Protocole de serveur de langage
Qu’est-ce que le protocole Language Server ?
La prise en charge de fonctionnalités d’édition enrichies telles que les saisies semi-automatiques du code source ou Atteindre la définition pour un langage de programmation dans un éditeur ou un IDE est traditionnellement très difficile et fastidieux. En règle générale, il nécessite l’écriture d’un modèle de domaine (un scanneur, un analyseur, un type case activée er, un générateur et plus) dans le langage de programmation de l’éditeur ou de l’IDE. Par exemple, le plug-in Eclipse CDT, qui prend en charge C/C++ dans l’IDE Eclipse est écrit en Java, car l’IDE Eclipse lui-même est écrit en Java. À l’issue de cette approche, cela signifierait implémenter un modèle de domaine C/C++ dans TypeScript pour Visual Studio Code et un modèle de domaine distinct en C# pour Visual Studio.
La création de modèles de domaine spécifiques au langage est également beaucoup plus facile si un outil de développement peut réutiliser des bibliothèques spécifiques au langage existantes. Toutefois, ces bibliothèques sont généralement implémentées dans le langage de programmation lui-même (par exemple, de bons modèles de domaine C/C++ sont implémentés en C/C++). L’intégration d’une bibliothèque C/C++ dans un éditeur écrit dans TypeScript est techniquement possible, mais difficile à faire.
Serveurs linguistiques
Une autre approche consiste à exécuter la bibliothèque dans son propre processus et à utiliser la communication interprocessus pour lui parler. Les messages envoyés en arrière forment un protocole. Le protocole LSP (Language Server Protocol) est le produit de la normalisation des messages échangés entre un outil de développement et un processus de serveur de langage. L’utilisation de serveurs linguistiques ou de démons n’est pas une idée nouvelle ou nouvelle. Les éditeurs tels que Vim et Emacs ont fait cela depuis un certain temps pour fournir une prise en charge sémantique de la saisie semi-automatique. L’objectif du LSP était de simplifier ces types d’intégrations et de fournir un framework utile pour exposer des fonctionnalités de langage à un large éventail d’outils.
Le fait d’avoir un protocole commun permet l’intégration des fonctionnalités du langage de programmation dans un outil de développement avec un minimum de fuss en réutilisant une implémentation existante du modèle de domaine du langage. Un serveur de langage principal peut être écrit en PHP, Python ou Java et le LSP lui permet d’être facilement intégré à un large éventail d’outils. Le protocole fonctionne à un niveau commun d’abstraction afin qu’un outil puisse offrir des services de langage enrichis sans avoir à comprendre pleinement les nuances spécifiques au modèle de domaine sous-jacent.
Comment travailler sur le fournisseur de services LSP a démarré
Le LSP a évolué au fil du temps et aujourd’hui, il est à la version 3.0. Il a commencé lorsque le concept d’un serveur de langage a été récupéré par OmniSharp pour fournir des fonctionnalités d’édition enrichies pour C#. Au départ, OmniSharp a utilisé le protocole HTTP avec une charge utile JSON et a été intégré à plusieurs éditeurs, notamment Visual Studio Code.
En même temps, Microsoft a commencé à travailler sur un serveur de langage TypeScript, avec l’idée de prendre en charge TypeScript dans les éditeurs tels que Emacs et Sublime Text. Dans cette implémentation, un éditeur communique via stdin/stdout avec le processus serveur TypeScript et utilise une charge utile JSON inspirée par le protocole de débogueur V8 pour les requêtes et les réponses. Le serveur TypeScript a été intégré au plug-in TypeScript Sublime et à VS Code pour la modification de TypeScript enrichie.
Après avoir intégré deux serveurs linguistiques différents, l’équipe VS Code a commencé à explorer un protocole de serveur de langage commun pour les éditeurs et les IDE. Un protocole commun permet à un fournisseur de langage de créer un serveur de langue unique qui peut être consommé par différents IDE. Un consommateur de serveur de langage n’a qu’à implémenter le côté client du protocole une seule fois. Cela entraîne une situation win-win pour le fournisseur de langue et le consommateur de langue.
Le protocole du serveur de langage a commencé avec le protocole utilisé par le serveur TypeScript, le développant avec d’autres fonctionnalités de langage inspirées par l’API de langage VS Code. Le protocole est soutenu avec JSON-RPC pour l’appel à distance en raison de sa simplicité et de ses bibliothèques existantes.
L’équipe VS Code a prototypené le protocole en implémentant plusieurs serveurs de langage linter qui répondent aux demandes de lint (analyser) un fichier et retournent un ensemble d’avertissements et d’erreurs détectés. L’objectif était de lint un fichier à mesure que l’utilisateur modifie dans un document, ce qui signifie qu’il y aura de nombreuses demandes de linting pendant une session d’éditeur. Il est judicieux de maintenir un serveur opérationnel afin qu’un nouveau processus de linting n’ait pas besoin d’être démarré pour chaque modification utilisateur. Plusieurs serveurs linter ont été implémentés, notamment les extensions ESLint et TSLint de VS Code. Ces deux serveurs linter sont implémentés dans TypeScript/JavaScript et s’exécutent sur Node.js. Ils partagent une bibliothèque qui implémente la partie client et serveur du protocole.
Fonctionnement du LSP
Un serveur de langage s’exécute dans son propre processus et des outils tels que Visual Studio ou VS Code communiquent avec le serveur à l’aide du protocole de langage via JSON-RPC. Un autre avantage du serveur de langage qui fonctionne dans un processus dédié est que les problèmes de performances liés à un modèle de processus unique sont évités. Le canal de transport réel peut être stdio, sockets, canaux nommés ou ipc de nœud si le client et le serveur sont écrits dans Node.js.
Voici un exemple pour savoir comment un outil et un serveur de langage communiquent pendant une session d’édition de routine :

L’utilisateur ouvre un fichier (appelé document) dans l’outil : l’outil informe le serveur de langue qu’un document est ouvert ('textDocument/didOpen'). À partir de maintenant, la vérité sur le contenu du document n’est plus sur le système de fichiers, mais conservée par l’outil en mémoire.
L’utilisateur effectue des modifications : l’outil informe le serveur de la modification du document ('textDocument/didChange') et les informations sémantiques du programme sont mises à jour par le serveur de langue. Comme cela se produit, le serveur de langue analyse ces informations et avertit l’outil avec les erreurs et avertissements détectés ('textDocument/publishDiagnostics').
L’utilisateur exécute « Atteindre la définition » sur un symbole dans l’éditeur : l’outil envoie une requête « textDocument/definition » avec deux paramètres : (1) l’URI du document et (2) la position de texte à partir de laquelle la requête Atteindre la définition a été lancée sur le serveur. Le serveur répond avec l’URI du document et la position de la définition du symbole à l’intérieur du document.
L’utilisateur ferme le document (fichier) : une notification « textDocument/didClose » est envoyée à partir de l’outil, informant le serveur de langue que le document n’est plus en mémoire et que le contenu actuel est maintenant à jour sur le système de fichiers.
Cet exemple montre comment le protocole communique avec le serveur de langage au niveau des fonctionnalités de l’éditeur, telles que « Accéder à la définition », « Rechercher toutes les références ». Les types de données utilisés par le protocole sont des « types de données » d’éditeur ou d’IDE comme le document texte actuellement ouvert et la position du curseur. Les types de données ne sont pas au niveau d’un modèle de domaine de langage de programmation qui fournit généralement des arborescences de syntaxe abstraites et des symboles du compilateur (par exemple, types résolus, espaces de noms, ...). Cela simplifie considérablement le protocole.
Examinons maintenant la demande « textDocument/definition » plus en détail. Vous trouverez ci-dessous les charges utiles qui vont entre l’outil client et le serveur de langage pour la requête « Atteindre la définition » dans un document C++.
Il s’agit de la demande :
{
"jsonrpc": "2.0",
"id" : 1,
"method": "textDocument/definition",
"params": {
"textDocument": {
"uri": "file:///p%3A/mseng/VSCode/Playgrounds/cpp/use.cpp"
},
"position": {
"line": 3,
"character": 12
}
}
}
Voici la réponse :
{
"jsonrpc": "2.0",
"id": "1",
"result": {
"uri": "file:///p%3A/mseng/VSCode/Playgrounds/cpp/provide.cpp",
"range": {
"start": {
"line": 0,
"character": 4
},
"end": {
"line": 0,
"character": 11
}
}
}
}
En rétrospect, décrire les types de données au niveau de l’éditeur plutôt qu’au niveau du modèle de langage de programmation est l’une des raisons de la réussite du protocole du serveur de langage. Il est beaucoup plus simple de normaliser un URI de document de texte ou une position de curseur par rapport à la normalisation d’une arborescence de syntaxe abstraite et des symboles de compilateur dans différents langages de programmation.
Lorsqu’un utilisateur travaille avec différents langages, VS Code démarre généralement un serveur de langage pour chaque langage de programmation. L’exemple ci-dessous montre une session où l’utilisateur fonctionne sur des fichiers Java et SAP.
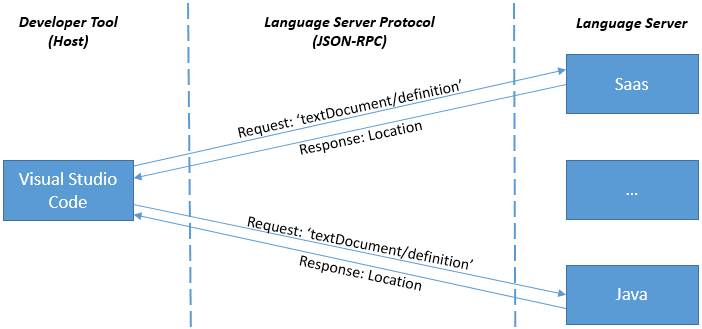
Fonctionnalités
Tous les serveurs linguistiques ne peuvent pas prendre en charge toutes les fonctionnalités définies par le protocole. Par conséquent, le client et le serveur annoncent leur ensemble de fonctionnalités pris en charge par le biais de « fonctionnalités ». Par exemple, un serveur annonce qu’il peut gérer la requête « textDocument/definition », mais il peut ne pas gérer la requête « workspace/symbol ». De même, les clients peuvent annoncer qu’ils sont en mesure de fournir des notifications « sur le point d’enregistrer » avant l’enregistrement d’un document, afin qu’un serveur puisse calculer les modifications textuelles pour mettre automatiquement en forme le document modifié.
Intégration d’un serveur de langage
L’intégration réelle d’un serveur de langage à un outil particulier n’est pas définie par le protocole du serveur de langage et est laissée aux implémenteurs d’outils. Certains outils intègrent des serveurs linguistiques de manière générique en ayant une extension qui peut démarrer et communiquer avec n’importe quel type de serveur de langage. D’autres, comme VS Code, créent une extension personnalisée par serveur de langage, afin qu’une extension puisse toujours fournir certaines fonctionnalités de langage personnalisées.
Pour simplifier l’implémentation de serveurs de langage et de clients, il existe des bibliothèques ou des kits sdk pour les composants client et serveur. Ces bibliothèques sont fournies pour différentes langues. Par exemple, il existe un module npm du client de langage pour faciliter l’intégration d’un serveur de langage à une extension VS Code et un autre module npm de serveur de langage pour écrire un serveur de langage à l’aide de Node.js. Il s’agit de la liste actuelle des bibliothèques de prise en charge.
Utilisation du protocole Language Server dans Visual Studio
- Ajout d’une extension language Server Protocol - Découvrez comment intégrer un serveur de langage dans Visual Studio.