Regressziós modell betanítása az AutoML és a Python használatával (SDK v1)
ÉRVÉNYES: Python SDK azureml v1
Python SDK azureml v1
Ebből a cikkből megtudhatja, hogyan taníthat be regressziós modellt az Azure Machine Tanulás Python SDK-val az Azure Machine Tanulás automatizált ml használatával. Ez a regressziós modell nyc taxidíjakat jelez előre.
Ez a folyamat elfogadja a betanítási adatokat és a konfigurációs beállításokat, és automatikusan iterálja a különböző funkciók normalizálási/szabványosítási módszereinek, modelljeinek és hiperparaméter-beállításainak kombinációjával a legjobb modell eléréséhez.
Ebben a cikkben a Python SDK használatával ír kódot. A következő feladatokat sajátíthatja el:
- Adatok letöltése, átalakítása és tisztítása az Azure Open Datasets használatával
- Automatizált gépi tanulási regressziós modell betanítása
- Modell pontosságának kiszámítása
Kód nélküli AutoML esetén próbálkozzon az alábbi oktatóanyagokkal:
Előfeltételek
Ha még nincs Azure-előfizetése, kezdés előtt hozzon létre egy ingyenes fiókot. Próbálja ki ma az Azure Machine ingyenes vagy fizetős verzióját Tanulás.
- Végezze el a rövid útmutatót: Első lépések az Azure Machine Tanulás, ha még nem rendelkezik Azure Machine-Tanulás-munkaterülettel vagy számítási példánnyal.
- A rövid útmutató elvégzése után:
- Válassza a Jegyzetfüzetek lehetőséget a stúdióban.
- Válassza a Minták lapot.
- Nyissa meg az SDK v1/tutorials/regression-automl-nyc-taxi-data/regression-automated-ml.ipynb notebookot.
- Ha az oktatóanyagban minden cellát futtatni szeretne, válassza a Jegyzetfüzet klónozása lehetőséget
Ez a cikk a GitHubon is elérhető, ha saját helyi környezetben szeretné futtatni. A szükséges csomagok beszerzéséhez
- Telepítse a teljes
automlügyfelet. - Futtassa
pip install azureml-opendatasets azureml-widgetsa szükséges csomagokat.
Adatok letöltése és előkészítése
Importálja a szükséges csomagokat. Az Open Datasets csomag egy olyan osztályt tartalmaz, amely minden adatforrást képvisel (NycTlcGreen például) a dátumparaméterek egyszerű szűréséhez a letöltés előtt.
from azureml.opendatasets import NycTlcGreen
import pandas as pd
from datetime import datetime
from dateutil.relativedelta import relativedelta
Először hozzon létre egy adatkeretet a taxiadatok tárolásához. Ha nem Spark-környezetben dolgozik, az Adathalmazok megnyitása csak egy hónapnyi adat letöltését teszi lehetővé bizonyos osztályok használatával, így elkerülhető MemoryError a nagy adathalmazok használata.
A taxiadatok letöltéséhez iteratív módon egyszerre egy hónapot kell beolvasni, és mielőtt green_taxi_df véletlenszerűen 2000 rekordot szúrhat be minden hónapból, hogy elkerülje az adatkeret felfúvódását. Ezután tekintse meg az adatokat.
green_taxi_df = pd.DataFrame([])
start = datetime.strptime("1/1/2015","%m/%d/%Y")
end = datetime.strptime("1/31/2015","%m/%d/%Y")
for sample_month in range(12):
temp_df_green = NycTlcGreen(start + relativedelta(months=sample_month), end + relativedelta(months=sample_month)) \
.to_pandas_dataframe()
green_taxi_df = green_taxi_df.append(temp_df_green.sample(2000))
green_taxi_df.head(10)
| vendorID | lpepPickupDatetime | lpepDropoffDatetime | passengerCount | tripDistance | puLocationId | doLocationId | pickupLongitude | pickupLatitude | dropoffLongitude | ... | paymentType | viteldíjAmount | Extra | mtaTax | improvementSurcharge | tipAmount | tollsAmount | ehailFee | totalAmount | tripType |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 131969 | 2 | 2015-01-11 05:34:44 | 2015-01-11 05:45:03 | 3 | 4.84 | Egyik sem | Egyik sem | -73.88 | 40.84 | -73.94 | ... | 2 | 15,00 | 0,50 | 0,50 | 0.3 | 0,00 | 0,00 | Nan | 16.30 |
| 1129817 | 2 | 2015-01-20 16:26:29 | 2015-01-20 16:30:26 | 1 | 0,69 | Egyik sem | Egyik sem | -73.96 | 40.81 | -73.96 | ... | 2 | 4,50 | 1,00 | 0,50 | 0.3 | 0,00 | 0,00 | Nan | 6.30 |
| 1278620 | 2 | 2015-01-01 05:58:10 | 2015-01-01 06:00:55 | 1 | 0,45 | Egyik sem | Egyik sem | -73.92 | 40.76 | -73.91 | ... | 2 | 4,00 | 0,00 | 0,50 | 0.3 | 0,00 | 0,00 | Nan | 4.80 |
| 348430 | 2 | 2015-01-17 02:20:50 | 2015-01-17 02:41:38 | 1 | 0,00 | Egyik sem | Egyik sem | -73.81 | 40.70 | -73.82 | ... | 2 | 12.50 | 0,50 | 0,50 | 0.3 | 0,00 | 0,00 | Nan | 13.80 |
| 1269627 | 1 | 2015-01-01 05:04:10 | 2015-01-01 05:06:23 | 1 | 0,50 | Egyik sem | Egyik sem | -73.92 | 40.76 | -73.92 | ... | 2 | 4,00 | 0,50 | 0,50 | 0 | 0,00 | 0,00 | Nan | 5,00 |
| 811755 | 1 | 2015-01-04 19:57:51 | 2015-01-04 20:05:45 | 2 | 1.10 | Egyik sem | Egyik sem | -73.96 | 40.72 | -73.95 | ... | 2 | 6.50 | 0,50 | 0,50 | 0.3 | 0,00 | 0,00 | Nan | 7,80 |
| 737281 | 1 | 2015-01-03 12:27:31 | 2015-01-03 12:33:52 | 1 | 0.90 | Egyik sem | Egyik sem | -73.88 | 40.76 | -73.87 | ... | 2 | 6,00 | 0,00 | 0,50 | 0.3 | 0,00 | 0,00 | Nan | 6.80 |
| 113951 | 1 | 2015-01-09 23:25:51 | 2015-01-09 23:39:52 | 1 | 3.30 | Egyik sem | Egyik sem | -73.96 | 40.72 | -73.91 | ... | 2 | 12.50 | 0,50 | 0,50 | 0.3 | 0,00 | 0,00 | Nan | 13.80 |
| 150436 | 2 | 2015-01-11 17:15:14 | 2015-01-11 17:22:57 | 1 | 1.19 | Egyik sem | Egyik sem | -73.94 | 40.71 | -73.95 | ... | 1 | 7.00 | 0,00 | 0,50 | 0.3 | 1,75 | 0,00 | Nan | 9.55 |
| 432136 | 2 | 2015-01-22 23:16:33 2015-01-22 23:20:13 1 0.65 | Egyik sem | Egyik sem | -73.94 | 40.71 | -73.94 | ... | 2 | 5,00 | 0,50 | 0,50 | 0.3 | 0,00 | 0,00 | Nan | 6.30 |
Távolítsa el azokat az oszlopokat, amelyekre nem lesz szüksége a betanításhoz vagy más funkcióépítéshez. A gépi tanulás automatizálása automatikusan kezeli az olyan időalapú funkciókat, mint a lpepPickupDatetime.
columns_to_remove = ["lpepDropoffDatetime", "puLocationId", "doLocationId", "extra", "mtaTax",
"improvementSurcharge", "tollsAmount", "ehailFee", "tripType", "rateCodeID",
"storeAndFwdFlag", "paymentType", "fareAmount", "tipAmount"
]
for col in columns_to_remove:
green_taxi_df.pop(col)
green_taxi_df.head(5)
Adatok tisztítása
Futtassa a függvényt describe() az új adatkereten az egyes mezők összesített statisztikáinak megtekintéséhez.
green_taxi_df.describe()
| vendorID | passengerCount | tripDistance | pickupLongitude | pickupLatitude | dropoffLongitude | dropoffLatitude | totalAmount | month_num day_of_month | day_of_week | hour_of_day |
|---|---|---|---|---|---|---|---|---|---|---|
| darabszám | 48000.00 | 48000.00 | 48000.00 | 48000.00 | 48000.00 | 48000.00 | 48000.00 | 48000.00 | 48000.00 | 48000.00 |
| középérték | 1.78 | 1,37 | 2,87 | -73.83 | 40.69 | -73.84 | 40.70 | 14.75 | 6.50 | 15.13 |
| szórás | 0.41 | 1.04 | 2.93 | 2.76 | 1.52 | 2.61 | 1.44 | 12.08 | 3.45 | 8.45 |
| min. | 1,00 | 0,00 | 0,00 | -74.66 | 0,00 | -74.66 | 0,00 | -300.00 | 1,00 | 1,00 |
| 25% | 2,00 | 1,00 | 1.06 | -73.96 | 40.70 | -73.97 | 40.70 | 7,80 | 3.75 | 8.00 |
| 50% | 2,00 | 1,00 | 1.90 | -73.94 | 40.75 | -73.94 | 40.75 | 11.30 | 6.50 | 15,00 |
| 75% | 2,00 | 1,00 | 3.60. | -73.92 | 40.80 | -73.91 | 40.79 | 17.80 | 9.25 | 22.00 |
| max. | 2,00 | 9,00 | 97.57 | 0,00 | 41.93 | 0,00 | 41.94 | 450.00 | 12.00 | 30.00 |
Az összefoglaló statisztikákból láthatja, hogy számos olyan mező van, amely kiugró értékekkel vagy értékekkel rendelkezik, amelyek csökkentik a modell pontosságát. Először szűrje a lat/hosszú mezőket, hogy a Manhattan terület határán belül legyenek. Ez kiszűri a hosszabb taxiutakat vagy utazásokat, amelyek kiugróan kiugróak a más funkciókkal való kapcsolatuk szempontjából.
Emellett szűrje a tripDistance mezőt úgy, hogy nullánál nagyobb, de 31 mérföldnél kisebb legyen (a két lat/hosszú pár közötti távolság). Ez kiküszöböli a hosszú kiugró utazásokat, amelyek inkonzisztens utazási költséggel rendelkeznek.
Végül, a totalAmount mező negatív értékeket tartalmaz a taxidíjakhoz, ami a modell kontextusában nem értelmezhető, és a passengerCount mező rossz adatokat tartalmaz, a minimális értékek nulla.
Szűrje ki ezeket az anomáliákat lekérdezési függvények használatával, majd távolítsa el az utolsó néhány oszlopot, amelyek betanításhoz szükségtelenek.
final_df = green_taxi_df.query("pickupLatitude>=40.53 and pickupLatitude<=40.88")
final_df = final_df.query("pickupLongitude>=-74.09 and pickupLongitude<=-73.72")
final_df = final_df.query("tripDistance>=0.25 and tripDistance<31")
final_df = final_df.query("passengerCount>0 and totalAmount>0")
columns_to_remove_for_training = ["pickupLongitude", "pickupLatitude", "dropoffLongitude", "dropoffLatitude"]
for col in columns_to_remove_for_training:
final_df.pop(col)
Hívja describe() meg újra az adatokat, hogy a tisztítás a várt módon működjön. Most már rendelkezik egy előkészített és megtisztított taxis, ünnepi és időjárási adatokkal, amelyeket a gépi tanulási modell betanításához használhat.
final_df.describe()
Munkaterület konfigurálása
Hozzon létre egy munkaterület-objektumot a meglévő munkaterületről. A munkaterület egy osztály, amely elfogadja az Azure-előfizetést és az erőforrás-információkat. Emellett létrehoz egy felhőalapú erőforrást a modellfuttatások figyeléséhez és nyomon követéséhez. Workspace.from_config() beolvassa a fájlt config.json , és betölti a hitelesítési adatokat egy nevű wsobjektumba. ws a jelen cikk többi kódjában is használható.
from azureml.core.workspace import Workspace
ws = Workspace.from_config()
Adatok felosztása betanítási és tesztelési csoportokra
Ossza fel az adatokat betanítási és tesztelési csoportokra a train_test_splitscikit-learn kódtárban található függvény használatával. Ez a függvény elkülöníti az adatokat az x (funkciók) adatkészletbe a modell betanítása és az y (előrejelezendő értékek) adatkészletbe tesztelés céljából.
A test_size paraméter határozza meg a teszteléshez lefoglalandó adatok százalékos arányát. A random_state paraméter beállít egy magot a véletlenszerű generátorra, hogy a betanítási teszt felosztásai determinisztikusak legyenek.
from sklearn.model_selection import train_test_split
x_train, x_test = train_test_split(final_df, test_size=0.2, random_state=223)
Ennek a lépésnek az a célja, hogy olyan adatpontokat használjon a kész modell teszteléséhez, amelyeket nem használtak a modell betanítására a valódi pontosság méréséhez.
Más szóval egy jól betanított modellnek képesnek kell lennie pontosan előrejelzéseket készíteni a még nem látott adatokból. Most már előkészítette az adatokat egy gépi tanulási modell automatikus betanításához.
Modell automatikus betanítása
Modell automatikus betanítása a következő lépésekkel:
- Adja meg a kísérlet futtatásának beállításait. Csatolja a betanítási adatokat a konfigurációhoz, és módosítsa a betanítási folyamatot vezérlő beállításokat.
- Küldje el a kísérletet a modell finomhangolásához. A kísérlet elküldése után a folyamat különböző gépi tanulási algoritmusokkal és hiperparaméter-beállításokkal iterál, betartva a megadott korlátozásokat. A pontossági metrikák optimalizálásával a legjobban illeszkedő modellt választja ki.
Betanítási beállítások megadása
Adja meg a betanítás kísérletparaméterét és modellbeállítását. A beállítások teljes listájának megtekintése. A kísérlet elküldése az alapértelmezett beállításokkal körülbelül 5–20 percet vesz igénybe, de ha rövidebb futási időt szeretne, csökkentse a paramétert experiment_timeout_hours .
| Tulajdonság | Érték ebben a cikkben | Leírás |
|---|---|---|
| iteration_timeout_minutes | 10 | Az egyes iterációk időkorlátja percekben. Növelje ezt az értéket olyan nagyobb adathalmazok esetében, amelyeknek több időre van szükségük az egyes iterációkhoz. |
| experiment_timeout_hours | 0.3 | A kísérlet leállása előtt az összes iteráció összevonásának maximális időtartama órákban. |
| enable_early_stopping | Igaz | Megjelölés a korai leállás engedélyezéséhez, ha a pontszám rövid távon nem javul. |
| primary_metric | spearman_correlation | Az optimalizálni kívánt metrika. A legjobban illeszkedő modellt a metrikák alapján választja ki a rendszer. |
| featurization | auto | Az automatikus használatával a kísérlet előre feldolgozhatja a bemeneti adatokat (hiányzó adatok kezelése, szöveg numerikussá alakítása stb.) |
| Bőbeszédűség | logging.INFO | Szabályozza a naplózás szintjét. |
| n_cross_validations | 5 | A keresztérvényesítési felosztások száma, ha az érvényesítési adatok nincsenek megadva. |
import logging
automl_settings = {
"iteration_timeout_minutes": 10,
"experiment_timeout_hours": 0.3,
"enable_early_stopping": True,
"primary_metric": 'spearman_correlation',
"featurization": 'auto',
"verbosity": logging.INFO,
"n_cross_validations": 5
}
Használja a definiált betanítási beállításokat egy objektum paramétereként **kwargsAutoMLConfig . Emellett adja meg a betanítási adatokat és a modell típusát, amely ebben az esetben van regression .
from azureml.train.automl import AutoMLConfig
automl_config = AutoMLConfig(task='regression',
debug_log='automated_ml_errors.log',
training_data=x_train,
label_column_name="totalAmount",
**automl_settings)
Feljegyzés
Az automatizált gépi tanulás előfeldolgozási lépései (funkció normalizálása, hiányzó adatok kezelése, szöveg numerikussá alakítása stb.) az alapul szolgáló modell részévé válnak. Ha a modellt előrejelzésekhez használja, a betanítás során alkalmazott előfeldolgozási lépéseket a rendszer automatikusan alkalmazza a bemeneti adatokra.
Az automatikus regressziós modell betanítása
Hozzon létre egy kísérletobjektumot a munkaterületen. A kísérletek tárolóként szolgálnak az egyes feladatokhoz. Adja át a megadott automl_config objektumot a kísérletnek, és állítsa be a kimenetet a feladat előrehaladásának megtekintéséhez True .
A kísérlet elindítása után a kimenet a kísérlet futtatásakor élőben jeleníti meg a frissítéseket. Minden iteráció esetében megjelenik a modell típusa, a futtatás időtartama és a betanítás pontossága. A mező BEST a metrikák típusától függően a legjobban futó betanítási pontszámot követi nyomon.
from azureml.core.experiment import Experiment
experiment = Experiment(ws, "Tutorial-NYCTaxi")
local_run = experiment.submit(automl_config, show_output=True)
Running on local machine
Parent Run ID: AutoML_1766cdf7-56cf-4b28-a340-c4aeee15b12b
Current status: DatasetFeaturization. Beginning to featurize the dataset.
Current status: DatasetEvaluation. Gathering dataset statistics.
Current status: FeaturesGeneration. Generating features for the dataset.
Current status: DatasetFeaturizationCompleted. Completed featurizing the dataset.
Current status: DatasetCrossValidationSplit. Generating individually featurized CV splits.
Current status: ModelSelection. Beginning model selection.
****************************************************************************************************
ITERATION: The iteration being evaluated.
PIPELINE: A summary description of the pipeline being evaluated.
DURATION: Time taken for the current iteration.
METRIC: The result of computing score on the fitted pipeline.
BEST: The best observed score thus far.
****************************************************************************************************
ITERATION PIPELINE DURATION METRIC BEST
0 StandardScalerWrapper RandomForest 0:00:16 0.8746 0.8746
1 MinMaxScaler RandomForest 0:00:15 0.9468 0.9468
2 StandardScalerWrapper ExtremeRandomTrees 0:00:09 0.9303 0.9468
3 StandardScalerWrapper LightGBM 0:00:10 0.9424 0.9468
4 RobustScaler DecisionTree 0:00:09 0.9449 0.9468
5 StandardScalerWrapper LassoLars 0:00:09 0.9440 0.9468
6 StandardScalerWrapper LightGBM 0:00:10 0.9282 0.9468
7 StandardScalerWrapper RandomForest 0:00:12 0.8946 0.9468
8 StandardScalerWrapper LassoLars 0:00:16 0.9439 0.9468
9 MinMaxScaler ExtremeRandomTrees 0:00:35 0.9199 0.9468
10 RobustScaler ExtremeRandomTrees 0:00:19 0.9411 0.9468
11 StandardScalerWrapper ExtremeRandomTrees 0:00:13 0.9077 0.9468
12 StandardScalerWrapper LassoLars 0:00:15 0.9433 0.9468
13 MinMaxScaler ExtremeRandomTrees 0:00:14 0.9186 0.9468
14 RobustScaler RandomForest 0:00:10 0.8810 0.9468
15 StandardScalerWrapper LassoLars 0:00:55 0.9433 0.9468
16 StandardScalerWrapper ExtremeRandomTrees 0:00:13 0.9026 0.9468
17 StandardScalerWrapper RandomForest 0:00:13 0.9140 0.9468
18 VotingEnsemble 0:00:23 0.9471 0.9471
19 StackEnsemble 0:00:27 0.9463 0.9471
Az eredmények vizsgálata
Ismerje meg az automatikus betanítás eredményeit egy Jupyter-widgettel. A widget lehetővé teszi az összes egyes feladat iterációjának gráfját és táblázatát, valamint a betanítási pontossági metrikákat és metaadatokat. Emellett a legördülő választóval különböző pontossági metrikákra is szűrhet, mint az elsődleges metrika.
from azureml.widgets import RunDetails
RunDetails(local_run).show()
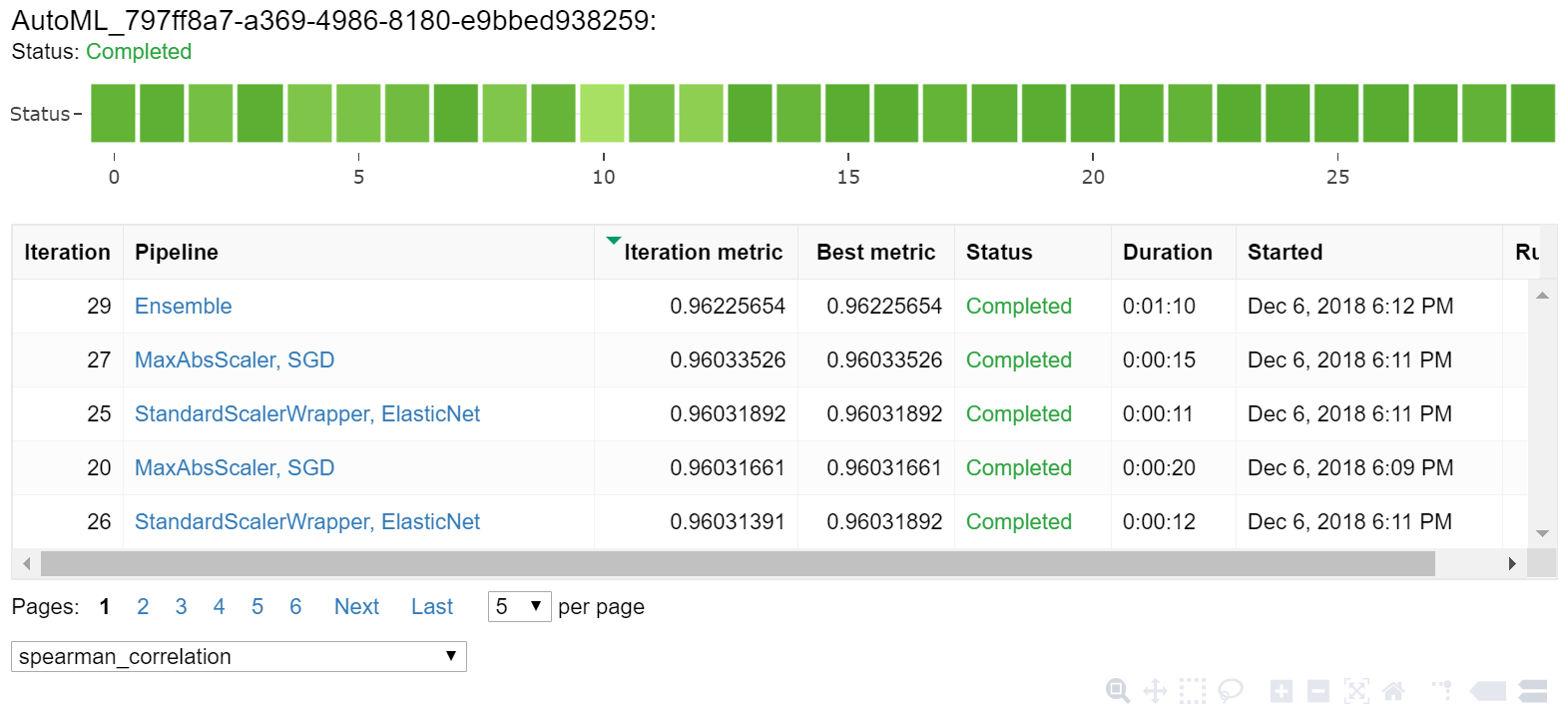
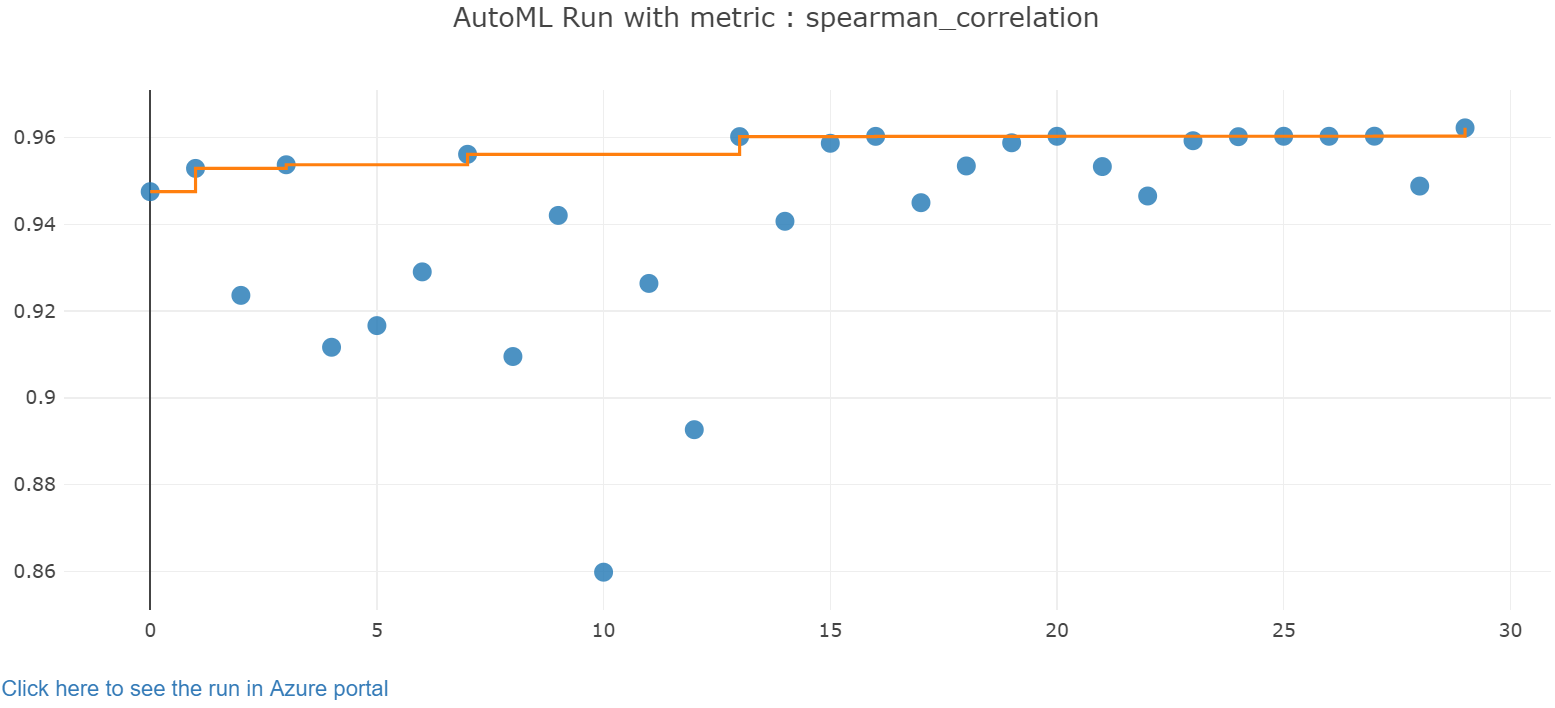
A legjobb modell lekérése
Válassza ki az iterációi közül a legjobb modellt. A get_output függvény a legjobb futást és az utolsó illesztési meghíváshoz beállított modellt adja vissza. A túlterhelések get_outputhasználatával lekérheti a legjobb futtatási és beszerelt modellt minden naplózott metrikához vagy egy adott iterációhoz.
best_run, fitted_model = local_run.get_output()
print(best_run)
print(fitted_model)
A modell legjobb pontosságának tesztelése
A legjobb modell használatával előrejelzéseket futtathat a tesztadatkészleten a taxidíjak előrejelzéséhez. A függvény predict a legjobb modellt használja, és előrejelzi az y, az utazási költség értékét az x_test adathalmazból. Az első 10 előrejelzett költségérték nyomtatása a következőből y_predict: .
y_test = x_test.pop("totalAmount")
y_predict = fitted_model.predict(x_test)
print(y_predict[:10])
Számítsa ki az root mean squared error eredmények értékét. Konvertálja az y_test adatkeretet listává az előrejelzett értékekkel való összehasonlításhoz. A függvény mean_squared_error két értéktömböt használ, és kiszámítja közöttük az átlagos négyzetes hibát. Az eredmény négyzetgyökének figyelembe vételével az y változóval megegyező egységekben hiba jelenik meg. Ez nagyjából azt jelzi, hogy a taxi viteldíj előrejelzései milyen messze vannak a tényleges viteldíjaktól.
from sklearn.metrics import mean_squared_error
from math import sqrt
y_actual = y_test.values.flatten().tolist()
rmse = sqrt(mean_squared_error(y_actual, y_predict))
rmse
Futtassa az alábbi kódot a teljes y_actual és y_predict az adatkészletek használatával kiszámított átlagos abszolút százalékos hiba (MAPE) kiszámításához. Ez a metrika az egyes előrejelzett és tényleges értékek abszolút különbségét számítja ki, és összegzi az összes különbséget. Ezt az összeget a tényleges értékek összegének százalékában fejezi ki.
sum_actuals = sum_errors = 0
for actual_val, predict_val in zip(y_actual, y_predict):
abs_error = actual_val - predict_val
if abs_error < 0:
abs_error = abs_error * -1
sum_errors = sum_errors + abs_error
sum_actuals = sum_actuals + actual_val
mean_abs_percent_error = sum_errors / sum_actuals
print("Model MAPE:")
print(mean_abs_percent_error)
print()
print("Model Accuracy:")
print(1 - mean_abs_percent_error)
Model MAPE:
0.14353867606052823
Model Accuracy:
0.8564613239394718
A két előrejelzési pontossági metrika alapján láthatja, hogy a modell elég jó a taxidíjak előrejelzéséhez az adathalmaz funkcióitól, jellemzően +- 4,00 dolláron belül, és körülbelül 15%-os hiba.
A hagyományos gépi tanulási modell fejlesztési folyamata rendkívül erőforrásigényes, és jelentős tartományi tudást és időbefektetést igényel több tucat modell eredményeinek futtatásához és összehasonlításához. Az automatizált gépi tanulás nagyszerű módja számos különböző modell gyors tesztelésének.
Az erőforrások eltávolítása
Ne fejezze be ezt a szakaszt, ha más Azure Machine-Tanulás oktatóanyagokat szeretne futtatni.
A számítási példány leállítása
Ha számítási példányt használt, állítsa le a virtuális gépet, ha nem használja a költségek csökkentésére.
A munkaterületen válassza a Számítás lehetőséget.
A listában válassza ki a számítási példány nevét.
Válassza a Leállítás lehetőséget.
Ha készen áll a kiszolgáló ismételt használatára, válassza a Start lehetőséget.
Minden törlése
Ha nem tervezi használni a létrehozott erőforrásokat, törölje őket, így nem kell fizetnie.
- Az Azure Portalon válassza az Erőforráscsoportok lehetőséget a bal szélen.
- Válassza ki a listában az Ön által létrehozott erőforráscsoportot.
- Válassza az Erőforráscsoport törlése elemet.
- Adja meg az erőforráscsoport nevét. Ezután válassza a Törlés elemet.
Megtarthatja az erőforráscsoportot is, de egyetlen munkaterületet törölhet. Jelenítse meg a munkaterület tulajdonságait, és válassza a Törlés lehetőséget.
Következő lépések
Ebben az automatizált gépi tanulási cikkben a következő feladatokat végezte el:
- Konfigurált egy munkaterületet, és előkészítette az adatokat egy kísérlethez.
- Betanítás helyileg automatizált regressziós modellel egyéni paraméterekkel.
- Megismert és áttekintett betanítási eredmények.
Az AutoML beállítása számítógépes látásmodellek Betanítása Pythonnal (v1)