DTU-alapú vásárlási modell áttekintése
A következőre vonatkozik:![]() Azure SQL Database
Azure SQL Database
Ebben a cikkben megismerheti az Azure SQL Database DTU-alapú vásárlási modelljét.
További információkért tekintse át a virtuális magalapú vásárlási modellt , és hasonlítsa össze a vásárlási modelleket.
Adatbázis-tranzakciós egységek (DTU-k)
Az adatbázis-tranzakciós egység (DTU) a processzor, a memória, az olvasások és az írások kombinált mértéke. A DTU-alapú vásárlási modell szolgáltatási szintjeit a számítási méretek tartománya különbözteti meg, rögzített mennyiségű belefoglalt tárterülettel, a biztonsági másolatok rögzített megőrzési időtartamával és rögzített árával. A DTU-alapú vásárlási modell összes szolgáltatási szintje rugalmasságot biztosít a számítási méretek minimális állásidővel történő módosításához. Van azonban egy olyan időszak, amikor a kapcsolat rövid ideig megszakad az adatbázishoz, ami az újrapróbálkozási logikával enyhíthető. Az önálló adatbázisok és rugalmas készletek számlázása óránként történik a szolgáltatási szint és a számítási méret alapján.
Egy adott számítási mérettel rendelkező adatbázis esetében az Azure SQL Database garantálja az adott adatbázishoz tartozó erőforrások bizonyos szintjét (minden más adatbázistól függetlenül). Ez a garancia kiszámítható teljesítményszintet biztosít. Az adatbázisokhoz lefoglalt erőforrások mennyisége több DTU-ként van kiszámítva, és a számítási, tárolási és I/O-erőforrások egy csomagban megadott mértéke.
Az erőforrások közötti arányt eredetileg egy online tranzakciófeldolgozási (OLTP) teljesítményteszt számítási feladat határozza meg, amely a valós OLTP-számítási feladatokra jellemző. Ha a számítási feladat túllépi ezen erőforrások mennyiségét, az átviteli sebesség szabályozva lesz, ami lassabb teljesítményt és időtúllépést eredményez.
Önálló adatbázisok esetén a számítási feladat által használt erőforrások nem befolyásolják az Azure-felhő más adatbázisai számára elérhető erőforrásokat. Hasonlóképpen, a más számítási feladatok által használt erőforrások nem befolyásolják az adatbázis számára elérhető erőforrásokat.
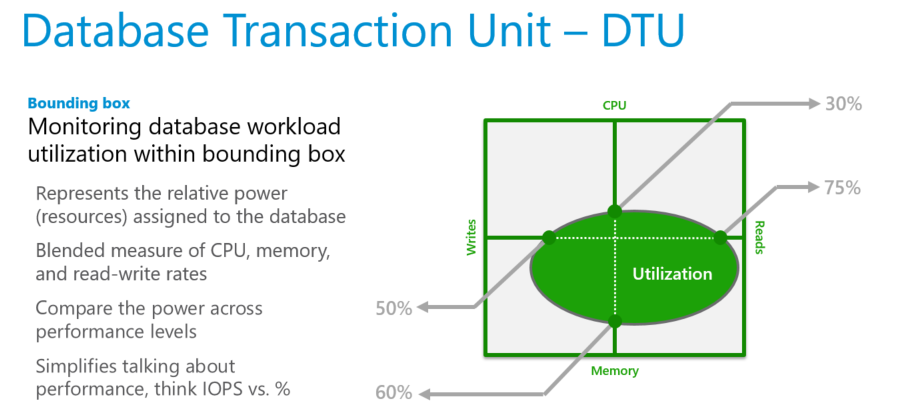
A DTU-k a leginkább hasznosak a különböző számítási méretekben és szolgáltatási szinteken lévő adatbázisokhoz lefoglalt relatív erőforrások megértéséhez. Például:
- A DTU-k megduplázása egy adatbázis számítási méretének növelésével egyenlő az adatbázis számára elérhető erőforráskészlet megduplázásával.
- A prémium szintű, 1750 DTU-val rendelkező P11-adatbázis 350-szer több DTU számítási teljesítményt biztosít, mint egy alapszintű, 5 DTU-val rendelkező szolgáltatásszint-adatbázis.
A számítási feladat erőforrás-(DTU-) felhasználásának részletesebb megismeréséhez használja a lekérdezési teljesítményre vonatkozó elemzéseket a következőre:
- Azonosítsa a leggyakoribb lekérdezéseket a processzor/időtartam/végrehajtás száma alapján, amelyek esetleg finomhangolhatók a jobb teljesítmény érdekében. Az I/O-igényes lekérdezések például kihasználhatják a memórián belüli optimalizálási technikákat , hogy jobban kihasználják a rendelkezésre álló memóriát egy bizonyos szolgáltatási szinten és számítási méretben.
- A lekérdezés részleteinek részletezése a lekérdezés szövegének és az erőforrás-használat előzményeinek megtekintéséhez.
- Tekintse meg az SQL Database Advisor által végrehajtott műveleteket bemutató teljesítmény-finomhangolási javaslatokat.
Rugalmas adatbázis-tranzakciós egységek (eDTU-k)
Ahelyett, hogy dedikált erőforráskészletet (DTU-kat) biztosítanának, amelyek nem mindig szükségesek, ezeket az adatbázisokat rugalmas készletbe helyezheti. A rugalmas készletben lévő adatbázisok az adatbázismotor egyetlen példányát használják, és ugyanazt az erőforráskészletet használják.
A rugalmas készlet megosztott erőforrásait rugalmas adatbázis-tranzakciós egységek (eDTU-k) mérik. A rugalmas készletek egyszerű, költséghatékony megoldást nyújtanak a teljesítménycélok kezelésére több olyan adatbázis esetében, amelyek használati mintái széles körben eltérőek és kiszámíthatatlanok. A rugalmas készlet garantálja, hogy a készlet egy adatbázisa nem használhatja fel az összes erőforrást, ugyanakkor biztosítja, hogy a készlet minden adatbázisa mindig rendelkezik a szükséges erőforrások minimális mennyiségével.
A készlet megadott számú eDTU-t kap a megadott árhoz. A rugalmas készletben az egyes adatbázisok automatikusan skálázhatók a konfigurált határokon belül. A nagyobb terhelésű adatbázisok több eDTU-t használnak fel az igények kielégítése érdekében. A kisebb terhelésű adatbázisok kevesebb eDTU-t használnak fel. A terhelés nélküli adatbázisok nem használnak eDTU-kat. Mivel az erőforrások az adatbázis helyett a teljes készlethez vannak kiépítve, a rugalmas készletek leegyszerűsítik a felügyeleti feladatokat, és kiszámítható költségvetést biztosítanak a készlet számára.
További eDTU-kat adhat hozzá egy meglévő készlethez minimális adatbázis-állásidővel. Hasonlóképpen, ha már nincs szüksége további eDTU-ra, távolítsa el őket egy meglévő készletből. Bármikor hozzáadhat adatbázisokat egy készlethez, vagy eltávolíthatja az adatbázisokat. Ha más adatbázisokhoz szeretne eDTU-kat lefoglalni, korlátozza a nagy terhelés alatt használható eDTU-adatbázisok számát. Ha egy adatbázis folyamatosan magas erőforrás-kihasználtsággal rendelkezik, amely hatással van a készlet többi adatbázisára, helyezze ki a készletből, és konfigurálja egyetlen adatbázisként, kiszámítható mennyiségű szükséges erőforrással.
Rugalmas erőforráskészlet előnyeit élvező számítási feladatok
A készletek ideálisak az alacsony erőforrás-kihasználtsággal és viszonylag ritkán kihasználtsággal rendelkező adatbázisokhoz. További információ: Mikor érdemes megfontolni egy rugalmas SQL Database-készletet?
A számítási feladathoz szükséges DTU-k számának meghatározása
Ha meglévő helyszíni vagy SQL Server virtuálisgép-számítási feladatot szeretne migrálni az SQL Database-be, tekintse meg a termékváltozatra vonatkozó javaslatokat a szükséges DTU-k számának közelítéséhez. Meglévő SQL Database-számítási feladatok esetén lekérdezési teljesítménybeli elemzésekkel megismerheti az adatbázis-erőforrás-felhasználást (DTU-kat), és mélyebb elemzéseket kaphat a számítási feladatok optimalizálásához. A sys.dm_db_resource_stats dinamikus felügyeleti nézet (DMV) lehetővé teszi az elmúlt óra erőforrás-fogyasztásának megtekintését. A sys.resource_stats katalógusnézet az elmúlt 14 nap erőforrás-felhasználását jeleníti meg, de az ötperces átlagok alacsonyabb hűsége esetén.
DTU-kihasználtság meghatározása
A DTU/eDTU-kihasználtság egy adatbázis vagy rugalmas készlet DTU/eDTU-korlátja alapján számított átlagos százalékos arányának meghatározásához használja az alábbi képletet:
avg_dtu_percent = MAX(avg_cpu_percent, avg_data_io_percent, avg_log_write_percent)
A képlet bemeneti értékei sys.dm_db_resource_stats, sys.resource_stats és sys.elastic_pool_resource_stats DMV-kből kérhetők le. Más szóval a DTU/eDTU-kihasználtság százalékos arányának meghatározásához egy adatbázis vagy egy rugalmas készlet DTU/eDTU-korlátja felé, válassza ki a legnagyobb százalékos értéket a következők közül: avg_cpu_percent, avg_data_io_percentés avg_log_write_percent egy adott időpontban.
Megjegyzés:
Az adatbázis DTU-korlátját a processzor, az olvasás, az írás és az adatbázis számára elérhető memória határozza meg. Mivel azonban az SQL Database-motor általában az összes rendelkezésre álló memóriát használja az adatgyorsítótárhoz a teljesítmény javítása érdekében, az avg_memory_usage_percent érték az adatbázis aktuális terhelésétől függetlenül általában közel 100 százalék lesz. Ezért annak ellenére, hogy a memória közvetetten befolyásolja a DTU-korlátot, a rendszer nem használja a DTU-kihasználtsági képletben.
Hardverkonfiguráció
A DTU-alapú vásárlási modellben az ügyfelek nem választhatják ki az adatbázisaikhoz használt hardverkonfigurációt. Bár egy adott adatbázis általában hosszú ideig (általában több hónapig) egy adott hardvertípuson marad, bizonyos események miatt az adatbázist más hardverre lehet áthelyezni.
Egy adatbázis például áthelyezhető más hardverre, ha fel- vagy leskálázva van egy másik szolgáltatási célkitűzésre, vagy ha az adatközpont jelenlegi infrastruktúrája megközelíti a kapacitáskorlátokat, vagy ha a jelenleg használt hardvert az élettartama miatt leszerelik.
Ha egy adatbázist más hardverre helyez át, a számítási feladatok teljesítménye változhat. A DTU-modell garantálja, hogy a DTU-teljesítményteszt számítási feladatainak átviteli sebessége és válaszideje lényegében megegyezik az adatbázis másik hardvertípusra való áthelyezésével, amíg a szolgáltatási célkitűzés (a DTU-k száma) változatlan marad.
Az Azure SQL Database-ben futó ügyfél-számítási feladatok széles spektrumában azonban hangsúlyosabb lehet a különböző hardverek ugyanazon szolgáltatási célkitűzéshez való használatának hatása. A különböző számítási feladatok különböző hardverkonfigurációk és funkciók előnyeit élvezhetik. Ezért a DTU-teljesítményteszttől eltérő számítási feladatok esetében a teljesítménybeli különbségek akkor láthatók, ha az adatbázis az egyik hardvertípusról a másikra kerül.
Az ügyfelek a virtuális mag modell használatával választhatják ki az előnyben részesített hardverkonfigurációt az adatbázis létrehozása és skálázása során. A virtuális mag modellben az egyes hardverkonfigurációkban szereplő egyes szolgáltatási célkitűzések részletes erőforráskorlátjai egyetlen adatbázisokhoz és rugalmas készletekhez vannak dokumentálva. A virtuálismag-modell hardverével kapcsolatos további információkért tekintse meg az SQL Database hardverkonfigurációját vagy a felügyelt SQL-példány hardverkonfigurációját.
Szolgáltatási szintek összehasonlítása
A szolgáltatási szint kiválasztása elsősorban az üzletmenet folytonossági, tárolási és teljesítménykövetelményeitől függ.
| Basic | Standard | Prémium | |
|---|---|---|---|
| Cél számítási feladat | Fejlesztés és gyártás | Fejlesztés és gyártás | Fejlesztés és gyártás |
| Üzemidejű SLA | 99.99% | 99.99% | 99.99% |
| Biztonsági mentés | Választható georedundáns, zónaredundáns vagy helyileg redundáns biztonsági mentési tároló, 1–7 napos megőrzés (alapértelmezett 7 nap) Akár 10 évig tartó hosszú távú megőrzés |
Választható georedundáns, zónaredundáns vagy helyileg redundáns biztonsági mentési tároló, 1–35 napos megőrzés (alapértelmezett 7 nap) Akár 10 évig tartó hosszú távú megőrzés |
Helyileg redundáns (LRS), zónaredundáns (ZRS) vagy georedundáns (GRS) tároló kiválasztása 1-35 nap (alapértelmezés szerint 7 nap) megőrzés, legfeljebb 10 év hosszú távú megőrzési idő áll rendelkezésre |
| CPU | Alacsony | Alacsony, Közepes, Magas | Közepes, Magas |
| IOPS (hozzávetőleges)* | 1-4 IOPS/DTU | 1-4 IOPS/DTU | >DTU-nként 25 IOPS |
| IO-késés (hozzávetőleges) | 5 ms (olvasás), 10 ms (írás) | 5 ms (olvasás), 10 ms (írás) | 2 ms (olvasás/írás) |
| Oszlopcentrikus indexelés | N/A | Standard S3 és újabb | Támogatott |
| Memóriabeli OLTP | N/A | N/A | Támogatott |
* Minden olvasási és írási IOPS adatfájlok, beleértve a háttér IO (ellenőrzőpont és lusta író).
Fontos
Az Alapszintű, S0, S1 és S2 szolgáltatási célkitűzések kevesebb virtuális magot (CPU-t) biztosítanak. A processzorigényes számítási feladatok esetében ajánlott az S3 vagy annál nagyobb szolgáltatási célkitűzés.
Az Alapszintű, az S0 és az S1 szolgáltatás célkitűzéseiben az adatbázisfájlok az Azure Standard Storage-ban vannak tárolva, amely merevlemez-alapú (HDD)-alapú tároló adathordozót használ. Ezek a szolgáltatási célkitűzések leginkább a fejlesztéshez, teszteléshez és más ritkán használt számítási feladatokhoz ideálisak, amelyek kevésbé érzékenyek a teljesítmény változékonyságára.
Tipp
Egy adatbázis vagy rugalmas készlet tényleges erőforrás-szabályozási korlátainak megtekintéséhez kérdezze le a sys.dm_user_db_resource_governance nézetet. Egyetlen adatbázis esetén a függvény egy sort ad vissza. Rugalmas készletben lévő adatbázisok esetén a készletben lévő összes adatbázishoz egy sor lesz visszaadva.
Megjegyzés:
Ingyenes Azure SQL Database-adatbázist az Alapszintű szolgáltatási szinten szerezhet be ingyenes Azure-fiókkal. További információ: Felügyelt felhőadatbázis létrehozása ingyenes Azure-fiókkal.
Erőforráskorlátok
Az erőforráskorlátok az önálló és a készletezett adatbázisok esetében különböznek.
Önálló adatbázis tárolási korlátai
Az Azure SQL Database-ben a számítási méretek az önálló adatbázisok adatbázis-tranzakciós egységei (DTU-k) és a rugalmas készletek rugalmas adatbázis-tranzakciós egységei (eDTU-k) szerint vannak kifejezve. További információkért tekintse át az önálló adatbázisok erőforráskorlátait.
| Basic | Standard | Prémium | |
|---|---|---|---|
| Maximális tárterületméret | 2 GB | 1 TB | 4 TB |
| Maximális DTU-k | 5 | 3000 | 4000 |
Fontos
Bizonyos körülmények között előfordulhat, hogy egy adatbázist zsugorítania kell a fel nem használt terület visszaszerzéséhez. További információ: Fájltér kezelése az Azure SQL Database-ben.
Rugalmas készletkorlátok
További információkért tekintse át a készletezett adatbázisok erőforráskorlátait.
| Basic | Standard | Prémium | |
|---|---|---|---|
| Adatbázisonkénti tárterület maximális mérete | 2 GB | 1 TB | 1 TB |
| Készletenkénti maximális tárterületméret | 156 GB | 4 TB | 4 TB |
| Adatbázisonkénti eDTU-k maximális száma | 5 | 3000 | 4000 |
| Készletenkénti maximális eDTU-k | 1600 | 3000 | 4000 |
| Az adatbázisok maximális száma készletenként | 500 | 500 | 100 |
Fontos
A Prémium szinten jelenleg több mint 1 TB tárterület érhető el, kivéve: Kelet-Kína, Észak-Kína, Közép-Németország és Északkelet-Németország. Ezekben a régiókban a prémium szinthez tartozó tárterület maximuma 1 TB. További információ: P11-P15 aktuális korlátozások.
Fontos
Bizonyos körülmények között előfordulhat, hogy egy adatbázist zsugorítania kell a fel nem használt terület visszaszerzéséhez. További információ: Fájltér kezelése az Azure SQL Database-ben.
DTU-teljesítményteszt
Az egyes DTU-mértékekhez társított fizikai jellemzők (CPU, memória, IO) egy valós adatbázis-számítási feladatot szimuláló teljesítményteszt használatával vannak kalibrálva.
Ismerje meg a DTU-teljesítményteszthez társított sémát, tranzakciótípusokat, számítási feladatokat, felhasználókat és pacingot, skálázási szabályokat és metrikákat.
DTU-alapú és virtuálismag-vásárlási modellek összehasonlítása
Bár a DTU-alapú vásárlási modell a számítási, tárolási és I/O-erőforrások egy csomagban megadott mértékén alapul, az Azure SQL Database virtuálismag-vásárlási modelljének összehasonlításával önállóan választhatja ki és méretezheti a számítási és tárolási erőforrásokat.
A virtuális magalapú vásárlási modell lehetővé teszi az SQL Serverhez készült Azure Hybrid Benefit használatát is a költségek megtakarításához, valamint kiszolgáló nélküli és rugalmas skálázási lehetőségeket kínál az Azure SQL Database-hez, amelyek nem érhetők el a DTU-alapú vásárlási modellben.
További információ: Az Azure SQL Database virtuális mag- és DTU-alapú vásárlási modelljeinek összehasonlítása.
További lépések
A modellek megvásárlásáról és a kapcsolódó fogalmakról az alábbi cikkekben talál további információt:
- Az önálló adatbázisokhoz elérhető konkrét számítási méretekről és tárméret-lehetőségekről az önálló adatbázisokra vonatkozó DTU-alapú SQL Database-erőforráskorlátokról olvashat.
- A rugalmas készletekhez elérhető konkrét számítási méretekről és tárméret-lehetőségekről további információt az SQL Database DTU-alapú erőforráskorlátjaiban talál.
- A DTU-alapú vásárlási modellhez társított referenciamutatóval kapcsolatos információkért lásd a DTU-teljesítménytesztet.
- Hasonlítsa össze az Azure SQL Database virtuális mag- és DTU-alapú vásárlási modelljeit.
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: