Utiliser des magasins de métadonnées externes dans Azure HDInsight
Important
Le metastore par défaut fournit une base de données Azure SQL avec le niveau de base et seulement 5 DTU et 2 Go de données maximum (SANS MISE À NIVEAU POSSIBLE) ! Utilisez-le uniquement pour l’assurance qualité et les tests. Pour les grandes charges de travail ou les charges de travail de production, nous vous recommandons de migrer vers un metastore externe !
HDInsight vous permet de prendre le contrôle de vos données et métadonnées grâce à des magasins de données externes. Cette fonctionnalité est disponible pour le metastore Apache Hive, le metastore Apache Oozie et la base de données Apache Ambari.
Le metastore Apache Hive dans HDInsight est une partie essentielle de l’architecture d’Apache Hadoop. Un metastore est le référentiel central de schémas. Le metastore peut être utilisé par d’autres outils d’accès au Big Data, comme Apache Spark, Interactive Query (LLAP), Presto ou Apache Pig. HDInsight utilise une base de données Azure SQL Database en tant que metastore Hive.
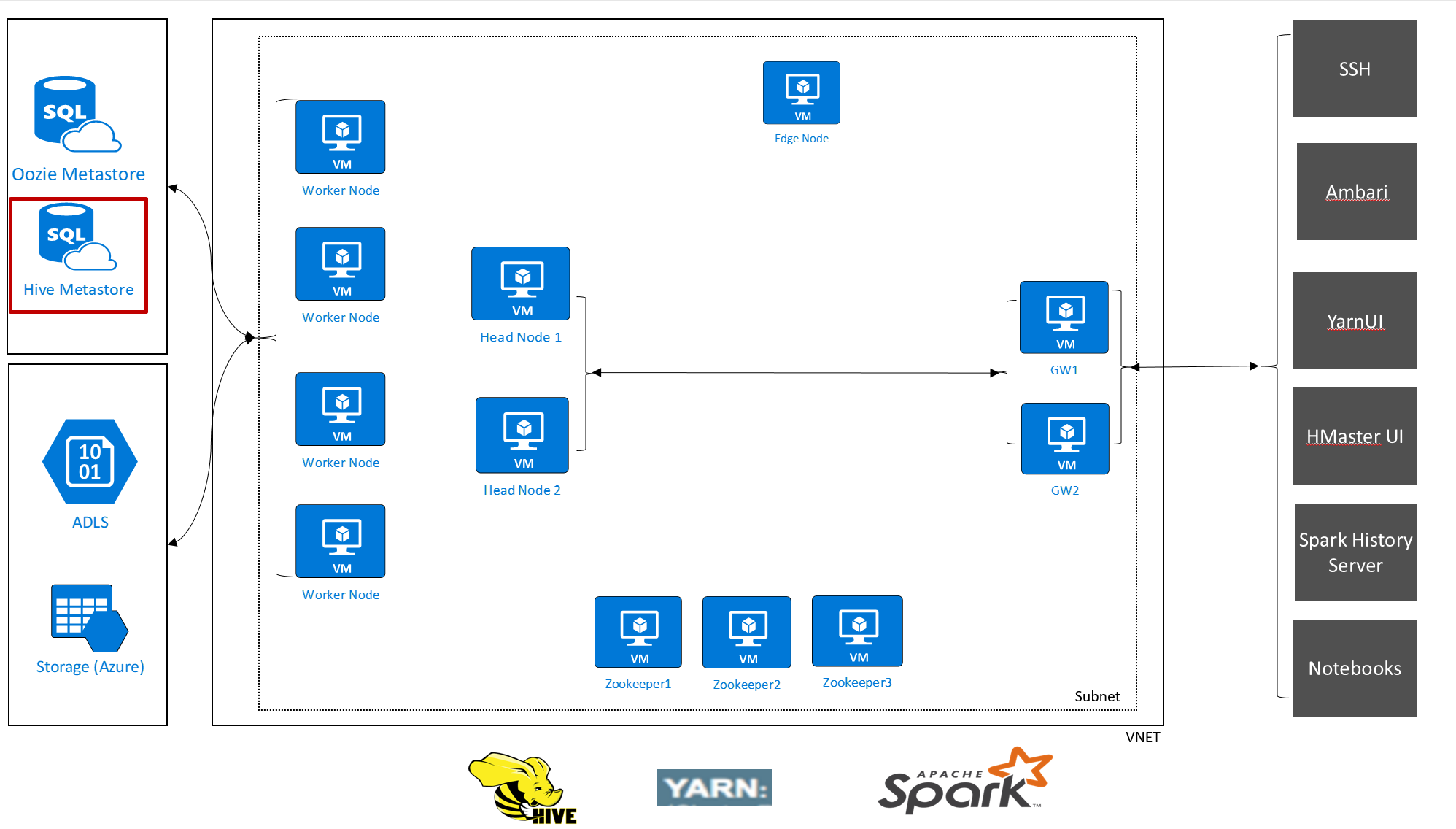
Il existe deux façons de configurer un metastore pour vos clusters HDInsight :
Metastore par défaut
Par défaut, HDInsight crée un metastore avec chaque type de cluster. Vous pouvez à la place spécifier un metastore personnalisé. Le metastore par défaut comprend les considérations suivantes :
Ressources limitées. Consultez la notification en haut de la page.
Pas de coût supplémentaire. HDInsight crée un metastore avec chaque type de cluster sans coût supplémentaire pour vous.
Le metastore par défaut fait partie du cycle de vie du cluster. Lorsque vous supprimez un cluster, le metastore et les métadonnées correspondants sont également supprimés.
Le metastore par défaut est recommandé uniquement pour les charges de travail simples. Ces charges de travail n’ont pas besoin de plusieurs clusters et ne nécessitent pas la conservation des métadonnées au-delà du cycle de vie du cluster.
Le metastore par défaut ne peut pas être partagé avec d’autres clusters.
Metastore personnalisé
HDInsight prend également en charge les magasins de métadonnées personnalisés, qui sont recommandés pour les clusters de production :
Vous spécifiez votre propre base de données Azure SQL comme metastore.
Le cycle de vie du metastore n’est pas lié à un cycle de vie de cluster. Vous pouvez donc créer et supprimer des clusters sans perdre les métadonnées. Les métadonnées telles que vos schémas Hive sont conservées même une fois que vous supprimez et recréez le cluster HDInsight.
Un metastore personnalisé vous permet d’attacher plusieurs clusters et types de cluster à ce metastore. Par exemple, un seul metastore peut être partagé entre les clusters de requête interactive, Hive et Spark dans HDInsight.
Vous payez le coût d’un metastore (Azure SQL Database), selon le niveau de performance que vous choisissez.
Vous pouvez augmenter l’échelle du metastore en fonction de vos besoins.
Le cluster et le metastore externe doivent être hébergés dans la même région.
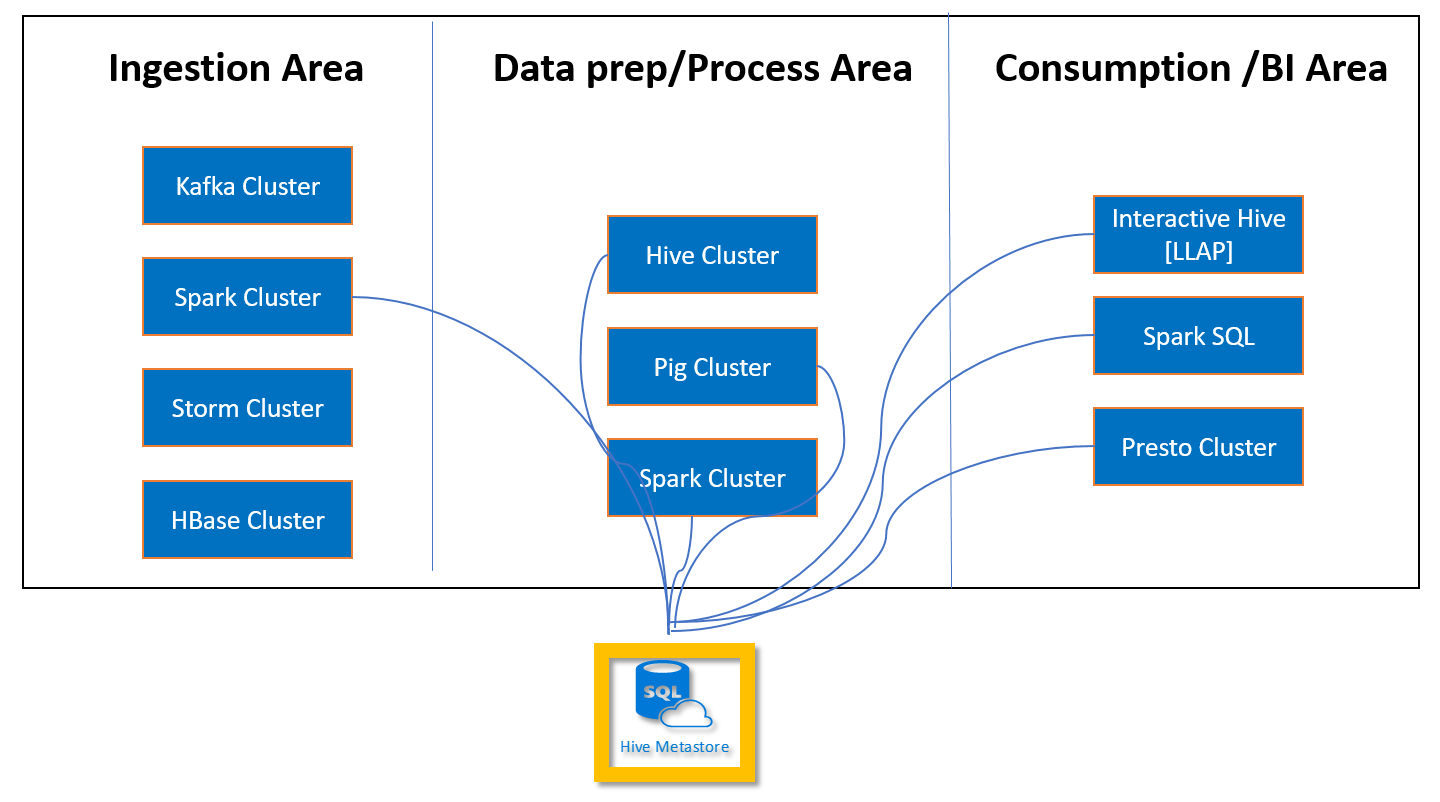
Créer et configurer une base de données Azure SQL Database pour le metastore personnalisé
Créer ou avoir une base de données Azure SQL Database existante avant de configurer un metastore Hive personnalisé pour un cluster HDInsight. Pour plus d’informations, consultez Démarrage rapide : Créer une base de données unique dans Azure SQL Database.
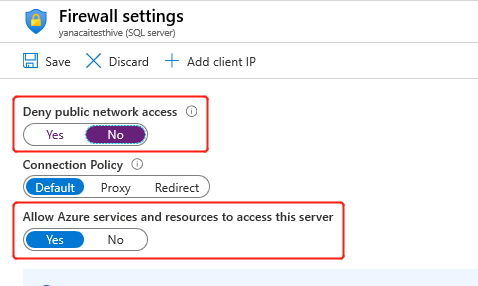
Lors de la création du cluster, le service HDInsight doit se connecter au metastore externe et vérifier vos informations d'identification. Configurez des règles de pare-feu Azure SQL Database pour autoriser les services et ressources Azure à accéder au serveur. Activez cette option dans le Portail Azure en sélectionnant Paramétrer le pare-feu du serveur. Sélectionnez ensuite Non sous Refuser l’accès au réseau public, puis Oui sous Autoriser les services et les ressources Azure à accéder à ce serveur pour Azure SQL Database. Pour plus d’informations, consultez Créer et gérer des règles de pare-feu IP
Les points de terminaison privés pour les magasins SQL sont uniquement pris en charge sur les clusters créés avec outbound ResourceProviderConnection. Pour plus d’informations, consultez la documentation.

Sélectionner un metastore personnalisé lors de la création du cluster
Vous pouvez pointer votre cluster vers une instance Azure SQL Database précédemment créée à tout moment. Pour la création d’un cluster via le portail, l’option est spécifiée à partir des paramètres Stockage > Metastore.

Recommandations du metastore Apache Hive
Notes
Utilisez un metastore personnalisé aussi souvent que possible, afin de mieux séparer les ressources de calcul (votre cluster en cours d’exécution) et les métadonnées (stockées dans le metastore). Commencez avec le niveau S2, qui fournit 50 DTU et 250 Go de stockage. Si vous voyez un goulot d’étranglement, vous pouvez mettre à l’échelle la base de données.
Si vous prévoyez d’utiliser plusieurs clusters HDInsight pour accéder aux données distinctes, utilisez une base de données distincte pour le metastore sur chaque cluster. Si vous partagez un metastore sur plusieurs clusters HDInsight, cela signifie que les clusters utilisent les mêmes métadonnées et fichiers de données utilisateur sous-jacentes.
Sauvegardez régulièrement votre metastore personnalisé. Azure SQL Database génère automatiquement des sauvegardes, mais la période de conservation des sauvegardes varie. Pour plus d’informations, consultez En savoir plus sur les sauvegardes automatiques SQL Database.
Placez votre metastore et le cluster HDInsight dans la même région. Cette configuration offre des performances optimales et des frais de sortie réseau les plus bas.
Surveillez les performances et la disponibilité de votre metastore à l’aide des outils de surveillance d’Azure SQL Database ou des journaux d’activité Azure Monitor.
Lorsqu’une nouvelle version d’Azure HDInsight plus élevée est créée sur une base de données de metastore personnalisée existante, le système met à niveau le schéma du metastore. Sans restauration de la base de données à partir d’une sauvegarde, la mise à niveau est irréversible.
Si vous partagez un metastore sur plusieurs clusters, assurez-vous que tous les clusters utilisent la même version de HDInsight. Différentes versions d’Hive utilisent différents schémas de base de données de metastore. Par exemple, vous ne pouvez pas partager un metastore entre des clusters Hive de versions 2.1 et 3.1.
Dans HDInsight 4.0, Spark et Hive utilisent des catalogues indépendants pour accéder aux tables SparkSQL ou Hive. Les tables créées par Spark résident dans le catalogue Spark. Les tables créées par Hive résident dans le catalogue Hive. Ce comportement est différent de HDInsight 3.6, où Hive et Spark partageaient le même catalogue. L’intégration de Hive et Spark à HDInsight 4.0 s’appuie sur le connecteur Hive Warehouse Connector (HWC). Le connecteur HWC sert de pont entre Spark et Hive. En savoir plus sur le connecteur Hive Warehouse Connector
Dans HDInsight 4.0, si vous souhaitez partager le metastore entre Hive et Spark, vous pouvez le faire en remplaçant la propriété metastore.catalog.default par hive dans votre cluster Spark. Vous pouvez trouver cette propriété dans Ambari Advanced spark2-hive-site-override. Il est important de comprendre que le partage du metastore ne fonctionne que pour les tables Hive externes. Cela ne fonctionnera pas si vous avez des tables Hive internes/gérées ou des tables ACID.
Mise à jour du mot de passe du metastore Hive
Lorsque vous utilisez une base de données metastore Hive personnalisée, vous avez la possibilité de modifier le mot de passe de la base de données SQL. Si vous modifiez le mot de passe du metastore personnalisé, les services Hive ne fonctionneront pas tant que vous n’aurez pas mis à jour le mot de passe dans le cluster HDInsight.
Pour mettre à jour le mot de passe du metastore Hive :
- Ouvrir l’interface utilisateur d’Ambari.
- Cliquez sur Services --> Hive --> Configs --> Base de données.
- Mettez à jour les champs Mot de passe de la base de données avec le nouveau mot de passe de la base de données SQL Server.
- Cliquez sur le bouton Tester la connexion pour vous assurer que le nouveau mot de passe fonctionne.
- Cliquez sur le bouton Enregistrer .
- Suivez les invites Ambari pour enregistrer la configuration, puis redémarrez les services requis.
Metastore Apache Oozie
Apache Oozie est un système de coordination de flux de travail qui gère les tâches Hadoop. Oozie prend en charge les tâches Hadoop pour Apache MapReduce, Pig, Hive et autres. Oozie utilise un metastore pour stocker les détails sur les workflows. Pour améliorer les performances avec Oozie, utilisez une base de données Azure SQL en tant que magasin de metastore personnalisé. Le metastore permet d’accéder aux données de travail Oozie après la suppression de votre cluster.
Pour obtenir des instructions sur la création d’un metastore Oozie avec Azure SQL Database, consultez Utiliser Apache Oozie pour les flux de travail.
Mise à jour du mot de passe du metastore Oozie
Lorsque vous utilisez une base de données metastore Oozie personnalisée, vous avez la possibilité de modifier le mot de passe de la base de données SQL. Si vous modifiez le mot de passe du metastore personnalisé, les services Oozie ne fonctionneront pas tant que vous n’aurez pas mis à jour le mot de passe dans le cluster HDInsight.
Pour mettre à jour le mot de passe du metastore Oozie :
- Ouvrir l’interface utilisateur d’Ambari.
- Cliquez sur Services --> Oozie --> Configs --> Base de données.
- Mettez à jour les champs Mot de passe de la base de données avec le nouveau mot de passe de la base de données SQL Server.
- Cliquez sur le bouton Tester la connexion pour vous assurer que le nouveau mot de passe fonctionne.
- Cliquez sur le bouton Enregistrer .
- Suivez les invites Ambari pour enregistrer la configuration, puis redémarrez les services requis.
Base de données Ambari personnalisée
Pour utiliser votre propre base de données externe avec Apache Ambari sur HDInsight, consultez Base de données Apache Ambari personnalisée.