Option de détection de l’intégrité au niveau base de données du groupe de disponibilité pour le basculement
S’applique à :![]() SQL Server
SQL Server
À compter de SQL Server 2016, l’option de détection de l’intégrité au niveau base de données (DB_FAILOVER) est disponible lors de la configuration d’un groupe de disponibilité Always On. La détection de l’état d’intégrité au niveau base de données indique quand une base de données n’est plus en ligne ou quand un problème se produit, puis déclenche le basculement automatique du groupe de disponibilité. Les exemples qui peuvent déclencher la détection d’intégrité incluent une base de données en mode suspect, une base de données hors connexion et une base de données en cours de récupération (échec de la récupération). Pour plus d’informations, consultez Colonne State dans sys.databases.
La détection de l’intégrité au niveau base de données est activée pour le groupe de disponibilité dans son ensemble : par conséquent, la détection d’intégrité au niveau base de données surveille chaque base de données du groupe de disponibilité. Elle ne peut pas être activée sélectivement pour des bases de données spécifiques du groupe de disponibilité.
Avantages de l’option de détection de l’intégrité au niveau base de données
L’option de détection de l’intégrité au niveau base de données du groupe de disponibilité est une option largement recommandée pour contribuer à garantir la haute disponibilité pour vos bases de données. Envisagez de l’activer pour tous les groupes de disponibilité. Si votre application dépend de la haute disponibilité de plusieurs bases de données, regroupez-les dans un groupe de disponibilité avec l’option de détection de l’intégrité des bases de données activée.
Par exemple, avec l’option de détection de l’intégrité au niveau base de données, si SQL Server n’a pas pu écrire dans le fichier journal des transactions pour une des bases de données, l’état de cette base de données va changer et indiquer cet échec : le groupe de disponibilité est sur le point de basculer tandis que votre application peut se reconnecter et continuer à fonctionner avec une interruption minimale une fois que les bases de données sont à nouveau en ligne.
Activation de l’option Détection de l’état d’intégrité au niveau base de données
Bien qu’elle soit généralement recommandée, l’option d’intégrité des bases de données est désactivée par défaut afin de conserver la compatibilité descendante avec les paramètres par défaut des versions antérieures.
Il existe plusieurs façons d’activer le paramètre de détection de l’intégrité au niveau base de données :
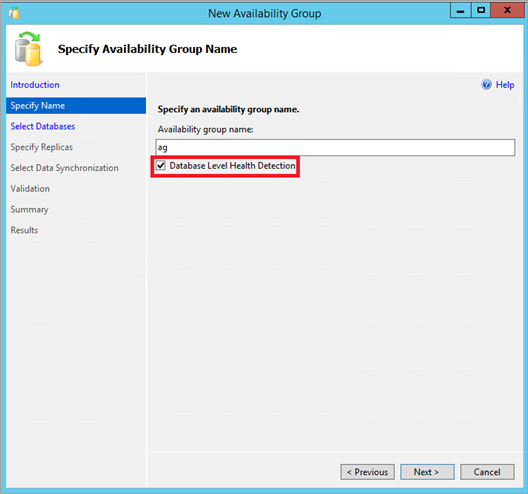
Dans SQL Server Management Studio, connectez-vous au moteur de base de données de votre serveur SQL Server. Dans la fenêtre de l’Explorateur d’objets, cliquez avec le bouton droit sur le nœud de Haute disponibilité Always On et lancez l’Assistant Nouveau groupe de disponibilité. Cochez la case Détection de l’état d’intégrité au niveau base de données sur la page Spécifier le nom. Ensuite, complétez le reste des pages pour terminer l’Assistant.
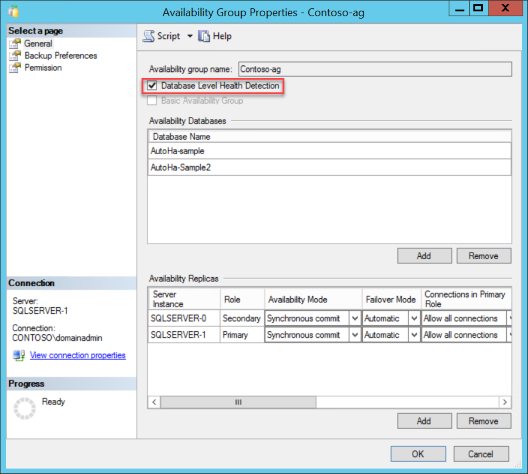
Affichez les Propriétés d’un groupe de disponibilité existant dans SQL Server Management Studio. Connectez-vous à votre serveur SQL Server. Dans la fenêtre de l’Explorateur d’objets, développez le nœud Haute disponibilité Always On. Développez Groupes de disponibilité. Cliquez avec le bouton droit sur le groupe de disponibilité et choisissez Propriétés. Activez l’option Détection de l’état d’intégrité au niveau base de données, puis cliquez sur OK ou générez un script avec la modification.
Syntaxe Transact-SQL pour CREATE AVAILABILITY GROUP. Le paramètre DB_FAILOVER accepte les valeurs ON ou OFF.
CREATE AVAILABILITY GROUP [Contoso-ag] WITH (DB_FAILOVER=ON) FOR DATABASE [AutoHa-Sample] REPLICA ON N'SQLSERVER-0' WITH (ENDPOINT_URL = N'TCP://SQLSERVER-0.DOMAIN.COM:5022', FAILOVER_MODE = AUTOMATIC, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT), N'SQLSERVER-1' WITH (ENDPOINT_URL = N'TCP://SQLSERVER-1.DOMAIN.COM:5022', FAILOVER_MODE = AUTOMATIC, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT);Syntaxe Transact-SQL pour ALTER AVAILABILITY GROUP. Le paramètre DB_FAILOVER accepte les valeurs ON ou OFF.
ALTER AVAILABILITY GROUP [Contoso-ag] SET (DB_FAILOVER = ON); ALTER AVAILABILITY GROUP [Contoso-ag] SET (DB_FAILOVER = OFF);
Mises en garde
Il est important de noter qu’actuellement l’option Détection de l’état d’intégrité au niveau base de données n’implique pas que SQL Server surveille le bon fonctionnement des disques. SQL Server ne surveille pas non plus directement la disponibilité des fichiers de base de données. Si un lecteur de disque est en échec ou devient non disponible, ce seul événement ne déclenche pas nécessairement le basculement automatique du groupe de disponibilité.
Par exemple, quand une base de données est inactive, sans aucune transaction active et sans qu’aucune écriture physique ne se produise, si certains fichiers de base de données deviennent inaccessibles, SQL Server peut n’effectuer aucune E/S en lecture ou en écriture sur les fichiers, ni changer l’état de cette base de données immédiatement : un basculement n’est donc pas déclenché. Par la suite, quand un point de contrôle de base de données est effectué, ou qu’il se produit une lecture ou une écriture physique pour répondre à une requête, SQL Server peut alors découvrir le problème relatif au fichier et réagir en changeant l’état de la base de données. Ensuite, le groupe de disponibilité pour lequel la détection d’intégrité au niveau base de données a été activée bascule en raison du changement de l’intégrité de la base de données.
Voici un autre exemple : quand le moteur de base de données SQL Server doit lire une page de données pour répondre à une requête, si la page de données est mise en cache dans le pool de mémoires tampons, un accès physique au disque peut ne pas être nécessaire pour répondre à la demande de la requête. Ainsi, un fichier de données manquant ou non disponible peut ne pas déclencher immédiatement un basculement automatique, même quand l’option d’intégrité de base de données est activée, car l’état de la base de données n’est pas mis à jour immédiatement.
Le basculement des bases de données est distinct de la stratégie de basculement flexible
La détection de l’état d’intégrité au niveau base de données implémente une stratégie de basculement flexible qui configure les seuils d’intégrité du processus SQL Server pour la stratégie de basculement. La détection de l’état d’intégrité au niveau base de données est configurée à l’aide du paramètre DB_FAILOVER, tandis que l’option FAILURE_CONDITION_LEVEL du groupe de disponibilité est distincte pour la configuration de la détection de l’état d’intégrité du processus SQL Server. Les deux options sont indépendantes.
Gestion et surveillance de la détection de l’état d’intégrité au niveau base de données
Vues de gestion dynamique
La vue de gestion dynamique système sys.availability_groups contient une colonne db_failover, qui indique si l’option de détection de l’état d’intégrité au niveau base de données est désactivée (0) ou activée (1).
select name, db_failover from sys.availability_groups
Exemple de sortie de la vue de gestion dynamique :
| name | db_failover |
|---|---|
| Contoso-ag | 1 |
ErrorLog
Le journal des erreurs de SQL Server (ou le texte retourné par sp_readerrorlog) affiche le message d’erreur 41653 quand un groupe de disponibilité a basculé en raison des contrôles de la détection de l’état d’intégrité au niveau base de données.
Par exemple, cet extrait de journal des erreurs montre qu’une écriture dans le journal des transactions a échoué en raison d’un problème de disque, et que par la suite, la base de données nommée AutoHa-Sample a été arrêtée, ce qui a déclenché le basculement du groupe de disponibilité par la détection de l’état d’intégrité au niveau base de données.
25-04-2016 12:20:21.08 spid1s Erreur : 17053, Gravité : 16, État : 1.
25-04-2016 12:20:21.08 spid1s SQLServerLogMgr::LogWriter: erreur du système d’exploitation 21(Le périphérique n’est pas prêt.). 25-04-2016 12:20:21.08 spid1s Erreur d’écriture lors du vidage du journal.
25-04-2016 12:20:21.08 spid79 Erreur : 9001, Gravité : 21, État : 4.
25-04-2016 12:20:21.08 spid79 Le journal de la base de données « AutoHa-Sample » n’est pas disponible. Consultez le journal des événements pour voir s'il contient des messages d'erreur liés à ce problème. Résolvez toutes les erreurs et redémarrez la base de données.
25-04-2016 12:20:21.15 spid79 Erreur : 41653, Gravité : 21, État : 1.
25-04-2016 12:20:21.15 spid79 La base de données « AutoHa-Sample » a rencontré une erreur (type d’erreur : 2 ’DB_SHUTDOWN’) entraînant une défaillance du groupe de disponibilité « Contoso-ag ». Reportez-vous au journal des erreurs de SQL Server pour en apprendre davantage sur les erreurs rencontrées. Si cette situation persiste, contactez l’administrateur système.
25-04-2016 12:20:21.17 spid79 Informations d’état de la base de données « AutoHa-Sample » - LSN sécurisé de manière renforcée : « (34:664:1) » LSN de validation : « (34:656:1) » Heure de validation : « 25 avril 2016 12:19 »
25-04-2016 12:20:21.19 spid15s Connexion des groupes de disponibilité Always On avec la base de données secondaire interrompue pour la base de données principale « AutoHa-Sample » sur le réplica de disponibilité « SQLServer-0 » associé à l’ID de réplica : {c4ad5ea4-8a99-41fa-893e-189154c24b49}. Ce message est fourni uniquement à titre d'information. Aucune action de l'utilisateur n'est requise.
25-04-2016 12:20:21.21 spid75 Always On : le réplica local du groupe de disponibilité « Contoso-ag » est en cours de préparation pour passer au rôle principal en réponse à une demande du cluster pour le clustering de basculement Windows Server (WSFC). Ce message est fourni uniquement à titre d'information. Aucune action de l'utilisateur n'est requise.
25-04-2016 12:20:21.21 spid75 L’état du réplica de disponibilité local du groupe de disponibilité « ag » est passé de « PRIMARY_NORMAL » à « RESOLVING_NORMAL ». L’état a changé, car le groupe de disponibilité passe hors connexion. Le réplica passe hors connexion, car le groupe de disponibilité associé a été supprimé, ou l’utilisateur a passé hors connexion le groupe de disponibilité associé dans la console de gestion WSFC, ou le groupe de disponibilité bascule sur une autre instance de SQL Server. Pour plus d’informations, consultez le journal des erreurs SQL Server, la console de gestion WSFC ou le journal WSFC.
Événement étendu sqlserver.availability_replica_database_fault_reporting
Il s’agit d’un nouvel événement étendu défini à compter de SQL Server 2016, qui est déclenché par la détection de l’état d’intégrité au niveau base de données. Le nom de l’événement est sqlserver.availability_replica_database_fault_reporting
Cet événement étendu est déclenché seulement sur le réplica principal. Cet événement étendu est déclenché quand un problème d’état d’intégrité au niveau base de données est détecté pour une base de données hébergée dans un groupe de disponibilité.
Voici un exemple de création d’une session XEvent qui capture cet événement. Comme aucun chemin n’est spécifié, le fichier de sortie XEvent doit se trouver dans le chemin par défaut du journal des erreurs SQL Server. Exécutez ceci sur le réplica principal de votre groupe de disponibilité :
Exemple de script de session d’événements étendus
CREATE EVENT SESSION [AlwaysOn_dbfault] ON SERVER
ADD EVENT sqlserver.availability_replica_database_fault_reporting
ADD TARGET package0.event_file(SET filename=N'dbfault.xel',max_file_size=(5),max_rollover_files=(4))
WITH (MAX_MEMORY=4096 KB,EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS,MAX_DISPATCH_LATENCY=30 SECONDS,
MAX_EVENT_SIZE=0 KB,MEMORY_PARTITION_MODE=NONE,TRACK_CAUSALITY=OFF,STARTUP_STATE=ON)
GO
ALTER EVENT SESSION AlwaysOn_dbfault ON SERVER STATE=START
GO
Sortie des événements étendus
Dans SQL Server Management Studio, connectez-vous au serveur SQL Server principal, développez le nœud Gestion puis développez Événements étendus. Recherchez la session (AlwaysOn_dbfault était le nom dans l’exemple ci-dessus) et développez-le pour voir les fichiers de sortie. Sélectionnez le fichier de sortie : le fichier d’événements s’ouvre alors dans un nouvel onglet.
Explication des champs :
| Données de la colonne | Description |
|---|---|
| availability_group_id | ID du groupe de disponibilité. |
| availability_group_name | Nom du groupe de disponibilité. |
| availability_replica_id | ID du réplica de disponibilité. |
| availability_replica_name | Nom du réplica de disponibilité. |
| database_name | Nom de la base de données signalant l’erreur. |
| database_replica_id | ID de la base de données du réplica de disponibilité. |
| failover_ready_replicas | Nombre de réplicas secondaires du basculement automatique qui sont synchronisés. |
| fault_type | ID de l’erreur signalée. Valeurs possibles : 0 - AUCUN 1 - Inconnu 2 - Arrêt |
| is_critical | À compter de SQL Server 2016, cette valeur doit toujours retourner true pour l’événement étendu. |
Dans cet exemple de sortie, fault_type indique qu’un événement critique s’est produit sur le groupe de disponibilité Contoso-ag, sur le réplica nommé SQLSERVER-1, en raison de la base de données nommée AutoHa-Sample2, avec le type d’erreur 2 - Shutdown (Arrêt).
| Champ | Valeur |
|---|---|
| availability_group_id | 24E6FE58-5EE8-4C4E-9746-491CFBB208C1 |
| availability_group_name | Contoso-ag |
| availability_replica_id | 3EAE74D1-A22F-4D9F-8E9A-DEFF99B1F4D1 |
| availability_replica_name | SQLSERVER-1 |
| database_name | AutoHa-Sample2 |
| database_replica_id | 39971379-8161-4607-82E7-098590E5AE00 |
| failover_ready_replicas | 1 |
| fault_type | 2 |
| is_critical | Vrai |
Références connexes
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour