Utiliser des packages externes avec des blocs-notes Jupyter Notebook dans des clusters Apache Spark sur HDInsight
Découvrez comment configurer un bloc-notes Jupyter Notebook dans un cluster Apache Spark sur HDInsight pour utiliser des packages Apache Maven externes bénéficiant de la contribution de la communauté, qui ne sont pas inclus dans le cluster.
Vous pouvez rechercher le référentiel Maven pour obtenir la liste complète des packages disponibles. Vous pouvez également obtenir une liste des packages disponibles à partir d’autres sources. Par exemple, une liste complète des packages bénéficiant de la contribution de la communauté est disponible sur le site Spark Packages(Packages Spark).
Dans cet article, vous allez apprendre à utiliser le package spark-csv avec le bloc-notes Jupyter Notebook.
Prérequis
Un cluster Apache Spark sur HDInsight. Pour obtenir des instructions, consultez Création de clusters Apache Spark dans Azure HDInsight.
Connaissances sur l’utilisation des blocs-notes Jupyter Notebook avec Spark sur HDInsight. Pour plus d’informations, consultez Charger des données et exécuter des requêtes sur un cluster Apache Spark dans Azure HDInsight.
Le schéma d’URI de votre principal espace de stockage de clusters. Il s’agirait de
wasb://pour Stockage Azure, deabfs://pour Azure Data Lake Storage Gen2 ou deadl://pour Azure Data Lake Storage Gen1. Si l’option de transfert sécurisé est activée pour Stockage Azure ou Data Lake Storage Gen2, l’URI seraitwasbs://ouabfss://, respectivement. Consultez également l’article dédié au transfert sécurisé.
Utiliser des packages externes avec des blocs-notes Jupyter
Accédez à
https://CLUSTERNAME.azurehdinsight.net/jupyter, oùCLUSTERNAMEest le nom de votre cluster Spark.Créer un nouveau bloc-notes. Sélectionnez Nouveau, puis sélectionnez Spark.
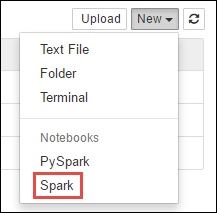
Un nouveau bloc-notes est créé et ouvert sous le nom Untitled.pynb. Sélectionnez le nom du bloc-notes en haut, puis entrez un nom convivial.
Vous allez utiliser la commande magique
%%configurepour configurer le bloc-notes afin d’utiliser un package externe. Dans les blocs-notes utilisant des packages externes, veillez à appeler la commande magique%%configuredans la première cellule de code. Cela garantit que le noyau est configuré pour utiliser le package avant le démarrage de la session.Important
Si vous oubliez de configurer le noyau dans la première cellule, vous pouvez utiliser
%%configureavec le paramètre-f. Toutefois, cette opération redémarrera la session et entraînera la perte de toute la progression.Version de HDInsight Commande Pour HDInsight 3.5 et HDInsight 3.6 %%configure{ "conf": {"spark.jars.packages": "com.databricks:spark-csv_2.11:1.5.0" }}Pour HDInsight 3.3 et HDInsight 3.4 %%configure{ "packages":["com.databricks:spark-csv_2.10:1.4.0"] }L’extrait de code ci-dessus attend une liste de coordonnées maven pour le package externe du référentiel central Maven. Dans cet extrait de code,
com.databricks:spark-csv_2.11:1.5.0est la coordonnée maven pour le package spark-csv . Voici comment vous construire les coordonnées d’un package.a. Recherchez le package dans le référentiel Maven. Dans cet article, nous utilisons spark-csv.
b. À partir du référentiel, rassemblez les valeurs pour GroupId, ArtifactId et Version. Vérifiez que les valeurs que vous collectez correspondent à votre cluster. Dans ce cas, nous utilisons un package Scala 2.11 et Spark 1.5.0, mais il peut être nécessaire de sélectionner des versions différentes pour la version appropriée de Scala ou de Spark dans votre cluster. Vous pouvez trouver la version de Scala sur votre cluster en exécutant
scala.util.Properties.versionStringsur le noyau Spark Jupyter ou sur spark-submit. Vous pouvez trouver la version de Spark sur votre cluster en exécutantsc.versionsur les blocs-notes Jupyter Notebook.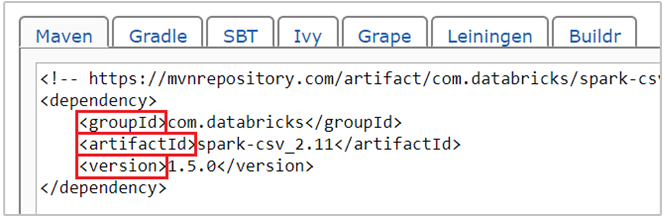
c. Concaténez les trois valeurs séparées par deux-points ( : ).
com.databricks:spark-csv_2.11:1.5.0Exécutez la cellule de code avec la commande magique
%%configure. Cela configurera la session Livy sous-jacente pour utiliser le package fourni. Dans les cellules suivantes du bloc-notes, vous pouvez maintenant utiliser le package, comme indiqué ci-dessous.val df = spark.read.format("com.databricks.spark.csv"). option("header", "true"). option("inferSchema", "true"). load("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv")Pour HDInsight 3.4 et versions antérieures, utilisez l’extrait de code suivant.
val df = sqlContext.read.format("com.databricks.spark.csv"). option("header", "true"). option("inferSchema", "true"). load("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv")Vous pouvez ensuite exécuter les extraits de code, comme illustré ci-dessous, pour afficher les données issues du tableau de données créé lors de l’étape précédente.
df.show() df.select("Time").count()
Voir aussi
Scénarios
- Apache Spark avec BI : effectuer une analyse interactive des données à l’aide de Spark sur HDInsight avec des outils décisionnels
- Apache Spark avec Machine Learning : Utiliser Spark dans HDInsight pour analyser la température d’un bâtiment à l’aide de données issues des systèmes de chauffage, de ventilation et de climatisation
- Apache Spark avec Machine Learning : utiliser Spark dans HDInsight pour prédire les résultats de l’inspection d’aliments
- Analyse des journaux de site web à l’aide d’Apache Spark dans HDInsight
Création et exécution d’applications
- Créer une application autonome avec Scala
- Exécuter des tâches à distance avec Apache Livy sur un cluster Apache Spark
Outils et extensions
- Utilisation de packages externes Python avec des Jupyter Notebooks dans des clusters Apache Spark sur HDInsight Linux
- Utilisation du plugin d’outils HDInsight pour IntelliJ IDEA pour créer et soumettre des applications Spark Scala
- Utiliser le plug-in Azure HDInsight Tools pour IntelliJ IDEA afin de déboguer des applications Apache Spark à distance
- Utiliser des blocs-notes Apache Zeppelin avec un cluster Apache Spark sur HDInsight
- Noyaux disponibles pour bloc-notes Jupyter dans un cluster Apache Spark pour HDInsight
- Install Jupyter on your computer and connect to an HDInsight Spark cluster (Installer Jupyter sur un ordinateur et se connecter au cluster Spark sur HDInsight)