Storm antipattern újrapróbálkozás
Ha egy szolgáltatás nem érhető el vagy foglalt, ha az ügyfelek túl gyakran próbálkoznak újra a kapcsolatukkal, a szolgáltatás nehezen helyreállhat, és súlyosbíthatja a problémát. Nincs értelme az újrapróbálkozásnak is, mivel a kérések általában csak meghatározott ideig érvényesek.
A probléma leírása
A felhőben a szolgáltatások időnként problémákat tapasztalnak, és elérhetetlenné válnak az ügyfelek számára, vagy szabályozniuk vagy korlátozniuk kell az ügyfeleiket. Bár az ügyfeleknek ajánlott újrapróbálkozniuk a szolgáltatásokkal létesített sikertelen kapcsolatokon, fontos, hogy ne próbálkozzanak túl gyakran vagy túl sokáig. Az újrapróbálkozási próbálkozások rövid időn belül nem lesznek sikeresek, mivel a szolgáltatások valószínűleg nem fognak helyreállni. Emellett a szolgáltatások még nagyobb stressznek lehetnek kitéve, ha sok csatlakozási kísérlet történik a helyreállítás közben, és az ismétlődő csatlakozási kísérletek akár túlterhelhetik a szolgáltatást, és súlyosbíthatják a mögöttes problémát.
Az alábbi példa egy olyan forgatókönyvet mutat be, amelyben egy ügyfél egy kiszolgálóalapú API-hoz csatlakozik. Ha a kérés nem sikerül, az ügyfél azonnal újra próbálkozik, és örökre újra próbálkozik. Az ilyen viselkedés gyakran finomabb, mint ebben a példában, de ugyanez az elv érvényes.
public async Task<string> GetDataFromServer()
{
while(true)
{
var result = await httpClient.GetAsync(string.Format("http://{0}:8080/api/...", hostName));
if (result.IsSuccessStatusCode) break;
}
// ... Process result.
}
A probléma megoldása
Az ügyfélalkalmazások az ajánlott eljárásokat követve kerülik el az újrapróbálkozási vihart.
- Korlátozza az újrapróbálkozási kísérletek számát, és ne próbálkozzon tovább hosszú ideig. Bár könnyen lehet hurkot
while(true)írni, szinte biztosan nem szeretne hosszú ideig újra próbálkozni, mivel a kérés indításához vezető helyzet valószínűleg megváltozott. A legtöbb alkalmazásban elegendő néhány másodpercig vagy percig újrapróbálkozás. - Szünet az újrapróbálkozási kísérletek között. Ha egy szolgáltatás nem érhető el, nem valószínű, hogy az azonnali újrapróbálkozás sikeres lesz. Fokozatosan növelheti a kísérletek közötti várakozási időt, például exponenciális visszalépési stratégia használatával.
- A hibák kezelése kecsesen történik. Ha a szolgáltatás nem válaszol, fontolja meg, hogy van-e értelme megszakítani a kísérletet, és visszaadni egy hibát az összetevő felhasználójának vagy hívójának. Az alkalmazás tervezésekor vegye figyelembe ezeket a hibaforgatókönyveket.
- Fontolja meg a megszakító minta használatát, amely kifejezetten az újrapróbálkozási viharok elkerülése érdekében lett kialakítva.
- Ha a kiszolgáló válaszfejlécet
retry-afterad meg, győződjön meg arról, hogy a megadott időtartam leteltéig nem kísérli meg az újrapróbálkozást. - Az Azure-szolgáltatásokkal való kommunikációhoz használjon hivatalos SDK-kat. Ezek az SDK-k általában beépített újrapróbálkozási szabályzatokkal és védelemmel rendelkeznek az újrapróbálkozási viharok okozása vagy az ahhoz való hozzájárulás ellen. Ha olyan szolgáltatással kommunikál, amely nem rendelkezik SDK-val, vagy ha az SDK nem kezeli megfelelően az újrapróbálkozás logikáját, fontolja meg egy olyan kódtár használatát, mint a Polly (.NET esetén), vagy próbálkozzon újra (JavaScript esetén) az újrapróbálkozás logikájának helyes kezeléséhez, és kerülje a kód írását.
