Az adattármodellek ismertetése
A modern üzleti rendszerek egyre nagyobb mennyiségű heterogén adatot kezelnek. Ez a sokféleség azt jelenti, hogy egyetlen adattár használata a legtöbb esetben nem megfelelő megoldás. Ehelyett gyakran jobb különböző típusú adatokat tárolni különböző adattárakban, amelyek mindegyike egy adott számítási feladatra vagy használati mintára összpontosít. A többnyelvű perzisztencia kifejezés az adattárolási technológiákat vegyesen használó megoldások leírására használatos. Ezért fontos megismerni a fő tárolási modelleket és azok kompromisszumait.
Az igényeinek megfelelő adattároló kiválasztása a tervezés egyik kulcsfontosságú döntése. Az SQL- és NoSQL-adatbázisok esetén több száz megvalósítási mód lehetséges. Az adattárakat általában az alapján kategorizáljuk, hogyan strukturálják az adatokat, illetve milyen műveleteket támogatnak. Ebben a cikkben a leggyakoribb tárolási modellek közül többet is ismertetünk. Vegye figyelembe, hogy egy adott adattároló technológia több tárolómodellt is támogathat. Például egy relációsadatbázis-kezelő rendszer (RDBMS) a kulcs/érték vagy a gráf típusú tárolókat is támogathatja. Az úgynevezett többmodelles támogatás általános trendje az, hogy egyetlen adatbázisrendszer több modellt is támogat. Ennek ellenére hasznos a különböző modellek magas szintű működésének megismerése.
Egy adott kategóriában nem minden adattár biztosítja ugyanazt a szolgáltatáskészletet. A legtöbb adattár kiszolgálóoldali funkciókat nyújt az adatok lekérdezéséhez és feldolgozásához. Egyes esetekben ez a funkció be van építve az adattár motorjába. Más esetekben az adattárolási és feldolgozási képességek elkülönülnek egymástól, és a feldolgozás és elemzés terén számos lehetőség közül választhat. Az adattárak különböző programozási és felügyeleti felületet is támogatnak.
Általánosan érvényes szabály, hogy elsőként azt kell eldöntenie, melyik tárolási modell felel meg legjobban az igényeinek. Ezután az adott kategórián belül válasszon ki egy adattárat a szolgáltatáskészlet, a költségek és az egyszerű kezelhetőséghez hasonló szempontok alapján.
Megjegyzés:
Az Azure-hoz készült Microsoft felhőadaptálási keretrendszer további információ az adatszolgáltatási követelmények felhőbevezetési követelményeinek azonosításáról és áttekintéséről. Hasonlóképpen megismerkedhet a tárolási eszközök és szolgáltatások kiválasztásával is.
Relációsadatbázis-kezelő rendszerek
A relációs adatbázisok kétdimenziós, sorokat és oszlopokat tartalmazó táblák sorozataként rendszerezik az adatokat. A legtöbb szállító a strukturált lekérdezési nyelv (SQL) dialektusát biztosítja az adatok beolvasásához és kezeléséhez. Egy RDBMS általában egy egységes tranzakciójú mechanizmust használ, amely az információfrissítés szempontjából megfelel az ACID-modellnek (Atomic, Consistent, Isolated, Durable – atomitás, konzisztencia, izoláció, tartósság).
Egy RDBMS általában egy írásiséma-modellt támogat, amelyben az adatok struktúrája előre meghatározott, és minden olvasási vagy írási műveletnek a sémát kell használnia.
Ez a modell nagyon hasznos, ha fontos az erős konzisztenciagarancia – ahol minden változás atomi, és a tranzakciók mindig konzisztens állapotban hagyják az adatokat. Az RDBMS azonban általában nem tud horizontálisan horizontálisan felskálázni az adatokat valamilyen módon. Emellett az RDBMS-ben lévő adatokat normalizálni kell, ami nem felel meg minden adathalmaznak.
Azure-szolgáltatások
- Azure SQL Database | (biztonsági alapkonfiguráció)
- Azure Database for MySQL | (biztonsági alapkonfiguráció)
- Azure Database for PostgreSQL | (biztonsági alapkonfiguráció)
- Azure Database for MariaDB | (biztonsági alapkonfiguráció)
Workload
- A rekordok gyakran jönnek létre és frissülnek.
- Több műveletet kell egyetlen tranzakción belül végrehajtani.
- A kapcsolatok kényszerítése az adatbázis korlátozásai révén valósul meg.
- A lekérdezési teljesítmény optimalizálása indexekkel történik.
Adattípus
- Az adatok nagymértékben normalizáltak.
- Az adatbázissémák szükségesek és kényszerítettek.
- Több-a-többhöz kapcsolatok az adatbázisban szereplő adatentitások között.
- A korlátozásokat a séma határozza meg, és alkalmazza az adatbázisban szereplő minden adatra.
- Szükséges az adatok nagy fokú integritása. Az indexeket és kapcsolatokat pontosan karban kell tartani.
- Szükséges az adatok erős konzisztenciája. A tranzakciók működésének módja biztosítja, hogy minden adat minden felhasználó és folyamat számára teljes mértékben megegyezzen.
- Az egyes adatbejegyzések mérete kicsi és közepes méretű.
Példák
- Készletkezelés
- Rendeléskezelés
- Jelentéskészítési adatbázis
- Könyvelés
Kulcs/érték tárolók
A kulcs/érték tároló minden adatértéket egyedi kulccsal társít. A legtöbb kulcs/érték tároló csak az egyszerű lekérdezési, beszúrási és törlési műveleteket támogatja. Egy érték (akár részleges, akár teljes) módosításához az alkalmazásnak a teljes értékre vonatkozóan felül kell írnia a meglévő adatokat. A legtöbb megvalósításban egyetlen érték olvasása vagy írása atomi műveletnek számít.
Az alkalmazások tetszőleges adatokat tárolhatnak értékhalmazként. Az alkalmazásnak minden sémainformációt meg kell adnia. A kulcs/érték tároló egyszerűen lekéri vagy kulcs szerint tárolja az értéket.
A kulcs-/értéktárolók rendkívül optimalizálva vannak az egyszerű kereséseket végző alkalmazásokhoz, de kevésbé megfelelőek, ha különböző kulcs-/értéktárolókban kell adatokat lekérdeznie. A kulcs-/értéktárolók nem is érték szerinti lekérdezésre vannak optimalizálva.
Egyetlen kulcs/érték tároló lehet rendkívüli mértékben skálázható, mivel az adattár könnyedén feloszthatja az adatokat több, külön gépeken található csomópont között.
Azure-szolgáltatások
- Azure Cosmos DB for Table és Azure Cosmos DB for NoSQL | (Azure Cosmos DB biztonsági alapkonfiguráció)
- Azure Cache for Redis | (biztonsági alapkonfiguráció)
- Azure Table Storage | (Biztonsági alapkonfiguráció)
Workload
- Az adatok elérése egyetlen kulccsal, például szótár használatával történik.
- Nincs szükség illesztésre, zárolásra vagy egyesítésre.
- Nem használ összesítési mechanizmusokat.
- A másodlagos indexeket általában nem használja.
Adattípus
- Minden kulcs egyetlen értékkel van társítva.
- Nincs sémakényszerítés.
- Nincsenek entitások közötti kapcsolatok.
Példák
- Adatok gyorsítótárazása
- Munkamenet-kezelés
- Felhasználói beállítások és profilkezelés
- Termékjavaslat és reklámszolgáltatás
Dokumentum-adatbázisok
A dokumentum-adatbázisok dokumentumgyűjteményt tárolnak, ahol minden dokumentum nevesített mezőkből és adatokból áll. Az adatok lehetnek egyszerű értékek vagy összetett elemek, például listák és gyermekgyűjtemények. A dokumentumokat egyedi kulcsok kérik le.
A dokumentumok általában egyetlen entitás, például ügyfél vagy megrendelés adatait tartalmazzák. A dokumentumok olyan információkat tartalmazhatnak, amelyek egy RDBMS több relációs táblájában is elférnek. A dokumentumoknak nem kell azonos struktúrával rendelkezniük. Az alkalmazások különböző adatokat tárolhatnak dokumentumokban, ahogyan változnak az üzleti követelmények.

Azure-szolgáltatás
Workload
- Gyakoriak a beszúrási és frissítési műveletek.
- Nincs objektumrelációs impedanica-eltérés. A dokumentumok jobban illeszkednek az alkalmazáskódban használt objektumstruktúrákhoz.
- Egyes dokumentumokat egyetlen blokként olvas be és ír a rendszer.
- Az adatokhoz többmezős indexelésre van szükség.
Adattípus
- Az adatok denormalizált módon is kezelhetők.
- Az egyes dokumentumadatok mérete viszonylag kicsi.
- Minden egyes dokumentumtípus használhatja a saját sémáját.
- A dokumentumok nem kötelező mezőket is tartalmazhatnak.
- A dokumentumadatok részben strukturáltak, ami azt jelenti, hogy az egyes mezők adattípusai nincsenek szigorúan meghatározva.
Példák
- Termékkatalógus
- Content management
- Készletkezelés
Gráfadatbázisok
A gráfadatbázisok kétféle típusú információt tárolnak: csomópontokat és éleket. Az élek a csomópontok közötti kapcsolatokat határozzák meg. A csomópontok és élek olyan tulajdonságokkal rendelkezhetnek, amelyek a tábla oszlopaihoz hasonlóan információt nyújtanak az adott csomópontról vagy élről. A szegélyeknek is lehet iránya, amely a kapcsolat természetét jelöli.
A gráfadatbázisok hatékonyan hajthatnak végre lekérdezéseket a csomópontok és élek hálózatán, és elemezhetik az entitások közötti kapcsolatokat. Az alábbi ábra egy szervezet gráfként strukturált személyzeti adatbázisát mutatja be. Az entitások alkalmazottak és részlegek, a peremhálózatok pedig a jelentéskészítési kapcsolatokat és azokat a részlegeket jelölik, amelyekben az alkalmazottak dolgoznak.
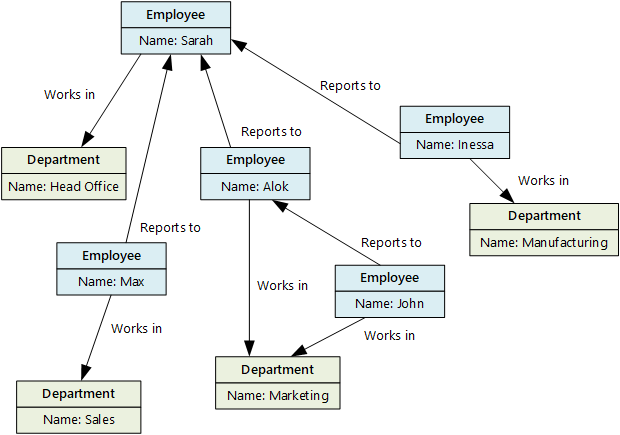
Ez a struktúra megkönnyíti az olyan lekérdezések elvégzését, mint a "Minden olyan alkalmazott megkeresése, aki közvetlenül vagy közvetve jelent Sarah-nak" vagy "Ki dolgozik ugyanabban a részlegben, mint John?" A sok entitást és kapcsolatot tartalmazó nagyméretű grafikonok esetében nagyon gyorsan végezhet nagyon összetett elemzéseket. Sok gráfadatbázis használ olyan lekérdezési nyelvet, amellyel egy kapcsolatokból álló hálózat hatékonyan bejárható.
Azure-szolgáltatások
- Azure Cosmos DB for Apache Gremlin | (biztonsági alapkonfiguráció)
- SQL Server | (biztonsági alapkonfiguráció)
Workload
- Összetett kapcsolatok az adatelemek között, amelyek számos ugrást foglalnak magukban a kapcsolódó adatelemek között.
- Az adatelemek közötti kapcsolat dinamikus, és az idő előrehaladtával változik.
- Az objektumok közötti kapcsolatok kiváló hozzáférést biztosítanak, a bejáráshoz nincs szükségük külső kulcsokra vagy illesztésekre.
Adattípus
- Csomópontok és kapcsolatok.
- A csomópontok a táblázatok soraihoz vagy a JSON-dokumentumokhoz hasonlítanak.
- A kapcsolatok épp olyan fontosak, mint a csomópontok, és a lekérdezési nyelvben közvetlenül megjelennek.
- Az összetett objektumokat (például egy több telefonszámmal rendelkező személy) a rendszer általában több kisebb csomópontra osztja szét, amelyeket bejárható kapcsolatok kötnek össze.
Példák
- Szervezeti diagramok
- Közösségi diagramok
- Csalások észlelése
- Javaslati motorok
Adatelemzés
Az adatelemzési tárolók nagymértékben párhuzamos megoldásokat biztosítanak az adatok betöltéséhez, tárolásához és elemzéséhez. Az adatok több kiszolgáló között oszlanak el a méretezhetőség maximalizálása érdekében. Az adatelemzésben széles körben használják a nagy adatfájlformátumokat, például a elválasztó fájlokat (CSV), a parquetet és az ORC-t . Az előzményadatokat általában olyan adattárakban tárolják, mint a Blob Storage vagy az Azure Data Lake Storage Gen2, amelyeket aztán külső táblákként az Azure Synapse, a Databricks vagy a HDInsight ér el. A teljesítmény szempontjából parquet-fájlokként tárolt adatokat használó tipikus forgatókönyvet a Synapse SQL külső táblák használata című cikk ismerteti.
Azure-szolgáltatások
- Azure Synapse Analytics | (biztonsági alapkonfiguráció)
- Azure Data Lake | (biztonsági alapkonfiguráció)
- Azure Data Explorer | (biztonsági alapkonfiguráció)
- Azure Analysis Services
- HDInsight | (biztonsági alapkonfiguráció)
- Azure Databricks | (biztonsági alapkonfiguráció)
Workload
- Adatelemzés
- Enterprise BI
Adattípus
- Több forrásból származó előzményadatok.
- Általában „csillag” vagy „hópehely” sémában denormalizálva. Tény- és dimenziótáblákból áll.
- Általában ütemezés szerint töltődik fel új adatokkal.
- A dimenziótáblák gyakran egy entitás több korábbi verzióját is tartalmazzák, amit lassan változó dimenziónak nevezünk.
Példák
- Nagyvállalati adattárház
Oszlopcsalád-adatbázisok
Az oszlopcsalád-adatbázisok sorokba és oszlopokba rendezik az adatokat. Legegyszerűbb formájában az oszlopcsalád-adatbázis a relációs adatbázishoz nagyon hasonlónak tűnhet, legalábbis a koncepciót tekintve. Az oszlopcsalád-adatbázisok igazi előnye a ritka adatok strukturálásának denormalizált megközelítésében rejlik.
Az oszlopcsalád-adatbázisok felfoghatók úgy, mintha a sorokat és oszlopokat tartalmazó táblázatba foglalt adatokról lenne szó, azonban az oszlopok oszlopcsaládoknak nevezett csoportokra vannak felosztva. Minden oszlopcsalád olyan oszlopokból álló készletet tartalmaz, amelyek logikailag kapcsolódnak egymáshoz, és beolvasásuk vagy módosításuk általában egy egységként történik. Az egyéb, külön elérhető adatok külön oszlopcsaládokban tárolhatók. Egy oszlopcsaládon belül az új oszlopok dinamikusan hozzáadhatók, a sorok pedig ritkák is lehetnek (ez azt jelenti, hogy a soroknak nem kell minden oszlophoz értéket tartalmazniuk).
Az alábbi ábrán látható példában két oszlopcsalád szerepel: Identity és Contact Info. Az egyetlen entitás adatai minden egyes oszlopcsaládban ugyanazt a sorkulcsot tartalmazzák. Ez a struktúra, amelyben az oszlopcsaládban szereplő egyes objektumokhoz tartozó sorok dinamikusan változhatnak, az oszlopcsalád-megközelítés egyik fontos előnye. Ezáltal ez az adattárolási forma kifejezetten alkalmas a strukturált, ideiglenes adatok tárolására.

A kulcs/érték tárolókkal vagy a dokumentum-adatbázisokkal ellentétben a legtöbb oszlopcsalád-adatbázis kulcs szerinti sorrendben tárolja az adatokat, nem pedig kivonatok számítása alapján. Számos megvalósítás esetén létrehozhat indexeket egy oszlopcsalád adott oszlopain. Az indexek révén az oszlop értéke szerint kérheti le az adatokat a sorkulcs helyett.
Az egy soron végrehajtott olvasási és írási műveletek általában atomi jellegűek egyetlen oszlopcsalád esetén, azonban egyes megvalósítások az egész, több oszlopcsaládon átívelő sorban biztosítják az atomitást.
Azure-szolgáltatások
- Azure Cosmos DB for Apache Cassandra | (Biztonsági alapkonfiguráció)
- HBase a HDInsightban | (biztonsági alapkonfiguráció)
Workload
- A legtöbb oszlopcsalád-adatbázis rendkívül gyorsan hajtja végre az írási műveleteket.
- A frissítési és törlési műveletek ritkák.
- Nagy teljesítmény és kis késleltetésű hozzáférés biztosítására tervezték.
- Támogatja egy jóval nagyobb méretű rekordon belüli adott mezőkészletre irányuló egyszerű lekérdezési hozzáféréseket.
- Nagy mértékben skálázható.
Adattípus
- Az adatok egy kulcsoszlopból és egy vagy több oszlopcsaládból álló táblákban tárolódnak.
- Az adott oszlopok az egyes sorokban eltérőek lehetnek.
- Az egyes cellák „get” és „put” parancsokkal érhetők el.
- Egy vizsgálat paranccsal több sort ad vissza.
Példák
- Javaslatok
- Személyre szabás
- Érzékelői adatok
- Telemetria
- Üzenetkezelés
- Közösségi médiaelemzés
- Webes elemzés
- Tevékenység figyelése
- Időjárási és egyéb idősorozat-adatok
Keresőmotor-adatbázisok
A keresőmotor-adatbázis lehetővé teszi, hogy az alkalmazások külső adattárakban tárolt információkat keressenek. A keresőmotor-adatbázisok nagy mennyiségű adatot indexelhetnek, és közel valós idejű hozzáférést biztosíthatnak ezekhez az indexekhez.
Az indexek lehetnek többdimenziósak, és támogathatják a szabad szöveges keresést a nagy kötegekből álló szöveges adatok esetén. Az indexelés elvégezhető egy lekérési modell használatával, amelyet a keresőmotor-adatbázis aktivál, vagy egy leküldéses modell használatával, amely külső alkalmazáskóddal indítható.
A keresés lehet pontos vagy intelligens. Az intelligens keresés olyan dokumentumokat keres, amelyek megfelelnek egy adott feltételkészletnek, és az egyezés mértékét is kiszámítja. Néhány keresőmotor támogatja az olyan nyelvi elemzéseket is, amelyek szinonimák, kategóriakiterjesztések (például dogs megfeleltetése pets-nek), szótővizsgálat (azonos szótővel rendelkező szavak megfeleltetése) alapján adnak vissza találatokat.
Azure-szolgáltatás
Workload
- Több forrásból és szolgáltatásból származó adatindexek.
- A lekérdezések ad-hoc jellegűek, és összetettek lehetnek.
- Teljes szöveges keresést igényel.
- Ad-hoc jellegű önkiszolgáló lekérdezéseket igényel.
Adattípus
- Félig strukturált vagy strukturálatlan szöveg
- Strukturált adatokra hivatkozó szöveg
Példák
- Termékkatalógusok
- Keresés webhelyen
- Logging
Idősorozat-adatbázisok
Az idősoradatok idő szerint rendezett értékek. Az idősorozat-adatbázisok általában nagy mennyiségű adatot gyűjtenek valós időben nagy számú forrásból. A frissítések ritkák, a törlések pedig a legtöbbször tömeges műveletként történnek. Annak ellenére, hogy az idősorozat-adatbázisokba írt rekordok mérete általában kicsi, gyakran előfordulnak nagy méretű rekordok, valamint az adatok összmérete is gyors ütemben növekedhet.
Azure-szolgáltatás
Workload
- A rekordok hozzáfűzése általában időrend szerint történik.
- A műveletek túlnyomó része (95-99%) írás.
- A frissítések ritkák.
- A törlések tömegesen fordulnak elő, céljaik általában egybefüggő blokkok vagy rekordok.
- Az adatok olvasása növekvő vagy csökkenő időrendben történik, gyakran párhuzamosan.
Adattípus
- Elsődleges kulcsként és rendezési mechanizmusként időbélyeget használunk.
- A címkék további információkat határozhatnak meg a bejegyzés típusáról, eredetéről és egyéb információiról.
Példák
- Monitorozás és eseménytelemetria.
- Érzékelő- és egyéb IoT-adatok.
Objektumtár
Az objektumtároló nagy méretű bináris objektumok (képek, fájlok, video- és audiostreamek, nagy méretű alkalmazás-adatobjektumok és dokumentumok, virtuális gépek lemezképei) tárolására van optimalizálva. A nagy adatfájlokat is népszerűen használják ebben a modellben, például elválasztó fájlt (CSV), parquetet és ORC-t. Az objektumtárolók rendkívül nagy mennyiségű strukturálatlan adatot kezelhetnek.
Azure-szolgáltatás
- Azure Blob Storage | (biztonsági alapkonfiguráció)
- Azure Data Lake Storage Gen2 | (biztonsági alapkonfiguráció)
Workload
- Kulcs azonosítja.
- A tartalom általában egy objektum, például elválasztó, kép vagy videófájl.
- A tartalomnak tartósnak és bármely alkalmazásszinten kívülinek kell lennie.
Adattípus
- Az adatok mérete nagy.
- Az érték nem átlátszó.
Példák
- Képek, videók, Office-dokumentumok, PDF-fájlok
- Statikus HTML, JSON, CSS
- Napló- és vizsgálati fájlok
- Adatbázisok biztonsági mentése
Megosztott fájlok
Időnként az egyszerű, egybesimított fájlok használata az információk tárolásának és lekérésének leghatékonyabb módja. A fájlmegosztások használatával a fájlok egy egész hálózaton elérhetők. A megfelelő biztonsági és egyidejű hozzáférési vezérlőmechanizmusok jelenlétében az adatok ilyen módon történő megosztása révén a megosztott szolgáltatások nagymértékben skálázható adathozzáférést biztosíthatnak az alapvető, alacsony szintű műveletek (például egyszerű olvasási és írási kérések) végrehajtásához.
Azure-szolgáltatás
Workload
- Áttelepítés meglévő alkalmazásokból, amelyek kommunikálnak a fájlrendszerrel.
- SMB-kapcsolatot igényel.
Adattípus
- Egy hierarchikus mappakészlet fájljai.
- Szabványos I/O-kódtárakkal elérhető.
Példák
- Örökölt fájlok
- A megosztott tartalom bizonyos számú virtuális gép vagy alkalmazáspéldány számára elérhető
A különböző adattárolási modellek megismerésével támogatott következő lépés a számítási feladat és az alkalmazás kiértékelése, valamint annak eldöntése, hogy melyik adattár felel meg az ön igényeinek. Az adattárolási döntési fával segítheti ezt a folyamatot.
További lépések
- Azure Cloud Storage-megoldások és -szolgáltatások
- A tárolási beállítások áttekintése
- A Microsoft Azure Storage bemutatása
- Az Azure Data Explorer bemutatása
Kapcsolódó erőforrások
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: