Dokumentumintelligencia-elrendezési modell
Fontos
- A Document Intelligence nyilvános előzetes verziójú kiadásai korai hozzáférést biztosítanak az aktív fejlesztés alatt lévő funkciókhoz.
- A funkciók, a megközelítések és a folyamatok az általános rendelkezésre állás (GA) előtt változhatnak a felhasználói visszajelzések alapján.
- A Document Intelligence ügyfélkódtárak nyilvános előzetes verziója alapértelmezés szerint a REST API 2024-02-29-preview verziója.
- A nyilvános előzetes verzió 2024-02-29 előzetes verziója jelenleg csak a következő Azure-régiókban érhető el:
- USA keleti régiója
- USA2 nyugati régiója
- Nyugat-Európa
Ez a tartalom a következőre vonatkozik::![]() v4.0 (előzetes verzió) | Korábbi verziók:
v4.0 (előzetes verzió) | Korábbi verziók:![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)![]() v2.1 (GA)
v2.1 (GA)
Ez a tartalom a következőre vonatkozik::![]() v3.1 (GA) | Legújabb verzió:
v3.1 (GA) | Legújabb verzió:![]() v4.0 (előzetes verzió) | Korábbi verziók:
v4.0 (előzetes verzió) | Korábbi verziók:![]() v3.0
v3.0![]() v2.1
v2.1
Ez a tartalom a következőre vonatkozik::![]() v3.0 (GA) | Legújabb verziók:
v3.0 (GA) | Legújabb verziók:![]() v4.0 (előzetes verzió)
v4.0 (előzetes verzió)![]() v3.1 | Korábbi verzió:
v3.1 | Korábbi verzió:![]() v2.1
v2.1
Ez a tartalom a következőre vonatkozik::![]() v2.1 | Legújabb verzió:
v2.1 | Legújabb verzió:![]() v4.0 (előzetes verzió)
v4.0 (előzetes verzió)
A Dokumentumintelligencia-elrendezési modell egy fejlett, gépi tanuláson alapuló dokumentumelemzési API, amely a Dokumentumintelligencia-felhőben érhető el. Lehetővé teszi a különböző formátumú dokumentumok készítését és a dokumentumok strukturált adatábrázolásának visszaadását. A hatékony optikai karakterfelismerési (OCR) képességek továbbfejlesztett verzióját ötvözi mélytanulási modellekkel a szöveg, a táblázatok, a kijelölési jelek és a dokumentumstruktúra kinyeréséhez.
Dokumentumelrendezés elemzése
A dokumentumstruktúra elrendezésének elemzése egy dokumentum elemzésének folyamata, amely kinyeri az érdekes régiókat és azok kapcsolatait. A cél a szöveg és a szerkezeti elemek kinyerése az oldalról, hogy jobb szemantikai megértési modelleket hozzon létre. A dokumentumelrendezés két szerepkörtípust különböztet meg:
- Geometriai szerepkörök: A szöveg, a táblázatok, az ábrák és a kijelölési jelek geometriai szerepkörökre mutatnak példákat.
- Logikai szerepkörök: A címek, címsorok és élőlábak példák a szövegek logikai szerepköreire.
Az alábbi ábra egy mintalap képének tipikus összetevőit mutatja be.

Fejlesztési lehetőségek
A Document Intelligence v4.0 (2024-02-29-preview, 2023-10-31-preview) a következő eszközöket, alkalmazásokat és kódtárakat támogatja:
| Szolgáltatás | Források | Modellazonosító |
|---|---|---|
| Elrendezési modell | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
előre összeállított elrendezés |
A Document Intelligence v3.1 a következő eszközöket, alkalmazásokat és kódtárakat támogatja:
| Szolgáltatás | Források | Modellazonosító |
|---|---|---|
| Elrendezési modell | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
előre összeállított elrendezés |
A Document Intelligence 3.0-s verzió a következő eszközöket, alkalmazásokat és kódtárakat támogatja:
| Szolgáltatás | Források | Modellazonosító |
|---|---|---|
| Elrendezési modell | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
előre összeállított elrendezés |
A Document Intelligence v2.1 a következő eszközöket, alkalmazásokat és kódtárakat támogatja:
| Szolgáltatás | Források |
|---|---|
| Elrendezési modell | • Dokumentumintelligencia-címkézési eszköz • REST API • Ügyfélkódtár SDK • Dokumentumintelligencia Docker-tároló |
Bemeneti követelmények
A legjobb eredmény érdekében dokumentumonként egy tiszta fényképet vagy kiváló minőségű vizsgálatot biztosít.
Támogatott fájlformátumok:
Modell PDF Kép:
JPEG/JPG, PNG, BMP, TIFF, HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX) és HTMLOlvasás ✔ ✔ ✔ Elrendezés ✔ ✔ ✔ (2024-02-29-preview, 2023-10-31-preview) Általános dokumentum ✔ ✔ Előre összeállított ✔ ✔ Egyéni kinyerés ✔ ✔ Egyéni besorolás ✔ ✔ ✔ (2024-02-29-preview) PDF és TIFF esetén legfeljebb 2000 oldal dolgozható fel (ingyenes szintű előfizetéssel csak az első két oldal dolgozható fel).
A dokumentumok elemzéséhez használt fájlméret 500 MB a fizetős (S0) és 4 MB az ingyenes (F0) szint esetén.
A képméreteknek 50 x 50 képpont és 10 000 képpont x 10 000 képpont között kell lenniük.
Ha a PDF-eket jelszó védi, akkor beküldés előtt el kell távolítania a védelmet.
A kinyerni kívánt szöveg minimális magassága 12 képpont egy 1024 x 768 képpontos képhez. Ez a dimenzió körülbelül
8150 pont/hüvelyk (DPI) pont szövegnek felel meg.Egyéni modell betanítása esetén a betanítási adatok oldalainak maximális száma az egyéni sablonmodell esetében 500, az egyéni neurális modell esetében pedig 50 000.
Egyéni extrakciós modell betanítása esetén a betanítási adatok teljes mérete sablonmodell esetén 50 MB, a neurális modell esetében pedig 1G-MB.
Egyéni besorolási modell betanítása esetén a betanítási adatok
1GBteljes mérete legfeljebb 10 000 oldal lehet.
- Támogatott fájlformátumok: JPEG, PNG, PDF és TIFF.
- Támogatott oldalak száma: PDF és TIFF esetén legfeljebb 2000 oldal feldolgozása történik. Az ingyenes szintű előfizetők számára csak az első két oldal feldolgozása történik meg.
- Támogatott fájlméret: a fájlméretnek 50 MB-nál kisebbnek és legalább 50 x 50 képpont méretűnek és legfeljebb 10 000 x 10 000 képpontnak kell lennie.
Az Elrendezési modell használatának első lépései
Megtudhatja, hogyan nyerik ki az adatokat, beleértve a szöveget, a táblázatfejléceket, a kijelölési jeleket és a struktúraadatokat a dokumentumokból a Dokumentumintelligencia használatával. A következő erőforrásokra van szüksége:
Azure-előfizetés – ingyenesen létrehozhat egyet.
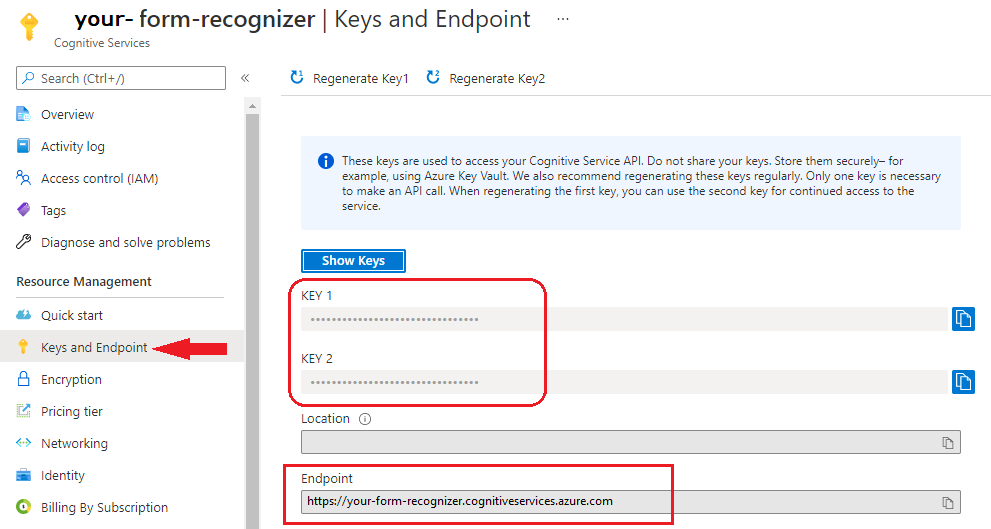
Dokumentumintelligencia-példány az Azure Portalon. A szolgáltatás kipróbálásához használhatja az ingyenes tarifacsomagot (
F0). Az erőforrás üzembe helyezése után válassza az Ugrás az erőforráshoz lehetőséget a kulcs és a végpont lekéréséhez.
Feljegyzés
A Document Intelligence Studio 3.0-s és újabb verziójú API-kkal érhető el.
A Document Intelligence Studióval feldolgozott mintadokumentum

A Document Intelligence Studio kezdőlapján válassza az Elrendezés lehetőséget.
Elemezheti a mintadokumentumot, vagy feltöltheti saját fájljait.
Válassza az Elemzés futtatása gombot, és szükség esetén konfigurálja az Elemzési beállításokat:

Dokumentumintelligencia-mintacímkéző eszköz
Lépjen a Dokumentumintelligencia mintaeszközre.
A mintaeszköz kezdőlapján válassza az Elrendezés használata lehetőséget a szöveg, a táblázatok és a kijelölési jelek lekéréséhez.
A Dokumentumintelligencia szolgáltatás végpont mezőjébe illessze be a Dokumentumintelligencia-előfizetéssel beszerzett végpontot.
A kulcsmezőbe illessze be a Dokumentumintelligencia-erőforrásból beszerzett kulcsot.
A Forrás mezőben válassza az URL-címet a legördülő menüből. Használhatja a mintadokumentumot:
Válassza a Beolvasás gombot.
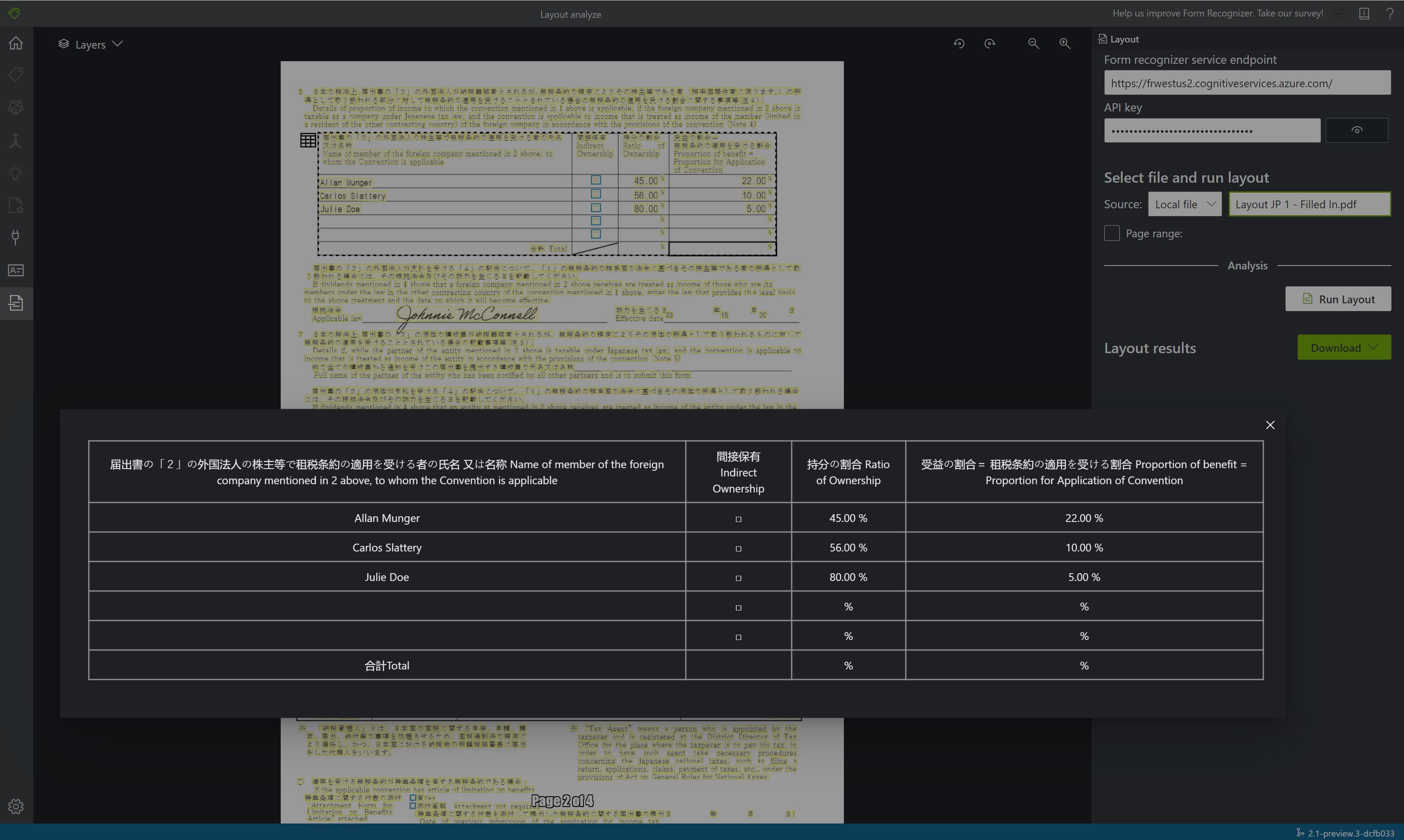
Válassza a Futtatás elrendezése lehetőséget. A dokumentumintelligencia-mintacímkézési eszköz meghívja az
Analyze LayoutAPI-t a dokumentum elemzéséhez.
Az eredmények megtekintése – lásd a kiemelt kinyert szöveget, az észlelt kijelölési jeleket és az észlelt táblákat.
{kind=link}
Támogatott nyelvek és területi beállítások
A támogatott nyelvek teljes listáját a Nyelvi támogatás – dokumentumelemzési modellek oldalon találja.
A Document Intelligence v2.1 a következő eszközöket, alkalmazásokat és kódtárakat támogatja:
| Szolgáltatás | Források |
|---|---|
| Layout API |
Adatkinyerés
Az elrendezési modell szövegeket, kijelölési jeleket, táblázatokat, bekezdéseket és bekezdéstípusokat (roles) nyer ki a dokumentumokból.
Feljegyzés
2023-10-31-previewA verziók és újabb verziók 2024-02-29-previewtámogatják a Microsoft Office-t (DOCX, XLSX, PPTX) és HTML-fájlokat. A következő funkciók nem támogatottak:
- Nincs szög, szélesség/magasság és egység az egyes oldalobjektumokkal.
- Minden észlelt objektum esetében nincs határoló sokszög vagy határoló régió.
- Az oldaltartomány (
pages) paraméterként nem támogatott. - Nincs
linesobjektum.
Oldalak
A lapgyűjtemény a dokumentum lapjainak listája. Minden oldal egymás után jelenik meg a dokumentumban, és tartalmazza a tájolási szöget, amely azt jelzi, hogy az oldal elforgatva van-e, valamint a szélességet és a magasságot (képpontban megadott méretek). A modell kimenetének oldalegységei az alábbi módon lesznek kiszámítva:
| Fájlformátum | Számított oldalegység | Összes oldal |
|---|---|---|
| Képek (JPEG/JPG, PNG, BMP, HEIF) | Minden kép = 1 oldalegység | Összes kép |
| A PDF minden oldala = 1 oldalegység | A PDF összes oldala | |
| TIFF | A TIFF minden képe = 1 oldal | Összes kép a TIFF-ben |
| Word (DOCX) | Legfeljebb 3000 karakter = 1 oldalegység, beágyazott vagy csatolt képek nem támogatottak | Legfeljebb 3000 karakter hosszúságú oldalak összesen |
| Excel (XLSX) | Minden munkalap = 1 oldalegység, beágyazott vagy csatolt képek nem támogatottak | Munkalapok összesen |
| PowerPoint (PPTX) | Minden dia = 1 oldalegység, beágyazott vagy csatolt képek nem támogatottak | Összes dia |
| HTML | Legfeljebb 3000 karakter = 1 oldalegység, beágyazott vagy csatolt képek nem támogatottak | Legfeljebb 3000 karakter hosszúságú oldalak összesen |
"pages": [
{
"pageNumber": 1,
"angle": 0,
"width": 915,
"height": 1190,
"unit": "pixel",
"words": [],
"lines": [],
"spans": []
}
]
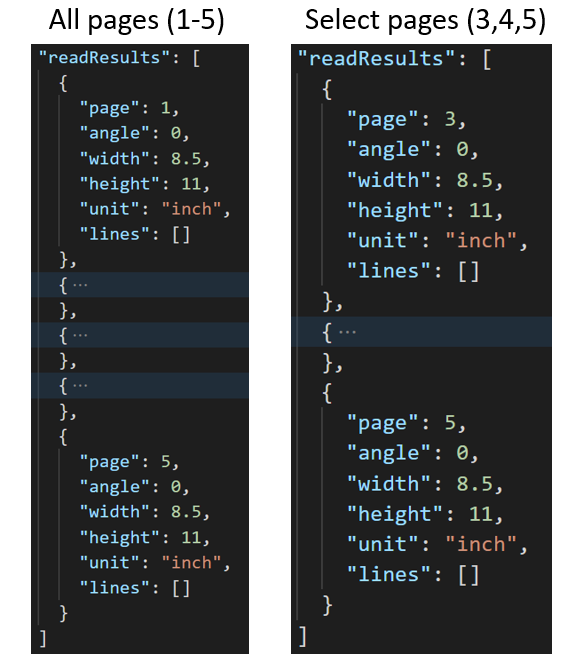
Kijelölt lapok kinyerése dokumentumokból
Nagyméretű, többoldalas dokumentumok esetén a pages lekérdezési paraméterrel konkrét oldalszámokat vagy oldaltartományokat jelölhet a szöveg kinyeréséhez.
Bekezdések
Az Elrendezési modell a gyűjtemény összes azonosított szövegblokkját legfelső szintű objektumként nyeri ki a paragraphs gyűjtemény alatt analyzeResults. A gyűjtemény minden bejegyzése egy szövegblokkot jelöl, és tartalmazza a kinyert szöveget éscontenta határoló polygon koordinátákat. Az span információk a dokumentum teljes szövegét tartalmazó legfelső szintű content tulajdonság szövegtöredékére mutatnak.
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
Bekezdésszerepkörök
Az új gépi tanuláson alapuló lapobjektum-észlelés olyan logikai szerepköröket nyer ki, mint a címek, szakaszfejlécek, oldalfejlécek, oldallábak stb. A Dokumentumintelligencia-elrendezés modell bizonyos szövegblokkokat rendel hozzá a gyűjteményhez a paragraphs modell által előrejelzett speciális szerepkörrel vagy típussal. Strukturálatlan dokumentumokkal a legjobban a kinyert tartalom elrendezésének megértéséhez használhatók a részletesebb szemantikai elemzéshez. A következő bekezdésszerepkörök támogatottak:
| Előrejelzett szerepkör | Leírás | Támogatott fájltípusok |
|---|---|---|
title |
A lap fő címsorai | pdf, image, docx, pptx, xlsx, html |
sectionHeading |
Egy vagy több alcím a lapon | pdf, image, docx, xlsx, html |
footnote |
Szöveg a lap alján | pdf, kép |
pageHeader |
Szöveg a lap felső széle közelében | pdf, kép, docx |
pageFooter |
Szöveg a lap alsó széle közelében | pdf, image, docx, pptx, html |
pageNumber |
Oldalszám | pdf, kép |
{
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"role": "title",
"content": "NEWS TODAY"
},
{
"spans": [],
"boundingRegions": [],
"role": "sectionHeading",
"content": "Mirjam Nilsson"
}
]
}
Szöveg, sorok és szavak
A Dokumentumintelligencia dokumentumelrendezési modellje kinyeri a nyomtatott és a kézzel írt stílusszöveget.lineswords A styles gyűjtemény tartalmaz minden kézzel írt stílust a vonalakhoz, ha észlelik, valamint a társított szövegre mutató spanokat. Ez a funkció a támogatott kézzel írt nyelvekre vonatkozik.
Microsoft Word, Excel, PowerPoint és HTML esetén a Dokumentumintelligencia 2024-02-29-preview és a 2023-10-31 előzetes verziójú elrendezési modell az összes beágyazott szöveget kinyeri. A szövegek szavakként és bekezdésekként lesznek kinyerve. A beágyazott képek nem támogatottak.
"words": [
{
"content": "While",
"polygon": [],
"confidence": 0.997,
"span": {}
},
],
"lines": [
{
"content": "While healthcare is still in the early stages of its Al journey, we",
"polygon": [],
"spans": [],
}
]
Kézzel írt stílus szövegsorokhoz
A válasz magában foglalja annak besorolását, hogy az egyes szövegsorok kézírásstílusúak-e vagy sem, valamint egy megbízhatósági pontszámot. További tudnivalók. Lásd: Kézzel írt nyelvi támogatás. Az alábbi példa egy JSON-kódrészletet mutat be.
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
Ha engedélyezi a betűtípus-/stílus hozzáadása funkciót, akkor az objektum részeként is megkapja a styles betűtípus/stílus eredményét.
Kijelölési jelek
Az Elrendezési modell kijelölési jeleket is kinyer a dokumentumokból. A kinyert kijelölési jelek az egyes lapok gyűjteményében pages jelennek meg. Ezek közé tartozik a határolókeret polygon, confidenceés a kijelölés state (selected/unselected). A szövegábrázolás (vagyis :selected::unselected) is szerepel a kezdőindexben (offset), és length a dokumentum teljes szövegét tartalmazó legfelső szintű content tulajdonságra hivatkozik.
{
"selectionMarks": [
{
"state": "unselected",
"polygon": [],
"confidence": 0.995,
"span": {
"offset": 1421,
"length": 12
}
}
]
}
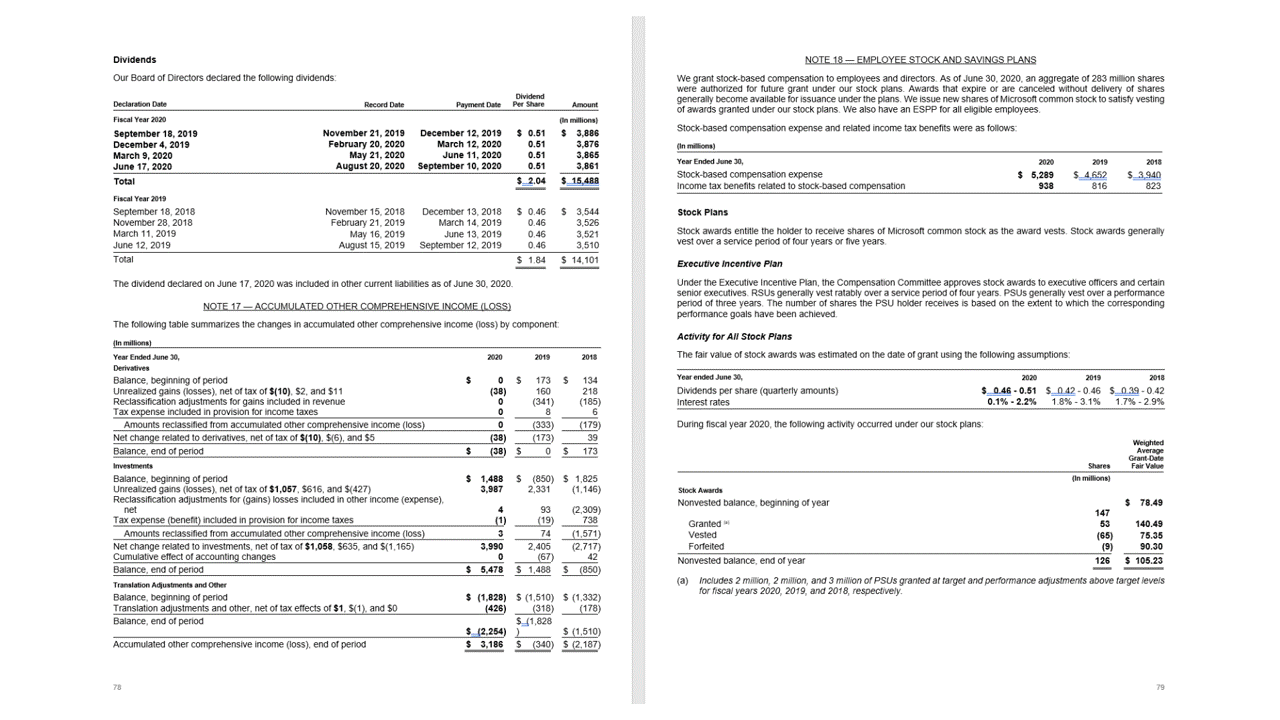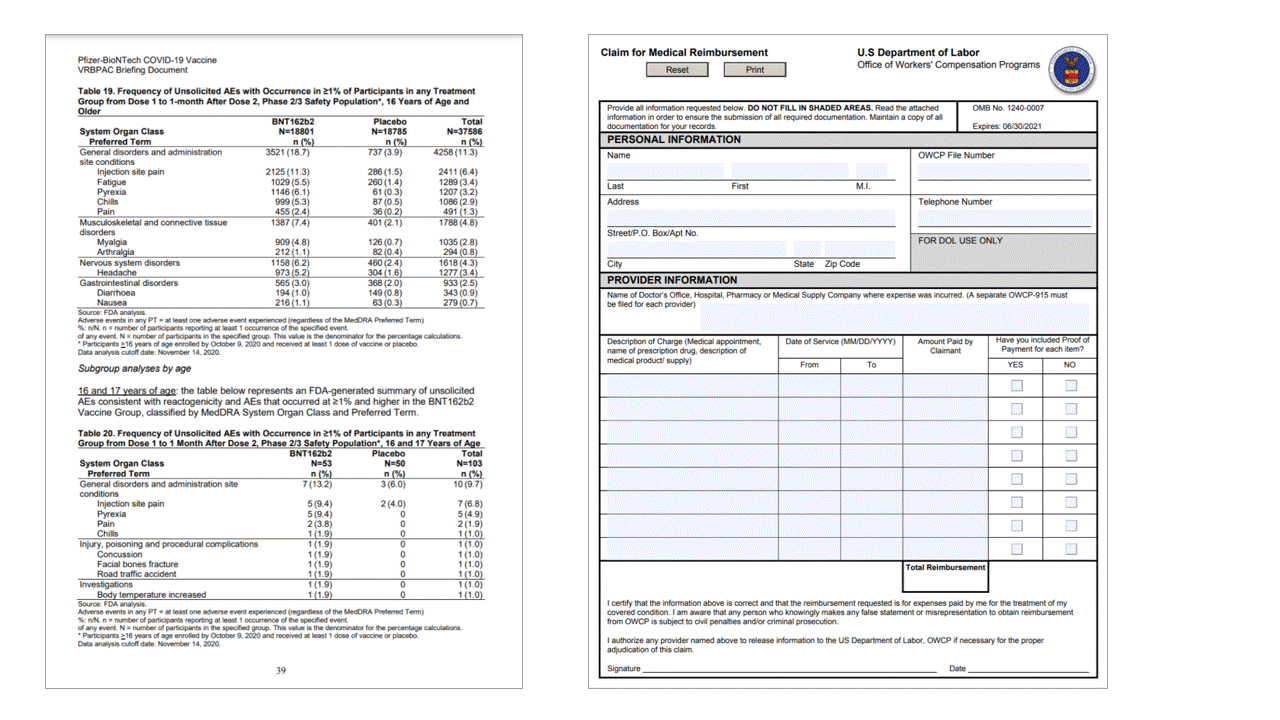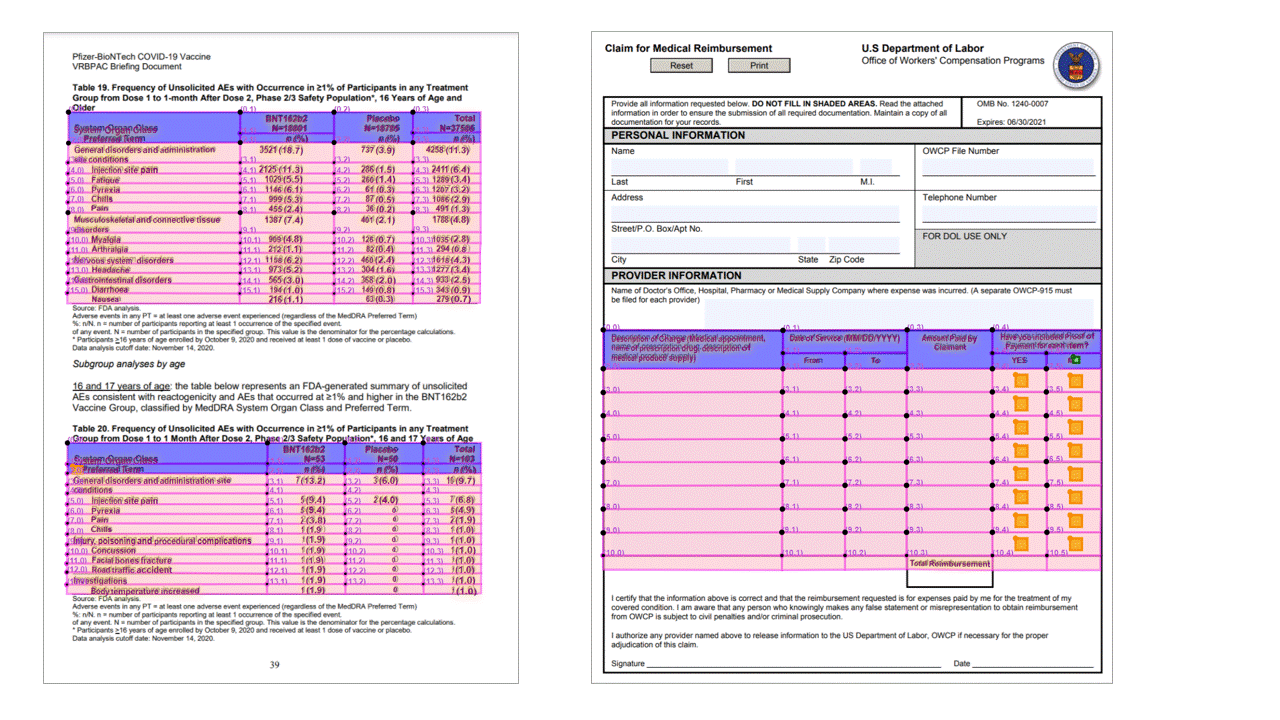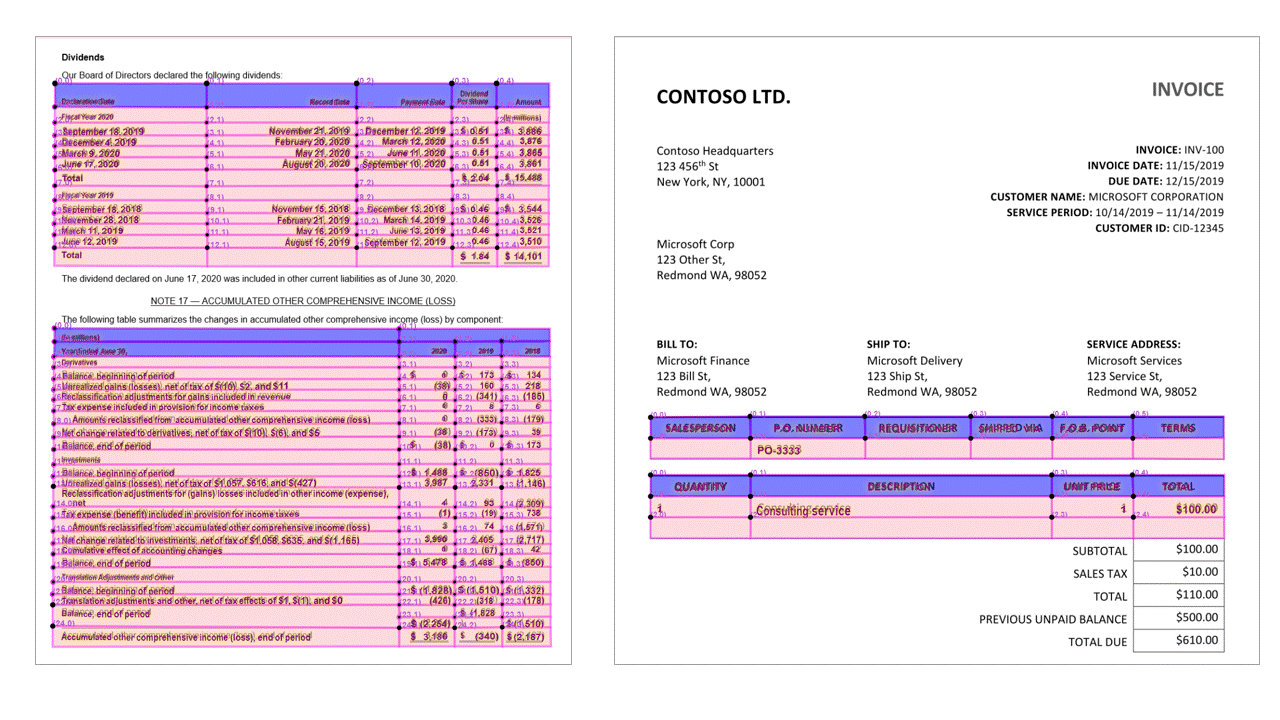
Táblák
A táblák kinyerése kulcsfontosságú követelmény a nagy mennyiségű adatot tartalmazó dokumentumok feldolgozásához, amelyek általában táblákként formázhatók. Az Elrendezési modell a JSON-kimenet szakaszában pageResults lévő táblákat nyeri ki. A kinyert táblaadatok tartalmazzák az oszlopok és sorok számát, a sorokat és az oszlopfedéseket. A határoló sokszöggel rendelkező cellák kimenete és annak információi, hogy a terület felismerhető-e columnHeader vagy sem. A modell támogatja az elforgatott táblák kinyerését. Minden táblázatcella tartalmazza a sor- és oszlopindexet, valamint a határoló sokszög koordinátáit. A cellaszöveg esetében a modell a kezdő indexet (offset) tartalmazó információkat adja kispan. A modell a length dokumentum teljes szövegét tartalmazó legfelső szintű tartalomon belül is kimenetet ad ki.
Feljegyzés
A tábla nem támogatott, ha a bemeneti fájl XLSX.
{
"tables": [
{
"rowCount": 9,
"columnCount": 4,
"cells": [
{
"kind": "columnHeader",
"rowIndex": 0,
"columnIndex": 0,
"columnSpan": 4,
"content": "(In millions, except earnings per share)",
"boundingRegions": [],
"spans": []
},
]
}
]
}
Széljegyzetek (csak az API-ban 2023-02-28-preview érhetők el.)
Az Elrendezési modell széljegyzeteket nyer ki a dokumentumokban, például ellenőrzésekben és keresztekben. A válasz tartalmazza a széljegyzetek fajtáját, valamint a megbízhatósági pontszámot és a határoló sokszöget.
{
"pages": [
{
"annotations": [
{
"kind": "cross",
"polygon": [...],
"confidence": 1
}
]
}
]
}
Kimenet markdown formátumba
Az Layout API markdown formátumban tudja kiírni a kinyert szöveget. A kimenet formátumának megadásához használja a outputContentFormat=markdown markdownt. A Markdown-tartalom a szakasz részeként jelenik meg content .
"analyzeResult": {
"apiVersion": "2024-02-29-preview",
"modelId": "prebuilt-layout",
"contentFormat": "markdown",
"content": "# CONTOSO LTD...",
}
Számok
A dokumentumokban szereplő ábrák (diagramok, képek) kulcsfontosságú szerepet játszanak a szöveges tartalom kiegészítésében és javításában, és olyan vizuális ábrázolásokat biztosítanak, amelyek elősegítik az összetett információk megértését. Az Elrendezési modell által észlelt ábraobjektum olyan kulcsfontosságú tulajdonságokkal rendelkezik, mint például boundingRegions (a dokumentumoldalakon lévő ábra térbeli helyei, beleértve az oldalszámot és az ábra határát tagoló sokszög koordinátákat), spans (az ábrához kapcsolódó szövegtartományokat részletezi, megadva azok eltolásait és hosszát a dokumentum szövegében. Ez a kapcsolat segít társítani az ábrát a megfelelő szöveges környezettel, elements (a dokumentum szöveges elemeinek vagy bekezdéseinek azonosítóit, amelyek az ábrához kapcsolódnak vagy írják le) és caption ha vannak ilyenek.
{
"figures": [
{
"boundingRegions": [],
"spans": [],
"elements": [
"/paragraphs/15",
...
],
"caption": {
"content": "Here is a figure with some text",
"boundingRegions": [],
"spans": [],
"elements": [
"/paragraphs/15"
]
}
}
]
}
Szakaszok
A hierarchikus dokumentumstruktúra-elemzés kulcsfontosságú a kiterjedt dokumentumok rendszerezésében, megértésében és feldolgozásában. Ez a megközelítés elengedhetetlen a hosszú dokumentumok szemantikai szegmentálásához a megértés fokozása, a navigáció megkönnyítése és az információlekérés javítása érdekében. A dokumentumgeneratív AI-ben a lekéréses kiterjesztett generáció (RAG) megjelenése kiemeli a hierarchikus dokumentumstruktúra-elemzés jelentőségét. Az Elrendezési modell támogatja a kimenet szakaszait és alszakaszait, amelyek azonosítják az egyes szakaszok szakaszainak és objektumainak kapcsolatát. A hierarchikus struktúra minden szakaszban megmarad elements . A kimenettel markdown formátumban egyszerűen lekérheti a szakaszokat és alszakaszokat a Markdownban.
{
"sections": [
{
"spans": [],
"elements": [
"/paragraphs/0",
"/sections/1",
"/sections/2",
"/sections/5"
]
},
...
}
Természetes olvasási sorrend kimenete (csak latin betűs)
A lekérdezési paraméterrel megadhatja a szövegsorok kimenetének sorrendjét readingOrder . Az alábbi példában látható, emberbarátabb olvasási sorrend kimenetéhez használható natural . Ez a funkció csak latin nyelvek esetén támogatott.

Oldalszámok vagy -tartományok kijelölése szövegkinyeréshez
Nagyméretű, többoldalas dokumentumok esetén a pages lekérdezési paraméterrel konkrét oldalszámokat vagy oldaltartományokat jelölhet a szöveg kinyeréséhez. Az alábbi példa egy 10 oldalas dokumentumot mutat be, amely mindkét esetben kinyert szöveget tartalmaz – az összes oldalt (1–10) és a kijelölt oldalakat (3–6).
Az Elemzési elrendezés eredményének lekérése művelet
A második lépés az Elemzési elrendezés eredményének lekérése művelet meghívása. Ez a művelet bemenetként a létrehozott művelet eredményazonosítóját Analyze Layout veszi fel. Egy JSON-választ ad vissza, amely egy állapotmezőt tartalmaz az alábbi lehetséges értékekkel.
| Mező | Típus | Lehetséges értékek |
|---|---|---|
| status | húr | notStarted: Az elemzési művelet nem indul el.running: Az elemzési művelet folyamatban van. failed: Az elemzési művelet sikertelen. succeeded: Az elemzési művelet sikeres volt. |
A művelet meghívása iteratív módon, amíg vissza nem adja az succeeded értéket. A másodpercenkénti kérelmek (RPS) sebességének túllépése érdekében 3–5 másodperces időközt használjon.
Ha az állapotmező rendelkezik az succeeded értékkel, a JSON-válasz tartalmazza a kinyert elrendezést, a szöveget, a táblázatokat és a kijelölési jeleket. A kinyert adatok közé tartoznak a kicsomagolt szövegsorok és szavak, a határolókeretek, a kézzel írt jelzéssel ellátott szöveg megjelenése, a táblázatok és a kijelölt/nem kijelölt kijelölési jelek.
Kézzel írt besorolás szövegsorokhoz (csak latin betűs)
A válasz magában foglalja annak besorolását, hogy az egyes szövegsorok kézírásstílusúak-e vagy sem, valamint egy megbízhatósági pontszámot. Ez a funkció csak latin nyelvek esetén támogatott. Az alábbi példa a kép szövegének kézzel írt besorolását mutatja be.

JSON-mintakimenet
Az Elemzési elrendezés eredményének lekérése műveletre adott válasz a dokumentum strukturált ábrázolása az összes kinyert információval. A mintadokumentumfájlt és a strukturált kimeneti mintaelrendezés kimenetét itt találja.
A JSON-kimenet két részből áll:
readResultscsomópont tartalmazza az összes felismert szöveget és kijelölési jelet. A szöveges bemutató hierarchiája a lap, majd a sor, majd az egyes szavak.pageResultsA csomópont tartalmazza a határolókeretekkel, megbízhatósággal és a "readResults" mező soraira és szavaira mutató hivatkozást tartalmazó táblákat és cellákat.
Példakimenet
Szöveg
Az Layout API több szövegszöggel és színnel kinyeri a dokumentumokat és képeket. Dokumentumokat, faxokat, nyomtatott és/vagy kézzel írt (csak angol nyelvű) szöveget és vegyes módokat fogad el. A szöveg sorokkal, szavakkal, határolókeretekkel, megbízhatósági pontszámokkal és stílussal (kézzel írt vagy más) információval nyerhető ki. A JSON-kimenet szakasza tartalmazza az readResults összes szöveges információt.
Fejléceket tartalmazó táblázatok
Az Layout API kinyeri a pageResults JSON-kimenet szakaszában lévő táblákat. A dokumentumok beolvashatók, lefényképezhetők vagy digitalizálhatók. A táblázatok összetettek lehetnek egyesített cellákkal vagy oszlopokkal, szegélyekkel vagy anélkül, valamint páratlan szögekkel. A kinyert táblaadatok tartalmazzák az oszlopok és sorok számát, a sorokat és az oszlopfedéseket. A határolókerettel rendelkező cellák mindegyike kimenet, valamint az is, hogy a terület felismerhető-e egy fejléc részeként. A modell által előrejelzett fejléccellák több sorra is kiterjedhetnek, és nem feltétlenül a tábla első sorai. Elforgatott táblákkal is működnek. Minden táblázatcella tartalmazza a szakasz egyes szavaira readResults mutató hivatkozásokat tartalmazó teljes szöveget is.
Kijelölési jelek
Az Layout API kijelölési jeleket is kinyer a dokumentumokból. A kinyert kijelölési jelek közé tartozik a határolókeret, a megbízhatóság és az állapot (kijelölve/kijelölve). A kijelölési jel adatai a readResults JSON-kimenet szakaszában lesznek kinyerve.
Migrálási útmutató
Következő lépések
Megtudhatja, hogyan dolgozhatja fel saját űrlapjait és dokumentumait a Document Intelligence Studióval.
Végezze el a Dokumentumintelligencia rövid útmutatóját , és kezdje el létrehozni egy dokumentumfeldolgozó alkalmazást a választott fejlesztési nyelven.
Megtudhatja, hogyan dolgozhatja fel saját űrlapjait és dokumentumait a Dokumentumintelligencia mintacímkéző eszközzel.
Végezze el a Dokumentumintelligencia rövid útmutatóját , és kezdje el létrehozni egy dokumentumfeldolgozó alkalmazást a választott fejlesztési nyelven.