Az Apache Spark strukturált streamelésének áttekintése
Az Apache Spark strukturált streamelés lehetővé teszi, hogy skálázható, nagy átviteli sebességű, hibatűrő alkalmazásokat implementáljon az adatfolyamok feldolgozásához. A strukturált streamelés a Spark SQL-motorra épül, és továbbfejleszti a Spark SQL-adatkeretek és -adathalmazok szerkezetét, így ugyanúgy írhat streamlekérdezéseket, mint a kötegelt lekérdezéseket.
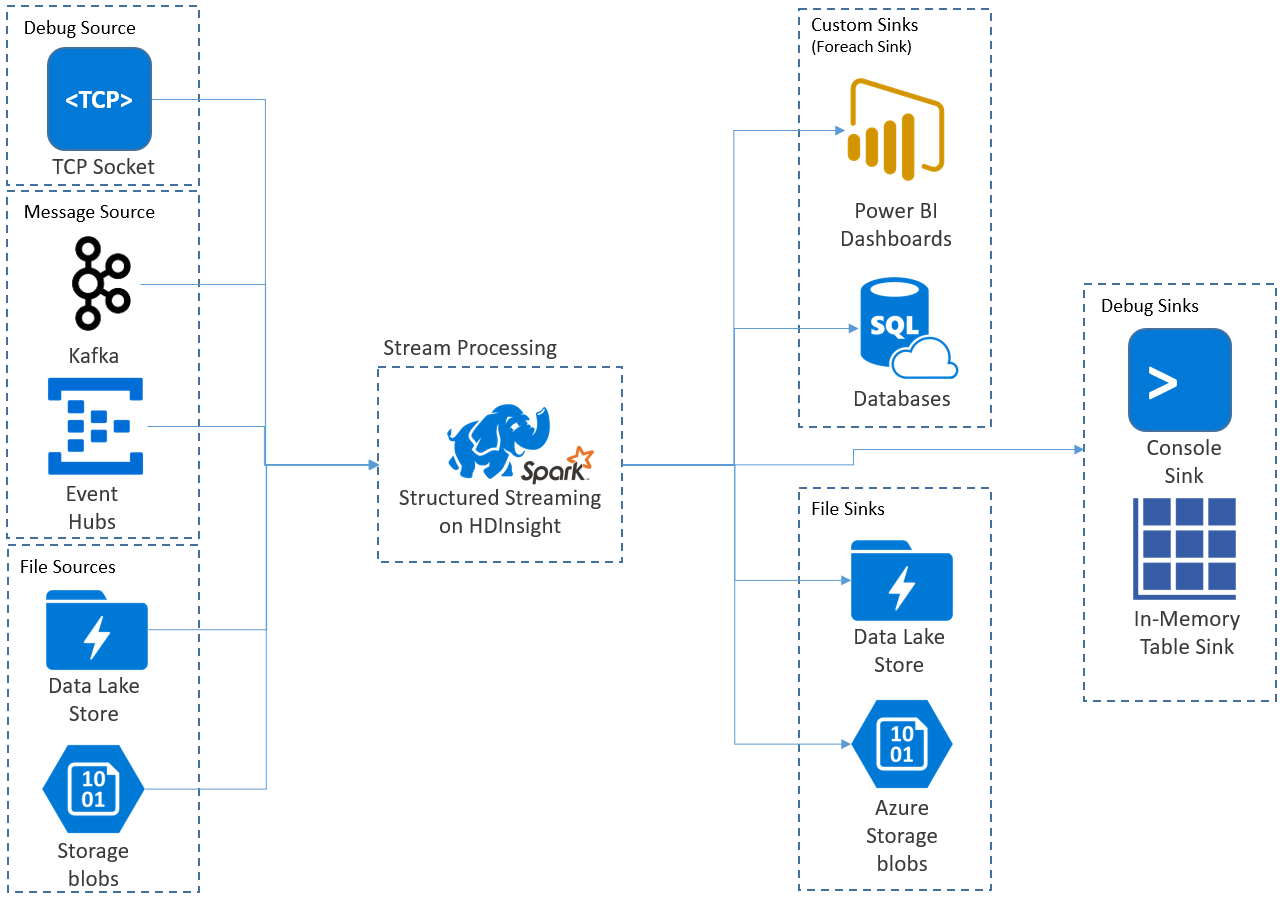
A strukturált streamelési alkalmazások HDInsight Spark-fürtökön futnak, és az Apache Kafkából, egy TCP-szoftvercsatornából (hibakeresési célból), az Azure Storage-ból vagy az Azure Data Lake Storage-ból csatlakoznak a streamelési adatokhoz. Az utóbbi két lehetőség, amely külső tárolási szolgáltatásokra támaszkodik, lehetővé teszi, hogy figyelje a tárba hozzáadott új fájlokat, és úgy dolgozza fel a tartalmát, mintha streamelték volna őket.
A strukturált streamelés egy hosszú ideig futó lekérdezést hoz létre, amely során műveleteket alkalmaz a bemeneti adatokra, például a kiválasztásra, a vetítésre, az összesítésre, az ablakozásra és a streamelési DataFrame-hez való csatlakozásra referencia DataFrame-ekkel. Ezután az eredményeket fájltárolóba (Azure Storage-blobok vagy Data Lake Storage) vagy bármely adattárba egyéni kóddal (például SQL Database vagy Power BI) adja ki. A strukturált streamelés emellett kimenetet biztosít a konzolnak a helyi hibakereséshez, valamint egy memórián belüli táblához, így láthatja a HDInsightban a hibakereséshez létrehozott adatokat.
Feljegyzés
A Spark Strukturált streamelés a Spark Streaming (D adatfolyamok) helyére kerül. A továbbiakban a strukturált streamelés fejlesztéseket és karbantartásokat kap, míg a D adatfolyamok csak karbantartási módban lesz. A strukturált streamelés jelenleg nem olyan funkciószintű, mint a D adatfolyamok az általa támogatott források és fogadók esetében, ezért értékelje ki a követelményeket a Spark-stream megfelelő feldolgozási lehetőségének kiválasztásához.
adatfolyamok táblákként
A Spark Strukturált stream olyan adatstreamet jelöl, amely egy olyan tábla, amely nem kötetlen mélységű, vagyis a tábla folyamatosan növekszik az új adatok érkezésekor. Ezt a bemeneti táblát folyamatosan dolgozza fel egy hosszú ideig futó lekérdezés, és a kimeneti táblába küldött eredmények:

A strukturált streamelés során az adatok meg érkeznek a rendszerbe, és azonnal betöltik egy bemeneti táblába. Lekérdezéseket írhat (a DataFrame és az Adathalmaz API-k használatával), amelyek műveleteket hajtanak végre ezen a bemeneti táblán. A lekérdezés kimenete egy másik táblát, az eredménytáblát eredményez. Az eredménytábla tartalmazza a lekérdezés eredményeit, amelyekből adatokat rajzolhat egy külső adattárhoz, például egy relációs adatbázishoz. A bemeneti tábla adatainak feldolgozásának időzítését az eseményindító időköze vezérli. Alapértelmezés szerint az eseményindító időköze nulla, ezért a strukturált streamelés amint megérkezik, megpróbálja feldolgozni az adatokat. A gyakorlatban ez azt jelenti, hogy amint a strukturált streamelés befejeződött az előző lekérdezés futtatásának feldolgozásával, egy újabb feldolgozást indít el az újonnan kapott adatokon. Az eseményindítót úgy konfigurálhatja, hogy időközönként fusson, így a streamelési adatok feldolgozása időalapú kötegekben történik.
Az eredménytáblákban szereplő adatok csak azokat az adatokat tartalmazhatják, amelyek a lekérdezés legutóbbi feldolgozása óta (hozzáfűzési mód) újak, vagy a tábla minden alkalommal frissíthető, amikor új adatok vannak, így a tábla tartalmazza az összes kimeneti adatot a streamelési lekérdezés kezdete óta (teljes mód).
Hozzáfűzési mód
Hozzáfűzési módban csak a legutóbbi lekérdezésfuttatás óta az eredménytáblához hozzáadott sorok szerepelnek az eredménytáblában, és külső tárolóba vannak írva. A legegyszerűbb lekérdezés például az összes adatot változatlanul másolja a bemeneti táblából az eredménytáblába. Minden alkalommal, amikor egy eseményindító időköze elévült, a rendszer feldolgozza az új adatokat, és az új adatokat képviselő sorok megjelennek az eredménytáblában.
Fontolja meg azt a forgatókönyvet, amelyben hőmérsékletérzékelőkből, például termosztátból származó telemetriát dolgoz fel. Tegyük fel, hogy az első eseményindító 00:01-kor feldolgozott egy eseményt az 1. eszköz esetében 95 fokos hőmérséklet-méréssel. A lekérdezés első eseményindítójában csak a 00:01 időpontú sor jelenik meg az eredménytáblában. Amikor egy másik esemény érkezik, 00:02 időpontban az egyetlen új sor a 00:02 időponttal rendelkező sor, így az eredménytábla csak azt a sort tartalmazza.
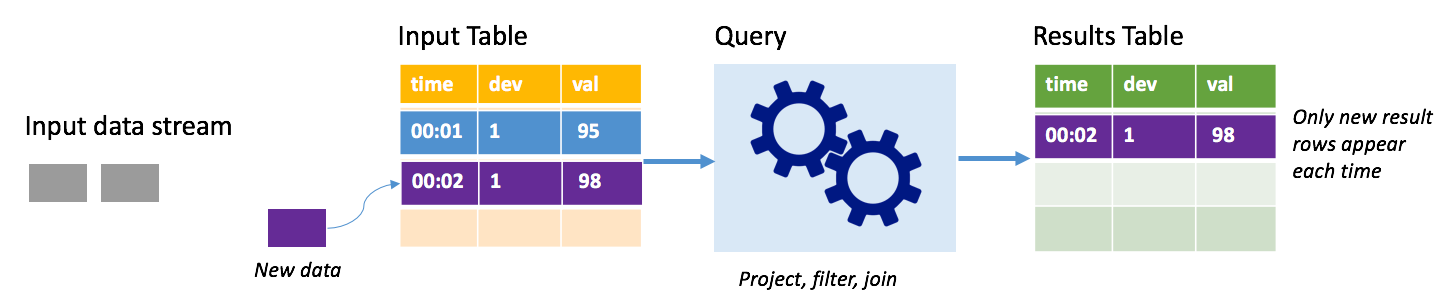
Hozzáfűzési mód használata esetén a lekérdezés kivetítéseket alkalmaz (kiválasztja azokat az oszlopokat, amelyek érdeklik), szűrést (csak bizonyos feltételeknek megfelelő sorokat választ ki), vagy összekapcsolást (az adatokat statikus keresési táblából származó adatokkal bővíti). A hozzáfűzési mód megkönnyíti, hogy csak a releváns új adatok kerülhessenek külső tárolóba.
Kész mód
Vegye figyelembe ugyanezt a forgatókönyvet, ezúttal teljes módban. Teljes módban a rendszer minden eseményindítón frissíti a teljes kimeneti táblát, így a tábla nem csak a legutóbbi eseményindító futtatásából, hanem az összes futtatásból származó adatokat is tartalmazza. Teljes módban másolhatja a bemeneti táblából a módosítás nélküli adatokat az eredménytáblába. Minden aktivált futtatáskor az új eredménysorok az összes korábbi sorral együtt jelennek meg. A kimeneti eredmények táblája a lekérdezés kezdete óta összegyűjtött összes adatot tárolja, és végül elfogy a memória. A teljes mód olyan összesítő lekérdezésekkel használható, amelyek valamilyen módon összegzik a bejövő adatokat, így minden eseményindítón az eredménytábla egy új összegzéssel frissül.
Tegyük fel, hogy eddig öt másodpercnyi adatot már feldolgoztak, és itt az ideje, hogy a hatodik másodpercig feldolgozzuk az adatokat. A bemeneti tábla a 00:01 és a 00:03 időpont eseményeit tartalmazza. A példában szereplő lekérdezés célja, hogy öt másodpercenként adja meg az eszköz átlagos hőmérsékletét. A lekérdezés végrehajtása olyan aggregátumot alkalmaz, amely az egyes 5 másodperces időszakokba eső összes értéket veszi át, átlagítja a hőmérsékletet, és egy sort állít elő az adott intervallum átlaghőmérsékletéhez. Az első 5 másodperces ablak végén két vonás van: (00:01, 1, 95) és (00:03, 1, 98). Tehát az ablak 00:00-00:05 az összesítés egy 96,5 fokos átlaghőmérsékletű rekordot hoz létre. A következő 5 másodperces ablakban csak egy adatpont van 00:06 időpontban, így az eredményként kapott átlaghőmérséklet 98 fok. 00:10-kor a teljes mód használata esetén az eredménytáblában a windows 00:00-00:05 és a 00:05-00:10 ablakok sorai is láthatók, mert a lekérdezés az összes összes összes sort kimeneteli, nem csak az újakat. Ezért az eredmények táblázata folyamatosan növekszik az új ablakok hozzáadásakor.
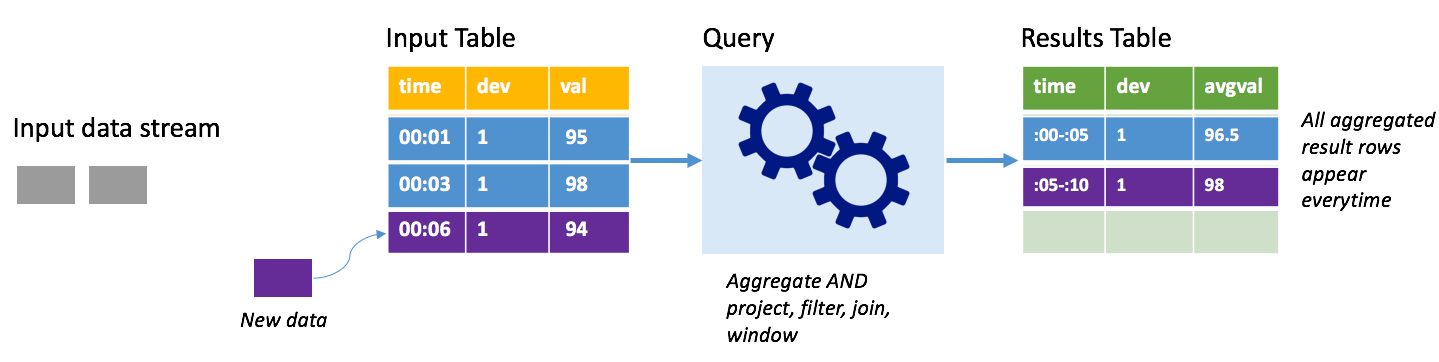
Nem minden teljes módot használó lekérdezés esetén a tábla korlátok nélkül nő. Az előző példában vegye figyelembe, hogy a hőmérséklet időkeret szerinti átlagolása helyett inkább eszközazonosító szerint átlagolt. Az eredménytábla rögzített számú sort (eszközönként egyet) tartalmaz, és az eszköz átlaghőmérséklete az adott eszköztől kapott összes adatponton. Az új hőmérsékletek érkeznek, az eredménytábla frissül, hogy a táblázatban szereplő átlagok mindig aktuálisak legyenek.
Spark strukturált streamelési alkalmazás összetevői
Egy egyszerű példa lekérdezés összegzi a hőmérsékleti értékeket óránkénti ablakok szerint. Ebben az esetben az adatok JSON-fájlokban vannak tárolva az Azure Storage-ban (a HDInsight-fürt alapértelmezett tárolójaként csatolva):
{"time":1469501107,"temp":"95"}
{"time":1469501147,"temp":"95"}
{"time":1469501202,"temp":"95"}
{"time":1469501219,"temp":"95"}
{"time":1469501225,"temp":"95"}
Ezek a JSON-fájlok a temps HDInsight-fürt tárolója alatti almappában vannak tárolva.
A bemeneti forrás meghatározása
Először konfiguráljon egy DataFrame-et, amely leírja az adatok forrását és a forrás által igényelt beállításokat. Ez a példa az Azure Storage JSON-fájljaiból származik, és olvasáskor sémát alkalmaz rájuk.
import org.apache.spark.sql.types._
import org.apache.spark.sql.functions._
//Cluster-local path to the folder containing the JSON files
val inputPath = "/temps/"
//Define the schema of the JSON files as having the "time" of type TimeStamp and the "temp" field of type String
val jsonSchema = new StructType().add("time", TimestampType).add("temp", StringType)
//Create a Streaming DataFrame by calling readStream and configuring it with the schema and path
val streamingInputDF = spark.readStream.schema(jsonSchema).json(inputPath)
A lekérdezés alkalmazása
Ezután alkalmazzon egy lekérdezést, amely a kívánt műveleteket tartalmazza a Stream DataFrame-hez. Ebben az esetben az összesítés az összes sort 1 órás ablakokba csoportosítja, majd kiszámítja az adott 1 órás ablakban a minimális, az átlag és a maximális hőmérsékletet.
val streamingAggDF = streamingInputDF.groupBy(window($"time", "1 hour")).agg(min($"temp"), avg($"temp"), max($"temp"))
A kimeneti fogadó definiálása
Ezután adja meg az eredménytáblához adott sorok célhelyét az egyes triggerintervallumokban. Ez a példa csak az összes sort egy memórián belüli táblába temps adja ki, amelyet később lekérdezhet a SparkSQL-lel. A teljes kimeneti mód biztosítja, hogy az összes ablak összes sora minden alkalommal kimenetként jelenik meg.
val streamingOutDF = streamingAggDF.writeStream.format("memory").queryName("temps").outputMode("complete")
A lekérdezés indítása
Indítsa el a streamelési lekérdezést, és futtassa addig, amíg meg nem kapja a végpontjelet.
val query = streamingOutDF.start()
Az eredmények megtekintése
Amíg a lekérdezés fut, ugyanabban a SparkSession-ben futtathat egy SparkSQL-lekérdezést azon a temps táblán, amelyen a lekérdezés eredményei vannak tárolva.
select * from temps
Ez a lekérdezés az alábbihoz hasonló eredményeket ad vissza:
| Ablak | min(temp) | avg(temp) | max(temp) |
|---|---|---|---|
| {u'start': u'2016-07-26T02:00:00.000Z', u'end'... | 95 | 95.231579 | 99 |
| {u'start': u'2016-07-26T03:00:00.000Z', u'end'... | 95 | 96.023048 | 99 |
| {u'start': u'2016-07-26T04:00:00.000Z', u'end'... | 95 | 96.797133 | 99 |
| {u'start': u'2016-07-26T05:00:00.000Z', u'end'... | 95 | 96.984639 | 99 |
| {u'start': u'2016-07-26T06:00:00.000Z', u'end'... | 95 | 97.014749 | 99 |
| {u'start': u'2016-07-26T07:00:00.000Z', u'end'... | 95 | 96.980971 | 99 |
| {u'start': u'2016-07-26T08:00:00.000Z', u'end'... | 95 | 96.965997 | 99 |
A Spark Strukturált Stream API-val, valamint az általa támogatott bemeneti adatforrásokkal, műveletekkel és kimeneti fogadókkal kapcsolatos részletekért tekintse meg az Apache Spark strukturált streamelési programozási útmutatóját.
Ellenőrzőpontok és előre írt naplók
A rugalmasság és a hibatűrés biztosítása érdekében a strukturált streamelés ellenőrzőpontokra támaszkodik, hogy a streamfeldolgozás a csomóponthibák esetén is zavartalanul folytatódhasson. A HDInsightban a Spark ellenőrzőpontokat hoz létre a tartós tároláshoz, az Azure Storage-hoz vagy a Data Lake Storage-hoz. Ezek az ellenőrzőpontok tárolják a streamelési lekérdezés állapotadatait. A strukturált streamelés emellett írási naplót (WAL) is használ. A WAL rögzíti a lekérdezés által fogadott, de még nem feldolgozott betöltési adatokat. Ha hiba történik, és a feldolgozás újraindul a WAL-ból, a forrástól kapott események nem vesznek el.
Spark Streaming-alkalmazások üzembe helyezése
Általában helyileg hoz létre egy Spark Streaming-alkalmazást egy JAR-fájlba, majd a HDInsight-alapú Sparkban helyezi üzembe a JAR-fájlt a HDInsight-fürthöz csatolt alapértelmezett tárolóba másolva. Az alkalmazást post művelettel indíthatja el a fürtből elérhető Apache Livy REST API-kkal. A POST törzse tartalmaz egy JSON-dokumentumot, amely megadja a JAR elérési útját, annak az osztálynak a nevét, amelynek fő metódusa meghatározza és futtatja a streamelési alkalmazást, valamint opcionálisan a feladat erőforrás-követelményeit (például a végrehajtók számát, a memóriát és a magokat), valamint az alkalmazáskód által igényelt konfigurációs beállításokat.
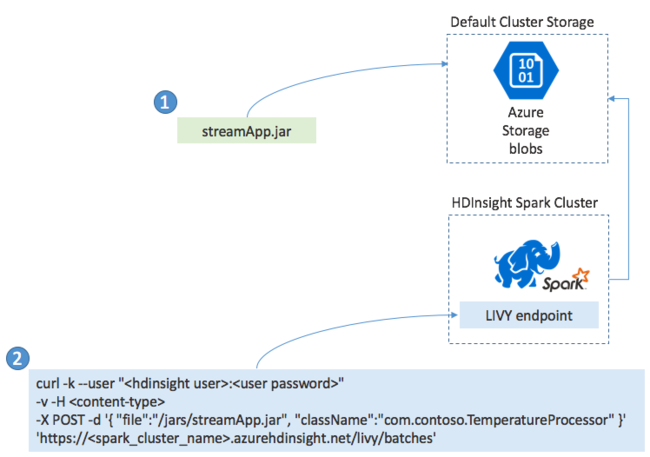
Az összes alkalmazás állapota egy GET kéréssel is ellenőrizhető egy LIVY-végponton. Végül leállíthat egy futó alkalmazást egy DELETE-kérés a LIVY-végponton való kiadásával. A LIVY API részleteiért lásd : Távoli feladatok az Apache LIVY-vel