Surveillance et diagnostics pour Azure Service Fabric
Cet article fournit une vue d’ensemble du monitoring et des diagnostics dans Azure Service Fabric. Le monitoring et les diagnostics sont essentiels au développement, au test et au déploiement de charges de travail dans tout environnement cloud. Par exemple, vous pouvez suivre la façon dont vos applications sont utilisées, les actions effectuées par la plateforme Service Fabric, votre utilisation des ressources avec des compteurs de performances et l’intégrité globale de votre cluster. Vous pouvez utiliser ces informations pour diagnostiquer et corriger les problèmes, et éviter qu’ils ne se reproduisent. Les sections suivantes décrivent brièvement chaque zone de la supervision de Service Fabric à prendre en compte pour les charges de travail de production.
Notes
Cet article a récemment été mis à jour pour utiliser le terme journaux d’activité Azure Monitor au lieu de Log Analytics. Les données de journal sont toujours stockées dans un espace de travail Log Analytics, et elles sont toujours collectées et analysées par le même service Log Analytics. Nous mettons la terminologie à jour pour mieux refléter le rôle des journaux d’activité dans Azure Monitor. Pour plus d'informations, consultez Modifications de la terminologie d'Azure Monitor.
Monitoring des applications
Le monitoring des applications permet de suivre l’utilisation des fonctionnalités et des composants de votre application. L’objectif est d’intercepter les problèmes qui impactent les utilisateurs. La responsabilité de la supervision des applications revient aux utilisateurs qui développent une application et ses services dans la mesure où il est unique à la logique métier de l’application. Le monitoring des applications peut être utile dans les scénarios suivants :
- Quel est le trafic que rencontre mon application ? - Devez-vous mettre à l’échelle vos services pour répondre aux demandes des utilisateurs ou traiter un goulot d’étranglement potentiel dans votre application ?
- Mes appels de service à service réussissent-ils et font-ils l’objet d’un suivi ?
- Quelles actions sont prises par les utilisateurs de mon application ? - La collecte de données de télémétrie peut guider le développement de nouvelles fonctionnalités et améliorer les diagnostics des erreurs d’application
- Mon application lève-t-elle des exceptions non gérées ?
- Que se passe-t-il dans les services qui s’exécutent au sein de mes conteneurs ?
L’avantage de la supervision des applications est que les développeurs peuvent utiliser les outils et le framework qu’ils souhaitent dans la mesure où il réside dans le contexte de votre application. Vous pouvez en apprendre plus sur la solution Azure pour la supervision des applications avec Azure Monitor – Application Insights dans Analyse d’événements avec Application Insights. Nous disposons également d’un tutoriel qui explique comment configurer ceci pour les applications .NET. Ce tutoriel aborde la façon d’installer les outils appropriés, un exemple pour écrire des données de télémétrie personnalisées dans votre application, et l’affichage des données de télémétrie et de diagnostic de l’application dans le portail Azure.
Monitoring de la plateforme (cluster)
Un utilisateur contrôle les données de télémétrie qui proviennent de l’application dans la mesure où un utilisateur écrit le code lui-même, mais qu’en est-il du diagnostic provenant de la plateforme Service Fabric ? L’un des objectifs de Service Fabric est d’assurer le bon fonctionnement des applications même en cas de défaillances matérielles. Cet objectif repose sur la capacité des services système de la plateforme à détecter les problèmes d’infrastructure et à basculer rapidement les charges de travail sur d’autres nœuds du cluster. Mais dans ce cas précis, que se passe-t-il si les services système subissent eux aussi des problèmes ? Que se passe-t-il si, durant une tentative de déploiement ou de déplacement d’une charge de travail, les règles de placement des services sont enfreintes ? Service Fabric fournit des diagnostics pour cela et pour vous garantir d’être informé de l’activité en cours dans votre cluster. Voici quelques exemples de scénarios pour la surveillance du cluster :
Service Fabric fournit un ensemble complet d’événements prêts à l’emploi. Ces événements Service Fabric sont accessibles via EventStore ou le canal opérationnel (canal d’événements exposé par la plateforme).
Canaux d’événements Service Fabric : sur Windows, les événements Service Fabric sont disponibles à partir d’un seul fournisseur ETW avec un ensemble de filtres
logLevelKeywordFilterspertinents permettant de choisir entre le canal opérationnel et le canal de données et de messagerie. Il s’agit de la méthode à l’aide de laquelle nous séparons des événements Service Fabric sortants à filtrer en fonction de vos besoins. Sur Linux, les événements Service Fabric transitent par LTTng et sont placés dans une table de stockage où ils peuvent être filtrés selon les besoins. Ces canaux contiennent des événements organisés et structurés que vous pouvez utiliser pour mieux comprendre l’état de votre cluster. Les diagnostics sont activés par défaut au moment de la création du cluster. Vous disposez ainsi d’une table Stockage Azure où sont envoyés les événements de ces canaux que vous pourrez interroger ultérieurement.EventStore - EventStore est une fonctionnalité offerte par la plateforme qui fournit les événements de la plateforme Service Fabric disponibles dans Service Fabric Explorer et via l’API REST. Vous pouvez obtenir une vue de capture de ce qui se passe dans votre cluster pour chaque entité (nœud, service, application et requête) basée sur l’heure de l’événement. Pour plus d’informations sur EventStore, consultez Vue d’ensemble d’EventStore.

Les diagnostics fournis sont sous la forme d’un ensemble complet d’événements prêts à l’emploi. Ces événements Service Fabric illustrent les actions effectuées par la plateforme sur différentes entités telles que les nœuds, les applications, les services, les partitions, etc. Dans le dernier scénario ci-dessus, si un nœud venait à tomber en panne, la plateforme émettrait un événement NodeDown et vous pourriez être informé immédiatement par votre outil de supervision préféré. D’autres exemples courants incluent ApplicationUpgradeRollbackStarted ou PartitionReconfigured lors d’un basculement. Les mêmes événements sont disponibles sur les clusters Windows et Linux.
Les événements sont envoyés par le biais des canaux standard sur Windows et Linux, et peuvent être lus par n’importe quel outil de supervision qui les prend en charge. La solution Azure Monitor correspond aux journaux Azure Monitor. Renseignez-vous sur notre intégration des journaux Azure Monitor, qui comporte un tableau de bord opérationnel personnalisé pour votre cluster et quelques exemples de requêtes permettant de créer des alertes. D’autres concepts de supervision de cluster sont disponibles dans Événement au niveau de la plateforme et génération de journal.
Surveillance de l’intégrité
La plateforme Service Fabric inclut un modèle d’intégrité qui fournit des rapports d’intégrité extensibles sur l’état des entités dans un cluster. Chaque nœud, application, service, partition, réplica ou instance a un état d’intégrité qui est mis à jour en permanence. L’état d’intégrité peut avoir la valeur « OK », « Avertissement » ou « Erreur ». Considérez les événements Service Fabric comme des verbes appliqués par le cluster aux diverses entités et l’intégrité comme un adjectif pour chaque entité. Chaque fois que l’intégrité d’une entité particulière change, un événement est également émis. De cette façon, vous pouvez définir des requêtes et des alertes pour les événements d’intégrité dans votre outil de supervision préféré, tout comme pour n’importe quel autre événement.
De plus, nous laissons même les utilisateurs remplacer l’intégrité des entités. Si votre application est en cours de mise à niveau et que des tests de validation échouent, vous pouvez écrire dans le composant d’intégrité de Service Fabric à l’aide de l’API Intégrité pour indiquer que votre application n’est plus intègre, et Service Fabric restaurera automatiquement la mise à niveau. Pour plus d’informations sur le modèle d’intégrité, consultez Présentation du contrôle d’intégrité de Service Fabric.
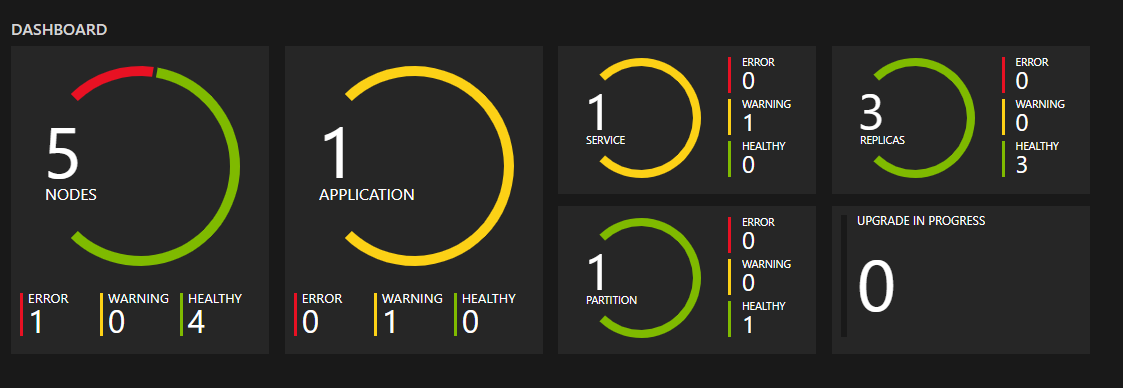
Agents de surveillance
En général, un agent de surveillance est un service distinct capable de surveiller l’intégrité et la charge des services, d’effectuer des tests ping sur les points de terminaison et de créer des rapports à partir des événements non sains du cluster. Cela vous permet de détecter plus facilement les erreurs que vous n’auriez pas pu détecter en vous basant uniquement sur les performances d’un seul service. Les agents de surveillance constituent également un bon emplacement pour héberger du code qui exécute des actions correctives sans intervention de l’utilisateur (par exemple, le nettoyage de fichiers journaux dans le stockage à intervalles réguliers). Si vous souhaitez un service de surveillance SF open source entièrement implémenté qui comprend un modèle d’extensibilité de surveillance facile à utiliser et qui s’exécute dans les clusters Windows et Linux, consultez le projet FabricObserver. FabricObserver est un logiciel prêt pour la production. Nous vous encourageons à déployer FabricObserver sur vos clusters de test et de production et à l’étendre pour répondre à vos besoins par le biais de son modèle de plug-in ou en le dupliquant et en écrivant vos propres observateurs intégrés. Ce dernier (plug-in) est l’approche recommandée.
Supervision de l’infrastructure (performances)
Maintenant que nous avons couvert les diagnostics dans votre application et sur la plateforme, comment savons-nous que le matériel fonctionne comme prévu ? Le monitoring de l’infrastructure sous-jacente est essentiel pour comprendre l’état de votre cluster et l’utilisation de vos ressources. La mesure des performances système dépend de nombreux facteurs qui peuvent être subjectifs en fonction de vos charges de travail. Ces facteurs sont généralement mesurés via des compteurs de performances. Ces compteurs de performances peuvent provenir de diverses sources, y compris du système d’exploitation, du .NET Framework ou de la plateforme Service Fabric proprement dite. Voici quelques scénarios dans lesquels ils peuvent être utiles :
- Est-ce que j’utilise efficacement mon matériel ? Voulez-vous utiliser votre matériel à 90 % ou 10 % du processeur ? Cela peut être pratique lors de la mise à l’échelle de votre cluster ou de l’optimisation des processus de votre application.
- Puis-je prévoir des problèmes d’infrastructure de façon proactive ? - de nombreux problèmes sont précédés de baisses (chutes) soudaines des performances. Vous pouvez donc utiliser des compteurs de performances comme E/S réseau et Utilisation de l’UC pour prédire et diagnostiquer les problèmes de façon proactive.
Vous trouverez la liste des compteurs de performances à collecter au niveau infrastructure dans Métriques de performances.
Service Fabric offre également une série de compteurs de performances pour les modèles de programmation Reliable Services et Reliable Actors. Si vous utilisez l’un de ces modèles, ces compteurs de performances peuvent fournir des informations garantissant que les procédures de « spin up » et de « spin down » de vos acteurs se déroulent correctement ou que vos demandes de services fiables sont gérées assez rapidement. Pour plus d’informations, consultez Surveillance pour Reliable Service Remoting et Surveillance des performances pour Reliable Actors.
La solution Azure Monitor permettant de les collecter correspond aux journaux Azure Monitor, tout comme le monitoring au niveau de la plateforme. Utilisez l’agent Log Analytics pour collecter les compteurs de performances souhaités et les afficher dans les journaux Azure Monitor.
Configuration recommandée
Maintenant que nous avons passé en revue chaque zone de supervision et les exemples de scénarios, voici un résumé des outils de supervision Azure et de leur configuration nécessaire pour superviser toutes les zones ci-dessus.
- Supervision des applications avec Application Insights
- Monitoring du cluster avec l’agent Diagnostics et les journaux Azure Monitor
- Monitoring de l’infrastructure avec les journaux Azure Monitor
Vous pouvez également utiliser et modifier l’exemple de modèle ARM situé ici pour automatiser le déploiement de tous les agents et ressources nécessaires.
Autres solutions de journalisation
Même si les deux solutions que nous recommandons, les journaux Azure Monitor et Application Insights, s’intègrent à Service Fabric, de nombreux événements sont écrits par les fournisseurs ETW et peuvent être étendus avec d’autres solutions de journalisation. Intéressez-vous également à Elastic Stack (notamment si vous envisagez d’exécuter un cluster dans un environnement hors connexion), à Dynatrace ou à toute autre plateforme de votre choix. Vous trouverez la liste des partenaires intégrés disponibles ici.
Quelle que soit la plateforme que vous choisissez, ses points clés doivent inclure la convivialité de l’interface utilisateur, les fonctions d’interrogation, les visualisations et tableaux de bord personnalisés disponibles, ainsi que les outils supplémentaires qu’elle met à votre disposition pour améliorer votre expérience de supervision.
Étapes suivantes
- Pour commencer à instrumenter vos applications, consultez Génération d’événements et de journaux au niveau application.
- Suivez les étapes de configuration d’Application Insights pour votre application dans Surveiller et diagnostiquer une application ASP.NET Core dans Service Fabric.
- Pour plus d’informations sur la surveillance de la plateforme et des événements fournis par Service Fabric, consultez Génération d’événements et de journaux au niveau plateforme.
- Configurez l’intégration des journaux Azure Monitor à Service Fabric, dans Configurer les journaux Azure Monitor pour un cluster.
- Découvrez comment configurer les journaux Azure Monitor pour le monitoring des conteneurs dans Monitoring et diagnostics des conteneurs Windows dans Azure Service Fabric.
- Consultez des exemples de problèmes de diagnostic et de solutions avec Service Fabric dans l’article Diagnostiquer des scénarios courants.
- Découvrez d’autres produits de diagnostic qui s’intègrent à Service Fabric dans l’article Solutions de partenaires pour la surveillance d’Azure Service Fabric.
- Découvrez les recommandations générales sur la surveillance des ressources Azure : Bonnes pratiques : Surveillance et diagnostics.