- Ha olyan környezetben fut, amely támogatja azt, használjon szolgáltatáshálót (vagy egy másik absztrakciós réteget) a kimenő hívások küldéséhez. Ezek az eszközök, például a Dapr általában támogatják az újrapróbálkozási szabályzatokat, és automatikusan követik az ajánlott eljárásokat, például az ismétlődő kísérletek utáni visszalépést. Ez a megközelítés azt jelenti, hogy nem kell újrapróbálkozési kódot írnia.
- Fontolja meg a kérelmek kötegelését és a kérelmek készletezésének használatát, ahol elérhető. Számos SDK kezeli a kérések kötegelését és a kapcsolatkészletezést az Ön nevében, ami csökkenti az alkalmazás által végrehajtott kimenő kapcsolati kísérletek teljes számát, bár továbbra is ügyelnie kell arra, hogy ne próbálkozzon túl gyakran ezekkel a kapcsolatokkal.
A szolgáltatásoknak meg kell védeniük magukat az újrapróbálkozásoktól.
- Adjon hozzá egy átjáróréteget, hogy kikapcsolhassa a kapcsolatokat egy incidens során. Ez egy példa a Válaszfal mintára. Az Azure számos különböző átjárószolgáltatást biztosít különböző típusú megoldásokhoz, például a Front Doorhoz, Application Gateway és API Management.
- A kérések szabályozása az átjárón, amely biztosítja, hogy ne fogadjon el annyi kérést, hogy a háttérösszetevők ne tudjanak tovább működni.
- Ha szabályoz, küldjön vissza egy
retry-afterfejlécet, amely segít az ügyfeleknek megérteni, hogy mikor kell újra létrehozni a kapcsolatokat.
Megfontolandó szempontok
- Az ügyfeleknek figyelembe kell venniük a visszaadott hiba típusát. Egyes hibatípusok nem a szolgáltatás hibáját jelzik, hanem azt jelzik, hogy az ügyfél érvénytelen kérést küldött. Ha például egy ügyfélalkalmazás hibaüzenetet
400 Bad Requestkap, valószínűleg nem fog segíteni, ha újrapróbálja ugyanazt a kérést, mivel a kiszolgáló azt mondja, hogy a kérés érvénytelen. - Az ügyfeleknek figyelembe kell venniük a kapcsolatok újraaktiválásának idejét. Az újrapróbálkozáshoz szükséges idő hosszát az üzleti követelmények határozzák meg, és hogy ésszerű módon propagálja-e a hibát egy felhasználónak vagy hívónak. A legtöbb alkalmazásban elegendő néhány másodpercig vagy percig újrapróbálkozás.
A probléma észlelése
Az ügyfél szempontjából a probléma tünetei közé tartozhat a nagyon hosszú válaszidő vagy a feldolgozási idő, valamint a telemetriai adatok, amelyek a kapcsolat újrapróbálkozására tett ismétlődő kísérleteket jelzik.
A szolgáltatás szempontjából a probléma tünetei közé tartozhat az egyik ügyféltől érkező kérések nagy száma rövid időn belül, vagy egy ügyféltől érkező kérések nagy száma a kimaradásokból való helyreállítás során. A tünetek közé tartozhat a szolgáltatás helyreállítása során fellépő nehézség, vagy a szolgáltatás folyamatos kaszkádolt meghibásodása közvetlenül a hiba kijavítása után.
Diagnosztikai példa
Az alábbi szakaszok egy lehetséges újrapróbálkozási vihar észlelésének egyik megközelítését szemléltetik, mind az ügyféloldalon, mind a szolgáltatásoldalon.
Azonosítás ügyféltelemetria alapján
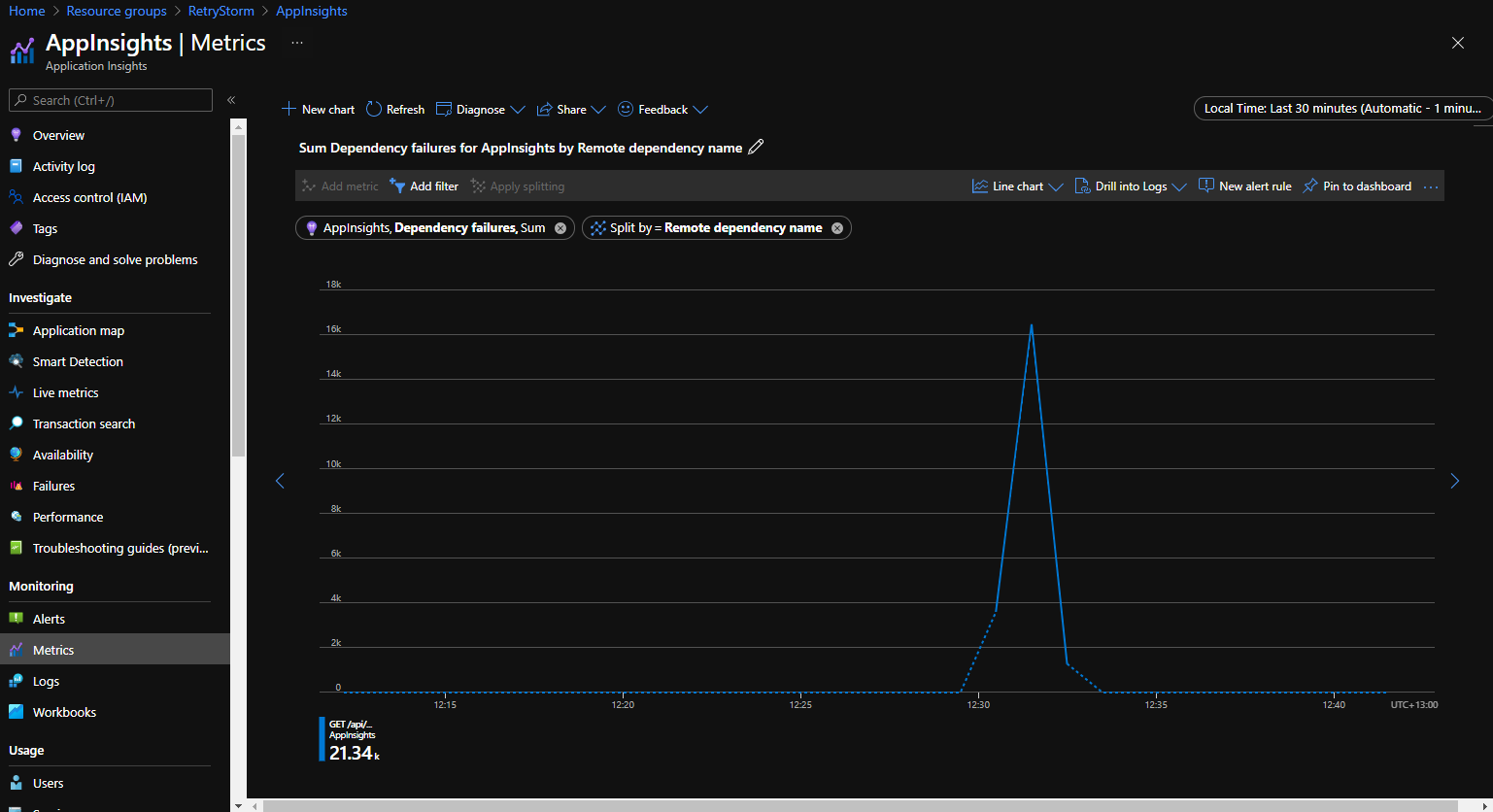
Azure-alkalmazás Insights rögzíti az alkalmazások telemetriáját, és elérhetővé teszi az adatokat a lekérdezéshez és a vizualizációhoz. A kimenő kapcsolatok függőségekként vannak nyomon követve, és a velük kapcsolatos információk elérhetők és diagramozhatók annak azonosításához, hogy egy ügyfél nagy számú kimenő kérést küld-e ugyanarra a szolgáltatásra.
Az alábbi gráf az Application Insights portál Metrikák lapjáról származik, és a Függőségi hibák metrika távoli függőség neve alapján felosztva jelenik meg. Ez azt a forgatókönyvet szemlélteti, amikor rövid időn belül nagy számú (több mint 21 000) sikertelen kapcsolati kísérlet történt egy függőségre.
Azonosítás kiszolgálói telemetria alapján
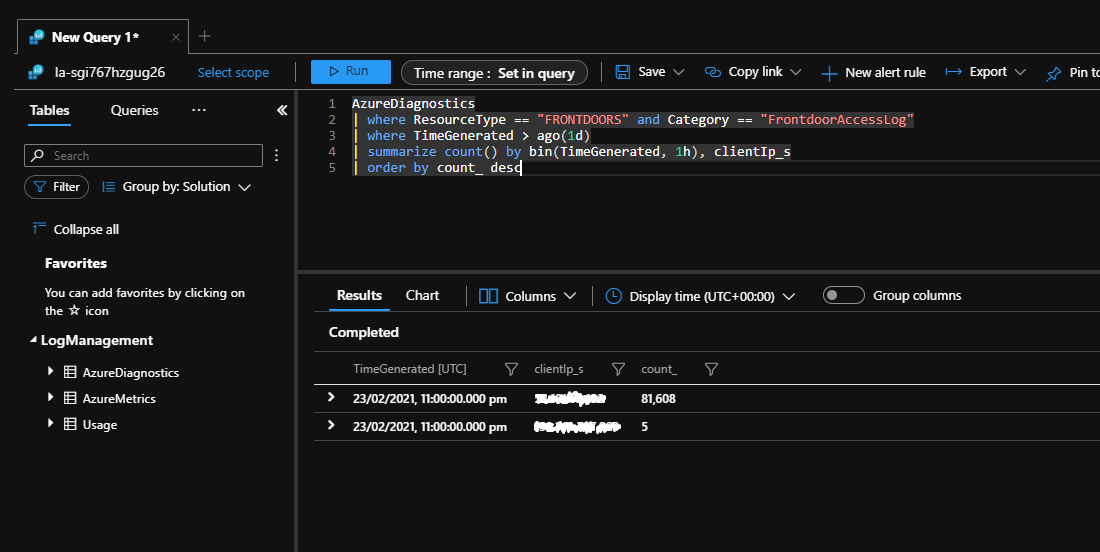
Előfordulhat, hogy a kiszolgálóalkalmazások nagy számú kapcsolatot észlelnek egyetlen ügyfélről. Az alábbi példában az Azure Front Door egy alkalmazás átjárójaként működik, és úgy lett konfigurálva, hogy minden kérést naplózzanak egy Log Analytics-munkaterületen.
Az alábbi Kusto-lekérdezés a Log Analyticsen futtatható. Azonosítja azokat az ügyfél IP-címeket, amelyek nagy számú kérést küldtek az alkalmazásnak az elmúlt napon.
AzureDiagnostics
| where ResourceType == "FRONTDOORS" and Category == "FrontdoorAccessLog"
| where TimeGenerated > ago(1d)
| summarize count() by bin(TimeGenerated, 1h), clientIp_s
| order by count_ desc
A lekérdezés újrapróbálkozási vihar során történő végrehajtása nagyszámú csatlakozási kísérletet jelenít meg egyetlen IP-címről.
Kapcsolódó források (lehet, hogy a cikkek angol nyelvűek)
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: