Compute
Le calcul Azure Databricks fait référence à la sélection des ressources informatiques disponibles dans l’espace de travail Azure Databricks. Les utilisateurs ont besoin d’un accès au calcul pour exécuter les charges de travail d’engineering données, de science des données et d’analytique données, comme les pipelines ETL de production, l’analytique de streaming, l’analytique ad-hoc et le machine learning.
Les utilisateurs peuvent se connecter au calcul existant ou créer un nouveau calcul s’ils disposent des autorisations appropriées.
Vous pouvez voir le calcul auquel vous avez accès en utilisant la section Calcul de l’espace de travail :
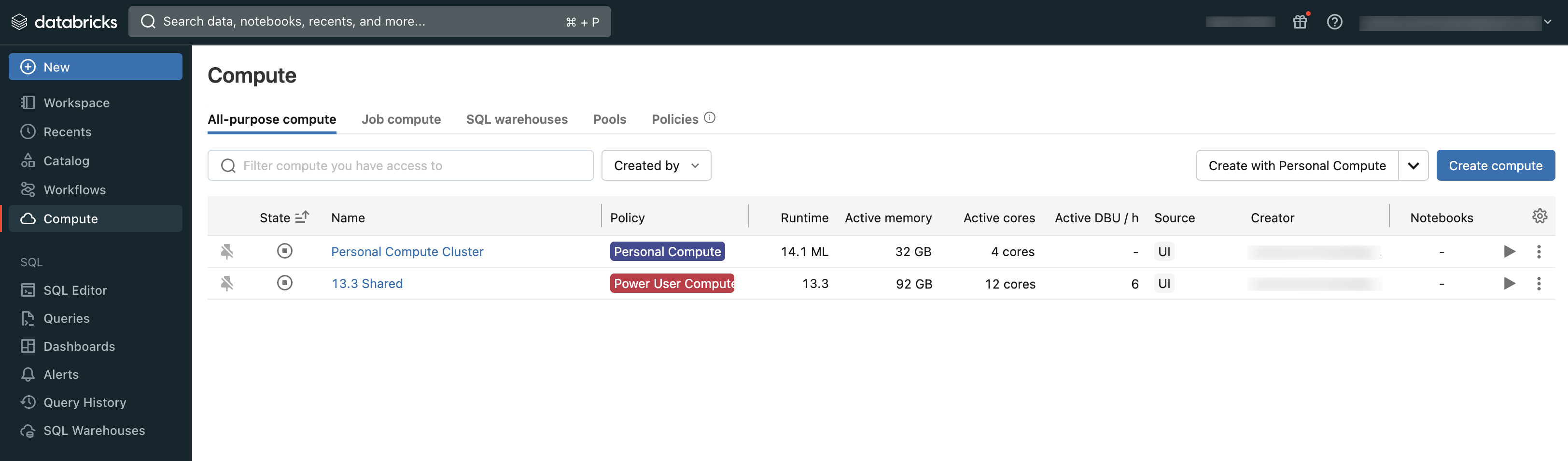
Types de calcul
Voici les types de calculs disponibles dans Azure Databricks :
Le calcul à usage général : utilisé pour analyser des données de façon collaborative à l’aide d’un notebook interactif. Vous pouvez créer, terminer et redémarrer ce calcul par l’interface utilisateur, de l’interface CLI ou l’API REST.
Calcul du travail : utilisé pour exécuter des travaux automatisés, rapides et solides. Le planificateur de travaux Azure Databricks crée un calcul de travail lorsque vous exécutez un travail sur un nouveau calcul. Le calcul se termine à la fin du travail. Vous ne pouvez pas redémarrer un calcul de travail. Consultez Utiliser le calcul Azure Databricks avec vos travaux.
Pools de l’instance : calcul avec des instances inactives, prêtes à l’emploi, utilisées pour réduire les temps de démarrage et de mise à l’échelle automatique. Vous pouvez créer ce calcul par l’interface utilisateur, l’interface CLI ou l’API REST.
Les entrepôts SQL serverless : calcul élastique à la demande utilisé pour exécuter des commandes SQL sur des objets de données dans l’éditeur SQL ou les notebooks interactifs. Vous pouvez créer des entrepôts SQL par l’interface utilisateur, l’interface CLI ou l’API REST.
Les entrepôts SQL classiques : calcul approvisionné utilisé pour exécuter des commandes SQL sur des objets de données dans l’éditeur SQL ou les notebooks interactifs. Vous pouvez créer des entrepôts SQL par l’interface utilisateur, l’interface CLI ou l’API REST.
Les articles de cette section décrivent comment utiliser des ressources de calcul au moyen de l’interface utilisateur Azure Databricks. Pour les autres méthodes, consultez Utiliser la ligne de commande et la référence de l’API REST Databricks.
Runtime Databricks
Databricks Runtime constitue l’ensemble des composants de base qui s’exécutent sur votre calcul. Databricks Runtime est un paramètre configurable pour tous types de travaux de calcul, mais est automatiquement sélectionné dans les entrepôts SQL.
Chaque version de Databricks Runtime inclut des mises à jour qui améliorent la convivialité, les performances et la sécurité des analyses de Big Data. Databricks Runtime sur votre calcul ajoute plusieurs fonctionnalités, notamment :
- Delta Lake, une couche de stockage de nouvelle génération construite au-dessus d’Apache Spark, qui offre des transactions ACID, des mises en page et des index optimisés, ainsi que des améliorations du moteur d'exécution pour la création de pipelines de données. Consultez Présentation de Delta Lake.
- Bibliothèques Java, Scala, Python et R installées.
- Ubuntu et ses bibliothèques système associées.
- Bibliothèques GPU pour les clusters compatibles GPU.
- Les services Azure Databricks qui s’intègrent à d’autres composants de la plate-forme, tels que les notebooks, les tâches et la gestion des clusters.
Pour plus d’informations sur le contenu de chaque version du runtime, consultez les notes de publication.
Contrôle de version de Runtime
Les versions de Databricks Runtime sont publiées régulièrement :
- Les versions Long Term Support sont représentées par un qualificateur LTS (par exemple, 3.5 LTS). Pour chaque version majeure, nous déclarons une version de fonctionnalités « canonique », pour laquelle nous assurons trois années complètes de support. Pour plus d'informations, voir Cycles de vie du support de Databricks Runtime.
- Les versions majeures sont représentées par un incrément au numéro de version qui précède la virgule (passage de 3.5 à 4.0, par exemple). Elles sont publiées en cas de modifications majeures, dont certaines peuvent ne pas offrir de rétrocompatibilité.
- Les versions de fonctionnalités sont représentées par un incrément au numéro de version qui précède la virgule (passage de 3.4 à 3.5, par exemple). Chaque version majeure comprend plusieurs versions de fonctionnalités. Les versions de fonctionnalités sont toujours rétrocompatibles avec les versions précédentes dans leur version majeure.