Betanítási adatok importálása a Machine Learning Studióba (klasszikus) különböző adatforrásokból
HATÓKÖR: A Machine Learning Studio (klasszikus)
A Machine Learning Studio (klasszikus)  Azure Machine Learning
Azure Machine Learning
Fontos
A (klasszikus) Machine Learning Studio támogatása 2024. augusztus 31-én megszűnik. Javasoljuk, hogy addig térjen át az Azure Machine Learning használatára.
2021. december 1-től kezdve nem fog tudni létrehozni új (klasszikus) Machine Learning Studio-erőforrásokat. 2024. augusztus 31-ig továbbra is használhatja a meglévő (klasszikus) Machine Learning Studio-erőforrásokat.
- További információ a gépi tanulási projektek ML Studióból (klasszikus) Azure Machine Learningbe való áthelyezéséről.
- További információ az Azure Machine Learningről
A (klasszikus) ML Studio dokumentációjának kivezetése folyamatban van, és a jövőben nem várható a frissítése.
Ha saját adatokat szeretne használni a Machine Learning Studióban (klasszikus) egy prediktív elemzési megoldás fejlesztéséhez és betanításahoz, a következő adatokból használhatja fel az alábbiakat:
- Helyi fájl – Helyi adatok előre betöltése a merevlemezről adathalmaz-modul létrehozásához a munkaterületen
- Online adatforrások – Az Adatok importálása modullal több online forrásból származó adatokat érhet el a kísérlet futtatása közben
- Machine Learning Studio (klasszikus) kísérlet – Adathalmazként mentett adatok használata a Machine Learning Studióban (klasszikus)
- SQL Server-adatbázis – Adatok manuális másolása nélkül SQL Server adatbázisból származó adatok használata
Megjegyzés
A Machine Learning Studióban (klasszikus) számos mintaadatkészlet érhető el, amelyeket felhasználhat a betanítási adatokhoz. Ezekről további információt a Machine Learning Studio (klasszikus) mintaadatkészleteinek használata című témakörben talál.
Adatok előkészítése
A Machine Learning Studio (klasszikus) úgy lett kialakítva, hogy téglalap alakú vagy táblázatos adatokkal, például egy adatbázisból tagolt vagy strukturált szöveges adatokkal működjön, bár bizonyos körülmények között nem téglalap alakú adatok is használhatók.
A legjobb, ha az adatok viszonylag tiszták, mielőtt importálja őket a Studióba (klasszikus). Érdemes lehet például olyan problémákat is elhárítani, mint a nem idézőjeles sztringek.
A (klasszikus) Studióban azonban vannak olyan modulok, amelyek az adatok importálása után lehetővé teszik az adatok kezelését a kísérletben. A használni kívánt gépi tanulási algoritmusoktól függően előfordulhat, hogy el kell döntenie, hogyan fogja kezelni az olyan adatszerkezeti problémákat, mint a hiányzó értékek és a ritka adatok, és vannak olyan modulok, amelyek segíthetnek ebben. A modulkatalógus Adatátalakítás szakaszában keresse meg azokat a modulokat, amelyek ezeket a függvényeket hajtják végre.
A kísérlet bármely pontján megtekintheti vagy letöltheti a modul által előállított adatokat a kimeneti portra kattintva. A modultól függően különböző letöltési lehetőségek érhetők el, vagy megjelenítheti az adatokat a webböngészőben a Studióban (klasszikus).
Támogatott adatformátumok és adattípusok
Számos adattípust importálhat a kísérletbe attól függően, hogy milyen mechanizmussal importál adatokat, és honnan származnak:
- Egyszerű szöveg (.txt)
- Vesszővel tagolt értékek (CSV) fejléccel (.csv) vagy (.nh.csv) nélkül
- Tabulátorral tagolt értékek (TSV) fejléccel (.tsv) vagy (.nh.tsv) nélkül
- Excel-fájl
- Azure-tábla
- Hive-tábla
- SQL-adatbázistábla
- OData-értékek
- SVMLight-adatok (.svmlight) (formátuminformációkért lásd az SVMLight definícióját )
- Attribútumrelációs fájlformátum (ARFF) adatai (.arff) (formátuminformációkért lásd az ARFF definícióját )
- Zip-fájl (.zip)
- R-objektum- vagy munkaterületfájl (. RData)
Ha metaadatokat tartalmazó formátumban importál adatokat, például ARFF formátumban, a Studio (klasszikus) ezeket a metaadatokat használja az egyes oszlopok fejlécének és adattípusának meghatározásához.
Ha olyan adatokat importál, mint a TSV vagy a CSV formátum, amely nem tartalmazza ezeket a metaadatokat, a Studio (klasszikus) az adatok mintavételezésével minden oszlop adattípusát kikövetkessze. Ha az adatok nem rendelkeznek oszlopfejlécekkel, a Studio (klasszikus) alapértelmezett neveket ad meg.
A Metaadatok szerkesztése modullal explicit módon megadhatja vagy módosíthatja az oszlopok fejléceit és adattípusait.
A Studio a következő adattípusokat ismeri fel (klasszikus):
- Sztring
- Egész szám
- Dupla
- Logikai érték
- DateTime
- időtartam
A Studio egy adattábla nevű belső adattípust használ az adatok modulok közötti átadásához. Az adatokat explicit módon adattábla-formátumba konvertálhatja a Konvertálás adathalmazsá modullal.
Az adattáblától eltérő formátumokat elfogadó modulok csendesen átalakítják az adatokat adattáblává, mielőtt átadják azokat a következő modulnak.
Ha szükséges, átalakíthatja az adattábla formátumát CSV, TSV, ARFF vagy SVMLight formátumba más konvertálási modulok használatával. A modulkatalógus Adatformátum-átalakítások szakaszában keresse meg azokat a modulokat, amelyek ezeket a függvényeket hajtják végre.
Adatkapacitások
A Machine Learning Studio (klasszikus) moduljai akár 10 GB sűrű numerikus adathalmazt is támogatnak a gyakori használati esetekhez. Ha egy modul egynél több bemenetből fogad adatokat, a bemenet összesített mérete nem haladhatja meg a 10 GB-ot. Nagyobb adathalmazok mintáit a Hive-ból vagy Azure SQL Database-ből származó lekérdezésekkel, vagy az adatok importálása előtt használhatja a Learning by Counts előfeldolgozást.
A szolgáltatásnormalizálás során a következő, 10 GB alá korlátozott adattípusok bővíthetők nagyobb adatkészletekké:
- Ritka
- Kategorikus
- Sztringek
- Bináris adatok
A következő modulok 10 GB-nál kisebb adatkészletekre vannak korlátozva:
- Ajánló modulok
- SMOTE (Synthetic Minority Oversampling Technique) modul
- Parancsfájlkezelési modulok: R, Python, SQL
- Olyan modulok, amelyeknél a kimeneti adatok mérete meghaladhatja a bemeneti adatok méretét; például az egyesítés vagy a szolgáltatáskivonatolás
- Kereszt-ellenőrzés, modell-hiperparaméterek beállítása, sorszámregresszió és multi-osztályú osztályozás nagyszámú ismétlés esetében
Néhány GB-nál nagyobb adathalmazok esetén töltse fel az adatokat az Azure Storage-ba vagy Azure SQL Database-be, vagy használja az Azure HDInsightot ahelyett, hogy közvetlenül egy helyi fájlból töltené fel az adatokat.
A képadatokkal kapcsolatos információkat a Képek importálása modul referenciájában találja.
Importálás helyi fájlból
Feltölthet egy adatfájlt a merevlemezről, hogy betanítási adatokként használhassa a Studióban (klasszikus). Adatfájl importálásakor létrehoz egy adathalmazmodult, amely készen áll a munkaterületen végzett kísérletekben való használatra.
Ha helyi merevlemezről szeretne adatokat importálni, tegye a következőket:
- Kattintson a +ÚJ gombra a Studio (klasszikus) ablak alján.
- Válassza az ADATKÉSZLET és a HELYI FÁJL LEHETŐSÉGET.
- Az Új adathalmaz feltöltése párbeszédpanelen tallózással keresse meg a feltölteni kívánt fájlt.
- Adjon meg egy nevet, azonosítsa az adattípust, és szükség esetén adjon meg egy leírást. A leírás ajánlott – lehetővé teszi az adatok azon jellemzőinek rögzítését, amelyekre emlékezni szeretne az adatok későbbi használatakor.
- Az Ez egy meglévő adatkészlet új verziója jelölőnégyzet lehetővé teszi, hogy egy meglévő adathalmazt új adatokkal frissítsen. Ehhez jelölje be ezt a jelölőnégyzetet, és adja meg egy meglévő adathalmaz nevét.
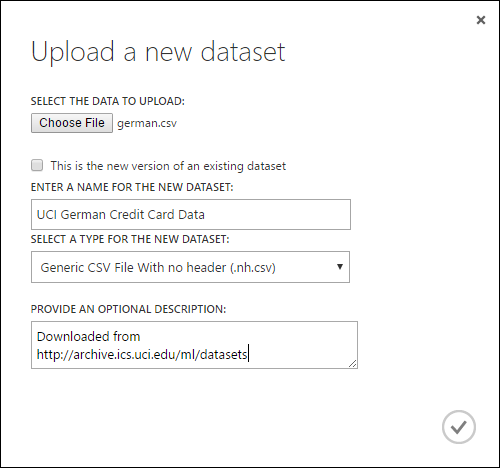
A feltöltési idő az adatok méretétől és a szolgáltatáshoz való kapcsolódás sebességétől függ. Ha tudja, hogy a fájl hosszú ideig fog tartani, a várakozás közben más műveleteket is elvégezhet a Studióban (klasszikus). Ha azonban az adatfeltöltés befejezése előtt bezárja a böngészőt, a feltöltés sikertelen lesz.
Az adatok feltöltése után az adatok egy adathalmazmodulban lesznek tárolva, és a munkaterület bármely kísérlete számára elérhetők.
Amikor egy kísérletet szerkeszt, a modulpaletta Mentett adathalmazok listájában található Saját adathalmazok listában találja a feltöltött adathalmazokat. Az adathalmazt áthúzhatja a kísérletvászonra, ha az adathalmazt további elemzéshez és gépi tanuláshoz szeretné használni.
Importálás online adatforrásokból
Az Adatok importálása modul használatával a kísérlet a kísérlet futása közben különböző online adatforrásokból tud adatokat importálni.
Megjegyzés
Ez a cikk általános információkat tartalmaz az Adatok importálása modulról. Az elérhető adattípusokról, a formátumokról, a paraméterekről és a gyakori kérdésekre adott válaszokról az Adatok importálása modul referenciatémakörében talál részletesebb tájékoztatást.
Az Adatok importálása modullal számos online adatforrás egyikéből érheti el az adatokat, miközben a kísérlet fut:
- Webes URL-cím HTTP használatával
- Hadoop a HiveQL használatával
- Azure Blob Storage
- Azure-tábla
- Azure SQL Database. SQL Managed Instance vagy SQL Server
- Jelenleg egy adatcsatorna-szolgáltató, az OData
- Azure Cosmos DB
Mivel ezek a betanítási adatok a kísérlet futása közben érhetők el, csak abban a kísérletben érhetők el. Ehhez képest az adathalmaz-modulban tárolt adatok a munkaterület bármely kísérletéhez elérhetők.
Ha online adatforrásokat szeretne elérni a Studio (klasszikus) kísérletében, adja hozzá az Adatok importálása modult a kísérlethez. Ezután válassza az Adatok importálása varázsló indítása lehetőséget a Tulajdonságok területen az adatforrás kiválasztásához és konfigurálásához szükséges részletes útmutatókhoz. Másik lehetőségként manuálisan is kiválaszthatja az adatforrást a Tulajdonságok területen, és megadhatja az adatok eléréséhez szükséges paramétereket.
A támogatott online adatforrások az alábbi táblázatban találhatók. Ez a táblázat a támogatott fájlformátumokat és az adatok eléréséhez használt paramétereket is összefoglalja.
Fontos
Az Adatok importálása és az Adatok exportálása modul jelenleg csak a klasszikus üzemi modellel létrehozott Azure Storage-ból tud adatokat olvasni és írni. Más szóval az új Azure Blob Storage fióktípus, amely gyakori elérésű vagy ritka elérésű tárolási hozzáférési szintet kínál, még nem támogatott.
Általában azokat az Azure Storage-fiókokat, amelyeket a szolgáltatás elérhetővé válása előtt hozott létre, nem érinti. Ha új fiókot kell létrehoznia, válassza a Klasszikus lehetőséget az üzembe helyezési modellhez, vagy használja a Resource Managert, és válassza az Általános célt a Blob Storage helyett fióktípusként.
További információ: Azure Blob Storage: Gyakori elérésű és ritka elérésű tárolási szintek.
Támogatott online adatforrások
A Machine Learning Studio (klasszikus) Adatimportálás modulja a következő adatforrásokat támogatja:
| Adatforrás | Description | Paraméterek |
|---|---|---|
| Webes URL-cím HTTP-en keresztül | Vesszővel tagolt értékek (CSV), tabulátorral tagolt értékek (TSV), attribútum-relációs fájlformátum (ARFF) és support vector machines (SVM-light) formátumban olvas be adatokat bármely HTTP-t használó webes URL-címről | URL-cím: Megadja a fájl teljes nevét, beleértve a webhely URL-címét és a fájlnevet bármilyen kiterjesztéssel. Adatformátum: A támogatott adatformátumok egyikét adja meg: CSV, TSV, ARFF vagy SVM-light. Ha az adatok fejlécsort tartalmaznak, oszlopnevek hozzárendelésére szolgálnak. |
| Hadoop/HDFS | Adatokat olvas be a Hadoop elosztott tárolójából. A kívánt adatokat egy SQL-szerű lekérdezési nyelv, a HiveQL használatával adhatja meg. A HiveQL az adatok összesítésére és adatszűrésre is használható, mielőtt hozzáadja az adatokat a Studióhoz (klasszikus). | Hive-adatbázis lekérdezése: Az adatok létrehozásához használt Hive-lekérdezést adja meg. HCatalog-kiszolgáló URI-ja : A fürt nevét a fürtnév.azurehdinsight.net> formátumban< adta meg. Hadoop-felhasználói fiók neve: A fürt kiépítéséhez használt Hadoop-felhasználói fiók nevét adja meg. Hadoop felhasználói fiók jelszava : A fürt kiépítésekor használt hitelesítő adatokat adja meg. További információ: Hadoop-fürtök létrehozása a HDInsightban. Kimeneti adatok helye: Meghatározza, hogy az adatok Hadoop elosztott fájlrendszerben (HDFS) vagy az Azure-ban legyenek tárolva.
Ha a kimeneti adatokat az Azure-ban tárolja, meg kell adnia az Azure Storage-fiók nevét, a Storage hozzáférési kulcsát és a Storage-tároló nevét. |
| SQL-adatbázis | Beolvassa a Azure SQL Database-ben, SQL Managed Instance vagy egy Azure-beli virtuális gépen futó SQL Server-adatbázisban tárolt adatokat. | Adatbázis-kiszolgáló neve: Annak a kiszolgálónak a nevét adja meg, amelyen az adatbázis fut.
Azure-beli virtuális gépen üzemeltetett SQL-kiszolgáló esetén adja meg a tcp:<virtuális gép DNS-nevét>, 1433 Adatbázis neve : A kiszolgálón lévő adatbázis nevét adja meg. Kiszolgálói felhasználói fiók neve: Olyan fiók felhasználónevet ad meg, amely hozzáférési engedélyekkel rendelkezik az adatbázishoz. Kiszolgálói felhasználói fiók jelszava: Megadja a felhasználói fiók jelszavát. Adatbázis-lekérdezés:Adjon meg egy SQL-utasítást, amely leírja az olvasni kívánt adatokat. |
| Helyszíni SQL-adatbázis | Egy SQL-adatbázisban tárolt adatokat olvas be. | Adatátjáró: A adatkezelés-átjáró nevét adja meg, amely olyan számítógépre van telepítve, amelyen hozzáférhet a SQL Server-adatbázishoz. Az átjáró beállításával kapcsolatos információkért lásd: Speciális elemzések végrehajtása a Machine Learning Studióval (klasszikus) SQL-kiszolgáló adataival. Adatbázis-kiszolgáló neve: Annak a kiszolgálónak a nevét adja meg, amelyen az adatbázis fut. Adatbázis neve : A kiszolgálón lévő adatbázis nevét adja meg. Kiszolgálói felhasználói fiók neve: Olyan fiók felhasználónevet ad meg, amely hozzáférési engedélyekkel rendelkezik az adatbázishoz. Felhasználónév és jelszó: Kattintson az Értékek megadása gombra az adatbázis hitelesítő adatainak megadásához. A windowsos integrált hitelesítést vagy SQL Server-hitelesítést a SQL Server konfigurálásának módjától függően használhatja. Adatbázis-lekérdezés:Adjon meg egy SQL-utasítást, amely leírja az olvasni kívánt adatokat. |
| Azure-tábla | Adatokat olvas be a Table service-ből az Azure Storage-ban. Ha ritkán olvas nagy mennyiségű adatot, használja az Azure Table Service-t. Rugalmas, nem relációs (NoSQL), nagymértékben méretezhető, olcsó és magas rendelkezésre állású tárolási megoldást biztosít. |
Az Adatok importálása lehetőség attól függően változik, hogy nyilvános adatokhoz vagy bejelentkezési hitelesítő adatokat igénylő privát tárfiókhoz fér hozzá. Ezt a hitelesítési típus határozza meg, amelynek értéke "PublicOrSAS" vagy "Account", amelyek mindegyike saját paraméterekkel rendelkezik. Nyilvános vagy közös hozzáférésű jogosultságkód (SAS) URI: A paraméterek a következők:
Megadja a tulajdonságnevek kereséséhez szükséges sorokat: Az értékek TopN értékűek a megadott számú sor vizsgálatához, a ScanAll pedig a tábla összes sorának lekéréséhez. Ha az adatok homogének és kiszámíthatók, javasoljuk, hogy válassza a TopN lehetőséget, és adjon meg egy számot az N értékhez. Nagy táblák esetén ez gyorsabb olvasási időt eredményezhet. Ha az adatok a táblázat mélységétől és pozíciójától függően változó tulajdonságok készleteivel vannak strukturálva, a ScanAll beállítással az összes sort beolvashatja. Ez biztosítja az eredményként kapott tulajdonság és metaadatok átalakításának integritását.
Fiókkulcs: A fiókhoz társított tárkulcsot adja meg. Tábla neve : Annak a táblának a nevét adja meg, amely az olvasandó adatokat tartalmazza. A tulajdonságnevek keresésére szolgáló sorok: Az értékek TopN értékűek a megadott számú sor vizsgálatához, a ScanAll pedig a tábla összes sorának lekéréséhez. Ha az adatok homogének és kiszámíthatók, javasoljuk, hogy válassza a TopN lehetőséget, és adjon meg egy számot az N számára. Nagy táblák esetén ez gyorsabb olvasási időt eredményezhet. Ha az adatok a táblázat mélységétől és pozíciójától függően változó tulajdonságok készleteivel vannak strukturálva, a ScanAll beállítással az összes sort beolvashatja. Ez biztosítja az eredményként kapott tulajdonság és metaadatok átalakításának integritását. |
| Azure Blob Storage | Beolvassa az Azure Storage Blob szolgáltatásában tárolt adatokat, beleértve a képeket, a strukturálatlan szöveget vagy a bináris adatokat. A Blob szolgáltatással nyilvánosan közzéteheti az adatokat, vagy privát módon tárolhatja az alkalmazásadatokat. Az adatokat http- vagy HTTPS-kapcsolatokkal bárhonnan elérheti. |
Az Adatok importálása modul beállításai attól függően változnak, hogy nyilvános adatokhoz vagy bejelentkezési hitelesítő adatokat igénylő privát tárfiókhoz fér hozzá. Ezt a hitelesítési típus határozza meg, amelynek értéke lehet "PublicOrSAS" vagy "Account". Nyilvános vagy közös hozzáférésű jogosultságkód (SAS) URI: A paraméterek a következők:
Fájlformátum: A Blob szolgáltatásban lévő adatok formátumát adja meg. A támogatott formátumok a CSV, a TSV és az ARFF.
Fiókkulcs: A fiókhoz társított tárkulcsot adja meg. Tároló, könyvtár vagy blob elérési útja : Az elolvasni kívánt adatokat tartalmazó blob nevét adja meg. Blobfájl formátuma: A blobszolgáltatásban lévő adatok formátumát adja meg. A támogatott adatformátumok a KÖVETKEZŐK: CSV, TSV, ARFF, MEGADOTT kódolású CSV és Excel.
Az Excel beállítással adatokat olvashat excel-munkafüzetekből. Az Excel adatformátum beállításában adja meg, hogy az adatok excel munkalaptartományban vagy Excel-táblázatban adhatók-e meg. Az Excel-munkalap vagy a beágyazott táblázat beállításban adja meg annak a lapnak vagy táblázatnak a nevét, amelyből olvasni szeretne. |
| Adatcsatorna-szolgáltató | Adatokat olvas be egy támogatott hírcsatorna-szolgáltatótól. Jelenleg csak az Open Data Protocol (OData) formátum támogatott. | Adattartalom típusa: Az OData formátumot adja meg. Forrás URL-címe: Az adatcsatorna teljes URL-címét adja meg. A következő URL-cím például a Northwind mintaadatbázisból olvas be: https://services.odata.org/northwind/northwind.svc/ |
Importálás másik kísérletből
Előfordulhat, hogy egy kísérlet köztes eredményét szeretné felhasználni egy másik kísérlet részeként. Ehhez a modult adatkészletként kell mentenie:
- Kattintson annak a modulnak a kimenetére, amelyet adathalmazként szeretne menteni.
- Kattintson a Mentés adathalmazként gombra.
- Amikor a rendszer kéri, adjon meg egy nevet és egy leírást, amely lehetővé teszi az adathalmaz egyszerű azonosítását.
- Kattintson az OK pipára .
Amikor a mentés befejeződött, az adatkészlet a munkaterület bármely kísérletében használható lesz. A modulkatalógus Mentett adathalmazok listájában található.