Telepítse a Jupyter Notebookot a számítógépre, és csatlakozzon az Apache Sparkhoz a HDInsighton
Ebből a cikkből megtudhatja, hogyan telepítheti a Jupyter Notebookot az egyéni PySpark (Pythonhoz) és az Apache Spark (Scala-hoz) kernelekkel Spark-varázslattal. Ezután csatlakoztatja a jegyzetfüzetet egy HDInsight-fürthöz.
A Jupyter telepítéséhez és az Apache Sparkhoz való csatlakozáshoz a HDInsighton négy fő lépés szükséges.
- A Spark-fürt konfigurálása.
- Telepítse a Jupyter Notebookot.
- Telepítse a PySparkot és a Spark-kerneleket a Spark-varázslattal.
- A Spark magic konfigurálása a Spark-fürt HDInsighton való eléréséhez.
További információ az egyéni kernelekről és a Spark magicről: A HDInsighton futó Apache Spark Linux-fürtökkel rendelkező Jupyter Notebookokhoz elérhető kernelek.
Előfeltételek
Apache Spark-fürt megléte a HDInsightban. További útmutatásért lásd: Apache Spark-fürt létrehozása az Azure HDInsightban. A helyi jegyzetfüzet csatlakozik a HDInsight-fürthöz.
A Jupyter-notebookok és a HDInsighton futó Spark használatának ismerete.
A Jupyter Notebook telepítése a számítógépre
Telepítse a Pythont a Jupyter Notebooks telepítése előtt. Az Anaconda-disztribúció a Pythont és a Jupyter Notebookot is telepíti.
Töltse le a platform Anaconda telepítőjét , és futtassa a telepítőt. A telepítővarázsló futtatása közben győződjön meg arról, hogy az Anaconda path változóhoz való hozzáadásának lehetőségét választja. Lásd még: A Jupyter telepítése az Anaconda használatával.
Spark magic telepítése
Adja meg a 3.6-os és 4.0-s verziójú HdInsight-fürtökhöz készült Spark Magic telepítéséhez szükséges parancsot
pip install sparkmagic==0.13.1. Lásd még: sparkmagic dokumentáció.A következő parancs futtatásával győződjön meg arról, hogy
ipywidgetsmegfelelően van telepítve:jupyter nbextension enable --py --sys-prefix widgetsnbextension
PySpark és Spark-kernelek telepítése
A telepítés helyének
sparkmagicazonosításához írja be a következő parancsot:pip show sparkmagicEzután módosítsa a munkakönyvtárat a fenti paranccsal azonosított helyre .
Az új munkakönyvtárban adjon meg egy vagy több parancsot az alábbi parancsok közül a kívánt kernel(ek) telepítéséhez:
Kernel Parancs Spark jupyter-kernelspec install sparkmagic/kernels/sparkkernelSparkR jupyter-kernelspec install sparkmagic/kernels/sparkrkernelPySpark jupyter-kernelspec install sparkmagic/kernels/pysparkkernelPySpark3 jupyter-kernelspec install sparkmagic/kernels/pyspark3kernelOpcionális. Adja meg az alábbi parancsot a kiszolgálóbővítmény engedélyezéséhez:
jupyter serverextension enable --py sparkmagic
A Spark Magic konfigurálása a HDInsight Spark-fürthöz való csatlakozáshoz
Ebben a szakaszban a korábban telepített Spark-varázslatot konfigurálja egy Apache Spark-fürthöz való csatlakozáshoz.
Indítsa el a Python-rendszerhéjat a következő paranccsal:
pythonA Jupyter konfigurációs adatait általában a felhasználók kezdőlapja tárolja. Adja meg a következő parancsot a kezdőkönyvtár azonosításához, és hozzon létre egy .sparkmagic nevű mappát. A rendszer a teljes elérési utat kimeneteli.
import os path = os.path.expanduser('~') + "\\.sparkmagic" os.makedirs(path) print(path) exit()A mappában
.sparkmagichozzon létre egy config.json nevű fájlt, és adja hozzá a következő JSON-kódrészletet.{ "kernel_python_credentials" : { "username": "{USERNAME}", "base64_password": "{BASE64ENCODEDPASSWORD}", "url": "https://{CLUSTERDNSNAME}.azurehdinsight.net/livy" }, "kernel_scala_credentials" : { "username": "{USERNAME}", "base64_password": "{BASE64ENCODEDPASSWORD}", "url": "https://{CLUSTERDNSNAME}.azurehdinsight.net/livy" }, "custom_headers" : { "X-Requested-By": "livy" }, "heartbeat_refresh_seconds": 5, "livy_server_heartbeat_timeout_seconds": 60, "heartbeat_retry_seconds": 1 }Végezze el a következő módosításokat a fájlon:
Sablon értéke Új érték {U Standard kiadás RNAME} Fürt bejelentkezése az alapértelmezett adminbeállítás.{CLUSTERDNSNAME} Fürt neve {BA Standard kiadás 64ENCODEDPASSWORD} Egy base64 kódolású jelszó a tényleges jelszóhoz. A base64-jelszót a következő helyen https://www.url-encode-decode.com/base64-encode-decode/hozhatja létre: . "livy_server_heartbeat_timeout_seconds": 60Ha használja sparkmagic 0.12.7(3.5-ös és 3.6-os fürtök). Ha a (3.4-es verziójú fürtöket) használjasparkmagic 0.2.3, cserélje le a következőre"should_heartbeat": true: .Egy teljes példafájl a minta config.json.
Tipp.
A rendszer szívveréseket küld annak érdekében, hogy a munkamenetek ne szivárogjanak ki. Amikor a számítógép alvó állapotba kerül vagy leáll, a rendszer nem küldi el a szívverést, így a munkamenet törlődik. A 3.4-es fürtök esetében, ha le szeretné tiltani ezt a viselkedést, beállíthatja a Livy-konfigurációt
livy.server.interactive.heartbeat.timeout0az Ambari felhasználói felületén. A 3.5-ös fürtök esetében, ha nem állítja be a fenti 3.5-ös konfigurációt, a munkamenet nem törlődik.Indítsa el a Jupytert. Használja a következő parancsot a parancssorból.
jupyter notebookEllenőrizze, hogy használhatja-e a kernelekkel elérhető Spark-varázslatot. Hajtsa végre a következő lépéseket.
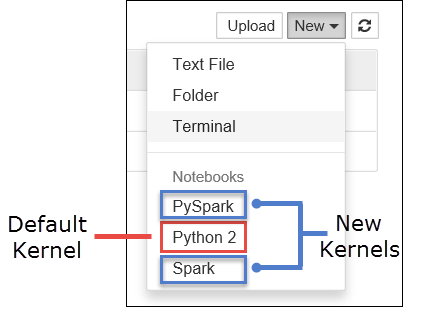
a. Hozzon létre új notebookot. A jobb oldali sarokban válassza az Új lehetőséget. Látnia kell az alapértelmezett Python 2 vagy Python 3 kernelt, valamint a telepített kerneleket. A tényleges értékek a telepítési lehetőségektől függően változhatnak. Válassza a PySpark lehetőséget.
Fontos
Miután kiválasztotta az Új felülvizsgálat lehetőséget, tekintse át a rendszerhéjat az esetleges hibákért. Ha azt a hibát
TypeError: __init__() got an unexpected keyword argument 'io_loop'látja, hogy a Tornado egyes verzióival kapcsolatban ismert problémát tapasztal. Ha igen, állítsa le a kernelt, majd állítsa le a Tornado telepítését a következő paranccsal:pip install tornado==4.5.3.b. Futtassa a következő kódrészletet.
%%sql SELECT * FROM hivesampletable LIMIT 5Ha sikeresen le tudja kérni a kimenetet, teszteli a HDInsight-fürthöz való kapcsolatot.
Ha frissíteni szeretné a jegyzetfüzet konfigurációját egy másik fürthöz való csatlakozáshoz, frissítse a config.json a fenti 3. lépésben látható új értékkészlettel.
Miért érdemes telepíteni a Jupytert a számítógépre?
A Jupyter telepítése a számítógépre, majd csatlakoztatása egy Apache Spark-fürthöz a HDInsighton:
- Lehetővé teszi, hogy helyileg hozza létre a jegyzetfüzeteket, tesztelje az alkalmazást egy futó fürtön, majd töltse fel a jegyzetfüzeteket a fürtbe. A jegyzetfüzetek fürtbe való feltöltéséhez feltöltheti őket a futó Jupyter Notebook vagy a fürt használatával, vagy mentheti őket a
/HdiNotebooksfürthöz társított tárfiók mappájába. További információ a jegyzetfüzetek fürtben való tárolásáról: Hol vannak tárolva a Jupyter Notebookok? - A helyileg elérhető jegyzetfüzetekkel az alkalmazásigénye alapján különböző Spark-fürtökhöz csatlakozhat.
- A GitHub használatával implementálhat egy forrásvezérlő rendszert, és verziókövetéssel rendelkezhet a jegyzetfüzetekhez. Olyan együttműködési környezettel is rendelkezhet, amelyben több felhasználó is használhatja ugyanazt a jegyzetfüzetet.
- A jegyzetfüzeteket helyileg is használhatja anélkül, hogy fürtöt kellene létrehoznia. Csak egy fürtre van szüksége a jegyzetfüzetek teszteléséhez, a jegyzetfüzetek vagy fejlesztési környezetek manuális kezeléséhez nem.
- Egyszerűbb lehet saját helyi fejlesztési környezetet konfigurálni, mint a Jupyter telepítését a fürtön. Kihasználhatja a helyileg telepített összes szoftvert egy vagy több távoli fürt konfigurálása nélkül.
Figyelmeztetés
Ha a Jupyter telepítve van a helyi számítógépen, egyszerre több felhasználó is futtathatja ugyanazt a jegyzetfüzetet ugyanazon a Spark-fürtön. Ilyen esetben több Livy-munkamenet jön létre. Ha problémába ütközik, és azt szeretné hibakeresésre használni, összetett feladat lesz nyomon követni, hogy melyik Livy-munkamenet melyik felhasználóhoz tartozik.