Hozzáférés az Azure Data Lake Storage-hez a Microsoft Entra ID (korábbi nevén Azure Active Directory) hitelesítő adatok átengedésével (örökölt)
Fontos
Ez a dokumentáció ki lett állítva, és lehet, hogy nem frissül.
A hitelesítő adatok átadása egy örökölt adatszabályozási modell. A Databricks azt javasolja, hogy frissítsen a Unity Catalogra. A Unity Catalog leegyszerűsíti az adatok biztonságát és szabályozását azáltal, hogy központi helyet biztosít az adatokhoz való hozzáférés felügyeletéhez és naplózásához a fiók több munkaterületén. Lásd : Mi az a Unity Katalógus?.
A fokozott biztonság és szabályozási helyzet érdekében forduljon az Azure Databricks-fiók csapatához, hogy letiltsa a hitelesítő adatok átadását az Azure Databricks-fiókban.
Feljegyzés
Ez a cikk hivatkozik az engedélyezési listán szereplő kifejezésre, egy olyan kifejezésre, amelyet az Azure Databricks nem használ. Ha a kifejezés el lesz távolítva a szoftverből, a cikkből is eltávolítjuk.
Az Azure Databricks-fürtökről az Azure Databricksből (ADLS Gen1) és az ADLS Gen2-ből az Azure Databricks-fürtökről automatikusan hitelesíthető az Azure Databricks-fürtökről az Azure Databricksbe való bejelentkezéshez használt Microsoft Entra-azonosító (korábbi nevén Azure Active Directory) identitás használatával. Ha engedélyezi az Azure Data Lake Storage hitelesítő adatainak átadását a fürthöz, a fürtön futtatott parancsok anélkül olvashatnak és írhatnak adatokat az Azure Data Lake Storage-ban, hogy konfigurálnia kellene a szolgáltatásnév hitelesítő adatait a tárolóhoz való hozzáféréshez.
A hitelesítő adatok átengedése az Azure Data Lake Storage-ban csak az Azure Data Lake Storage Gen1 és Gen2 esetében támogatott. Az Azure Blob Storage nem támogatja a hitelesítő adatok átengedését.
Ez a cikk a következőket ismerteti:
- Hitelesítőadat-átengedés engedélyezése standard és magas egyidejűségi fürtök esetén.
- A hitelesítő adatok átengedésének konfigurálása és a tárerőforrások inicializálása az ADLS-fiókokban.
- Az ADLS-erőforrások közvetlen elérése, ha engedélyezve van a hitelesítő adatok átadása.
- Az ADLS-erőforrások elérése csatlakoztatási ponton keresztül, ha engedélyezve van a hitelesítő adatok átengedése.
- A hitelesítő adatok átengedésekor támogatott funkciók és korlátozások.
A jegyzetfüzetek példákat nyújtanak a hitelesítő adatok átengedésére az ADLS Gen1 és az ADLS Gen2 tárfiókokkal.
Követelmények
- Prémium csomag. A standard csomag prémiumra való frissítésével kapcsolatos részletekért tekintse meg az Azure Databricks-munkaterület frissítéséről vagy régebbi verzióra váltásáról szóló cikket.
- Azure Data Lake Storage Gen1 vagy Gen2 tárfiók. Az Azure Data Lake Storage Gen2-tárfiókoknak a hierarchikus névteret kell használniuk a hitelesítő adatok Azure Data Lake Storage-beli átengedéséhez. Az új ADLS Gen2-fiók létrehozásával kapcsolatos útmutatásért (beleértve a hierarchikus névtér engedélyezésének módját) tekintse meg a tárfiók létrehozását ismertető cikket.
- Megfelelően konfigurált felhasználói engedélyek az Azure Data Lake Storage-hoz. Az Azure Databricks rendszergazdájának biztosítania kell, hogy a felhasználók a megfelelő szerepkörökkel rendelkezzenek, például a Storage Blob Data Contributor szerepkörökkel az Azure Data Lake Storage-ban tárolt adatok olvasásához és írásához. Lásd: Az Azure Portal használata a blob- és üzenetsoradatok elérésére szolgáló Azure-szerepkör hozzárendeléséhez.
- Ismerje meg az átengedéshez engedélyezett munkaterület-rendszergazdák jogosultságait, és tekintse át a meglévő munkaterület-rendszergazdai hozzárendeléseket. A munkaterület rendszergazdái kezelhetik a munkaterület műveleteit, beleértve a felhasználók és szolgáltatásnevek hozzáadását, fürtök létrehozását és más felhasználók munkaterület-rendszergazdákként való delegálását. A munkaterület-kezelési feladatok, például a feladatok tulajdonjogának kezelése és a jegyzetfüzetek megtekintése közvetett hozzáférést biztosíthatnak az Azure Data Lake Storage-ban regisztrált adatokhoz. A munkaterület-rendszergazda olyan kiemelt szerepkör, amelyet körültekintően kell elosztani.
- Nem használhat ADLS-hitelesítő adatokkal konfigurált fürtöt, például szolgáltatásnév hitelesítő adatait hitelesítő adatokkal.
Fontos
Nem hitelesíthet az Azure Data Lake Storage-ban a Microsoft Entra-azonosító hitelesítő adataival, ha olyan tűzfal mögött van, amely nincs konfigurálva a Microsoft Entra-azonosító felé történő forgalom engedélyezésére. Az Azure Firewall alapértelmezés szerint letiltja az Active Directory-hozzáférést. A hozzáférés engedélyezéséhez konfigurálja az AzureActiveDirectory szolgáltatáscímkét. A hálózati virtuális berendezésekre vonatkozó megfelelő információkat az AzureActiveDirectory címke alatt találja az Azure IP-tartományok és szolgáltatáscímkék JSON-fájljában. További információért tekintse meg az Azure Firewall szolgáltatáscímkéiről és a nyilvános felhőkhöz való Azure-beli IP-címekről szóló részeket.
Naplózási javaslatok
Az Azure Storage diagnosztikai naplóiban naplózhatja az ADLS-tárolónak átadott identitásokat. A naplózási identitások lehetővé teszik, hogy az ADLS-kérelmek az Azure Databricks-fürtök egyes felhasználóihoz legyenek kötve. Kapcsolja be a diagnosztikai naplózást a tárfiókon a következő naplók fogadásához:
- Azure Data Lake Storage Gen1: Kövesse a Data Lake Storage Gen1-fiók diagnosztikai naplózásának engedélyezése című témakör utasításait.
- Azure Data Lake Storage Gen2: Konfigurálja a PowerShellt a
Set-AzStorageServiceLoggingPropertyparanccsal. Adja meg a 2.0-s verziót, mert a 2.0-s naplóbejegyzési formátum tartalmazza a felhasználónév nevét a kérelemben.
Azure Data Lake Storage hitelesítő adatok átadásának engedélyezése magas egyidejűségi fürt esetén
A magas egyidejűségi fürtöket több felhasználó is megoszthatja. Csak a Pythont és az SQL-t támogatják az Azure Data Lake Storage hitelesítő adatok átengedésével.
Fontos
Ha engedélyezi az Azure Data Lake Storage hitelesítőadat-átengedését egy magas egyidejűségi fürthöz, a 44., az 53. és a 80. port kivételével a fürt összes portja blokkolva van.
- Fürt létrehozásakor állítsa a fürt üzemmódotmagas egyidejűségre.
- A Speciális beállítások területen válassza a Hitelesítő adatok átengedésének engedélyezése felhasználói szintű adathozzáféréshez lehetőséget, és csak a Python- és SQL-parancsok engedélyezését.

Azure Data Lake Storage hitelesítő adatok átadásának engedélyezése standard fürtökhöz
A hitelesítő adatok átengedésére vonatkozó standard fürtök csak egyetlen felhasználóra korlátozódnak. A standard fürtök támogatják a Pythont, az SQL-t, a Scalát és az R-t. A Databricks Runtime 10.4 LTS és újabb verziók esetében a Sparklyr támogatott.
A fürt létrehozásakor hozzá kell rendelnie egy felhasználót, de a fürtöt bármikor SZERKESZTHETI engedéllyel rendelkező felhasználó az eredeti felhasználó lecseréléséhez.
Fontos
A fürthöz rendelt felhasználónak rendelkeznie kell legalább a FÜRTHÖZ CSATOLHATÓ engedéllyel ahhoz, hogy parancsokat futtasson a fürtön. A munkaterület rendszergazdái és a fürt létrehozója kezelheti az engedélyeket, de csak akkor futtathatnak parancsokat a fürtön, ha ők a kijelölt fürtfelhasználók.
- Fürt létrehozásakor állítsa a Fürt módot Standard értékre.
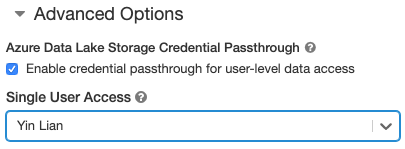
- A Speciális beállítások területen válassza a Hitelesítő adatok átengedése engedélyezése felhasználói szintű adathozzáféréshez lehetőséget, és válassza ki a felhasználónevet az Egyfelhasználós hozzáférés legördülő listából.
Tároló létrehozása
A tárolók lehetővé teszik az objektumok rendszerezését egy Azure Storage-fiókban.
Az Azure Data Lake Storage közvetlen elérése hitelesítő adatok átengedése használatával
Az Azure Data Lake Storage hitelesítő adatok átadásának konfigurálása és tárolótárolók létrehozása után közvetlenül az Azure Data Lake Storage Gen1-ben férhet hozzá az adatokhoz egy adl:// elérési út, az Azure Data Lake Storage Gen2 pedig egy abfss:// elérési út használatával.
Azure Data Lake Storage Gen1
Python
spark.read.format("csv").load("adl://<storage-account-name>.azuredatalakestore.net/MyData.csv").collect()
R
# SparkR
library(SparkR)
sparkR.session()
collect(read.df("adl://<storage-account-name>.azuredatalakestore.net/MyData.csv", source = "csv"))
# sparklyr
library(sparklyr)
sc <- spark_connect(method = "databricks")
sc %>% spark_read_csv("adl://<storage-account-name>.azuredatalakestore.net/MyData.csv") %>% sdf_collect()
- Cserélje le
<storage-account-name>az ADLS Gen1 tárfiók nevére.
A 2. generációs Azure Data Lake Storage
Python
spark.read.format("csv").load("abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/MyData.csv").collect()
R
# SparkR
library(SparkR)
sparkR.session()
collect(read.df("abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/MyData.csv", source = "csv"))
# sparklyr
library(sparklyr)
sc <- spark_connect(method = "databricks")
sc %>% spark_read_csv("abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/MyData.csv") %>% sdf_collect()
- Cserélje le
<container-name>egy tároló nevét az ADLS Gen2 tárfiókban. - Cserélje le
<storage-account-name>az ADLS Gen2 tárfiók nevére.
Az Azure Data Lake Storage csatlakoztatása a DBFS-hez hitelesítő adatok átadásával
Csatlakoztathat egy Azure Data Lake Storage-fiókot vagy egy mappát a Mi az a Databricks fájlrendszerhez (DBFS)?. A csatlakoztatás egy Data Lake Store-ra mutat, így az adatok szinkronizálása sosem helyben történik.
Ha az Azure Data Lake Storage hitelesítő adatok átengedése által engedélyezett fürt használatával csatlakoztat adatokat, a csatlakoztatási pontra történő olvasás vagy írás a Microsoft Entra-azonosító hitelesítő adatait használja. Ez a csatlakoztatási pont látható lesz a többi felhasználó számára, de csak azok a felhasználók férhetnek hozzá olvasási és írási hozzáféréssel, akik:
- Hozzáférés a mögöttes Azure Data Lake Storage-tárfiókhoz
- Az Azure Data Lake Storage hitelesítő adatok átengedéséhez engedélyezett fürtöt használ
Azure Data Lake Storage Gen1
Azure Data Lake Storage Gen1-erőforrás vagy mappa csatlakoztatásához használja a következő parancsokat:
Python
configs = {
"fs.adl.oauth2.access.token.provider.type": "CustomAccessTokenProvider",
"fs.adl.oauth2.access.token.custom.provider": spark.conf.get("spark.databricks.passthrough.adls.tokenProviderClassName")
}
# Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "adl://<storage-account-name>.azuredatalakestore.net/<directory-name>",
mount_point = "/mnt/<mount-name>",
extra_configs = configs)
Scala
val configs = Map(
"fs.adl.oauth2.access.token.provider.type" -> "CustomAccessTokenProvider",
"fs.adl.oauth2.access.token.custom.provider" -> spark.conf.get("spark.databricks.passthrough.adls.tokenProviderClassName")
)
// Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "adl://<storage-account-name>.azuredatalakestore.net/<directory-name>",
mountPoint = "/mnt/<mount-name>",
extraConfigs = configs)
- Cserélje le
<storage-account-name>az ADLS Gen2 tárfiók nevére. - Cserélje le
<mount-name>a dbFS-ben a kívánt csatlakoztatási pont nevére.
A 2. generációs Azure Data Lake Storage
Az Azure Data Lake Storage Gen2 fájlrendszerének vagy egy mappájának csatlakoztatásához használja a következő parancsokat:
Python
configs = {
"fs.azure.account.auth.type": "CustomAccessToken",
"fs.azure.account.custom.token.provider.class": spark.conf.get("spark.databricks.passthrough.adls.gen2.tokenProviderClassName")
}
# Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/",
mount_point = "/mnt/<mount-name>",
extra_configs = configs)
Scala
val configs = Map(
"fs.azure.account.auth.type" -> "CustomAccessToken",
"fs.azure.account.custom.token.provider.class" -> spark.conf.get("spark.databricks.passthrough.adls.gen2.tokenProviderClassName")
)
// Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/",
mountPoint = "/mnt/<mount-name>",
extraConfigs = configs)
- Cserélje le
<container-name>egy tároló nevét az ADLS Gen2 tárfiókban. - Cserélje le
<storage-account-name>az ADLS Gen2 tárfiók nevére. - Cserélje le
<mount-name>a dbFS-ben a kívánt csatlakoztatási pont nevére.
Figyelmeztetés
A csatlakoztatási ponton való hitelesítéshez ne adja meg a tárfiók hozzáférési kulcsait vagy a szolgáltatásnév hitelesítő adatait. Ez hozzáférést adna más felhasználóknak a fájlrendszerhez ezen hitelesítő adatok használatával. Az Azure Data Lake Storage hitelesítő adatok átadásának célja, hogy megakadályozza, hogy ezeket a hitelesítő adatokat használja, és hogy a fájlrendszerhez való hozzáférés csak azokra a felhasználókra korlátozódjon, akik hozzáférnek a mögöttes Azure Data Lake Storage-fiókhoz.
Biztonsági
Biztonságosan megoszthatja az Azure Data Lake Storage hitelesítőadat-átengedési fürtöit más felhasználókkal. El lesznek különítve egymástól, és nem fogják tudni olvasni vagy használni egymás hitelesítő adatait.
Támogatott funkciók
| Szolgáltatás | A Databricks runtime minimális verziója | Jegyzetek |
|---|---|---|
| Python és SQL | 5,5 | |
| 1. generációs Azure Data Lake Storage | 5,5 | |
%run |
5,5 | |
| DBFS | 5,5 | A hitelesítő adatok csak akkor lesznek átadva, ha a DBFS elérési útja az Azure Data Lake Storage Gen1 vagy Gen2 egy helyére kerül. A más tárolórendszerekre feloldó DBFS-útvonalak esetében használjon másik módszert a hitelesítő adatok megadásához. |
| Azure Data Lake Storage Gen2 | 5,5 | |
| Delta-gyorsítótárazás | 5,5 | |
| PySpark ML API | 5,5 | A következő ML-osztályok nem támogatottak: * org/apache/spark/ml/classification/RandomForestClassifier* org/apache/spark/ml/clustering/BisectingKMeans* org/apache/spark/ml/clustering/GaussianMixture* org/spark/ml/clustering/KMeans* org/spark/ml/clustering/LDA* org/spark/ml/evaluation/ClusteringEvaluator* org/spark/ml/feature/HashingTF* org/spark/ml/feature/OneHotEncoder* org/spark/ml/feature/StopWordsRemover* org/spark/ml/feature/VectorIndexer* org/spark/ml/feature/VectorSizeHint* org/spark/ml/regression/IsotonicRegression* org/spark/ml/regression/RandomForestRegressor* org/spark/ml/util/DatasetUtils |
| Szórási változók | 5,5 | A PySparkon belül korlátozva van a létrehozható Python UDF-ek mérete, mivel a nagy méretű UDF-ek szórási változóként lesznek elküldve. |
| Jegyzetfüzet-hatókörű kódtárak | 5,5 | |
| Scala | 5,5 | |
| SparkR | 6,0 | |
| sparklyr | 10.1 | |
| Databricks-jegyzetfüzet futtatása egy másik jegyzetfüzetből | 6.1 | |
| PySpark ML API | 6.1 | Az összes PySpark ML-osztály támogatott. |
| Fürtmetrikák | 6.1 | |
| Databricks-kapcsolat | 7.3 | Az átengedés standard fürtökön támogatott. |
Korlátozások
Az Azure Data Lake Storage hitelesítő adatok átengedése nem támogatja az alábbi funkciókat:
%fs(helyette használja az ezzel egyenértékű dbutils.fs parancsot).- Databricks-munkafolyamatok.
- A Databricks REST API-referencia.
- Unity Katalógus.
- Táblázat hozzáférés-vezérlése. Az Azure Data Lake Storage hitelesítő adatok átengedése által biztosított engedélyek segítségével megkerülhető a tábla ACL-ek részletes engedélyei, míg a tábla ACL-ek további korlátozásai korlátozzák a hitelesítő adatok átengedéséből származó előnyök némelyikét. Különösen:
- Ha rendelkezik Microsoft Entra ID-engedéllyel az adott táblához tartozó adatfájlok eléréséhez, akkor az RDD API-n keresztül teljes engedélyekkel rendelkezik a táblára vonatkozóan, függetlenül attól, hogy milyen korlátozások vonatkoznak rájuk a tábla ACL-jén keresztül.
- A tábla ACL-engedélyei csak a DataFrame API használatakor lesznek korlátozva. Ha közvetlenül a DataFrame API-val próbál fájlokat olvasni, figyelmeztetések jelennek meg arról, hogy nem rendelkezik engedéllyel
SELECTegyetlen fájlhoz sem, annak ellenére, hogy ezeket a fájlokat közvetlenül az RDD API-n keresztül is elolvashatja. - Az Azure Data Lake Storage-tól eltérő fájlrendszerek által támogatott táblákból akkor sem tud olvasni, ha tábla ACL-engedéllyel rendelkezik a táblák olvasásához.
- SparkContext (
sc) és SparkSession (spark) objektumokon a következő metódusok:- Elavult metódusok.
- Olyan metódusok, mint például
addFile()aaddJar()nem rendszergazdai felhasználók számára a Scala-kód meghívása. - Bármely olyan módszer, amely nem az Azure Data Lake Storage Gen1 vagy Gen2 fájlrendszeréhez fér hozzá (ha engedélyezni szeretné az Azure Data Lake Storage hitelesítő adatok átadását engedélyező fürt más fájlrendszereit, használjon másik módszert a hitelesítő adatok megadásához, és tekintse meg a megbízható fájlrendszerek hibaelhárítási szakaszát).
- A régi Hadoop API-k (
hadoopFile()éshadoopRDD()). - Streamelési API-k, mivel az átadott hitelesítő adatok lejárnak, amíg a stream még fut.
- A DBFS-csatlakoztatások (
/dbfs) csak a Databricks Runtime 7.3 LTS és újabb verziókban érhetők el. Ezen az útvonalon nem támogatottak a hitelesítő adatok átengedése által konfigurált csatlakoztatási pontok. - Azure Data Factory.
- MLflow magas egyidejűségi fürtökön.
- azureml-sdk Python-csomag magas egyidejűségi fürtökön.
- A Microsoft Entra ID átengedő jogkivonatok élettartamát nem hosszabbíthatja meg a Microsoft Entra ID-jogkivonatok élettartam-szabályzatai használatával. Ennek következtében, ha egy óránál hosszabb ideig tartó parancsot küld a fürtnek, az sikertelen lesz, ha egy Azure Data Lake Storage-erőforrás az 1 órás jelölés után érhető el.
- A Hive 2.3 és újabb verziók használatakor nem adhat hozzá partíciót olyan fürthöz, amelyen engedélyezve van a hitelesítő adatok átengedése. További információkért tekintse meg a vonatkozó hibaelhárítási szakaszt.
Példajegyzetfüzetek
Az alábbi jegyzetfüzetek az Azure Data Lake Storage 1. generációs és 2. generációs Azure Data Lake Storage hitelesítő adatait mutatják be.
Azure Data Lake Storage Gen1 átengedő jegyzetfüzet
Azure Data Lake Storage Gen2 átengedő jegyzetfüzet
Hibaelhárítás
py4j.security.Py4JSecurityException: ... nincs engedélyezve
Ez a kivétel akkor jelentkezik, ha olyan metódust ér el, amelyet az Azure Databricks nem jelölt meg kifejezetten biztonságosként az Azure Data Lake Storage hitelesítő adatokat átengedő fürtjeihez. A legtöbb esetben ez azt jelenti, hogy a metódus lehetővé teheti, hogy az Azure Data Lake Storage hitelesítő adatokat átengedő fürtjén lévő felhasználók hozzáférjenek egy másik felhasználó hitelesítő adataihoz.
org.apache.spark.api.python.PythonSecurityException: Path ... nem megbízható fájlrendszert használ
Ez a kivétel akkor jelentkezik, ha olyan fájlrendszert próbál elérni, amelyet az Azure Data Lake Storage hitelesítő adatokat átengedő fürtje nem tart számon biztonságosként. Ha nem megbízható fájlrendszert használ, az lehetővé teheti, hogy egy Azure Data Lake Storage hitelesítőadat-átengedő fürtön lévő felhasználó hozzáférjen egy másik felhasználó hitelesítő adataihoz, ezért letiltjuk az összes olyan fájlrendszert, amely nem biztos abban, hogy biztonságosan használják őket.
Ha megbízható fájlrendszereket szeretne konfigurálni egy hitelesítő adatokat átengedő Azure Data Lake Storage-fürtön, állítsa be a fürtön a spark.databricks.pyspark.trustedFilesystems Spark-konferenciakulcsot azon osztálynevek vesszővel elválasztott listájaként, amelyek az org.apache.hadoop.fs.FileSystem megbízható implementációi.
A partíció hozzáadása meghiúsul AzureCredentialNotFoundException , ha engedélyezve van a hitelesítő adatok átadása
Ha a Hive 2.3–3.1 használata esetében olyan fürtön próbál partíciót hozzáadni, amelyen engedélyezve van a hitelesítő adatok átengedése, a következő kivétel jelentkezik:
org.apache.spark.sql.AnalysisException: org.apache.hadoop.hive.ql.metadata.HiveException: MetaException(message:com.databricks.backend.daemon.data.client.adl.AzureCredentialNotFoundException: Could not find ADLS Gen2 Token
A probléma megoldásához adjon hozzá partíciókat egy fürthöz hitelesítő adatok átengedésének engedélyezése nélkül.