Tutoriel : Utiliser Stockage Blob Azure avec SQL Server
S’applique à :![]() SQL Server 2016 (13.x) et ultérieur
SQL Server 2016 (13.x) et ultérieur
Ce tutoriel vous aide à comprendre comment utiliser le Stockage Blob Azure pour les fichiers de données et les sauvegardes dans SQL Server 2016 et versions ultérieures.
La prise en charge de l’intégration de SQL Server pour stockage Blob Azure a commencé en tant qu’amélioration de SQL Server 2012 Service Pack 1 CU2 et a été améliorée avec SQL Server 2014 et SQL Server 2016. Pour obtenir une vue d’ensemble des fonctionnalités et des avantages offerts, consultez Fichiers de données SQL Server dans Microsoft Azure.
Ce didacticiel vous montre comment utiliser des fichiers de données SQL Server dans Stockage Blob Azure en plusieurs parties. Chaque partie porte sur une tâche spécifique et les différentes parties doivent être traitées dans l’ordre. Tout d’abord, vous allez apprendre à créer un conteneur dans Stockage Blob Azure avec une stratégie d’accès stockée et une signature d’accès partagé. Ensuite, vous découvrirez comment créer des informations d’identification SQL Server pour intégrer SQL Server à Stockage Blob Azure. Ensuite, vous sauvegarderez une base de données dans Stockage Blob Azure et la restaurerez dans une machine virtuelle Azure. Vous allez ensuite utiliser la sauvegarde du journal des transactions de capture instantanée de fichiers SQL Server pour effectuer une restauration à un point dans le temps et dans une nouvelle base de données. Enfin, pour illustrer les sauvegardes d’instantanés de fichiers et leur utilisation, le didacticiel vous montrera comment utiliser des fonctions et procédures stockées système de métadonnées.
Prerequisites
Pour suivre ce tutoriel, vous devez être familiarisé avec les concepts de sauvegarde et de restauration SQL Server et la syntaxe T-SQL.
Pour utiliser ce didacticiel, vous avez besoin d’un compte de stockage Azure, de SQL Server Management Studio (SSMS), d’un accès à une instance de SQL Server locale, d’un accès à une machine virtuelle Azure exécutant une instance de SQL Server 2016 ou version ultérieure et d’une AdventureWorks2022 base de données. Par ailleurs, le compte utilisé pour émettre les commandes BACKUP et RESTORE doit figurer dans le rôle de base de données db_backupoperator avec les autorisations modifier les informations d’identification.
- Obtenir gratuitement un compte Azure.
- Créez un compte de stockage Azure.
- Installez SQL Server 2017 Developer Edition.
- Approvisionnez une machine virtuelle Azure exécutant SQL Server
- Installez SQL Server Management Studio.
- Téléchargez un échantillon de base de données AdventureWorks.
- Affectez le compte utilisateur au rôle de db_backupoperator et autorisez modifier les informations d’identification.
Important
SQL Server ne prend pas en charge Azure Data Lake Storage, vérifiez que l’espace de noms hiérarchique n’est pas activé sur le compte de stockage utilisé pour ce didacticiel.
1 : créer une stratégie d’accès stockée et un stockage d’accès partagé
Dans cette section, vous allez utiliser un script Azure PowerShell pour créer une signature d’accès partagé sur un conteneur stockage Blob Azure à l’aide d’une stratégie d’accès stockée.
Note
Ce script est écrit à l’aide d’Azure PowerShell 5.0.10586.
Une signature d’accès partagé est un URI qui octroie des droits d’accès restreints aux conteneurs, aux objets blob, aux files d’attente ou aux tables. Une stratégie d’accès stockée fournit un niveau de contrôle supplémentaire sur des signatures d’accès partagé côté serveur, notamment en matière de révocation, d’expiration ou d’extension d’un accès. Si vous utilisez cette nouvelle amélioration, vous devez créer une stratégie sur un conteneur avec au minimum des droits en lecture, en écriture et en création de liste.
Vous pouvez créer une stratégie d’accès stockée et une signature d’accès partagé à l’aide d’Azure PowerShell, du kit de développement logiciel (SDK) Stockage Azure, de l’API REST Azure ou d’un utilitaire tiers. Ce didacticiel montre comment utiliser un script Azure PowerShell pour effectuer cette tâche. Le script utilise le modèle de déploiement Resource Manager et crée les ressources suivantes :
- Resource group
- Compte de stockage
- Conteneur de stockage d'objets blob Azure
- Stratégie SAP
Ce script commence par déclarer plusieurs variables pour spécifier les noms des ressources ci-dessus et les noms des valeurs d’entrée requises suivantes :
- Un nom de préfixe utilisé pour nommer les autres objets de ressource
- Nom d’abonnement
- Emplacement du centre de données
Le script se termine par la génération de l’instruction CREATE CREDENTIAL appropriée, que vous utiliserez dans 2 : créer des informations d’identification SQL Server à l’aide d’une signature d’accès partagé. Cette instruction est automatiquement copiée dans le Presse-papiers et apparaît dans la console.
Pour créer une stratégie sur le conteneur et générer une signature d’accès partagé (SAP), procédez comme suit :
Ouvrez Windows PowerShell ou Windows PowerShell ISE (voir plus haut la version requise).
Modifiez, puis exécutez le script ci-dessous :
# Define global variables for the script $prefixName = '<a prefix name>' # used as the prefix for the name for various objects $subscriptionID = '<your subscription ID>' # the ID of subscription name you will use $locationName = '<a data center location>' # the data center region you will use $storageAccountName= $prefixName + 'storage' # the storage account name you will create or use $containerName= $prefixName + 'container' # the storage container name to which you will attach the SAS policy with its SAS token $policyName = $prefixName + 'policy' # the name of the SAS policy # Set a variable for the name of the resource group you will create or use $resourceGroupName=$prefixName + 'rg' # Add an authenticated Azure account for use in the session Connect-AzAccount # Set the tenant, subscription and environment for use in the rest of Set-AzContext -SubscriptionId $subscriptionID # Create a new resource group - comment out this line to use an existing resource group New-AzResourceGroup -Name $resourceGroupName -Location $locationName # Create a new Azure Resource Manager storage account - comment out this line to use an existing Azure Resource Manager storage account New-AzStorageAccount -Name $storageAccountName -ResourceGroupName $resourceGroupName -Type Standard_RAGRS -Location $locationName # Get the access keys for the Azure Resource Manager storage account $accountKeys = Get-AzStorageAccountKey -ResourceGroupName $resourceGroupName -Name $storageAccountName # Create a new storage account context using an Azure Resource Manager storage account $storageContext = New-AzStorageContext -StorageAccountName $storageAccountName -StorageAccountKey $accountKeys[0].Value # Creates a new container in Blob Storage $container = New-AzStorageContainer -Context $storageContext -Name $containerName # Sets up a Stored Access Policy and a Shared Access Signature for the new container $policy = New-AzStorageContainerStoredAccessPolicy -Container $containerName -Policy $policyName -Context $storageContext -StartTime $(Get-Date).ToUniversalTime().AddMinutes(-5) -ExpiryTime $(Get-Date).ToUniversalTime().AddYears(10) -Permission rwld # Gets the Shared Access Signature for the policy $sas = New-AzStorageContainerSASToken -name $containerName -Policy $policyName -Context $storageContext Write-Host 'Shared Access Signature= '$($sas.Substring(1))'' # Sets the variables for the new container you just created $container = Get-AzStorageContainer -Context $storageContext -Name $containerName $cbc = $container.CloudBlobContainer # Outputs the Transact SQL to the clipboard and to the screen to create the credential using the Shared Access Signature Write-Host 'Credential T-SQL' $tSql = "CREATE CREDENTIAL [{0}] WITH IDENTITY='Shared Access Signature', SECRET='{1}'" -f $cbc.Uri,$sas.Substring(1) $tSql | clip Write-Host $tSql # Once you're done with the tutorial, remove the resource group to clean up the resources. # Remove-AzResourceGroup -Name $resourceGroupNameune fois le script terminé, l’instruction CREATE CREDENTIAL se trouve dans le Presse-papiers pour une utilisation dans la partie suivante.
2 : créer des informations d’identification SQL Server à l’aide d’une signature d’accès partagé
Dans cette section, vous allez créer des informations d’identification pour stocker les informations de sécurité qui seront utilisées par SQL Server pour écrire et lire à partir du conteneur Stockage Blob Azure que vous avez créé à l’étape précédente.
Les informations d'identification SQL Server sont des objets utilisés pour stocker les informations d'authentification requises pour la connexion à une ressource en dehors de SQL Server. Les informations d’identification stockent le chemin d’URI du conteneur Stockage Blob Azure et la signature d’accès partagé pour ce conteneur.
Pour créer des informations d’identification SQL Server, procédez comme suit :
Lancez SSMS.
Ouvrez une nouvelle fenêtre de requête et connectez-vous à l’instance SQL Server du moteur de base de données dans votre environnement local.
Dans la nouvelle fenêtre de requête, collez l’instruction CREATE CREDENTIAL avec la signature d’accès partagé issue de la parte 1, puis exécutez ce script.
Le script ressemble au code suivant.
/* Example: USE master CREATE CREDENTIAL [https://msfttutorial.blob.core.windows.net/containername] WITH IDENTITY='SHARED ACCESS SIGNATURE' , SECRET = 'sharedaccesssignature' GO */ USE master CREATE CREDENTIAL [https://<mystorageaccountname>.blob.core.windows.net/<mystorageaccountcontainername>] -- this name must match the container path, start with https and must not contain a forward slash at the end WITH IDENTITY='SHARED ACCESS SIGNATURE' -- this is a mandatory string and should not be changed , SECRET = 'sharedaccesssignature' -- this is the shared access signature key that you obtained in section 1. GOPour voir toutes les informations d’identification disponibles, exécutez l’instruction suivante dans une fenêtre de requête connectée à votre instance :
SELECT * from sys.credentialsOuvrez une nouvelle fenêtre de requête et connectez-vous à l’instance SQL Server du moteur de base de données sur votre machine virtuelle Azure.
Dans la nouvelle fenêtre de requête, collez l’instruction CREATE CREDENTIAL avec la signature d’accès partagé issue de la parte 1, puis exécutez ce script.
Répétez les étapes 5 et 6 pour toutes les instances SQL Server supplémentaires que vous souhaitez avoir accès au conteneur.
3 - Sauvegarde de base de données vers l’URL
Dans cette section, vous allez sauvegarder la AdventureWorks2022 base de données dans votre instance SQL Server dans le conteneur que vous avez créé dans la section 1.
Note
Si vous souhaitez sauvegarder une base de données SQL Server 2012 (11.x) SP1 CU2+ ou une base de données SQL Server 2014 (12.x) sur ce conteneur, vous pouvez utiliser la syntaxe déconseillée documentée ici pour sauvegarder l’URL à l’aide de la WITH CREDENTIAL syntaxe.
Pour sauvegarder une base de données dans le stockage d’objets blob, procédez comme suit :
Lancez SSMS.
Ouvrez une nouvelle fenêtre de requête et connectez-vous à l’instance SQL Server dans votre machine virtuelle Azure.
Copiez et collez le script Transact-SQL suivant dans la fenêtre de requête. Modifiez l’URL en fonction du nom de votre compte de stockage et du conteneur que vous avez spécifiés dans la partie 1, puis exécutez ce script.
-- To permit log backups, before the full database backup, modify the database to use the full recovery model. USE master; ALTER DATABASE AdventureWorks2022 SET RECOVERY FULL; -- Back up the full AdventureWorks2022 database to the container that you created in section 1 BACKUP DATABASE AdventureWorks2022 TO URL = 'https://<mystorageaccountname>.blob.core.windows.net/<mystorageaccountcontainername>/AdventureWorks2022_onprem.bak'Ouvrez l’Explorateur d’objets et connectez-vous au stockage Azure à l’aide de votre compte de stockage et de la clé de compte.
- Développez Conteneurs, développez le conteneur que vous avez créé dans la section 1 et vérifiez que la sauvegarde de l’étape 3 ci-dessus apparaît dans ce conteneur.
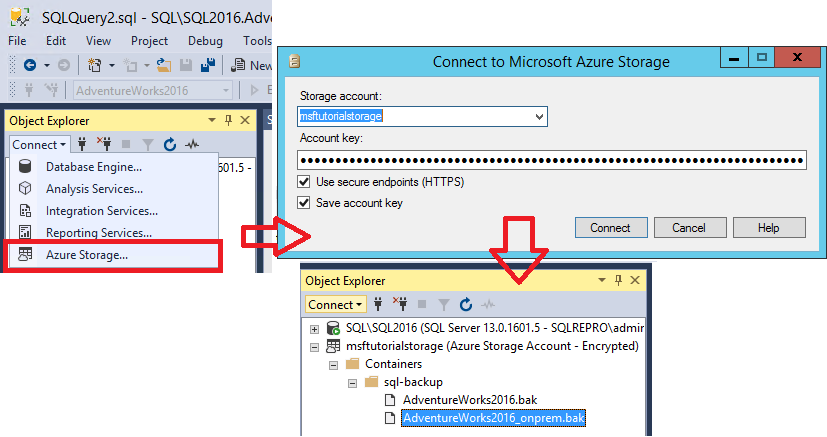
4 : restaurer une base de données sur une machine virtuelle à partir d’une URL
Dans cette section, vous allez restaurer la AdventureWorks2022 base de données sur votre instance SQL Server dans votre machine virtuelle Azure.
Note
Pour simplifier ce didacticiel, nous utilisons le même conteneur pour les fichiers journaux et les données que celui que nous avons utilisé pour la sauvegarde de base de données. Dans un environnement de production, vous utilisez probablement plusieurs conteneurs et souvent plusieurs fichiers de données. Vous pouvez également envisager de supprimer votre sauvegarde sur plusieurs objets blob pour augmenter les performances de sauvegarde lors de la sauvegarde d’une base de données volumineuse.
Pour restaurer la AdventureWorks2022 base de données à partir du Stockage Blob Azure sur votre instance SQL Server sur votre machine virtuelle Azure, procédez comme suit :
Lancez SSMS.
Ouvrez une nouvelle fenêtre de requête et connectez-vous à l’instance SQL Server du moteur de base de données sur votre machine virtuelle Azure.
Copiez et collez le script Transact-SQL suivant dans la fenêtre de requête. Modifiez l’URL en fonction du nom de votre compte de stockage et du conteneur que vous avez spécifiés dans la partie 1, puis exécutez ce script.
-- Restore AdventureWorks2022 from URL to SQL Server instance using Azure Blob Storage for database files RESTORE DATABASE AdventureWorks2022 FROM URL = 'https://<mystorageaccountname>.blob.core.windows.net/<mystorageaccountcontainername>/AdventureWorks2022_onprem.bak' WITH MOVE 'AdventureWorks2022_data' to 'https://<mystorageaccountname>.blob.core.windows.net/<mystorageaccountcontainername>/AdventureWorks2022_Data.mdf' ,MOVE 'AdventureWorks2022_log' to 'https://<mystorageaccountname>.blob.core.windows.net/<mystorageaccountcontainername>/AdventureWorks2022_Log.ldf' --, REPLACEOuvrez l’Explorateur d’objets et connectez-vous à votre instance Azure SQL Server.
Dans l’Explorateur d’objets, développez le nœud Bases de données et vérifiez que la
AdventureWorks2022base de données a été restaurée (actualisez le nœud si nécessaire)- Cliquez avec le bouton droit sur AdventureWorks2022, puis sélectionnez Propriétés.
- Sélectionnez Fichiers et vérifiez que les chemins des deux fichiers de base de données sont des URL pointant vers des objets blob dans votre conteneur Stockage Blob Azure (sélectionnez Annuler lorsque vous avez terminé).
] database on the Azure VM.](media/tutorial-use-azure-blob-storage-service-with-sql-server-2016/adventureworks-on-azure-vm.png?view=sql-server-2017)
Dans l’Explorateur d’objets, connectez-vous au stockage Azure.
- Développez Conteneurs, développez le conteneur que vous avez créé dans la section 1 et vérifiez que l’étape
AdventureWorks2022_Data.mdfAdventureWorks2022_Log.ldf3 ci-dessus apparaît dans ce conteneur, ainsi que le fichier de sauvegarde de la section 3 (actualisez le nœud si nécessaire).
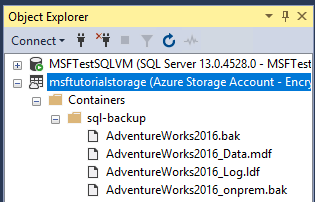
- Développez Conteneurs, développez le conteneur que vous avez créé dans la section 1 et vérifiez que l’étape
5 : sauvegarder une base de données à l’aide d’une sauvegarde d’instantanés de fichiers
Dans cette section, vous allez sauvegarder la AdventureWorks2022 base de données dans votre machine virtuelle Azure à l’aide de la sauvegarde d’instantanés de fichiers pour effectuer une sauvegarde presque instantanée à l’aide d’instantanés Azure. Pour plus d’informations sur les sauvegardes d’instantanés de fichiers, consultez Sauvegarde d’instantanés de fichiers pour les fichiers de base de données dans Azure
Pour sauvegarder la base de données à l’aide de la AdventureWorks2022 sauvegarde d’instantané de fichier, procédez comme suit :
Lancez SSMS.
Ouvrez une nouvelle fenêtre de requête et connectez-vous à l’instance SQL Server du moteur de base de données sur votre machine virtuelle Azure.
Copiez, collez et exécutez le script Transact-SQL suivant dans la fenêtre de requête (ne fermez pas cette fenêtre de requête, vous réexécuterez ce script à l’étape 5. Ce système de procédure stockées vous permet d’afficher les sauvegardes d’instantanés de fichiers existantes pour chaque fichier qui comprend une base de données spécifiée. Notez qu’il n’y a aucune sauvegarde d’instantanés de fichiers pour cette base de données.
-- Verify that no file snapshot backups exist SELECT * FROM sys.fn_db_backup_file_snapshots ('AdventureWorks2022');Copiez et collez le script Transact-SQL suivant dans la fenêtre de requête. Modifiez l’URL en fonction du nom de votre compte de stockage et du conteneur que vous avez spécifiés dans la partie 1, puis exécutez ce script. Notez la rapidité d’exécution de cette sauvegarde.
-- Backup the AdventureWorks2022 database with FILE_SNAPSHOT BACKUP DATABASE AdventureWorks2022 TO URL = 'https://<mystorageaccountname>.blob.core.windows.net/<mystorageaccountcontainername>/AdventureWorks2022_Azure.bak' WITH FILE_SNAPSHOT;Après avoir vérifié que le script de l’étape 4 a été correctement exécuté, réexécutez le script suivant. Notez que l’opération de sauvegarde d’instantanés de fichiers de l’étape 4 a généré des instantanés de fichiers des données et du fichier journal.
-- Verify that two file-snapshot backups exist SELECT * FROM sys.fn_db_backup_file_snapshots ('AdventureWorks2022');
Dans l’Explorateur d’objets, dans votre instance SQL Server de votre machine virtuelle Azure, développez le nœud Bases de données et vérifiez que la
AdventureWorks2022base de données a été restaurée sur cette instance (actualisez le nœud si nécessaire).Dans l’Explorateur d’objets, connectez-vous au stockage Azure.
Développez Conteneurs, développez le conteneur que vous avez créé dans la section 1 et vérifiez que l’étape
AdventureWorks2022_Azure.bak4 ci-dessus apparaît dans ce conteneur, ainsi que le fichier de sauvegarde de la section 3 et les fichiers de base de données de la section 4 (actualisez le nœud si nécessaire).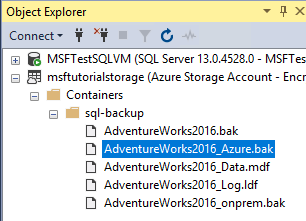
6 : générer un journal d’activité et de sauvegarde à l’aide d’une sauvegarde d’instantanés de fichiers
Dans cette section, vous allez générer une activité dans la base de données et créer régulièrement des sauvegardes de journal des transactions à l’aide AdventureWorks2022 de sauvegardes d’instantanés de fichiers. Pour plus d’informations sur l’utilisation de sauvegardes d’instantanés de fichiers, consultez Sauvegarde d’instantanés de fichiers pour les fichiers de base de données dans Azure.
Pour générer une activité dans la AdventureWorks2022 base de données et créer régulièrement des sauvegardes de journal des transactions à l’aide de sauvegardes d’instantanés de fichiers, procédez comme suit :
Lancez SSMS.
Ouvrez deux nouvelles fenêtres de requête et connectez-vous à l’instance SQL Server du moteur de base de données dans votre machine virtuelle Azure.
Copiez, collez et exécutez le script Transact-SQL suivant dans l’une des fenêtres de requête. Notez que le
Production.Locationtableau comporte 14 lignes avant d’ajouter de nouvelles lignes à l’étape 4.-- Verify row count at start SELECT COUNT (*) from AdventureWorks2022.Production.Location;Copiez et collez les deux scripts Transact-SQL suivants dans les deux fenêtres de requête. Modifiez l’URL en fonction du nom de votre compte de stockage et du conteneur que vous avez spécifié dans la partie 1, puis exécutez ces scripts simultanément dans les fenêtres de requête. L’exécution de ces scripts prendra environ sept minutes.
-- Insert 30,000 new rows into the Production.Location table in the AdventureWorks2022 database in batches of 75 DECLARE @count INT=1, @inner INT; WHILE @count < 400 BEGIN BEGIN TRAN; SET @inner =1; WHILE @inner <= 75 BEGIN; INSERT INTO AdventureWorks2022.Production.Location (Name, CostRate, Availability, ModifiedDate) VALUES (NEWID(), .5, 5.2, GETDATE()); SET @inner = @inner + 1; END; COMMIT; WAITFOR DELAY '00:00:01'; SET @count = @count + 1; END; SELECT COUNT (*) from AdventureWorks2022.Production.Location;--take 7 transaction log backups with FILE_SNAPSHOT, one per minute, and include the row count and the execution time in the backup file name DECLARE @count INT=1, @device NVARCHAR(120), @numrows INT; WHILE @count <= 7 BEGIN SET @numrows = (SELECT COUNT (*) FROM AdventureWorks2022.Production.Location); SET @device = 'https://<mystorageaccountname>.blob.core.windows.net/<mystorageaccountcontainername>/tutorial-' + CONVERT (varchar(10),@numrows) + '-' + FORMAT(GETDATE(), 'yyyyMMddHHmmss') + '.bak'; BACKUP LOG AdventureWorks2022 TO URL = @device WITH FILE_SNAPSHOT; SELECT * from sys.fn_db_backup_file_snapshots ('AdventureWorks2022'); WAITFOR DELAY '00:1:00'; SET @count = @count + 1; END;Examinez la sortie du premier script ; le nombre de lignes final est désormais 29 939.
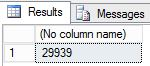
Examinez la sortie du deuxième script ; chaque fois que l’instruction BACKUP LOG est exécutée, deux instantanés de fichiers sont créés, à savoir un instantané de fichier du fichier journal et un instantané de fichier du fichier de données, soit un total de deux instantanés de fichiers par fichier de base de données. Une fois le deuxième script terminé, il existe un total de 16 instantanés de fichiers, à raison de 8 par fichier de base de données (un issu de l’instruction BACKUP DATABASE et un pour chaque exécution de l’instruction BACKUP LOG).
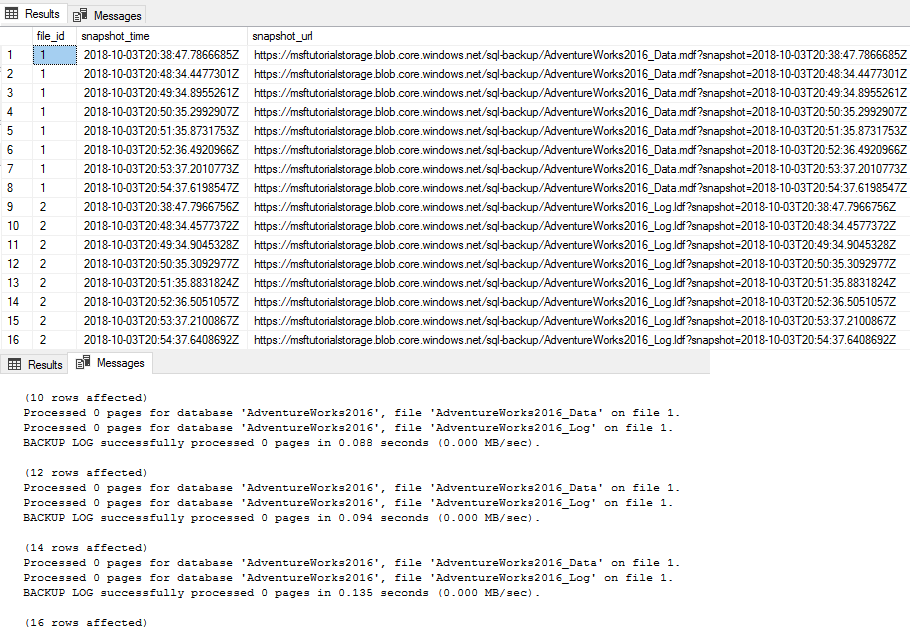
Dans l’Explorateur d’objets, connectez-vous au stockage Azure.
Développez Conteneurs, développez le conteneur que vous avez créé dans la section 1 et vérifiez que sept nouveaux fichiers de sauvegarde apparaissent, ainsi que les fichiers de données des sections précédentes (actualisez le nœud si nécessaire).
7 : restaurer une base de données à un moment donné
Dans cette section, vous allez restaurer la AdventureWorks2022 base de données à un point dans le temps entre deux sauvegardes du journal des transactions.
Avec les sauvegardes traditionnelles, pour obtenir une restauration à un moment donné, vous deviez utiliser la sauvegarde complète de la base de données, peut-être une sauvegarde différentielle, et tous les fichiers journaux des transactions jusqu’au moment où vous vouliez effectuer la restauration et juste après. Avec les sauvegardes d’instantanés de fichiers, vous n’avez besoin que des deux fichiers adjacents de sauvegarde du journal qui délimitent le moment où vous voulez effectuer la restauration. Vous n’avez besoin que de deux jeux de sauvegarde d’instantanés de fichiers journaux, car chaque sauvegarde de journal crée un instantané de chaque fichier de base de données (chaque fichier de données et le fichier journal).
Pour restaurer une base de données à un point spécifié dans le temps à partir de jeux de sauvegarde d’instantanés de fichiers, procédez comme suit :
Lancez SSMS.
Ouvrez une nouvelle fenêtre de requête et connectez-vous à l’instance SQL Server du moteur de base de données sur votre machine virtuelle Azure.
Copiez, collez et exécutez le script Transact-SQL suivant dans la fenêtre de requête. Vérifiez que la
Production.Locationtable comporte 29 939 lignes avant de la restaurer à un point dans le temps où il y a moins de lignes à l’étape 4.-- Verify row count at start SELECT COUNT (*) from AdventureWorks2022.Production.Location
Copiez et collez le script Transact-SQL suivant dans la fenêtre de requête. Sélectionnez deux fichiers de sauvegarde de journal adjacents et remplacez le nom de fichier par la date et l’heure dont vous avez besoin pour ce script. Modifiez l’URL en fonction du nom de votre compte de stockage et du conteneur que vous avez spécifiés dans la partie 1, fournissez les noms des premier et deuxième fichiers de sauvegarde du journal, fournissez l’heure STOPAT au format « June 26, 2018 01:48 PM », puis exécutez ce script. Le script s’exécute pendant quelques minutes
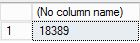
-- restore and recover to a point in time between the times of two transaction log backups, and then verify the row count ALTER DATABASE AdventureWorks2022 SET SINGLE_USER WITH ROLLBACK IMMEDIATE; RESTORE DATABASE AdventureWorks2022 FROM URL = 'https://<mystorageaccountname>.blob.core.windows.net/<mystorageaccountcontainername>/<firstbackupfile>.bak' WITH NORECOVERY,REPLACE; RESTORE LOG AdventureWorks2022 FROM URL = 'https://<mystorageaccountname>.blob.core.windows.net/<mystorageaccountcontainername>/<secondbackupfile>.bak' WITH RECOVERY, STOPAT = 'June 26, 2018 01:48 PM'; ALTER DATABASE AdventureWorks2022 set multi_user; -- get new count SELECT COUNT (*) FROM AdventureWorks2022.Production.Location ;Passez en revue la sortie. Notez qu’après la restauration, le nombre de lignes est 18 389, nombre qui se situe entre les sauvegardes de journal 5 et 6 (le nombre de lignes peut varier).
8 : restaurer une nouvelle base de données à partir de la sauvegarde de journal
Dans cette section, vous allez restaurer la AdventureWorks2022 base de données en tant que nouvelle base de données à partir d’une sauvegarde du journal des transactions d’instantané de fichier.
Dans ce scénario, vous effectuez une restauration vers une instance de SQL Server sur une machine virtuelle différente à des fins d’analyse des activités et de création de rapports. La restauration vers une autre instance sur une autre machine virtuelle permet de déplacer la charge de travail vers une machine virtuelle dédiée et dimensionnée à cet effet, et dont les besoins en ressources n’affectent pas le système transactionnel.
Effectuer une restauration à partir d’une sauvegarde de journal des transactions avec une sauvegarde d’instantanés de fichiers est très rapide, notamment par rapport aux sauvegardes en continu traditionnelles. Dans le cas des sauvegardes en continu traditionnelles, vous devez utiliser la sauvegarde complète de la base de données, éventuellement une sauvegarde différentielle, et tout ou partie des sauvegardes du journal des transactions (ou une nouvelle sauvegarde complète de la base de données). Toutefois, dans le cas des sauvegardes de journaux d’instantanés de fichiers, vous avez uniquement besoin de la dernière sauvegarde de journal (ou toute autre sauvegarde de journal ou deux sauvegardes de journaux voisines pour une restauration à un point dans le temps situé entre deux heures de sauvegarde de journal). En clair, vous avez besoin d’un seul jeu de sauvegarde d’instantanés de fichiers journaux, car chaque sauvegarde de journal d’instantanés de fichiers crée un instantané de fichier de chaque fichier de base de données (chaque fichier de données et le fichier journal).
Pour restaurer une base de données dans une nouvelle base de données à partir d’une sauvegarde du journal des transactions à l’aide de la sauvegarde d’instantanés de fichiers, procédez comme suit :
Lancez SSMS.
Ouvrez une nouvelle fenêtre de requête et connectez-vous à l’instance SQL Server du moteur de base de données dans une machine virtuelle Azure.
Note
S’il s’agit d’une machine virtuelle Azure différente de celle que vous avez utilisée pour les parties précédentes, assurez-vous d’avoir suivi les étapes de 2 : créer des informations d’identification SQL Server à l’aide d’une signature d’accès partagé. Si vous souhaitez restaurer vers un autre conteneur, suivez les étapes de 1 : créer une stratégie d’accès stockée et le stockage de l’accès partagé pour le nouveau conteneur.
Copiez et collez le script Transact-SQL suivant dans la fenêtre de requête. Sélectionnez le fichier de sauvegarde de journal à utiliser. Modifiez l’URL en fonction du nom de votre compte de stockage et du conteneur que vous avez spécifiés dans la partie 1, fournissez le nom du fichier de sauvegarde du journal, puis exécutez ce script.
-- restore as a new database from a transaction log backup file RESTORE DATABASE AdventureWorks2022_EOM FROM URL = 'https://<mystorageaccountname>.blob.core.windows.net/<mystorageaccountcontainername>/<logbackupfile.bak>' WITH MOVE 'AdventureWorks2022_data' to 'https://<mystorageaccountname>.blob.core.windows.net/<mystorageaccountcontainername>/AdventureWorks2022_EOM_Data.mdf' , MOVE 'AdventureWorks2022_log' to 'https://<mystorageaccountname>.blob.core.windows.net/<mystorageaccountcontainername>/AdventureWorks2022_EOM_Log.ldf' , RECOVERY --, REPLACEExaminez la sortie pour vérifier que la restauration a réussi.
Dans l’Explorateur d’objets, connectez-vous au stockage Azure.
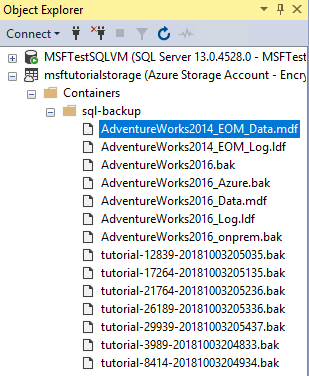
Développez Conteneurs, développez le conteneur que vous avez créé dans la section 1 (actualisez si nécessaire) et vérifiez que les nouveaux fichiers de données et de journaux apparaissent dans le conteneur, ainsi que les objets blob des sections précédentes.
Partie 9 : gérer des jeux de sauvegarde et des sauvegardes d’instantanés de fichiers
Dans cette section, vous allez supprimer un jeu de sauvegarde à l’aide de la procédure stockée système sp_delete_backup (Transact-SQL ). Cette procédure stockée système supprime le fichier de sauvegarde et la capture instantanée de fichier sur chaque fichier de base de données associé à ce jeu de sauvegarde.
Note
Si vous tentez de supprimer un jeu de sauvegarde en supprimant simplement le fichier de sauvegarde du conteneur Stockage Blob Azure, vous supprimez uniquement le fichier de sauvegarde lui-même. Les captures instantanées de fichiers associées restent. Si vous vous trouvez dans ce scénario, utilisez la fonction système sys.fn_db_backup_file_snapshots (Transact-SQL) pour identifier l’URL des instantanés de fichiers orphelins et utiliser la procédure stockée système sp_delete_backup_file_snapshot (Transact-SQL) pour supprimer chaque instantané de fichier orphelin. Pour plus d’informations, consultez Sauvegarde d’instantanés de fichiers pour les fichiers de base de données dans Azure.
