Ez a cikk áttekintést nyújt az Azure Architecture Centerben ismertetett Azure-adatbázis-megoldásokról.
Az Apache®, az Apache Cassandra® és a Hadoop embléma az Apache Software Foundation bejegyzett védjegyei vagy védjegyei a Egyesült Államok és/vagy más országokban. Az Apache Software Foundation nem támogatja ezeket a jeleket.
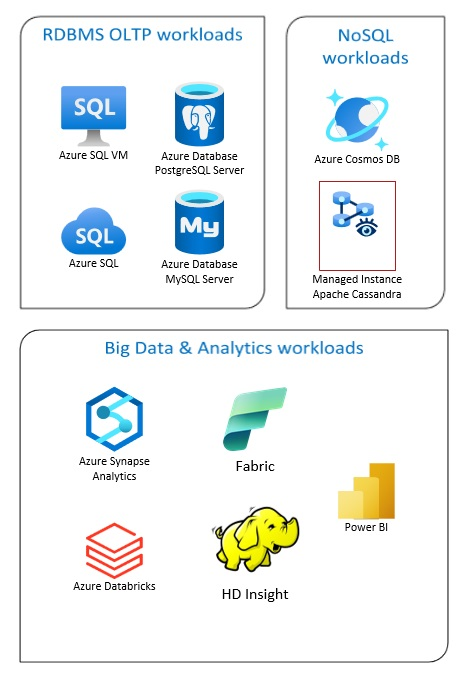
Az Azure Database-megoldások közé tartoznak a hagyományos relációsadatbázis-kezelő rendszerek (RDBMS és OLTP), a big data- és elemzési számítási feladatok (beleértve az OLAP-ot) és a NoSQL-számítási feladatok.
Az RDBMS számítási feladatai közé tartozik az online tranzakciófeldolgozás (OLTP) és az online elemzési feldolgozás (OLAP). A szervezet több forrásából származó adatok összevonhatók egy adattárházba. A forrásadatok áthelyezéséhez és átalakításához kinyerési, átalakítási és betöltési (ETL) vagy kinyerési, betöltési és átalakítási (ELT) folyamat használható. Az RDBMS-adatbázisokkal kapcsolatos további információkért lásd: Relációs adatbázisok felfedezése az Azure-ban.
A big data architektúrát úgy tervezték, hogy nagy vagy összetett adatok betöltését, feldolgozását és elemzését kezelje. A big data-megoldások általában nagy mennyiségű relációs és nem kapcsolódó adatot tartalmaznak, amelyek tárolására a hagyományos RDBMS-rendszerek nem alkalmasak. Ezek általában olyan megoldásokat tartalmaznak, mint a Data Lakes, a Delta Lakes és a lakehouses. További információ az Elemzési architektúra tervezésében.
A NoSQL-adatbázisokat felcserélhetően nem kapcsolódónak, NoSQL-nek vagy nem SQL-nek is nevezik, hogy kiemelje azt a tényt, hogy nagy mennyiségű gyorsan változó, strukturálatlan adatot képesek kezelni. Nem tárolnak adatokat táblákban, sorokban és oszlopokban, például (SQL-) adatbázisokban. További információ a No SQL DBs-adatbázisokról: NoSQL Data and What are NoSQL Databases?.
Ez a cikk az Azure-adatbázisok megismeréséhez nyújt forrásanyagokat. Felvázolja azokat az architektúrákat, amelyek megfelelnek az igényeinek és ajánlott eljárásainak, hogy a megoldások tervezése során szem előtt tarthassa azokat.
Számos architektúra közül választhat az adatbázis igényeinek kielégítéséhez. Emellett megoldási ötleteket is biztosítunk, amelyek a szükséges összetevőkre mutató hivatkozásokat tartalmaznak.
Tudnivalók az Azure-beli adatbázisokról
A megoldás lehetséges architektúráinak átgondolása során elengedhetetlen, hogy a megfelelő adattárat válassza. Ha még nem ismerkedik az Azure-beli adatbázisokkal, a legjobb kiindulópont a Microsoft Learn. Ez az ingyenes online platform videókkal és oktatóanyagokkal szolgál a gyakorlati tanuláshoz. A Microsoft Learn olyan képzési terveket kínál, amelyek a munkakörén alapulnak, például fejlesztő vagy adatelemző.
Az Azure különböző adatbázisainak és azok használatának általános leírásával kezdheti. Az Azure-adatmodulok között is böngészhet, és adattárolási megközelítést választhat az Azure-ban. Ezek a cikkek segítenek megérteni az Azure-adatmegoldásokban elérhető lehetőségeket, és megtudhatja, hogy egyes megoldások miért ajánlottak adott helyzetekben.
Az alábbiakban hasznosnak talál néhány Learn-modult:
- Az Azure-ba való migrálás megtervezése
- Az Azure SQL Database üzembe helyezése
- Az Azure-adatbázis- és elemzési szolgáltatások felfedezése
- Az Azure SQL Database védelme
- Azure Cosmos DB
- Azure Database for PostgreSQL
- Azure Database for MySQL
- SQL Server Azure-beli virtuális gépeken
Az éles környezet elérési útja
A relációs adatok kezeléséhez hasznos lehetőségek megtalálásához vegye figyelembe az alábbi erőforrásokat:
- Ha többet szeretne megtudni a több forrásból származó adatok gyűjtésére szolgáló erőforrásokról, valamint az adatfolyamok adatátalakításainak módjáról és alkalmazásáról, tekintse meg az Azure Analyticst.
- A nagy üzleti adatbázisok rendszerezését és az összetett elemzéseket támogató OLAP-ról az Online elemzési feldolgozás című témakörben olvashat.
- Az OLTP-rendszerek az üzleti interakciókat az előfordulásuk során rögzítik, lásd : Online tranzakciófeldolgozás.
A nem összefüggő adatbázisok nem használják a sorok és oszlopok táblázatos sémáját. További információ: Nem kapcsolódó adatok és NoSQL.
A nagy mennyiségű adatot natív, nyers formátumban tároló data lake-ekről további információt a Data Lakes című témakörben talál.
A big data architektúra képes kezelni a hagyományos adatbázisrendszerekhez túl nagy vagy túl összetett adatok betöltését, feldolgozását és elemzését. További információ: Big data-architektúrák és elemzések.
A hibrid felhő olyan informatikai környezet, amely egyesíti a nyilvános felhőt és a helyszíni adatközpontokat. További információ: Helyszíni adatmegoldások kiterjesztése a felhőre, vagy az Azure Arc és az Azure-adatbázisok együttes használata.
Az Azure Cosmos DB egy teljes mértékben felügyelt NoSQL adatbázis-szolgáltatás modern alkalmazásfejlesztéshez. További információ: Azure Cosmos DB erőforrásmodell.
Az Adatok átvitele az Azure-ba és az Azure-ból az Azure-ba történő átvitel lehetőségével kapcsolatban lásd: Adatok átvitele az Azure-ba és az Azure-ból.
Ajánlott eljárások
A megoldások tervezésekor tekintse át ezeket az ajánlott eljárásokat.
| Ajánlott eljárások | Leírás |
|---|---|
| Adatkezelési minták | Az adatkezelés a felhőalkalmazások kulcsfontosságú eleme. Ez befolyásolja a legtöbb minőségi attribútumot. |
| Tranzakciós kimenő üzenetek mintája az Azure Cosmos DB-vel | Megtudhatja, hogyan használhatja a tranzakciós kimenő üzenetek mintáját a megbízható üzenetkezeléshez és az események garantált kézbesítéséhez. |
| Az adatok globális elosztása az Azure Cosmos DB-vel | Az alacsony késés és a magas rendelkezésre állás érdekében egyes alkalmazásokat a felhasználókhoz közeli adatközpontokban kell üzembe helyezni. |
| Biztonság az Azure Cosmos DB-ben | A biztonsági ajánlott eljárások segítenek megelőzni, észlelni és reagálni az adatbázis-incidensekre. |
| Folyamatos biztonsági mentés időponthoz kötött visszaállítással az Azure Cosmos DB-ben | Ismerje meg az Azure Cosmos DB időponthoz kötött visszaállítási funkcióját. |
| Magas rendelkezésre állás elérése az Azure Cosmos DB-vel | Az Azure Cosmos DB több funkciót és konfigurációs lehetőséget biztosít a magas rendelkezésre állás eléréséhez. |
| Magas rendelkezésre állás az Azure SQL Database-hez és a felügyelt SQL-példányhoz | Az adatbázis nem lehet egyetlen meghibásodási pont az architektúrában. |
Technológiai lehetőségek
Az Azure Database-ekkel számos technológia használható. Ezek a cikkek segítenek kiválasztani az igényeinek leginkább megfelelő technológiákat.
- Adattár kiválasztása
- Elemzési adattár kiválasztása az Azure-ban
- Adatelemzési technológia kiválasztása az Azure-ban
- Kötegelt feldolgozási technológia kiválasztása az Azure-ban
- Big Data Storage-technológia kiválasztása az Azure-ban
- Adatfolyamat-vezénylési technológia kiválasztása az Azure-ban
- Keresési adattár kiválasztása az Azure-ban
- Streamfeldolgozási technológia kiválasztása az Azure-ban
Az adatbázisok naprakészen tartása
Tekintse meg az Azure-frissítéseket az Azure Databases technológia naprakészen tartásához.
Kapcsolódó erőforrások
Ezek az architektúrák adatbázis-technológiákat használnak.
Íme néhány egyéb erőforrás:
- Adatum Corporation-forgatókönyv az Azure-beli adatkezeléshez és -elemzéshez
- Lamna Healthcare-forgatókönyv adatkezeléshez és elemzéshez az Azure-ban
- SQL Server-példányok felügyeletének optimalizálása
- Relecloud-forgatókönyv az Azure-beli adatkezeléshez és -elemzéshez
Példamegoldások
Ezek a megoldási ötletek a példamegoldások közé tartoznak, amelyek az igényeihez igazíthatók.
- Adatgyorsítótár
- Vállalati adattárház
- Üzenetkezelés
- Kiszolgáló nélküli alkalmazások az Azure Cosmos DB használatával
Hasonló adatbázis-termékek
Ha ismeri az Amazon Web Servicest (AWS) vagy a Google Cloudot, tekintse meg az alábbi összehasonlításokat: