IA et dataflows
Cet article montre comment utiliser l’intelligence artificielle (IA) avec des dataflows. Cet article aborde les points suivants :
- Cognitive Services
- Machine learning automatisé
- Intégration d’Azure Machine Learning
Cognitive Services dans Power BI
Avec Cognitive Services dans Power BI, vous pouvez appliquer différents algorithmes d’Azure Cognitive Services pour enrichir vos données dans la préparation des données en libre-service pour les flux de données.
Les services actuellement pris en charge sont l’analyse des sentiments, l’extraction de phrases clés, la détection de langue et le balisage des images. Les transformations sont exécutées sur le service Power BI et ne nécessitent pas d’abonnement Azure Cognitive Services. Cette fonctionnalité requiert Power BI Premium.
Activer les fonctionnalités d’IA
Les services cognitifs sont pris en charge pour les nœuds de capacité Premium EM2, A2 ou P1 et les autres nœuds avec plus de ressources. Cognitive Services est également disponible avec une licence Premium par utilisateur. Une charge de travail d’intelligence artificielle distincte sur la capacité est utilisée pour exécuter les services cognitifs. Avant d’utiliser des services cognitifs dans Power BI, la charge de travail IA a besoin d’être activée dans les paramètres de capacité du portail d’administration. Vous pouvez activer la charge de travail d’intelligence artificielle dans la section des charges de travail et définir la quantité maximale de mémoire que vous souhaitez que cette charge de travail utilise. La limite de mémoire recommandée est de 20 %. Le dépassement de cette limite ralentit la requête.
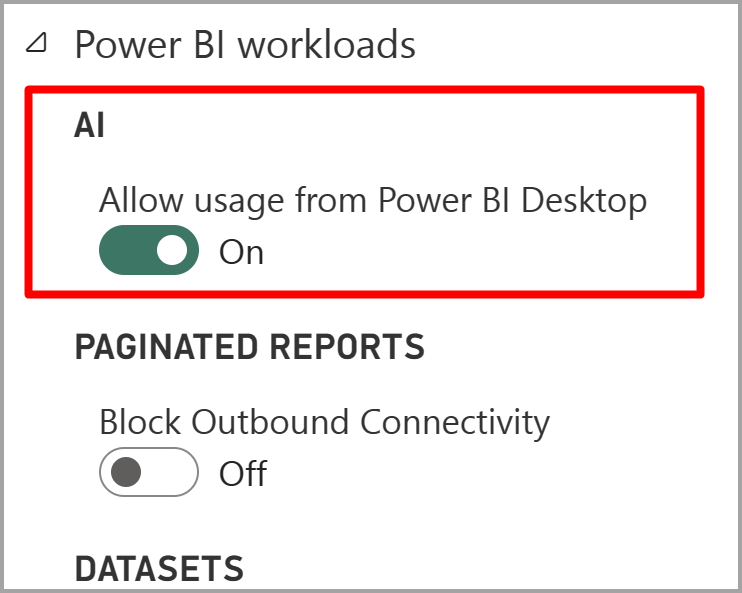
Bien démarrer avec Cognitive Services dans Power BI
Les transformations de Cognitive Services font partie de la préparation des données de libre-service pour les flux de données. Pour enrichir vos données avec Cognitive Services, commencez par modifier un flux de données.
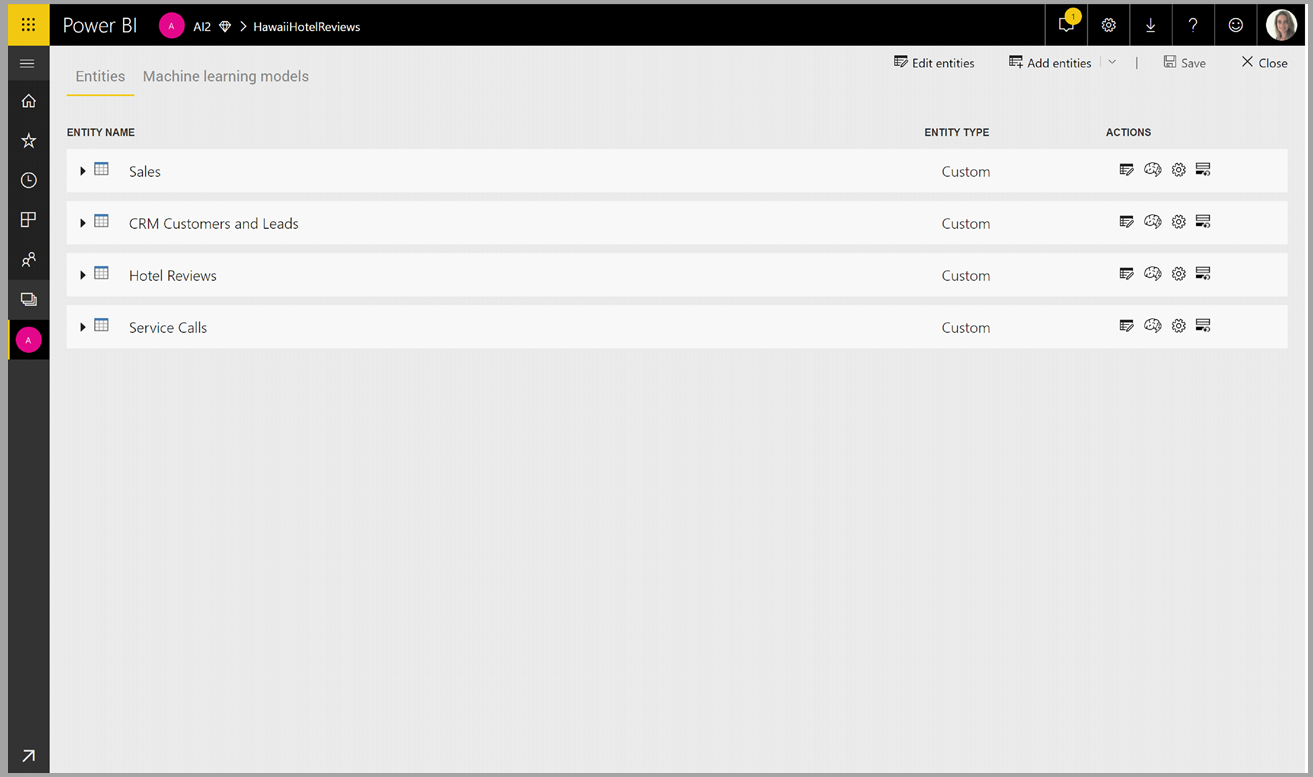
Sélectionnez le bouton Insights IA dans le ruban supérieur de l’éditeur Power Query.
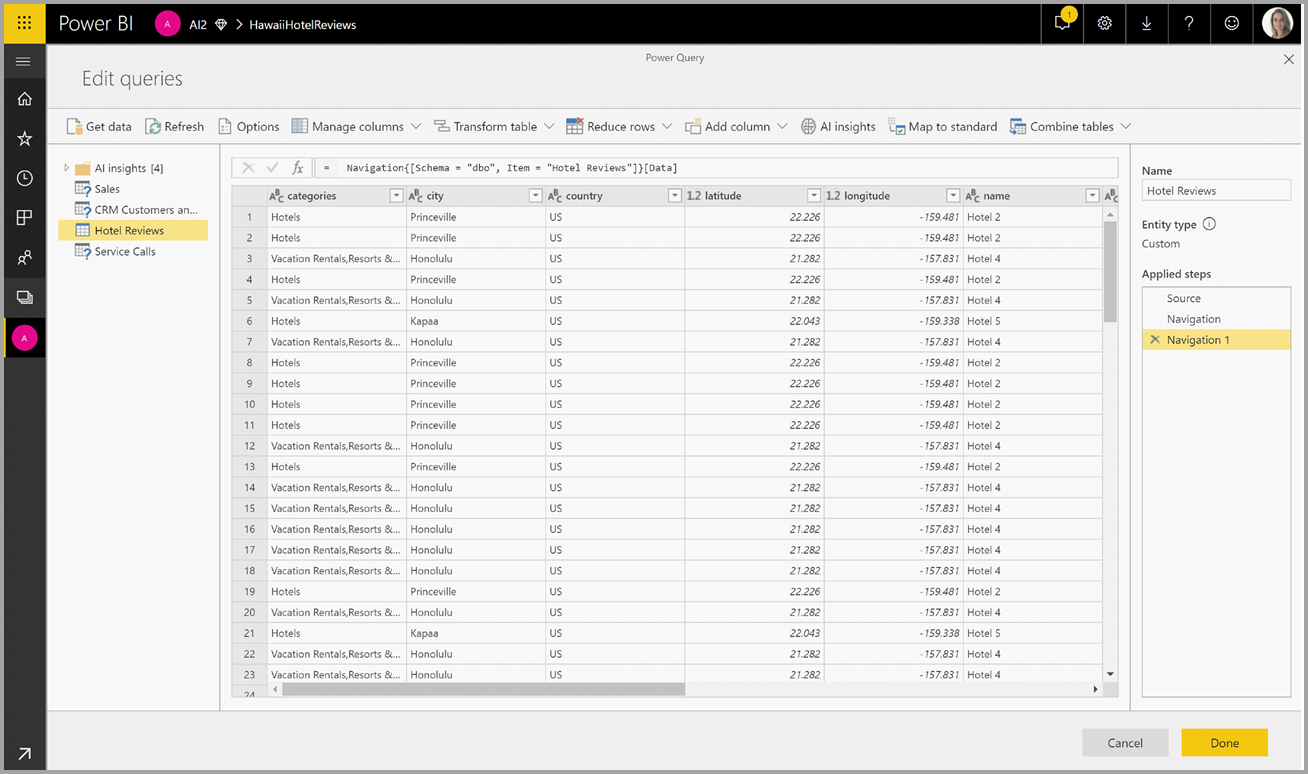
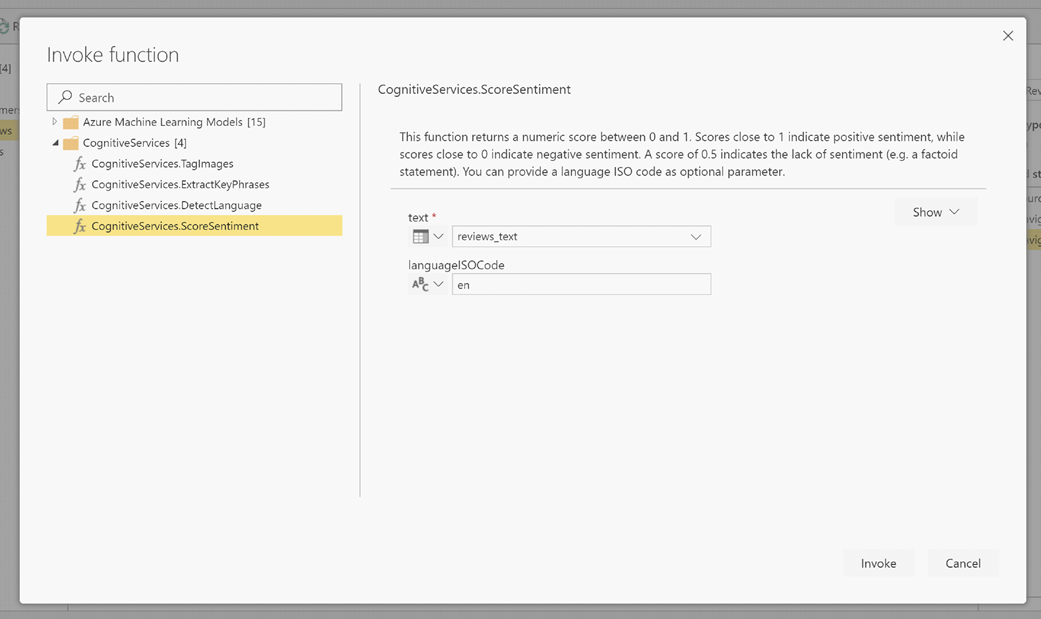
Dans la fenêtre contextuelle, sélectionnez la fonction que vous souhaitez utiliser et les données que vous souhaitez transformer. Cet exemple définit un score pour le sentiment d’une colonne qui contient le texte de la révision.
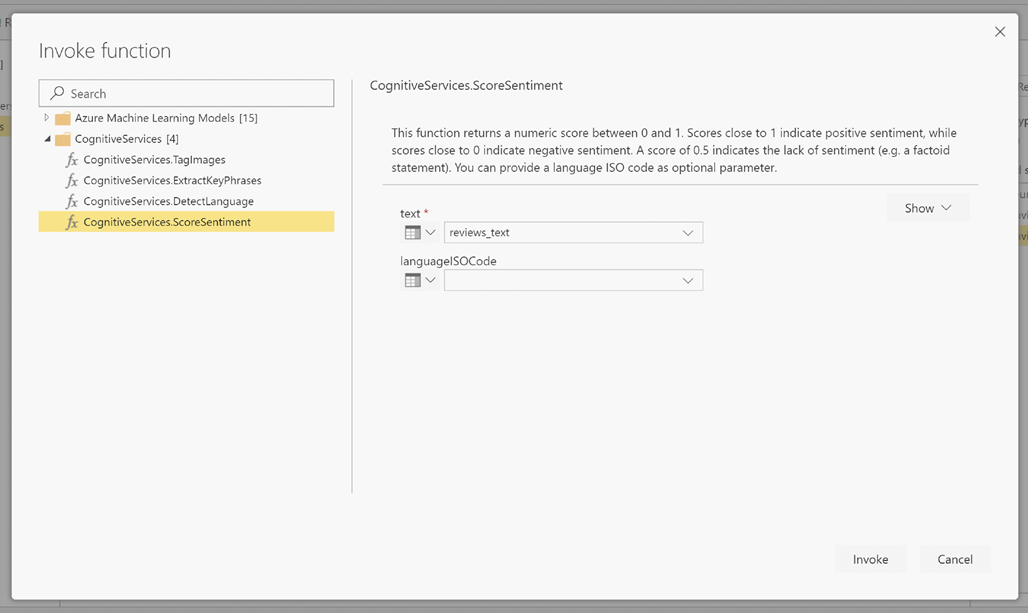
LanguageISOCode est une entrée facultative pour spécifier la langue du texte. Cette colonne attend un code ISO. Vous pouvez utiliser une colonne en tant qu’entrée pour LanguageISOCode ou une colonne statique. Dans cet exemple, la langue spécifiée pour toute la colonne est l’anglais (en). Si vous laissez cette colonne vide, Power BI détecte automatiquement la langue avant d’appliquer la fonction. Ensuite, sélectionnez Appeler.
