Utiliser des notebooks Jupyter dans Azure Data Studio
S’applique à :![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Jupyter Notebook est une application web open source qui vous permet de créer et de partager des documents contenant du code en temps réel, des équations, des visualisations et du texte narratif. L’utilisation inclut le nettoyage des données et la transformation, la simulation numérique, la modélisation statistique, la visualisation des données et le machine learning.
Cet article explique comment créer un notebook dans la dernière version d’Azure Data Studio et comment commencer à créer vos propres notebooks à l’aide de différents noyaux.
Regardez cette courte vidéo (cinq minutes) de présentation des notebooks dans Azure Data Studio :
Créer un notebook
Il existe plusieurs façons de créer un notebook. Dans chaque cas, un nouveau fichier nommé Notebook-1.ipynb s’ouvre.
Accédez au menu Fichier dans Azure Data Studio, puis sélectionnez Nouveau notebook.
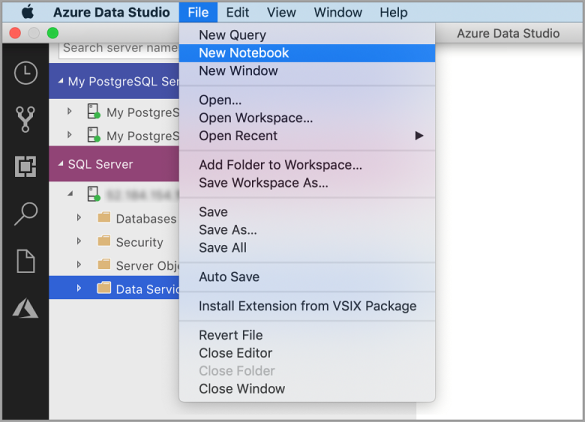
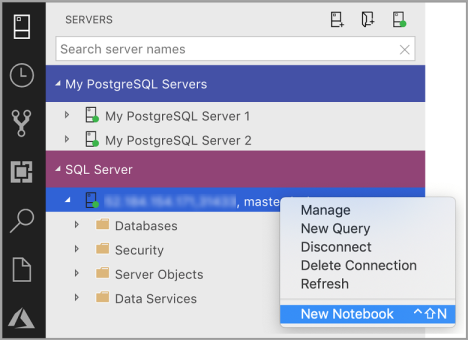
Cliquez avec le bouton droit sur une connexion SQL Server et sélectionnez Nouveau notebook.
Ouvrez la palette de commandes (Ctrl+Maj+P), tapez « nouveau notebook », puis sélectionnez la commande Nouveau notebook.

Se connecter à un noyau
Les notebooks Azure Data Studio prennent en charge plusieurs noyaux, notamment SQL Server, Python et PySpark. Chaque noyau prend en charge un langage différent dans les cellules de code de votre notebook. Par exemple, quand vous êtes connecté au noyau SQL Server, vous pouvez entrer et exécuter des instructions T-SQL dans une cellule de code de notebook.
Attacher à fournit le contexte pour le noyau. Par exemple, si vous utilisez le noyau SQL, vous pouvez attacher n’importe laquelle de vos instances SQL Server. Si vous utilisez le noyau Python3, vous attachez à localhost et vous pouvez utiliser ce noyau pour votre développement Python local.
Le noyau SQL peut également être utilisé pour se connecter à des instances de serveur PostgreSQL. Si vous êtes développeur PostgreSQL et que vous souhaitez connecter les notebooks à votre serveur PostgreSQL, téléchargez l’extension PostgreSQL sur la Place de marché d’extensions Azure Data Studio et connectez-vous au serveur PostgreSQL.
Si vous êtes connecté à un cluster Big Data SQL Server 2019, la valeur par défaut d’Attacher à est le point de terminaison du cluster. Vous pouvez soumettre du code Python, Scala et R à l’aide du calcul Spark du cluster.
| Noyau | Description |
|---|---|
| Noyau SQL | Écrivez du code SQL ciblé sur votre base de données relationnelle. |
| Noyau PySpark3 et PySpark | Écrivez du code Python à l’aide du calcul Spark à partir du cluster. |
| Noyau Spark | Écrivez du code Scala et R à l’aide du calcul Spark à partir du cluster. |
| Noyau Python | Écrivez du code Python pour le développement local. |
Pour plus d’informations sur les noyaux spécifiques, consultez :
- Créer et exécuter un notebook SQL Server
- Créer et exécuter un notebook Python
- Extension Kqlmagic dans Azure Data Studio : étend les fonctionnalités du noyau python
Ajouter une cellule de code
Les cellules de code vous permettent d’exécuter du code de manière interactive dans le notebook.
Pour ajouter une nouvelle cellule de code, cliquez sur la commande + Cellule dans la barre d’outils et sélectionnez Cellule de code. Une nouvelle cellule de code est ajoutée après la cellule actuellement sélectionnée.
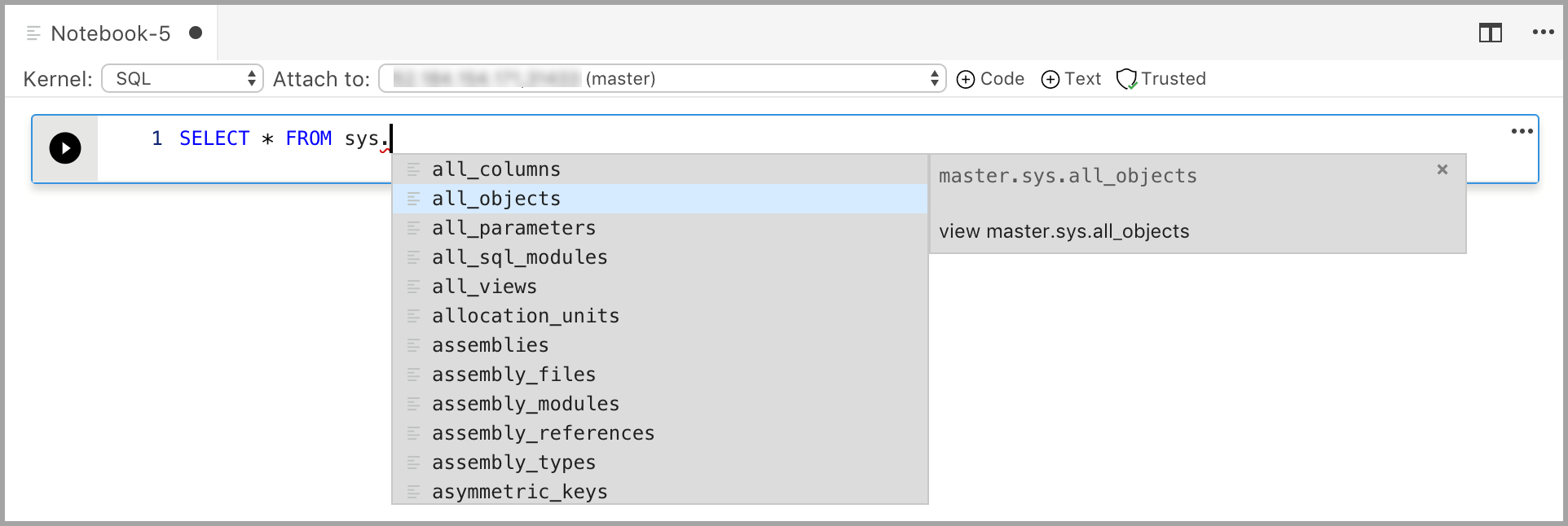
Entrez du code dans la cellule pour le noyau sélectionné. Par exemple, si vous utilisez le noyau SQL, vous pouvez entrer des commandes T-SQL dans la cellule de code.
La saisie de code avec le noyau SQL est similaire à un éditeur de requête SQL. La cellule de code prend en charge une expérience de codage SQL moderne avec des fonctionnalités intégrées, telles qu’un riche éditeur SQL, IntelliSense et des extraits de code intégrés. Les extraits de code vous permettent de générer la syntaxe SQL appropriée pour créer des bases de données, des tables, des vues et des procédures stockées ainsi que pour mettre à jour des objets de base de données existants. Utilisez les extraits de code pour créer rapidement des copies de votre base de données à des fins de développement ou de test, et pour générer et exécuter des scripts.
Ajouter une cellule de texte
Les cellules de texte vous permettent de documenter votre code en ajoutant des blocs de texte Markdown entre les cellules de code.
Pour ajouter une nouvelle cellule de texte, cliquez sur la commande + Cellule dans la barre d’outils et sélectionnez Cellule de texte.
La cellule commence en mode édition, dans lequel vous pouvez taper le texte Markdown. À mesure que vous tapez, un aperçu est affiché en dessous.
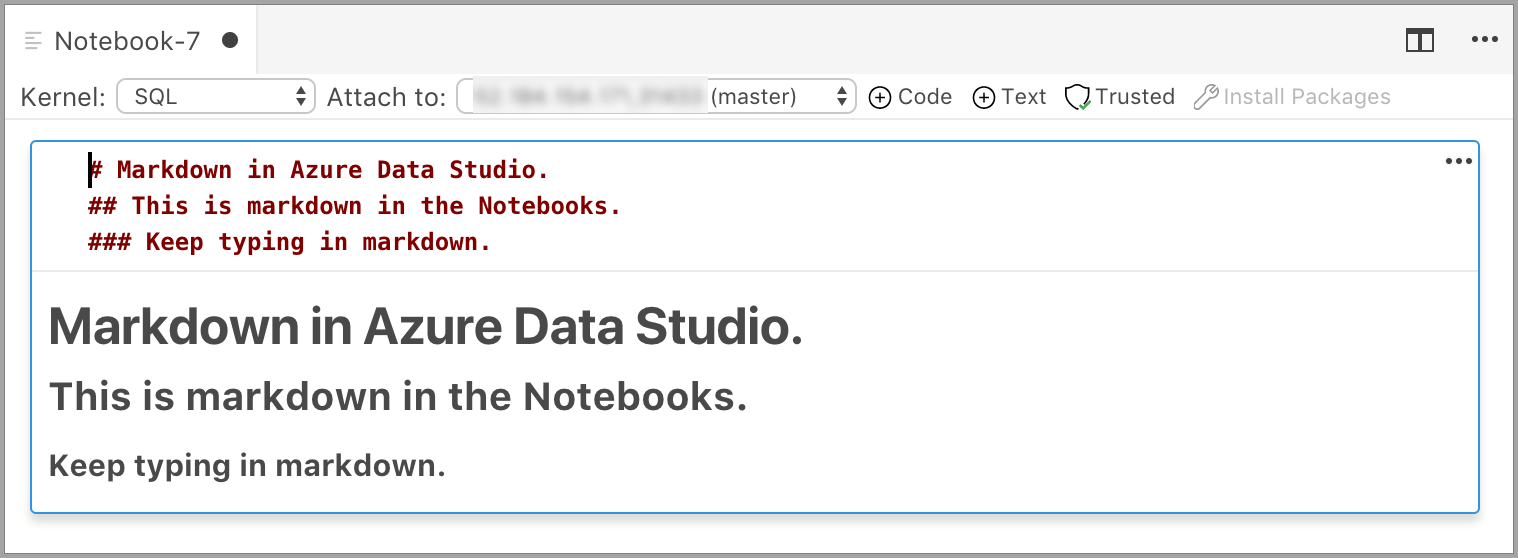
Si vous sélectionnez un élément en dehors de la cellule de texte, le texte Markdown apparaît.
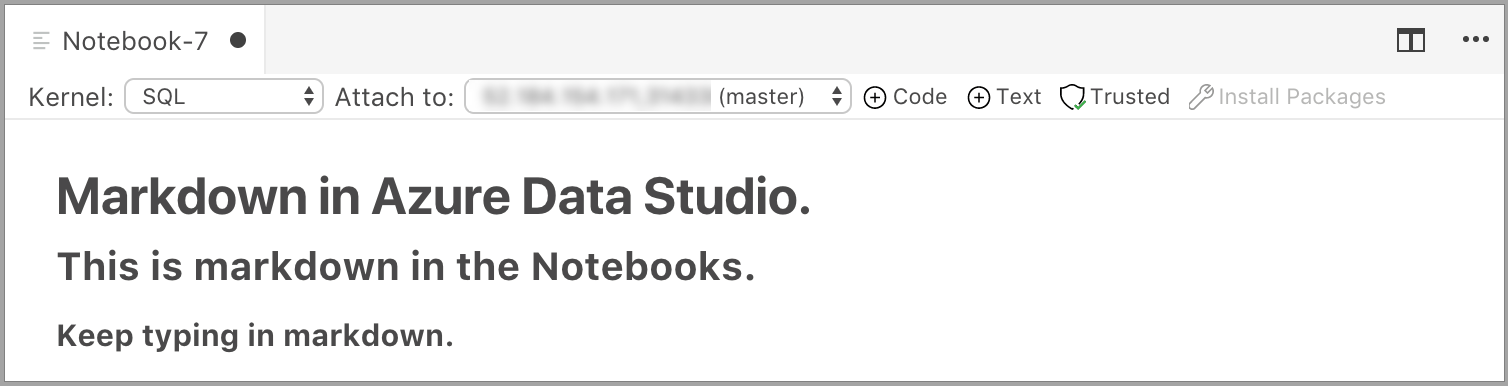
Si vous cliquez à nouveau sur la cellule de texte, elle passe en mode édition.
Exécuter une cellule
Pour exécuter une cellule unique, cliquez sur Exécuter la cellule (flèche noire ronde) à gauche de la cellule, ou sélectionnez la cellule et appuyez sur F5. Vous pouvez exécuter toutes les cellules du notebook en cliquant sur Tout exécuter dans la barre d’outils. Les cellules sont exécutées une à la fois, et l’exécution s’arrête si une erreur est rencontrée dans une cellule.
Les résultats de la cellule s’affichent sous la cellule. Vous pouvez effacer les résultats de toutes les cellules exécutées dans le notebook en sélectionnant le bouton Effacer les résultats dans la barre d’outils.
Enregistrer un notebook
Pour enregistrer un notebook, effectuez l’une des opérations suivantes.
- Tapez Ctrl+S
- Dans le menu Fichier, sélectionnez Enregistrer
- Dans le menu Fichier, sélectionnez Enregistrer sous
- Dans le menu Fichier, sélectionnez Tout enregistrer : cela enregistre tous les notebooks ouverts
- Dans la palette de commandes, entrez Fichier : Enregistrer
Les notebooks sont enregistrés en tant que fichiers .ipynb.
Approuvé et non approuvé
Les notebooks ouverts dans Azure Data Studio sont approuvés par défaut.
Si vous ouvrez un notebook à partir d’une autre source, il est ouvert en mode non approuvé. Vous pouvez ensuite le rendre approuvé.
Exemples
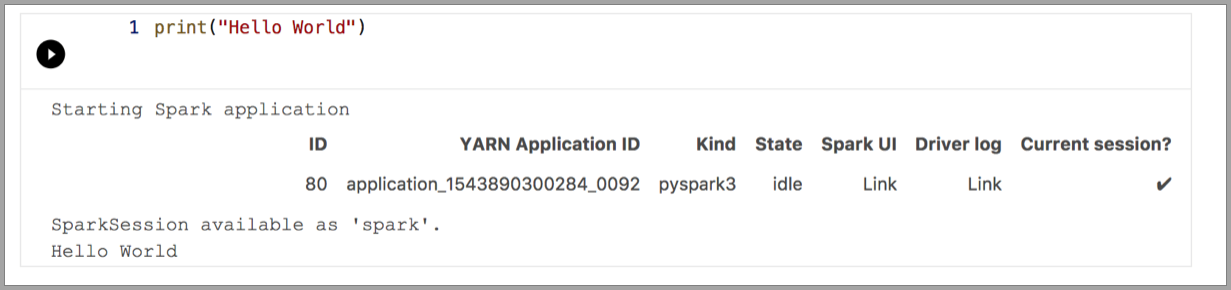
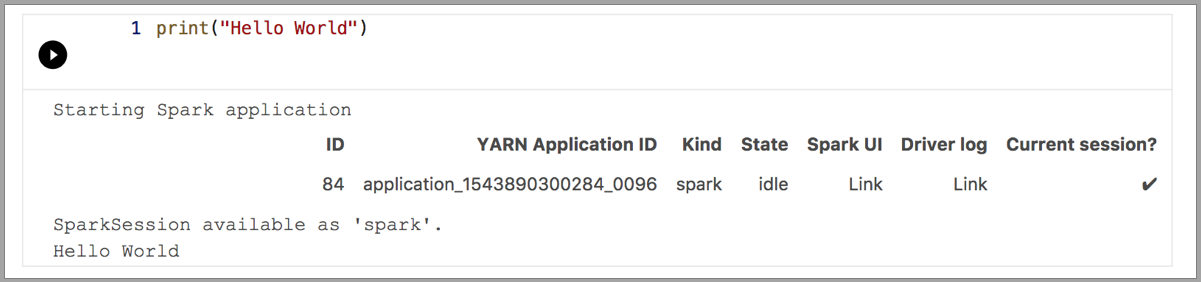
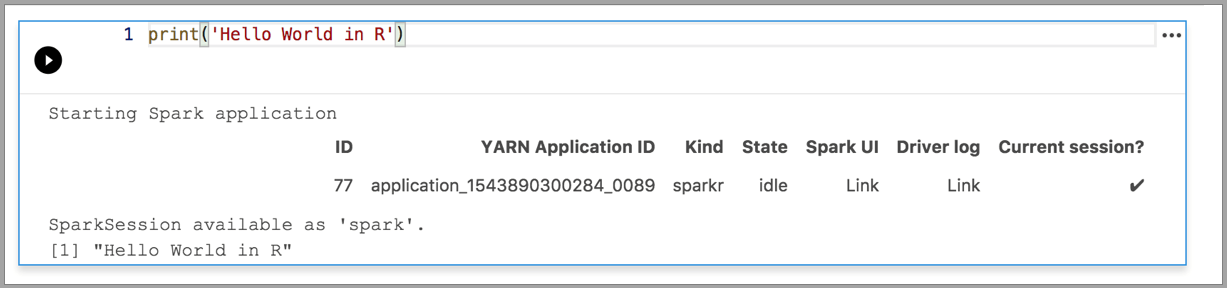
Les exemples suivants illustrent l’utilisation de différents noyaux pour exécuter une simple commande « Hello World ». Sélectionnez le noyau, entrez l’exemple de code dans une cellule, puis cliquez sur Exécuter la cellule.
Pyspark
Spark | Langage Scala
Spark | Langage R
Python 3

Étapes suivantes
- Créer et exécuter un notebook SQL Server.
- Créer et exécuter un notebook Python
- Exécuter des scripts Python et R dans des notebooks Azure Data Studio avec SQL Server Machine Learning Services.
- Déployer un cluster Big Data SQL Server avec un notebook Azure Data Studio.
- Gérer des clusters Big Data SQL Server avec des notebooks Azure Data Studio.
- Exécuter un exemple de notebook avec Spark.
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour