Sélection de caractéristiques par filtrage
Cet article décrit comment utiliser le composant Sélection de caractéristiques par filtrage dans le concepteur Azure Machine Learning. Ce composant vous aide à identifier les colonnes de votre jeu de données d’entrée qui ont la plus grande capacité de prédiction.
En général, la sélection de caractéristiques fait référence au processus d’application de tests statistiques à des entrées, en fonction d’une sortie donnée. L’objectif est de déterminer quelles colonnes prédisent le mieux la sortie. Le composant Sélection de caractéristiques par filtrage permet de choisir parmi plusieurs algorithmes de sélection de caractéristiques. Le composant inclut des méthodes de corrélation telles que les valeurs de corrélation de Pearson et de test du khi-deux.
Lorsque vous utilisez le composant Sélection de caractéristiques par filtrage, vous fournissez un jeu de données et identifiez la colonne qui contient l’étiquette ou la variable dépendante. Vous spécifiez ensuite une méthode unique à utiliser pour mesurer l’importance des caractéristiques.
Le composant génère un jeu de données qui contient les meilleures colonnes de type Caractéristique, classées en fonction de leur capacité de prédiction. Il renvoie également le nom des caractéristiques et leur score selon la métrique sélectionnée.
Nature de la sélection de caractéristiques par filtrage
Ce composant pour la sélection de caractéristiques est appelé « par filtrage » car vous utilisez la métrique sélectionnée pour rechercher les attributs non pertinents. Vous excluez ensuite par filtrage les colonnes redondantes de votre modèle. Vous choisissez une métrique statistique unique qui correspond à vos données et le composant calcule un score pour chaque colonne de type Caractéristique. Les colonnes sont ensuite classées en fonction de leur score de caractéristique.
En choisissant les caractéristiques appropriées, vous pouvez potentiellement améliorer la précision et l’efficacité de la classification.
En général, vous n’utilisez que les colonnes avec le meilleur score pour générer votre modèle prédictif. Vous pouvez laisser dans votre jeu de données les colonnes dont le score de sélection de caractéristiques est bas ; elles seront ignorées quand vous générerez un modèle.
Comment choisir une métrique de sélection de caractéristiques
Le composant Sélection de caractéristiques par filtrage fournit diverses métriques pour évaluer la valeur informative figurant dans chaque colonne. Cette section fournit une description générale de chaque métrique et de son mode d’application. Vous trouverez des exigences supplémentaires pour l’utilisation de chaque métrique dans les notes techniques et dans les instructions de configuration de chaque composant.
Corrélation de Pearson
Le coefficient de corrélation de Pearson est également représenté dans les modèles statistiques par la valeur
r. Pour deux variables quelconques, il retourne une valeur qui indique la force de la corrélation.Le coefficient de corrélation de Pearson est calculé en prenant la covariance de deux variables et en la divisant par le produit de leurs écarts-types. Les changements d’échelle des deux variables n’affectent pas le coefficient.
Test du khi-deux
Le test du Khi-deux bidirectionnel est une méthode statistique qui mesure l’écart entre les valeurs attendues et les résultats obtenus. La méthode suppose que les variables soient aléatoires et tirées d’un échantillon adéquat de variables indépendantes. La statistique Khi-deux résultante indique l’écart entre les résultats obtenus et le résultat attendu (aléatoire).
Conseil
Si vous avez besoin d’une autre option pour la méthode de sélection des caractéristiques personnalisée, utilisez le composant Exécuter un script R.
Comment configurer la sélection de caractéristiques par filtrage
Vous choisissez une métrique statistique standard. Le composant calcule la corrélation entre deux colonnes : la colonne d’étiquette et une colonne de caractéristique.
Ajoutez le composant Sélection de caractéristiques par filtrage à votre pipeline. Ce module figure dans la catégorie Sélection des caractéristiques de la version pour les concepteurs.
Connectez un jeu de données d’entrée qui contient au moins deux colonnes qui sont des caractéristiques potentielles.
Pour s’assurer qu’une colonne sera analysée et qu’un score de caractéristique généré, utilisez le composant Modifier les métadonnées pour définir l’attribut IsFeature.
Important
Assurez-vous que les colonnes que vous fournissez comme entrées sont des caractéristiques potentielles. Par exemple, une colonne qui contient une valeur unique n’a pas de valeur d’information.
Si vous savez que certaines colonnes risquent de fournir des caractéristiques inadaptées, vous pouvez les supprimer de la sélection. Vous pouvez également utiliser le composant Modifier les métadonnées pour les définir comme Catégorie.
Pour la méthode de notation des caractéristiques, choisissez l’une des méthodes statistiques établies ci-dessous. Celle-ci sera utilisée pour le calcul des scores.
Méthode Spécifications Corrélation de Pearson L’étiquette peut être de type texte ou numérique. Les caractéristiques doivent être numériques. Test du khi-deux Les étiquettes et les caractéristiques peuvent être de type texte ou numérique. Utilisez cette méthode pour calculer l’importance des caractéristiques pour deux colonnes Catégorie. Conseil
Si vous modifiez la métrique sélectionnée, toutes les autres sélections sont réinitialisées. Par conséquent, veillez à définir cette option en premier.
Sélectionnez l’option Operate on feature columns only (Appliquer uniquement aux colonnes de caractéristiques) pour générer un score uniquement pour les colonnes précédemment marquées comme caractéristiques.
Si vous désélectionnez cette option, le composant crée un score pour toutes les colonnes qui par ailleurs répondent aux critères, jusqu’à atteindre le nombre de colonnes spécifié dans Number of desired features (Nombre de caractéristiques souhaitées).
Pour Colonne cible, sélectionnez Launch column selector (Lancer le sélecteur de colonne) pour choisir la colonne d’étiquette par nom ou par son index. (Les index sont de base un.)
Une colonne de type Étiquette est requise pour toutes les méthodes qui impliquent une corrélation statistique. Le composant renvoie une erreur au moment de la conception si vous ne choisissez aucune colonne Étiquette ou plusieurs colonnes Étiquette.Pour Number of desired features (Nombre de caractéristiques souhaitées), entrez le nombre de colonnes de caractéristiques que vous souhaitez retourner dans les résultats :
Le nombre minimal de caractéristiques que vous pouvez spécifier est 1, mais nous vous recommandons d’augmenter cette valeur.
Si le nombre spécifié de caractéristiques souhaitées est supérieur au nombre de colonnes dans le jeu de données, toutes les caractéristiques sont retournées. Même les caractéristiques avec des scores nuls sont retournées.
Si vous spécifiez moins de colonnes de résultats qu’il n’y a de colonnes de caractéristiques, les caractéristiques sont classées par ordre décroissant de leur score. Seules les caractéristiques principales sont retournées.
Envoyez le pipeline.
Important
Si vous envisagez d’utiliser Sélection de caractéristiques par filtrage dans l’inférence, vous devez utiliser Transformation d’une sélection de colonnes pour stocker le résultat sélectionné de la fonctionnalité et Appliquer une transformation pour appliquer la transformation sélectionnée de la fonctionnalité au jeu de données de scoring.
Reportez-vous à la capture d’écran suivante pour créer votre pipeline, afin de vous assurer que les sélections de colonnes sont les mêmes pour le processus de scoring.
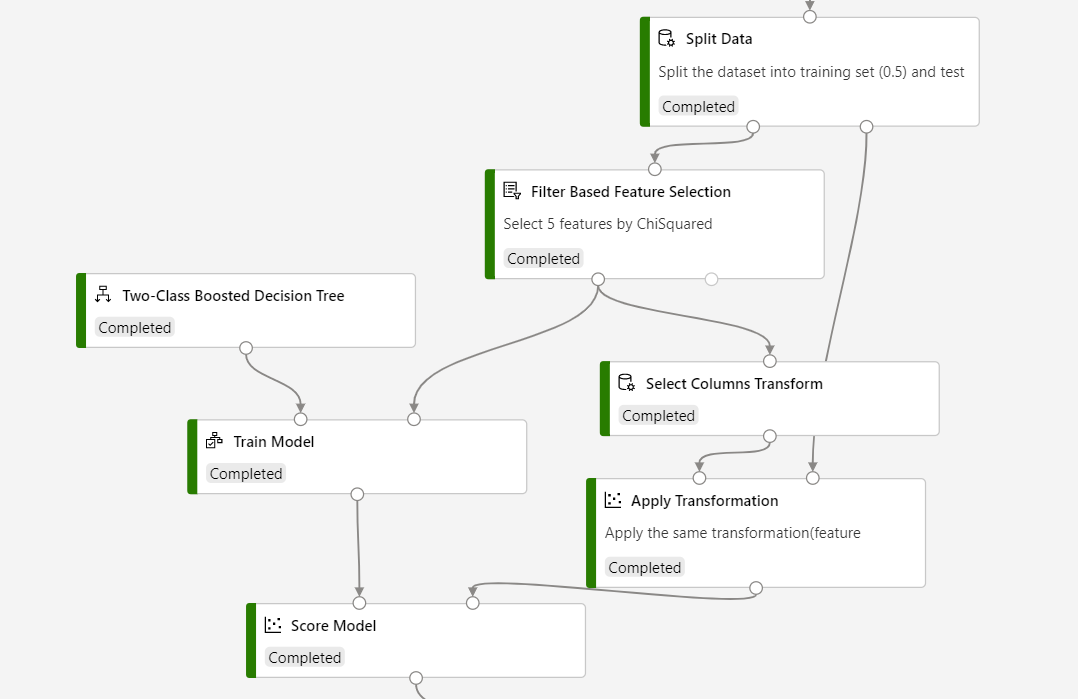
Résultats
Une fois le processus terminé :
Pour afficher la liste complète des colonnes de caractéristiques analysées ainsi que leurs scores, cliquez avec le bouton droit sur le composant, puis sélectionnez Visualiser.
Pour afficher le jeu de données basé sur vos critères de sélection de caractéristiques, cliquez avec le bouton droit sur le composant, puis sélectionnez Visualiser.
Si le jeu de données contient moins de colonnes que prévu, vérifiez les paramètres du composant. Vérifiez également les types de données des colonnes fournies comme entrées. Par exemple, si vous avez indiqué 1 dans Number of desired features (Nombre de caractéristiques souhaité), le jeu de données de sortie contient seulement deux colonnes : la colonne Étiquette et la colonne de type Caractéristique la mieux classée.
Notes techniques
Informations d’implémentation
Si vous utilisez la corrélation de Pearson sur une caractéristique numérique et une étiquette de catégorie, le score de caractéristique est calculé comme suit :
Pour chaque niveau de la colonne de type Catégorie, calculez la moyenne conditionnelle de la colonne numérique.
Mettez en corrélation la colonne des moyennes conditionnelles avec la colonne numérique.
Spécifications
Il est impossible de générer un score de sélection de caractéristiques pour une colonne désignée comme colonne d’étiquette ou de score.
Si vous essayez d’utiliser une méthode de scoring avec une colonne d’un type de données que la méthode ne prend pas en charge, le composant génère une erreur. Ou, un score nul est affecté à la colonne.
Si une colonne contient des valeurs logiques (true/false), celles-ci sont traitées comme suit :
True = 1etFalse = 0.Une colonne ne peut pas être une caractéristique si elle a été désignée comme colonne d’étiquette ou de score.
Gestion des valeurs manquantes
Vous ne pouvez pas spécifier comme colonne cible (étiquette) une colonne dont toutes les valeurs sont manquantes.
Si une colonne contient des valeurs manquantes, le composant les ignore lors du calcul du score de la colonne.
Si une colonne désignée comme colonne de caractéristique ne contient que des valeurs manquantes, le composant lui affecte un score nul.
Étapes suivantes
Consultez les composants disponibles pour Azure Machine Learning.