Après avoir appelé la fonction, le résultat est ajouté à la table en tant que nouvelle colonne. La transformation est également ajoutée en tant qu’étape appliquée dans la requête.
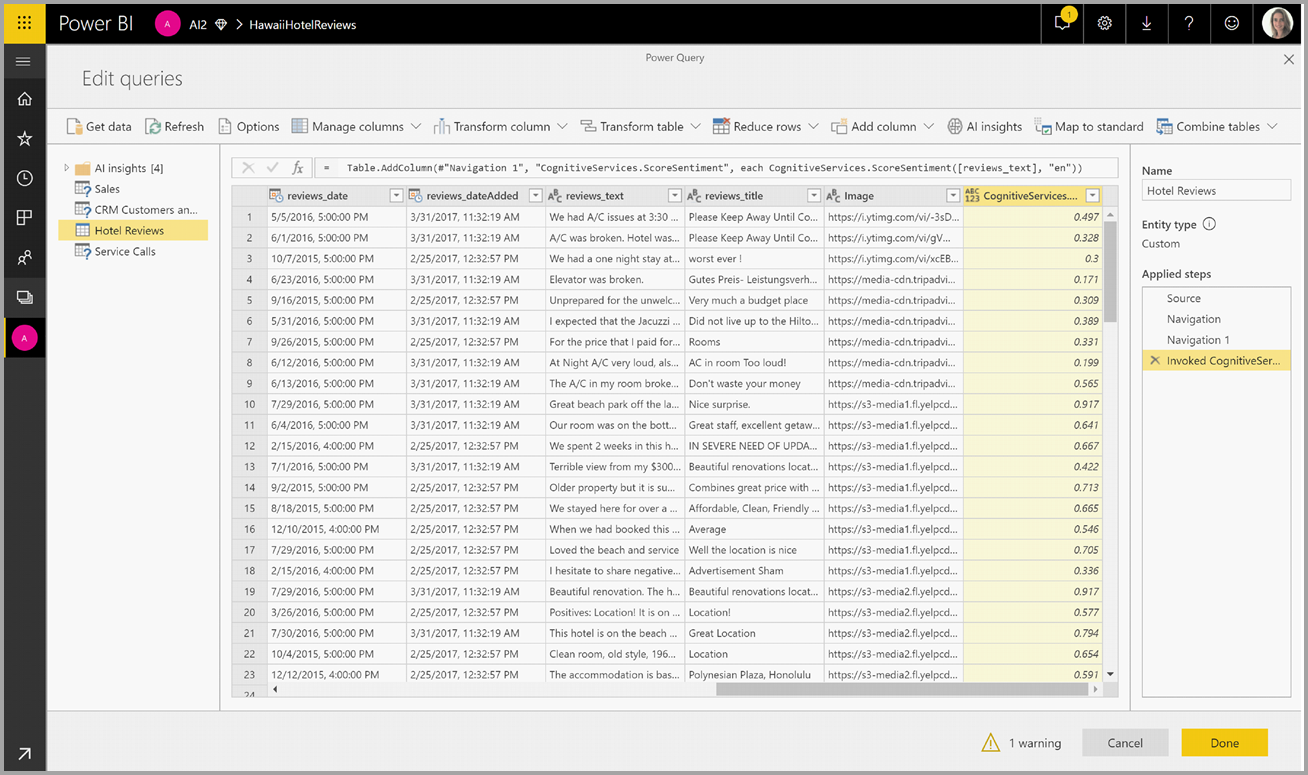
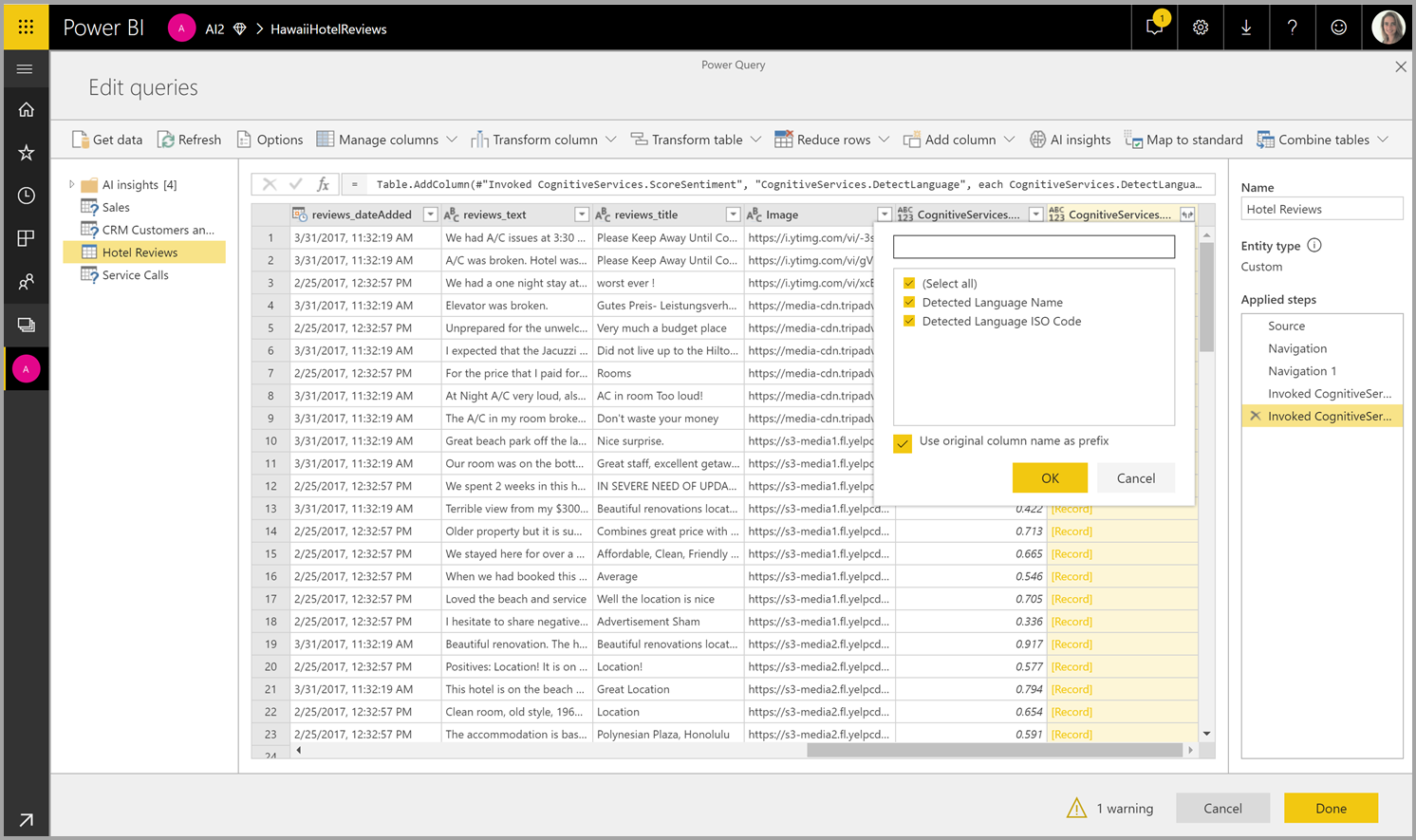
Si la fonction retourne plusieurs colonnes de sortie, l’appel de la fonction ajoute une nouvelle colonne avec une ligne de plusieurs colonnes de sortie.
Utilisez l’option de développement pour ajouter une ou les deux valeurs en tant que colonnes à vos données.
Fonctions disponibles
Cette section décrit les fonctions disponibles dans Cognitive Services dans Power BI.
Détecter la langue
La fonction de détection de la langue évalue le texte entré et, pour chaque colonne, retourne le nom de la langue et l’identificateur ISO. Cette fonction est utile pour les colonnes de données qui collectent du texte arbitraire dont la langue est inconnue. La fonction attend des données au format texte en tant qu’entrée.
L’analyse de texte reconnaît jusqu'à 120 langues. Pour plus d’informations, consultez Qu’est-ce que la détection de langue dans Azure Cognitive Service for Language ?
Extraire les phrases clés
La fonction Extraction de phrases clés évalue du texte non structuré et, pour chaque colonne de texte, retourne la liste des phrases clés. La fonction nécessite une colonne de texte en tant qu’entrée et accepte une entrée facultative pour LanguageISOCode. Pour plus d’informations, consultez Bien démarrer.
L’extraction de phrases clés fonctionne au mieux lorsque vous lui donnez de plus grands blocs de texte à traiter, à l’opposé de l’analyse des sentiments. L’analyse des sentiments fonctionne mieux sur des blocs de texte plus petits. Pour obtenir les meilleurs résultats lors des deux opérations, envisagez de restructurer les entrées en conséquence.
Noter le sentiment
La fonction Noter le sentiment évalue une entrée de texte et retourne un score de valeur de 0 (négatif) à 1 (positif) pour chaque document. Cette fonction est utile pour détecter les sentiments positifs et négatifs dans les médias sociaux, les avis de clients et les forums de discussion.
L’analyse de texte utilise un algorithme de classification de Machine Learning pour générer un score de sentiment entre 0 et 1. Les scores plus proches de 1 indiquent un sentiment positif. Les scores plus proches de 0 indiquent un sentiment négatif. Le modèle est préformé avec un corps de texte étendu contenant des associations de sentiments. Il n’est actuellement pas possible de fournir vos propres données d’apprentissage. Le modèle utilise une combinaison de techniques pendant l’analyse de texte, notamment le traitement de texte, l’analyse morphosyntaxique, le placement des mots et les associations de mots. Pour plus d’informations sur l’algorithme, consultez Machine Learning et analyse de texte.
L’analyse des sentiments est effectuée sur toute la colonne d’entrée, par opposition à l’extraction des sentiments pour une table particulière du texte. Dans la pratique, on a tendance à noter la précision d’amélioration lorsque des documents contiennent une ou deux phrases plutôt qu’un grand bloc de texte. Pendant une phase d’évaluation de l’objectivité, le modèle détermine si une colonne d’entrée en tant que tout est objective ou contient des sentiments. Une colonne d’entrée principalement objective ne passe pas à la phase de détection des sentiments. Un score de 0,50 est généré sans traitement supplémentaire. Pour que les colonnes d’entrée continuent dans le pipeline, la phase suivante génère un score inférieur ou supérieur à 0,50, selon le degré de sentiment détecté dans la colonne d’entrée.
Actuellement, l’analyse des sentiments prend en charge l’anglais, l’allemand, l’espagnol et le français. D’autres langues sont en préversion. Pour plus d’informations, consultez Qu’est-ce que la détection de langue dans Azure Cognitive Service for Language ?
Marquer des images
La fonction Baliser des images retourne des balises basées sur plus de 2 000 objets, êtres vivants, scènes et actions reconnaissables. Lorsque des balises sont ambiguës ou ne sont pas connues de beaucoup de personnes, la sortie donne des « indications » pour clarifier la signification de la balise dans le contexte d’un paramètre connu. Les balises ne sont pas organisées sous la forme d’une taxonomie et il n’y a pas de hiérarchies d’héritage. La collection de balises de contenu constitue la « description » essentielle d’une image, qui est affichée sous forme de texte lisible par l’homme (phrases complètes).
Après le chargement d’une image ou la spécification d’une URL d’image, les algorithmes de vision par ordinateur sortent des balises basées sur des objets, des êtres vivants et des actions identifiés dans l’image. Le balisage ne se limite pas au sujet principal, comme une personne au premier plan, mais il inclut également le décor (intérieur ou extérieur), le mobilier, les outils, les plantes, les animaux, les accessoires, les gadgets, etc.
Cette fonction requiert une URL de l’image ou une colonne de base de données 64 bits en tant qu’entrée. Actuellement, le balisage des images prend en charge l’anglais, l’espagnol, le japonais, le portugais et le chinois simplifié. Pour plus d’informations, consultez ComputerVision Interface.
Machine Learning automatisé dans Power BI
Le Machine Learning automatisé (AutoML) pour les dataflows permet aux analystes métier d’entraîner, de valider et d’appeler des modèles Machine Learning (ML) directement dans Power BI. Il offre une expérience simple pour la création d’un nouveau modèle Machine Learning dans lequel les analystes peuvent utiliser leurs dataflows pour spécifier les données d’entrée pour effectuer l’apprentissage du modèle. Le service extrait automatiquement les caractéristiques les plus pertinentes et sélectionne un algorithme approprié, puis il ajuste et valide le modèle Machine Learning. Après l’entraînement d’un modèle, Power BI génère automatiquement un rapport sur les performances qui comprend les résultats de la validation. Le modèle peut ensuite être appelé sur toutes les données nouvelles ou mises à jour dans le dataflow.
Le Machine Learning automatisé est disponible pour les dataflows hébergés sur les capacités Power BI Premium et Embedded uniquement.
Utiliser AutoML
Le Machine Learning et l’IA connaissent une popularité sans précédent auprès des industries et des domaines de recherche scientifique. Les entreprises recherchent également des moyens d’intégrer ces nouvelles technologies à leurs opérations.
Les dataflows assurent une préparation des données en libre-service pour le Big Data. AutoML est intégré aux dataflows et vous permet d’utiliser votre préparation des données pour créer des modèles Machine Learning directement dans Power BI.
AutoML dans Power BI permet aux analystes de données d’utiliser les dataflows pour créer des modèles Machine Learning avec une expérience simplifiée, en utilisant uniquement des compétences Power BI. Power BI automatise en grande partie la science des données qui est utilisée dans le cadre de la création des modèles ML. Elle comprend des systèmes qui garantissent la qualité du modèle créé, et permet de voir le processus qui est utilisé pour créer votre modèle ML.
AutoML prend en charge la création de modèles de Prédiction binaire, de Classification et de Régression pour les dataflows. Ces fonctionnalités sont des techniques de Machine Learning supervisées qui s’entraînent à partir des résultats connus d’observations passées pour prédire les résultats d’autres observations. Le modèle sémantique d’entrée pour effectuer l’apprentissage d’un modèle AutoML est un ensemble de lignes étiquetées avec les résultats connus.
AutoML dans Power BI intègre le machine learning automatisé d’Azure Machine Learning pour créer vos modèles Machine Learning. Toutefois, vous n’avez pas besoin d’un abonnement Azure pour utiliser AutoML dans Power BI. Le service Power BI gère entièrement le processus d’entraînement et d’hébergement des modèles Machine Learning.
Après l’apprentissage d’un modèle Machine Learning, AutoML génère automatiquement un rapport Power BI qui explique les performances probables de votre modèle Machine Learning. AutoML met l’accent sur la facilité d’explication, en mettant en évidence les facteurs d’influence clés parmi les entrées qui influencent les prédictions retournées par votre modèle. Le rapport comprend également des métriques clés pour le modèle.
D’autres pages du rapport généré affichent le résumé statistique du modèle et les détails de la formation. Le résumé statistique présente un intérêt pour les utilisateurs qui souhaitent voir les mesures de science des données standard concernant les performances du modèle. Les détails de la formation résument toutes les itérations exécutées pour créer votre modèle, avec les paramètres de modélisation associés. Ils décrivent également comment chaque entrée a été utilisée pour créer le modèle Machine Learning.
Vous pouvez ensuite appliquer votre modèle Machine Learning à vos données pour scoring. Lorsque le dataflow est actualisé, vos données sont mises à jour avec les prédictions de votre modèle ML. Power BI comprend également une explication individualisée pour chaque prédiction produite par le modèle Machine Learning.
Créer un modèle Machine Learning
Cette section décrit comment créer un modèle AutoML.
Préparation des données pour la création d’un modèle Machine Learning
Pour créer un modèle Machine Learning dans Power BI, vous devez d’abord créer un dataflow pour les données comprenant les informations d’historique des résultats, qui sont utilisées pour effectuer l’entraînement du modèle ML. Vous devez aussi ajouter des colonnes calculées pour toutes les métriques métier susceptibles d’être des éléments de prédiction forts pour les résultats que vous essayez de prédire. Pour plus d’informations sur la configuration de votre dataflow, consultez Configurer et consommer un dataflow.
AutoML a des exigences spécifiques en matière de données pour la formation d’un modèle Machine Learning. Ces exigences sont décrites dans les sections suivantes, en fonction des types de modèles respectifs.
Configurer les entrées du modèle Machine Learning
Pour créer un modèle AutoML, sélectionnez l’icône ML dans la colonne Actions de la table de dataflow, puis sélectionnez Ajouter un modèle Machine Learning.
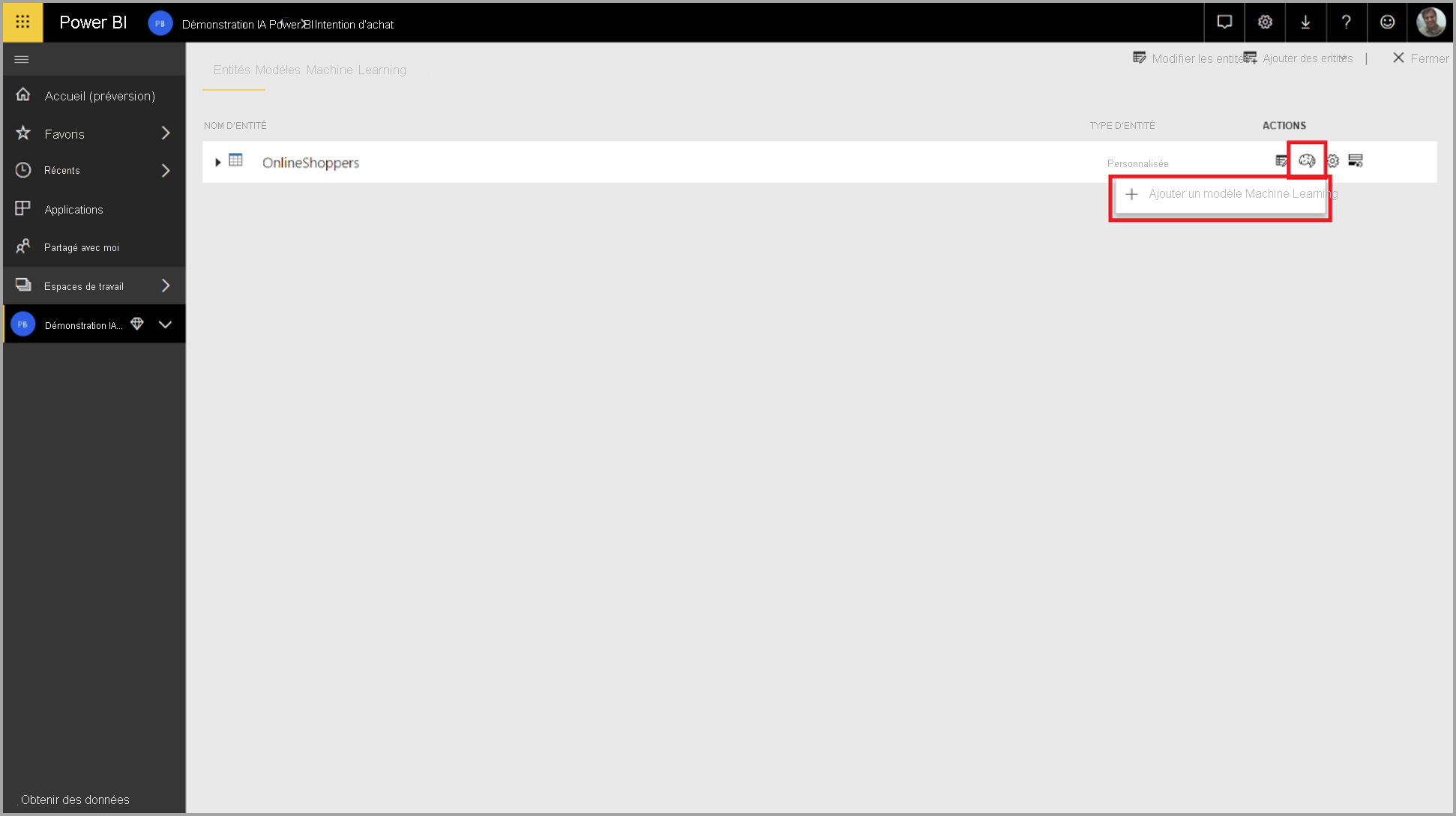
Une expérience simplifiée se lance, composée d’un Assistant qui vous guide tout au long du processus de création du modèle Machine Learning. L’assistant comprend les étapes simples suivantes.
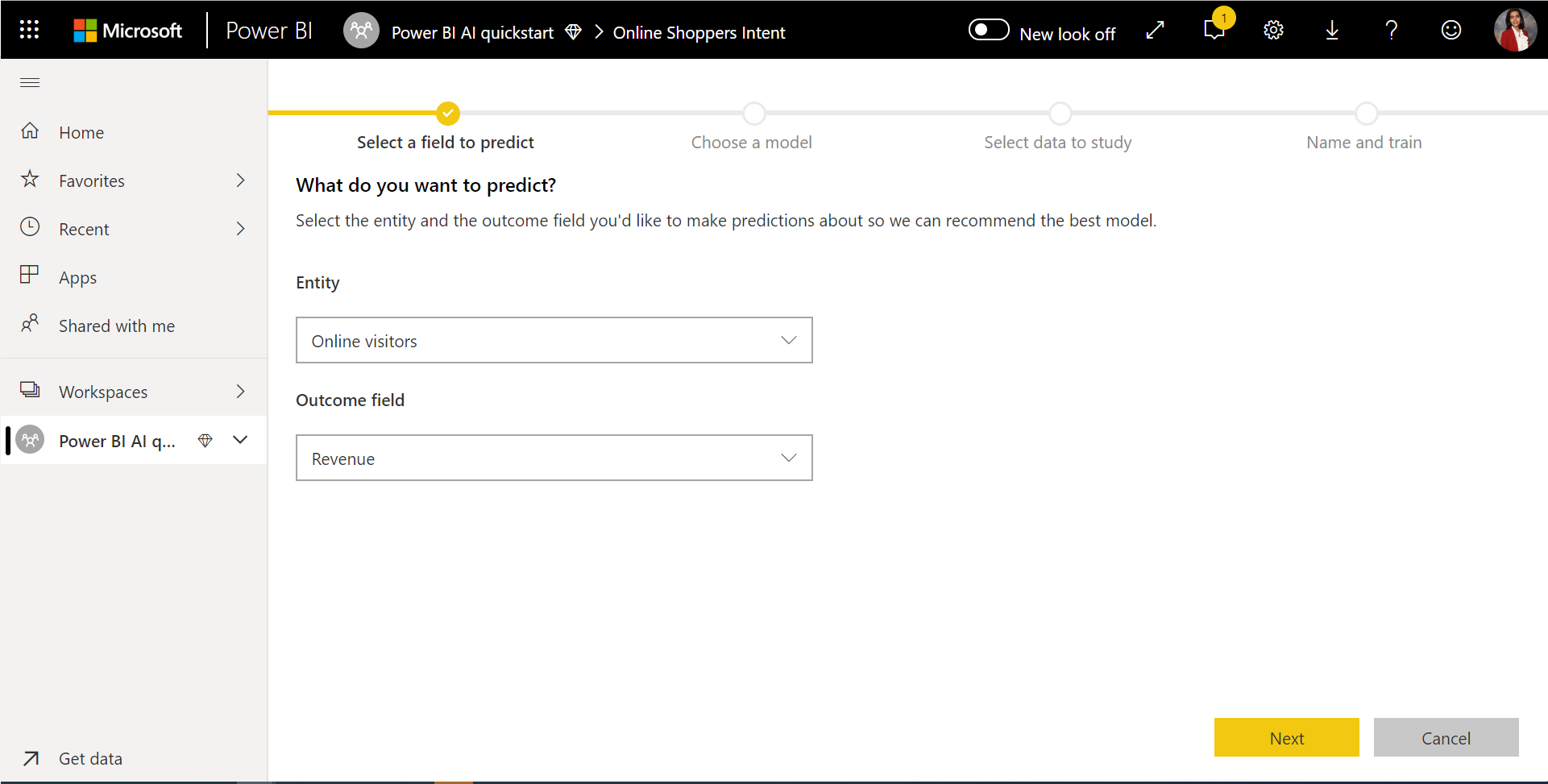
1. Sélectionner la table avec les données historiques et la colonne de résultat pour laquelle vous voulez une prédiction
La colonne de résultat identifie l’attribut d’étiquette pour l’entraînement du modèle Machine Learning, comme illustré dans l’image suivante.
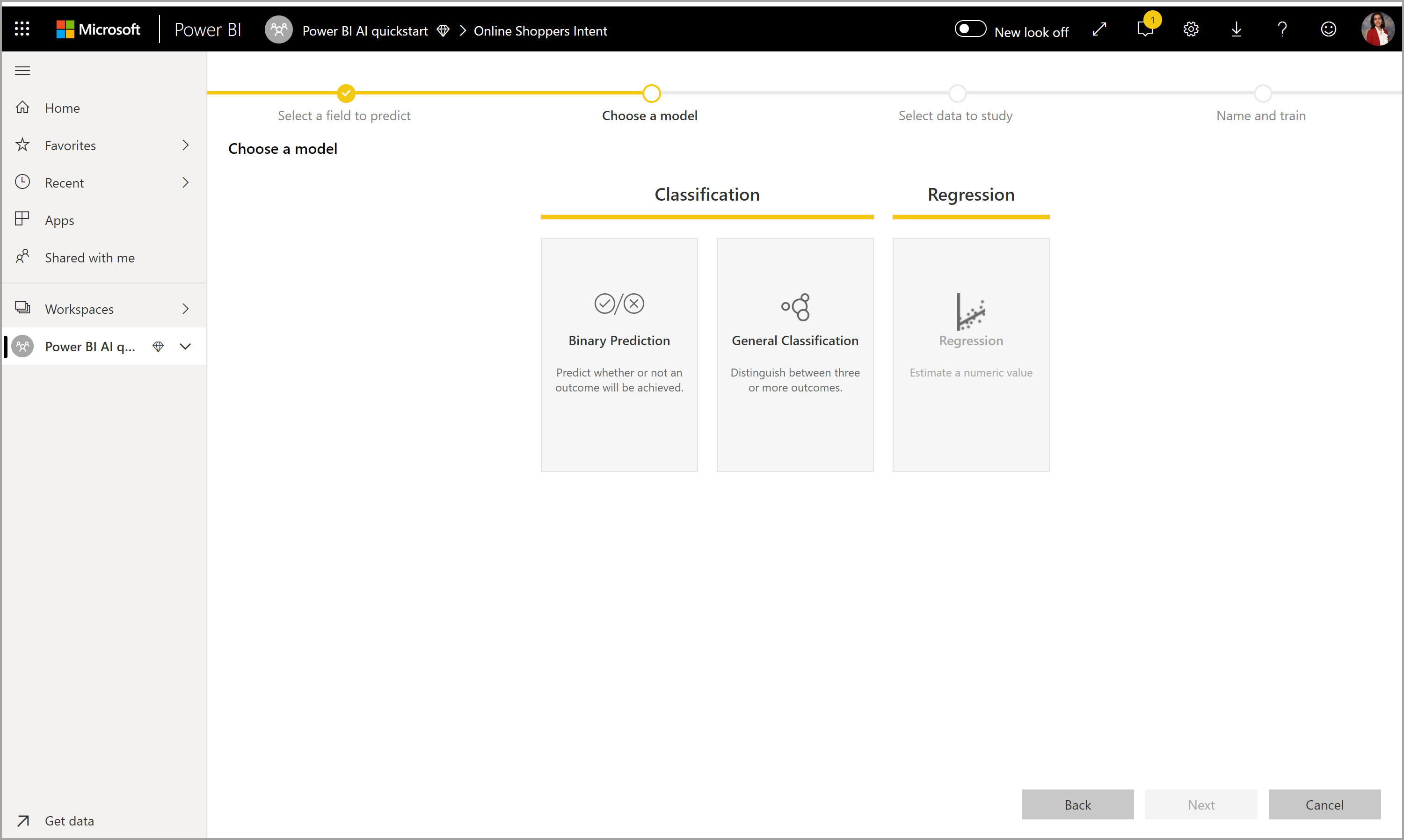
2. Choisir un type de modèle
Lorsque vous spécifiez la colonne de résultat, AutoML analyse les données d’étiquette pour recommander le type de modèle ML qui a le plus de chances de pouvoir être entraîné. Vous pouvez sélectionner un type de modèle différent comme illustré dans l’image suivante en cliquant sur Choisir un modèle.
Notes
Certains types de modèles risquent de ne pas être pris en charge pour les données que vous avez sélectionnées et sont donc désactivés. Dans l’exemple précédent, la régression est désactivée, car une colonne de texte est sélectionnée en tant que colonne de résultat.
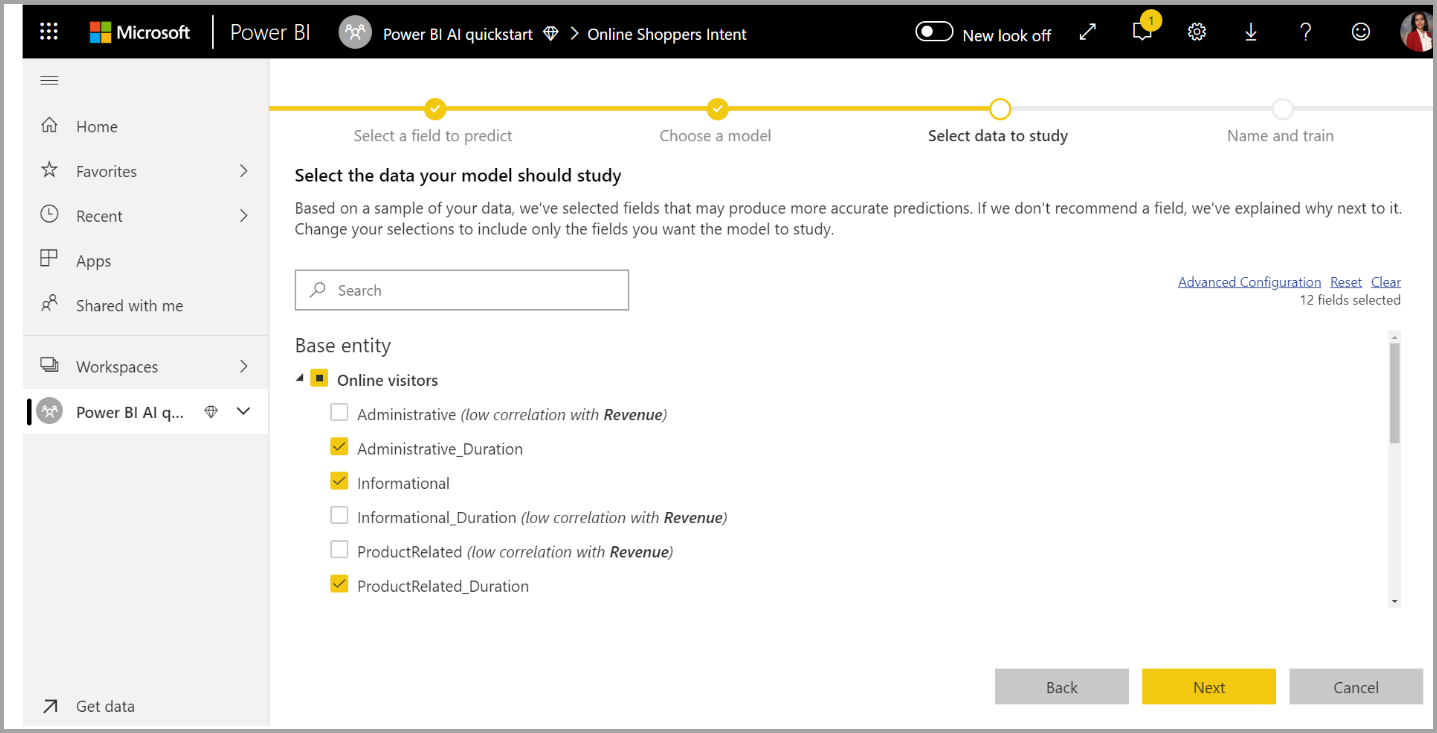
3. Sélectionner les entrées que vous souhaitez que le modèle utilise comme signaux prédictifs
AutoML analyse un échantillon de la table sélectionnée afin de suggérer les entrées qui peuvent être utilisées pour l’entraînement du modèle Machine Learning. Des explications sont fournies en regard des colonnes qui ne sont pas sélectionnées. Si une colonne a un trop grand nombre de valeurs différentes ou n’a qu’une seule valeur, ou si la corrélation avec la colonne de sortie est trop faible ou trop élevée, ce choix n’est pas recommandé.
Les entrées qui dépendent de la colonne de résultat (ou de la colonne d’étiquette) ne doivent pas être utilisées pour entraîner le modèle Machine Learning, car elles affectent les performances. Ces colonnes sont marquées comme ayant une « forte corrélation suspecte avec la colonne de sortie ». L’ajout de ces colonnes dans les données d’entraînement provoque une fuite d’étiquette : le modèle s’exécute correctement sur les données de validation et de test, mais pas dans un contexte de scoring dans un environnement de production. Si les performances du modèle d’entraînement paraissent trop élevées, il est possible qu’une fuite d’étiquette affecte les modèles AutoML.
Cette recommandation de caractéristique est basée sur un échantillon de données. Vous devez donc passer en revue toutes les entrées utilisées. Vous pouvez modifier les sélections pour y inclure uniquement les colonnes que le modèle doit étudier. Vous pouvez également sélectionner toutes les colonnes en cochant la case en regard du nom de la table.
4. Nommer votre modèle et enregistrez votre configuration
Dans la dernière étape, vous pouvez nommer le modèle, sélectionner Enregistrer et choisir celui qui démarre l’entraînement du modèle ML. Vous pouvez choisir de réduire la durée de l’entraînement pour avoir des résultats rapidement, ou d’augmenter sa durée pour obtenir le meilleur modèle possible.
Formation du modèle Machine Learning
La formation des modèles AutoML fait partie de l’actualisation du dataflow. AutoML prépare tout d’abord vos données pour l’apprentissage. AutoML fractionne les données d’historique que vous fournissez dans les modèles sémantiques d’apprentissage et les modèles sémantiques de test. Le modèle sémantique de test est un ensemble de données d’exclusion utilisé pour valider les performances du modèle après l’apprentissage. Ces jeux se présentent sous la forme de tables Entraînement et test dans le dataflow. AutoML utilise la validation croisée pour la validation du modèle.
Ensuite, chaque colonne d’entrée est analysée et l’imputation est appliquée, ce qui remplace toutes les valeurs manquantes par des valeurs substituées. Plusieurs stratégies d’imputation sont utilisées par AutoML. Pour les attributs d’entrée traités comme des caractéristiques numériques, la moyenne des valeurs de colonne est utilisée pour l’imputation. Pour les attributs d’entrée traités comme des caractéristiques catégoriques, AutoML utilise le mode des valeurs de colonne pour l’imputation. Le framework AutoML calcule la moyenne et le mode des valeurs utilisées pour l’imputation d’après le modèle sémantique d’entraînement sous-échantillonné.
Ensuite, l’échantillonnage et la normalisation sont appliqués à vos données. Pour les modèles de classification, AutoML exécute les données d’entrée via un échantillonnage stratifié et équilibre les classes pour garantir que celles-ci ont toutes le même nombre de lignes.
AutoML applique plusieurs transformations sur chaque colonne d’entrée sélectionnée en fonction de son type de données et de ses propriétés statistiques. AutoML utilise ces transformations pour extraire les fonctionnalités à utiliser lors de la formation de votre modèle Machine Learning.
Le processus d’apprentissage pour les modèles AutoML se compose de jusqu’à 50 itérations avec différents algorithmes de modélisation et des paramètres d’hyperparamètre pour trouver le modèle avec les meilleures performances. L’entraînement peut se terminer tôt avec des itérations moins importantes si AutoML constate que les performances n’ont pas été améliorées. AutoML évalue les performances de chacun de ces modèles en effectuant une validation avec le modèle sémantique d’exclusion de test. Au cours de cette étape de formation, AutoML crée plusieurs pipelines pour effectuer l'apprentissage et la validation de ces itérations. Le processus d’évaluation des performances des modèles peut prendre du temps, entre quelques minutes et quelques heures, jusqu’à la durée d’entraînement configurée dans l’Assistant. Le temps nécessaire dépend de la taille de votre modèle sémantique et des ressources de capacité disponibles.
Dans certains cas, le modèle final généré peut utiliser l’apprentissage ensembliste, où plusieurs modèles sont utilisés pour fournir de meilleures performances prédictives.
Facilité d’explication du modèle AutoML
Une fois le modèle formé, AutoML analyse la relation entre les fonctionnalités d’entrée et la sortie du modèle. Il évalue l’amplitude de la modification apportée à la sortie du modèle pour le modèle sémantique d’exclusion de test de chaque caractéristique d’entrée. Cette relation est connue sous le nom d’importance d’une caractéristique. Cette analyse se produit dans le cadre de l’actualisation une fois l’entraînement terminé. Par conséquent, votre actualisation peut prendre plus de temps que la durée d’entraînement configurée dans l’Assistant.
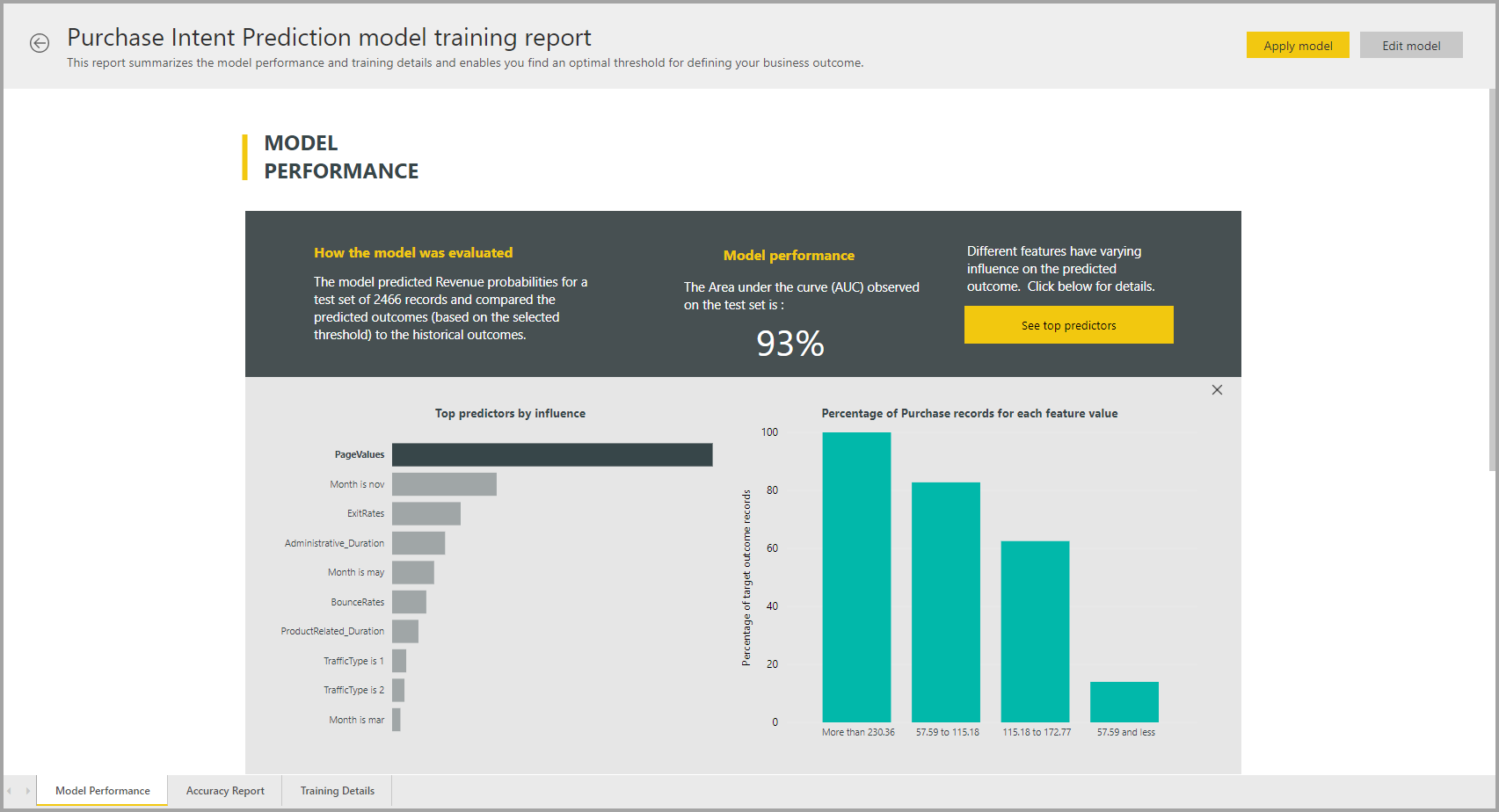
Rapport sur le modèle AutoML
AutoML génère un rapport Power BI qui résume les performances du modèle pendant la validation, ainsi que l’importance globale des fonctionnalités. Ce rapport est accessible à partir de l’onglet Modèles Machine Learning une fois l’actualisation du dataflow correctement accomplie. Le rapport résume les résultats de l’application du modèle Machine Learning aux données d’exclusion de test et de la comparaison des prédictions avec les valeurs de résultat connues.
Vous pouvez consulter le rapport de modèle pour comprendre ses performances. Vous pouvez également vérifier que les influenceurs clés du modèle s’alignent sur les insights métier sur les résultats connus.
Les graphiques et mesures utilisés pour décrire les performances du modèle dans le rapport varient selon le type de modèle. Ces graphiques et mesures de performance sont décrits dans les sections suivantes.
D’autres pages du rapport peuvent décrire des mesures statistiques sur le modèle du point de vue de la science des données. Par exemple, le rapport Prédiction binaire comprend un graphique de gain et la courbe ROC pour le modèle.
Les rapports incluent également une page Détails de l’entraînement qui comprend une description de la façon dont le modèle a été entraîné, ainsi qu’un graphique décrivant les performances du modèle sur chacune des itérations exécutées.
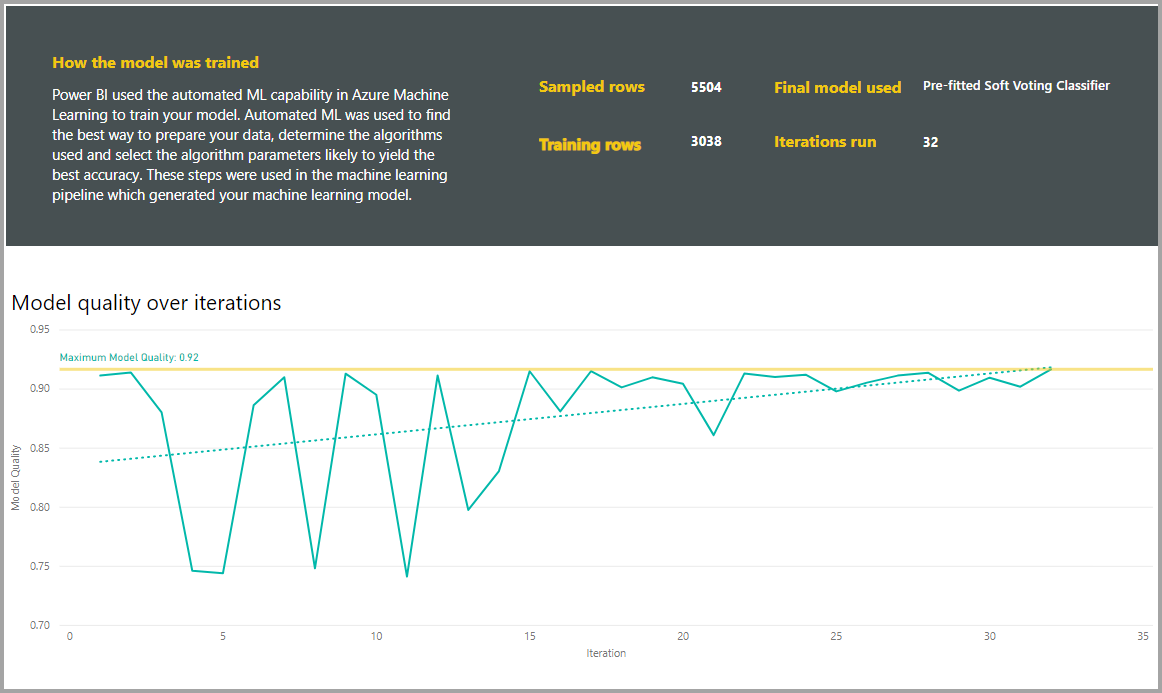
Une autre section de cette page décrit le type de la colonne d’entrée détectée, ainsi que la méthode d’imputation utilisée pour le remplissage des valeurs manquantes. Elle comprend également les paramètres utilisés par le modèle final.
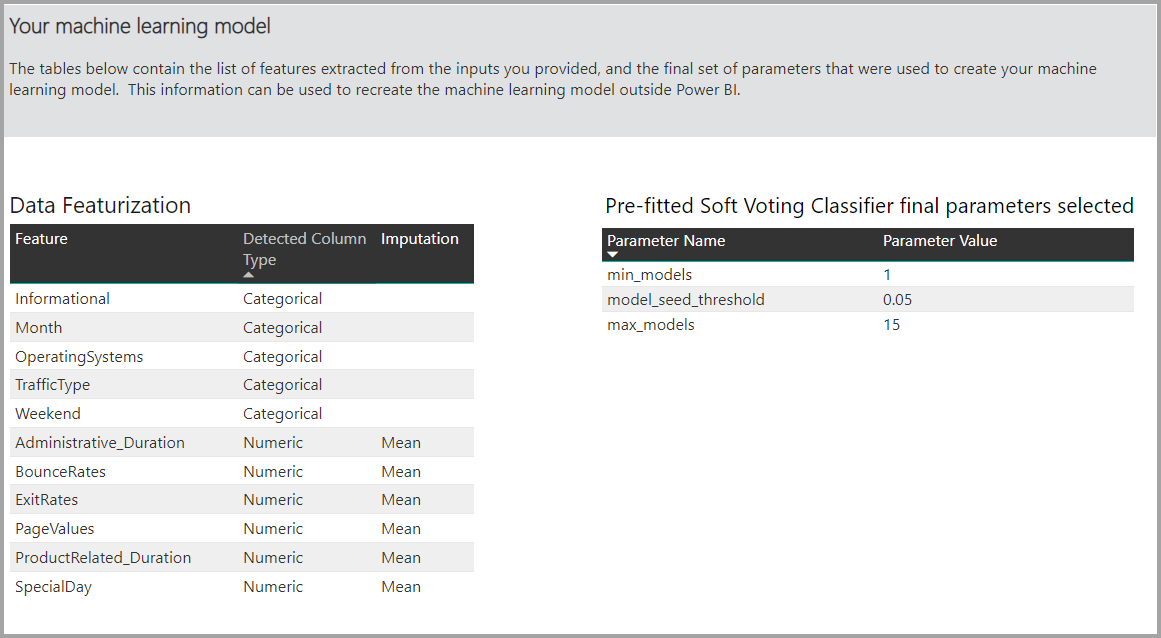
Si le modèle produit utilise l’apprentissage ensembliste, alors la page Détails de l’entraînement comprend aussi un graphique qui représente la pondération de chaque modèle constitutif de l’ensemble, ainsi que ses paramètres.

Appliquer le modèle AutoML
Si vous êtes satisfait des performances du modèle Machine Learning créé, vous pouvez l’appliquer à des données nouvelles ou mises à jour lorsque votre dataflow est actualisé. Dans le rapport du modèle, sélectionnez le bouton Appliquer dans le coin supérieur droit ou le bouton Appliquer le modèle ML situé sous les actions de l’onglet Modèles Machine Learning.
Pour appliquer le modèle ML, vous devez spécifier le nom de la table à laquelle il doit être appliqué et un préfixe pour les colonnes qui seront ajoutées à cette table pour la sortie du modèle. Le préfixe par défaut des noms de colonne est le nom du modèle. La fonction Appliquer peut inclure d’autres paramètres propres au type de modèle.
L’application du modèle ML crée deux tables de dataflows qui contiennent les prédictions et des explications individualisées pour chaque ligne à laquelle elle attribue un score dans la table de sortie. Par exemple, si vous appliquez le modèle PurchaseIntent à la table OnlineShoppers, la sortie génère les tables OnlineShoppers enriched PurchaseIntent et OnlineShoppers enriched PurchaseIntent explanations. Pour chaque ligne de la table enrichie, les explications sont réparties sur plusieurs lignes, en fonction de la caractéristique d’entrée. Une ExplanationIndex permet de mapper les lignes de la table d’explications enrichie avec celles de la table enrichie.
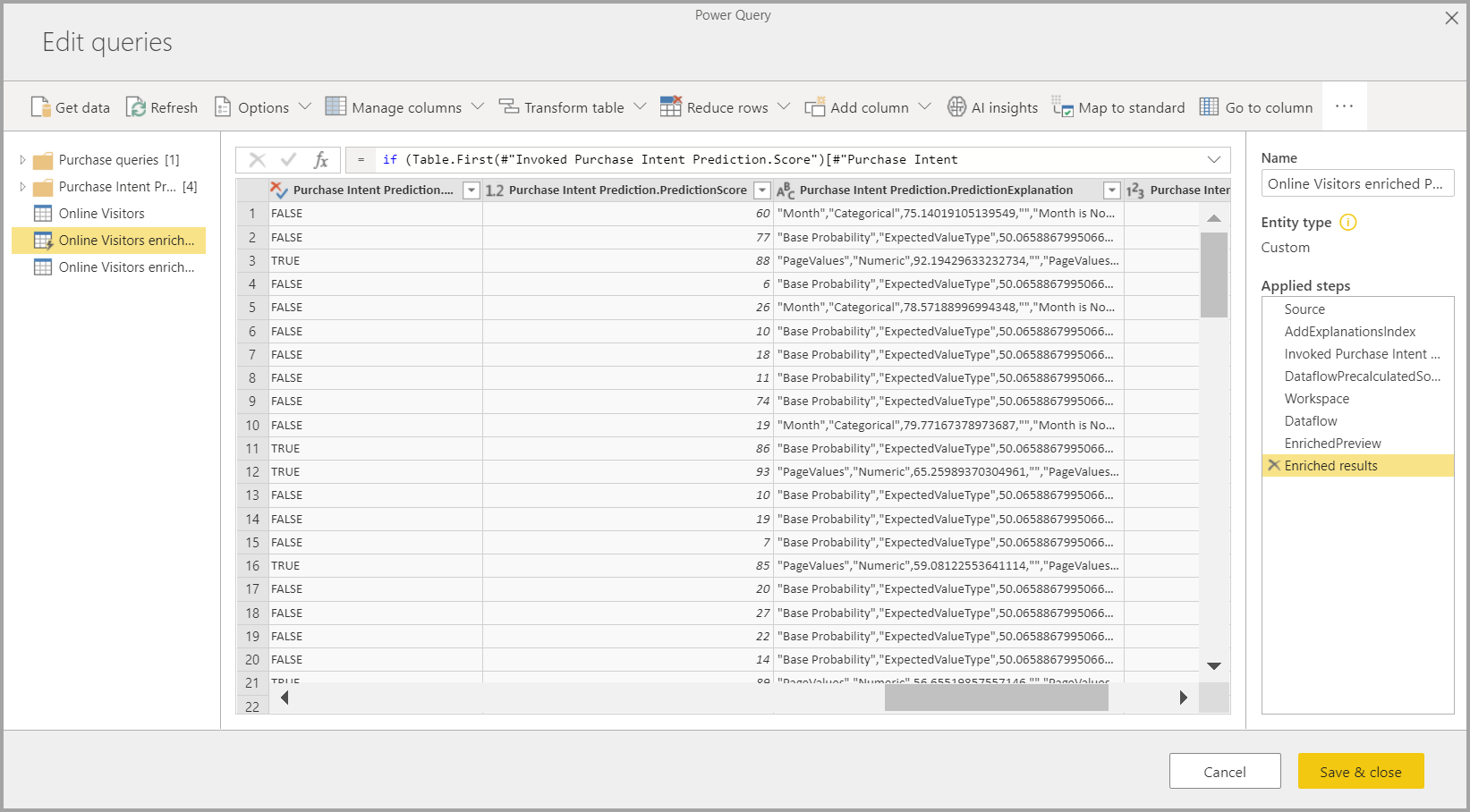
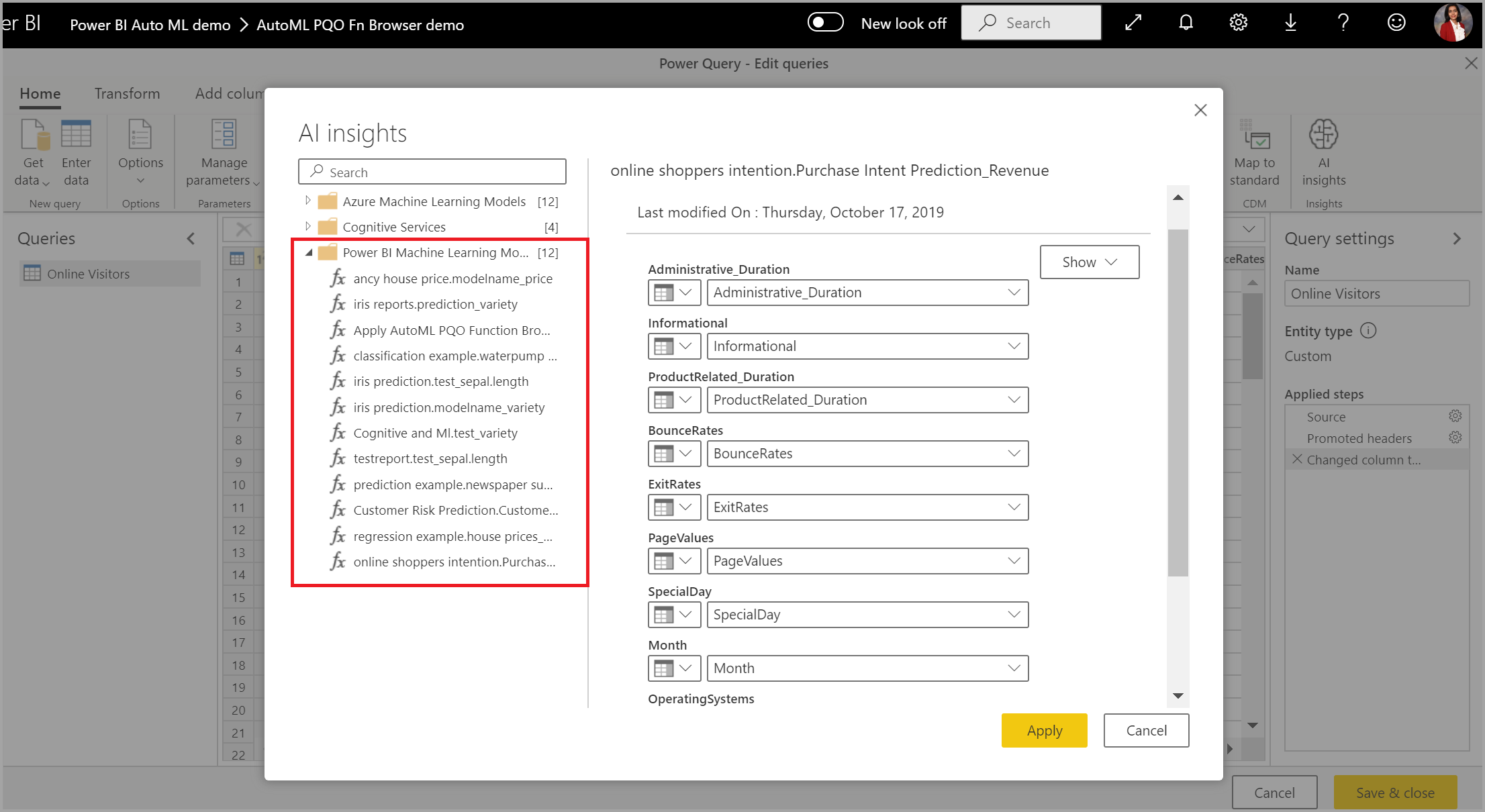
Vous pouvez également appliquer tout modèle AutoML Power BI à des tables dans un dataflow compris dans le même espace de travail à l’aide d’Insights IA dans l’explorateur de fonctions PQO. De cette façon, vous pouvez utiliser des modèles créés par d’autres dans le même espace de travail sans nécessairement être un propriétaire du flux de données qui a le modèle. Power Query Découvre tous les modèles de Power BI ML dans l’espace de travail et les expose en tant que fonctions Power Query dynamiques. Vous pouvez appeler ces fonctions en y accédant à partir du ruban dans l’Éditeur Power Query ou en appelant directement la fonction M. Cette fonctionnalité est actuellement uniquement prise en charge pour les dataflows Power BI et pour Power Query Online dans le service Power BI. Ce processus est différent de l’application des modèles ML dans un dataflow à l’aide de l’Assistant AutoML. Aucune table d’explications n’est créée avec cette méthode. À moins d’être propriétaire du dataflow, vous ne pouvez pas accéder aux rapports d’entraînement du modèle ni réentraîner le modèle. De plus, si le modèle source est modifié, par l’ajout ou la suppression de colonnes d’entrée, ou si le modèle ou le dataflow source est supprimé, alors ce dataflow dépendant s’arrête.
Une fois le modèle appliqué, AutoML garde vos prédictions à jour après chaque actualisation du dataflow.
Pour utiliser les insights et les prédictions du modèle Machine Learning dans un rapport Power BI, vous pouvez vous connecter à la table de sortie à partir de Power BI Desktop avec le connecteur de dataflows.
Modèles de prédiction binaire
Les modèles de prédiction binaire, plus connus sous le nom de modèles de classification binaire, sont utilisés pour classer un modèle sémantique en deux groupes. Elles sont utilisées pour prédire les événements qui peuvent avoir un résultat binaire. Par exemple si une opportunité de vente sera convertie, si un client ne renouvellera pas, si une facture sera payée à temps, si une transaction sera frauduleuse, et ainsi de suite.
La sortie d’un modèle de prédiction binaire est un score de probabilité, qui identifie la probabilité que le résultat cible soit obtenu.
Entraîner un modèle de prédiction binaire
Conditions préalables :
- Au moins 20 lignes de données d’historique sont nécessaires pour chaque classe de résultats
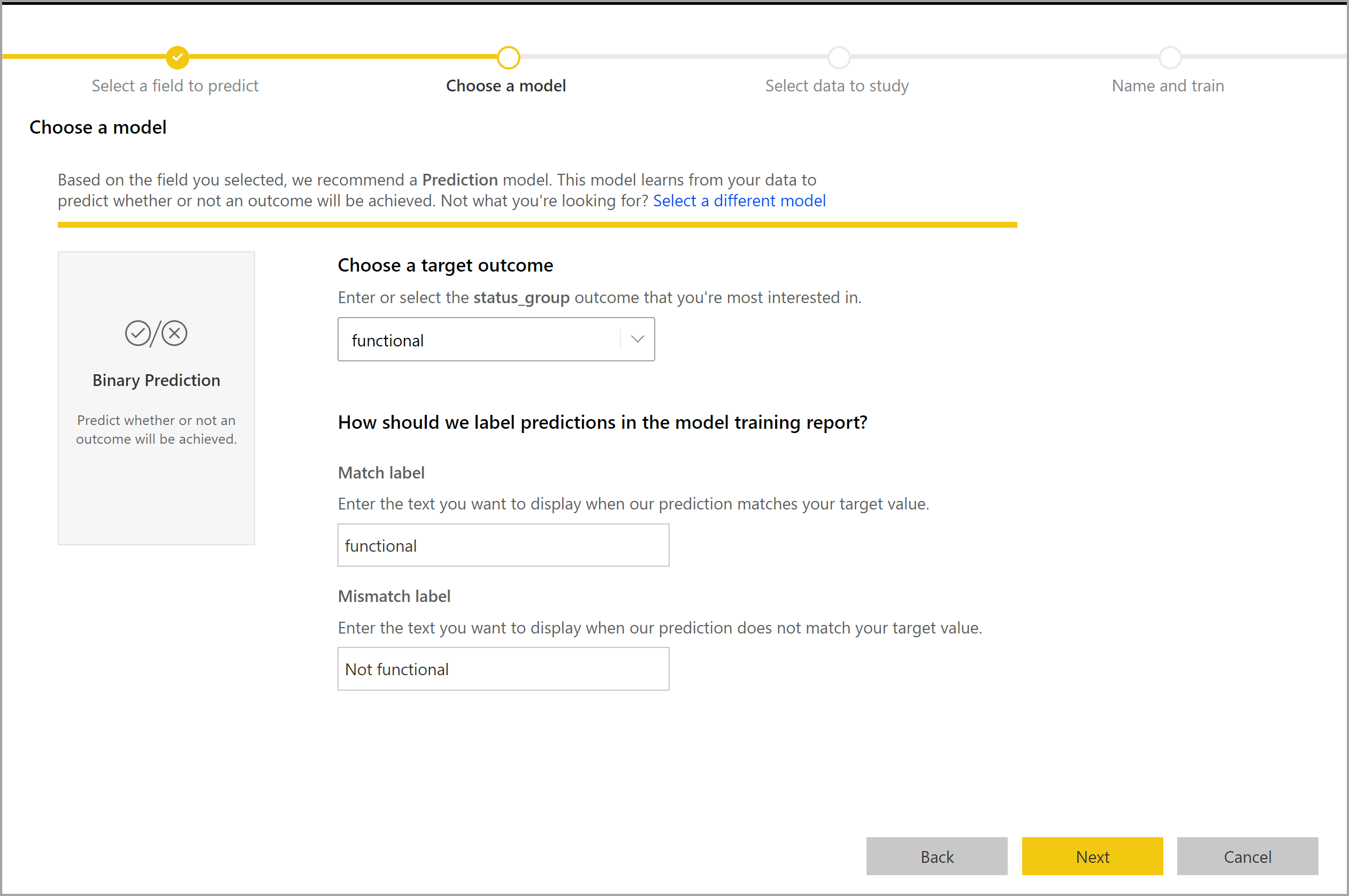
Le processus de création d’un modèle de prédiction binaire suit les mêmes étapes que les autres modèles AutoML, décrits dans la section précédente, Configurer les entrées du modèle Machine Learning. La seule différence se trouve au niveau de l’étape Choisir un modèle, où vous pouvez sélectionner la valeur de résultat cible qui vous intéresse le plus. Vous pouvez également fournir des étiquettes conviviales pour les résultats à utiliser dans le rapport généré automatiquement qui synthétise les résultats de la validation du modèle.
Rapport de modèle de prédiction binaire
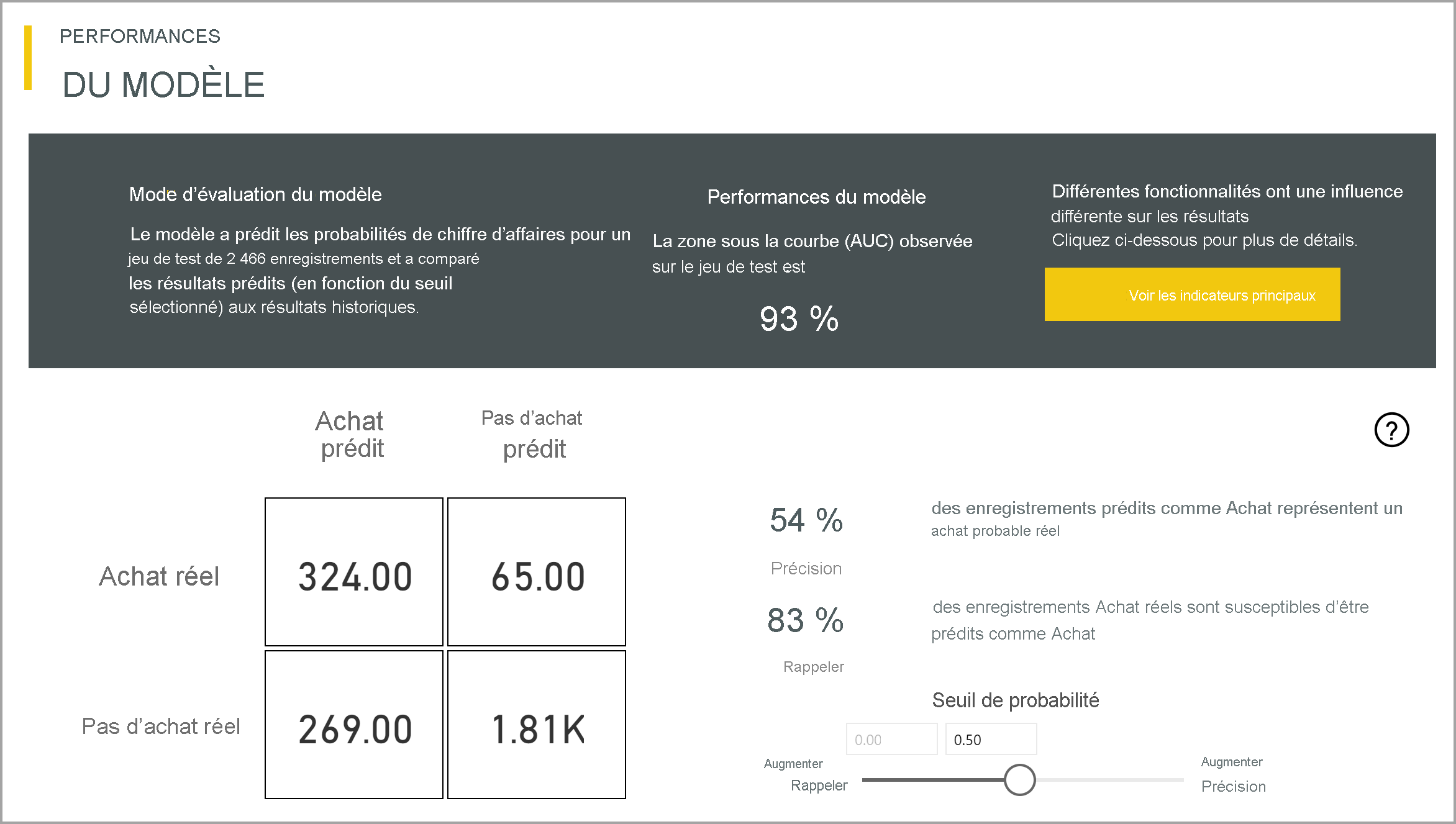
Le modèle de prédiction binaire permet de connaître la probabilité pour qu’une ligne atteigne le résultat cible. Le rapport comprend un segment pour le seuil de probabilité, qui détermine la façon dont les scores supérieurs et inférieurs au seuil de probabilité sont interprétés.
Le rapport décrit les performances du modèle en termes de Vrais positifs, Faux positifs, Vrais négatifs et Faux négatifs. Les vrais positifs et vrais négatifs sont des résultats prédits correctement pour les deux classes dans les données de résultat. Les faux positifs sont des lignes pour lesquelles il a été prédit qu’elles atteindraient le résultat cible, alors qu’elles ne l’ont pas atteint. À l’inverse, les faux négatifs sont des lignes qui ont atteint le résultat cible, mais pour lesquelles cela n’avait pas été prédit.
Les mesures, telles que la précision et le rappel, décrivent l’effet du seuil de probabilité sur les résultats prédits. Vous pouvez utiliser le segment de seuil de probabilité pour sélectionner un seuil qui atteint un compromis équilibré entre précision et rappel.
Le rapport comprend également un outil d’analyse coût-avantages permettant d’identifier le sous-ensemble de la population qui doit être ciblé afin d’obtenir les bénéfices les plus élevés. L’analyse coût-avantages tente d’optimiser les bénéfices en se basant sur l’estimation du coût unitaire de ciblage et sur l’avantage unitaire obtenu en atteignant le résultat cible. Vous pouvez utiliser cet outil pour choisir votre seuil de probabilité basé sur le point maximal du graphe en vue d’optimiser les bénéfices. Vous pouvez également utiliser le graphe pour calculer les bénéfices ou les coûts associés à votre choix de seuil de probabilité.
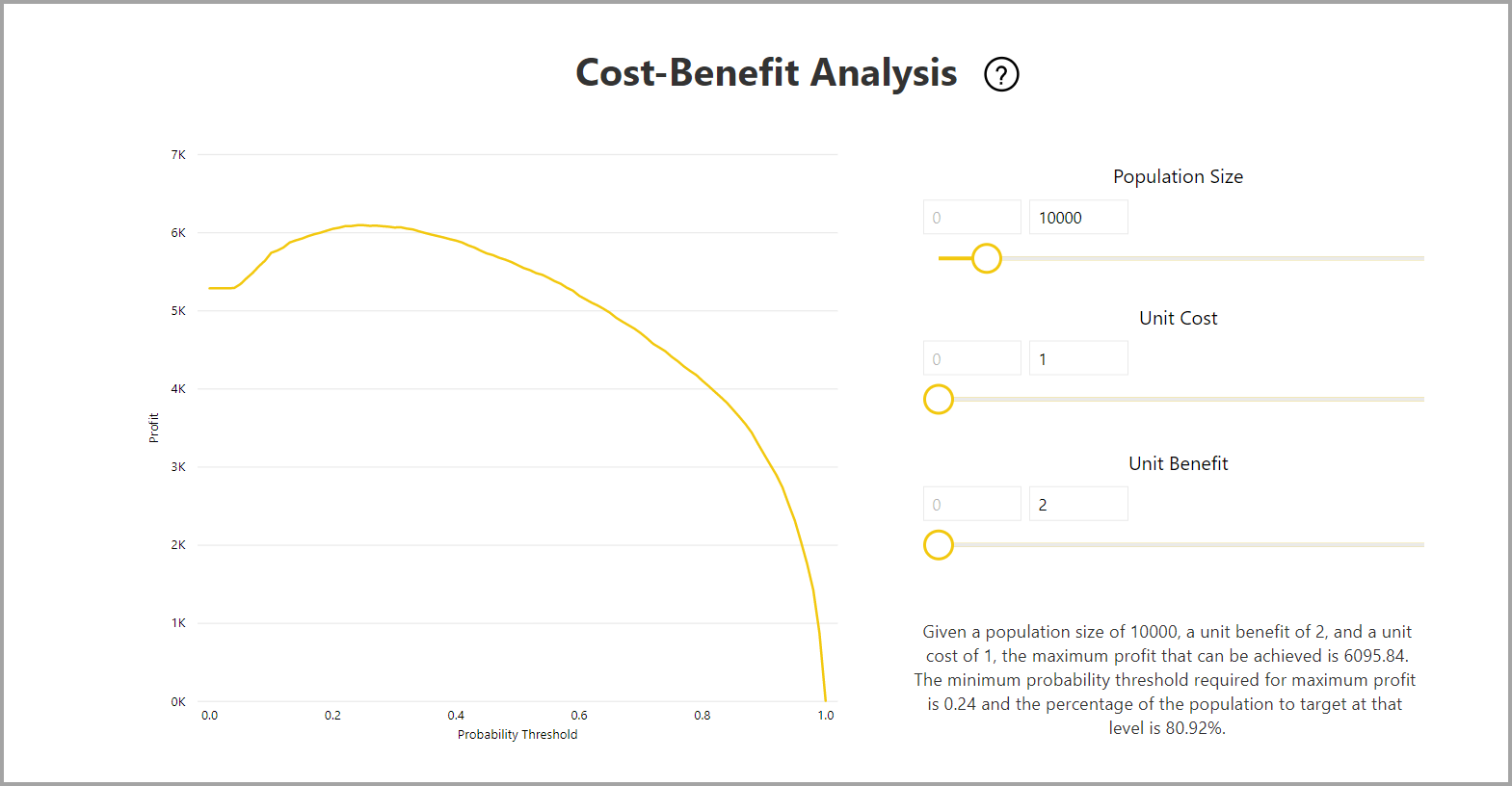
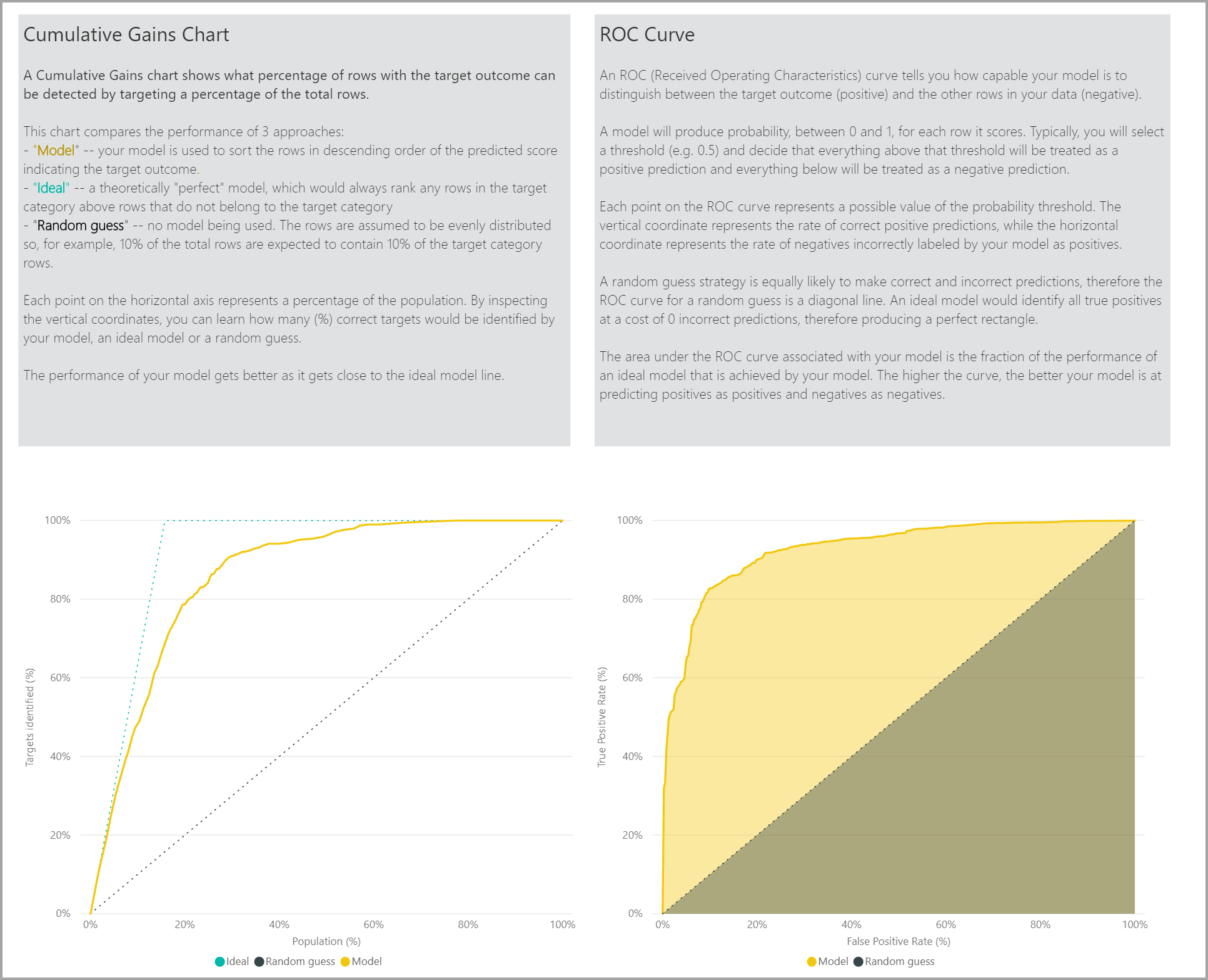
La page Rapport de précision du rapport de modèle comprend le graphique Gains cumulés et la courbe ROC pour le modèle. Ces données fournissent des mesures statistiques des performances du modèle. Les rapports incluent des descriptions des graphiques affichés.
Appliquer un modèle de prédiction binaire
Pour appliquer un modèle de prédiction binaire, vous devez spécifier la table avec les données auxquelles vous souhaitez appliquer les prédictions à partir du modèle Machine Learning. Les autres paramètres incluent le préfixe du nom de la colonne de sortie et le seuil de probabilité pour la classification des résultats prédits.
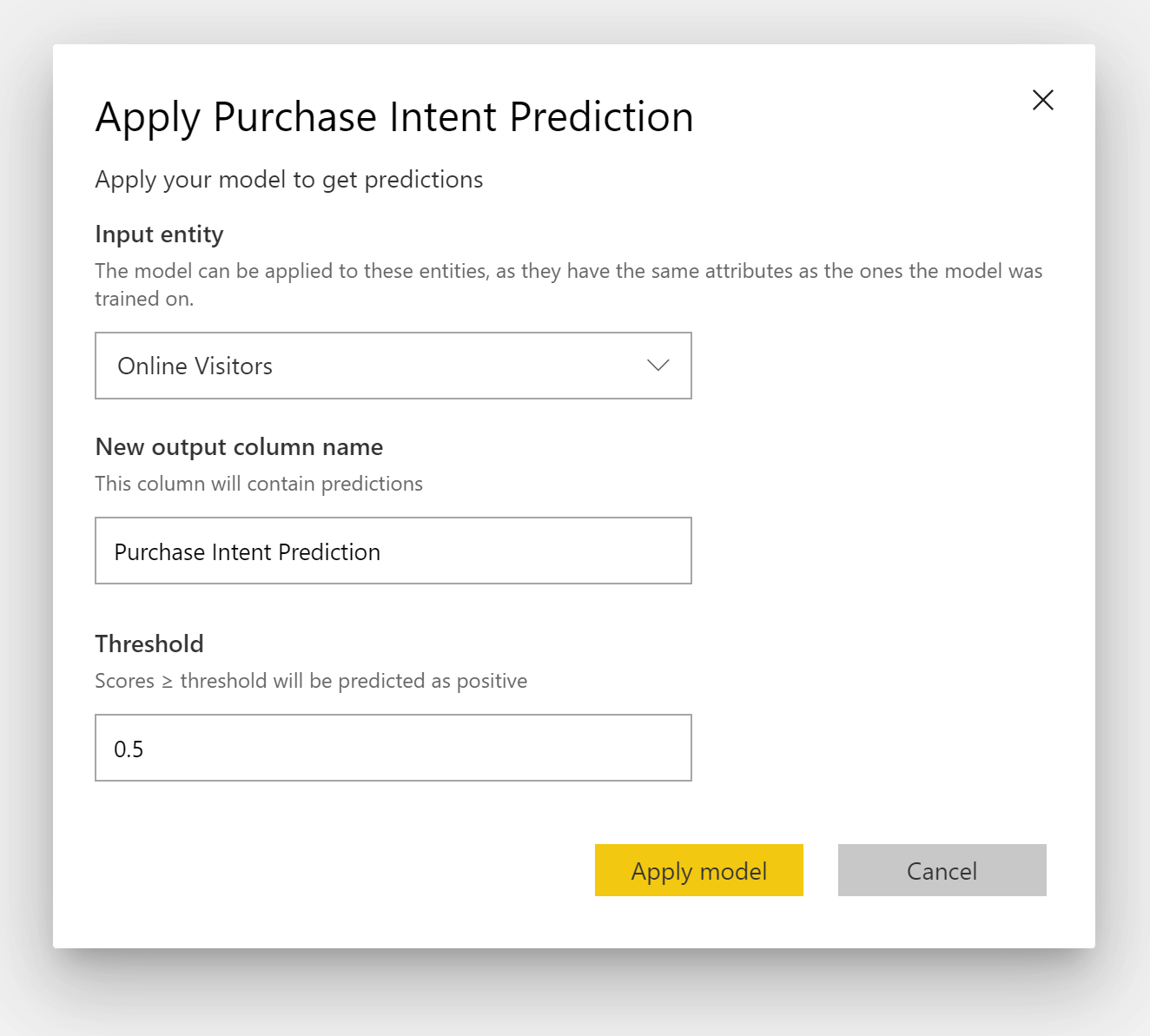
Lorsqu’un modèle de prédiction binaire est appliqué, celui-ci ajoute quatre colonnes de sortie à la table de sortie enrichie : Outcome, PredictionScore, PredictionExplanation et ExplanationIndex. Le préfixe est spécifié pour les noms de colonnes de la table lorsque le modèle est appliqué.
PredictionScore est un pourcentage de probabilité correspondant à la probabilité que le résultat cible soit obtenu.
La colonne Outcome contient l’étiquette du résultat prédit. Les enregistrements avec des probabilités qui dépassent le seuil sont prédits comme susceptibles d’obtenir le résultat cible et sont étiquetés avec la valeur True. Les enregistrements inférieurs au seuil de probabilité sont prédits comme peu susceptibles d’obtenir le résultat et sont étiquetés avec la valeur False.
La colonne PredictionExplanation contient une explication de l’influence spécifique que les fonctionnalités d’entrée avaient sur le PredictionScore.
Modèles de classification
Les modèles de classification sont utilisés pour classer un modèle sémantique en plusieurs groupes ou classes. Ils sont utilisés pour prédire les événements pouvant avoir l’un des nombreux résultats possibles. Par exemple, si un client est susceptible d’avoir une valeur de durée de vie élevée, moyenne ou faible. Ils peuvent également prédire si le risque de défaut est élevé, modéré, faible, etc.
La sortie d’un modèle de classification est un score de probabilité qui identifie la probabilité qu’une ligne atteigne les critères d’une classe donnée.
Entraîner un modèle de classification
La table d’entrée contenant les données d’entraînement d’un modèle de classification doit avoir une colonne de chaîne ou une colonne de nombre entier comme colonne de résultat, où sont identifiés les résultats passés connus.
Conditions préalables :
- Au moins 20 lignes de données d’historique sont nécessaires pour chaque classe de résultats
Le processus de création d’un modèle de classification suit les mêmes étapes que les autres modèles AutoML, décrits dans la section précédente, Configurer les entrées du modèle Machine Learning.
Rapport de modèle de classification
Power BI crée le rapport du modèle de classification en appliquant le modèle ML aux données d’exclusion de test. Ensuite, il compare la classe prédite pour une ligne avec la classe connue réelle.
Le rapport de modèle contient un graphique qui comprend la répartition des lignes correctement et incorrectement classées pour chaque classe connue.
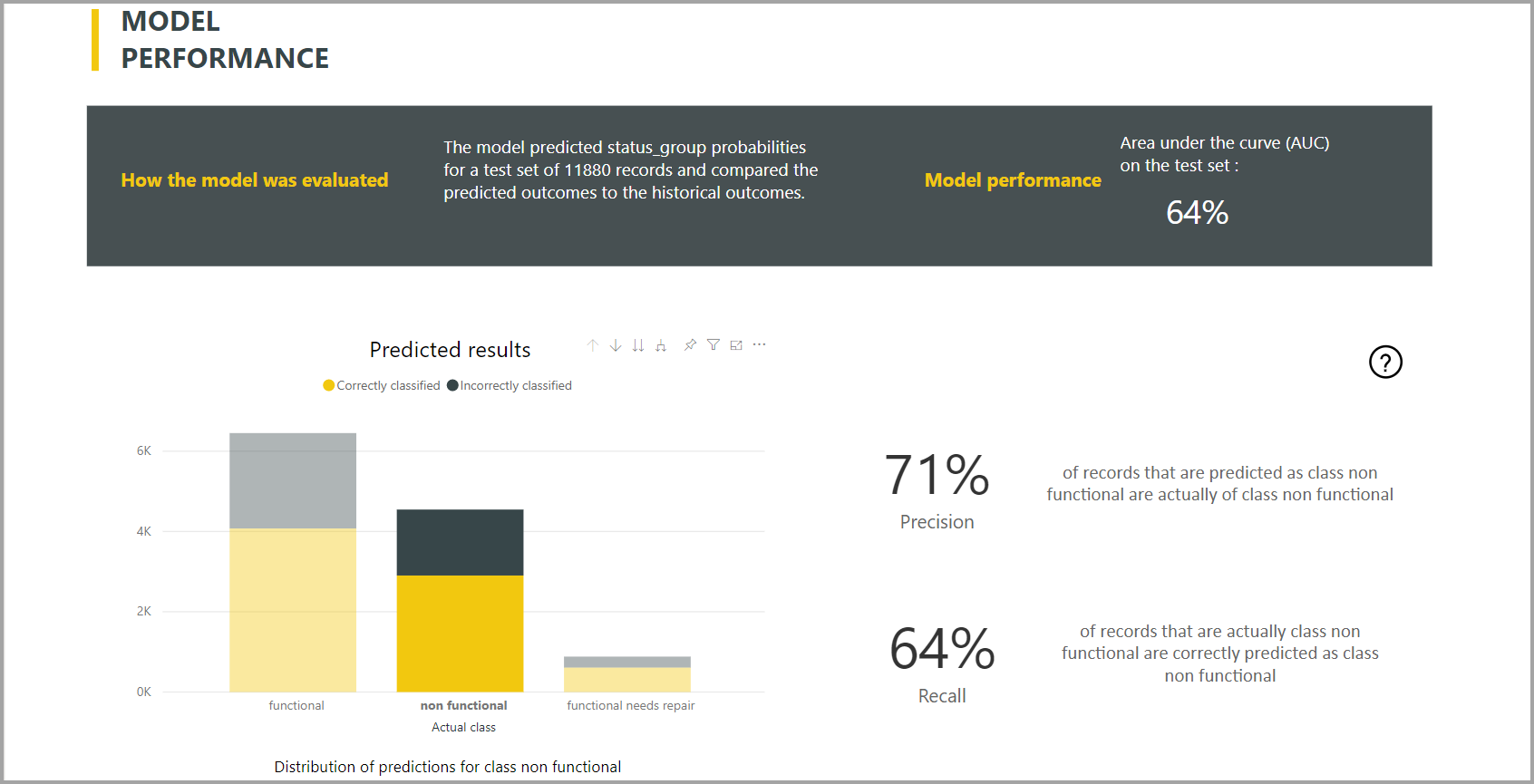
Une autre action d’exploration des détails spécifique à la classe permet d’analyser la manière dont les prédictions d’une classe connue sont distribuées. Cette analyse comprend les autres classes dans lesquelles les lignes de cette classe connue sont susceptibles d’être mal classifiées.
L’explication du modèle dans le rapport comprend également les meilleures prédictions de chaque classe.
Le rapport du modèle de classification comprend également une page Détails de l’entraînement similaire aux pages des autres types de modèles, comme décrit précédemment dans Rapport sur le modèle AutoML.
Appliquer un modèle de classification
Pour appliquer un modèle de classification Machine Learning, vous devez spécifier la table avec les données d’entrée et le préfixe du nom de la colonne de sortie.
Lorsqu’un modèle de classification est appliqué, il ajoute cinq colonnes de sortie à la table de sortie enrichie : ClassificationScore, ClassificationResult, ClassificationExplanation, ClassProbabilities et ExplanationIndex. Le préfixe est spécifié pour les noms de colonnes de la table lorsque le modèle est appliqué.
La colonne ClassProbabilities contient la liste des scores de probabilité pour la ligne de chaque classe possible.
ClassificationScore est un pourcentage de probabilité qui indique la probabilité qu’une ligne atteigne les critères d’une classe donnée.
La colonne ClassificationResult contient la classe prédite comme étant la plus probable pour la ligne.
La colonne ClassificationExplanation explique l’influence que les caractéristiques d’entrée ont eu sur ClassificationScore.
Modèles de régression
Les modèles de régression servent à prédire une valeur numérique et ils peuvent être utilisés dans des scénarios visant à déterminer :
- Le chiffre d’affaires susceptible d’être réalisé à partir d’un contrat de vente.
- La valeur de durée de vie d’un compte.
- Le montant d’une facture client susceptible d’être payée.
- La date à laquelle une facture peut être payée, etc.
La sortie d’un modèle de régression est la valeur prédite.
Formation d’un modèle de régression
La table d’entrée contenant les données d’entraînement d’un modèle de régression doit avoir une colonne numérique comme colonne de résultat, où sont identifiées les valeurs des résultats connus.
Conditions préalables :
- Un modèle de régression nécessite au minimum 100 lignes de données historiques.
Le processus de création d’un modèle de régression suit les mêmes étapes que les autres modèles AutoML, décrits dans la section précédente, Configurer les entrées du modèle Machine Learning.
Rapport sur le modèle de régression
Comme les autres rapports de modèle AutoML, le rapport de régression est basé sur les résultats de l’application du modèle aux données d’exclusion de test.
Le rapport de modèle comprend un graphique qui compare les valeurs prédites aux valeurs réelles. Dans ce graphique, la distance par rapport à la diagonale indique l’erreur dans la prédiction.
Le tableau d’erreurs résiduelles affiche la répartition du pourcentage moyen d’erreur pour les différentes valeurs dans le modèle sémantique d’exclusion de test. L’axe horizontal représente la moyenne de la valeur réelle du groupe. La taille de la bulle reflète la fréquence ou le nombre de valeurs dans cette plage. L’axe vertical est l’erreur résiduelle moyenne.
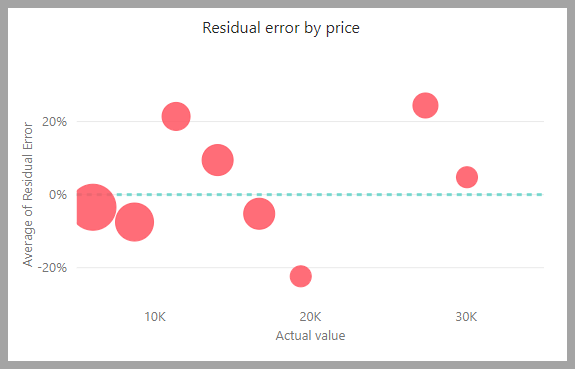
Le rapport du modèle de régression comprend également une page Détails de l’entraînement, comme les rapports des autres types de modèles, comme décrit dans la section précédente, Rapport sur le modèle AutoML.
Appliquer un modèle de régression
Pour appliquer un modèle de régression Machine Learning, vous devez spécifier la table avec les données d’entrée et le préfixe du nom de la colonne de sortie.
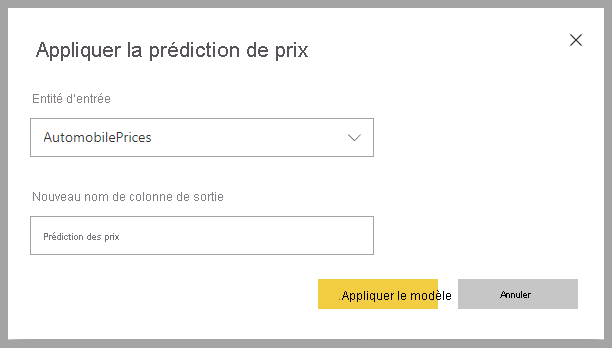
Lorsqu’un modèle de régression est appliqué, il ajoute trois colonnes de sortie à la table de sortie enrichie : RegressionResult, RegressionExplanation et ExplanationIndex. Le préfixe est spécifié pour les noms de colonnes de la table lorsque le modèle est appliqué.
La colonne RegressionResult contient la valeur prédite de la ligne d’après les colonnes d’entrée. La colonne RegressionExplanation explique l’influence que les caractéristiques d’entrée ont eu sur RegressionResult.
Intégration d’Azure Machine Learning dans Power BI
De nombreuses organisations utilisent des modèles Machine Learning pour bénéficier d’insights et de prédictions sur leur activité. Vous pouvez utiliser le Machine Learning avec vos rapports, tableaux de bord et autres analyses pour obtenir ces insights. La possibilité de visualiser et d’appeler des insights à partir de ces modèles peut aider à diffuser ces insights pour les utilisateurs professionnels qui en ont le plus besoin. Power BI facilite désormais l’incorporation des insights tirés de modèles hébergés sur Azure Machine Learning avec des gestes simples de pointer-cliquer.
Pour utiliser cette fonctionnalité, un scientifique des données peut autoriser l’analyste décisionnel à accéder au modèle Azure Machine Learning avec le portail Azure. Ensuite, au début de chaque session, Power Query permet de découvrir tous les modèles Azure Machine Learning auxquels l’utilisateur a accès et les expose en tant que fonctions dynamiques de Power Query. L’utilisateur peut alors appeler ces fonctions en y accédant à partir du ruban dans l’éditeur de Power Query, ou en appelant directement la fonction M. Power BI regroupe automatiquement les demandes d’accès lorsque vous appelez le modèle Azure Machine Learning pour un ensemble de lignes afin d’obtenir de meilleures performances.
Cette fonctionnalité est actuellement uniquement prise en charge pour les flux de données Power BI et pour Power Query Online dans le service Power BI.
Pour en savoir plus sur les dataflows, consultez Introduction aux dataflows et à la préparation des données en libre-service.
Pour en savoir plus sur Azure Machine Learning, consultez :
- Vue d’ensemble : Qu'est-ce que Microsoft Azure Machine Learning ?
- Démarrages rapides et tutoriels pour Azure Machine Learning : Documentation Azure Machine Learning
Octroyer à un utilisateur Power BI l’accès au modèle Azure Machine Learning
Pour accéder à un modèle Azure Machine Learning à partir de Power BI, l’utilisateur doit avoir un accès en lecture à l’abonnement Azure et à l’espace de travail Machine Learning.
Cet article décrit pas à pas comment autoriser un utilisateur de Power BI à accéder à un modèle hébergé sur le service Azure Machine Learning de telle manière que ce modèle soit accessible en tant que fonction Power Query. Pour plus d’informations, consultez Attribuer des rôles Azure en utilisant le portail Azure.
Connectez-vous au portail Azure.
Accédez à la page Abonnements. Vous pouvez trouver la page Abonnements via la liste Tous les services dans le menu du panneau de navigation du portail Azure.

Sélectionnez votre abonnement.

Sélectionnez Contrôle d’accès (IAM), puis le bouton Ajouter.

Sélectionnez le rôle Lecteur. Choisissez ensuite l’utilisateur Power BI auquel vous voulez octroyer l’accès au modèle Azure Machine Learning.
Sélectionnez Enregistrer.
Répétez les étapes 3 à 6 pour octroyer l’accès Lecteur à l’utilisateur pour l’espace de travail Machine Learning spécifique hébergeant le modèle.




Découverte de schéma pour les modèles Machine Learning
Les scientifiques des données utilisent principalement Python pour développer et même déployer leurs modèles Machine Learning pour le Machine Learning. Le scientifique des données doit générer explicitement le fichier de schéma avec Python.
Ce fichier de schéma doit être inclus dans le service web déployé pour les modèles Machine Learning. Pour générer automatiquement le schéma pour le service web, vous devez fournir un exemple d’entrée/de sortie dans le script d’entrée pour le modèle déployé. Pour plus d’informations, consultez Déployer et scorer un modèle Machine Learning en utilisant un point de terminaison en ligne. Le lien inclut l’exemple de script d’entrée avec les instructions pour la génération du schéma.
Plus précisément, les fonctions @input_schema et @output_schema dans le script d’entrée font référence aux formats des échantillons d’entrée et de sortie dans les variables input_sample et output_sample. Les fonctions utilisent ces exemples pour générer une spécification OpenAPI (Swagger) pour le service web pendant le déploiement.
Ces instructions relatives à la génération du schéma en mettant à jour le script d’entrée doivent également être appliquées aux modèles créés à l’aide d’expériences de Machine Learning automatisé avec le SDK Azure Machine Learning.
Notes
Les modèles créés à l’aide de l’interface visuelle d’Azure Machine Learning ne prennent actuellement pas en charge la génération de schéma, mais ils le feront dans de prochaines versions.
Appel du modèle Azure Machine Learning dans Power BI
Vous pouvez appeler tout modèle Azure Machine Learning auquel vous avez le droit d’accéder directement à partir de l’éditeur Power Query dans votre dataflow. Pour accéder aux modèles Azure Machine Learning, sélectionnez le bouton Modifier la table de la table à enrichir avec des insights de votre modèle Azure Machine Learning, comme le montre l’image suivante.

La sélection du bouton Modifier la table ouvre l’éditeur Power Query pour les tables de votre dataflow.

Sélectionnez le bouton Insights IA dans le ruban, puis sélectionnez le dossier Modèles Azure Machine Learning dans le menu du volet de navigation. Tous les modèles Azure Machine Learning auxquels vous avez accès sont listés ici en tant que fonctions Power Query. De plus, les paramètres d’entrée pour le modèle Azure Machine Learning sont automatiquement mappés en tant que paramètres de la fonction Power Query correspondante.
Pour appeler un modèle Azure Machine Learning, vous pouvez définir une des colonnes de la table sélectionnée en tant qu’entrée dans la liste déroulante. Vous pouvez également spécifier une valeur constante à utiliser comme entrée en basculant l’icône de la colonne à gauche de la boîte de dialogue d’entrée.

Sélectionnez Appeler pour afficher l’aperçu de la sortie du modèle Azure Machine Learning sous forme de nouvelle colonne dans la table. L’appel du modèle apparaît comme une étape appliquée pour la requête.

Si le modèle retourne plusieurs paramètres de sortie, ils sont regroupés sous forme de ligne dans la colonne de sortie. Vous pouvez développer la colonne pour produire des paramètres de sortie individuels dans des colonnes distinctes.

Une fois que vous avez enregistré votre dataflow, le modèle est automatiquement appelé quand le dataflow est actualisé, pour toutes les lignes nouvelles ou mises à jour de la table.
Observations et limitations
- Actuellement, Dataflows Gen2 ne s’intègre pas au Machine Learning automatisé.
- Les insights IA (modèles Cognitive Services et Azure Machine Learning) ne sont pas pris en charge sur les machines avec une configuration d’authentification proxy.
- Les modèles Azure Machine Learning ne sont pas pris en charge pour les utilisateurs invités.
- L’utilisation de la passerelle avec AutoML et Cognitive Services pose quelques problèmes connus. Si vous avez besoin d’utiliser une passerelle, nous vous recommandons de créer un flux de données qui importe d’abord les données nécessaires via la passerelle. Créez ensuite un autre flux de données qui fait référence au premier flux de données pour créer ou appliquer ces modèles et fonctions IA.
- Si votre travail d’IA avec des flux de données échoue, il est possible que vous deviez activer la combinaison rapide lors d’une utilisation de l’IA avec des flux de données. Une fois que vous avez importé votre table et avant de commencer à ajouter des fonctionnalités d’IA, sélectionnez Options dans le ruban Accueil, puis dans la fenêtre qui s’affiche, sélectionnez la case à cocher à côté d’Autoriser la combinaison de données provenant de plusieurs sources pour activer la fonctionnalité, puis sélectionnez OK pour enregistrer votre sélection. Vous pouvez ensuite ajouter des fonctionnalités d’IA à votre flux de données.
Contenu connexe
Cet article donne une vue d’ensemble du Machine Learning automatisé pour les dataflows dans le service Power BI. Les articles suivants peuvent également vous être utiles.
- Tutoriel : Créer un modèle Machine Learning dans Power BI
- Tutoriel : Utiliser Cognitive Services dans Power BI
Les articles suivants vous permettront d’en savoir plus sur les dataflows et Power BI :
- Introduction aux dataflows et à la préparation des données en libre-service
- Création d’un flux de données
- Configurer et consommer un dataflow
- Configurer le stockage de flux de données pour utiliser Azure Data Lake Gen 2
- Fonctionnalités Premium des dataflows
- Considérations et limitations relatives aux flux de données
- Bonnes pratiques pour les dataflows
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour