Adatkészletek az Azure Data Factoryben és az Azure Synapse Analyticsben
A következőkre vonatkozik: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp.
Próbálja ki a Data Factoryt a Microsoft Fabricben, amely egy teljes körű elemzési megoldás a nagyvállalatok számára. A Microsoft Fabric az adattovábbítástól az adatelemzésig, a valós idejű elemzésig, az üzleti intelligenciáig és a jelentéskészítésig mindent lefed. Ismerje meg, hogyan indíthat új próbaverziót ingyenesen!
Ez a cikk bemutatja, hogy mik az adathalmazok, hogyan definiálják őket JSON formátumban, és hogyan használják őket az Azure Data Factoryben és a Synapse-folyamatokban.
Ha még nem ismerkedik a Data Factory szolgáltatásban, tekintse át az Azure Data Factory bemutatása című témakört. További információ az Azure Synapse-ről: Mi az Az Azure Synapse?
Áttekintés
Egy Azure Data Factory- vagy Synapse-munkaterületen egy vagy több folyamat is lehet. A folyamat olyan tevékenységek logikai csoportosítása, amelyek együttesen hajtanak végre egy feladatot. A folyamat tevékenységei meghatározzák az adatokon végrehajtandó műveleteket. Az adathalmazok mostantól az adatok nevesített nézetei, amelyek egyszerűen a tevékenységekben használni kívánt adatokra mutatnak vagy hivatkoznak bemenetként és kimenetként. Az adatkészletek adatokat határoznak meg a különböző adattárakban, például táblákban, fájlokban, mappákban és dokumentumokban. Egy Azure Blob-adatkészlet például azt a blobtárolót és mappát adja meg a Blob Storage-ban, amelyből a tevékenységnek be kell olvasnia az adatokat.
Mielőtt létrehoz egy adathalmazt, létre kell hoznia egy társított szolgáltatást , amely összekapcsolja az adattárat a szolgáltatással. A társított szolgáltatások hasonlóak a kapcsolati sztring, amelyek meghatározzák a szolgáltatás külső erőforrásokhoz való csatlakozásához szükséges kapcsolati információkat. Gondoljon rá így; az adatkészlet a csatolt adattárakban lévő adatok struktúráját jelöli, a társított szolgáltatás pedig az adatforráshoz való kapcsolatot határozza meg. Egy Azure Storage társított szolgáltatás például összekapcsol egy tárfiókot. Az Azure Blob-adatkészlet a feldolgozandó bemeneti blobokat tartalmazó Blob-tárolót és azon belüli mappát jelöli az Azure Storage-fiókban.
Íme egy példaforgatókönyv. Ha a Blob Storage-ból egy SQL Database-be szeretne adatokat másolni, két társított szolgáltatást kell létrehoznia: az Azure Blob Storage-t és az Azure SQL Database-t. Ezután hozzon létre két adatkészletet: tagolt szöveges adatkészletet (amely az Azure Blob Storage társított szolgáltatásra hivatkozik, feltéve, hogy forrásként szöveges fájlokat használ) és az Azure SQL Table-adatkészletet (amely az Azure SQL Database társított szolgáltatására hivatkozik). Az Azure Blob Storage és az Azure SQL Database társított szolgáltatásai kapcsolati sztring tartalmaznak, amelyeket a szolgáltatás futásidőben használ az Azure Storage-hoz és az Azure SQL Database-hez való csatlakozáshoz. A tagolt szöveg adatkészlet a blobtárolóban lévő bemeneti blobokat és a formátumhoz kapcsolódó beállításokat tartalmazó blobtárolót és blobmappát adja meg. Az Azure SQL Table-adatkészlet megadja az SQL Database azon SQL-tábláját, amelybe az adatokat át szeretné másolni.
Az alábbi ábra a folyamat, a tevékenység, az adatkészlet és a társított szolgáltatások közötti kapcsolatokat mutatja be:

Adathalmaz létrehozása felhasználói felülettel
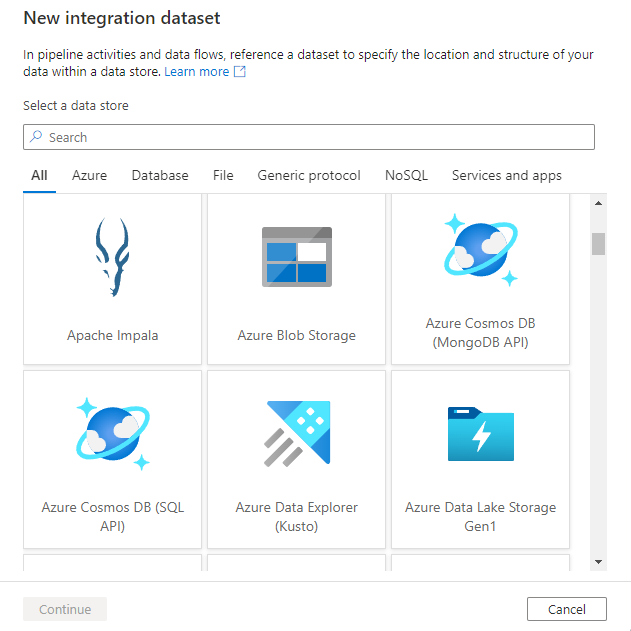
Ha az Azure Data Factory Studióval szeretne adathalmazt létrehozni, válassza a Szerző lapot (a ceruza ikonnal), majd a pluszjel ikont az Adathalmaz kiválasztásához.
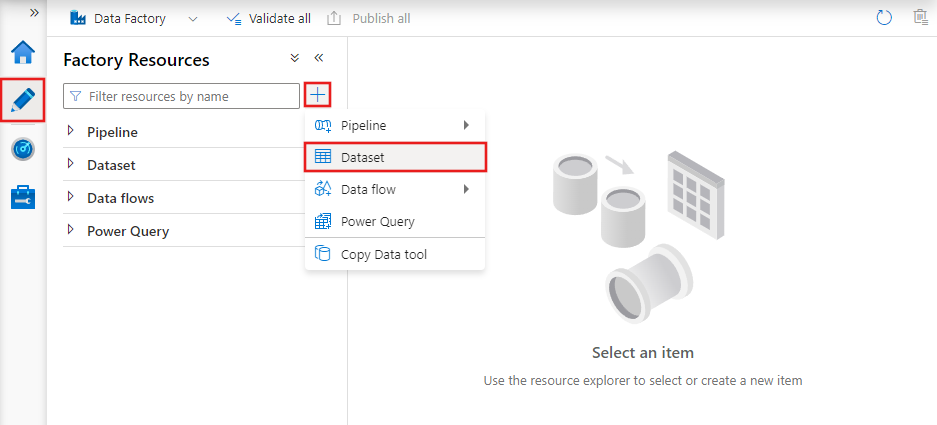
Megjelenik az új adathalmazablak, amely kiválasztja az Azure Data Factoryben elérhető összekötőket egy meglévő vagy új társított szolgáltatás beállításához.
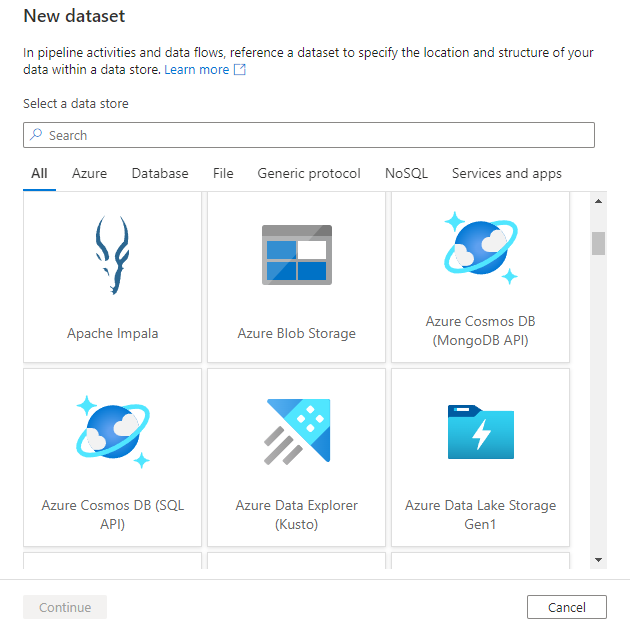
Ezután a rendszer kérni fogja, hogy válassza ki az adathalmaz formátumát.

Végül kiválaszthatja az adathalmazhoz kiválasztott típusú meglévő társított szolgáltatást, vagy létrehozhat egy újat, ha még nincs definiálva.
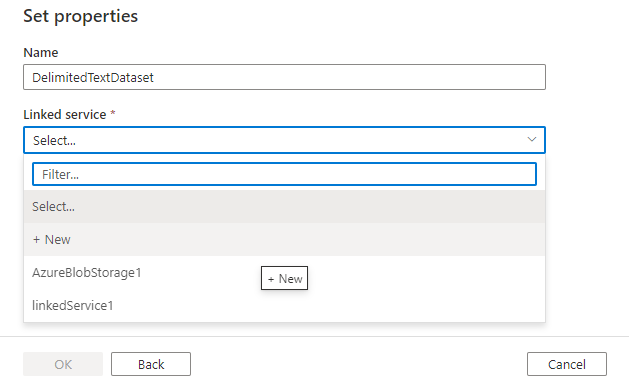
Miután létrehozta az adathalmazt, az Azure Data Factory bármely folyamatában használhatja.
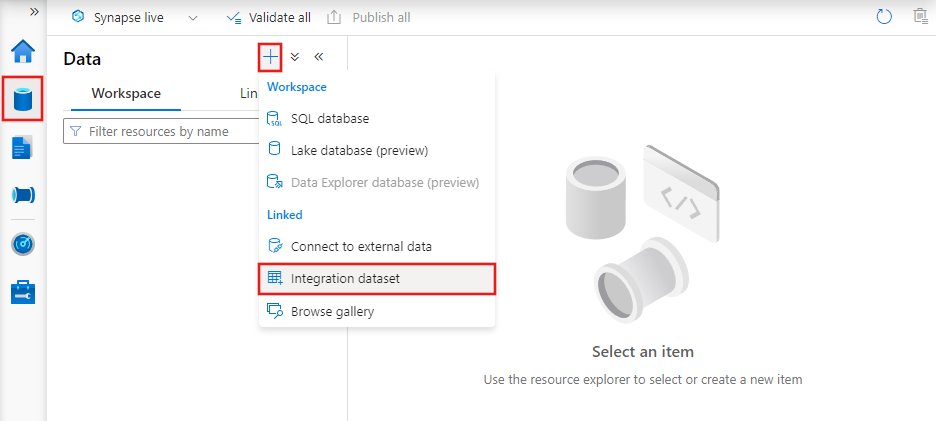
JSON-adathalmaz
Az adatkészletek a következő JSON formátumban vannak definiálva:
{
"name": "<name of dataset>",
"properties": {
"type": "<type of dataset: DelimitedText, AzureSqlTable etc...>",
"linkedServiceName": {
"referenceName": "<name of linked service>",
"type": "LinkedServiceReference",
},
"schema":[
],
"typeProperties": {
"<type specific property>": "<value>",
"<type specific property 2>": "<value 2>",
}
}
}
Az alábbi táblázat a fenti JSON tulajdonságait ismerteti:
| Property | Leírás | Required |
|---|---|---|
| név | Az adathalmaz neve. Lásd az elnevezési szabályokat. | Igen |
| típus | Az adathalmaz típusa. Adja meg a Data Factory által támogatott típusokat (például: DelimitedText, AzureSqlTable). További részletekért tekintse meg az adathalmazok típusait. |
Igen |
| schema | Az adathalmaz sémája a fizikai adattípust és -alakzatot jelöli. | Nem |
| typeProperties | A típustulajdonságok minden típushoz eltérőek. A támogatott típusokkal és azok tulajdonságaival kapcsolatos részletekért lásd : Adathalmaz típusa. | Igen |
Az adathalmaz sémájának importálásakor válassza a Séma importálása gombot, és válassza a forrásból vagy egy helyi fájlból történő importálást. A legtöbb esetben közvetlenül a forrásból fogja importálni a sémát. Ha azonban már rendelkezik helyi sémafájllal (egy Parquet-fájllal vagy fejlécekkel rendelkező CSV-vel), utasíthatja a szolgáltatást, hogy a sémát az adott fájlra alapozza.
Másolási tevékenység esetén az adathalmazok a forrásban és a fogadóban használatosak. Az adathalmazban definiált séma nem kötelező referenciaként. Ha oszlop-/mezőleképezést szeretne alkalmazni a forrás és a fogadó között, tekintse meg a séma- és típusleképezést.
A Adatfolyam az adathalmazokat a forrás- és fogadóátalakításokban használják. Az adatkészletek határozzák meg az alapszintű adatsémákat. Ha az adatok nem rendelkezik sémával, használhatja a sémaeltolódást a forráshoz és a fogadóhoz. Az adathalmazokból származó metaadatok forrásvetítésként jelennek meg a forrásátalakításban. A forrásátalakításban a kivetítés a definiált névvel és típusokkal rendelkező Adatfolyam adatokat jelöli.
Adathalmaz típusa
A szolgáltatás számos különböző adathalmaztípust támogat a használt adattáraktól függően. A támogatott adattárak listáját Csatlakozás or áttekintési cikkéből találja. Válasszon ki egy adattárat, és ismerje meg, hogyan hozhat létre társított szolgáltatást és adatkészletet.
Határoló szöveg típusú adatkészlet esetében például az adathalmaz típusa DelimitedText értékre van állítva, ahogyan az a következő JSON-mintában látható:
{
"name": "DelimitedTextInput",
"properties": {
"linkedServiceName": {
"referenceName": "AzureBlobStorage",
"type": "LinkedServiceReference"
},
"annotations": [],
"type": "DelimitedText",
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"fileName": "input.log",
"folderPath": "inputdata",
"container": "adfgetstarted"
},
"columnDelimiter": ",",
"escapeChar": "\\",
"quoteChar": "\""
},
"schema": []
}
}
Adatkészletek létrehozása
Adatkészleteket az alábbi eszközök vagy SDK-k egyikével hozhat létre: .NET API, PowerShell, REST API, Azure Resource Manager-sablon és Azure Portal
Jelenlegi verzió és 1. verziójú adatkészletek
Íme néhány különbség a Data Factory aktuális verziójában (és az Azure Synapse-ban) lévő adathalmazok és az örökölt Data Factory 1-es verziója között:
- A külső tulajdonság az aktuális verzióban nem támogatott. Egy trigger váltja fel.
- A szabályzat és a rendelkezésre állás tulajdonságai az aktuális verzióban nem támogatottak. A folyamat kezdési ideje az eseményindítóktól függ.
- A hatókörrel rendelkező adathalmazok (egy folyamatban definiált adathalmazok) nem támogatottak az aktuális verzióban.
Kapcsolódó tartalom
A folyamatok és adathalmazok ezen eszközök vagy SDK-k használatával történő létrehozására vonatkozó részletes útmutatásért tekintse meg az alábbi oktatóanyagot.