Interactions vocales
Intégrez la reconnaissance vocale et la conversion de texte par synthèse vocale (également appelée TTS ou synthèse vocale) directement dans l’expérience utilisateur de votre application.
Reconnaissance vocale La reconnaissance vocale convertit les mots prononcés par l’utilisateur en texte pour la saisie de formulaire, pour la dictée de texte, pour spécifier une action ou une commande et pour accomplir des tâches. Les deux grammaires prédéfinies pour la dictée de texte libre et la recherche web, ainsi que les grammaires personnalisées basées sur la norme SRGS (Speech Recognition Grammar Specification) version 1.0, sont prises en charge.
TTS TTS utilise un moteur de synthèse vocale (voix) pour convertir une chaîne de texte en mots parlés. La chaîne d’entrée peut être du texte basique sans fioriture ou un texte SSML (Speech Synthesis Markup Language) plus complexe. Le langage SSML fournit un moyen standard de contrôler les caractéristiques de la restitution vocale telles que la prononciation, le volume, la tonalité, le débit ou la vitesse et l’accentuation.
Autres composants liés à la parole :Cortana dans les applications Windows utilise des commandes vocales personnalisées (parlées ou tapées) pour lancer votre application au premier plan (l’application prend le focus, comme si elle a été lancée à partir du menu Démarrer) ou l’activer en tant que service en arrière-plan (Cortana conserve le focus mais fournit les résultats de l’application). Consultez les instructions relatives aux commandes vocales Cortana (VCD) si vous exposez des fonctionnalités d’application dans l’interface utilisateur cortana .
Conception de l’interaction vocale
Conçues et mises en œuvre efficacement, les fonctions vocales peuvent permettre aux utilisateurs d’interagir avec votre application de manière fiable et agréable. Elles peuvent aussi compléter, voire remplacer le clavier, la souris, l’écran tactile et les mouvements.
Ces instructions et recommandations décrivent comment intégrer au mieux la reconnaissance vocale et la TTS dans l’expérience d’interaction de votre application.
Si vous envisagez de prendre en charge des interactions vocales dans votre application :
- Quelles actions peuvent être effectuées par le biais de reconnaissance vocale ? L’utilisateur peut-il naviguer entre les pages, appeler des commandes ou entrer des notes, des messages longs ou des données en tant que champs de texte ?
- La saisie vocale est-elle une option pratique pour mener à bien une tâche ?
- Comment un utilisateur peut-il savoir que la saisie vocale est disponible ?
- L’application est-elle toujours à l’écoute, ou l’utilisateur doit-il effectuer une action pour que l’application passe en mode d’écoute ?
- Quelles sont les expressions qui initient une action ou un comportement ? Les actions et les expressions doivent-elles être énumérées à l’écran ?
- La TTS ou les écrans d’invite, de confirmation et de levée d’ambiguïté sont-ils requis ?
- Quelle est la boîte de dialogue d’interaction entre l’application et l’utilisateur ?
- Un vocabulaire personnalisé ou restreint (médical, scientifique ou régional) est-il requis pour le contexte de votre application ?
- La connectivité réseau est-elle nécessaire ?
Saisie de texte
Les fonctions vocales pour la saisie de texte peuvent varier du court (un seul mot ou une seule expression) au long (dictée en continu). L’entrée courte doit être inférieure à 10 secondes, tandis que l’entrée longue peut durer jusqu’à 2 minutes. (L’entrée longue peut être redémarrée sans intervention de l’utilisateur afin de donner l’impression d’une dictée en continu).
Vous devez fournir un signal visuel pour indiquer que la reconnaissance vocale est prise en charge et disponible pour l’utilisateur, et si elle doit être activée. Par exemple, un bouton de barre de commandes avec un glyphe de microphone (voir Barres de commandes) peut être utilisé pour afficher la disponibilité et l’état.
Fournissez des commentaires en continu pour minimiser l’absence de réponse apparente lorsque la reconnaissance est en cours d’exécution.
Donnez aux utilisateurs la possibilité de réviser le texte de reconnaissance à l’aide de saisie au clavier, d’invites de levée d’ambiguïté, de suggestions ou de reconnaissance vocale supplémentaire.
Arrêtez la reconnaissance si une entrée en provenance d’un appareil autre que la reconnaissance vocale (entrée tactile ou clavier) est détectée. Cela indique probablement que l’utilisateur effectue une autre tâche, telle que la correction du texte de reconnaissance ou l’interaction avec d’autres champs de formulaire.
Spécifiez la durée maximale sans entrée vocale indiquant que la reconnaissance est terminée. Ne redémarrez pas automatiquement la reconnaissance après cette période de temps, car cela indique généralement que l’utilisateur a cessé d’interagir avec votre application.
Désactivez la reconnaissance vocale continue de l’interface utilisateur et mettez fin à la session de reconnaissance si aucune connexion réseau n’est disponible. La reconnaissance continue nécessite une connexion réseau.
Commandes
La saisie vocale permet d’initier des actions, d’appeler des commandes et d’accomplir des tâches.
Si l’espace le permet, envisagez d’afficher les réponses prises en charge pour le contexte de l’application en cours, avec des exemples d’entrée valide. Cela réduit les réponses potentielles que votre application doit traiter et permet d’éviter toute confusion pour l’utilisateur.
Essayez de formuler vos questions de manière à ce que la réponse soit la plus précise possible. Par exemple, « Que voulez-vous faire aujourd’hui ? » est très ouvert et nécessiterait une définition grammaticale très large en raison de la variété des réponses. Sinon, « Voulez-vous jouer à un jeu ou écouter de la musique ? » contraint la réponse à l’une des deux réponses valides avec une définition grammaticale de petite taille correspondante. Une grammaire simple est beaucoup plus facile à créer et génère des résultats de reconnaissance beaucoup plus précis.
Demandez confirmation à l’utilisateur quand le niveau de fiabilité de la reconnaissance vocale est faible. Si l’intention de l’utilisateur n’est pas évidente, il est préférable de la clarifier avant de lancer une action involontaire.
Vous devez fournir un signal visuel pour indiquer que la reconnaissance vocale est prise en charge et disponible pour l’utilisateur, et si elle doit être activée. Par exemple, un bouton de barre de commandes avec un glyphe de microphone (voir Recommandations en matière de barres de commandes) peut être utilisé pour afficher la disponibilité et l’état.
Si le commutateur de reconnaissance vocale est hors de la vue, envisagez d’afficher un indicateur d’état dans la zone de contenu de l’application.
Si la reconnaissance est initiée par l’utilisateur, envisagez d’utiliser l’expérience de reconnaissance intégrée par souci de cohérence. L’expérience intégrée comprend des écrans personnalisables avec invites, des exemples, des levées d’ambiguïté, des confirmations et des erreurs.
Les écrans varient selon les contraintes spécifiées :
Grammaire prédéfinie (dictée ou recherche web)
- Écran Écoute
- Écran Réflexion
- Écran Nous vous avons entendu dire ou écran de notification d’erreur
Liste de mots ou d’expressions, ou fichier de grammaire SRGS
- Écran Écoute
- Écran Nous vous avons entendu dire, si l’interprétation de ce que l’utilisateur a prononcé pourrait avoir plusieurs résultats éventuels
- Écran Nous vous avons entendu dire ou écran de notification d’erreur
Sur l’écran Écoute, vous pouvez :
- personnaliser le titre ;
- fournir un exemple de texte illustrant ce que peut dire l’utilisateur ;
- spécifier si l’écran Nous vous avons entendu dire s’affiche ;
- restituer à l’utilisateur la chaîne reconnue sur l’écran Nous vous avons entendu dire.
Voici un exemple du flux de reconnaissance intégrée pour un module de reconnaissance vocale qui utilise une contrainte définie par le SRGS. Dans cet exemple, la reconnaissance vocale est une réussite.
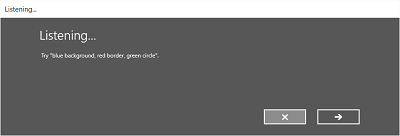
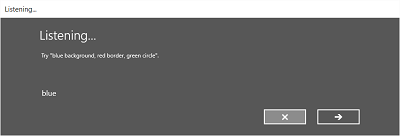
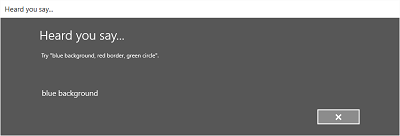
Toujours à l’écoute
Votre application peut écouter et reconnaître la saisie vocale dès que l’application est lancée, sans intervention de l’utilisateur.
Vous devez personnaliser les contraintes de grammaire en fonction du contexte de l’application. Cela permet non seulement de cibler l’expérience de reconnaissance vocale sur les tâches en cours afin de la rendre plus pertinente, mais également de minimiser les erreurs.
Qu’est-ce que je dis ?
Lorsque la saisie vocale est activée, il est important d’aider les utilisateurs à cerner ce qui est compréhensible et les actions qui peuvent être effectuées.
Si la reconnaissance vocale est activée par l’utilisateur, envisagez d’utiliser la barre de commandes ou une commande de menu pour afficher tous les mots et expressions pris en charge dans le contexte actuel.
Si la reconnaissance vocale est toujours activée, envisagez d’ajouter l’expression « Que puis-je dire ? » à chaque page. Lorsque l’utilisateur prononce cette phrase, affichez tous les mots et expressions pris en charge dans le contexte actuel. Cette expression fournit un moyen cohérent pour les utilisateurs de découvrir les fonctionnalités vocales du système.
Gestion des échecs de la reconnaissance
La reconnaissance vocale peut échouer. Les échecs se produisent lorsque la qualité audio est médiocre, qu’une seule partie d’une expression est reconnue, ou qu’aucune entrée n’est détectée.
Gérez au mieux ces échecs en aidant l’utilisateur à comprendre pourquoi la reconnaissance n’a pas fonctionné et recherchez une solution.
Votre application doit informer l’utilisateur qu’il n’a pas été compris et qu’il doit réessayer.
Envisagez de fournir des exemples d’expressions prises en charge. L’utilisateur est susceptible de répéter une expression suggérée, ce qui augmente la réussite de la reconnaissance vocale.
Vous pouvez afficher une liste de correspondances potentielles dans laquelle l’utilisateur peut piocher. Cela peut s’avérer bien plus efficace que de reprendre le processus de reconnaissance à zéro.
Vous devez prendre en charge les autres types d’entrée afin de gérer au mieux les échecs de reconnaissance répétés. Par exemple, vous pourriez suggérer à l’utilisateur d’utiliser le clavier, l’interaction tactile ou la souris pour effectuer une sélection dans la liste des correspondances potentielles.
Utilisez l’expérience de la reconnaissance vocale intégrée, car elle comprend des écrans qui indiquent à l’utilisateur que la reconnaissance a échoué et qui lui permettent de parler de nouveau pour effectuer une autre tentative de reconnaissance.
Détectez et corrigez les problèmes liés à l’entrée audio. Le module de reconnaissance vocale peut détecter les problèmes liés à la qualité audio, susceptibles d’affecter la précision de la reconnaissance vocale. Vous pouvez utiliser les informations fournies par le module de reconnaissance vocale pour informer l’utilisateur du problème et lui permettre de le résoudre, le cas échéant. Par exemple, si le paramètre du volume sur le microphone est trop faible, vous pouvez inviter l’utilisateur à parler plus fort ou à augmenter le volume.
Contraintes
Les contraintes, ou les grammaires, définissent les mots et les expressions qui peuvent être détectés par le module de reconnaissance vocale. Vous pouvez spécifier l’une des grammaires de service web prédéfinies ou encore créer une grammaire personnalisée installée sur votre application.
Grammaires prédéfinies
Les grammaires de dictée et de recherche web prédéfinies vous permettent d’activer la reconnaissance vocale dans votre application sans créer votre propre grammaire. Si vous optez pour ces grammaires, la reconnaissance vocale est effectuée par un service web distant qui renvoie les résultats à l’appareil.
- La grammaire de dictée de texte libre par défaut peut reconnaître la plupart des mots et expressions prononcés par un utilisateur dans une langue spécifique. Elle est optimisée pour reconnaître les expressions courtes. La dictée de texte libre est utile si vous ne souhaitez pas limiter ce qu’un utilisateur peut dire. Elle est généralement utilisée pour créer des notes ou dicter le contenu d’un message.
- La grammaire de recherche web, comme une grammaire de dictée, contient un grand nombre de mots et expressions qu’un utilisateur peut dire. Toutefois, elle est optimisée pour reconnaître les termes que les personnes utilisent généralement lors des recherches sur le web.
Notes
Étant donné que les grammaires de dictée et de recherche web prédéfinies peuvent être volumineuses et qu’elles sont hébergées en ligne (elles ne se trouvent pas sur l’appareil), les performances obtenues peuvent ne pas être aussi bonnes qu’avec des grammaires personnalisées qui sont installées sur l’appareil.
Ces grammaires prédéfinies peuvent être utilisées pour reconnaître jusqu’à 10 secondes de saisie vocale et ne nécessitent aucun effort de création de votre part. Elles nécessitent toutefois une connexion à un réseau.
Grammaires personnalisées
Une grammaire personnalisée est conçue et créée par vous-même, et installé sur votre application. La reconnaissance vocale à l’aide d’une contrainte personnalisée est effectuée sur l’appareil.
Les contraintes de liste de programmation permettent de créer facilement une grammaire simple sous la forme d’une liste de mots ou d’expressions. Une contrainte de liste fonctionne correctement pour la reconnaissance d’expressions distinctes courtes. En indiquant explicitement des mots dans une grammaire, vous améliorez également la précision de la reconnaissance, car le traitement de la parole par le moteur de reconnaissance se limite à la confirmation d’une correspondance. La liste peut également être mise à jour par programme.
Contrairement à une contrainte de liste de programmation, une grammaire SRGS est un document statique au format XML défini par la norme SRGS version 1.0. Une grammaire SRGS permet de contrôler au maximum l’expérience de la reconnaissance vocale en capturant plusieurs significations sémantiques dans une même reconnaissance.
Voici quelques conseils pour la création de grammaires SRGS :
- Limitez chaque grammaire. Les grammaires qui contiennent peu d’expressions ont tendance à offrir une reconnaissance plus précise que les grammaires complexes qui contiennent de nombreuses expressions. Il est préférable d’utiliser plusieurs grammaires de taille réduite pour les différents scénarios plutôt qu’une seule grammaire pour la totalité de l’application.
- Indiquez aux utilisateurs ce qu’ils doivent dire pour chaque contexte d’application, et activez et désactivez les grammaires selon les besoins.
- Concevez chaque grammaire de manière à ce que les utilisateurs puissent prononcer une commande de différentes manières. Par exemple, vous pouvez utiliser la règle GARBAGE pour accepter la saisie vocale que votre grammaire ne définit pas. Cela permet aux utilisateurs de prononcer des mots supplémentaires qui n’ont aucune signification pour votre application. Par exemple, « donnez-moi », « et », « euh », « peut-être », etc.
- Utilisez l’élément sapi:subset pour faciliter la détection de l’entrée vocale. Il s’agit d’une extension Microsoft à la spécification SRGS permettant de mieux répondre aux expressions partielles.
- Évitez de définir des expressions dans votre grammaire qui ne contiennent qu’une seule syllabe. La reconnaissance tend à être plus précise pour les expressions contenant au moins deux syllabes.
- Évitez d’utiliser des expressions qui se ressemblent. Par exemple, les expressions telles que « matin », « châtain » et « latin » peuvent induire en erreur le module de reconnaissance et affecter le degré de précision de la reconnaissance.
Notes
Le type de contrainte que vous utilisez dépend de la complexité de l’expérience de reconnaissance que vous voulez créer. Un type de contrainte peut être mieux adapté à une tâche de reconnaissance vocale particulière, mais vous pouvez aussi combiner tous les types de contrainte dans votre application.
Prononciations personnalisées
Si votre application contient un vocabulaire spécialisé avec des mots inhabituels, fictifs ou dont la prononciation est particulière, vous pouvez améliorer leur reconnaissance en définissant des prononciations personnalisées.
Pour une petite liste de mots et d’expressions, ou une liste de mots et d’expressions rarement utilisés, vous pouvez créer des prononciations personnalisées dans une grammaire SRGS. Pour plus d’informations, voir Élément token.
Pour les listes de mots et d’expressions plus conséquentes, ou pour les mots et les expressions fréquemment utilisés, vous pouvez créer des documents de lexique de prononciation distincte. Pour plus d’informations, voir À propos des lexiques et des alphabets phonétiques.
Test
Testez la précision de la reconnaissance vocale et l’interface utilisateur prise en charge auprès du public cible de votre application. C’est la meilleure façon de déterminer l’efficacité de l’expérience d’interaction vocale de votre application. Par exemple, vos utilisateurs ont-ils obtenu de mauvais résultats de reconnaissance, car votre application n’est pas à l’écoute d’une expression courante ?
Changez la grammaire de manière à prendre en charge cette expression ou fournissez aux utilisateurs une liste d’expressions prises en charge. Si vous fournissez une liste des expressions prises en charge, assurez-vous qu’elle est facilement accessible.
Conversion de texte par synthèse vocale
TTS génère la sortie vocale à partir du texte brut ou du langage SSML.
Concevez des invites courtoises et encourageantes.
Envisagez de lire les longues chaînes de texte. C’est une chose d’écouter un message texte, mais une autre d’écouter une longue liste de résultats de recherche qui sont difficiles à mémoriser.
Vous devez fournir les contrôles multimédias pour permettre aux utilisateurs de suspendre ou d’arrêter TTS.
Vous devez écouter toutes les chaînes de texte TTS pour vous assurer qu’elles sont compréhensibles et naturelles.
- En reliant une séquence de mots inhabituels ou en prononçant des numéros de référence ou des signes de ponctuation, l’expression risque de devenir incompréhensible.
- La parole peut manquer de naturel lorsque la prosodie ou l’intonation est différente de la façon dont un locuteur natif prononcerait une expression.
Les deux problèmes peuvent être résolus en utilisant SSML au lieu de texte brut comme entrée dans le synthétiseur vocal. Pour plus d’informations sur le langage SSML, voir Utiliser le langage SSML pour contrôler la voix synthétisée et Informations de référence sur le langage SSML (Speech Synthesis Markup Language).
Autres articles de cette section
| Rubrique | Description |
|---|---|
| Reconnaissance vocale | La reconnaissance vocale permet de fournir une saisie vocale, de spécifier une action ou une commande et d’accomplir différentes tâches. |
| Spécifier la langue de reconnaissance vocale | Découvrez comment sélectionner une langue installée à utiliser pour la reconnaissance vocale. |
| Définir des contraintes de reconnaissance vocale personnalisées | Découvrez comment définir et utiliser des contraintes personnalisées pour la reconnaissance vocale. |
| Activer la dictée continue | Découvrez comment capturer et reconnaître une entrée vocale dictée en continu et sur une longue durée. |
| Gérer les problèmes liés à l’entrée audio | Découvrez comment gérer les problèmes liés à la précision de la reconnaissance vocale qu’entraîne une baisse de qualité des entrées audio. |
| Définir des délais d’expiration de reconnaissance vocale | Définissez la durée pendant laquelle un moteur de reconnaissance vocale ignore les silences ou les sons incompréhensibles (brouhaha) et continue à écouter la saisie vocale. |
Articles connexes
Exemples

Windows developer
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour