1. oktatóanyag: Hitelkockázat előrejelzése – Machine Learning Studio (klasszikus)
HATÓKÖR: Machine Learning Studio (klasszikus)
Machine Learning Studio (klasszikus)  Azure Machine Learning
Azure Machine Learning
Fontos
A (klasszikus) Machine Learning Studio támogatása 2024. augusztus 31-én megszűnik. Javasoljuk, hogy addig térjen át az Azure Machine Learning használatára.
2021. december 1-től kezdve nem fog tudni létrehozni új (klasszikus) Machine Learning Studio-erőforrásokat. 2024. augusztus 31-ig továbbra is használhatja a meglévő (klasszikus) Machine Learning Studio-erőforrásokat.
- További információ a gépi tanulási projektek ML Studióból (klasszikus) Azure Machine Learningbe való áthelyezéséről.
- További információ az Azure Machine Learningről
A (klasszikus) ML Studio dokumentációjának kivezetése folyamatban van, és a jövőben nem várható a frissítése.
Ebben az oktatóanyagban egy prediktív elemzési megoldás fejlesztésének folyamatát tekintheti át. Egy egyszerű modellt fejleszthet a Machine Learning Studióban (klasszikus). Ezután gépi tanulási webszolgáltatásként helyezi üzembe a modellt. Ez az üzembe helyezett modell új adatokkal tud előrejelzéseket készíteni. Ez az oktatóanyag egy háromrészes oktatóanyag-sorozat első része.
Tegyük fel, hogy előrejelzést kell készíteni egy személy hitelkockázatáról az általa kitöltött hitelkérelemben megadott adatok alapján.
A hitelkockázat-értékelés összetett probléma, de ez az oktatóanyag egy kicsit leegyszerűsíti. Példaként fogjuk használni arra, hogyan hozhat létre prediktív elemzési megoldást a Machine Learning Studio (klasszikus) használatával. Ehhez a megoldáshoz a (klasszikus) aMachine Learning Studiót és egy Machine Learning-webszolgáltatást fog használni.
Ebben a háromrészes oktatóanyagban nyilvánosan elérhető hitelkockázati adatokkal fog kezdeni. Ezután egy prediktív modellt fejleszthet és taníthat be. Végül üzembe helyezi a modellt webszolgáltatásként.
Az oktatóanyag ezen részében a következőket fogja elhozni:
- Machine Learning Studio -munkaterület létrehozása (klasszikus)
- Meglévő adatok feltöltése
- Kísérlet létrehozása
Ezt a kísérletet használhatja a modellek betanítása 2. részében , majd üzembe helyezheti őket a 3. részben.
Előfeltételek
Ez az oktatóanyag feltételezi, hogy legalább egyszer már használta a (klasszikus) Machine Learning Studiót, és rendelkezik a gépi tanulási fogalmak ismeretével. Az útmutató azonban nem feltételezi, hogy a fent említett területeken szakértő lenne.
Ha még soha nem használta a Machine Learning Studiót (klasszikus), érdemes lehet a rövid útmutatóval kezdeni, amely az első adatelemzési kísérlet létrehozása a Machine Learning Studióban (klasszikus). A rövid útmutató első alkalommal nyitja meg a (klasszikus) Machine Learning Studiót. Bemutatja az alapokat, azt, hogy hogyan húzhat be modulokat a kísérletbe és kapcsolhatja össze azokat, és hogyan futtathatja a kísérletet és tekintheti meg az eredményeket.
Tipp
Az oktatóanyagban kifejlesztett kísérlet működő másolatát az Azure AI-galériában találja. Lépjen az Oktatóanyag – Hitelkockázat előrejelzése elemre, és kattintson a Megnyitás a Studióban elemre a kísérlet másolatának letöltéséhez a Machine Learning Studio (klasszikus) munkaterületére.
Machine Learning Studio -munkaterület létrehozása (klasszikus)
A Machine Learning Studio (klasszikus) használatához (klasszikus) Machine Learning Studio-munkaterülettel kell rendelkeznie. Ez a munkaterület tartalmazza a kísérletek létrehozásához, kezeléséhez és közzétételéhez szükséges eszközöket.
Munkaterület létrehozásához tekintse meg a Machine Learning Studio (klasszikus) munkaterületének létrehozását és megosztását.
A munkaterület létrehozása után nyissa meg a Machine Learning Studiót (klasszikus) (https://studio.azureml.net/Home). Ha több munkaterülete van, kiválaszthatja a munkaterületet az ablak jobb felső sarkában található eszköztáron.
Tipp
Ha Ön a munkaterület tulajdonosa, megoszthatja azokat a kísérleteket, amelyeken dolgozik, ha meghív másokat a munkaterületre. Ezt a Machine Learning Studio (klasszikus) GÉPI BEÁLLÍTÁSOK lapján teheti meg. Csak a Microsoft-fiókra vagy a szervezeti fiókra van szüksége minden felhasználóhoz.
A BEÁLLÍTÁSOK lapon kattintson a FELHASZNÁLÓK elemre, majd az ablak alján kattintson a TOVÁBBI FELHASZNÁLÓK MEGHÍVÁSA elemre.
Meglévő adatok feltöltése
A hitelkockázat prediktív modelljének fejlesztéséhez olyan adatokra van szüksége, amelyeket felhasználhat a modell betanítása és tesztelése céljából. Ebben az oktatóanyagban az UC Irvine Machine Learning-adattár "UCI Statlog (német kreditadatok) adatkészletét" fogja használni. Itt találhatja meg:
https://archive.ics.uci.edu/ml/datasets/Statlog+(German+Credit+Data)
A german.data nevű fájlt fogja használni. Töltse le ezt a fájlt a helyi merevlemezre.
A german.data adatkészlet 20 változó sorát tartalmazza 1000 korábbi hitelkéredő esetében. Ez a 20 változó az adathalmaz jellemzőinek halmazát (a jellemzővektort) jelöli, amely azonosítja az egyes hiteligénylők jellemzőit. Minden sorban egy további oszlop jelöli a kérelmező kiszámított hitelkockázatát, 700 kérelmezőt alacsony hitelkockázatként, 300-at pedig magas kockázatként azonosítottak.
Az UCI weboldala az adatok jellemzővektorának attribútumait ismerteti. Az adatok közé tartoznak a pénzügyi adatok, a hitelelőzmények, a foglalkoztatási állapot és a személyes adatok. Minden kérelmező esetében bináris minősítést adtak, amely jelzi, hogy alacsony vagy magas hitelkockázatról van-e szó.
Ezeket az adatokat egy prediktív elemzési modell betanítása során fogja használni. Amikor elkészült, a modellnek képesnek kell lennie elfogadni egy új személy jellemzővektorát, és előre jeleznie kell, hogy alacsony vagy magas hitelkockázatról van-e szó.
Íme egy érdekes csavar.
Az UCI webhelyén található adathalmaz leírása megemlíti, hogy mennyibe kerül, ha egy személy hitelkockázatát tévesen sorolja be. Ha a modell magas hitelkockázatot jelez előre egy olyan személy számára, aki valójában alacsony hitelkockázatot jelent, a modell téves besorolást hajtott végre.
A fordított besorolás azonban ötször nagyobb költséggel jár a pénzügyi intézmény számára: ha a modell alacsony hitelkockázatot jelez előre egy olyan személy számára, aki valóban magas hitelkockázatot jelent.
Ezért érdemes betanítani a modellt, hogy az utóbbi típusú téves besorolás költsége ötször magasabb legyen, mint a másik besorolás.
Ennek egyik egyszerű módja, ha a modell betanítása során a kísérletben megkettőzi (ötször) azokat a bejegyzéseket, amelyek magas hitelkockázattal rendelkező személyeket jelölnek.
Ezután, ha a modell tévesen sorol be valakit alacsony hitelkockázatként, amikor valójában magas kockázattal jár, a modell ugyanezt a téves besorolást ötször végzi el, egyszer minden ismétlődésnél. Ez növeli a hiba költségét a betanítási eredményekben.
Az adathalmaz formátumának konvertálása
Az eredeti adatkészlet üresen elválasztott formátumot használ. A Machine Learning Studio (klasszikus) jobban működik egy vesszővel tagolt (CSV) fájllal, így az adathalmazt a szóközök vesszővel való helyettesítésével konvertálhatja.
Ezeket az adatokat többféleképpen is konvertálhatja. Ennek egyik módja az alábbi Windows PowerShell parancs használata:
cat german.data | %{$_ -replace " ",","} | sc german.csv
Másik lehetőségként használja a Unix sed parancsot:
sed 's/ /,/g' german.data > german.csv
Mindkét esetben az adatok vesszővel tagolt verzióját hozta létre egy german.csv nevű fájlban, amelyet felhasználhat a kísérletben.
Az adatkészlet feltöltése a Machine Learning Studióba (klasszikus)
Miután az adatok CSV formátumra lettek konvertálva, fel kell töltenie őket a Machine Learning Studióba (klasszikus).
Nyissa meg a Machine Learning Studio (klasszikus) kezdőlapját (https://studio.azureml.net).
Kattintson a
 Az ablak bal felső sarkában kattintson az Azure Machine Learning elemre, válassza a Studio lehetőséget, és jelentkezzen be.
Az ablak bal felső sarkában kattintson az Azure Machine Learning elemre, válassza a Studio lehetőséget, és jelentkezzen be.Kattintson az ablak alján található +ÚJ gombra.
Válassza az ADATKÉSZLET lehetőséget.
Válassza a HELYI FÁJL LEHETŐSÉGET.
Az Új adathalmaz feltöltése párbeszédpanelen kattintson a Tallózás gombra, és keresse meg a létrehozott german.csv fájlt.
Adja meg az adathalmaz nevét. Ebben az oktatóanyagban az "UCI german credit card data" (UCI német hitelkártyaadatok) nevet ad neki.
Adattípusként válassza az Általános CSV-fájl fejléc nélkül (.nh.csv) lehetőséget.
Igény szerint adjon meg egy leírást.
Kattintson az OK pipára .
Ez feltölti az adatokat egy kísérletben használható adathalmazmodulba.
A (klasszikus) Studióba feltöltött adathalmazokat a Studio (klasszikus) ablakától balra található DATASETS fülre kattintva kezelheti.

További információ más típusú adatok kísérletbe való importálásáról: Betanítási adatok importálása a Machine Learning Studióba (klasszikus)
Kísérlet létrehozása
Az oktatóanyag következő lépése egy kísérlet létrehozása a Machine Learning Studióban (klasszikus), amely a feltöltött adathalmazt használja.
A (klasszikus) Studióban kattintson az ablak alján található +ÚJ gombra.
Válassza a KÍSÉRLET lehetőséget, majd az "Üres kísérlet" lehetőséget.
Válassza ki az alapértelmezett kísérletnevet a vászon tetején, és nevezze át valami értelmes névre.

Tipp
A Tulajdonságok panelen célszerű kitölteni a kísérlet összegzését és leírását. Ezek a tulajdonságok lehetővé teszik a kísérlet dokumentálására, hogy bárki, aki később megtekinti, megérthesse a céljait és módszertanát.

A kísérletvászontól balra található modulpalettán bontsa ki a Mentett adathalmazok elemet.
Keresse meg a Saját adathalmazok területen létrehozott adathalmazt, és húzza a vászonra. Az adatkészletet úgy is megkeresheti, hogy beírja a nevet a paletta feletti Keresőmezőbe .

Az adatok előkészítése
Megtekintheti az adatok első 100 sorát és a teljes adatkészlet néhány statisztikai adatát: Kattintson az adathalmaz kimeneti portjára (alul a kis körre), és válassza a Vizualizáció lehetőséget.
Mivel az adatfájl nem rendelkezett oszlopfejlécekkel, a Studio (klasszikus) általános címsorokat (Col1, Col2 stb.) biztosított. A jó címsorok nem nélkülözhetetlenek a modellek létrehozásához, de megkönnyítik a kísérletben szereplő adatokkal való munkát. Továbbá, amikor végül közzéteszi ezt a modellt egy webszolgáltatásban, a címsorok segítenek azonosítani a szolgáltatás felhasználójának az oszlopokat.
Oszlopfejléceket a Metaadatok szerkesztése modullal adhat hozzá.
A Metaadatok szerkesztése modullal módosíthatja az adathalmazhoz társított metaadatokat. Ebben az esetben az oszlopfejlécek felhasználóbarátabb neveinek megadására szolgál.
A metaadatok szerkesztésének használatához először meg kell adnia, hogy mely oszlopokat kell módosítani (ebben az esetben az összeset).) Ezután megadhatja az oszlopokon végrehajtandó műveletet (ebben az esetben az oszlopfejlécek módosítását).)
A modulkatalógusban írja be a "metaadatok" kifejezést a Keresőmezőbe . A Metaadatok szerkesztése elem megjelenik a modullistában.
Kattintson a Metaadatok szerkesztése modulra, és húzza a vásznon a korábban hozzáadott adathalmaz alá.
Csatlakoztassa az adathalmazt a Metaadatok szerkesztése elemhez: kattintson az adathalmaz kimeneti portjára (az adathalmaz alján található kis körre), húzza a metaadatok szerkesztése bemeneti portjára (a modul tetején található kis körre), majd engedje fel az egérgombot. Az adatkészlet és a modul akkor is csatlakoztatva marad, ha a vásznon mozog.
A kísérletnek így kell kinéznie:
A piros felkiáltójel azt jelzi, hogy még nem állította be a modul tulajdonságait. Ezt a következő lépésben teheti meg.
Tipp
A modulokhoz megjegyzéseket adhat. Ehhez kattintson duplán a kívánt modulra, majd gépelje be a megjegyzés szövegét. Így egyetlen pillantással felmérheti, hogy mire szolgál az adott modul a kísérletben. Ebben az esetben kattintson duplán a Metaadatok szerkesztése modulra, és írja be az "Oszlopfejlécek hozzáadása" megjegyzést. Kattintson bárhová a vásznon a szövegdoboz bezárásához. A megjegyzés megjelenítéséhez kattintson a modul lefelé mutató nyilára.
Válassza a Metaadatok szerkesztése lehetőséget, majd a vászon jobb oldalán lévő Tulajdonságok panelen kattintson az Oszlopkijelölő indítása elemre.
Az Oszlopok kijelölése párbeszédpanelen jelölje ki az elérhető oszlopok összes sorát , és kattintással > helyezze át őket a kijelölt oszlopokba. A párbeszédpanelnek így kell kinéznie:
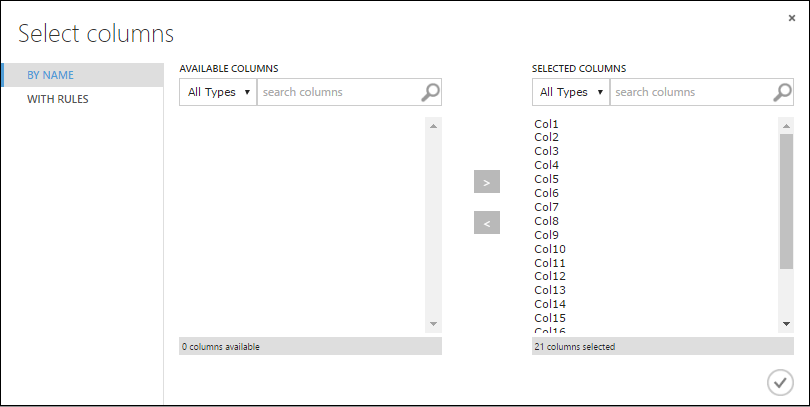
Kattintson az OK pipára .
A Tulajdonságok panelen keresse meg az Új oszlopnevek paramétert. Ebben a mezőben adja meg az adathalmaz 21 oszlopának nevét vesszővel és oszlopsorrenddel elválasztva. Az oszlopneveket az adathalmaz dokumentációjából szerezheti be az UCI webhelyén, vagy az egyszerűség kedvéért másolja és illessze be az alábbi listát:
Status of checking account, Duration in months, Credit history, Purpose, Credit amount, Savings account/bond, Present employment since, Installment rate in percentage of disposable income, Personal status and sex, Other debtors, Present residence since, Property, Age in years, Other installment plans, Housing, Number of existing credits, Job, Number of people providing maintenance for, Telephone, Foreign worker, Credit riskA Tulajdonságok panel a következőképpen néz ki:

Tipp
Ha ellenőrizni szeretné az oszlopfejléceket, futtassa a kísérletet (kattintson a KÍSÉRLET gombra a kísérlet vászna alatt). A futtatás befejezése után (a Metaadatok szerkesztése területen zöld pipa jelenik meg), kattintson a Metaadatok szerkesztése modul kimeneti portjára, és válassza a Vizualizáció lehetőséget. Bármely modul kimenetét ugyanúgy tekintheti meg, mint az adatok előrehaladását a kísérleten keresztül.
Betanítási és tesztelési adatkészletek létrehozása
Szüksége lesz néhány adatra a modell betanítása, mások pedig a teszteléshez. A kísérlet következő lépésében tehát az adathalmazt két külön adathalmazra osztja fel: egyet a modell betanítására, egyet pedig a tesztelésre.
Ehhez az Adatok felosztása modult kell használnia.
Keresse meg az Adatok felosztása modult, húzza a vászonra, és csatlakoztassa a Metaadatok szerkesztése modulhoz.
Alapértelmezés szerint a felosztási arány 0,5, a véletlenszerű felosztási paraméter pedig be van állítva. Ez azt jelenti, hogy az adatok véletlenszerű fele a Split Data modul egyik portjának kimenetén, a másikon pedig a felén keresztül jön létre. Ezeket a paramétereket, valamint a Véletlenszerű mag paramétert is módosíthatja a betanítási és a tesztelési adatok közötti felosztás módosításához. Ebben a példában azokat a következőképpen hagyja meg.
Tipp
Az első kimeneti adatkészlet sorainak törtrésze tulajdonság határozza meg, hogy az adatok mekkora részét adja ki a bal oldali kimeneti porton keresztül. Ha például az arányt 0,7-re állítja, akkor az adatok 70%-a a bal oldali porton, 30%-a pedig a jobb porton keresztül jön létre.
Kattintson duplán az Adatok felosztása modulra, és írja be a "Betanítási/tesztelési adatok 50%-os felosztása" megjegyzést.
Az Adatok felosztása modul kimeneteit tetszés szerint használhatja, de a bal oldali kimenetet használhatja betanítási adatokként, a megfelelő kimenetet pedig tesztelési adatokként.
Amint azt az előző lépésben említettük, a magas hitelkockázat alacsonyként való helytelen besorolásának költsége ötször magasabb, mint az alacsony hitelkockázatok alacsonyként való besorolásának költsége. Ennek figyelembe vételéhez létrehoz egy új adatkészletet, amely tükrözi ezt a költségfüggvényt. Az új adathalmazban a rendszer minden magas kockázatú példát ötször replikál, míg az alacsony kockázatú példákat nem replikálja a rendszer.
Ezt a replikációt R-kóddal végezheti el:
Keresse meg és húzza az Execute R Script modult a kísérletvászonra.
Csatlakoztassa az Adatok felosztása modul bal oldali kimeneti portját az R-szkript végrehajtása modul első bemeneti portjához ("Dataset1").
Kattintson duplán az R-szkript végrehajtása modulra, és írja be a "Költségbeállítás beállítása" megjegyzést.
A Tulajdonságok panelen törölje az alapértelmezett szöveget az R-szkript paraméterből, és írja be a következő szkriptet:
dataset1 <- maml.mapInputPort(1) data.set<-dataset1[dataset1[,21]==1,] pos<-dataset1[dataset1[,21]==2,] for (i in 1:5) data.set<-rbind(data.set,pos) maml.mapOutputPort("data.set")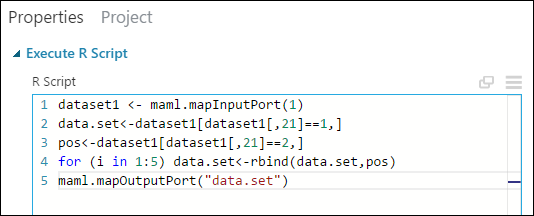
Ugyanezt a replikációs műveletet kell végrehajtania az Adatok felosztása modul minden kimenetén, hogy a betanítási és tesztelési adatok ugyanolyan költségkorrekcióval rendelkezzenek. Ennek legegyszerűbb módja, ha duplikálja az imént létrehozott R-szkript végrehajtása modult, és csatlakoztatja az Adatok felosztása modul másik kimeneti portjához.
Kattintson a jobb gombbal az R-szkript végrehajtása modulra, és válassza a Másolás parancsot.
Kattintson a jobb gombbal a kísérletvászonra, és válassza a Beillesztés parancsot.
Húzza az új modult a pozícióba, majd csatlakoztassa az Adatok felosztása modul megfelelő kimeneti portját az új R-szkript végrehajtása modul első bemeneti portjához.
A vászon alján kattintson a Futtatás gombra.
Tipp
Az Execute R Script modul másolata ugyanazt a szkriptet tartalmazza, mint az eredeti modul. Amikor egy modult másol és illeszt be a vászonra, a másolat megőrzi az eredeti összes tulajdonságát.
A kísérlet most a következőképpen néz ki:
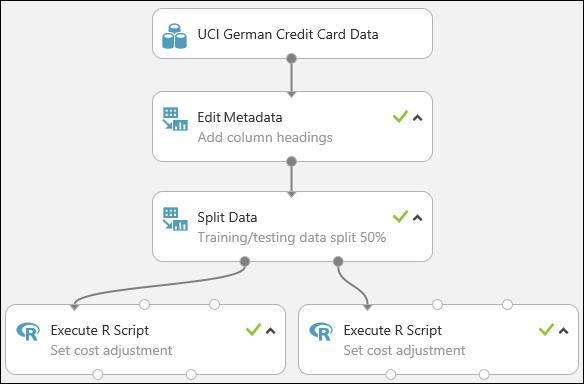
További információ az R-szkriptek kísérletben való használatáról: Kísérlet kiterjesztése az R-vel.
Az erőforrások eltávolítása
Ha már nincs szüksége a cikkben létrehozott erőforrásokra, törölje őket, hogy elkerülje a költségek felmerülését. Ebből a cikkből megtudhatja, hogyan exportálhatja és törölheti a terméken belüli felhasználói adatokat.
Következő lépések
Ebben az oktatóanyagban az alábbi lépéseket hajtotta végre:
- Machine Learning Studio-munkaterület létrehozása (klasszikus)
- Meglévő adatok feltöltése a munkaterületre
- Kísérlet létrehozása
Most már készen áll az adatokhoz tartozó modellek betanítása és kiértékelése.