Pour supprimer un jeu de sauvegarde de captures instantanées de fichiers, procédez comme suit :
Lancez SSMS.
Ouvrez une nouvelle fenêtre de requête et connectez-vous à l’instance SQL Server du moteur de base de données dans votre machine virtuelle Azure (ou à n’importe quelle instance SQL Server disposant des autorisations de lecture et d’écriture sur ce conteneur).
Copiez et collez le script Transact-SQL suivant dans la fenêtre de requête. Sélectionnez la sauvegarde du journal à supprimer, ainsi que ses captures instantanées de fichiers associées. Modifiez l’URL en fonction du nom de votre compte de stockage et du conteneur que vous avez spécifiés dans la partie 1, fournissez le nom du fichier de sauvegarde du journal, puis exécutez ce script.
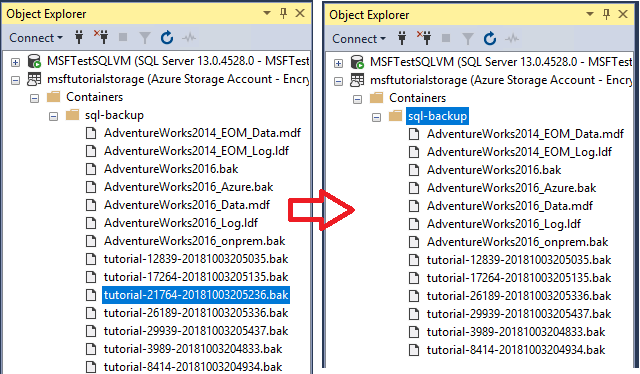
sys.sp_delete_backup 'https://<mystorageaccountname>.blob.core.windows.net/<mystorageaccountcontainername>/tutorial-21764-20181003205236.bak';Dans l’Explorateur d’objets, connectez-vous au stockage Azure.
Développez Conteneurs, développez le conteneur que vous avez créé dans la section 1 et vérifiez que le fichier de sauvegarde que vous avez utilisé à l’étape 3 n’apparaît plus dans ce conteneur (actualisez le nœud si nécessaire).
Copiez, collez et exécutez le script Transact-SQL suivant dans la fenêtre de requête pour vérifier que les deux captures instantanées de fichiers ont été supprimées.
-- verify that two file snapshots have been removed SELECT * from sys.fn_db_backup_file_snapshots ('AdventureWorks2022');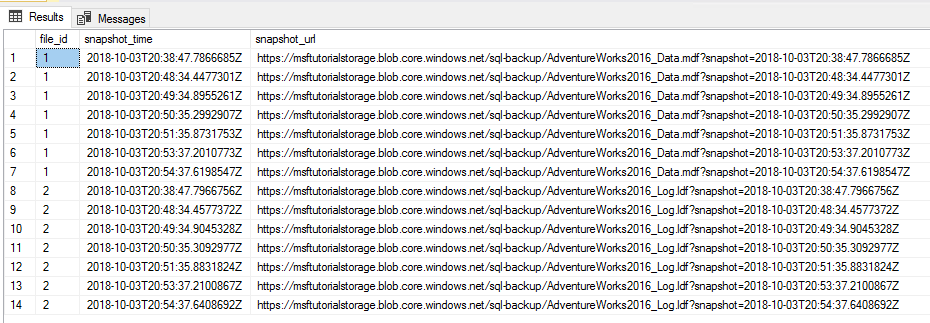
10 : supprimer des ressources
Une fois que vous avez terminé ce tutoriel, pour préserver les ressources, prenez soin de supprimer le groupe de ressources créé dans ce tutoriel.
Pour supprimer le groupe de ressources, exécutez le code PowerShell suivant :
# Define global variables for the script
$prefixName = '<prefix name>' # should be the same as the beginning of the tutorial
# Set a variable for the name of the resource group you will create or use
$resourceGroupName=$prefixName + 'rg'
# Adds an authenticated Azure account for use in the session
Connect-AzAccount
# Set the tenant, subscription and environment for use in the rest of
Set-AzContext -SubscriptionId $subscriptionID
# Remove the resource group
Remove-AzResourceGroup -Name $resourceGroupName
Étapes suivantes
- Fichiers de données SQL Server dans Microsoft Azure
- Sauvegarde d’instantanés de fichiers pour les fichiers de base de données dans Azure
- Sauvegarde SQL Server vers une URL
- Signatures d'accès partagé, partie 1 : présentation du modèle SAP
- Créer un conteneur
- Set Container ACL
- Get Container ACL
- Informations d'identification (moteur de base de données)
- CREATE CREDENTIAL (Transact-SQL)
- sys.credentials (Transact-SQL)
- sp_delete_backup (Transact-SQL)
- sys.fn_db_backup_file_snapshots (Transact-SQL)
- sp_delete_backup_file_snapshot (Transact-SQL)
- Sauvegarde d’instantanés de fichiers pour les fichiers de base de données dans Azure
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour