Mi az az Azure HDInsight?
Az Azure HDInsight egy felhőbeli felügyelt, teljes körű, nyílt forráskódú elemzési szolgáltatás vállalatok részére. A HDInsighttal olyan nyílt forráskódú keretrendszereket használhat, mint az Apache Spark, az Apache Hive, az LLAP, az Apache Kafka, a Hadoop stb. az Azure-környezetben.
Mi a HDInsight, és mik azok a Hadoop-technológiák?
Az Azure HDInsight egy felügyelt fürtplatform, amely megkönnyíti olyan big data-keretrendszerek futtatását, mint az Apache Spark, az Apache Hive, az LLAP, az Apache Kafka, az Apache Hadoop és más azure-környezetek. Úgy tervezték, hogy nagy mennyiségű adatot kezeljen nagy sebességgel és hatékonysággal.
Miért érdemes az Azure HDInsightot használni?
| Funkció | Leírás |
|---|---|
| Natív felhőalapú | Az Azure HDInsight lehetővé teszi, hogy optimalizált fürtöket hozzon létre a Sparkhoz, az interaktív lekérdezéshez (LLAP), a Kafkához, a HBase-hez és a Hadoophoz az Azure-ban. A HDInsight egy végpontok közötti SLA-t is biztosít az összes éles környezetben futó számítási feladathoz. |
| Alacsony költségű és méretezhető | A HDInsight lehetővé teszi a számítási feladatok vertikális fel- vagy leskálázását. Csökkentheti a költségeket, ha igény szerint hoz létre fürtöket, és csak azért fizet, amit használ. A feladatokat adatfolyamatok létrehozásával is működtetheti. A leválasztott számítás és tárolás jobb teljesítményt és rugalmasságot biztosít. |
| Biztonságos és megfelelő | A HDInsight lehetővé teszi a vállalati adategységek védelmét az Azure Virtual Network használatával, a titkosítással és a Microsoft Entra ID-val való integrációval. A HDInsight továbbá megfelel a legnépszerűbb iparági és kormányzati megfelelőségi szabványoknak. |
| Figyelés | Az Azure HDInsight az Azure Monitor-naplókkal integrálva egyetlen felületet biztosít, amellyel az összes fürtöt figyelheti. |
| Globális rendelkezésre állás | A HDInsight több régióban érhető el, mint bármely más big data-elemzési ajánlat. Az Azure HDInsight elérhető az Azure Governmentben, Kínában, és Németországban is, így megfelelhet a vállalati igényeknek a főbb szuverén területeken. |
| Termelékenység | Az Azure HDInsight számos hatékony eszközt biztosít a Hadoop és a Spark használatához a választott fejlesztési környezetben. Ezek a fejlesztési környezetek közé tartozik a Visual Studio, a VS Code, az Eclipse és az IntelliJ a Scalához, Pythonhoz, Java-hoz és .NET-támogatáshoz. |
| Bővíthetőség | A HDInsight-fürtöket kiterjesztheti telepített összetevőkkel (Hue, Presto stb.) szkriptműveletekkel, élcsomópontok hozzáadásával vagy más big data minősített alkalmazásokkal való integrálással. A HDInsight egykattintásos üzembe helyezéssel biztosít zökkenőmentes integrációt a legnépszerűbb big data-megoldásokkal. |
What is big data? (Mi az a big data?)
A big data gyűjtése egyre nagyobb mennyiségben és sebességgel, minden korábbinál többféle formátumban történik. Ezek az adatok lehetnek előzményadatok (azaz tárolt) vagy valós idejű adatok (vagyis a forrásból streamelt adatok). A big data leggyakoribb alkalmazási helyzetei: A HDInsight használatára vonatkozó forgatókönyvek.
Fürttípusok a HDInsightban
A HDInsight adott fürttípusokat és fürttestreszabási képességeket is tartalmaz, például lehetővé teszi összetevők, segédprogramok és nyelvek hozzáadását. A HDInsight a következő fürttípusokat kínálja:
| Fürt típusa | Leírás | Első lépések |
|---|---|---|
| Apache Hadoop | Egy keretrendszer, amely HDFS-t, YARN-erőforrás-kezelést és egyszerű MapReduce programozási modellt használ a kötegelt adatok párhuzamos feldolgozásához és elemzéséhez. | Apache Hadoop-fürt létrehozása |
| Apache Spark | Nyílt forráskódú párhuzamos feldolgozási keretrendszer, amely támogatja a memórián belüli feldolgozást a big data-elemzési alkalmazások teljesítményének növelése érdekében. Lásd: Mi a HDInsight-alapú Apache Spark?. | Apache Spark-fürt létrehozása |
| Apache HBase | A Hadoopra épülő NoSQL-adatbázis véletlenszerű hozzáférést és erős konzisztenciát biztosít nagy mennyiségű strukturálatlan és félig strukturált adathoz – akár több milliárd sor is több millió oszlophoz. Lásd: Mi a HDInsight-alapú HBase? | Apache HBase-fürt létrehozása |
| Apache Interactive Query | Memóriabeli gyorsítótárazás interaktív és gyorsabb Hive-lekérdezésekhez. Lásd: Az interaktív lekérdezés használata a HDInsightban. | Interaktív lekérdezésfürt létrehozása |
| Apache Kafka | A streamelési adatfolyamok és alkalmazások készítéséhez nyílt forráskódú platformot használnak. A Kafka egy Üzenetsor funkciót is biztosít, amelynek segítségével közzétehet adatstreameket vagy feliratkozhat rájuk. Lásd: A HDInsight alatt futó Apache Kafka bemutatása. | Apache Kafka-fürt létrehozása |
A HDInsight használatára vonatkozó forgatókönyvek
Az Azure HDInsight a big data-feldolgozás különböző forgatókönyveihez használható. Lehetnek előzményadatok (már összegyűjtött és tárolt adatok) vagy valós idejű adatok (a forrásból közvetlenül streamelt adatok). Az ilyen adatok feldolgozásának forgatókönyveit a következő kategóriákban lehet összegezni:
Kötegelt feldolgozás (ETL)
A kinyerési, átalakítási és betöltési (ETL) folyamat során a rendszer strukturálatlan és strukturált adatokat nyer ki heterogén adatforrásokból. Ezután strukturált formátumúvá alakítja azokat, majd betölti egy adattárba. Az átalakított adatok adatelemzéshez vagy adatraktározáshoz használhatók.
Adatraktározás
A HDInsight segítségével petabájtos nagyságrendű interaktív lekérdezéseket végezhet strukturált vagy strukturálatlan adatokon. Modelleket is létrehozhat BI-eszközökhöz való csatlakoztatással.
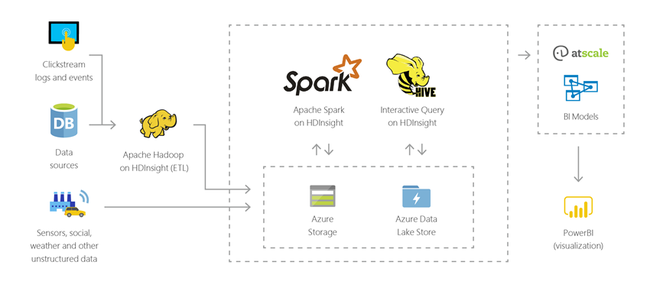
Eszközök internetes hálózata (IoT)
A HDInsight használatával feldolgozhatja a különböző eszközökről valós időben érkező streamelési adatokat. További információkért olvassa el ezt az Azure-blogbejegyzést, amely az Azure Managed Disksben HDInsight alatt futó Apache Kafka nyilvános előzetes verzióját jelenti be.
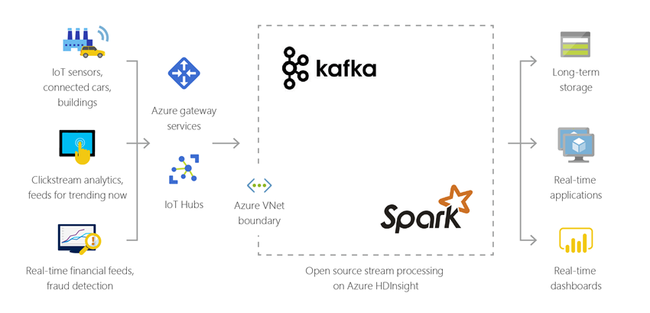
Hibrid
A HDInsight használatával kiterjesztheti meglévő helyszíni big data-infrastruktúráját az Azure-ra a felhő fejlett elemzési képességeinek alkalmazásához.
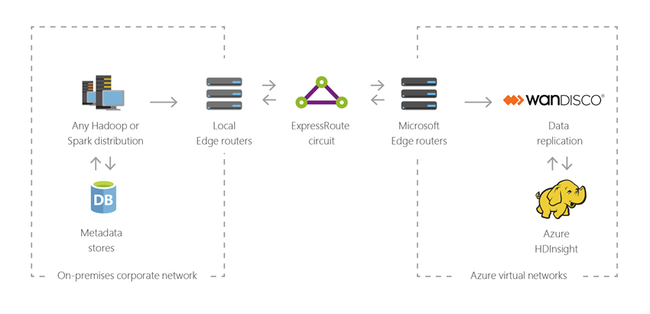
Nyílt forráskódú összetevők a HDInsightban
Az Azure HDInsight lehetővé teszi olyan nyílt forráskódú keretrendszerekkel rendelkező fürtök létrehozását, mint a Spark, a Hive, az LLAP, a Kafka, a Hadoop és a HBase. Alapértelmezés szerint ezek a fürtök különböző nyílt forráskódú összetevőket tartalmaznak, például Apache Ambari, Avro, Apache Hive 3, HCatalog, Apache Hadoop MapReduce, Apache Hadoop YARN, Apache Phoenix, Apache Pig, Apache Sqoop, Apache Tez, Apache Oozie és Apache ZooKeeper.
Programozási nyelvek a HDInsightban
A HDInsight-fürtök, például többek közt a Spark, a HBase, a Kafka, és a Hadoop, számos programozási nyelvet támogatnak. Egyes programozási nyelvek nincsenek alapértelmezés szerint telepítve. Az alapértelmezés szerint nem telepített kódtárak, modulok vagy csomagok esetében szkriptművelettel telepítse az összetevőt.
| Programozási nyelv | Tájékoztatás |
|---|---|
| Alapértelmezés szerint támogatott programozási nyelvek | Alapértelmezés szerint a HDInsight-fürtök a következőket támogatják:
|
| JVM (Java virtuális gép) nyelvek | A Java-alapú virtuális gépeken (JVM) a Javán kívül számos más nyelv is futtatható. Ha azonban ezen nyelvek némelyikét futtatja, előfordulhat, hogy további összetevőket kell telepítenie a fürtre. A HDInsight-fürtökön a következő JVM-alapú nyelvek támogatottak:
|
| Hadoop-specifikus nyelvek | A HDInsight-fürtök a Hadoop technológiai veremre jellemző alábbi nyelveket támogatják:
|
A HDInsight fejlesztői eszközei
A HDInsight fejlesztői eszközei (köztük az IntelliJ, az Eclipse, a Visual Studio Code és a Visual Studio) használatával HDInsight-adatlekérdezéseket és feladatokat szerkeszthet és küldhet be Azure-ral zökkenőmentesen együttműködve.
- Azure-eszközkészlet intelliJ 10-hez
- Azure-eszközkészlet az Eclipse 6-hoz
- Azure HDInsight-eszközök a VS Code 13-hoz
- Azure data lake tools for Visual Studio 9
Üzleti intelligencia a HDInsighton
A jól ismert üzletiintelligencia- (BI-) eszközök a Power Query beépülő modul vagy a Microsoft Hive ODBC-illesztő segítségével kérik le, elemzik és jelentik a HDInsight rendszerébe integrált adatokat:
Az Apache Spark BI adatvizualizációs eszközeinek használata az Azure HDInsighttal
Apache Hive-adatok vizualizációja a Microsoft Power BI-val az Azure HDInsightban
Csatlakozás Excelt az Apache Hadoopba a Power Queryvel (Windows szükséges)
Csatlakozás Excelt az Apache Hadoopba a Microsoft Hive ODBC-illesztőprogrammal (Windows szükséges)
Régión belüli adattárolás
A Spark, a Hadoop és az LLAP nem tárolja az ügyféladatokat, ezért ezek a szolgáltatások automatikusan megfelelnek az Adatvédelmi központban megadott régión belüli adattárolási követelményeknek.
A Kafka és a HBase tárolja az ügyféladatokat. Ezeket az adatokat a Kafka és a HBase automatikusan egyetlen régióban tárolja, így ez a szolgáltatás megfelel az Adatvédelmi központban megadott régión belüli adattárolási követelményeknek.
A jól ismert üzletiintelligencia-eszközök lekérik, elemzik és jelentik a HDInsighttal integrált adatokat a Power Query bővítmény vagy a Microsoft Hive ODBC-illesztőprogram használatával.