commentaires sont disponibles pour les versions de modèle uniquement.
- Les descriptions sont destinées à fournir des informations sur le modèle.
- Les commentaires offrent un moyen de maintenir une discussion sur les activités sur une version de modèle.
- Les étiquettes vous permettent de personnaliser les métadonnées du modèle pour faciliter la recherche de modèles spécifiques.
Ajouter ou mettre à jour la description d’un modèle ou d’une version de modèle
Dans la page du modèle inscrit ou de la version du modèle, cliquez sur Modifier en regard de Description. Une fenêtre d'édition apparaît.
Entrez ou modifiez la description dans la fenêtre de modification.
Cliquez sur Enregistrer pour enregistrer vos modifications ou sur Annuler pour fermer la fenêtre.
Si vous avez entré une description de version de modèle, elle s’affiche dans la colonne Description de la table située dans la page du modèle inscrit. La colonne affiche au maximum 32 caractères ou une ligne de texte, le plus petit des deux étant conservé.
Ajouter des commentaires pour une version de modèle
- Faites défiler la page version du modèle et cliquez sur la flèche vers le bas à côté de Activités.
- Tapez votre commentaire dans la fenêtre d’édition, puis cliquez sur Ajouter un commentaire.
Ajouter des étiquettes pour un modèle ou une version de modèle
Dans la page du modèle inscrit ou de la version du modèle, cliquez sur
 si elle n'est pas déjà ouverte. Le tableau Étiquettes s’affiche.
si elle n'est pas déjà ouverte. Le tableau Étiquettes s’affiche.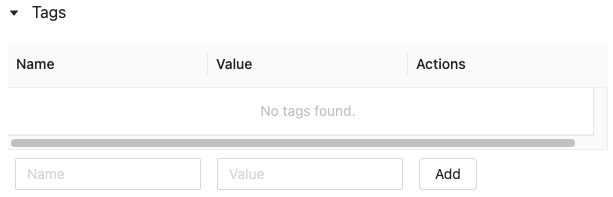
Cliquez dans les champs Nom et Valeur, puis entrez la clé et la valeur de votre étiquette.
Cliquez sur Ajouter.

Modifier ou supprimer des étiquettes pour un modèle ou une version de modèle
Pour modifier ou supprimer une étiquette existante, utilisez les icônes de la colonne Actions.
Annoter une version de modèle à l’aide de l’API
Pour mettre à jour la description d’une version de modèle, utilisez la méthode update_model_version() de l’API cliente MLflow :
client = MlflowClient()
client.update_model_version(
name="<model-name>",
version=<model-version>,
description="<description>"
)
Pour définir ou mettre à jour une étiquette pour un modèle inscrit ou une version du modèle, utilisez la méthode set_registered_model_tag()) ou set_model_version_tag() de l’API cliente MLflow :
client = MlflowClient()
client.set_registered_model_tag()(
name="<model-name>",
key="<key-value>",
tag="<tag-value>"
)
client = MlflowClient()
client.set_model_version_tag()(
name="<model-name>",
version=<model-version>,
key="<key-value>",
tag="<tag-value>"
)
Renommer un modèle (API uniquement)
Pour renommer un modèle inscrit, utilisez la méthode rename_registered_model() de l’API cliente MLflow :
client=MlflowClient()
client.rename_registered_model("<model-name>", "<new-model-name>")
Remarque
Vous ne pouvez renommer un modèle inscrit que s’il n’a pas de version ou si toutes les versions se trouvent dans la phase None (Aucune) ou Archived (Archivage).
Rechercher un modèle
Vous pouvez rechercher des modèles dans le registre des modèles d'espace de travail à l'aide de l'interface utilisateur ou de l'API.
Remarque
Quand vous recherchez un modèle, seuls les modèles pour lesquels vous disposez au moins des autorisations PEUT LIRE sont retournés.
Rechercher un modèle à l’aide de l’interface utilisateur
Pour afficher les modèles enregistrés, cliquez sur ![]() Modèles dans la barre latérale.
Modèles dans la barre latérale.
Pour rechercher un modèle spécifique, entrez du texte dans la zone de recherche. Vous pouvez entrer le nom d’un modèle ou toute partie du nom :
Vous pouvez également effectuer une recherche sur des étiquettes. Entrez des étiquettes au format suivant : tags.<key>=<value>. Pour rechercher plusieurs balises, utilisez l’opérateur AND.
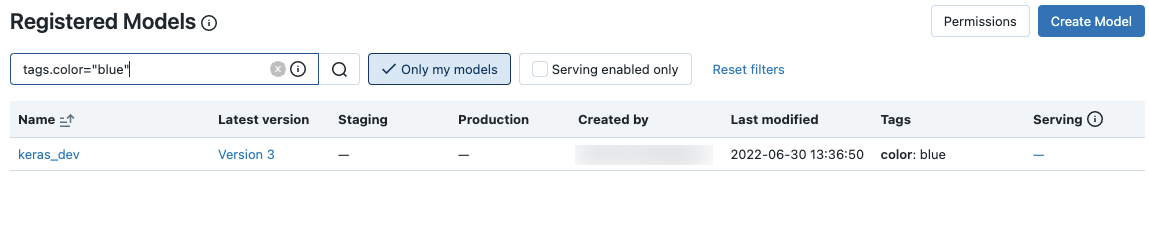
Vous pouvez effectuer une recherche sur le nom et les étiquettes à l’aide de la syntaxe de recherche MLflow. Par exemple :

Rechercher un modèle à l’aide de l’API
Vous pouvez rechercher des modèles enregistrés dans le registre des modèles d'espace de travail avec la méthode de l'API client MLflow search_registered_models()
Si vous avez défini des étiquettes pour vos modèles, vous pouvez également effectuer une recherche en fonction de ces étiquettes avec search_registered_models().
print(f"Find registered models with a specific tag value")
for m in client.search_registered_models(f"tags.`<key-value>`='<tag-value>'"):
pprint(dict(m), indent=4)
Vous pouvez aussi rechercher un nom de modèle spécifique et lister les détails de ses versions en utilisant la méthode search_model_versions() de l’API cliente MLflow :
from pprint import pprint
client=MlflowClient()
[pprint(mv) for mv in client.search_model_versions("name='<model-name>'")]
En voici la sortie :
{ 'creation_timestamp': 1582671933246,
'current_stage': 'Production',
'description': 'A random forest model containing 100 decision trees '
'trained in scikit-learn',
'last_updated_timestamp': 1582671960712,
'name': 'sk-learn-random-forest-reg-model',
'run_id': 'ae2cc01346de45f79a44a320aab1797b',
'source': './mlruns/0/ae2cc01346de45f79a44a320aab1797b/artifacts/sklearn-model',
'status': 'READY',
'status_message': None,
'user_id': None,
'version': 1 }
{ 'creation_timestamp': 1582671960628,
'current_stage': 'None',
'description': None,
'last_updated_timestamp': 1582671960628,
'name': 'sk-learn-random-forest-reg-model',
'run_id': 'd994f18d09c64c148e62a785052e6723',
'source': './mlruns/0/d994f18d09c64c148e62a785052e6723/artifacts/sklearn-model',
'status': 'READY',
'status_message': None,
'user_id': None,
'version': 2 }
Supprimer un modèle ou une version de modèle
Vous pouvez supprimer un modèle à l’aide de l’interface utilisateur ou de l’API.
Supprimer une version de modèle ou un modèle à l’aide de l’interface utilisateur
Avertissement
Vous ne pouvez pas annuler cette action. Vous pouvez faire passer une version de modèle en phase Archived (Archivage) au lieu de la supprimer du Registre. Lorsque vous supprimez un modèle, tous les artefacts de modèle stockés par Espace de travail Model Registry et toutes les métadonnées associées au modèle enregistré sont supprimés.
Remarque
Vous ne pouvez supprimer que les modèles et les versions de modèle en phase None (Aucune) ou Archived (Archivage). Si un modèle inscrit a des versions en phase Staging (Préproduction) ou Production, vous devez les faire passer en phase None (Aucune) ou Archived (Archivage) avant de supprimer le modèle.
Pour supprimer un modèle de modèle :
- Cliquez sur Modèles dans la barre latérale.
- Cliquez sur un nom de modèle.
- Cliquez sur une version de modèle.
- Cliquez sur
 dans le coin supérieur droit de l'écran et sélectionnez Supprimer dans le menu déroulant.
dans le coin supérieur droit de l'écran et sélectionnez Supprimer dans le menu déroulant.
Pour supprimer un modèle :
- Cliquez sur Modèles dans la barre latérale.
- Cliquez sur un nom de modèle.
- Cliquez sur dans le coin supérieur droit de l'écran et sélectionnez Supprimer dans le menu déroulant.
Supprimer une version de modèle ou un modèle à l’aide de l’API
Avertissement
Vous ne pouvez pas annuler cette action. Vous pouvez faire passer une version de modèle en phase Archived (Archivage) au lieu de la supprimer du Registre. Lorsque vous supprimez un modèle, tous les artefacts de modèle stockés par Espace de travail Model Registry et toutes les métadonnées associées au modèle enregistré sont supprimés.
Remarque
Vous ne pouvez supprimer que les modèles et les versions de modèle en phase None (Aucune) ou Archived (Archivage). Si un modèle inscrit a des versions en phase Staging (Préproduction) ou Production, vous devez les faire passer en phase None (Aucune) ou Archived (Archivage) avant de supprimer le modèle.
Supprimer une version de modèle
Pour supprimer une version de modèle, utilisez la méthode delete_model_version() de l’API cliente MLflow :
# Delete versions 1,2, and 3 of the model
client = MlflowClient()
versions=[1, 2, 3]
for version in versions:
client.delete_model_version(name="<model-name>", version=version)
Supprimer un modèle
Pour supprimer un modèle, utilisez la méthode delete_registered_model() de l’API cliente MLflow :
client = MlflowClient()
client.delete_registered_model(name="<model-name>")
Partager des modèles dans des espaces de travail
Databricks recommande d’utiliser des modèles dans Unity Catalog pour partager des modèles entre les espaces de travail. Unity Catalog fournit une prise en charge prête à l'emploi pour l'accès aux modèles inter-espaces de travail, la gouvernance et la journalisation d'audit.
Toutefois, si vous utilisez le registre de modèles d'espace de travail, vous pouvez également partager des modèles sur plusieurs espaces de travail avec une certaine configuration. Par exemple, vous pouvez développer et enregistrer un modèle dans votre propre espace de travail, puis y accéder à partir d'un autre espace de travail à l'aide d'un registre de modèles d'espace de travail distant. Cela est utile quand plusieurs équipes partagent l’accès aux modèles. Vous pouvez créer plusieurs espaces de travail de façon à utiliser et gérer les modèles dans ces environnements.
Copier des objets MLflow entre des espaces de travail
Pour importer ou exporter des objets MLflow vers ou depuis votre espace de travail Azure Databricks, vous pouvez utiliser le projet open source alimenté par la communauté MLflow Export-Import pour migrer des expériences, des modèles et des exécutions MLflow entre des espaces de travail.
Grâce à ces outils, vous pouvez :
- Partagez et collaborez avec d’autres scientifiques des données dans le même serveur de suivi ou un autre. Par exemple, vous pouvez cloner une expérience d’un autre utilisateur dans votre espace de travail.
- Copiez un modèle d’un espace de travail vers un autre, par exemple à partir d’un espace de travail de développement vers un espace de travail de production.
- Copiez des expériences et exécutions MLflow de votre serveur de suivi local vers votre espace de travail Databricks.
- Sauvegardez les expériences et modèles stratégiques dans un autre espace de travail Databricks.
Exemple
Cet exemple illustre comment utiliser Espace de travail Model Registry pour créer une application de machine learning.