Adatok másolása és átalakítása felügyelt Azure SQL-példányban az Azure Data Factory vagy a Synapse Analytics használatával
A következőkre vonatkozik: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp.
Próbálja ki a Data Factoryt a Microsoft Fabricben, amely egy teljes körű elemzési megoldás a nagyvállalatok számára. A Microsoft Fabric az adattovábbítástól az adatelemzésig, a valós idejű elemzésig, az üzleti intelligenciáig és a jelentéskészítésig mindent lefed. Ismerje meg, hogyan indíthat új próbaverziót ingyenesen!
Ez a cikk bemutatja, hogyan másolhat adatokat a felügyelt Azure SQL-példányból és az Azure SQL-példányba a másolási tevékenység használatával, és hogyan alakíthat át adatokat a felügyelt Azure SQL-példányban az Adatfolyam használatával. További információkért olvassa el az Azure Data Factory és a Synapse Analytics bevezető cikkeit.
Támogatott képességek
Ez az Azure SQL Managed Instance-összekötő a következő képességeket támogatja:
| Támogatott képességek | IR | Felügyelt privát végpont |
|---|---|---|
| Copy tevékenység (forrás/fogadó) | (1) (2) | ✓ Nyilvános előzetes verzió |
| Adatfolyam leképezése (forrás/fogadó) | (1) | ✓ Nyilvános előzetes verzió |
| Keresési tevékenység | (1) (2) | ✓ Nyilvános előzetes verzió |
| GetMetadata-tevékenység | (1) (2) | ✓ Nyilvános előzetes verzió |
| Szkripttevékenység | (1) (2) | ✓ Nyilvános előzetes verzió |
| Tárolt eljárástevékenység | (1) (2) | ✓ Nyilvános előzetes verzió |
(1) Azure-integrációs modul (2) Saját üzemeltetésű integrációs modul
Az Copy tevékenység esetében ez az Azure SQL Database-összekötő a következő funkciókat támogatja:
- Adatok másolása SQL-hitelesítéssel és Microsoft Entra-alkalmazásjogkivonat-hitelesítéssel az Azure-erőforrások szolgáltatásnévvel vagy felügyelt identitásaival.
- Forrásként az adatok lekérése SQL-lekérdezéssel vagy tárolt eljárással. Az SQL MI-forrásból történő párhuzamos másolást is választhatja, a részletekért tekintse meg az SQL MI párhuzamos példányát ismertető szakaszt.
- Fogadóként automatikusan hozzon létre céltáblát, ha nem létezik a forrásséma alapján; adatok hozzáfűzése egy táblához, vagy tárolt eljárás meghívása egyéni logikával a másolás során.
Előfeltételek
A felügyelt SQL-példány nyilvános végpontjának eléréséhez használhat felügyelt Azure-integrációs futtatókörnyezetet. Ügyeljen arra, hogy a nyilvános végpontot és a nyilvános végpont forgalmát is engedélyezze a hálózati biztonsági csoporton, hogy a szolgáltatás csatlakozni tudjon az adatbázisához. További információkért tekintse meg ezt az útmutatót.
Egy felügyelt SQL-példány privát végpontjának eléréshez be kell állítani egy saját üzemeltetésű integrációs modult, amely hozzáfér az adatbázishoz. Ha a saját üzemeltetésű integrációs modult ugyanazon a virtuális hálózaton helyezi üzembe, ahol a felügyelt példány van, akkor ügyeljen arra, hogy az integrációs modul gépe ne ugyanazon az alhálózaton legyen, mint a felügyelt példány. Ha a saját üzemeltetésű integrációs modult egy másik virtuális hálózaton helyezi üzembe, mint ahol a felügyelt példány van, akkor virtuális hálózati társviszony-létesítést vagy virtuális hálózatok közötti kapcsolatot is használhat. További információ: Alkalmazás felügyelt SQL-példányhoz csatlakoztatása.
Első lépések
A Copy tevékenység folyamattal való végrehajtásához használja az alábbi eszközök vagy SDK-k egyikét:
- Az Adatok másolása eszköz
- Az Azure Portal
- A .NET SDK
- A Python SDK
- Azure PowerShell
- A REST API
- Az Azure Resource Manager-sablon
Társított szolgáltatás létrehozása felügyelt Azure SQL-példányhoz felhasználói felületen
Az alábbi lépésekkel létrehozhat egy társított szolgáltatást egy felügyelt SQL-példányhoz az Azure Portal felhasználói felületén.
Keresse meg az Azure Data Factory vagy a Synapse-munkaterület Kezelés lapját, és válassza a Társított szolgáltatások lehetőséget, majd kattintson az Új gombra:
Keressen rá az SQL-re, és válassza ki a felügyelt Azure SQL Server-példány összekötőt.

Konfigurálja a szolgáltatás részleteit, tesztelje a kapcsolatot, és hozza létre az új társított szolgáltatást.
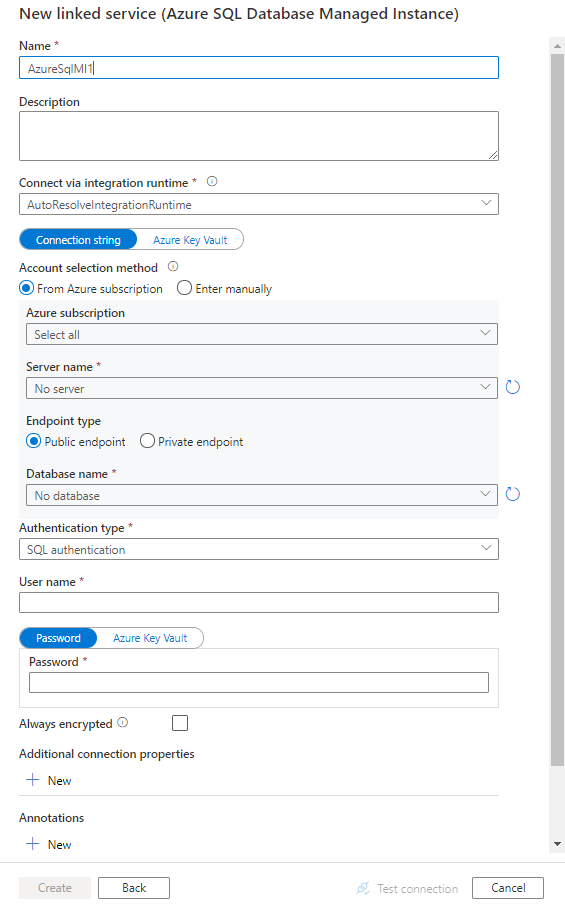


Csatlakozás or konfigurációjának részletei
Az alábbi szakaszokban az SQL Managed Instance-összekötőre jellemző Azure Data Factory-entitások meghatározásához használt tulajdonságokat ismertetjük.
Társított szolgáltatás tulajdonságai
Ezek az általános tulajdonságok támogatottak egy felügyelt SQL-példányhoz társított szolgáltatás esetében:
| Tulajdonság | Leírás | Kötelező |
|---|---|---|
| típus | A típustulajdonságnak AzureSqlMI-nek kell lennie. | Igen |
| connectionString | Ez a tulajdonság adja meg a felügyelt SQL-példányhoz SQL-hitelesítéssel való csatlakozáshoz szükséges connectionString-adatokat . További információkért tekintse meg az alábbi példákat. Az alapértelmezett port az 1433. Ha nyilvános végponttal használja a felügyelt SQL-példányt, explicit módon adja meg a 3342-s portot. Jelszót is elhelyezhet az Azure Key Vaultban. Ha SQL-hitelesítésről van szó, húzza ki a konfigurációt password a kapcsolati sztring. További információ: JSON-példa a tábla és az Azure Key Vaultban tárolt hitelesítő adatok tárolására. |
Igen |
| azureCloudType | A szolgáltatásnév hitelesítéséhez adja meg annak az Azure-felhőkörnyezetnek a típusát, amelyre a Microsoft Entra-alkalmazás regisztrálva van. Az engedélyezett értékek az AzurePublic, az AzureChina, az AzureUsGovernment és az AzureGermany. Alapértelmezés szerint a szolgáltatás felhőkörnyezetét használja a rendszer. |
Nem |
| alwaysEncrypted Gépház | Adja meg az Always Encrypted engedélyezéséhez szükséges Alwaysencryptedsettings-adatokat , amelyek felügyelt identitással vagy szolgáltatásnévvel védik az SQL Serveren tárolt bizalmas adatokat. További információ: A táblázatot és az Always Encrypted használata szakaszt követő JSON-példa. Ha nincs megadva, az alapértelmezett mindig titkosított beállítás le van tiltva. | Nem |
| connectVia | Ez az integrációs modul az adattárhoz való csatlakozásra szolgál. Használhat saját üzemeltetésű integrációs modult vagy Azure-integrációs futtatókörnyezetet, ha a felügyelt példány nyilvános végponttal rendelkezik, és lehetővé teszi a szolgáltatás számára annak elérését. Ha nincs megadva, a rendszer az alapértelmezett Azure-integrációs modult használja. | Igen |
A különböző hitelesítési típusok esetében tekintse meg az egyes tulajdonságokra, előfeltételekre és JSON-mintákra vonatkozó alábbi szakaszokat:
- SQL-hitelesítés
- Egyszerű szolgáltatás hitelesítése
- Rendszer által hozzárendelt felügyelt identitás hitelesítése
- Felhasználó által hozzárendelt felügyelt identitás hitelesítése
SQL-hitelesítés
Az SQL-hitelesítés típusának használatához adja meg az előző szakaszban ismertetett általános tulajdonságokat.
1. példa: SQL-hitelesítés használata
{
"name": "AzureSqlMILinkedService",
"properties": {
"type": "AzureSqlMI",
"typeProperties": {
"connectionString": "Data Source=<hostname,port>;Initial Catalog=<databasename>;Integrated Security=False;User ID=<username>;Password=<password>;"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
2. példa: SQL-hitelesítés használata jelszóval az Azure Key Vaultban
{
"name": "AzureSqlMILinkedService",
"properties": {
"type": "AzureSqlMI",
"typeProperties": {
"connectionString": "Data Source=<hostname,port>;Initial Catalog=<databasename>;Integrated Security=False;User ID=<username>;",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
3. példa: SQL-hitelesítés használata Always Encrypted használatával
{
"name": "AzureSqlMILinkedService",
"properties": {
"type": "AzureSqlMI",
"typeProperties": {
"connectionString": "Data Source=<hostname,port>;Initial Catalog=<databasename>;Integrated Security=False;User ID=<username>;Password=<password>;"
},
"alwaysEncryptedSettings": {
"alwaysEncryptedAkvAuthType": "ServicePrincipal",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Egyszerű szolgáltatás hitelesítése
A szolgáltatásnév-hitelesítés használatához az előző szakaszban ismertetett általános tulajdonságok mellett adja meg a következő tulajdonságokat
| Tulajdonság | Leírás | Kötelező |
|---|---|---|
| servicePrincipalId | Adja meg az alkalmazás ügyfél-azonosítóját. | Igen |
| servicePrincipalKey | Adja meg az alkalmazás kulcsát. Jelölje meg ezt a mezőt SecureStringként, hogy biztonságosan tárolja, vagy hivatkozzon az Azure Key Vaultban tárolt titkos kódra. | Igen |
| bérlő | Adja meg a bérlő adatait, például azt a tartománynevet vagy bérlőazonosítót, amely alatt az alkalmazás található. Kérje le az egérmutatót az Azure Portal jobb felső sarkában. | Igen |
Az alábbi lépéseket is követnie kell:
Kövesse a lépéseket egy Microsoft Entra-rendszergazda felügyelt példányhoz való kiépítéséhez.
Microsoft Entra-alkalmazás létrehozása az Azure Portalról. Jegyezze fel az alkalmazás nevét és a társított szolgáltatást meghatározó alábbi értékeket:
- Pályázat azonosítója
- Alkalmazáskulcs
- Bérlőazonosító
Hozzon létre bejelentkezéseket a szolgáltatásnévhez. Az SQL Server Management Studióban (SSMS) csatlakozzon a felügyelt példányhoz egy sysadmin nevű SQL Server-fiókkal. A főadatbázisban futtassa a következő T-SQL-t:
CREATE LOGIN [your application name] FROM EXTERNAL PROVIDERTartalmazott adatbázis-felhasználók létrehozása a szolgáltatásnévhez. Csatlakozás arra az adatbázisra, ahonnan adatokat szeretne másolni, futtassa a következő T-SQL-t:
CREATE USER [your application name] FROM EXTERNAL PROVIDERAdja meg a szolgáltatásnévnek a szükséges engedélyeket, ahogyan azt az SQL-felhasználók és mások esetében általában teszi. Futtassa a következő kódot. További lehetőségekért tekintse meg ezt a dokumentumot.
ALTER ROLE [role name e.g. db_owner] ADD MEMBER [your application name]Felügyelt SQL-példány társított szolgáltatásának konfigurálása.
Példa: egyszerű szolgáltatáshitelesítés használata
{
"name": "AzureSqlDbLinkedService",
"properties": {
"type": "AzureSqlMI",
"typeProperties": {
"connectionString": "Data Source=<hostname,port>;Initial Catalog=<databasename>;",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Rendszer által hozzárendelt felügyelt identitás hitelesítése
Egy adat-előállító vagy Synapse-munkaterület társítható egy rendszer által hozzárendelt felügyelt identitással az Azure-erőforrásokhoz , amelyek a szolgáltatást más Azure-szolgáltatásokhoz való hitelesítéshez képviselik. Ezt a felügyelt identitást használhatja felügyelt SQL-példány hitelesítéséhez. A kijelölt szolgáltatás ezzel az identitással férhet hozzá és másolhat adatokat az adatbázisból vagy az adatbázisba.
A rendszer által hozzárendelt felügyelt identitáshitelesítés használatához adja meg az előző szakaszban ismertetett általános tulajdonságokat, és kövesse az alábbi lépéseket.
Kövesse a lépéseket egy Microsoft Entra-rendszergazda felügyelt példányhoz való kiépítéséhez.
Bejelentkezések létrehozása a rendszer által hozzárendelt felügyelt identitáshoz. Az SQL Server Management Studióban (SSMS) csatlakozzon a felügyelt példányhoz egy sysadmin nevű SQL Server-fiókkal. A főadatbázisban futtassa a következő T-SQL-t:
CREATE LOGIN [your_factory_or_workspace_ name] FROM EXTERNAL PROVIDERTartalmazott adatbázis-felhasználók létrehozása a rendszer által hozzárendelt felügyelt identitáshoz. Csatlakozás arra az adatbázisra, ahonnan adatokat szeretne másolni, futtassa a következő T-SQL-t:
CREATE USER [your_factory_or_workspace_name] FROM EXTERNAL PROVIDERAdja meg a rendszer által hozzárendelt felügyelt identitásnak a szükséges engedélyeket, ahogyan azt az SQL-felhasználók és mások esetében általában teszi. Futtassa a következő kódot. További lehetőségekért tekintse meg ezt a dokumentumot.
ALTER ROLE [role name e.g. db_owner] ADD MEMBER [your_factory_or_workspace_name]Felügyelt SQL-példány társított szolgáltatásának konfigurálása.
Példa: rendszer által hozzárendelt felügyelt identitás hitelesítése
{
"name": "AzureSqlDbLinkedService",
"properties": {
"type": "AzureSqlMI",
"typeProperties": {
"connectionString": "Data Source=<hostname,port>;Initial Catalog=<databasename>;"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Felhasználó által hozzárendelt felügyelt identitás hitelesítése
Egy adat-előállító vagy Synapse-munkaterület társítható felhasználó által hozzárendelt felügyelt identitásokkal, amelyek a szolgáltatást képviselik más Azure-szolgáltatásokhoz való hitelesítéshez. Ezt a felügyelt identitást használhatja felügyelt SQL-példány hitelesítéséhez. A kijelölt szolgáltatás ezzel az identitással férhet hozzá és másolhat adatokat az adatbázisból vagy az adatbázisba.
A felhasználó által hozzárendelt felügyelt identitáshitelesítés használatához az előző szakaszban ismertetett általános tulajdonságok mellett adja meg a következő tulajdonságokat:
| Tulajdonság | Leírás | Kötelező |
|---|---|---|
| hitelesítő adatok | Adja meg a felhasználó által hozzárendelt felügyelt identitást hitelesítő objektumként. | Igen |
Az alábbi lépéseket is követnie kell:
Kövesse a lépéseket egy Microsoft Entra-rendszergazda felügyelt példányhoz való kiépítéséhez.
Bejelentkezések létrehozása a felhasználó által hozzárendelt felügyelt identitáshoz. Az SQL Server Management Studióban (SSMS) csatlakozzon a felügyelt példányhoz egy sysadmin nevű SQL Server-fiókkal. A főadatbázisban futtassa a következő T-SQL-t:
CREATE LOGIN [your_factory_or_workspace_ name] FROM EXTERNAL PROVIDERTartalmazott adatbázis-felhasználók létrehozása a felhasználó által hozzárendelt felügyelt identitáshoz. Csatlakozás arra az adatbázisra, ahonnan adatokat szeretne másolni, futtassa a következő T-SQL-t:
CREATE USER [your_factory_or_workspace_name] FROM EXTERNAL PROVIDERHozzon létre egy vagy több felhasználó által hozzárendelt felügyelt identitást , és adja meg a felhasználó által hozzárendelt felügyelt identitásnak a szükséges engedélyeket, ahogyan azt az SQL-felhasználók és mások esetében általában teszi. Futtassa a következő kódot. További lehetőségekért tekintse meg ezt a dokumentumot.
ALTER ROLE [role name e.g. db_owner] ADD MEMBER [your_factory_or_workspace_name]Rendeljen hozzá egy vagy több felhasználó által hozzárendelt felügyelt identitást az adat-előállítóhoz, és hozzon létre hitelesítő adatokat minden felhasználó által hozzárendelt felügyelt identitáshoz.
Felügyelt SQL-példány társított szolgáltatásának konfigurálása.
Példa: felhasználó által hozzárendelt felügyelt identitáshitelesítést használ
{
"name": "AzureSqlDbLinkedService",
"properties": {
"type": "AzureSqlMI",
"typeProperties": {
"connectionString": "Data Source=<hostname,port>;Initial Catalog=<databasename>;",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Adathalmaz tulajdonságai
Az adathalmazok definiálásához használható szakaszok és tulajdonságok teljes listáját az adathalmazokról szóló cikkben találja. Ez a szakasz a felügyelt SQL-példány adatkészlete által támogatott tulajdonságok listáját tartalmazza.
Az adatok felügyelt SQL-példányba való másolásához és onnan való másolásához a következő tulajdonságok támogatottak:
| Tulajdonság | Leírás | Kötelező |
|---|---|---|
| típus | Az adathalmaz típustulajdonságának AzureSqlMITable értékre kell állítania. | Igen |
| schema | A séma neve. | Nem a forráshoz, igen a fogadóhoz |
| table | A tábla/nézet neve. | Nem a forráshoz, igen a fogadóhoz |
| tableName | A táblázat/nézet neve sémával. Ez a tulajdonság támogatja a visszamenőleges kompatibilitást. Új számítási feladatokhoz használja schema és table. |
Nem a forráshoz, igen a fogadóhoz |
Példa
{
"name": "AzureSqlMIDataset",
"properties":
{
"type": "AzureSqlMITable",
"linkedServiceName": {
"referenceName": "<SQL Managed Instance linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
}
}
}
Másolási tevékenység tulajdonságai
A tevékenységek definiálásához használható szakaszok és tulajdonságok teljes listáját a Folyamatok című cikkben találja. Ez a szakasz a felügyelt SQL-példány forrása és fogadója által támogatott tulajdonságok listáját tartalmazza.
Felügyelt SQL-példány forrásként
Tipp.
Ha hatékonyan szeretne adatokat betölteni az SQL MI-ből adatparticionálással, további információt az SQL MI párhuzamos másolásáról tudhat meg.
A felügyelt SQL-példány adatainak másolásához a másolási tevékenység forrás szakasza az alábbi tulajdonságokat támogatja:
| Tulajdonság | Leírás | Kötelező |
|---|---|---|
| típus | A másolási tevékenység forrásának típustulajdonságát sqlMISource-ra kell állítani. | Igen |
| sqlReaderQuery | Ez a tulajdonság az egyéni SQL-lekérdezést használja az adatok olvasásához. Például: select * from MyTable. |
Nem |
| sqlReaderStoredProcedureName | Ez a tulajdonság annak a tárolt eljárásnak a neve, amely adatokat olvas be a forrástáblából. Az utolsó SQL-utasításnak egy Standard kiadás LECT utasításnak kell lennie a tárolt eljárásban. | Nem |
| storedProcedureParameters | Ezek a paraméterek a tárolt eljáráshoz tartoznak. Az engedélyezett értékek név- vagy értékpárok. A paraméterek nevének és burkolatának meg kell egyeznie a tárolt eljárásparaméterek nevével és burkolatával. |
Nem |
| isolationLevel | Az SQL-forrás tranzakciózárolási viselkedését adja meg. Az engedélyezett értékek a következők: ReadCommitted, ReadUncommitted, RepeatableRead, Serializable, Snapshot. Ha nincs megadva, a rendszer az adatbázis alapértelmezett elkülönítési szintjét használja. További részletekért tekintse meg ezt a dokumentumot. | Nem |
| partitionOptions | Megadja az SQL MI-ből való adatok betöltéséhez használt adatparticionálási beállításokat. Az engedélyezett értékek a következők: Nincs (alapértelmezett), PhysicalPartitionsOfTable és DynamicRange. Ha egy partíciós beállítás engedélyezve van (vagyis nem None), az SQL MI-ből egyidejűleg betöltendő adatok párhuzamossági fokát a parallelCopies másolási tevékenység beállítása szabályozza. |
Nem |
| partíció Gépház | Adja meg az adatparticionálás beállításainak csoportját. Akkor alkalmazható, ha a partíciós beállítás nem None. |
Nem |
A következő alatt partitionSettings: |
||
| partitionColumnName | Adja meg annak a forrásoszlopnak a nevét egész számban vagy dátum/dátum/idő típusban (int, , smallint, bigint, datesmalldatetime, datetime, , datetime2) , datetimeoffsetamelyet a tartomány particionálása használ a párhuzamos másoláshoz. Ha nincs megadva, a rendszer automatikusan észleli és partícióoszlopként használja a tábla indexét vagy elsődleges kulcsát.Akkor alkalmazható, ha a partíció beállítás. DynamicRange Ha lekérdezést használ a forrásadatok lekéréséhez, a WHERE záradékban kapcsoljon ?AdfDynamicRangePartitionCondition be. Példaként tekintse meg az SQL Database párhuzamos másolatát. |
Nem |
| partitionUpperBound | A partíciótartományok felosztásához használt partícióoszlop maximális értéke. Ez az érték határozza meg a partíciós léptetést, nem pedig a tábla sorainak szűrésére. A tábla vagy lekérdezés eredményének összes sora particionálásra és másolásra kerül. Ha nincs megadva, a másolási tevékenység automatikusan észleli az értéket. Akkor alkalmazható, ha a partíció beállítás. DynamicRange Példaként tekintse meg az SQL Database párhuzamos másolatát. |
Nem |
| partitionLowerBound | A partíciótartományok felosztásához használt partícióoszlop minimális értéke. Ez az érték határozza meg a partíciós léptetést, nem pedig a tábla sorainak szűrésére. A tábla vagy lekérdezés eredményének összes sora particionálásra és másolásra kerül. Ha nincs megadva, a másolási tevékenység automatikusan észleli az értéket. Akkor alkalmazható, ha a partíció beállítás. DynamicRange Példaként tekintse meg az SQL Database párhuzamos másolatát. |
Nem |
Vegye figyelembe a következő szempontokat:
- Ha sqlReaderQuery van megadva az SqlMISource-hoz, a másolási tevékenység ezt a lekérdezést a felügyelt SQL-példány forrásán futtatja az adatok lekéréséhez. Tárolt eljárást is megadhat az sqlReaderStoredProcedureName és a storedProcedureParameters megadásával, ha a tárolt eljárás paramétereket vesz fel.
- Ha tárolt eljárást használ a forrásban az adatok lekéréséhez, vegye figyelembe, hogy a tárolt eljárás más sémát ad vissza, amikor különböző paraméterértéket ad át, akkor előfordulhat, hogy a séma felhasználói felületről történő importálásakor vagy az adatok sql-adatbázisba való automatikus létrehozásakor hiba vagy váratlan eredmény jelenik meg.
Példa: SQL-lekérdezés használata
"activities":[
{
"name": "CopyFromAzureSqlMI",
"type": "Copy",
"inputs": [
{
"referenceName": "<SQL Managed Instance input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlMISource",
"sqlReaderQuery": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Példa: Tárolt eljárás használata
"activities":[
{
"name": "CopyFromAzureSqlMI",
"type": "Copy",
"inputs": [
{
"referenceName": "<SQL Managed Instance input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlMISource",
"sqlReaderStoredProcedureName": "CopyTestSrcStoredProcedureWithParameters",
"storedProcedureParameters": {
"stringData": { "value": "str3" },
"identifier": { "value": "$$Text.Format('{0:yyyy}', <datetime parameter>)", "type": "Int"}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
A tárolt eljárás definíciója
CREATE PROCEDURE CopyTestSrcStoredProcedureWithParameters
(
@stringData varchar(20),
@identifier int
)
AS
SET NOCOUNT ON;
BEGIN
select *
from dbo.UnitTestSrcTable
where dbo.UnitTestSrcTable.stringData != stringData
and dbo.UnitTestSrcTable.identifier != identifier
END
GO
Felügyelt SQL-példány fogadóként
Tipp.
További információ a felügyelt SQL-példányba való adatbetöltés ajánlott eljárásainak támogatott írási viselkedéseiről, konfigurációiról és ajánlott eljárásairól.
Az adatok felügyelt SQL-példányba való másolásához a másolási tevékenység fogadó szakasza az alábbi tulajdonságokat támogatja:
| Tulajdonság | Leírás | Kötelező |
|---|---|---|
| típus | A másolási tevékenység fogadójának típustulajdonságát SqlMISink értékre kell állítani. | Igen |
| preCopyScript | Ez a tulajdonság egy SQL-lekérdezést ad meg a másolási tevékenység futtatásához, mielőtt adatokat írna a felügyelt SQL-példányba. Másolási futtatásonként csak egyszer lesz meghívva. Ezzel a tulajdonságkal törölheti az előre betöltött adatokat. | Nem |
| tableOption | Megadja, hogy automatikusan létre kívánja-e hozni a fogadótáblát , ha nem létezik a forrásséma alapján. Az automatikus táblalétrehozás nem támogatott, ha a fogadó a tárolt eljárást határozza meg. Az engedélyezett értékek a következők: none (alapértelmezett), autoCreate. |
Nem |
| sqlWriterStoredProcedureName | A tárolt eljárás neve, amely meghatározza a forrásadatok céltáblába való alkalmazását. Ezt a tárolt eljárást kötegenként hívja meg a rendszer. Olyan műveletek esetén, amelyek csak egyszer futnak, és nincs köze a forrásadatokhoz, például törléshez vagy csonkolási műveletekhez, használja a tulajdonságot preCopyScript .Tekintse meg az SQL-fogadó tárolt eljárásának meghívására vonatkozó példát. |
Nem |
| storedProcedureTableTypeParameterName | A tárolt eljárásban megadott táblatípus paraméterneve. | Nem |
| sqlWriterTableType | A tárolt eljárásban használandó táblatípus neve. A másolási tevékenység elérhetővé teszi az áthelyezett adatokat egy ilyen típusú ideiglenes táblában. A tárolt eljáráskód ezután egyesítheti a másolt adatokat a meglévő adatokkal. | Nem |
| storedProcedureParameters | A tárolt eljárás paraméterei. Az engedélyezett értékek név- és értékpárok. A paraméterek nevének és burkolatának meg kell egyeznie a tárolt eljárásparaméterek nevével és burkolatával. |
Nem |
| writeBatchSize | Az SQL-táblába kötegenként beszúrandó sorok száma. Az engedélyezett értékek a sorok számának egész száma. Alapértelmezés szerint a szolgáltatás dinamikusan határozza meg a megfelelő kötegméretet a sorméret alapján. |
Nem |
| writeBatchTimeout | A beszúrási, upsert- és tárolt eljárásművelet befejezésének várakozási ideje, mielőtt túllépi az időkorlátot. Az engedélyezett értékek az időbélyeghez tartoznak. Ilyen például a "00:30:00" 30 percig. Ha nincs megadva érték, az időtúllépés alapértelmezés szerint "00:30:00". |
Nem |
| maxConcurrent Csatlakozás ions | Az adattárhoz a tevékenység futtatása során létrehozott egyidejű kapcsolatok felső korlátja. Csak akkor adjon meg értéket, ha korlátozni szeretné az egyidejű kapcsolatokat. | Nem |
| WriteBehavior | Adja meg az adatok Azure SQL MI-be való betöltéséhez szükséges másolási tevékenység írási viselkedését. Az engedélyezett érték a Beszúrás és az Upsert. Alapértelmezés szerint a szolgáltatás beszúrással tölti be az adatokat. |
Nem |
| upsert Gépház | Adja meg az írási viselkedés beállításainak csoportját. Alkalmazza, ha a WriteBehavior beállítás a következő Upsert: . |
Nem |
A következő alatt upsertSettings: |
||
| useTempDB | Adja meg, hogy globális ideiglenes vagy fizikai táblát használjon-e köztes táblaként az upserthez. Alapértelmezés szerint a szolgáltatás globális ideiglenes táblát használ köztes táblaként. értéke . true |
Nem |
| interimSchemaName | Adja meg a köztes sémát a köztes tábla létrehozásához fizikai tábla használata esetén. Megjegyzés: a felhasználónak rendelkeznie kell a tábla létrehozására és törlésére vonatkozó engedéllyel. Alapértelmezés szerint a köztes tábla ugyanazt a sémát fogja megosztani, mint a fogadó táblát. Akkor alkalmazható, ha a useTempDB beállítás a Falsekövetkező: . |
Nem |
| keys | Adja meg az egyedi sorazonosítás oszlopnevét. Egy vagy több kulcs használható. Ha nincs megadva, a rendszer az elsődleges kulcsot használja. | Nem |
1. példa: Adatok hozzáfűzése
"activities":[
{
"name": "CopyToAzureSqlMI",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<SQL Managed Instance output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SqlMISink",
"tableOption": "autoCreate",
"writeBatchSize": 100000
}
}
}
]
2. példa: Tárolt eljárás meghívása másolás közben
További információ az SQL MI-fogadó tárolt eljárásának meghívásáról.
"activities":[
{
"name": "CopyToAzureSqlMI",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<SQL Managed Instance output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SqlMISink",
"sqlWriterStoredProcedureName": "CopyTestStoredProcedureWithParameters",
"storedProcedureTableTypeParameterName": "MyTable",
"sqlWriterTableType": "MyTableType",
"storedProcedureParameters": {
"identifier": { "value": "1", "type": "Int" },
"stringData": { "value": "str1" }
}
}
}
}
]
3. példa: Upsert data
"activities":[
{
"name": "CopyToAzureSqlMI",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<SQL Managed Instance output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SqlMISink",
"tableOption": "autoCreate",
"writeBehavior": "upsert",
"upsertSettings": {
"useTempDB": true,
"keys": [
"<column name>"
]
},
}
}
}
]
Párhuzamos másolás az SQL MI-ből
Az Azure SQL Managed Instance-összekötő másolási tevékenységben beépített adatparticionálást biztosít az adatok párhuzamos másolásához. Az adatparticionálási beállításokat a másolási tevékenység Forrás lapján találja.
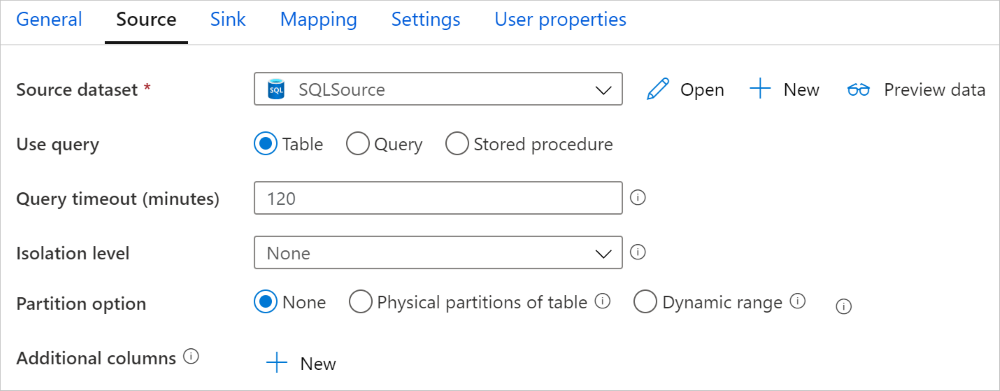
Ha engedélyezi a particionált másolást, a másolási tevékenység párhuzamos lekérdezéseket futtat az SQL MI-forráson az adatok partíciók szerinti betöltéséhez. A párhuzamos fokot a másolási parallelCopies tevékenység beállításai vezérlik. Ha például négyre van állítva parallelCopies , a szolgáltatás egyszerre generál és futtat négy lekérdezést a megadott partícióbeállítás és -beállítások alapján, és minden lekérdezés lekéri az adatok egy részét az SQL MI-ből.
Javasoljuk, hogy engedélyezze a párhuzamos másolást adatparticionálással, különösen akkor, ha nagy mennyiségű adatot tölt be az SQL MI-ből. A következő javasolt konfigurációk különböző forgatókönyvekhez. Ha fájlalapú adattárba másol adatokat, ajánlott több fájlként írni egy mappába (csak a mappa nevét kell megadni), ebben az esetben a teljesítmény jobb, mint egyetlen fájlba írni.
| Eset | Javasolt beállítások |
|---|---|
| Teljes terhelés nagy táblából, fizikai partíciókkal. | Partíciós beállítás: A tábla fizikai partíciói. A végrehajtás során a szolgáltatás automatikusan észleli a fizikai partíciókat, és partíciók alapján másolja az adatokat. Ha ellenőrizni szeretné, hogy a tábla rendelkezik-e fizikai partícióval, tekintse meg ezt a lekérdezést. |
| Teljes terhelés nagy táblából fizikai partíciók nélkül, egész számmal vagy datetime oszlopmal az adatparticionáláshoz. | Partícióbeállítások: Dinamikus tartomány partíciója. Partícióoszlop (nem kötelező): Adja meg az adatok particionálásához használt oszlopot. Ha nincs megadva, a rendszer az indexet vagy az elsődleges kulcs oszlopot használja. A partíció felső határa és a partíció alsó határa (nem kötelező): Adja meg, hogy meg szeretné-e határozni a partíciós lépést. Ez nem a táblázat sorainak szűrésére, hanem a tábla összes sorának particionálása és másolása történik. Ha nincs megadva, a másolási tevékenység automatikusan észleli az értékeket. Ha például az "ID" partícióoszlop értéke 1 és 100 között van, és az alsó kötést 20-ra, a felső kötést pedig 80-ra állítja be, a párhuzamos másolás 4-zel történik, a szolgáltatás 4 partícióval kéri le az adatokat – azonosítók az =20, [21, 50], [51, 80] és >=81 tartományban<. |
| Nagy mennyiségű adat betöltése egyéni lekérdezéssel fizikai partíciók nélkül, az adatparticionáláshoz pedig egész számmal vagy dátum/dátum/idő oszlopmal. | Partícióbeállítások: Dinamikus tartomány partíciója. Lekérdezés: SELECT * FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition AND <your_additional_where_clause>.Partícióoszlop: Adja meg az adatok particionálásához használt oszlopot. A partíció felső határa és a partíció alsó határa (nem kötelező): Adja meg, hogy meg szeretné-e határozni a partíciós lépést. Ez nem a tábla sorainak szűrésére használható, a lekérdezés eredményének összes sora particionálásra és másolásra kerül. Ha nincs megadva, a másolási tevékenység automatikusan észleli az értéket. A végrehajtás során a szolgáltatás lecseréli az egyes partíciók ?AdfRangePartitionColumnName tényleges oszlopnevét és értéktartományait, és elküldi az SQL MI-nek. Ha például az "ID" partícióoszlop értéke 1 és 100 között van, és az alsó kötést 20-ra, a felső kötést pedig 80-ra állítja be, a párhuzamos másolás 4-zel, akkor a szolgáltatás 4 partícióazonosítóval kéri le az adatokat az =20, [21, 50], [51, 80] és >=81 tartományban<. Az alábbiakban további minta lekérdezéseket talál a különböző forgatókönyvekhez: 1. A teljes tábla lekérdezése: SELECT * FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition2. Lekérdezés oszlopkijelöléssel és további where-clause szűrőkkel rendelkező táblából: SELECT <column_list> FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition AND <your_additional_where_clause>3. Lekérdezés al lekérdezésekkel: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?AdfDynamicRangePartitionCondition AND <your_additional_where_clause>4. Lekérdezés a partícióval az alkérdezésben: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition) AS T |
Ajánlott eljárások az adatok partíciós beállítással való betöltéséhez:
- Válassza a megkülönböztető oszlopot partícióoszlopként (például elsődleges kulcs vagy egyedi kulcs) az adateltérés elkerülése érdekében.
- Ha a tábla beépített partícióval rendelkezik, a jobb teljesítmény érdekében használja a "Tábla fizikai partíciói" partícióbeállítást.
- Ha az Azure Integration Runtime-t használja az adatok másolásához, nagyobb "adatintegráció egységeket (DIU)" (>4) állíthat be a nagyobb számítási erőforrások használatához. Ellenőrizze a vonatkozó forgatókönyveket.
- A "másolási párhuzamosság foka" szabályozza a partíciószámokat, a túl nagy szám beállítása néha rontja a teljesítményt, javasoljuk, hogy állítsa be ezt a számot (DIU vagy a saját üzemeltetésű INTEGRÁCIÓs csomópontok száma) * (2–4).
Példa: teljes terhelés nagy táblából fizikai partíciókkal
"source": {
"type": "SqlMISource",
"partitionOption": "PhysicalPartitionsOfTable"
}
Példa: lekérdezés dinamikus tartománypartícióval
"source": {
"type": "SqlMISource",
"query": "SELECT * FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
Minta lekérdezés a fizikai partíció ellenőrzéséhez
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, pf.name AS PartitionFunctionName, c.name AS ColumnName, iif(pf.name is null, 'no', 'yes') AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
Ha a tábla fizikai partícióval rendelkezik, a "HasPartition" az alábbihoz hasonlóan "igen" értékként jelenik meg.

Ajánlott eljárás adatok felügyelt SQL-példányba való betöltéséhez
Ha adatokat másol a felügyelt SQL-példányba, előfordulhat, hogy eltérő írási viselkedésre van szükség:
- Hozzáfűzés: A forrásadatok csak új rekordokat tartalmaznak.
- Upsert: A forrásadatok beszúrásokkal és frissítésekkel is rendelkeznek.
- Felülírás: Minden alkalommal újra szeretném betölteni a teljes dimenziótáblát.
- Írás egyéni logikával: További feldolgozásra van szükségem a végső beszúrás előtt a céltáblába.
A konfiguráláshoz és az ajánlott eljárásokhoz tekintse meg a megfelelő szakaszokat.
Adatok hozzáfűzése
A felügyelt SQL-példány fogadó összekötőjének alapértelmezett viselkedése az adatok hozzáfűzése. A szolgáltatás tömeges beszúrással hatékonyan ír a táblába. Ennek megfelelően konfigurálhatja a forrást és a fogadót a másolási tevékenységben.
Adatok beszúrása és frissítése (upsert)
Copy tevékenység mostantól támogatja az adatok natív betöltését egy adatbázis ideiglenes táblájába, majd frissíti a fogadó táblában lévő adatokat, ha van kulcs, és egyéb módon szúrjon be új adatokat. Ha többet szeretne megtudni a másolási tevékenységek upsert beállításairól, tekintse meg a felügyelt SQL-példányt fogadóként.
A teljes táblázat felülírása
A preCopyScript tulajdonságot a másolási tevékenység fogadójában konfigurálhatja. Ebben az esetben minden futtatott másolási tevékenységnél először a szolgáltatás futtatja a szkriptet. Ezután futtatja a másolatot az adatok beszúrásához. Ha például felül szeretné írni a teljes táblát a legújabb adatokkal, adjon meg egy szkriptet, amely először törli az összes rekordot, mielőtt tömegesen betöltené az új adatokat a forrásból.
Adatok írása egyéni logikával
Az adatok egyéni logikával történő írásának lépései hasonlóak az Upsert adatszakaszban leírtakhoz. Ha további feldolgozást kell alkalmaznia a forrásadatok céltáblába történő végleges beszúrása előtt, betölthet egy átmeneti táblába, majd meghívhatja a tárolt eljárástevékenységet, vagy meghívhat egy tárolt eljárást a másolási tevékenység fogadójában az adatok alkalmazásához.
Tárolt eljárás meghívása SQL-fogadóból
Ha adatokat másol a felügyelt SQL-példányba, konfigurálhat és meghívhat egy felhasználó által megadott tárolt eljárást is további paraméterekkel a forrástábla minden kötegén. A tárolt eljárás funkció kihasználja a táblaértékű paraméterek előnyeit.
Tárolt eljárást akkor használhat, ha a beépített másolási mechanizmusok nem szolgálják a célt. Ilyen például, ha a forrásadatok végső beszúrása előtt további feldolgozást szeretne alkalmazni a céltáblába. További feldolgozási példák az oszlopok egyesítése, további értékek keresése és több táblába való beszúrás.
Az alábbi minta bemutatja, hogyan használható tárolt eljárás egy upsert az SQL Server-adatbázis táblájába. Tegyük fel, hogy a bemeneti adatok és a fogadó marketingtáblája három oszlopból áll: ProfileID, State és Category. Végezze el az upsertet a ProfileID oszlop alapján, és csak a "ProductA" nevű adott kategóriára alkalmazza.
Az adatbázisban adja meg az sqlWriterTableType nevével megegyező nevű táblatípust. A táblatípus sémája megegyezik a bemeneti adatok által visszaadott sémával.
CREATE TYPE [dbo].[MarketingType] AS TABLE( [ProfileID] [varchar](256) NOT NULL, [State] [varchar](256) NOT NULL, [Category] [varchar](256) NOT NULL )Az adatbázisban adja meg a tárolt eljárást az sqlWriterStoredProcedureName névvel megegyező néven. Kezeli a megadott forrásból származó bemeneti adatokat, és egyesül a kimeneti táblában. A tárolt eljárásban a táblatípus paraméterneve megegyezik az adathalmazban definiált TableName paraméternévvel .
CREATE PROCEDURE spOverwriteMarketing @Marketing [dbo].[MarketingType] READONLY, @category varchar(256) AS BEGIN MERGE [dbo].[Marketing] AS target USING @Marketing AS source ON (target.ProfileID = source.ProfileID and target.Category = @category) WHEN MATCHED THEN UPDATE SET State = source.State WHEN NOT MATCHED THEN INSERT (ProfileID, State, Category) VALUES (source.ProfileID, source.State, source.Category); ENDA folyamatban adja meg az SQL MI fogadó szakaszát a másolási tevékenységben az alábbiak szerint:
"sink": { "type": "SqlMISink", "sqlWriterStoredProcedureName": "spOverwriteMarketing", "storedProcedureTableTypeParameterName": "Marketing", "sqlWriterTableType": "MarketingType", "storedProcedureParameters": { "category": { "value": "ProductA" } } }
Adatfolyam-tulajdonságok leképezése
A leképezési adatfolyam adatainak átalakításakor a felügyelt Azure SQL-példányból olvashat és írhat táblákba. További információkért tekintse meg a forrásátalakítást és a fogadóátalakítást a leképezési adatfolyamokban.
Forrásátalakítás
Az alábbi táblázat az Azure SQL Managed Instance-forrás által támogatott tulajdonságokat sorolja fel. Ezeket a tulajdonságokat a Forrás beállításai lapon szerkesztheti.
| Név | Leírás | Kötelező | Megengedett értékek | Adatfolyam-szkript tulajdonság |
|---|---|---|---|---|
| Tábla | Ha bemenetként a Táblázat lehetőséget választja, az adatfolyam lekéri az adathalmazban megadott táblából az összes adatot. | Nem | - | - |
| Lekérdezés | Ha bemenetként a Lekérdezés lehetőséget választja, adjon meg egy SQL-lekérdezést az adatok forrásból való lekéréséhez, amely felülírja az adathalmazban megadott táblázatokat. A lekérdezések használatával csökkenthetők a tesztelési és keresési sorok. Az Order By záradék nem támogatott, de beállíthat egy teljes Standard kiadás LECT FROM utasítást. Felhasználó által definiált táblafüggvényeket is használhat. A *elemet az udfGetData() egy UDF az SQL-ben, amely egy olyan táblát ad vissza, amelyet az adatfolyamban használhat. Példa lekérdezésre: Select * from MyTable where customerId > 1000 and customerId < 2000 |
Nem | Sztring | Lekérdezés |
| Köteg mérete | Adjon meg egy kötegméretet, amely nagy méretű adatokat olvas be. | Nem | Egész | batchSize |
| Elkülönítési szint | Válasszon az alábbi elkülönítési szintek közül: - Lekötött olvasás – Nem véglegesített olvasás (alapértelmezett) - Ismételhető olvasás -Szerializálható - Nincs (az elkülönítési szint figyelmen kívül hagyása) |
Nem | READ_COMMITTED READ_UNCOMMITTED REPEATABLE_READ Standard kiadás RIALIZABLE NINCS |
isolationLevel |
| Növekményes kivonat engedélyezése | Ezzel a beállítással az ADF-nek csak azokat a sorokat kell feldolgoznia, amelyek a folyamat legutóbbi végrehajtása óta megváltoztak. | Nem | - | - |
| Növekményes oszlop | A növekményes kinyerési funkció használatakor ki kell választania azt a dátum-/idő- vagy numerikus oszlopot, amelyet vízjelként szeretne használni a forrástáblában. | Nem | - | - |
| Natív módosítási adatrögzítés engedélyezése (előzetes verzió) | Ezzel a beállítással azt jelezheti az ADF-nek, hogy a folyamat legutóbbi végrehajtása óta csak az SQL-változási adatrögzítési technológia által rögzített változásadatokat dolgozza fel. Ezzel a beállítással a rendszer automatikusan betölti a deltaadatokat, beleértve a sor beszúrását, frissítését és törlését anélkül, hogy növekményes oszlopra lenne szükség. A beállítás ADF-ben való használata előtt engedélyeznie kell a változásadatok rögzítését az Azure SQL MI-ben. Az ADF-ben elérhető beállítással kapcsolatos további információkért lásd a natív változásadatok rögzítését. | Nem | - | - |
| Olvasás indítása az elejétől | Ha ezt a beállítást növekményes kivonattal állítja be, az ADF arra utasítja az ADF-t, hogy olvassa be az összes sort egy folyamat első végrehajtásakor, és be van kapcsolva a növekményes kivonat. | Nem | - | - |
Tipp.
Az SQL-ben használt közös táblakifejezés (CTE) nem támogatott a leképezési adatfolyam lekérdezési módjában, mivel ennek a módnak az előfeltétele, hogy a lekérdezések használhatók legyenek az SQL-lekérdezés FROM záradékában, de a CTE-k ezt nem tehetik meg. A CTE-k használatához létre kell hoznia egy tárolt eljárást a következő lekérdezéssel:
CREATE PROC CTESP @query nvarchar(max)
AS
BEGIN
EXECUTE sp_executesql @query;
END
Ezután használja a Tárolt eljárás módot a leképezési adatfolyam forrásátalakításában, és állítsa be a @query hasonló példát with CTE as (select 'test' as a) select * from CTE. Ezután használhatja a CT-eket a várt módon.
Példa felügyelt Azure SQL-példány forrásszkriptje
Ha a felügyelt Azure SQL-példányt használja forrástípusként, a társított adatfolyam-szkript a következő:
source(allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
query: 'select * from MYTABLE',
format: 'query') ~> SQLMISource
Fogadó átalakítása
Az alábbi táblázat a felügyelt Azure SQL-példány fogadója által támogatott tulajdonságokat sorolja fel. Ezeket a tulajdonságokat a Fogadó beállításai lapon szerkesztheti.
| Név | Leírás | Kötelező | Megengedett értékek | Adatfolyam-szkript tulajdonság |
|---|---|---|---|---|
| Frissítési módszer | Adja meg, hogy milyen műveletek engedélyezettek az adatbázis célhelyén. Az alapértelmezett beállítás csak a beszúrások engedélyezése. A sorok frissítéséhez, frissítéséhez vagy törléséhez a sorok címkézéséhez alter sorátalakítás szükséges. |
Igen | true vagy false |
törölhető beszúrható Frissíthető upsertable |
| Kulcsoszlopok | Frissítések, upserts és deletes esetén a kulcsoszlop(ok) beállításához meg kell határozni, hogy melyik sort kell módosítani. A kulcsként megadott oszlopnevet a rendszer a következő frissítés, a frissítés, a törlés részeként fogja használni. Ezért ki kell választania egy olyan oszlopot, amely a fogadóleképezésben található. |
Nem | Tömb | keys |
| Kulcsoszlopok írásának kihagyása | Ha nem szeretné az értéket a kulcsoszlopba írni, válassza a "Kulcsoszlopok írásának kihagyása" lehetőséget. | Nem | true vagy false |
skipKeyWrites |
| Táblaművelet | Meghatározza, hogy az írás előtt újra létre kell-e hozni vagy eltávolítani az összes sort a céltáblából. - Nincs: A rendszer nem hajt végre műveletet a táblán. - Újra: A tábla elvetve és újra létrehozva lesz. Új tábla dinamikus létrehozása esetén kötelező. - Csonkolási: A céltábla összes sora el lesz távolítva. |
Nem | true vagy false |
Újra megcsonkít |
| Köteg mérete | Adja meg, hogy hány sor legyen megírva az egyes kötegekben. A nagyobb kötegméretek javítják a tömörítést és a memóriaoptimalizálást, de az adatok gyorsítótárazásakor a memóriakivételek kiesnek. | Nem | Egész | batchSize |
| SQL-szkriptek elő- és postálása | Adja meg azokat a többsoros SQL-szkripteket, amelyek a fogadó adatbázisba való írása előtt (előzetes feldolgozás) és (utófeldolgozás) után hajtanak végre. | Nem | Sztring | preSQLs postSQLs |
Tipp.
Azure SQL Managed Instance fogadószkript – példa
Ha a felügyelt Azure SQL-példányt fogadótípusként használja, a társított adatfolyam-szkript a következő:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
deletable:false,
insertable:true,
updateable:true,
upsertable:true,
keys:['keyColumn'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> SQLMISink
Keresési tevékenység tulajdonságai
A tulajdonságok részleteinek megismeréséhez tekintse meg a keresési tevékenységet.
GetMetadata tevékenység tulajdonságai
A tulajdonságok részleteinek megismeréséhez ellenőrizze a GetMetadata-tevékenységet
Felügyelt SQL-példány adattípus-leképezése
Ha az adatokat másolási tevékenység használatával másolják át a felügyelt SQL-példányba és onnan, a rendszer a következő leképezéseket használja a felügyelt SQL-példányok adattípusaiból a szolgáltatáson belül használt köztes adattípusokra. Ha szeretné megtudni, hogy a másolási tevékenység hogyan képez le a forrássémáról és az adattípusról a fogadóra, tekintse meg a séma- és adattípus-leképezéseket.
| Felügyelt SQL-példány adattípusa | Köztes szolgáltatás adattípusa |
|---|---|
| bigint | Int64 |
| Bináris | Bájt[] |
| Kicsit | Logikai |
| Char | Sztring, Karakter[] |
| dátum: | Dátum/idő |
| Datetime | Dátum/idő |
| datetime2 | Dátum/idő |
| Datetimeoffset | DateTimeOffset |
| Decimális | Decimális |
| FILESTREAM attribútum (varbinary(max)) | Bájt[] |
| Lebegőpontos értékek | Dupla |
| rendszerkép | Bájt[] |
| egész | Int32 |
| Pénzt | Decimális |
| nchar | Sztring, Karakter[] |
| ntext | Sztring, Karakter[] |
| Numerikus | Decimális |
| nvarchar | Sztring, Karakter[] |
| valós szám | Egyszeres |
| rowversion | Bájt[] |
| smalldatetime | Dátum/idő |
| smallint | Int16 |
| smallmoney | Decimális |
| sql_variant | Objektum |
| text | Sztring, Karakter[] |
| time | időtartam |
| időbélyeg | Bájt[] |
| tinyint | Int16 |
| uniqueidentifier | GUID |
| varbinary | Bájt[] |
| varchar | Sztring, Karakter[] |
| xml | Sztring |
Feljegyzés
A decimális köztes típusra leképezhető adattípusok esetében jelenleg Copy tevékenység legfeljebb 28 pontosságot támogat. Ha 28-nál nagyobb pontosságot igénylő adatokkal rendelkezik, fontolja meg az SQL-lekérdezések sztringgé alakítását.
Always Encrypted használata
Ha adatokat másol a felügyelt SQL-példányból vagy az sql-ből az Always Encrypted használatával, kövesse az alábbi lépéseket:
Tárolja az oszlop főkulcsát (CMK) egy Azure Key Vaultban. További információ az Always Encrypted Azure Key Vault használatával történő konfigurálásáról
Győződjön meg arról, hogy nagy hozzáféréssel rendelkezik ahhoz a kulcstartóhoz, amelyben az oszlop főkulcsa (CMK) található. A szükséges engedélyekért tekintse meg ezt a cikket .
Hozzon létre társított szolgáltatást az SQL-adatbázishoz való csatlakozáshoz, és engedélyezze az "Always Encrypted" függvényt felügyelt identitás vagy szolgáltatásnév használatával.
Feljegyzés
Az SQL Managed Instance Always Encrypted az alábbi forgatókönyveket támogatja:
- A forrás- vagy fogadóadattárak a felügyelt identitást vagy a szolgáltatásnevet használják kulcsszolgáltatói hitelesítési típusként.
- A forrás- és fogadóadattárak is a felügyelt identitást használják kulcsszolgáltatói hitelesítési típusként.
- A forrás- és fogadóadattárak ugyanazt a szolgáltatásnevet használják, mint a kulcsszolgáltatói hitelesítés típusát.
Feljegyzés
Jelenleg az SQL Managed Instance Always Encrypted csak a forrásátalakításhoz támogatott a leképezési adatfolyamokban.
Natív változásadat-rögzítés
Az Azure Data Factory támogatja az SQL Server, az Azure SQL DB és az Azure SQL MI natív változásadat-rögzítési képességeit. Az ADF-leképezési adatfolyam automatikusan észlelheti és kinyerheti a módosított adatokat, beleértve a sor beszúrását, frissítését és törlését az SQL-tárolókban. Mivel nincs kódélmény az adatfolyam leképezésében, a felhasználók egyszerűen elérhetik az SQL-tárolókból származó adatreplikációs forgatókönyvet úgy, hogy céltárolóként hozzáfűznek egy adatbázist. Ráadásul a felhasználók bármilyen adatátalakítási logikát is megírhatnak az SQL-tárolók növekményes ETL-forgatókönyvének elérése érdekében.
Győződjön meg arról, hogy a folyamat és a tevékenység neve változatlan marad, hogy az ADF rögzíthesse az ellenőrzőpontot, hogy a legutóbbi futtatás során automatikusan megváltoztassa az adatokat. Ha módosítja a folyamat nevét vagy tevékenységnevét, az ellenőrzőpont alaphelyzetbe lesz állítva, ami azt eredményezi, hogy az első lépésektől kezdve vagy a következő futtatáskor a módosítások lekérése következik. Ha módosítani szeretné a folyamat nevét vagy tevékenységnevét, de továbbra is megtartja az ellenőrzőpontot, hogy az utolsó futtatásból származó módosított adatokat automatikusan megkapja, használja a saját Ellenőrzőpont-kulcsát az adatfolyam-tevékenységben ennek eléréséhez.
A folyamat hibakeresésekor ez a funkció ugyanúgy működik. Vegye figyelembe, hogy az ellenőrzőpont alaphelyzetbe áll, amikor frissíti a böngészőt a hibakeresési futtatás során. Miután elégedett a hibakeresési futtatás folyamatának eredményével, közzéteheti és aktiválhatja a folyamatot. Abban a pillanatban, amikor először aktiválja a közzétett folyamatot, az automatikusan újraindul az elejétől, vagy mostantól módosításokat kap.
A figyelési szakaszban mindig lehetősége van egy folyamat újrafuttatására. Ha így tesz, a módosított adatok mindig a kiválasztott folyamatfuttatás előző ellenőrzőpontjáról lesznek rögzítve.
1. példa:
Ha közvetlenül láncol egy SQL CDC-kompatibilis adatkészletre hivatkozott forrásátalakítást egy leképezési adatfolyam adatbázisára hivatkozva, a rendszer automatikusan alkalmazza a módosításokat az SQL-forráson a céladatbázisra, így könnyen lekérheti az adatbázisok közötti adatreplikációs forgatókönyvet. A fogadóátalakítás frissítési metódusával kiválaszthatja, hogy engedélyezi-e a beszúrást, engedélyezi a frissítést vagy engedélyezi a törlést a céladatbázison. A leképezési adatfolyam példaszkriptje az alábbi módon érhető el.
source(output(
id as integer,
name as string
),
allowSchemaDrift: true,
validateSchema: false,
enableNativeCdc: true,
netChanges: true,
skipInitialLoad: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source1
source1 sink(allowSchemaDrift: true,
validateSchema: false,
deletable:true,
insertable:true,
updateable:true,
upsertable:true,
keys:['id'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true,
errorHandlingOption: 'stopOnFirstError') ~> sink1
2. példa:
Ha az sql CDC-n keresztüli adatreplikáció helyett az ETL-forgatókönyvet szeretné engedélyezni az adatbázis között, kifejezéseket használhat az adatfolyam leképezésében, beleértve az isInsert(1), az isUpdate(1) és az isDelete(1) függvényt a sorok különböző művelettípusokkal való megkülönböztetéséhez. Az alábbi példaszkriptek egyike az adatfolyamok leképezésére egy oszlopból származó érték alapján: 1 a beszúrt sorok jelzésére, 2 a frissített sorok jelzésére, 3 pedig a törölt sorok jelzésére az alsóbb rétegbeli átalakításokhoz a deltaadatok feldolgozásához.
source(output(
id as integer,
name as string
),
allowSchemaDrift: true,
validateSchema: false,
enableNativeCdc: true,
netChanges: true,
skipInitialLoad: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source1
source1 derive(operationType = iif(isInsert(1), 1, iif(isUpdate(1), 2, 3))) ~> derivedColumn1
derivedColumn1 sink(allowSchemaDrift: true,
validateSchema: false,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> sink1
Ismert korlátozás:
- Az ADF csak az SQL CDC nettó módosításait tölti be cdc.fn_cdc_get_net_changes_ keresztül.
Kapcsolódó tartalom
A másolási tevékenység által forrásként és fogadóként támogatott adattárak listáját lásd : Támogatott adattárak.