Effectuer l’apprentissage d’un modèle de régression avec AutoML et Python (SDK v1)
S’APPLIQUE À : Kit de développement logiciel (SDK) Python azureml v1
Kit de développement logiciel (SDK) Python azureml v1
Dans cet article, vous allez découvrir comment effectuer l’apprentissage d’un modèle de régression à l’aide du kit SDK Python Azure Machine Learning avec ML automatisé d’Azure Machine Learning. Ce modèle de régression prédit les tarifs des taxis de New York.
Ce processus accepte les données d'apprentissage et les paramètres de configuration, et itère automatiquement via des combinaisons de méthodes et de modèles de normalisation/standardisation de fonctionnalités et des paramètres hyperparamètres afin d'obtenir le meilleur modèle.

Vous écrivez du code en utilisant le SDK Python dans cet article. Vous allez apprendre à effectuer les tâches suivantes :
- Télécharger, transformer et nettoyer des données avec Azure Open Datasets
- Effectuer l'apprentissage d'un modèle de régression Machine Learning automatisé
- Calculer la précision du modèle
Pour AutoML sans code, consultez les tutoriels suivants :
Tutoriel : effectuer l’apprentissage des modèles de classification sans code
Tutoriel : Prévoir la demande avec le Machine Learning automatisé
Prérequis
Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer. Essayez la version gratuite ou payante d’Azure Machine Learning dès aujourd’hui.
- Suivez le guide Démarrage rapide : Bien démarrer avec Azure Machine Learning, si vous ne disposez pas déjà d’un espace de travail Azure Machine Learning ou d’une instance de calcul.
- Après avoir suivi le guide de démarrage rapide :
- Sélectionnez Notebooks dans le studio.
- Sélectionnez l’onglet Exemples.
- Ouvrez le notebook SDK v1/tutorials/regression-automl-nyc-taxi-data/regression-automated-ml.ipynb.
- Pour exécuter chaque cellule du tutoriel, sélectionnez Cloner ce notebook.
Vous trouverez également cet article sur GitHub si vous souhaitez l’exécuter dans votre propre environnement local. Pour vous procurer les packages requis :
- Installez le client
automlcomplet. - Exécutez
pip install azureml-opendatasets azureml-widgetspour vous procurer les packages requis.
Télécharger et préparer les données
Importez les packages nécessaires. Le package Open Datasets contient une classe représentant chaque source de données (NycTlcGreen, par exemple) afin de facilement filtrer les paramètres de date avant le téléchargement.
from azureml.opendatasets import NycTlcGreen
import pandas as pd
from datetime import datetime
from dateutil.relativedelta import relativedelta
Commencez par créer un dataframe pour contenir les données des taxis. Quand vous travaillez dans un environnement autre que Spark, Open Datasets permet de télécharger un seul mois de données à la fois avec certaines classes, afin d’éviter MemoryError avec les grands jeux de données.
Pour charger les données de taxi, extrayez de façon itérative un mois à la fois et, avant de l’ajouter à green_taxi_df, échantillonnez de manière aléatoire 2 000 enregistrements de chaque mois pour éviter d’encombrer le dataframe. Prévisualisez ensuite les données.
green_taxi_df = pd.DataFrame([])
start = datetime.strptime("1/1/2015","%m/%d/%Y")
end = datetime.strptime("1/31/2015","%m/%d/%Y")
for sample_month in range(12):
temp_df_green = NycTlcGreen(start + relativedelta(months=sample_month), end + relativedelta(months=sample_month)) \
.to_pandas_dataframe()
green_taxi_df = green_taxi_df.append(temp_df_green.sample(2000))
green_taxi_df.head(10)
| vendorID | lpepPickupDatetime | lpepDropoffDatetime | passengerCount | tripDistance | puLocationId | doLocationId | pickupLongitude | pickupLatitude | dropoffLongitude | ... | paymentType | fareAmount | extra | mtaTax | improvementSurcharge | tipAmount | tollsAmount | ehailFee | totalAmount | tripType |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 131969 | 2 | 2015-01-11 05:34:44 | 2015-01-11 05:45:03 | 3 | 4,84 | None | None | -73,88 | 40,84 | -73,94 | ... | 2 | 15,00 | 0.50 | 0.50 | 0.3 | 0,00 | 0,00 | NaN | 16,30 |
| 1129817 | 2 | 2015-01-20 16:26:29 | 2015-01-20 16:30:26 | 1 | 0,69 | None | None | -73,96 | 40,81 | -73,96 | ... | 2 | 4.50 | 1.00 | 0.50 | 0.3 | 0,00 | 0,00 | NaN | 6,30 |
| 1278620 | 2 | 2015-01-01 05:58:10 | 2015-01-01 06:00:55 | 1 | 0,45 | None | None | -73,92 | 40,76 | -73,91 | ... | 2 | 4,00 | 0,00 | 0.50 | 0.3 | 0,00 | 0,00 | NaN | 4,80 |
| 348430 | 2 | 2015-01-17 02:20:50 | 2015-01-17 02:41:38 | 1 | 0,00 | None | None | -73,81 | 40,70 | -73,82 | ... | 2 | 12,50 | 0.50 | 0.50 | 0.3 | 0,00 | 0,00 | NaN | 13,80 |
| 1269627 | 1 | 2015-01-01 05:04:10 | 2015-01-01 05:06:23 | 1 | 0.50 | None | None | -73,92 | 40,76 | -73,92 | ... | 2 | 4,00 | 0.50 | 0.50 | 0 | 0,00 | 0,00 | NaN | 5.00 |
| 811755 | 1 | 2015-01-04 19:57:51 | 2015-01-04 20:05:45 | 2 | 1,10 | None | None | -73,96 | 40,72 | -73,95 | ... | 2 | 6,50 | 0.50 | 0.50 | 0.3 | 0,00 | 0,00 | NaN | 7,80 |
| 737281 | 1 | 2015-01-03 12:27:31 | 2015-01-03 12:33:52 | 1 | 0,90 | None | None | -73,88 | 40,76 | -73,87 | ... | 2 | 6,00 | 0,00 | 0.50 | 0.3 | 0,00 | 0,00 | NaN | 6,80 |
| 113951 | 1 | 2015-01-09 23:25:51 | 2015-01-09 23:39:52 | 1 | 3,30 | None | None | -73,96 | 40,72 | -73,91 | ... | 2 | 12,50 | 0.50 | 0.50 | 0.3 | 0,00 | 0,00 | NaN | 13,80 |
| 150436 | 2 | 2015-01-11 17:15:14 | 2015-01-11 17:22:57 | 1 | 1,19 | None | None | -73,94 | 40,71 | -73,95 | ... | 1 | 7,00 | 0,00 | 0.50 | 0.3 | 1,75 | 0,00 | NaN | 9,55 |
| 432136 | 2 | 2015-01-22 23:16:33 2015-01-22 23:20:13 1 0.65 | None | None | -73,94 | 40,71 | -73,94 | ... | 2 | 5.00 | 0.50 | 0.50 | 0.3 | 0,00 | 0,00 | NaN | 6,30 |
Supprimez certaines colonnes dont vous n’avez pas besoin pour l’entraînement ou la création de caractéristiques supplémentaires. Le Machine Learning automatisé gérera automatiquement les fonctionnalités basées sur le temps, telles que lpepPickupDatetime.
columns_to_remove = ["lpepDropoffDatetime", "puLocationId", "doLocationId", "extra", "mtaTax",
"improvementSurcharge", "tollsAmount", "ehailFee", "tripType", "rateCodeID",
"storeAndFwdFlag", "paymentType", "fareAmount", "tipAmount"
]
for col in columns_to_remove:
green_taxi_df.pop(col)
green_taxi_df.head(5)
Nettoyer les données
Exécutez la fonction describe() sur le nouveau dataframe pour afficher un résumé des statistiques de chaque champ.
green_taxi_df.describe()
| vendorID | passengerCount | tripDistance | pickupLongitude | pickupLatitude | dropoffLongitude | dropoffLatitude | totalAmount | month_num day_of_month | day_of_week | hour_of_day |
|---|---|---|---|---|---|---|---|---|---|---|
| count | 48000,00 | 48000,00 | 48000,00 | 48000,00 | 48000,00 | 48000,00 | 48000,00 | 48000,00 | 48000,00 | 48000,00 |
| mean | 1.78 | 1,37 | 2.87 | -73,83 | 40,69 | -73,84 | 40,70 | 14,75 | 6,50 | 15,13 |
| std | 0.41 | 1.04 | 2,93 | 2.76 | 1,52 | 2.61 | 1,44 | 12,08 | 3.45 | 8,45 |
| min | 1.00 | 0,00 | 0,00 | -74,66 | 0,00 | -74,66 | 0,00 | -300,00 | 1.00 | 1.00 |
| 25 % | 2,00 | 1.00 | 1,06 | -73,96 | 40,70 | -73,97 | 40,70 | 7,80 | 3,75 | 8,00 |
| 50% | 2,00 | 1.00 | 1,90 | -73,94 | 40,75 | -73,94 | 40,75 | 11,30 | 6,50 | 15,00 |
| 75 % | 2,00 | 1.00 | 3.60 | -73,92 | 40,80 | -73,91 | 40,79 | 17,80 | 9.25 | 22,00 |
| max | 2,00 | 9,00 | 97,57 | 0,00 | 41,93 | 0,00 | 41,94 | 450,00 | 12,00 | 30.00 |
À partir des statistiques récapitulatives, vous constatez que plusieurs champs ont des valeurs hors norme ou des valeurs qui réduisent l’exactitude du modèle. Tout d’abord, filtrez les champs lat/long pour qu’ils figurent dans les limites de la zone Manhattan. Cela masque les courses de taxi plus longues ou les trajets hors norme par rapport à leur relation avec les autres caractéristiques.
Filtrez aussi le champ tripDistance pour qu’il soit supérieur à zéro, mais inférieur à 31 kilomètres (distance Haversine entre les deux paires de latitude/longitude). Cela élimine les longs trajets hors norme qui présentent un coût de trajet inégal.
Enfin, le champ totalAmount contient des valeurs négatives pour les tarifs des taxis, ce qui n’est pas pertinent dans le contexte de notre modèle, et le champ passengerCount contient des données incorrectes avec des valeurs minimales égales à zéro.
Excluez ces anomalies à l'aide des fonctions de requête, puis supprimez les dernières colonnes inutiles à des fins de formation.
final_df = green_taxi_df.query("pickupLatitude>=40.53 and pickupLatitude<=40.88")
final_df = final_df.query("pickupLongitude>=-74.09 and pickupLongitude<=-73.72")
final_df = final_df.query("tripDistance>=0.25 and tripDistance<31")
final_df = final_df.query("passengerCount>0 and totalAmount>0")
columns_to_remove_for_training = ["pickupLongitude", "pickupLatitude", "dropoffLongitude", "dropoffLatitude"]
for col in columns_to_remove_for_training:
final_df.pop(col)
Appelez une nouvelle fois describe() sur les données pour vérifier que le nettoyage a bien fonctionné. Vous disposez maintenant d’un jeu préparé et nettoyé de données de taxis, congés et météorologiques à des fins d'apprentissage du modèle de Machine Learning.
final_df.describe()
Configurer l’espace de travail
Créez un objet d’espace de travail à partir de l’espace de travail existant. Un espace de travail est une classe qui accepte les informations concernant vos abonnements et vos ressources Azure. Il crée également une ressource cloud pour superviser et suivre les exécutions de votre modèle. Workspace.from_config() lit le fichier config.json et charge les détails d’authentification dans un objet nommé ws. ws est utilisé dans tout le reste du code de cet article.
from azureml.core.workspace import Workspace
ws = Workspace.from_config()
Diviser les données entre un jeu d’entraînement et un jeu de test
Divisez les données en jeu d’entraînement et en jeu de test à l’aide de la fonction train_test_split de la bibliothèque scikit-learn. Cette fonction sépare les données entre le jeu de données x (caractéristiques) pour l’entraînement du modèle, et le jeu de données y (valeurs à prédire) pour les tests.
Le paramètre test_size détermine le pourcentage de données à allouer pour les tests. Le paramètre random_state définit une valeur initiale pour le générateur aléatoire, afin que les deux jeux de données soient déterministes.
from sklearn.model_selection import train_test_split
x_train, x_test = train_test_split(final_df, test_size=0.2, random_state=223)
L’objectif de cette étape est d’obtenir des points de données qui n’ont pas été utilisés pour entraîner le modèle, afin de mesurer la véritable précision en testant le modèle terminé.
En d’autres termes, un modèle bien entraîné doit être en mesure d’établir avec précision des prédictions à partir de données qu’il n’a pas encore vues. Vous disposez maintenant de données préparées pour l’entraînement automatique d’un modèle Machine Learning.
Entraîner automatiquement un modèle
Pour entraîner automatiquement un modèle, effectuez les étapes suivantes :
- Définissez des paramètres pour l’exécution de l’expérience. Attachez vos données d’entraînement à la configuration et modifiez les paramètres qui contrôlent le processus d’entraînement.
- Soumettez l’expérience pour l’optimisation du modèle. Une fois l’expérience envoyée, le processus itère dans différents algorithmes et paramètres hyperparamètres de Machine Learning tout en respectant vos contraintes définies. Il choisit le modèle le mieux adapté en optimisant une métrique de précision.
Définir les paramètres d’entraînement
Définissez les paramètres du modèle et de l’expérience pour l’entraînement. Affichez la liste complète des paramètres. L’envoi de l’expérience avec ces paramètres par défaut peut prendre entre 5 et 20 min, mais si vous voulez raccourcir la durée d’exécution, diminuez le paramètre experiment_timeout_hours.
| Propriété | Valeur de cet article | Description |
|---|---|---|
| iteration_timeout_minutes | 10 | Limite de temps (en minutes) pour chaque itération. Augmentez cette valeur pour les jeux de données plus volumineux qui ont besoin de plus de temps pour chaque itération. |
| experiment_timeout_hours | 0.3 | Durée maximale en heures pendant laquelle toutes les itérations combinées peuvent être effectuées avant que l’expérience ne se termine. |
| enable_early_stopping | True | Indicateur activant la fin anticipée si le score ne s’améliore pas à court-terme. |
| primary_metric | spearman_correlation | Métrique que vous souhaitez optimiser. Le modèle le mieux adapté est choisi en fonction de cette métrique. |
| featurization | auto | En utilisant auto, l’expérience peut traiter les données d’entrée au préalable (gestion des données manquantes, conversion du texte en caractères numériques, etc.) |
| verbosity | logging.INFO | Contrôle le niveau de journalisation. |
| n_cross_validations | 5 | Nombre de divisions de validation croisée à effectuer quand les données de validation ne sont pas spécifiées. |
import logging
automl_settings = {
"iteration_timeout_minutes": 10,
"experiment_timeout_hours": 0.3,
"enable_early_stopping": True,
"primary_metric": 'spearman_correlation',
"featurization": 'auto',
"verbosity": logging.INFO,
"n_cross_validations": 5
}
Utilisez vos paramètres d’entraînement définis en tant que paramètre **kwargs sur un objet AutoMLConfig. De plus, spécifiez vos données d’entraînement et le type de modèle, c’est-à-dire regression dans ce cas.
from azureml.train.automl import AutoMLConfig
automl_config = AutoMLConfig(task='regression',
debug_log='automated_ml_errors.log',
training_data=x_train,
label_column_name="totalAmount",
**automl_settings)
Notes
Les étapes de prétraitement du Machine Learning automatisé (normalisation des fonctionnalités, gestion des données manquantes, conversion de texte en valeurs numériques, etc.) font partie du modèle sous-jacent. Lorsque vous utilisez le modèle pour des prédictions, les étapes de prétraitement qui sont appliquées pendant l’entraînement sont appliquées automatiquement à vos données d’entrée.
Entraîner le modèle de régression automatique
Créez un objet d’expérience dans votre espace de travail. Une expérience fait office de conteneur pour vos travaux individuels. Transmettez l’objet automl_config défini à l’expérience et définissez la sortie sur True pour suivre la progression du travail.
Une fois l’expérience démarrée, la sortie illustrée est mise à jour en temps réel à mesure que l’expérience s’exécute. Pour chaque itération, vous voyez le type de modèle, la durée d’exécution et la précision de l’entraînement. Le champ BEST effectue un suivi du meilleur score d’entraînement en cours d’exécution, en fonction de votre type de métrique.
from azureml.core.experiment import Experiment
experiment = Experiment(ws, "Tutorial-NYCTaxi")
local_run = experiment.submit(automl_config, show_output=True)
Running on local machine
Parent Run ID: AutoML_1766cdf7-56cf-4b28-a340-c4aeee15b12b
Current status: DatasetFeaturization. Beginning to featurize the dataset.
Current status: DatasetEvaluation. Gathering dataset statistics.
Current status: FeaturesGeneration. Generating features for the dataset.
Current status: DatasetFeaturizationCompleted. Completed featurizing the dataset.
Current status: DatasetCrossValidationSplit. Generating individually featurized CV splits.
Current status: ModelSelection. Beginning model selection.
****************************************************************************************************
ITERATION: The iteration being evaluated.
PIPELINE: A summary description of the pipeline being evaluated.
DURATION: Time taken for the current iteration.
METRIC: The result of computing score on the fitted pipeline.
BEST: The best observed score thus far.
****************************************************************************************************
ITERATION PIPELINE DURATION METRIC BEST
0 StandardScalerWrapper RandomForest 0:00:16 0.8746 0.8746
1 MinMaxScaler RandomForest 0:00:15 0.9468 0.9468
2 StandardScalerWrapper ExtremeRandomTrees 0:00:09 0.9303 0.9468
3 StandardScalerWrapper LightGBM 0:00:10 0.9424 0.9468
4 RobustScaler DecisionTree 0:00:09 0.9449 0.9468
5 StandardScalerWrapper LassoLars 0:00:09 0.9440 0.9468
6 StandardScalerWrapper LightGBM 0:00:10 0.9282 0.9468
7 StandardScalerWrapper RandomForest 0:00:12 0.8946 0.9468
8 StandardScalerWrapper LassoLars 0:00:16 0.9439 0.9468
9 MinMaxScaler ExtremeRandomTrees 0:00:35 0.9199 0.9468
10 RobustScaler ExtremeRandomTrees 0:00:19 0.9411 0.9468
11 StandardScalerWrapper ExtremeRandomTrees 0:00:13 0.9077 0.9468
12 StandardScalerWrapper LassoLars 0:00:15 0.9433 0.9468
13 MinMaxScaler ExtremeRandomTrees 0:00:14 0.9186 0.9468
14 RobustScaler RandomForest 0:00:10 0.8810 0.9468
15 StandardScalerWrapper LassoLars 0:00:55 0.9433 0.9468
16 StandardScalerWrapper ExtremeRandomTrees 0:00:13 0.9026 0.9468
17 StandardScalerWrapper RandomForest 0:00:13 0.9140 0.9468
18 VotingEnsemble 0:00:23 0.9471 0.9471
19 StackEnsemble 0:00:27 0.9463 0.9471
Lire les résultats
Explorez les résultats de l’entraînement automatique à l’aide d’un widget Jupyter. Le widget vous permet d’afficher un graphique et un tableau de toutes les itérations de travaux individuels, ainsi que des métriques et des métadonnées sur la précision de l’apprentissage. Vous pouvez aussi filtrer sur des métriques de précision différentes de votre métrique principale avec le sélecteur de liste déroulante.
from azureml.widgets import RunDetails
RunDetails(local_run).show()
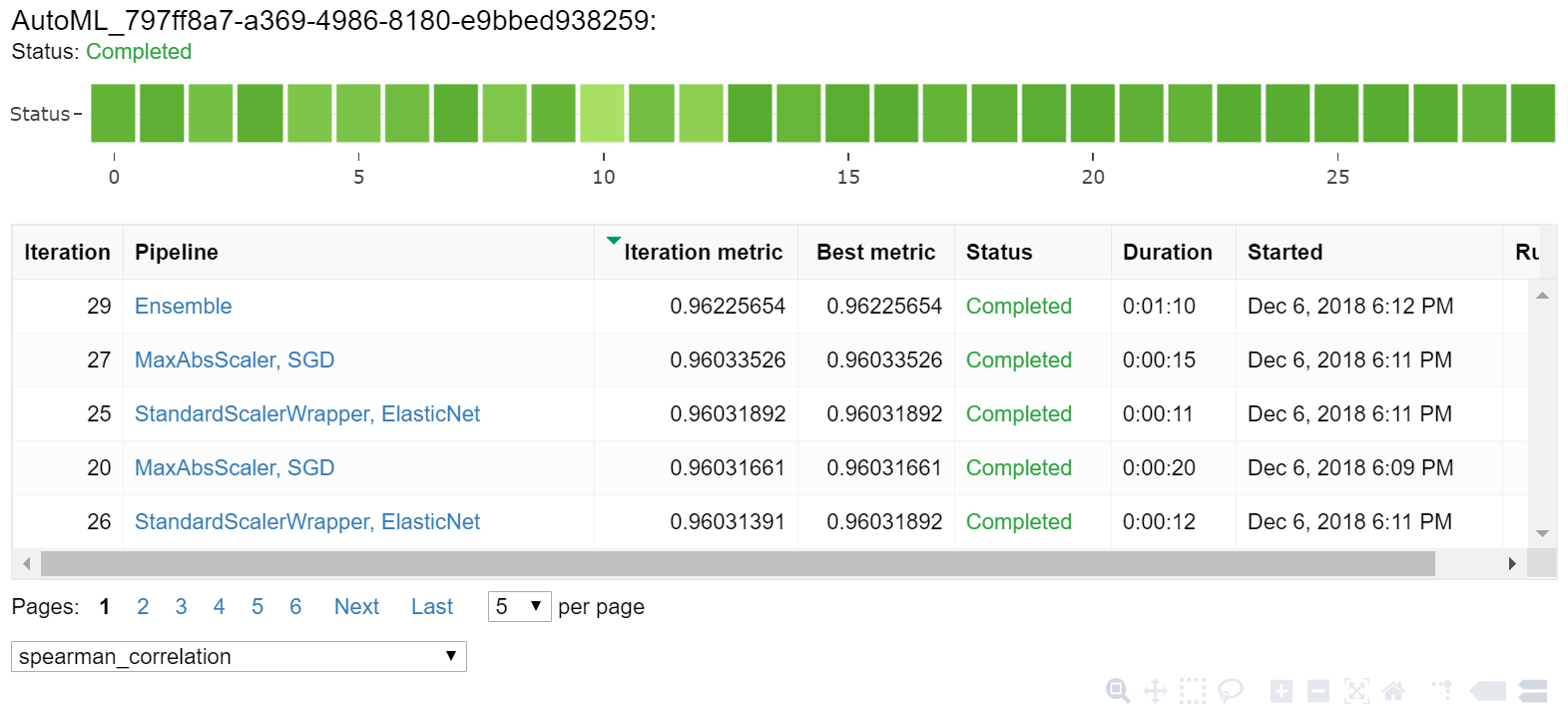
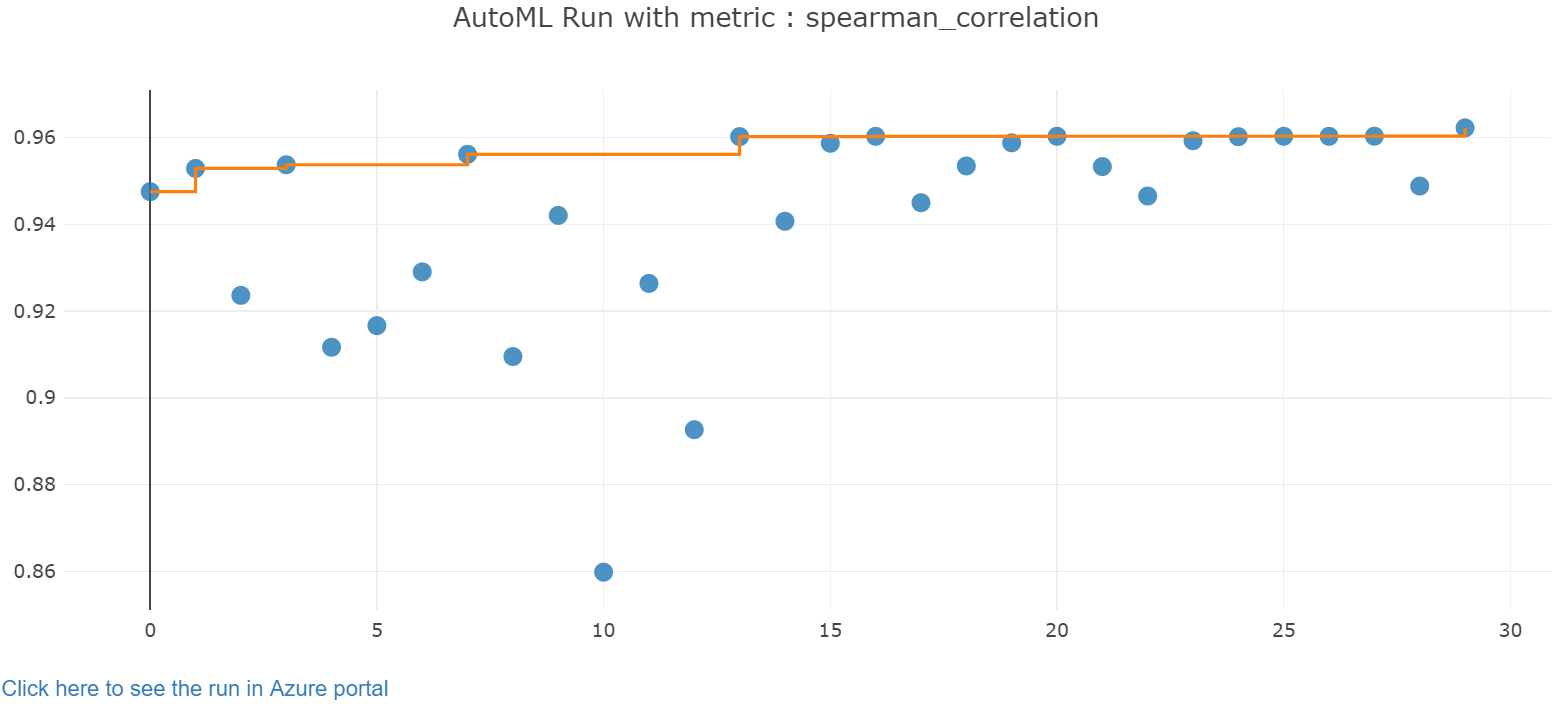
Récupérer le meilleur modèle
Sélectionnez le meilleur modèle dans vos itérations. La fonction get_output retourne la meilleure exécution ainsi que le modèle ajusté pour le dernier appel d’ajustement. En utilisant des surcharges sur get_output, vous pouvez récupérer la meilleure exécution et le modèle ajusté pour toute métrique consignée ou itération.
best_run, fitted_model = local_run.get_output()
print(best_run)
print(fitted_model)
Tester la précision du meilleur modèle
Utilisez le meilleur modèle pour exécuter des prédictions sur le jeu de données de test et prédire les tarifs des courses de taxi. La fonction predict utilise le meilleur modèle et prédit les valeurs de y, coût du trajet, à partir du jeu de données x_test. Affichez les 10 premières valeurs de coût à partir de y_predict.
y_test = x_test.pop("totalAmount")
y_predict = fitted_model.predict(x_test)
print(y_predict[:10])
Calculez le(la) root mean squared error des résultats. Convertissez le dataframe y_test en liste à comparer aux valeurs prédites. La fonction mean_squared_error accepte deux tableaux de valeurs et calcule l’erreur au carré moyenne entre ces tableaux. En prenant la racine carrée du résultat, vous obtenez une erreur dans les mêmes unités que la variable y, cost. Elle indique l’écart approximatif entre les prédictions de tarifs de taxi et les tarifs réels.
from sklearn.metrics import mean_squared_error
from math import sqrt
y_actual = y_test.values.flatten().tolist()
rmse = sqrt(mean_squared_error(y_actual, y_predict))
rmse
Exécutez le code suivant pour calculer le pourcentage d’erreur absolue moyenne (MAPE) à l’aide des jeux de données y_actual et y_predict complets. Cette métrique calcule une différence absolue entre chaque valeur prédite et réelle et additionne toutes les différences. Ensuite, elle exprime cette somme sous forme de pourcentage du total des valeurs réelles.
sum_actuals = sum_errors = 0
for actual_val, predict_val in zip(y_actual, y_predict):
abs_error = actual_val - predict_val
if abs_error < 0:
abs_error = abs_error * -1
sum_errors = sum_errors + abs_error
sum_actuals = sum_actuals + actual_val
mean_abs_percent_error = sum_errors / sum_actuals
print("Model MAPE:")
print(mean_abs_percent_error)
print()
print("Model Accuracy:")
print(1 - mean_abs_percent_error)
Model MAPE:
0.14353867606052823
Model Accuracy:
0.8564613239394718
Les deux métriques de précision de la prédiction montrent que le modèle est assez bon pour prédire les tarifs de taxi à partir des caractéristiques du jeu de données, en général à ± 4,00 dollars US et environ 15 % d’erreur.
Le processus traditionnel de développement des modèles d’entraînement est très gourmand en ressources, et nécessite des investissements importants en temps et en connaissances pour exécuter et comparer les résultats de dizaines de modèles. Le machine learning automatisé se révèle un excellent moyen de tester rapidement de nombreux modèles pour votre scénario.
Nettoyer les ressources
Sautez cette section si vous prévoyez d’exécuter d’autres tutoriels Azure Machine Learning.
Arrêter l’instance de calcul
Si vous avez utilisé une instance de calcul, arrêtez la machine virtuelle quand vous ne l’utilisez pas afin de réduire les coûts.
Dans votre espace de travail, sélectionnez Capacité de calcul.
Dans la liste, sélectionnez le nom de l’instance de calcul.
Sélectionnez Arrêter.
Quand vous êtes prêt à utiliser à nouveau le serveur, sélectionnez Démarrer.
Tout supprimer
Si vous n’avez pas l’intention d’utiliser les ressources que vous avez créées, supprimez-les pour éviter des frais.
- Dans le portail Azure, sélectionnez Groupes de ressources tout à gauche.
- À partir de la liste, sélectionnez le groupe de ressources créé.
- Sélectionnez Supprimer le groupe de ressources.
- Entrez le nom du groupe de ressources. Puis sélectionnez Supprimer.
Vous pouvez également conserver le groupe de ressources mais supprimer un espace de travail unique. Affichez les propriétés de l’espace de travail, puis sélectionnez Supprimer.
Étapes suivantes
Dans cet article sur le machine learning automatisé, vous avez effectué les tâches suivantes :
- Configuration d’un espace de travail et préparation des données pour une expérience
- Entraînement à l’aide d’un modèle de régression automatisé local avec des paramètres personnalisés
- Exploration et analyse des résultats de l’entraînement
Configurer AutoML pour entraîner des modèles de vision par ordinateur avec Python (v1)